") 使用NVIDIA Riva構(gòu)建轉(zhuǎn)錄和實體識別應(yīng)用程序
使用NVIDIA Riva構(gòu)建轉(zhuǎn)錄和實體識別應(yīng)用程序
在過去的幾個月里,我們中的許多人已經(jīng)習(xí)慣于通過視頻電話看醫(yī)生。這當(dāng)然很方便,但在通話結(jié)束后,醫(yī)生的重要建議就開始溜走了。我需要服用什么新藥?有什么副作用需要注意嗎?
Conversational AI 可以幫助構(gòu)建一個應(yīng)用程序來轉(zhuǎn)錄語音,并突出該轉(zhuǎn)錄本中的重要短語。 NVIDIA Riva 是一款 SDK ,它可以減少您構(gòu)建和部署可用于這些任務(wù)的最先進(jìn)的深度學(xué)習(xí)模型的時間。
在本文中,我們將向您展示如何構(gòu)建一個 web 應(yīng)用程序,該應(yīng)用程序可以從實時視頻聊天中轉(zhuǎn)錄語音,并在轉(zhuǎn)錄本中標(biāo)記關(guān)鍵短語。視頻聊天使用 PeerJS ,這是一個基于 WebRTC 的開源對等聊天框架。對于實時轉(zhuǎn)錄,您使用 Riva 中的自動語音識別( ASR )。標(biāo)記成績單中的關(guān)鍵短語使用命名實體識別( NER ),也來自 Riva 。我們還向您展示了如何使用來自醫(yī)學(xué)領(lǐng)域的數(shù)據(jù)來訓(xùn)練 NER 模型。雖然我們確實包含代碼示例,但為了清晰起見,我們省略了一些技術(shù)細(xì)節(jié),因此我們鼓勵您看看 Riva Samples Docker 容器。
該應(yīng)用程序的起點是一個簡單的點對點視頻通話 web 應(yīng)用程序。它包含以下資源:
一個 HTML 頁面
一個客戶端 JavaScript 文件
一個服務(wù)器 JavaScript 文件,用于托管資產(chǎn)并設(shè)置對等連接
我們將教程保持在最低限度,因此請記住,真正的應(yīng)用程序應(yīng)該更加復(fù)雜。它將包括身份和會話管理、警報、分析和更強(qiáng)大的網(wǎng)絡(luò)處理。

圖 2 。基本的點對點視頻聊天。
在本文中,我們將重點介紹如何將 ASR 和 NLP 功能添加到 web 應(yīng)用程序中,并跳過有關(guān)應(yīng)用程序結(jié)構(gòu)的一些細(xì)節(jié)。總結(jié)一下這個應(yīng)用程序,它是一個簡單的服務(wù)器,在 Node 。 js 中實現(xiàn),它使用 Express 托管 web 資產(chǎn),使用 PeerJ 幫助客戶端在點對點 WebRTC 視頻聊天中相互連接。在客戶機(jī)上,瀏覽器加載網(wǎng)頁,然后與服務(wù)器對話以幫助建立與對等方的連接。建立對等連接后,兩個客戶端直接相互通信。視頻不再通過服務(wù)器路由。
此時,用戶可以加載網(wǎng)頁,聯(lián)系其他用戶,并進(jìn)行實時視頻聊天。
添加 ASR 和 NLP
NVIDIA Riva 是一個 SDK ,可快速部署高性能對話式人工智能服務(wù)。 Riva quick start 參考資料提供了一個簡單易懂的指南,用于部署到 Riva 推理服務(wù)器。將資源下載到服務(wù)器后,可以歸結(jié)為幾個基本步驟:
在 config.sh 中配置部署。
通過運行 riva_init.sh 下載、優(yōu)化和準(zhǔn)備模型。
使用 riva_start.sh 啟動 Riva 技能服務(wù)器。
服務(wù)器啟動后,它會創(chuàng)建幾個 gRPC 端點,以幫助應(yīng)用程序與 Riva 通信。為了確保一切正常工作,請嘗試從設(shè)置 Riva 的服務(wù)器啟動客戶端容器。致電 riva_start_client.sh ,然后查看示例客戶端,瀏覽筆記本,了解 Riva 提供的功能。
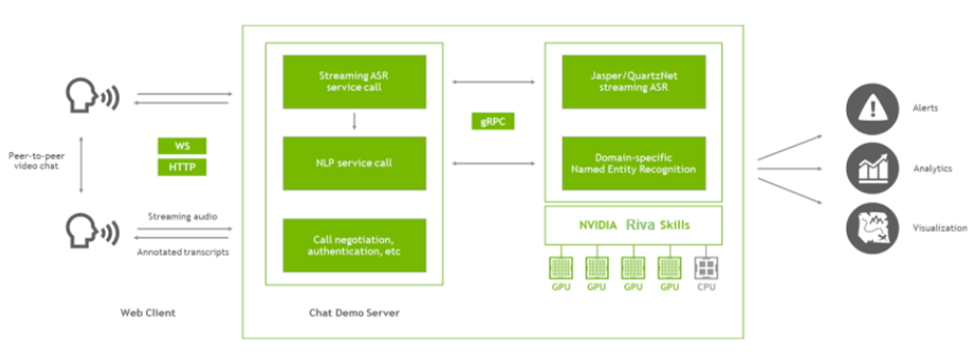
圖 3 。通過 Riva 的 ASR 和 NLP 進(jìn)行點對點聊天。
圖 3 顯示了應(yīng)用程序的主要組件,現(xiàn)在您已經(jīng)添加了 Riva 。聊天演示服務(wù)器( Node 。 js 應(yīng)用程序)仍然設(shè)置視頻通話,現(xiàn)在它還與 Riva 服務(wù)器通信。
在該應(yīng)用程序中,您可以使用 Riva 實現(xiàn)兩個功能:獲取對話的流媒體記錄,并在記錄中標(biāo)記關(guān)鍵短語(命名實體)。為此,從客戶端提取音頻流,并將該音頻傳遞到 Node 。 js 服務(wù)器。服務(wù)器使用 gRPC 調(diào)用 Riva 來獲取成績單和命名實體,并將結(jié)果傳遞回客戶端。然后,客戶端可以在瀏覽器中呈現(xiàn)文本,并通過點對點連接傳遞文本,以便兩個用戶都可以看到整個對話。
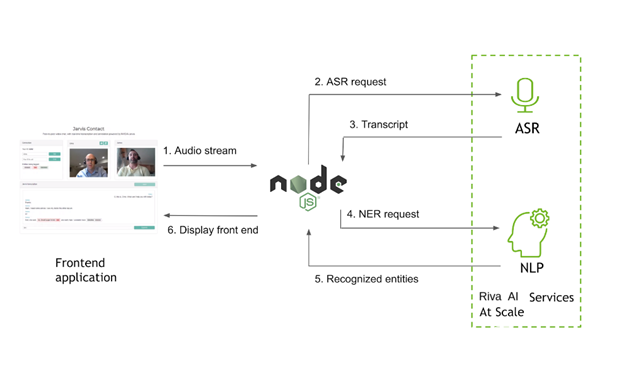
圖 4 。通過應(yīng)用程序的數(shù)據(jù)流。
從 web 客戶端獲取音頻
在客戶端,您可以通過點擊發(fā)送給對等方進(jìn)行視頻聊天的本地 WebRTC 流來訪問音頻流。在客戶端 JavaScript 文件中,當(dāng)用戶選擇時,初始化與服務(wù)器的 Riva 連接開始。 您正在通過套接字連接發(fā)送音頻數(shù)據(jù),因此首先確保套接字處于活動狀態(tài):

WebRTC audio 使用處理圖的概念。要在瀏覽器中使用音頻,請執(zhí)行以下操作:
連接到音頻源,在本例中是從本地視頻聊天流。
創(chuàng)建一個處理節(jié)點來處理該音頻。
在您參與之前,將新節(jié)點連接回原始目的地,即音頻最初傳輸?shù)牡胤健?/p>
每次您獲得進(jìn)入新處理節(jié)點的完整音頻緩沖區(qū)時,請使用 web worker 重新采樣,并通過套接字連接將重新采樣的緩沖區(qū)發(fā)送到服務(wù)器。設(shè)置音頻源連接并初始化重采樣器:

每次緩沖區(qū)填滿時,瀏覽器都會觸發(fā)一個事件,因此告訴處理器節(jié)點如何處理它。使用輔助線程重新采樣,然后使用套接字連接將其傳遞給服務(wù)器:

在將音頻發(fā)送到 Riva 之前,不完全需要對其進(jìn)行重新采樣。 Riva 可以自行進(jìn)行重新采樣。但是,在瀏覽器中執(zhí)行此操作既降低了帶寬要求,又簡化了從一個錄制源到另一個錄制源的一些差異。現(xiàn)在,您可以將新處理器節(jié)點連接到音頻圖中,包括源音頻和目標(biāo)音頻:

此時,應(yīng)用程序可以從用戶的麥克風(fēng)中提取音頻,對流重新采樣,并使用套接字將重新采樣的音頻發(fā)送到服務(wù)器。接下來,我們將向您展示如何在服務(wù)器上使用此音頻。
將音頻路由到 Riva
在 Node 。 js 中實現(xiàn)的主服務(wù)器腳本使用 Express server 和 Socket 。 IO 來處理傳入的連接。當(dāng)插座首次連接時,設(shè)置 Riva 連接。

這里發(fā)生了一些事情。您可以創(chuàng)建一個新的 ASRPipe 并將其附加到套接字的 handshake.session 對象,這樣您就有一個單獨的 setupASR 流與每個客戶端連接關(guān)聯(lián)。使用 Riva 執(zhí)行一些基本的 Riva 設(shè)置,然后啟動 ASR 偵聽循環(huán)。
ASR 偵聽循環(huán)是異步的。您定期向它發(fā)送成批的音頻數(shù)據(jù),它通過回調(diào)函數(shù)定期發(fā)送結(jié)果。回調(diào)函數(shù)是傳遞給 mainASR 的函數(shù)。在流模式下, Riva 可以發(fā)回兩種結(jié)果:一種是臨時假設(shè),隨著更多音頻的進(jìn)入(提供更多的上下文),該假設(shè)會發(fā)生變化;另一種是最終的轉(zhuǎn)錄本。每當(dāng)音頻中有短暫的停頓時,例如當(dāng)演講者呼吸時,抄本往往會作為“最終”返回。您將這兩種結(jié)果都發(fā)送回客戶機(jī),但當(dāng)您獲得最終結(jié)果時,您也會將這些成績單發(fā)送到 NLP 服務(wù)以獲得 NER 。無論哪種方式,都可以使用 transcript 事件通過相同的套接字連接將結(jié)果傳遞回客戶端。
使用 Socket 。 IO ,可以為特定事件設(shè)置偵聽器。前面提到過其中一個事件: audio_in 事件,該事件在客戶端發(fā)送音頻數(shù)據(jù)包時觸發(fā)。在服務(wù)器端,將偵聽器添加到用于初始化 Riva 的相同 io.on(‘connect’) 作用域。

這一部分很簡單,因為它不需要做很多事情。在連接套接字時設(shè)置了 Riva 流之后,您所要做的就是傳遞新的音頻內(nèi)容。
發(fā)送語音識別請求
現(xiàn)在看看 gRPC 接口本身,從 ASR 開始。連接到 gRPC service using Node.js 時,主要有三個步驟:
使用協(xié)議緩沖區(qū)導(dǎo)入 Riva API 。
圍繞 API 編寫方便的函數(shù)。
在客戶端和 Riva 函數(shù)之間調(diào)解數(shù)據(jù)。
在 asr 。 js 模塊中,定義前面調(diào)用的 ASRPipe 類,首先導(dǎo)入 Riva API :

然后,定義 ASRPipe 類以及前面調(diào)用的設(shè)置函數(shù):

在這里,您創(chuàng)建一個 Riva ASR 客戶機(jī)并定義一些配置參數(shù),這些參數(shù)在流打開時作為第一個請求發(fā)送到流。在同一類定義中,指定 mainASR 函數(shù)以設(shè)置實際 ASR 流:

streamingRecognize 函數(shù)是異步的。只要 Riva 有結(jié)果要發(fā)送,就會觸發(fā)數(shù)據(jù)事件,因此請重新打包這些結(jié)果,并將它們從早期發(fā)送到回調(diào)函數(shù)。
發(fā)送 NER 請求
調(diào)用 Riva NER 服務(wù)更簡單。像前面一樣加載 NLP API ,然后使用要處理的每行文本調(diào)用 ClassifyTokens 函數(shù)。每個請求發(fā)送文本以及要使用的 Riva – 部署模型。如果需要,在名為 computeSpans 的函數(shù)中進(jìn)行一些后處理,然后傳遞結(jié)果。

至此,您已經(jīng)完成了對 Riva 的 gRPC 調(diào)用。您可以在客戶端捕獲音頻,通過流式連接將其發(fā)送到 Riva 以獲取轉(zhuǎn)錄本,并在文本中標(biāo)記命名實體。每次 Riva 發(fā)回結(jié)果時,通過帶有 transcript 事件的套接字將結(jié)果傳遞給用戶的 web 客戶端。現(xiàn)在,通過在瀏覽器中處理這些結(jié)果來完成回路。
在瀏覽器中渲染結(jié)果
現(xiàn)在,您已經(jīng)將帶有注釋的成績單返回到 web 客戶端,請在瀏覽器中顯示它們。回想一下,所有的客戶機(jī) – 服務(wù)器通信都是通過 Socket 。 IO 連接進(jìn)行的,因此請為帶有結(jié)果的 transcript 事件設(shè)置一個偵聽器。

input_field 元素在 web UI 中是一個方便的地方,可以顯示臨時記錄,在您講話時可以實時更新。在完整應(yīng)用程序中,您使用同一字段發(fā)送純文本請求。當(dāng)成績單標(biāo)記為最終成績單時,將其顯示在單獨的框中,并將成績單副本發(fā)送給通話中的另一人,以便您可以看到對話的雙方。
呈現(xiàn)成績單本身是標(biāo)準(zhǔn)的 HTML 和 CSS 。為了讓您的生活更輕松,請使用優(yōu)秀的 displaCy-ENT 將命名實體與文本對齊。
微調(diào)醫(yī)療設(shè)備的模型
默認(rèn)情況下, Riva 提供了一個 NER 模型,該模型處理位置、人員、組織和時間等實體。這對于許多應(yīng)用程序來說都很好,比如理解新聞文章和構(gòu)建聊天機(jī)器人。早些時候,我們討論了對話 AI MIG ht 如何幫助遠(yuǎn)程醫(yī)療應(yīng)用程序。以下是 MIG ht 如何為 Riva 訓(xùn)練一個 NER 模型來標(biāo)記醫(yī)療實體。
從頭開始的培訓(xùn)模型通常是一個時間密集型過程。您可以使用現(xiàn)有的經(jīng)過訓(xùn)練的模型并對自定義數(shù)據(jù)進(jìn)行微調(diào),而不是從新的模型開始。 NVIDIA TAO Toolkit 是一款基于 Python 的 AI 工具包,專門設(shè)計用于減少使用數(shù)據(jù)微調(diào)和定制預(yù)訓(xùn)練模型所需的時間。
因為醫(yī)療數(shù)據(jù)可能高度敏感,所以在線查找并不總是那么容易。一個優(yōu)秀的 NER 數(shù)據(jù)集來自 2010 i2b2/VA challenge ,其中包含針對問題(如疾病或癥狀)、治療(包括藥物)和測試標(biāo)記的未識別醫(yī)生注釋。您可以申請訪問數(shù)據(jù)集,這是醫(yī)學(xué) NLP 社區(qū)中使用的標(biāo)準(zhǔn)競爭基準(zhǔn)。
NER 數(shù)據(jù)通常以某種形式的 IOB 提供 標(biāo)記,其中文本中的每個標(biāo)記標(biāo)記為實體開頭、實體內(nèi)部(不是第一個單詞)或外部。對于醫(yī)學(xué)文本,它通常如下所示:

這是用作 TAO 工具包輸入的數(shù)據(jù)。有關(guān)使用工具包培訓(xùn) NER 模型的更多信息,請參閱 TAO- Riva NER 集合中的培訓(xùn)筆記本。在本例中,您從預(yù)訓(xùn)練的語言模型檢查點 bert base uncased 開始,并使用預(yù)處理的 i2b2 數(shù)據(jù)為 NER 任務(wù)對其進(jìn)行調(diào)優(yōu)。
培訓(xùn)和部署自定義模型需要幾個步驟。從預(yù)訓(xùn)練的檢查點開始,您可以使用數(shù)據(jù)微調(diào) TAO 工具箱中的模型。再次使用工具箱將模型導(dǎo)出為 Riva 的優(yōu)化形式。為 Riva 提供一些基本部署設(shè)置,構(gòu)建一個綁定配置的中間表單。然后,部署該包以創(chuàng)建一個正在運行的 Riva 服務(wù)器。有關(guān)更多信息,請參閱 NVIDIA Riva Speech Skills 。
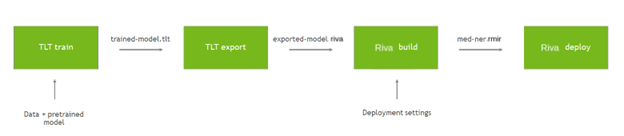
圖 5 。培訓(xùn)和部署微調(diào)模型。
以下命令使用 TAO 工具包對自定義數(shù)據(jù)上的預(yù)訓(xùn)練模型進(jìn)行微調(diào):

完成后, TAO 工具包將模型保存在名為 trained-model.tlt 的文件中。下一步是將此模型導(dǎo)出為 Riva 可用于部署的 riva 格式:

該模型現(xiàn)在導(dǎo)出為 exported-model.riva ,可在 Riva 中使用。
使用 Riva ServiceMaker Docker 映像,構(gòu)建并部署新模型。

--IOB 標(biāo)志告訴 Riva 將模型輸出解釋為 IOB 標(biāo)記的 NER 模型,這簡化了模型輸出。 $RIVA_REPO_DIR 是 Riva 存儲庫的位置,該存儲庫是在從快速啟動腳本運行 riva_init.sh 時創(chuàng)建的。該存儲庫包含一個 models 子目錄,其中包含所有已部署的模型,包括默認(rèn)的通用域。調(diào)用 riva-deploy 時, Riva 將新的 NER 模型插入該位置。
有了這個新的 NER 模型,你現(xiàn)在可以在應(yīng)用程序中獲得醫(yī)學(xué)領(lǐng)域標(biāo)簽,通過對話實時顯示。

圖 6 。使用經(jīng) TAO 工具包調(diào)整的 NER 模型進(jìn)行醫(yī)學(xué)領(lǐng)域標(biāo)記。
部署到生產(chǎn)環(huán)境中
Riva 設(shè)計為高度可擴(kuò)展,使用 Riva SDK 開發(fā)的應(yīng)用程序可以部署在云端或本地 Kubernetes 集群中。 Riva 提供了一個示例頭盔圖,可用于入門:
在集群上安裝 Kubernetes 、 Helm 3 。 0 和 Kubernetes 的 NVIDIA GPU Operator 。接下來,從 NGC 下載 Riva AI 服務(wù)掌舵圖。

解開壓縮文件夾后,在 /riva-api 下查找部署所需的文件。

Chart 。 yaml 文件包含有關(guān)頭盔部署的信息,如名稱、版本等。要更改部署配置,請查看 values 。 yaml 文件,并根據(jù)需要更改配置:
replicaCount : Riva 服務(wù)副本的數(shù)量。
speechServices [asr | nlp | tts] :啟用語音服務(wù)的三個布爾參數(shù)。
ngcModelConfigs :要從 NGC 下載的型號配置。
service :要在生產(chǎn)中部署的負(fù)載平衡服務(wù)。
從 values 。 yaml 文件讀取值的 Kubernetes 部署文件位于 templates 文件夾中。 Kubernetes 集群上的 Riva 示例部署執(zhí)行以下操作:
找到 GPU 節(jié)點并使用預(yù)訓(xùn)練模型拉取 Riva 語音 Docker 容器。
裝載包含模型目錄的 Docker 卷。
拉動、設(shè)置和運行 Triton 推理服務(wù)器。
為入站推斷請求和出站響應(yīng)打開端口。
設(shè)置 Prometheus 服務(wù)以提取 GPU 和推斷度量。
最后,要部署 Riva 服務(wù)器,請運行以下命令:![]() 或者,使用 --set 選項安裝,而不修改 values 。 yaml 文件。確保正確設(shè)置 NGC _ API _鍵 ngcCredentials.email 和 model_key_string 值。默認(rèn)情況下, model_key_string 選項設(shè)置為 tlt_encode.
或者,使用 --set 選項安裝,而不修改 values 。 yaml 文件。確保正確設(shè)置 NGC _ API _鍵 ngcCredentials.email 和 model_key_string 值。默認(rèn)情況下, model_key_string 選項設(shè)置為 tlt_encode.

檢查日志,查看 Riva 服務(wù)器是否已部署且沒有任何錯誤:

要向 Riva 服務(wù)器發(fā)出推斷請求,必須獲取負(fù)載平衡器的 IP 地址:

EXTERNAL-IP 值可以在 env.txt 中用作 external endpoint:![]() 在理想的微服務(wù)部署架構(gòu)中,示例 web 應(yīng)用程序也應(yīng)包含在 Helm 部署中。但是,對于本文,請將 Node 。 js 應(yīng)用程序排除在集群環(huán)境之外。使用示例應(yīng)用程序中的上一個命令中的群集 IP 地址,并測試 Riva ASR 和 NLP 的規(guī)模能力。
在理想的微服務(wù)部署架構(gòu)中,示例 web 應(yīng)用程序也應(yīng)包含在 Helm 部署中。但是,對于本文,請將 Node 。 js 應(yīng)用程序排除在集群環(huán)境之外。使用示例應(yīng)用程序中的上一個命令中的群集 IP 地址,并測試 Riva ASR 和 NLP 的規(guī)模能力。
結(jié)論
很難構(gòu)建一個針對您的用例定制的高性能、可伸縮的對話 AI 應(yīng)用程序。在本文中,我們討論了如何使用 NVIDIA Riva 輕松地向現(xiàn)有應(yīng)用程序添加音頻轉(zhuǎn)錄和命名實體識別功能。我們還介紹了如何使用 TAO Toolkit 定制應(yīng)用程序,以及如何使用 Helm 圖表大規(guī)模部署應(yīng)用程序。您可以從 下載 Riva 開始學(xué)習(xí)。
關(guān)于作者
About wnger:
About Christopher Parisien:是一位應(yīng)用科學(xué)家,致力于醫(yī)療保健方面的對話人工智能。在加入 NVIDIA 之前, Christopher 領(lǐng)導(dǎo)過研究和工程團(tuán)隊,并為虛擬助手、臨床語言理解和以患者為中心的護(hù)理構(gòu)建了應(yīng)用程序。克里斯托弗擁有多倫多大學(xué)計算語言學(xué)博士學(xué)位。
About Abhishek Sawarkar:責(zé)在 NVIDIA Jarvis 框架上開發(fā)和展示以深度學(xué)習(xí)為重點的內(nèi)容。他的背景是計算機(jī)視覺和機(jī)器學(xué)習(xí),但目前他正致力于整個 Jarvis 多模式管道,包括 ASR 、 NLP 、 TTS 和 CV 。他是卡內(nèi)基梅隆大學(xué)的一名應(yīng)屆畢業(yè)生,具有電氣和計算機(jī)工程碩士學(xué)位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4978瀏覽量
102989 -
AI
+關(guān)注
關(guān)注
87文章
30728瀏覽量
268889 -
應(yīng)用程序
+關(guān)注
關(guān)注
37文章
3265瀏覽量
57678
發(fā)布評論請先 登錄
相關(guān)推薦
AWTK-WEB 快速入門(1) - C 語言應(yīng)用程序

使用OpenVINO GenAI API在C++中構(gòu)建AI應(yīng)用程序
借助NVIDIA DOCA 2.7增強(qiáng)AI 云數(shù)據(jù)中心和NVIDIA Spectrum-X
NVIDIA Omniverse USD Composer能用來做什么?如何獲取呢?
使用Redis和Spring?Ai構(gòu)建rag應(yīng)用程序

使用NVIDIA Holoscan for Media構(gòu)建下一代直播媒體應(yīng)用
蘋果ReALM模型在實體識別測試中超越OpenAI GPT-4.0
NVIDIA宣布推出基于Omniverse Cloud API構(gòu)建的全新軟件框架
應(yīng)用程序中的服務(wù)器錯誤怎么解決?
使用ADS .NET Framework構(gòu)建一個應(yīng)用程序,.s (匯編文件)文件無法編譯的原因?
基于NVIDIA DOCA 2.6實現(xiàn)高性能和安全的AI云設(shè)計
u8g2應(yīng)用程序無法在moduStoolBox中構(gòu)建是為什么?
Modustoolbox3.1離線時無法構(gòu)建模板應(yīng)用程序怎么辦?
如何構(gòu)建linux開發(fā)環(huán)境和編譯軟件工程、應(yīng)用程序





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論