 基于Python語言的RFM模型講解
基于Python語言的RFM模型講解
背景
RFM(Recency Frequency Monetary)模型是衡量客戶價值和客戶創利能力的重要工具和手段。在眾多的客戶關系管理(CRM)的分析模式中,RFM模型是被廣泛提到的。
RFM模型是屬于業務分析方法與模型中的部分。它的本質是用戶分類。本文將用現代最流行的編程語言---Python語言來實踐課堂上講解的RFM模型,將用戶進行分類。
本文采用Anaconda進行Python編譯,主要涉及的Python模塊:
-
pandas
-
matplotlib
-
seaborn
-
datetime
本章分為三部分講解:
1.RFM模型原理與步驟
2.Python分布實現RFM
3.總結
RFM模型原理與步驟
RFM模型的思路是:該模型是根據用戶歷史行為數據,結合業務理解選擇劃分維度,實現用戶分類,助力用戶精準營銷。此外,還學習了構建RFM模型的步驟:
-
獲取R、F、M三個維度下的原始數據
-
定義R、F、M的評估模型與判斷閾值
-
進行數據處理,獲取R、F、M的值
-
參照評估模型與閾值,對用戶進行分層
-
針對不同層級用戶制定運營策略
上面步驟可以知道,我們需要有RFM三個維度,根據我們在業務分析方法課程中學到的,業務分析模型離不開指標,而指標是對度量的匯總。因此,在找出RFM三個維度后,需要對每個維度下度量實現不同匯總規則。下面講述對R、F、M三個維度下的度量如何進行匯總。
1.R代表最近一次消費,是計算最近一次消費時間點和當前時間點的時間差。因此,這里需要用到多維數據透視分析中的基本透視規則---最小值MIN求出最小的時間差。
2.F代表消費頻次,是在指定區間內統計用戶的購買次數。因此,這里需要用到多維數據透視分析中的基本透視規則---技術類COUNT(技術類不去重指標)統計用戶的購買次數。
3.M代表消費金額,是指在指定區間內統計用戶的消費總金額,因此,這里需要用到求和類指標,也即基本透視規則中的合計規則---SUM。
在對得到RFM模型中的指標值后最重要的一步就是分層,根據我們在課堂上學到的內容,大部分的用戶分層是根據經驗來分層的,本文在追求數據的客觀性下采取統計學中的等距分箱方法來進行分層,對R、F、M三個維度分成兩類。
綜上,我們大致了解了如何構建RFM模型,下面以Python實現RFM模型,并對每一步進行詳細的講解。
03 Python實現RFM模型
數據準備
本文所需的數據是一家公司對2021年10月底至今的客戶購買行為數據,(前十二行)如圖下:
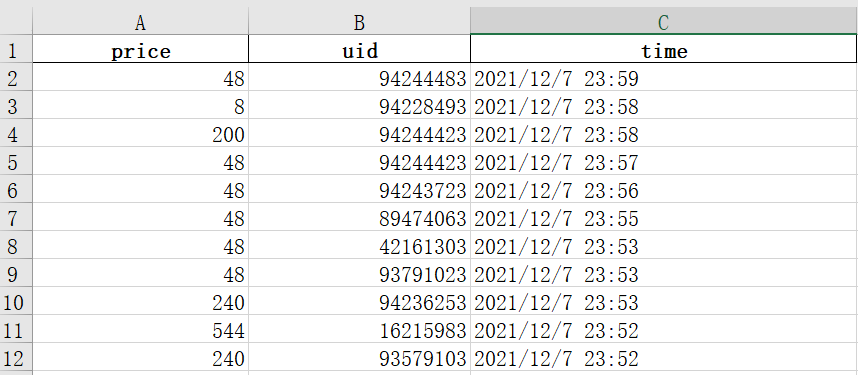
其中,uid代表客戶的id,是存在重復情況的。prince維度代表客戶每發生一次交易行為所花費的金額。time為客戶發生交易行為的時間。
數據讀取與理解
在得到一份數據之后,我們第一步就是要理解數據的業務意義,以及對數據表的EDA(探索性分析),這里通過如下代碼,發現以下特征:

具體代碼(包含Python導入包部分)如下:
#導入相關包
importpandasaspd
importtime
importnumpyasnp
importseabornassns
importmatplotlib.pyplotasplt
plt.rcParams['font.sans-serif']=["SimHei"]
plt.rcParams["axes.unicode_minus"]=Falsesns.set(style="darkgrid")
#數據讀取與查看
data=pd.read_excel('data.xlsx')
data.head()
data.isnull().sum()#查看缺失值
data.duplicated().sum()#重復值,但是不刪
data.dtypes#查看數據類型
data.describe()
#創建dataframe,存放RFM各值
data_rfm=pd.DataFrame()
接下來進行R、F、M指標值構建。
時間維度處理
從上文可以知道time維度,即每筆交易行為發生的時間是字符串object的格式,而在Python中我們對時間作差需要的是datetime格式,因此利用pandas庫中的pd.to_datetime函數將時間格式進行轉換,代碼如下:
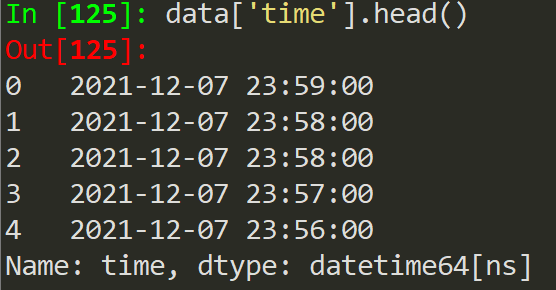
data['time']=pd.to_datetime(data['time'])
得到的前五行數據如圖下,可以看到數據類型變成了datetime64[ns]
統計每筆訂單產生時間與當前時間的差(這里的當前時間是2021年12月11日),得到的差是timedelta64[ns]類型
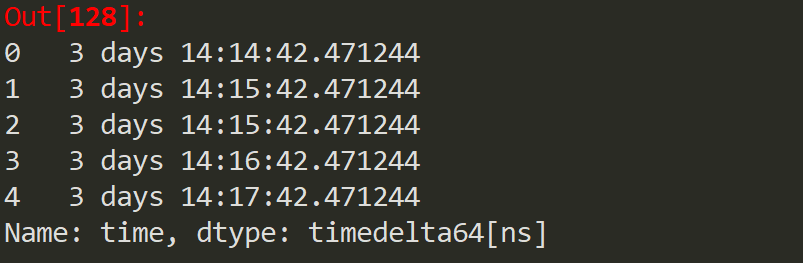
可以看到時間差中包含了day、時、分、秒4個維度,但是這里我們僅需要day維度,因此我們用astype()函數將類型轉為僅含有day維度的timedelta64[D]類型。具體代碼如下:
#統計沒條數據與當前日期的時間差
##計算相差天數
data['R']=(pd.datetime.now()-data['time'])
##將時間差timedelta格式轉化為需要的日格式
data['R']=data['R'].astype('timedelta64[D]').astype('int')
(tips:這里可能會報警告:FutureWarning: The pandas.datetime class is deprecated and will be removed from pandas in a future version. Import from datetime module instead.讀者無需理會,這是由于我們所用的pd.datetime.now()是一個比較舊的函數,以后將會廢棄。)
統計R值
在上面我們已經創建了名為data_rfm的表結構的數據框,因此,將下面統計的R值放入其中。R值得統計是找客戶最近發生交易行為日期與當前日期的差。換一種思路就是找所有時間差中的最小值。
因此利用pandas中的groupby函數對每個用戶以上一步統計的R值作為分組依據進行分組,并求出最小值。具體代碼如下:
data_rfm=pd.merge(data_rfm,data.groupby('uid')['R'].min(),
left_on='user_id',right_on='uid')
統計F值
F值得統計就是統計指定區間內的消費頻次,而指定區間一般為人為設定,這里我們取全部數據,即2021年10月底至今作為指定區間。
本文利用value_counts()函數對uid進行統計即為每個用戶得消費頻次,同時將結果合并到data_rfm數據框中。
#統計指定區間內的消費頻次
data_rfm['user_id']=data['uid'].value_counts().index
data_rfm['F']=data['uid'].value_counts().values
統計M值
本文以uid作為分組依據對price字段進行求和,得到求和類指標M值。此外,將結果合并到data_rfm數據框中。
data_rfm=pd.merge(data_rfm,data.groupby('uid')['price'].sum(),
left_on='user_id',right_on='uid')
data_rfm.rename(columns={'price':'M'},inplace=True)
上述代碼中出現了pandas庫中得合并語法merge(),merge()函數采取的是橫向合并,不同于MYSQL,不需要指定左表還是右表為主表,只需要提供左表與右表的公共字段在各表中的名稱即可。
由于data_rfm數據表中的user_id是去重的,因此將其作為主鍵。而data.groupby('uid')['price'].sum()得到的表格也是去重的,因此我們可以采取多維數據模型中的連接對應關系---一對一對兩表進行合并。公共字段為:左表的uid,右表的user_id。
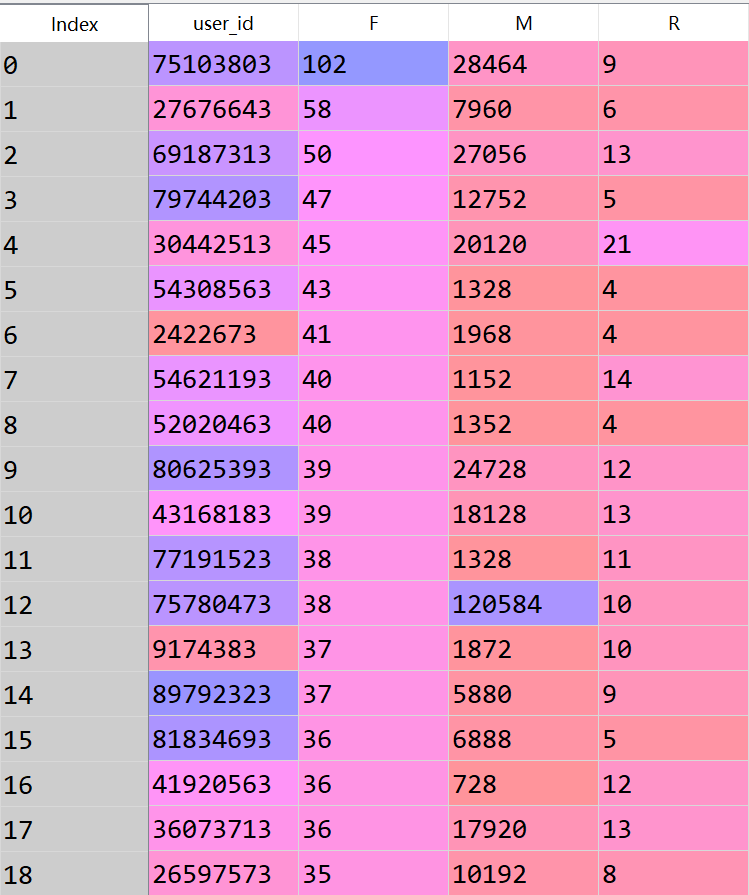
最終表格結果如下,展現前18行:
數據分箱
在得到R、F、M三個指標值后,我們需要對這三個指標進行分類,并將每個用戶進行分層。
本文不采取人為主觀性的經驗法則劃分,而是采取等距分箱的方式劃分,等距分箱的原理較簡單,這里寫出步驟:
-
從最小值到最大值之間,均分為$N$等份(這里$N$取為2)。
-
如果 $A$,$B$ 為最小最大值, 則每個區間的長度為 $W=(B?A)/N$ ,.
-
則區間邊界值為$A+W$,$A+2W$,….$A+(N?1)W$ 。這里只考慮邊界,采用左閉右開的方式,即每個等份的實例數量不等。
在Python中可以利用pandas庫中的cut()函數輕松實現上述等距分箱,同時將結果R_label,F_label,M_label合并到data_rfm數據框中具體代碼如下:
#分箱客觀左閉右開
cut_R=pd.cut(data_rfm['R'],bins=2,right=False,labels=range(1,3)).astype('int')
data_rfm['R_label']=cut_R
cut_F=pd.cut(data_rfm['F'],bins=2,right=False,labels=range(1,3)).astype('int')
data_rfm['F_label']=cut_F
cut_M=pd.cut(data_rfm['M'],bins=2,right=False,labels=range(1,3)).astype('int')
data_rfm['M_label']=cut_M
由于利用cut()函數得到的是區間形式的值,因此需要賦予label值進行虛擬變量引用。label值使用1和2,對應的區間為從小到大。具體代表意思如下表:

得到最終的表格形式如下:
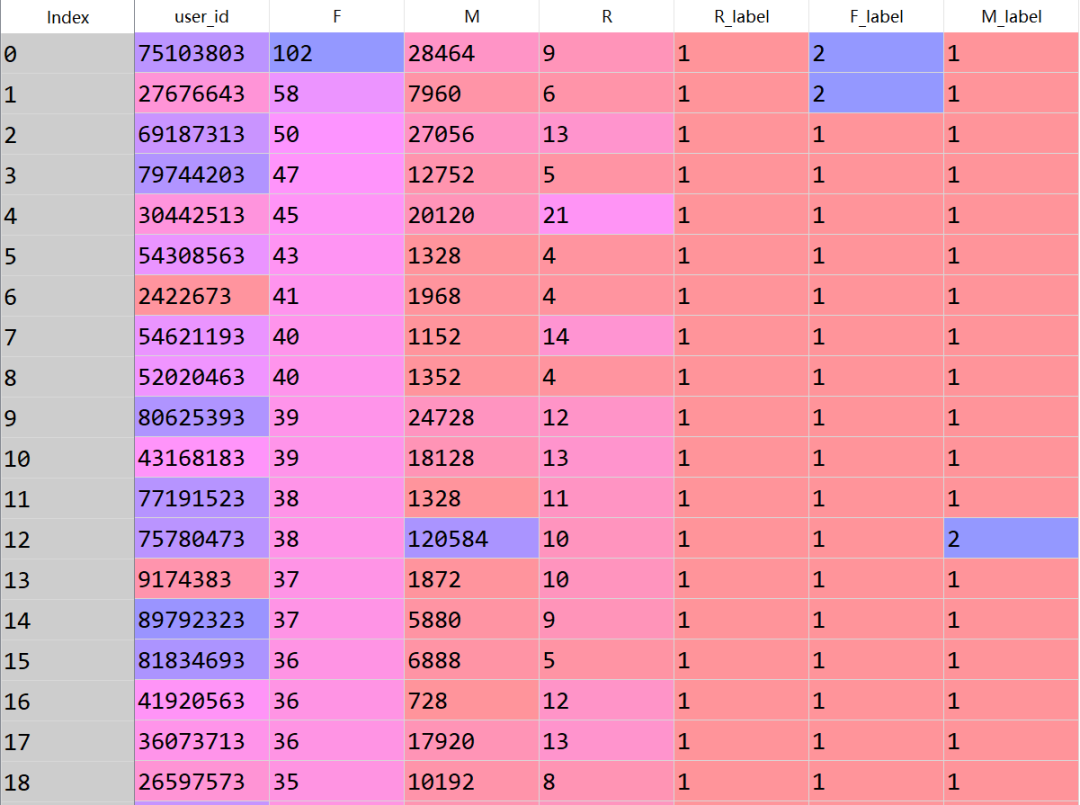
用戶分類
在得到每個用戶的R、F、M三個維度的label值后,最后就是需要對用戶進行分類,分類的原則如圖下:
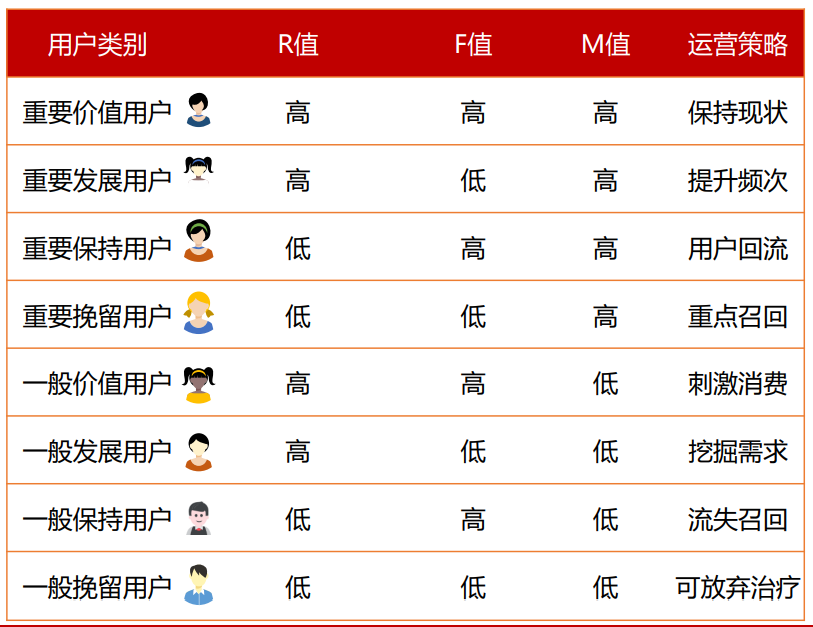
利用pandas庫中的·terrows()函數循環遍歷每個用戶行為記錄,將符合上述條件的劃分對應的類,具體代碼如下:
fori,jindata_rfm.iterrows():
ifj['R_label']==2andj['F_label']==2andj['M_label']==2:
data_rfm.loc[i,'用戶類別']='重要價值用戶'
ifj['R_label']==2andj['F_label']==1andj['M_label']==2:
data_rfm.loc[i,'用戶類別']='重要發展用戶'
ifj['R_label']==1andj['F_label']==2andj['M_label']==2:
data_rfm.loc[i,'用戶類別']='重要保持用戶'
ifj['R_label']==1andj['F_label']==1andj['M_label']==2:
data_rfm.loc[i,'用戶類別']='重要挽留用戶'
ifj['R_label']==2andj['F_label']==2andj['M_label']==1:
data_rfm.loc[i,'用戶類別']='一般價值用戶'
ifj['R_label']==2andj['F_label']==1andj['M_label']==1:
data_rfm.loc[i,'用戶類別']='一般發展用戶'
ifj['R_label']==1andj['F_label']==2andj['M_label']==1:
data_rfm.loc[i,'用戶類別']='一般保持用戶'
ifj['R_label']==1andj['F_label']==1andj['M_label']==1:
data_rfm.loc[i,'用戶類別']='一般挽留用戶'
條形圖可視化用戶類別
利用seaborn畫圖庫對已劃分類別的用戶進行技術統計與可視化,得到如下圖表
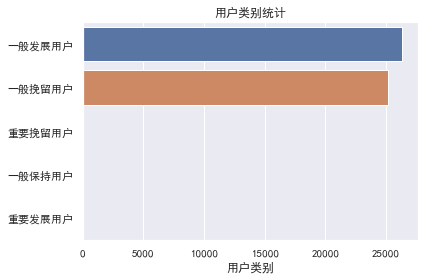
可以看出,大部分的用戶屬于一般發展用戶與一般挽留用戶。而對于一般發展用戶而言采取的策略為挖掘需求,后者則是放棄治療。因此,可以看出該公司在10月底至今的時間段內,用戶流失較多,但是可發展的用戶同樣是非常多的,想要提高收入,對一般發展用戶入手是成本少,效率高的選擇。
總結
RFM模型同時還利用了多維數據透視分析和業務分析方法兩個模塊的內容。所以說實踐是檢驗和鞏固學到的東西的最好方法。
例如一級的常考題上,我們常碰到一個模擬題,包含RFM模型劃分規則和一張帕累托圖,問題是在公司有限成本下提高公司收入,需要針對哪種用戶營銷最好,答案是一般發展用戶。相信大家一開始都很疑惑為什么選這個,這時候如果像本文一樣對一份數據進行實踐,這樣你就會更加理解為什么是這個答案。
審核編輯:郭婷
-
python
+關注
關注
56文章
4792瀏覽量
84628
原文標題:基于客觀事實的 RFM 模型(Python 代碼)
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型開發語言是什么
對比Python與Java編程語言
【《大語言模型應用指南》閱讀體驗】+ 基礎篇
python訓練出的模型怎么調用
大語言模型(LLM)快速理解






 工商網監
工商網監
評論