") HugeCTR能夠高效地利用GPU來(lái)進(jìn)行推薦系統(tǒng)的訓(xùn)練
HugeCTR能夠高效地利用GPU來(lái)進(jìn)行推薦系統(tǒng)的訓(xùn)練
1. Introduction
HugeCTR 能夠高效地利用 GPU 來(lái)進(jìn)行推薦系統(tǒng)的訓(xùn)練,為了使它還能直接被其他 DL 用戶(hù),比如 TensorFlow 所直接使用,我們開(kāi)發(fā)了 SparseOperationKit (SOK),來(lái)將 HugeCTR 中的高級(jí)特性封裝為 TensorFlow 可直接調(diào)用的形式,從而幫助用戶(hù)在 TensorFlow 中直接使用 HugeCTR 中的高級(jí)特性來(lái)加速他們的推薦系統(tǒng)。
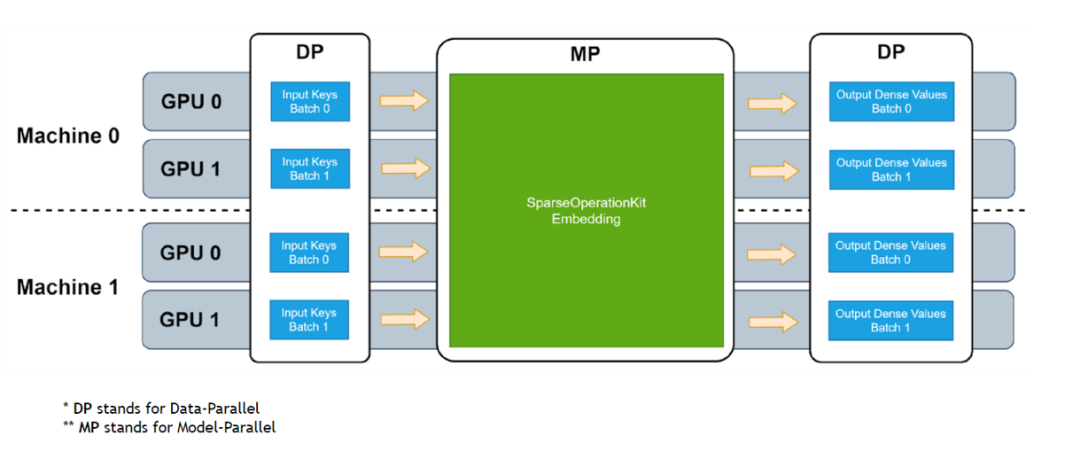
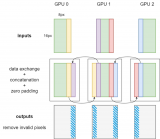
圖 1. SOK embedding 工作流程
SOK 以數(shù)據(jù)并行的方式接收輸入數(shù)據(jù),然后在 SOK 內(nèi)部做黑盒式地模型轉(zhuǎn)換,最后將計(jì)算結(jié)果以數(shù)據(jù)并行的方式傳遞給初始 GPU。這種方式可以盡可能少地修改用戶(hù)已有的代碼,以更方便、快捷地在多個(gè) GPU 上進(jìn)行擴(kuò)展。
SOK 不僅僅是加速了 TensorFlow 中的算子,而是根據(jù)業(yè)界中的實(shí)際需求提供了對(duì)應(yīng)的新解決方案,比如說(shuō) GPU HashTable。SOK 可以與 TensorFlow 1.15 和 TensorFlow 2.x 兼容使用;既可以使用 TensorFlow 自帶的通信工具,也可以使用 Horovod 等第三方插件來(lái)作為 embedding parameters 的通信工具。
使用 MLPerf 的標(biāo)準(zhǔn)模型 DLRM 來(lái)對(duì) SOK 的性能進(jìn)行測(cè)試。
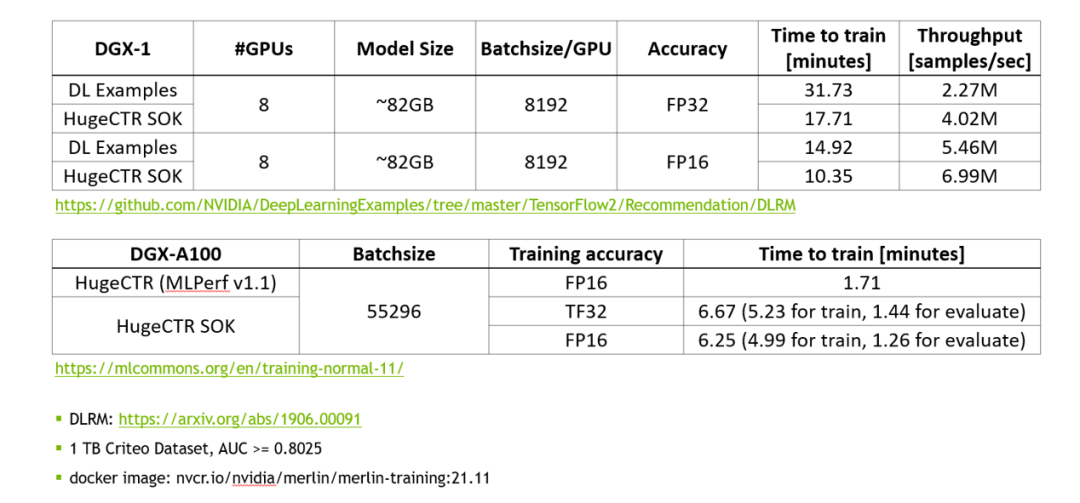
圖 2. SOK 性能測(cè)試數(shù)據(jù)
相比于 NVIDIA 的 DeepLearning Examples,使用 SOK 可以獲得更快的訓(xùn)練速度以及更高的吞吐量。
3. API
SOK 提供了簡(jiǎn)潔的、類(lèi) TensorFlow 的 API;使用 SOK 的方式非常簡(jiǎn)單、直接;讓用戶(hù)通過(guò)修改幾行代碼就可以使用 SOK。
1. 定義模型結(jié)構(gòu)

左側(cè)是使用 TensorFlow 的 API 來(lái)搭建模型,右側(cè)是使用 SOK 的 API 來(lái)搭建相同的模型。使用 SOK 來(lái)搭建模型的時(shí)候,只需要將 TensorFlow 中的 Embedding Layer 替換為 SOK 對(duì)應(yīng)的 API 即可。
2. 使用 Horovod 來(lái)定義 training loop

同樣的,左側(cè)是使用 TensorFlow 來(lái)定義 training loop,右側(cè)是使用 SOK 時(shí),training loop 的定義方式。可以看到,使用 SOK 時(shí),只需要對(duì) Embedding Variables 和 Dense Variables 進(jìn)行分別處理即可。其中,Embedding Variables 部分由 SOK 管理,Dense Variables 由 TensorFlow 管理。
3. 使用 tf.distribute.MirroredStrategy 來(lái)定義 training loop

類(lèi)似的,還可以使用 TensorFlow 自帶的通信工具來(lái)定義 training loop。
4. 開(kāi)始訓(xùn)練

在開(kāi)始訓(xùn)練過(guò)程時(shí),使用 SOK 與使用 TensorFlow 時(shí)所用代碼完全一致。
4. 結(jié)語(yǔ)
SOK 將 HugeCTR 中的高級(jí)特性包裝為 TensorFlow 可以直接使用的模塊,通過(guò)修改少數(shù)幾行代碼即可在已有模型代碼中利用上 HugeCTR 的先進(jìn)設(shè)計(jì)。
審核編輯 :李倩
-
gpu
+關(guān)注
關(guān)注
28文章
4753瀏覽量
129062 -
SOK
+關(guān)注
關(guān)注
0文章
5瀏覽量
6338
原文標(biāo)題:Merlin HugeCTR Sparse Operation Kit 系列之一
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
GPU是如何訓(xùn)練AI大模型的
如何利用地物光譜進(jìn)行土地利用分類(lèi)?
訓(xùn)練AI大模型需要什么樣的gpu
NPU與GPU的性能對(duì)比
PyTorch GPU 加速訓(xùn)練模型方法
為什么ai模型訓(xùn)練要用gpu
GPU服務(wù)器在AI訓(xùn)練中的優(yōu)勢(shì)具體體現(xiàn)在哪些方面?
蘋(píng)果承認(rèn)使用谷歌芯片來(lái)訓(xùn)練AI
SOK在手機(jī)行業(yè)的應(yīng)用案例
llm模型訓(xùn)練一般用什么系統(tǒng)
如何利用Matlab進(jìn)行神經(jīng)網(wǎng)絡(luò)訓(xùn)練
如何提高自動(dòng)駕駛汽車(chē)感知模型的訓(xùn)練效率和GPU利用率
AI訓(xùn)練,為什么需要GPU?

FPGA在深度學(xué)習(xí)應(yīng)用中或?qū)⑷〈?b class='flag-5'>GPU
應(yīng)用大模型提升研發(fā)效率的實(shí)踐與探索






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論