") CFI的基本概念
CFI的基本概念
偉林,中年碼農(nóng),從事過電信、手機、安全、芯片等行業(yè),目前依舊從事Linux方向開發(fā)工作,個人愛好Linux相關(guān)知識分享,個人微博CSDN pwl999,歡迎大家關(guān)注!
目錄
1. 簡介
1.1 控制流攻擊歷史 1.2 CFI的基本概念 1.3 CFI發(fā)展歷史
2. Orig CFI
2.1 Windows CFG的實現(xiàn)
3. CCFIR
4. VTV
5. Kernel CFI
5.1 forward-edge protection CFI(Control-Flow Integrity) 5.2 backward-edge protection SCS(Shadow Call Stack) 5.3 Shared library support(Cross-DSO)
6. 利用硬件來提升CFI的效率
01 簡介
? CFI: Control-Flow Integrity(控制流完整性)
? CFG: Control Flow Guard(Windows的CFI實現(xiàn))
? CFG: Control-Flow Graph(控制流圖)
? LTO: Link Time Optimization(鏈接時優(yōu)化)
1.1 控制流攻擊歷史
控制流劫持是一種危害性極大的攻擊方式,攻擊者能夠通過它來獲取目標機器的控制權(quán),甚至進行提權(quán)操作,對目標機器進行全面控制。當攻擊者掌握了被攻擊程序的內(nèi)存錯誤漏洞后,一般會考慮發(fā)起控制流劫持攻擊。
●shellcode
早期的攻擊通常采用代碼注入(shellcode)的方式,通過上載一段代碼,將控制轉(zhuǎn)向這段代碼執(zhí)行。
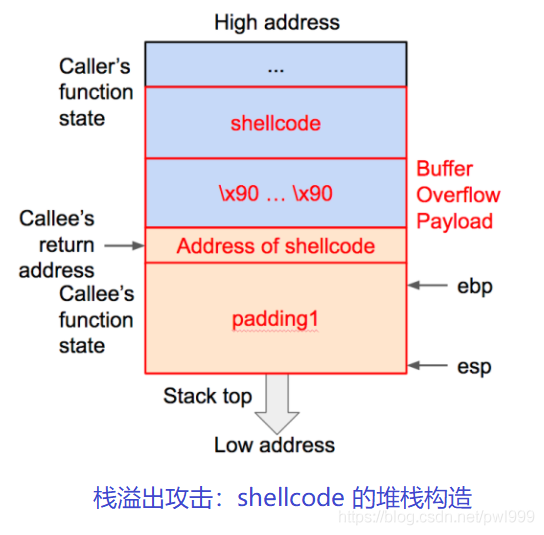
為了阻止這類攻擊,后來的計算機系統(tǒng)中都基本上都部署了NX/DEP(Data Execution Prevention)機制,通過限定內(nèi)存頁不能同時具備寫權(quán)限和執(zhí)行權(quán)限,來阻止攻擊者所上載的代碼的執(zhí)行。
●Return2libc/ROP
為了突破DEP的防御,攻擊者又探索出了代碼重用攻擊方式,他們利用被攻擊程序中的代碼片段,進行拼接以形成攻擊邏輯。代碼重用攻擊包括Return-to-libc、ROP(Return Oriented Programming)、JOP(Jump Oriented Programming)等。研究表明,當被攻擊程序的代碼量達到一定規(guī)模后,一般能夠從被攻擊程序中找到圖靈完備的代碼片段。
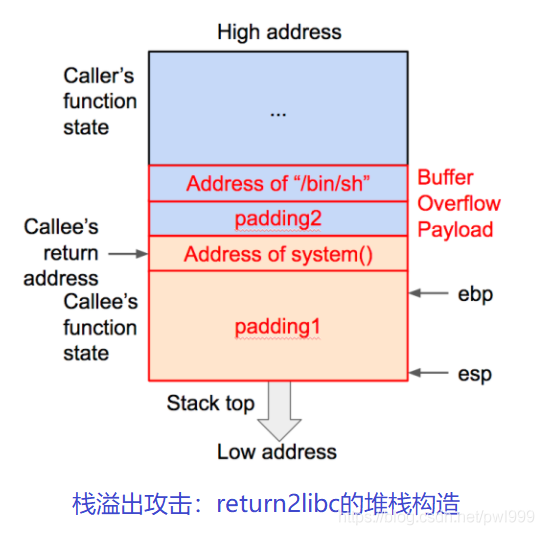
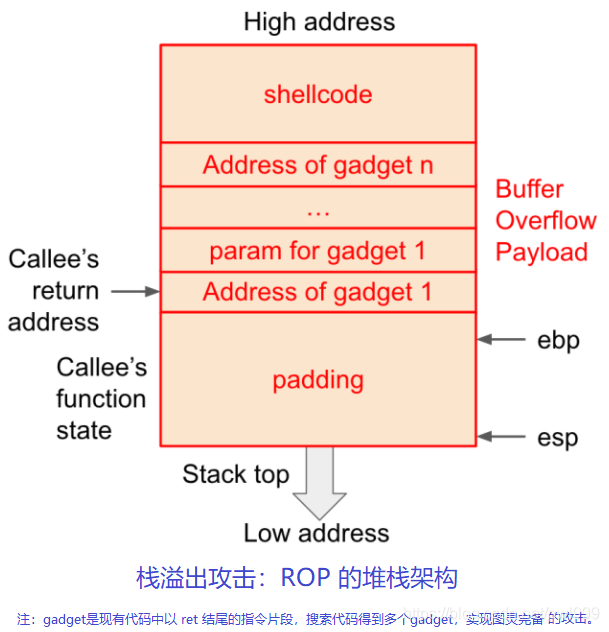
Return2libc/ROP利用return間接訪問,繞過了NX/DEP訪問。因為代碼并不會直接在堆棧上執(zhí)行,而只是根據(jù)堆棧中的地址,間接跳轉(zhuǎn)到對應(yīng)正常代碼段執(zhí)行。
● DOP
DOP(Data Oriented Programming)攻擊。隨著防護技術(shù)的發(fā)展,針對控制流的攻擊變得愈發(fā)困難。而不通過劫持控制流,而是針對數(shù)據(jù)流來進行攻擊的方式,如Non-control data(非控制數(shù)據(jù))攻擊雖然顯示出了其潛在的危害性,但目前對針對數(shù)據(jù)流的攻擊還知之甚少,長久以來該攻擊手段可實現(xiàn)的攻擊目標一直被認為是有限的。實際上,非控制數(shù)據(jù)攻擊可以是圖靈完備的,這就是DOP攻擊。
類似于ROP,DOP攻擊的實現(xiàn)也依賴于gadgets。但二者有以下兩點不同:
1、DOP的gadgets只能使用內(nèi)存來傳遞操作的結(jié)果,而ROP的gadgets可以使用寄存器。
2、DOP的gadgets必須符合控制流圖(CFG),不能發(fā)生非法的控制流轉(zhuǎn)移,而且無需一個接一個的執(zhí)行。而ROP的gadgets必須成鏈,順序執(zhí)行。
● CFI
為了應(yīng)對這些新型的控制流劫持攻擊,加州大學(xué)和微軟公司于2005年提出了控制流完整性(Control Flow Integrity, CFI)的防御機制。其核心思想是限制程序運行中的控制轉(zhuǎn)移,使之始終處于原有的控制流圖所限定的范圍內(nèi)。具體做法是通過分析程序的控制流圖,獲取間接轉(zhuǎn)移指令(包括間接跳轉(zhuǎn)、間接調(diào)用、和函數(shù)返回指令)目標的白名單,并在運行過程中,核對間接轉(zhuǎn)移指令的目標是否在白名單中。控制流劫持攻擊往往會違背原有的控制流圖,CFI使得這種攻擊行為難以實現(xiàn),從而保障軟件系統(tǒng)的安全。
CFI從實現(xiàn)角度上,被分為細粒度和粗粒度兩種。細粒度CFI嚴格控制每一個間接轉(zhuǎn)移指令的轉(zhuǎn)移目標,這種精細的檢查,在現(xiàn)有的系統(tǒng)環(huán)境中,通常會引入很大的開銷。而粗粒度CFI則是將一組類似或相近類型的目標歸到一起進行檢查,以降低開銷,但這種方法會導(dǎo)致安全性的下降。
CFI對非控制數(shù)據(jù)的攻擊無能為力,但是這不妨礙我們詳細研究CFI的實現(xiàn)原理。
1.2 CFI的基本概念
了解CFI(Control-Flow Integrity),需要從CFG(Control-Flow Graph)講起。這里的CFG是基于靜態(tài)分析的用圖的方式表達程序的執(zhí)行路徑(函數(shù)級別,非指令級別?):
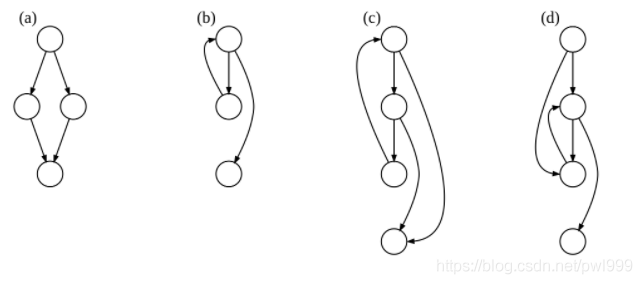
CFI并不會檢測CFG中所有的邊,為了降低開銷受檢測的邊應(yīng)該越少越好。因此在CFG中只考慮將可能受到攻擊的間接call、間接jmp和ret指令作為邊。
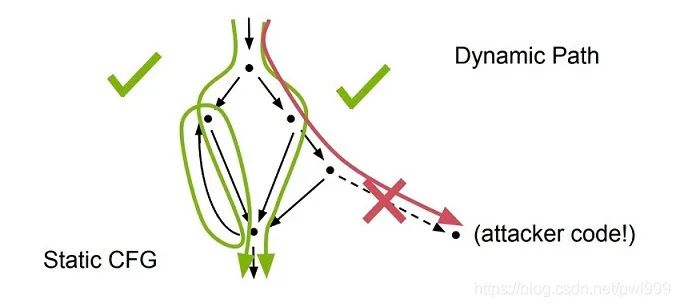
如上圖,綠色的靜態(tài)控制流路徑并不易受到攻擊,紅色的動態(tài)控制流路徑容易受到攻擊。靜態(tài)路徑就是直接跳轉(zhuǎn),動態(tài)路徑就是間接跳轉(zhuǎn)的路徑。
●直接跳轉(zhuǎn)和間接跳轉(zhuǎn)
直接跳轉(zhuǎn)指令的示例如下所示:
1| CALL 0x1060000F
在程序執(zhí)行到這條語句時,就會將指令寄存器的值替換為0x1060000F。這種在指令中直接給出跳轉(zhuǎn)地址的尋址方式就叫做直接轉(zhuǎn)移。在高級語言中, 像if-else,靜態(tài)函數(shù)調(diào)用這種跳轉(zhuǎn)目標往往可以確定的語句就會被轉(zhuǎn)換為直接跳轉(zhuǎn)指令。
間接跳轉(zhuǎn)指令則是使用數(shù)據(jù)尋址方式間接的指出轉(zhuǎn)移地址,比如:
1| JMP EBX
執(zhí)行完這條指令之后, 指令寄存器的值就被替換為EBX寄存器的值。它的轉(zhuǎn)換對象為作為回調(diào)參數(shù)的函數(shù)指針等動態(tài)決定目標地址的語句。
●前向轉(zhuǎn)移(forward)和后向轉(zhuǎn)移(backward)
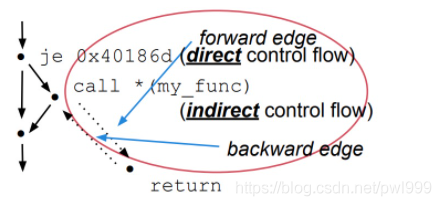
將控制權(quán)定向到程序中一個新位置的轉(zhuǎn)移方式, 就叫做前向轉(zhuǎn)移, 比如jmp和call指令。
而將控制權(quán)返回到先前位置的就叫做后向轉(zhuǎn)移, 最常見的就是ret指令。
將以上兩種分類方式結(jié)合起來:
前向轉(zhuǎn)移指令call和jmp根據(jù)尋址方式不同, 又可以分為直接jmp, 間接jmp,直接call,間接call四種。
后向轉(zhuǎn)移指令ret沒有操作數(shù),它的目標地址計算是通過從棧中彈出的數(shù)來決定的。正因為ret指令的特性,引發(fā)了一系列針對返回地址的攻擊。
CFI(Control-Flow Integrity)關(guān)注的就是間接jmp、間接call、ret這幾種指令控制流的完整性。
1.3 CFI發(fā)展歷史
Control-Flow-Integrity這篇文章詳細的描述了CFI的發(fā)展歷史。
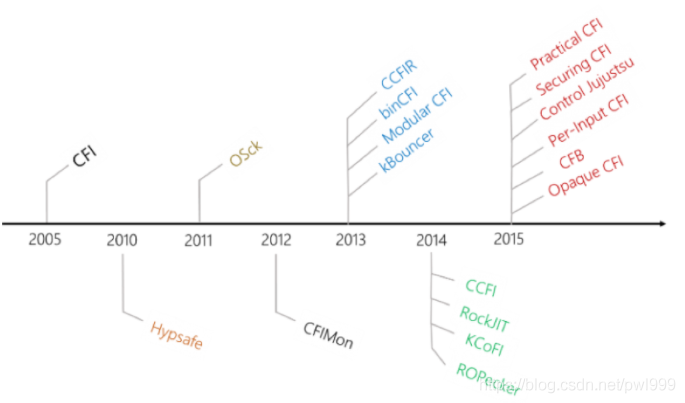
上圖是CFI技術(shù)發(fā)展的歷史路線圖,其中代表性的有四種CFI技術(shù),下圖是這四種技術(shù)在各個維度的一個比較:
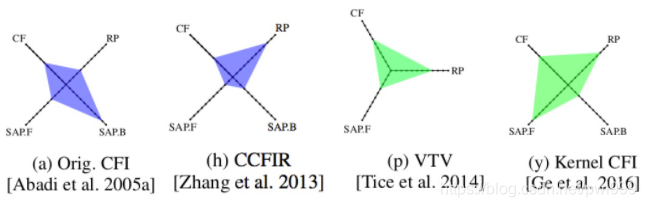
上圖,是各個CFI技術(shù)在安全性能四個維度的得分:
●一個是支持的控制流傳輸方案,比如前向后向、間接返回等等,用CF表示。
●二是性能數(shù)值,用1-10來區(qū)別,10為最高分,用RP來表示。
●SAP.F是對前向控制流的靜態(tài)分析精度,
●SAP.B是對后向控制流的分析精度。
02 Orig CFI
原始CFI技術(shù)都來源于這篇文章:Control-Flow Integrity Principles, Implementations, and Applications。
這種技術(shù)的思想就是在就是間接jmp、間接call、ret這幾種指令的控制流中插樁,在間接跳轉(zhuǎn)之前判斷跳轉(zhuǎn)地址是否合法。
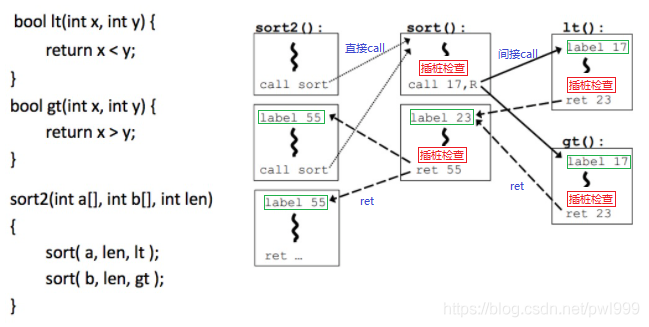
用上圖來解釋,利用左側(cè)的代碼生成了右側(cè)的CFG控制流圖。其中的直接call路徑是不用關(guān)注的,針對間接call和ret指令的控制流路徑,插入代碼進行判斷:
1、在間接call和ret的目標地址插入一個獨有的label id。
2、在間接call和ret指令之前插入一段樁代碼,來檢查目的地址的id是否合法。合法才能間接跳轉(zhuǎn),不合法則出錯返回。
3、還約定如果指向兩個目標地址的邊擁有相同的源集合的話,那么這兩個目標地址就是等價的,等價的目標用同一label表示。所以我們看到兩個相同的label 55和兩個相同的label 17。這就是一種粗粒度的CFI,它將多個不同的目標地址合在一起減少需要檢測目標地址的數(shù)量。為了降低性能開銷,是以犧牲安全性為前提的。
下圖是上述理論在x86上的一個具體實現(xiàn):
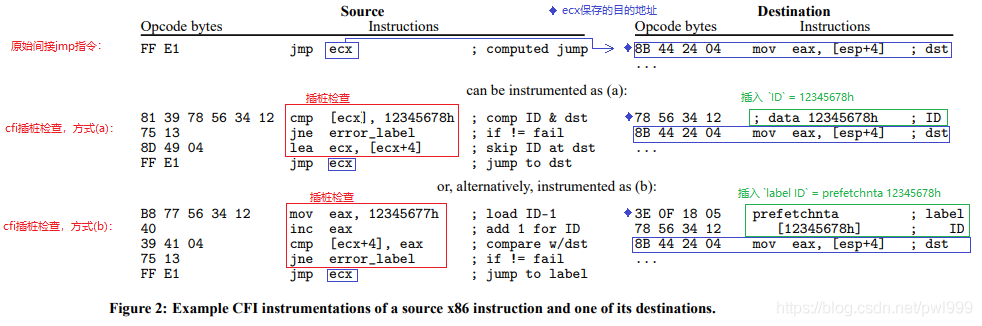
●原始狀態(tài):ecx保存了目的地址,jmp ecx間接跳轉(zhuǎn)到目的地址執(zhí)行
●插樁方式(a):首先在目的地址插入一個4字節(jié)ID 12345678h,然后在jmp跳轉(zhuǎn)前插入一段樁函數(shù)判斷,判斷目的地址的值是否為12345678h。不合法則出錯處理,合法則間接跳轉(zhuǎn)到[ecx + 4]地址執(zhí)行原來的目的指令。
●插樁方式(b):在方式(a)的基礎(chǔ)上做了優(yōu)化,首先在目的地址插入一個4字節(jié)的lable指令prefetchnta + 4字節(jié)ID 12345678h,然后在jmp跳轉(zhuǎn)前插入一段樁函數(shù)判斷,判斷[ecx + 4]地址的值是否為12345678h。不合法則出錯處理,合法則間接跳轉(zhuǎn)到[ecx]地址執(zhí)行l(wèi)abel ID指令。注意這里的技巧是判斷合法后,還是跳轉(zhuǎn)到ecx原地址,但是這時這個地址上存儲的是label ID指令,這條命令沒啥副作用,緊接著才會繼續(xù)執(zhí)行原有的命令。
下圖是間接jmp、ret指令路徑,都被cfi插樁的情況:

CFI確保運行時執(zhí)行沿著給定的CFG進行,例如,保證典型功能的執(zhí)行始終從頭開始,并從頭到尾進行。因此,CFI可以提高任何基于CFG的技術(shù)的可靠性(例如,增強現(xiàn)有技術(shù)以防止緩沖區(qū)溢出和入侵檢測[32,58])。下面介紹基于CFI的其他應(yīng)用,內(nèi)聯(lián)參考監(jiān)視器IRM(Inlined Reference Monitors)、SFI(Software Fault Isolation)、軟件內(nèi)存訪問控制SMAC(Software Memory Access Control),我們在此介紹它們。它還顯示了如何依靠SMAC或標準x86硬件支持來加強CFI實施。
下圖還展示了一個影子調(diào)用堆棧(shadow call stack)的原理,這是ret路徑上的另一種cfi保護形式:
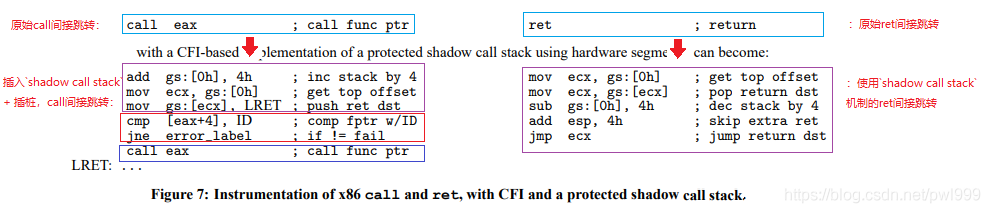
●shadow call stack 在 ret路徑上不再使用判斷id是否正確的方式,而是把返回地址在另外一個堆棧另存了一份,這樣棧溢出漏洞無法覆蓋,就算堆棧溢出但是函數(shù)還是返回到原來的調(diào)用位置。
●在函數(shù)調(diào)用前的時候,把返回地址備份到shadow call stack。
●在函數(shù)返回前,從shadow call stack中彈出備份的返回地址,廢棄掉原堆棧中的返回地址,這樣ret返回地址的安全性多了一層保障。
實現(xiàn)CFI,三個假設(shè)成立至關(guān)重要。這三個假設(shè)是:
● UNQ. 唯一ID:在CFI檢測之后,除了ID和ID檢查之外,選擇為ID的位模式不得出現(xiàn)在代碼存儲器中的任何位置。通過使ID足夠大(例如32位,對于合理大小的軟件)并且通過選擇ID使得它們不與軟件的其余部分中的操作碼字節(jié)沖突,可以容易地實現(xiàn)該屬性。
● NWC. 不可寫代碼:程序必須無法在運行時修改代碼內(nèi)存。否則,攻擊者可能能夠繞過CFI,例如通過覆蓋ID檢查。除了在加載動態(tài)庫和運行時代碼生成期間,NWC在大多數(shù)當前系統(tǒng)中已經(jīng)是正確的。
● NXD. 不可執(zhí)行數(shù)據(jù):程序必須不能像執(zhí)行代碼那樣執(zhí)行數(shù)據(jù)。否則,攻擊者可能會導(dǎo)致執(zhí)行標有預(yù)期ID的數(shù)據(jù)。最新的x86處理器上的硬件支持NXD,Windows XP SP2使用此支持來強制分離代碼和數(shù)據(jù)[Microsoft Corporation 2004]。NXD也可以用軟件實現(xiàn)[PaX Project 2004]。NXD本身(沒有CFI)阻止了一些攻擊,但不適于那些利用預(yù)先存在的代碼的攻擊,例如“jump-to-libc”攻擊。
2.1 Windows CFG的實現(xiàn)
Windows利用以上思想建立了自己的CFI防護機制CFG(Control Flow Guard)。在Win10安全特性之執(zhí)行流保護、繞過Windows Control Flow Guard思路分享等文章中有對CFG的實現(xiàn)原理進行過描述。
以win10 preview 9926中IE11的Spartan html解析模塊為例,看一下CFG的具體情況:
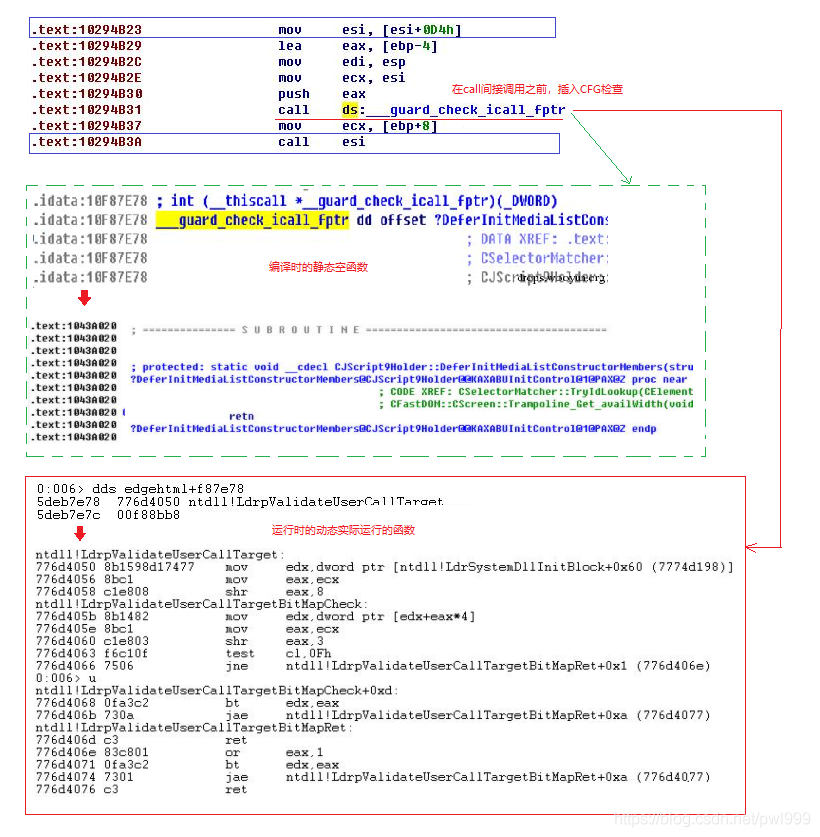
最終實際運行的CFG檢查函數(shù)為ntdll!LdrpValidateUserCallTarget(),其檢測過程如下:
1、首先從LdrSystemDllInitBlock+0x60處讀取一個位圖(bitmap),這個位圖表明了哪些函數(shù)地址是有效的。通過間接調(diào)用的函數(shù)地址的高3個字節(jié)作為一個索引,獲取該函數(shù)地址所在的位圖的一個DWORD值,一共32位,證明1位代表了8個字節(jié),但一般來說間接調(diào)用的函數(shù)地址都是0x10對齊的,因此一般奇數(shù)位是不使用的。
2、通過函數(shù)地址的高3個字節(jié)作為索引拿到了一個所在的位圖的DWORD值,然后檢查低1字節(jié)的0-3位是否為0,如果為0,證明函數(shù)是0x10對齊的,則用3-7bit共5個bit就作為這個DWORD值的索引,這樣通過一個函數(shù)地址就能找到位圖中所對應(yīng)的位了。如果置位了,表明函數(shù)地址有效,反之則會觸發(fā)異常。
對win CFG的防護思路沒有完全理解透徹,反正原理就是根據(jù)跳轉(zhuǎn)的目的地址去查bitmap表來確定是否合法。
03 CCFIR
在CFI被提出后過了很長時間都沒有被廣泛應(yīng)用到實際生產(chǎn)中去,主要原因還是插樁引起的開銷過大。因此在2013年又提出了CCFIR,在同一年提出的還有binCFI,ModularCFI等等,但CCFIR是非常典型的一個實現(xiàn)。
與上面我們所講的機制將目標集合按照指向邊的源集合是否相同來劃分不一樣,CCFIR更加簡潔的將目標集合劃分為了三類:
所有的間接call和jmp指令的目標被歸為一類,稱為函數(shù)指針;
ret指令的目標被歸為兩類,一類是敏感庫函數(shù)(比如libc中的額system函數(shù)),另一類是普通函數(shù)。
下面我們以下圖中的例子來說明CCFIR的工作原理:
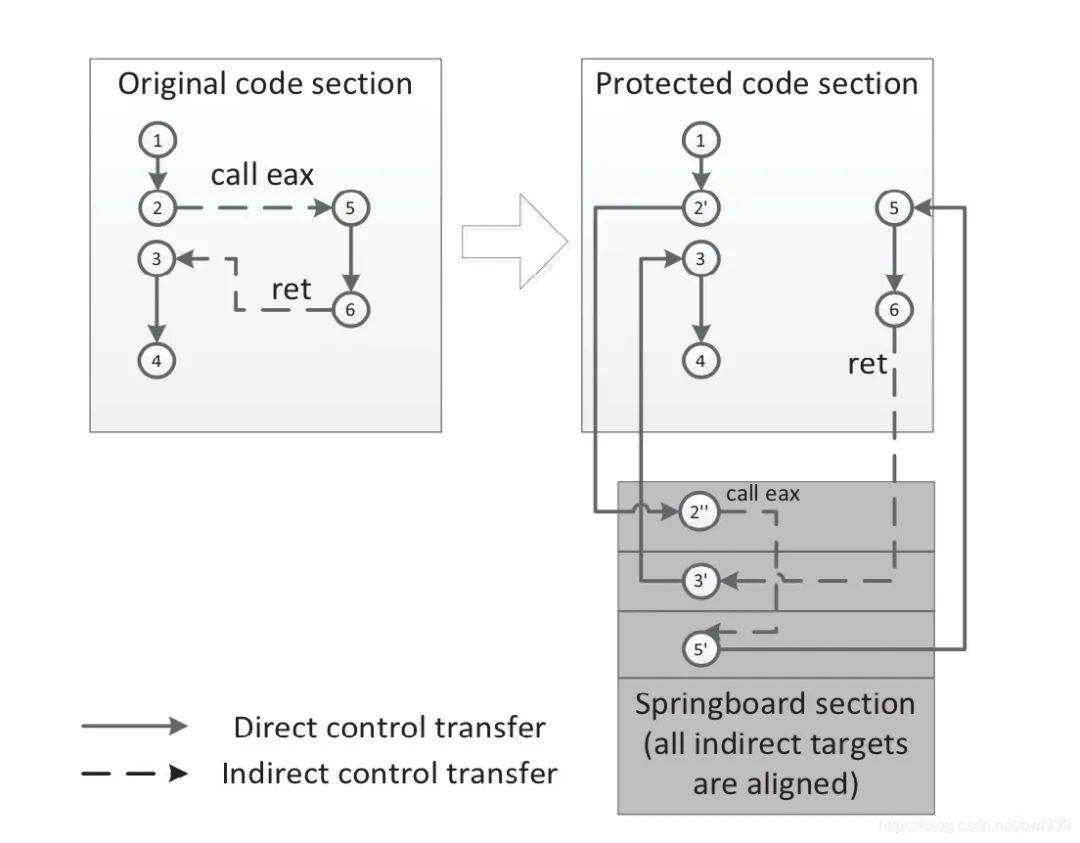
左邊是原始的控制流,右邊是CCFIR機制下的控制流。CCFIR提出了通過Springboard段(下方灰色部分)存放有效間接轉(zhuǎn)移目標的地址,在這段控制流中,5和3節(jié)點節(jié)點分別是call eax指令和ret指令這兩個間接轉(zhuǎn)移指令的目標地址,因此都會被存在Springboard段中。在程序執(zhí)行到節(jié)點2’時,會檢測接下來的跳轉(zhuǎn)地址是否在Springboard段中,是則跳轉(zhuǎn),否則出錯,從節(jié)點6跳轉(zhuǎn)到3也是一樣。
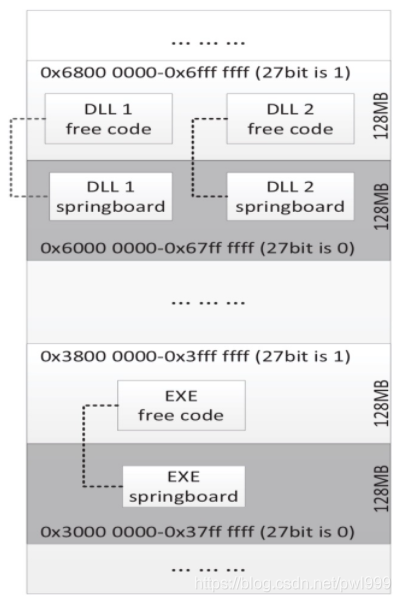
Springboard段的內(nèi)存布局如上圖所示,通過將某一位設(shè)置成0/1來區(qū)分普通段和Springboard段。這樣在跳轉(zhuǎn)檢測時檢查某一個目標是否在Springboard段,只要檢測某一位的值就可以了。
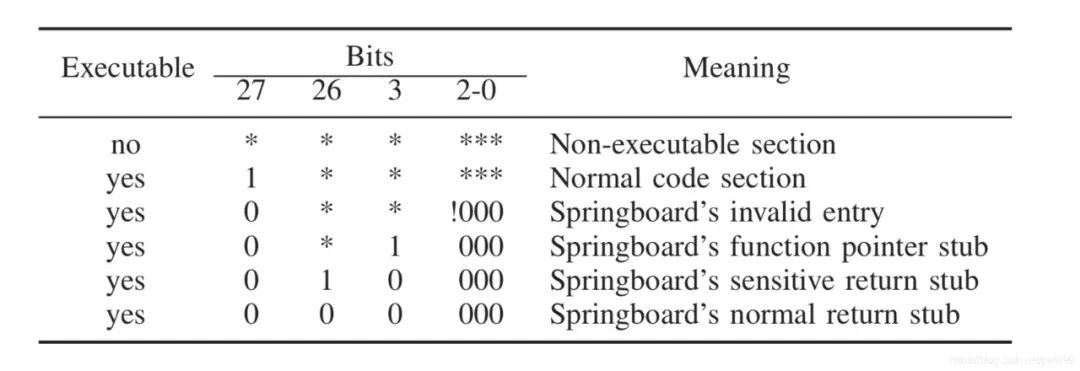
再進一步擴展,由于目標地址主要被分為三類,那么這三類又可以通過幾位的不同來區(qū)分,如下圖。第27bit為0則表示是Springboard段,第3位為1則屬于函數(shù)指針,為0屬于ret地址,并通過26位區(qū)分是敏感函數(shù)地址還是普通函數(shù)地址。
CCFIR的主要貢獻在于它降低了CFI機制的開銷,希望能將CFI投入實際使用中去。
04 VTV
2014年 Google 間接函數(shù)調(diào)用檢查(第6篇文章)。隨著對堆棧的保護越來越完善,出現(xiàn)了很多基于非堆棧的前向轉(zhuǎn)移攻擊,尤其是call指令。例如利用UAF漏洞覆蓋vtable指針等等。這篇文章的主要貢獻不是提出了什么新的機制,而是將CFI真正用到了生產(chǎn)編譯器中,僅針對于前向轉(zhuǎn)移。以下是主要工作:
Vtable Verification (VTV), in GCC 4.9,主要是對vtable調(diào)用進行檢測,VTV在每個調(diào)用點驗證用于虛擬調(diào)用的vtable指針的有效性。
Indirect Function Call Checker (IFCC), in LLVM。它通過為間接調(diào)用目標生成跳轉(zhuǎn)表并在間接調(diào)用點添加代碼來轉(zhuǎn)換函數(shù)指針來保護間接調(diào)用,從而確保它們指向跳轉(zhuǎn)表條目。任何未指向相應(yīng)表的函數(shù)指針都被視為CFI違規(guī)。- - Indirect Function Call Sanitizer (FSan), in LLVM是一個可選的間接調(diào)用檢查器。
LLVM Clang Control Flow Integrity Design Documentation一文詳細的描述了Forward-Edge CFI for Virtual Calls的實現(xiàn)原理。
05 Kernel CFI
Linux 內(nèi)核的代碼量比較少但是內(nèi)核權(quán)限更大,一旦被攻擊會更加致命,所以kernel也需要擁有自己CFI防護方案。
在Andriod上google投入了大量精力來防止代碼重用攻擊(ROP),主要的防護思路是通過基于編譯器的安全緩解措施:
● 代碼重用攻擊(ROP)利用內(nèi)核的常用方法是使用錯誤來覆蓋存儲在內(nèi)存中的函數(shù)指針,例如存儲了回調(diào)函數(shù)的指針,或已被推送到堆棧的返回地址。這允許攻擊者執(zhí)行任意內(nèi)核代碼來完成利用,即使他們不能注入自己的可執(zhí)行代碼。這種獲取代碼執(zhí)行能力的方法在內(nèi)核中特別受歡迎,因為它使用了大量的函數(shù)指針,以及使代碼注入更具挑戰(zhàn)性的現(xiàn)有內(nèi)存保護機制。
●CFI 嘗試通過添加額外的檢查來確認內(nèi)核控制流停留在預(yù)先設(shè)計的版圖中,以便緩解這類攻擊。盡管這無法阻止攻擊者利用一個已存在的 bug 獲取寫入權(quán)限,從而更改函數(shù)指針,但它會嚴格限制可被其有效調(diào)用的目標,這使得攻擊者在實踐中利用漏洞的過程變得更加困難。
Google 的 Pixel 3 將是第一款在內(nèi)核中實施 LLVM 前端控制流完整性(CFI)的設(shè)備,已經(jīng)實現(xiàn)了 Android 內(nèi)核版本 4.9 和 4.14 中對 CFI 的支持。
Android 內(nèi)核控制流完整性和CFI in Android Kernel Security介紹了Android下實現(xiàn)kernel CFI的大概情況。
Control Flow Integrity (CFI) in the Linux kernel和LLVM Clang Control Flow Integrity Design Documentation介紹了Kernel CFI的詳細實現(xiàn)原理。
5.1forward-edge protection
CFI(Control-Flow Integrity)
Kernel CFI 前向邊沿的防護。
1、將前向間接跳轉(zhuǎn)的目的地址搜集到一起組成一張表,在跳轉(zhuǎn)前判斷目的地址的合法性。因為合法的目的地址都是實際存在的函數(shù),所以表的大小是有限的。當然也不會把所有的目的函數(shù)都集中到一張表里,會根據(jù)函數(shù)的原型把原型相同的函數(shù)搜集到同一張表中。
函數(shù)原型一致:
1| int do_fast_path(unsigned long, struct file *file) 2| int do_slow_path(unsigned long, struct file *file)
函數(shù)原型不一致:
1| void foo(unsigned long) 2| int bar(unsigned long)
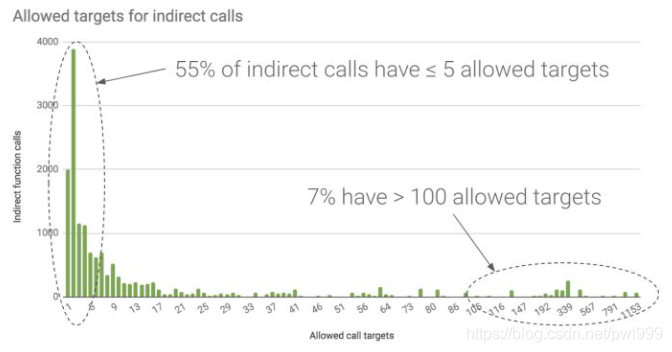
如上圖根據(jù)google的研究統(tǒng)計,使用原型法來分類函數(shù)。LLVM 的 CFI 將 55% 的間接調(diào)用限制為最多 5 個可能的目標,80% 限制為最多 20 個目標。
因為linux kernel有時并未嚴格遵守函數(shù)指針和函數(shù)原型絕對一致的約定,所以在開啟CFI特性時需要修復(fù)這類問題。
2、在鏈接時進行間接調(diào)用目的函數(shù)表的分類和創(chuàng)建,以及調(diào)用前的插樁。這要求連接器具有LTO功能。
llvm的CFI模塊會用LTO來決定所有valid call targets,必須使用llvm的整體的匯編器來進行inline匯編,必須使用LTO-aware的鏈接器,比如說 GNU gold linker或者是llvm的ld。
下圖為LLVM的LTO原理簡介:
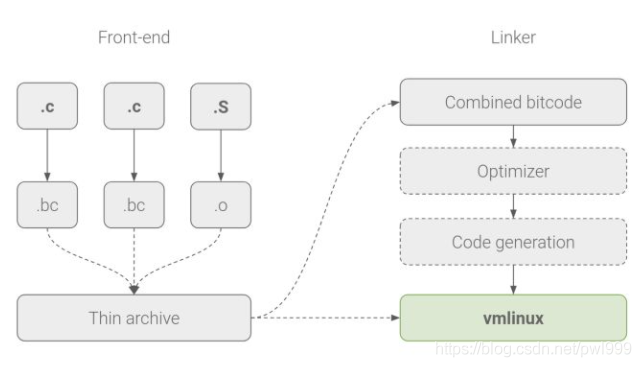
為了確定每個間接分支的所有有效調(diào)用目標,編譯器需要立即查看所有內(nèi)核代碼。傳統(tǒng)上,編譯器一次處理單個編譯單元(源代文件),并將目標文件合并到鏈接器。LLVM 的 CFI 要求使用 LTO,其編譯器為所有 C 編譯單元生成特定于 LLVM 的 bitcode,并且 LTO 感知鏈接器使用 LLVM 后端來組合 bitcode,并將其編譯為本機代碼。
幾十年來,Linux 一直使用 GNU 工具鏈來匯編,編譯和鏈接內(nèi)核。雖然我們繼續(xù)將 GNU 匯編程序用于獨立的匯編代碼,但 LTO 要求我們切換到 LLVM 的集成匯編程序以進行內(nèi)聯(lián)匯編,并將 GNU gold 或 LLVM 自己的 lld 作為鏈接器。在巨大的軟件項目上切換到未經(jīng)測試的工具鏈會導(dǎo)致兼容性問題,我們已經(jīng)在內(nèi)核版本 4.9 和 4.14 的 arm64 LTO 補丁集中解決了這些問題。
3、具體實例
實例的c語言代碼:(action()間接調(diào)用,可以調(diào)用do_simple()或者do_fancy())
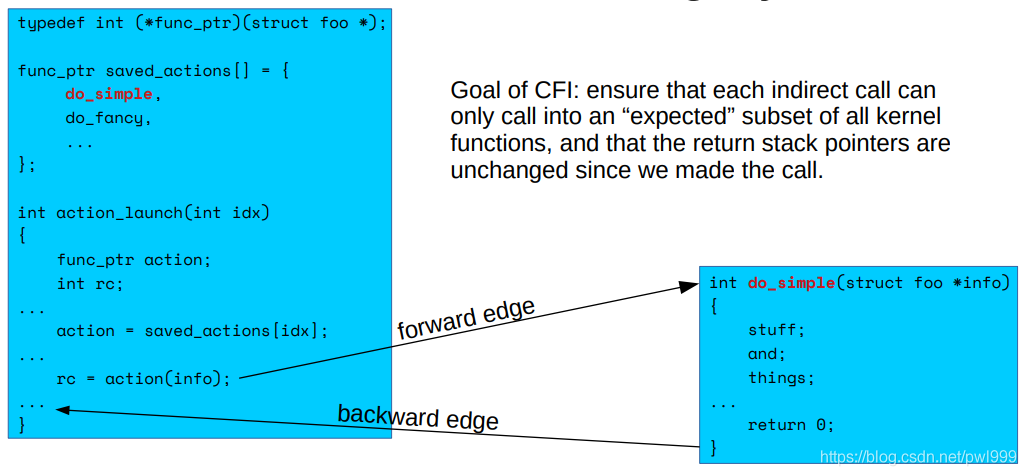
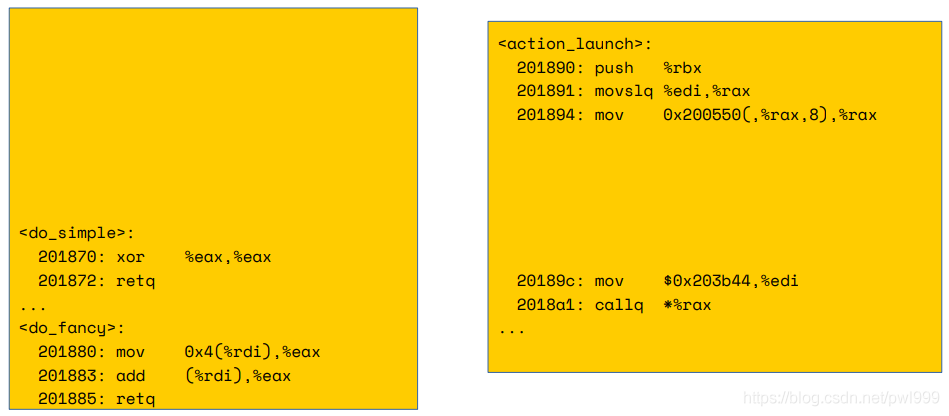
對應(yīng)的匯編代碼如下:
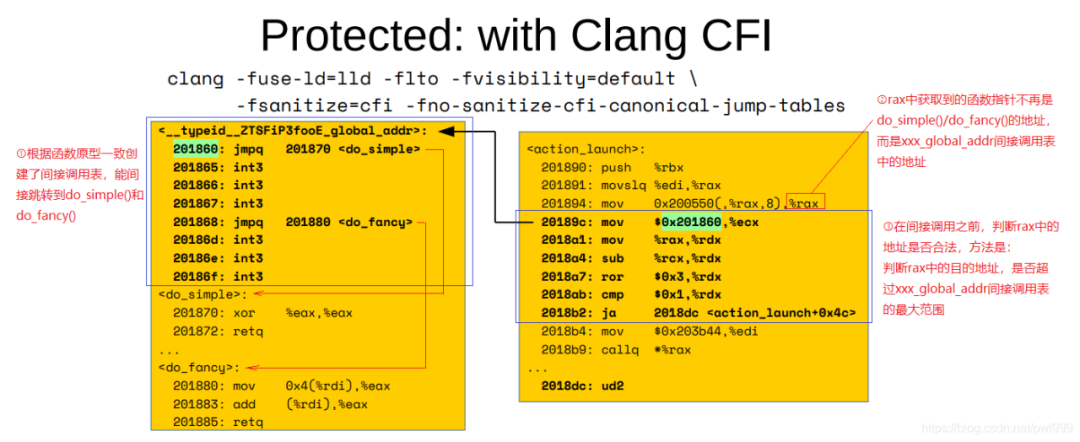
開啟cfi保護以后的匯編代碼:
5.2
backward-edgeprotectioSCS(Shadow Call Stack
5.2 backward-edge protectioSCS
(Shadow Call Stack)

Kernel CFI 后向邊沿,使用影子調(diào)用堆棧的方式來防護。
● 方式1:專用寄存器用于單獨的返回堆棧:“影子調(diào)用堆棧”
x86已經(jīng)不使用這種方式,因為它運行緩慢且存在競爭條件。arm64可以為所有影子堆棧操作保留寄存器(x18),陰影堆棧的位置需要保密。
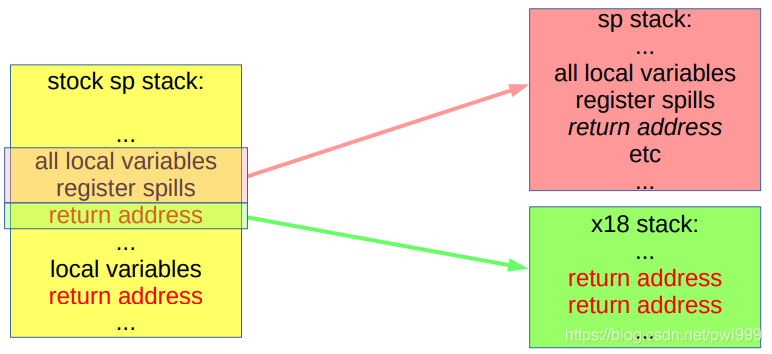
結(jié)果出現(xiàn)在兩個堆棧寄存器中:sp和未緩存的x18僅將來自影子堆棧(由x18指向)的返回地址(鏈接)寄存器的負載用于返回:
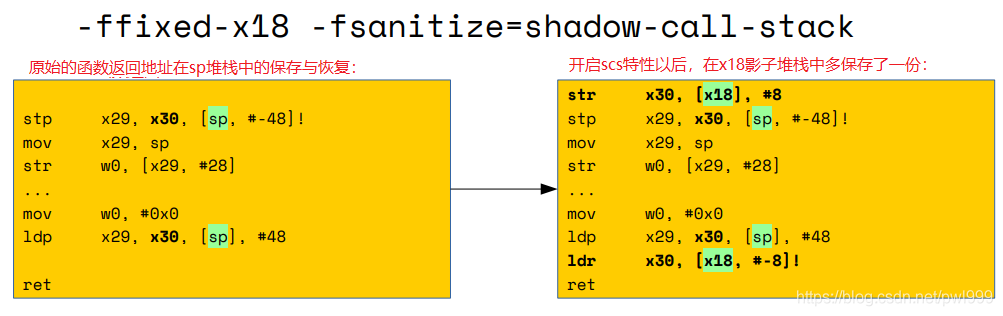
● 方式2:使用專屬硬件完成(x86: CET, arm64:Pointer Authentication)
Intel CET: 基于硬件的只讀影子調(diào)用堆棧。在調(diào)用和退出指令期間隱式使用否則為只讀的影子堆棧。
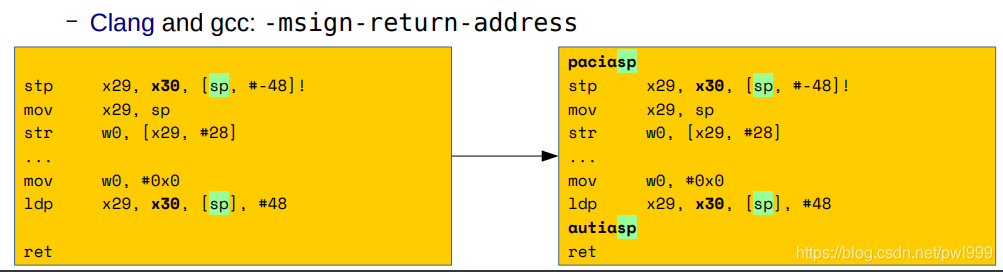
ARM v8.3a Pointer Authentication (“signed return address”)。新指令:paciasp 和 autiasp。Clang and gcc: -msign-return-address。
以下是使用arm PA實現(xiàn)的硬件影子堆棧:
5.3 Shared library support
(Cross—DSO)
因為內(nèi)核是全解析的,所有不會有間接調(diào)用外部模塊的情況。在用戶態(tài)的共享庫中還有間接調(diào)用還是穿越DSO模塊。LLVM Clang Control Flow Integrity Design Documentation一文中詳細描述了這些技術(shù)的實現(xiàn)。
06 利用硬件來提升CFI的效率
我們相信上述設(shè)計可以在硬件中有效地實現(xiàn)。添加到ISA的一條新指令將允許以每次檢查更少的字節(jié)(更小的代碼大小開銷)執(zhí)行前向CFI檢查(可能會更有效)。當前的純軟件檢測要求每個檢查至少32字節(jié)(在x86_64上)。硬件指令可能小于12個字節(jié)。這樣的指令將檢查參數(shù)指針是否入站且已正確對齊,并且如果檢查失敗,它將捕獲(在單片方案中)或調(diào)用慢路徑函數(shù)(跨DSO方案)。對于硬件實現(xiàn)而言,位矢量查找可能太復(fù)雜了。
注意,這種硬件擴展將補充被叫方的支票,例如。英特爾ENDBRANCH。而且,CFI將從ENDBRANCH具有兩個好處:a)精度和b)防止多態(tài)類型之間無效轉(zhuǎn)換的能力。
為了能夠在性能和防御方面取得更好的效果,一些研究著手于利用現(xiàn)有的硬件機制,來降低CFI的開銷。
Vasilis Pappas提出利用硬件性能計數(shù)器,在運行時觀察執(zhí)行流的思路,該方法被稱為kBouncer[10]。他們利用LBR(Last Branch Register)來捕獲最近的16次跳轉(zhuǎn)信息。具體做法是在敏感系統(tǒng)調(diào)用處,對捕獲的16次跳轉(zhuǎn)進行安全性判斷,即return指令需要跳轉(zhuǎn)到調(diào)用點的后繼位置,indirect-call指令的目標是函數(shù)入口,其余跳轉(zhuǎn)指令目標基本塊長度不能全部少于20條指令。為了避免攻擊者利用庫函數(shù)調(diào)用來完成攻擊,文章在所有的庫函數(shù)調(diào)用點,來進行上述合法性檢查。為了驗證kBouncer的防御效果,作者對IE瀏覽器、Adobe Flash Player和Adobe Reader進行了實驗(利用已知安全漏洞,組織ROP payload攻擊這三種應(yīng)用),實驗結(jié)果表明該方法能夠有效緩解ROP攻擊。同時,該方法的性能開銷低于~4%。
Yueqiang Chen等人設(shè)計了一種與kBouncer類似的方法,稱作ROPecker[11],也是利用LBR捕獲程序控制流的方式進行ROP攻擊監(jiān)測。但不同之處在于判斷是否遭受ROP攻擊的邏輯和觸發(fā)監(jiān)測的時機。1、判斷邏輯:在運行時檢測過去(利用LBR)和未來的執(zhí)行流(模擬執(zhí)行)中是否存在長gadget鏈(5個比較短的gadget),若存在,則認為這是一次ROP攻擊。Gadget信息是通過靜態(tài)分析二進制程序和共享庫得到的。2、運行時監(jiān)測是事件驅(qū)動的,具體時機是調(diào)用敏感系統(tǒng)調(diào)用和執(zhí)行流跳出滑動窗口觸發(fā)異常。ROPecker設(shè)計了一個滑動窗口,因為代碼本身具有時間和空間的局部性,但是gadget鏈卻是散列的,利用這一特性,系統(tǒng)保證該窗口內(nèi)的gadget數(shù)目不足以構(gòu)成一次ROP攻擊,窗口內(nèi)的代碼設(shè)置可執(zhí)行權(quán)限,窗口外的代碼不可執(zhí)行,當執(zhí)行流跳出滑動窗口時,便會觸發(fā)異常,進行運行時檢測。該方法利用代碼本身具有的時間和空間局部性,針對gadget鏈是散列的前提,提出了滑動窗口機制,使用事件驅(qū)動的檢測方法,具有較高的準確性和高效性。為了驗證該方法的安全性,ROPecker選取了有棧溢出的真實世界應(yīng)用(Linux Hex-editer)進行攻防演練。實驗結(jié)果證明,ROPecker能夠有效的阻止ROP攻擊。同時,SPEC CPU2006 benchmark顯示了該方法的開銷非常低(~2%)。
Yubin Xia等人設(shè)計的CFIMon[12],也是采用性能計數(shù)器來捕獲程序執(zhí)行流,并進行合法性判斷。但他們采用的是BTB(Branch Trace Buffer),來捕獲受保護程序運行過程中所有跳轉(zhuǎn)指令的信息。BTB與LBR不同之處在于,BTB可以把程序整個執(zhí)行過程中所有的跳轉(zhuǎn)指令的歷史信息都記錄下來,LBR只能記錄16條。但是BTB需要CPU向指定的一個緩沖區(qū)內(nèi)寫入跳轉(zhuǎn)信息,當緩沖區(qū)滿時,CPU會觸發(fā)異常交給操作系統(tǒng)處理(將緩沖區(qū)內(nèi)容寫入文件中),LBR是循環(huán)的寄存器。使用BTB的程序性能明顯比LBR性能低。CFIMon檢查BTB的時機在兩個階段:一是當緩沖區(qū)滿時,操作系統(tǒng)將所有歷史信息寫入另一個進程,由另一個進程進行合法性判斷;二是當受保護進程執(zhí)行敏感系統(tǒng)調(diào)用時,另一個進程也進行歷史信息的合法性判斷。合法性判斷主要檢查間接控制轉(zhuǎn)移的跳轉(zhuǎn)目標是合法目標集合內(nèi)。如果所有間接控制轉(zhuǎn)移的歷史跳轉(zhuǎn)目標在合法目標集合中,認為當前受保護進程沒有收到攻擊;如果有至少一個間接控制轉(zhuǎn)移的歷史跳轉(zhuǎn)目標在合法目標集合中,那么認為受保護進程受到攻擊。合法目標的集合是在線下通過靜態(tài)分析獲得的,并且存儲在檢查進程中。
原文標題:CFI/CFG 安全防護原理詳解
文章出處:【微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
寄存器
+關(guān)注
關(guān)注
31文章
5357瀏覽量
120632 -
代碼
+關(guān)注
關(guān)注
30文章
4801瀏覽量
68735 -
數(shù)據(jù)流
+關(guān)注
關(guān)注
0文章
120瀏覽量
14371
原文標題:CFI/CFG 安全防護原理詳解
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
智能天線的基本概念
微波基本概念
電波的基本概念





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論