


1、compile():
-
編譯正則表達式模式,返回一個
正則對象的模式。(可以把那些常用的正則表達式編譯成正則表達式對象,這樣可以提高一點效率。) -
格式:
re.compile(pattern[,flags=0])-
pattern: 編譯時用的表達式字符串。 -
flags: 編譯標志位,用于修改正則表達式的匹配方式,如:re.I(不區分大小寫)、re.S等
-
import re
tt = "Tina is a good girl, she is cool, clever, and so on..."
rr = re.compile(r'\w*oo\w*')
print(rr.findall(tt)) #查找所有包含'oo'的單詞
# 執行結果如下:
# ['good', 'cool']2、match()
- 決定RE是否在字符串剛開始的位置匹配。
- //注:這個方法并不是完全匹配。當pattern結束時若string還有剩余字符,仍然視為成功。
-
格式:
re.match(pattern, string[, flags=0])
print(re.match('com','comwww.csdn').group())
print(re.match('com','Comwww.csdn',re.I).group())
#執行結果如下:
#com
#com3、search()
-
格式:
re.search(pattern, string[, flags=0]) - re.search函數會在字符串內查找模式匹配,只要找到第一個匹配然后返回,如果字符串沒有匹配,則返回None。
print(re.search('\dcom','www.4comcsdn.5com').group())
執行結果如下:
# 4com-
注:match和search一旦匹配成功,就是一個match object對象,而match object對象有以下方法:
- group() 返回被 RE 匹配的字符串
- start() 返回匹配開始的位置
- end() 返回匹配結束的位置
- span() 返回一個元組包含匹配 (開始,結束) 的位置
import re
a = "123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) #123abc456,返回整體
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
###group(1) 列出第一個括號匹配部分,group(2) 列出第二個括號匹配部分,group(3) 列出第三個括號匹配部分。###4、findall()
- re.findall遍歷匹配,可以獲取字符串中所有匹配的字符串,返回一個列表。
-
格式:
re.findall(pattern, string[, flags=0])
p = re.compile(r'\d+')
print(p.findall('o1n2m3k4'))
執行結果如下:
['1', '2', '3', '4']
import re
tt = "Tina is a good girl, she is cool, clever, and so on..."
rr = re.compile(r'\w*oo\w*')
print(rr.findall(tt))
print(re.findall(r'(\w)*oo(\w)',tt))#()表示子表達式
執行結果如下:
['good', 'cool']
[('g', 'd'), ('c', 'l')]5、split()
- 按照能夠匹配的子串將string分割后返回列表。
- 可以使用re.split來分割字符串,如:re.split(r'\s+', text);將字符串按空格分割成一個單詞列表。
-
格式:
re.split(pattern, string[, maxsplit])-
maxsplit: 用于指定最大分割次數,不指定將全部分割。
-
print(re.split('\d+','one1two2three3four4five5'))
# 執行結果如下:
# ['one', 'two', 'three', 'four', 'five', '']6、sub()
- 使用re替換string中每一個匹配的子串后返回替換后的字符串。
-
格式:
re.sub(pattern, repl, string, count)
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
print(re.sub(r'\s+', '-', text))
執行結果如下:
JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on...
其中第二個函數是替換后的字符串;本例中為'-'
第四個參數指替換個數。默認為0,表示每個匹配項都替換。- re.sub還允許使用函數對匹配項的替換進行復雜的處理。
- 如:re.sub(r'\s', lambda m: '[' + m.group(0) + ']', text, 0);將字符串中的空格' '替換為'[ ]'。
import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
print(re.sub(r'\s+', lambda m:'['+m.group(0)+']', text,0))
執行結果如下:
JGood[ ]is[ ]a[ ]handsome[ ]boy,[ ]he[ ]is[ ]cool,[ ]clever,[ ]and[ ]so[ ]on...
審核編輯:湯梓紅
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
格式
+關注
關注
0文章
23瀏覽量
17076 -
字符串
+關注
關注
1文章
590瀏覽量
22423 -
python
+關注
關注
56文章
4829瀏覽量
87109
發布評論請先 登錄
相關推薦
熱點推薦
labview如何使用VISA串口資源查找的正則表達式提取串口的資源名稱?
如圖,如何利用VISA資源查找的正則表達式從很多串口當中提取想要的目標串口(Quectel USB AT Port這個串口)?
發表于 07-07 17:20
基礎篇3:掌握Python中的條件語句與循環
不同的條件執行不同的代碼塊。Python中的條件語句主要使用if、elif(else if的縮寫)和else關鍵字。
if語句
最簡單的條件語句是if語句,它的工作方式如下:
復制代碼
if 條件表達式
發表于 07-03 16:13
干貨分享 | 零基礎上手!TSMaster圖形信號表達式實操指南
TSMaster軟件支持在圖形里面的信號表達式功能,主要用于多信號表達式運算和顯示的場景。本文將以A2L中的標定變量為例,介紹如何使用圖形中的信號表

Cubeide1.18.1在線調試改變\"現場表達式\"中的值提示找不到地址怎么解決?
Cubeide1.18.1在線調試時,在\"現場表達式\"中添加全局變量,然后改變其數值,Console窗口提示:
Failed to read all registers
發表于 04-27 06:18
Linux中文本處理命令的用法
Linux 三劍客是(grep,sed,awk)三者的簡稱,熟練使用這三個工具可以提升運維效率。Linux 三劍客以正則表達式作為基礎,而在Linux系統中,支持兩種正則表達式,分別為“標準正
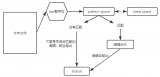
Linux grep命令詳解
Linux grep命令是一種非常常用的文本搜索工具,它可以在給定的文件中搜索匹配的字符串,并輸出匹配的行。grep是全稱“global search regular expression print”,可以識別正則表達式,并使
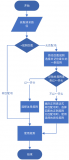
Verilog表達式的位寬確定規則
很多時候,Verilog中表達式的位寬都是被隱式確定的,即使你自己設計了位寬,它也是根據規則先確定位寬后,再擴展到你的設計位寬,這常常會導致結果產生意想不到的錯誤。
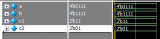
通過工業智能網關實現中間變量表達式的快速配置
,出現告警可能是多個變量達到條件而觸發的,就需要對中間變量進行配置。 對此,物通博聯提供基于工業智能網關實現中間變量表達式的快速配置操作。用戶可以根據生產現場的應用需求,靈活配置中間變量表達式,實現多參數、多條件
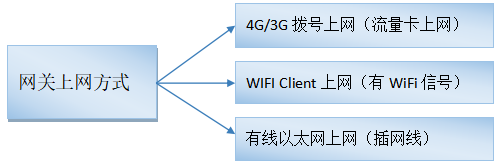
nginx中的正則表達式和location路徑匹配指南
前言,我這里驗證的nginx-v1.23.2單機環境下的nginx中的正則表達式、location路徑匹配規則和優先級。
TestStand表達式中常用的語法規則和運算符使用
TestStand也有自己的語言嘛?在回答這個問題之前大家可以想一下在使用TestStand時有一個和語言密切相關的屬性。沒錯那就是表達式(Expressions),在這篇文章中,小編將以Q&A的方式來帶著大家來理解并熟悉TestStand

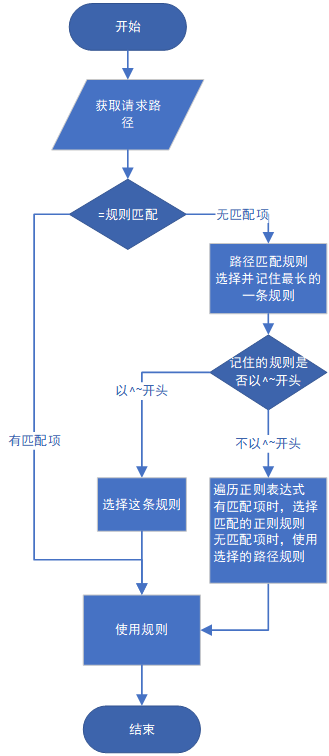
Java表達式引擎選型調研分析
1 簡介 我們項目組主要負責面向企業客戶的業務系統, 企業的需求往往是多樣化且復雜的,對接不同企業時會有不同的定制化的業務模型和流程。 我們在業務系統中 使用表達式引擎,集中配置管理業務規則,并實現
鴻蒙原生應用元服務開發-倉頡基本概念表達式(二)
。for-in 表達式的基本形式為:
for (迭代變量 in 序列) {
循環體
}
其中“循環體”是一個代碼塊。“迭代變量”是單個標識符或由多個標識符構成的元組,用于綁定每輪遍歷中由迭代器指向的數據,可以
發表于 08-09 14:26
鴻蒙原生應用元服務開發-倉頡基本概念表達式(一)
實參等。此外,因為倉頡是強類型的編程語言,所以倉頡表達式不僅可求值,還有確定的類型。
倉頡編程語言的各種表達式將在后續章節中逐一介紹,本節介紹最常用的條件
發表于 08-08 10:27





 工商網監
工商網監

評論