 ostgreSQL中的查詢:查詢執行階段
ostgreSQL中的查詢:查詢執行階段
ostgreSQL中的查詢:1.查詢執行階段
開始關于PG內部執行機制的文章系列。這一篇側重于查詢計劃和執行機制。
本系列包括:
1、查詢執行階段(本文)
2、統計數據
3、順序掃描
4、索引掃描
5、嵌套循環連接
6、哈希連接
7、Merge join
本系列針對PG14編寫。
簡單查詢協議
PG客戶端-服務協議的基本目的是雙重的:將SQL查詢發送到服務,接收整個執行結果作為響應。服務接收到查詢去執行要經過幾個階段。
解析
首先,需要解析查詢文本,這樣服務才能準確了解需要執行什么。
詞法分析器和解析器。詞法解析器負責識別查詢字符串中的詞位(如SQL關鍵字、字符串、數字文字等),而解析器確保生成的詞位集在語法上是有效的。解析器和詞法解析器使用標準工具Bison和Flex實現。解析的查詢表示位抽象的語法樹。例如:

在這里,將在后臺內存中構建一棵樹。下面以高度簡化的形式表示該樹。樹中節點用查詢的相應部分標記:
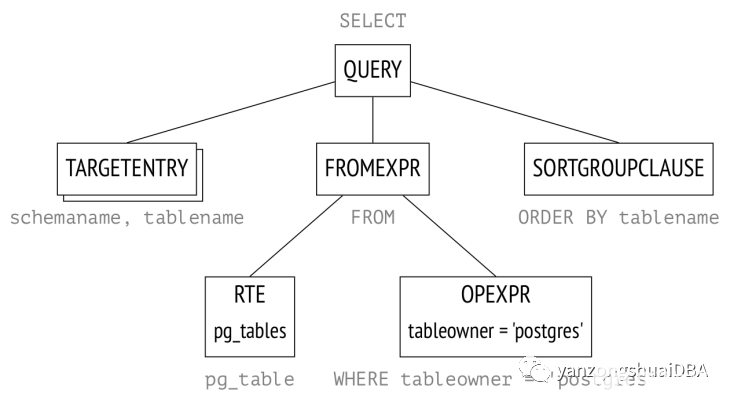
RTE是一個晦澀的縮寫,表示“范圍表條目”。PG源碼中“range table”指***查詢、連接結果--也就是說SQL語句操作的任何記錄集。
語法分析器。語法分析器確定數據庫中是否存在查詢中引用的表和其他對象,用戶是否有訪問這些對象的權限。語法分析需要的所有信息都在系統catalog中。
語法分析接收分析器傳來的解析樹并重新構建它,并用引用的特定數據庫對象、數據類型信息等來補充它。如果開啟debug_right_parse,則會在服務消息日志中顯示完整的樹信息,盡管這沒什么實際意義。
轉換
下一步,對查詢進行重寫。
系統內核將重寫用于多種目的。其中之一是將解析樹中的視圖名替換為該視圖查詢相對應的子樹。pg_tables是上面例子的一個視圖,重寫后的解析樹將采用以下形式:
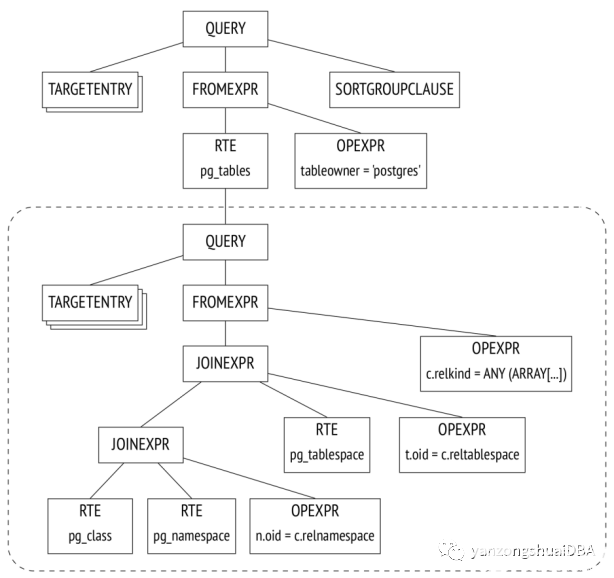
解析樹對應的查詢(經所有操作僅在樹上執行,而不是在查詢文本上執行):

解析樹反映查詢的語法結構,而不是執行操作的順序。行級安全性在轉換階段實施。
系統核心使用重寫的另一個例子是版本14中遞歸查詢的SEARCH和CYCLE子句中實現。
PG支持自定義轉換,用戶可以使用重寫規則系統來實現。規則系統作為PG主要功能之一。這些規則得到了項目基礎的支持,并在早期開發過程中反復重新設計。這是一個強大的機制,但難以理解和調試。甚至有人提議將規則從PG中完全刪除,但沒有得到普遍支持。在大多數情況下,使用觸發器而不是規則更安全、更方便。
如果debug_print_rewritten開啟,則完整重寫的解析樹會顯示在服務消息日志中。
計劃
SQL是一種聲明性語言:查詢指定要檢索什么,但不指定如何檢索它。任何查詢都可以通過多種方式執行。解析樹中的每個操作都有多個執行選項。例如,您可以通過讀取整個表并丟棄不需要的行來從表中檢索特定記錄,或者可以使用索引來查詢與您查詢匹配的行。數據集總是成對連接。連接順序的變化會產生大量執行選項。然后有許多方法可以將2組行連接在一起。例如,您可以逐個遍歷第一個集合中的行,并在另一個集合中查找匹配的行,或者您可以先對2個集合進行排序,然后將他們合并在一起。不同方法在某些情況下表現更好,在另一些情況下表現更差。
最佳計劃的執行速度可能比非最佳計劃快幾個數量級,這就是為什么優化解析查詢的執行計劃器是系統最復雜的元素之一。
計劃樹。執行計劃也可以表示為樹,但其節點是對數據的物理操作而不是邏輯操作。
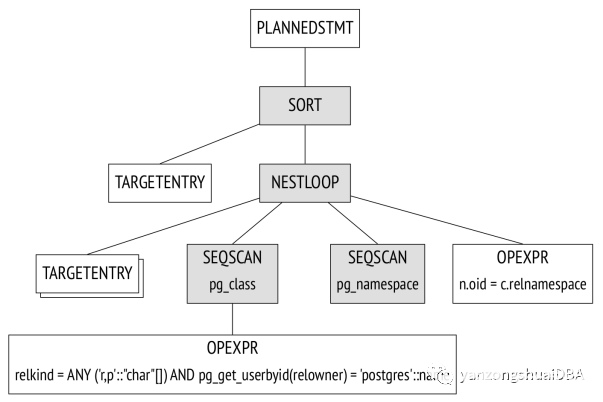
開啟debug_print_plan,則整個執行計劃樹會顯示在服務消息日志中。這是非常不切實際的,因為日志非常混亂。更方便的選擇是使用EXPLAIN命令:
EXPLAIN
SELECT schemaname, tablename
FROM pg_tables
WHERE tableowner = 'postgres'
ORDER BY tablename;
QUERY PLAN?????????????????????????????????????????????????????????????????????
Sort (cost=21.03..21.04 rows=1 width=128)
Sort Key: c.relname
?> Nested Loop Left Join (cost=0.00..21.02 rows=1 width=128)
Join Filter: (n.oid = c.relnamespace)
?> Seq Scan on pg_class c (cost=0.00..19.93 rows=1 width=72)
Filter: ((relkind = ANY ('{r,p}'::"char"[])) AND (pg_g...
?> Seq Scan on pg_namespace n (cost=0.00..1.04 rows=4 wid...
(7 rows)
該圖顯示了樹的主要節點。相同的節點在EXPLAIN輸出中使用箭頭標記。Seq Scan節點表示讀取表操作,而Nested Loop節點表示表連接操作。這里有2個優趣的點需要注意:
1) 其中一個初始化表從執行計劃樹中消失了,因為執行計劃器指出查詢處理中不需要它
2) 估算要處理的行數和每個節點處理的代價
計劃查詢。為找到最佳計劃,PG使用基于成本的查詢優化器。優化器會檢查各種可用的執行計劃并估算需要的資源量,例如IO周期和CPU周期。這個計算出的估算值轉換成任意單位,被稱為計劃成本。選擇結果成本最低的計劃來執行。
問題是,可能的計劃數量隨著連接數量的增加而呈指數增長,即使對于相對簡單的查詢,也無法一一篩選所有計劃。因此,使用動態規劃和啟發式限制搜索范圍。這允許在合理的時間內精確第解決查詢中更多表的問題,但不能保證所選的計劃是真正最優的。因為計劃其使用簡化的數學模型并可能使用不精確的初始化數據。
Ordering joins:可以以特定方式構建查詢,以顯著縮小搜索范圍(有可能錯過找到最佳計劃的機會):
1) 公共表表達式通常與主查詢分開優化。從12開始可以使用MATERIALIZE子句來強制執行此操作。
2) 來自非SQL函數的查詢和主查詢分開優化。(在某些情況下,SQL函數可以內聯到主查詢中)
3) join_collapse_limit參數與現式join子句以及from_collapse_limit參數與子查詢一起可以定義某些連接順序,具體取決于查詢語法。
最后一個可能需要解釋,下面的查詢調用FROM子句中的幾個表,沒有顯式連接:
SELECT ...FROM a, b, c, d, eWHERE ...
下面是此查詢的解析樹:
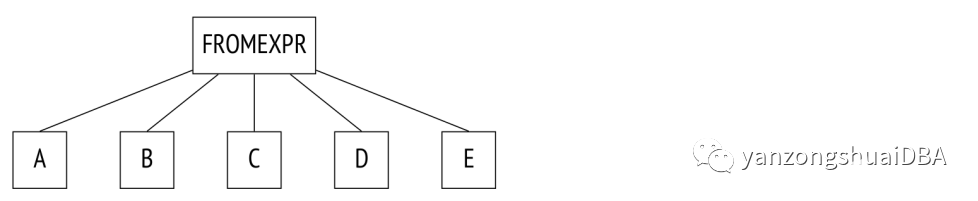
在這個查詢中,規劃器將考慮所有可能的連接順序。在下一個示例中,一些連接由JOIN子句顯式定義:
SELECT ...FROM a, b JOIN c ON ..., d, eWHERE ...
解析樹反映了這一點:
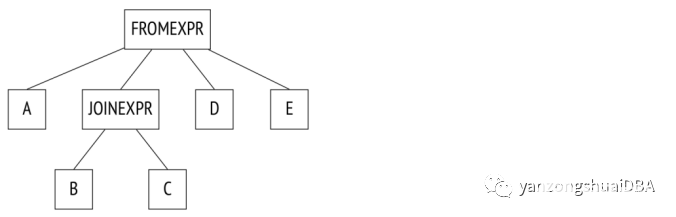
規劃器折疊連接樹,有效地將其轉換為上一個示例中的樹。該算法遞歸地遍歷樹并用其組件的平面列表替換每個JOINEXPR節點。
但是只有在生成的屏幕列表包含不超過join_collapse_limit個元素(默認8個)時,才會發生這種“扁平化”。在上面示例中,如果將join_collapse_limit設置5或更少,則不會折疊JOINEXPR節點。對于規劃器來說,這意味著兩件事:表B必須連接到表C(反之亦然,join對中的join 順序不受限制);表A、D、E以及B到C的連接可以按任意順序連接。
如果join_collapse_limit設置為1,則將保留任何顯式JOIN順序。注意,無論該參數如何,操作FULL OUTER JOIN都不會折疊。
參數from_collapse_limit(默認也是8)以類似的方式限制子查詢的展平。子查詢似乎與連接沒有太多共同之處,但當它歸結為解析樹級別時,相似性顯而易見。
例子:
SELECT ...FROM a, b JOIN c ON ..., d, eWHERE ...
下面是對應樹:
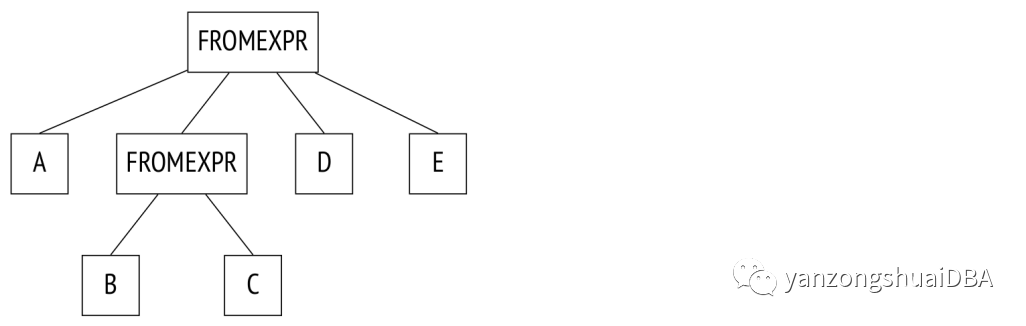
這里唯一的區別是JOINEXPR節點被替換成FROMEXPR(因此參數名稱為FROM)。
遺傳搜索:每當生成的扁平樹以太多相同級別的節點(表或連接結果)結束時,規劃時間可能會飆升,因為每個節點都需要單獨優化。如果geqo參數開啟,當同級節點數量達到geqo_threshold(默認12)時,PG將切換到遺傳搜索。遺傳搜索比動態規劃的方法快得多。但并不能保證找到最佳計劃。該算法有許多可調整的選項,這時另一篇文章主題。
選擇最佳計劃:最佳計劃的定義因預期用途而異。當需要完整的輸出時,計劃必須優化與查詢匹配的所有行的檢索。另一方面,如果只想要前幾個匹配的行,則最佳計劃可能會完全不同。PG通過計算2個成本組件來解決這個問題。他們顯示在“成本”一詞之后的查詢計劃輸出中:
Sort (cost=21.03..21.04 rows=1 width=128)
第一個組成部分:啟動成本,是為節點執行做準備的成本;第2個組成部分,總成本:代表總節點執行成本。
選擇計劃時,計劃器首先要檢查是否使用cursor(可以通過DECLARE命令設置cursor或者在PL/pgSQL中明確聲明)。如果沒有,計劃器假設需要全部輸出并選擇總成本最低的計劃。否則,如果使用cursor,則規劃器會選擇一個規劃,以最佳方式檢索匹配行總數中等于cursor_tuple_fraction(默認0.1)的行數。或者具體地說最低的計劃:startup cost + cursor_tuple_fraction*(total cost- startup cost)。
成本計算過程。要估計計劃的成本,必須單獨估計其每個節點。節點成本取決于節點類型(從表中讀取的成本遠低于對表排序的成本)和處理的數據量(通常,數據越多,成本越高)。雖然節點類型是立即知道的,但要評估數據量,我們首先需要估計節點的基數(輸入行的數量)和選擇性(剩余用于輸出的行的比例)。為此,我們需要數據統計:表大小、跨列的數據分布。
因此優化依賴于準確的統計數據,這些數據由自動分析過程受繼并保持最新。
如果每個計劃節點的基數估計準確,計算出的總成本通常會與實際成本相匹配。場景的計劃偏差通常是基數和選擇性估計不準確的結果。這些錯誤是由不準確、過時或不可用的統計數據引起的,并在較小程度上是規劃期所基于的固有模型不完善。
基數估計。基數估計是遞歸執行的。節點基數使用2個值計算:節點的字節的的基數,或輸入行數;節點的選擇性,或輸出行于輸入行的比例。基數是這2個值的成績。選擇性是一個介于0和1之間的數字。接近于零的選擇性值稱為高選擇性,接近1的值稱為低選擇性。這是因為高選擇性會消除較高比例的行,而較低的選擇性值會降低閾值,因此丟棄的行數回更少。首先處理具有數據訪問方法的葉節點。這就是表大小等統計信息的來源。應用于表的條件的選擇性取決于條件類型。在最簡單的形式中,選擇性可以是一個常數值,但計劃著回嘗試使用所有可用信息來產生最準確的估計。最簡單條件的選擇性估計作為基礎,使用不二運算構建的復雜條件可以使用以下簡單公式進一步計算:
selx and y = selx sely
selx or y = 1-(1-selx )(1-sely )=selx + sely - selx sely
在這些公式中,x和y認為是獨立的。如果他們相關,則使用這些公式,會使估計不太準確。對于連接的基數估計,計算2個值:笛卡爾積的基數(2個數據集的基數的乘積)和連接條件的選擇性,這又取決于條件類型。其他節點類型的基數,例如排序或聚合節點也是類似計算的。
請注意,較低節點中的基數計算錯誤將向上傳播,導致成本估算不準確,并最終導致次優計劃。計劃器只有表的統計數據,而不是連接結果的統計數據,這使情況變得更糟。
代價估算。代價估算過程也是遞歸的。子樹的成本包括其子節點的成本加上父節點的成本。節點成本計算基于其執行操作的數學模型。已經計算的基數用于輸入。該過程計算啟動成本和總成本。有些操作不需要任何準備,可以立即開始執行。對于這些操作,啟動成本是0.其他操作可能有先決標記。例如排序節點通常需要來自其子節點的所有數據才能開始操作。這些節點的啟動成本不為0。即使下一個節點(或客戶端)只需要單行輸出,也必須計算此成本。
成本是計劃者的最佳估計。任何計劃錯誤都會影響成本與實際執行的相關程度。成本評估的注意目的是讓計劃者在相同條件下比較相同查詢的不同執行計劃。在任何其他情況下,按成本比較查詢(更糟糕的是,不同的查詢)是沒有意義和錯誤的。例如,考慮由于統計數據不準確而被低估的成本。更新統計數據--成本可能會發生變化,但估算會變得更加準確,計劃最終會得到改進。
執行
按照計劃執行優化后的查詢。在后端內存中創建一個portal對象。Portal存儲著執行查詢需要的狀態。這個狀態以樹的形式表示,其結構與計劃樹相同。樹的節點作為裝配線,相互請求和傳遞行記錄:

從root節點開始執行。Root節點(例子中的SORT節點)向2個字節的請求數據。當它接收到所有請求的數據時會執行排序操作,然后將數據向上傳遞給客戶端。
一些節點(例如NESTLOOP節點)連接來自不同來源的數據。該節點向2個字節的請求數據。在接收到與連接條件匹配的行后,節點立即將結果行傳遞給父節點(和排序不同,排序必須在處理他們之前接收所有行),然后該節點停止,知道其父節點請求另一行。因此,如果只需要部分結果(例如LIMIT設置),則操作不會完全執行。
2個SEQSCAN葉節點是表掃描。根據父節點的請求,葉節點從表中讀取下一行并將其返回。這個節點和其他一些節點根本不存儲行,而只是交付并立即忘記他們。其他節點例如排序,可能需要一次存儲大量數據。為解決這個問題,在后端內存分配了一個work_mem內存塊,默認是保守的4MB限制;當內存用完時,多余的數據會被發送到磁盤上的臨時文件中。
一個計劃可能包含多個具有存儲要求的節點,因此他可能分配了幾塊內存,每個塊大小為work_mem。查詢進程可能占用的總內存大小沒有限制。
擴展查詢協議
使用簡單的查詢協議,任何命令即使它一次又一次重復也會經歷上述所有階段:解析、重寫、規劃、執行。但是沒有理由一遍又一遍地解析同一個查詢。如果他們盡在常量上有所不同,也沒有理由重新解析查詢:解析樹將是相同的。簡單查詢協議的另一個煩惱是客戶端接收完整的輸出,而不管它可能有多長。
這2個問題都可以通過使用SQL命令來解決:為第一個問題準備一個查詢并執行它,為第二個問題聲明一個游標并獲取所需行。但隨后客戶端將不得不處理命名新對象,而服務器將需要解析額外的命令。
擴展查詢協議可以在協議命令級別對單獨的執行階段進行精確控制。
準備
在準備期間,查詢會像往常一樣被解析和重寫,但解析樹存儲在后端內存中。PG沒有用于解析查詢的全局緩存。即使一個進程之前已經解析過查詢,其他進程也必須再次解析它。然而,這中設計也有好處。在高負載下,全局內存緩沖很容易因為鎖稱為瓶頸。一個客戶端發送多個小命令可能會影響整個實例的性能。在PG中,查詢解析很便宜并與其他進程隔離。
可以使用附加參數準備查詢。下面是一個使用SQL命令的例子(同樣,這并不等同于協議命令級別的準備,但最終的效果是一樣的):
PREPARE plane(text) ASSELECT * FROM aircrafts WHERE aircraft_code = $1;
本文的案例都使用demo數據庫“Airlines”。此視圖顯示所有命名的預準備語句:
SELECT name, statement, parameter_types
FROM pg_prepared_statements gx
?[ RECORD 1 ]???+??????????????????????????????????????????????????
name | plane
statement | PREPARE plane(text) AS +
| SELECT * FROM aircrafts WHERE aircraft_code = $1;
parameter_types | {text}
該視圖沒有列出任何未命名的語句(使用擴展協議或PL/pgSQL)。但它也沒有列出來其他會話的準備好的語句:訪問另一個會話的內存是不可能的。
參數綁定
在執行準備好的查詢之前,會綁定當前參數值。
EXECUTE plane('733');
aircraft_code | model | range
???????????????+???????????????+???????
733 | Boeing 737?300 | 4200(1 row)
與文字表達式的串聯相比,準備好的語句的一個優點是可以防止任何類型的SQL注入。因為參數值不會影響已經構建的解析樹。在沒有準備好的聲明的情況下達到相同的安全級別,將需要對來自不受信任來源的所有值進行廣泛轉義。
規劃和執行
執行準備好的語句時,首先會考慮提供的參數來計劃其查詢,然后發送選擇的計劃以執行。實際參數值對規劃者很重要,因為不同參數集的最有規劃也可能不同。例如,在查找高級航班預訂時,使用索引掃描(例如Index Scan字樣所示),因為計劃者預計匹配的行不多:
CREATE INDEX ON bookings(total_amount);
EXPLAIN SELECT * FROM bookings WHERE total_amount > 1000000;
QUERY PLAN?????????????????????????????????????????????????????????????????????
Bitmap Heap Scan on bookings (cost=86.38..9227.74 rows=4380 wid...
Recheck Cond: (total_amount > '1000000'::numeric)
?> Bitmap Index Scan on bookings_total_amount_idx (cost=0.00....
Index Cond: (total_amount > '1000000'::numeric)
(4 rows)
然而,下一個條件完全符合所有預訂。索引掃描在這里沒用,進行順序掃描Seq Scan:
EXPLAIN SELECT * FROM bookings WHERE total_amount > 100;
QUERY PLAN???????????????????????????????????????????????????????????????????
Seq Scan on bookings (cost=0.00..39835.88 rows=2111110 width=21)
Filter: (total_amount > '100'::numeric)
(2 rows)
在某些情況下,除了解析樹外,規劃器還會存儲查詢計劃,以避免再出現時再次規劃它。整個沒有參數值的計劃稱為通用計劃,而不是使用給定參數值生成的自定義計劃。通用計劃的一個明顯用例是沒有參數的語句。
對于前4此運行,帶有參數的預處理語句總是根據實際參數值進行優化。然后計算平均計劃成本。在第5次及以后,如果通用計劃平均比自定義計劃代價低,那么規劃器從那時起存儲和使用通用計劃,并進行進一步優化。
plane準備好的語句已經執行過一次,在接下來的2次執行中,仍然使用自定義計劃,如查詢計劃中的參數值所示:
EXECUTE plane('763');
EXECUTE plane('773');
EXPLAIN EXECUTE plane('319');
QUERY PLAN??????????????????????????????????????????????????????????????????
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '319'::text)
(2 rows)
執行4次后,規劃器切換到通用規劃。在這種情況下,通用計劃與定制計劃相同,成本相同,因此更可取。現在EXPLAIN命令顯示參數編號,而不是實際值:
EXECUTE plane('320');
EXPLAIN EXECUTE plane('321');
QUERY PLAN??????????????????????????????????????????????????????????????????
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = '$1'::text)
(2 rows)
不幸的是,只有前4個定制計劃比通用計劃更昂貴,而任何進一步的定制計劃都會更便宜,但計劃者會完全忽略他們。另一個可能的不完善來源是計劃者比較成本估算,而不是要花費的實際資源成本。
這就是為什么在版本12及更高版本中,如果用戶不喜歡自動結果,他們可以強制系統使用通用計劃或自定義計劃。這是通過參數plan_cache_mode來完成:
SET plan_cache_mode = 'force_custom_plan';
EXPLAIN EXECUTE plane('CN1');
QUERY PLAN??????????????????????????????????????????????????????????????????
Seq Scan on aircrafts_data ml (cost=0.00..1.39 rows=1 width=52)
Filter: ((aircraft_code)::text = 'CN1'::text)
(2 rows)
14及更高版本中,pg_prepared_statements視圖還顯示計劃選擇統計信息:
SELECT name, generic_plans, custom_plans
FROM pg_prepared_statements;
name | generic_plans | custom_plans
???????+???????????????+??????????????
plane | 1 | 6
(1 row)
輸出檢索
擴展查詢協議允許客戶端批量獲取輸出,一次多行,而不是一次全部獲取。借助游標也可以實現相同目的,但成本更高,并且規劃器將優化對第一個cursor_tuple_fraction行的檢索:
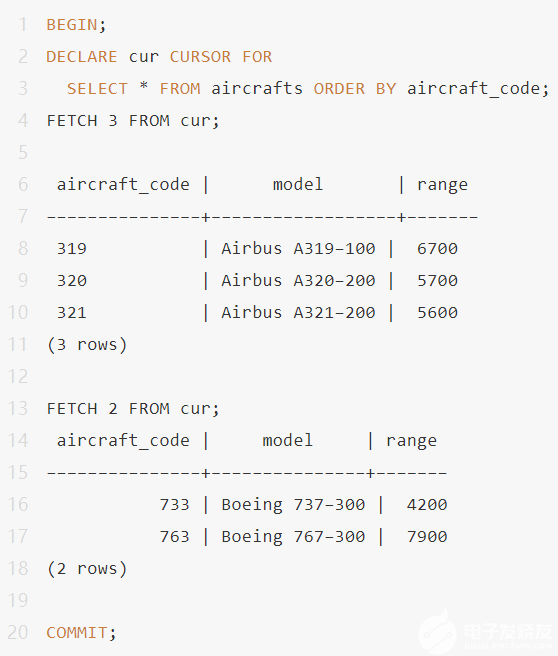
每當查詢返回大量行并且客戶端都需要他們時,一次檢索的行數對于整體數據傳輸速度至關重要。單批行越大,往返延遲損失的時間越少。然而,隨著批量大小的增加,節省的效率會下降。例如,從批量大小1切換到批量大小10將顯著增加時間節省。但從10切換到100幾乎沒有任何區別。
-
數據傳輸
+關注
關注
9文章
1913瀏覽量
64640 -
SQL
+關注
關注
1文章
766瀏覽量
44159
發布評論請先 登錄
相關推薦
色環電阻查詢器的使用方法
在查詢聲卡芯片 PCM2902C 顯示無法查詢到芯片
根據ip地址查網頁怎么查詢?
常見的IP地址查詢技術

如何利用IP查詢技術保護網絡安全?
探討IP查詢技術在金融行業的深度應用
如何利用python和API查詢IP地址?
華納云:Ubuntu18.04系統如何查詢域名的具體dns信息
ClickHouse內幕(3)基于索引的查詢優化

如何在stm32cubemx中精確查詢?
查詢SQL在mysql內部是如何執行?





 工商網監
工商網監
評論