 如何使用CMake工具套件構建CUDA應用程序
如何使用CMake工具套件構建CUDA應用程序
跨平臺軟件開發對應用程序的構建過程提出了許多挑戰。如何針對多個平臺而不維護多個平臺特定的構建腳本、項目或生成文件?如果您需要構建 CUDA 代碼作為過程的一部分呢? CMake 是一個開源、跨平臺的工具系列,旨在跨不同平臺構建、測試和打包軟件。許多開發人員使用 CMake 來使用簡單的獨立于平臺和編譯器的配置文件來控制他們的軟件編譯過程。 CMake 生成可在您選擇的編譯器環境中使用的本機 makefile 和工作區。 CMake 工具套件是由 Kitware 創建的,是為了響應對 ITK 和 VTK 等開源項目的強大、跨平臺構建環境的需求。
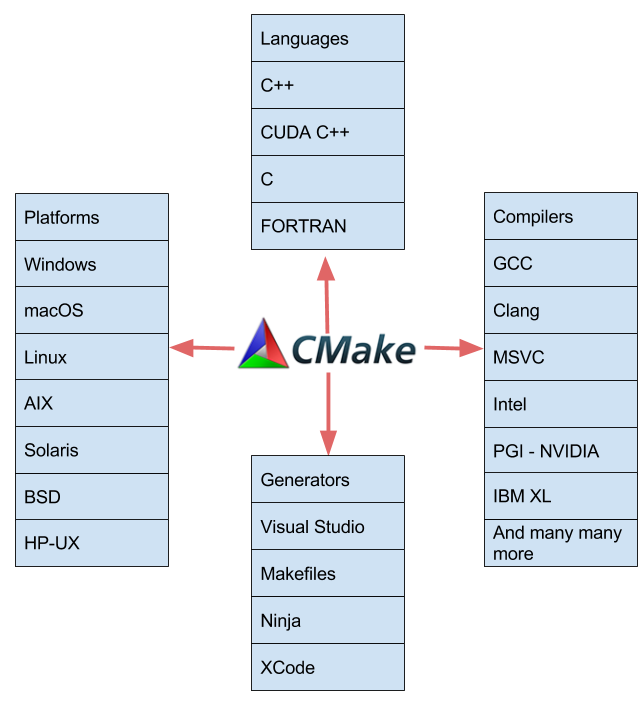
在這篇文章中,我想向您展示使用 cmake3 . 8 +( 3 . 9 支持 MSVC )的特性來構建 CUDA 應用程序是多么容易。從 2009 年起, CMake (從 2 . 8 . 0 開始)就提供了通過 Find CUDA 包提供的cuda_add_executable和cuda_add_library等自定義命令編譯 CUDA 代碼的能力。 CGEASE 3 . 8 使 CUDA C ++成為一種本質上支持的語言。 CUDA 現在加入了 CMake 支持的各種語言、平臺、編譯器和 ide ,如圖 1 所示。
CMake 中的一個 CUDA 示例
讓我們從一個用 CMake 構建 CUDA 的例子開始。清單 1 顯示了名為“ particles ”的 CUDA 示例的 CMake 文件。我已經在 Github 上提供了此示例的完整代碼。
cmake_minimum_required(VERSION 3.8 FATAL_ERROR) project(cmake_and_cuda LANGUAGES CXX CUDA) include(CTest) add_library(particles STATIC randomize.cpp randomize.h particle.cu particle.h v3.cu v3.h ) # Request that particles be built with -std=c++11 # As this is a public compile feature anything that links to # particles will also build with -std=c++11 target_compile_features(particles PUBLIC cxx_std_11) # We need to explicitly state that we need all CUDA files in the # particle library to be built with -dc as the member functions # could be called by other libraries and executables set_target_properties( particles PROPERTIES CUDA_SEPARABLE_COMPILATION ON) add_executable(particle_test test.cu) set_property(TARGET particle_test PROPERTY CUDA_SEPARABLE_COMPILATION ON) target_link_libraries(particle_test PRIVATE particles) if(APPLE) # We need to add the path to the driver (libcuda.dylib) as an rpath, # so that the static cuda runtime can find it at runtime. set_property(TARGET particle_test PROPERTY BUILD_RPATH ${CMAKE_CUDA_IMPLICIT_LINK_DIRECTORIES}) endif()
在我完成清單 1 所示的所有邏輯和特性之前,讓我們先跳過構建。如果您使用 VisualStudio ,則需要使用 CGuess 3 . 9 和 VisualStudio CUDA 構建擴展(包含在 CUDA 工具包中),否則您可以使用生成文件生成器(或忍者生成器)與nvcc( NVIDIA CUDA 編譯器)和 C ++編譯器在您的路徑中使用 CMASE 3 . 8 或更高。(或者,您可以將CUDACXX和CXX環境變量分別設置為nvcc和 C ++編譯器的路徑)。


為了配置 CMake 項目并生成一個 makefile ,我使用了以下命令
cmake -DCMAKE_CUDA_FLAGS=”-arch=sm_30” .
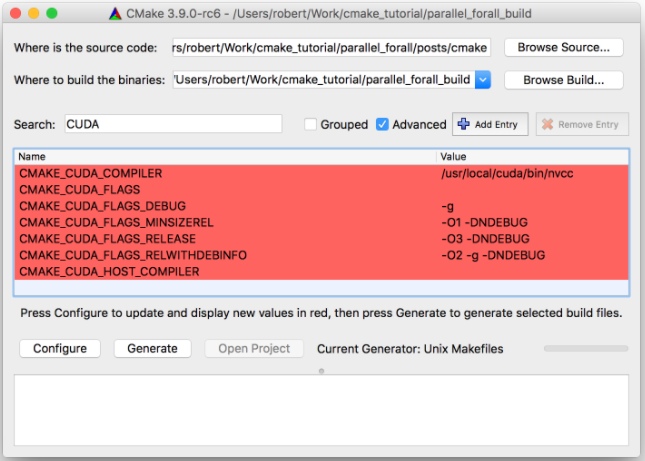
圖 1 顯示了輸出。 CMADE 自動發現并驗證 C ++和 CUDA 編譯器并生成一個 MaMaFrimeProject 。注意,參數-DCMAKE_CUDA_FLAGS="-arch=sm_30"將-arch=sm_30傳遞給nvcc,告訴它以我計算機中的開普勒體系結構( SM _ 30 或 ComputeCapability 3 . 0 ) GPU 為目標。
接下來,圖 1 顯示了我如何使用命令make -j4調用構建。這運行了make多個線程,因此它并行編譯 C ++和 CUDA 源文件。有關 CMake 如何確定在項目中的何處查找并行性的更多信息,請閱讀““用你所有的核心來建設”。 CMake 還可以自動管理將多種語言構建和鏈接到可執行文件或共享庫中。
啟用 CUDA
讓我們深入研究 CMake 代碼并研究不同的組件。和往常一樣,根 CMake 文件中的第一個命令應該是cmake_minimum_required,它斷言 CMake 版本足夠新,并確保 CMake 可以確定當用戶運行的 CMake 版本比需要的版本更新時,它需要保留哪些向后兼容性。
接下來,第 2 行是 Project 命令,它設置項目名稱(cmake_and_cuda)并定義所需語言( C ++和 CUDA )。這使 CMake 能夠識別和驗證所需的編譯器,并緩存結果。這將生成圖 3 所示的公共緩存語言標志。
既然 CMake 已經確定了項目需要什么語言,并且配置了它的內部基礎設施,我們就可以繼續編寫一些真正的 CMake 代碼了。
用 CMake 建立圖書館
學習 CMake 時,每個人做的第一件事就是編寫一個生成單個可執行文件的玩具示例就像這個。讓我們更大膽一點,并生成一個可執行文件使用的靜態庫。
使用要求是現代 CMake 的核心。 include 目錄、編譯器定義和編譯器選項等信息可以與目標相關聯,這樣這些信息就可以通過target_link_libraries自動傳播給使用者。在 CMake 的早期版本中,構建 CUDA 代碼需要命令,比如cuda_add_library。不幸的是,這些命令無法參與使用需求,因此無法使用傳播的編譯器標志或定義。 CMake 中現在對 CUDA 的內在支持使使用 CUDA 的目標能夠充分利用現代 CMake 使用需求,并為所有語言提供統一的 CMake 語法。
C ++語言層
在一個項目中,首先要配置的事情之一是 C ++語言級別( 98 , 11 , 14 , 17 …)。 CGuSE 3 . 1 介紹了為整個項目或基于每個目標的基礎來設置 C ++語言級別的能力。還可以控制 CUDA 編譯的 C ++語言級別。
您可以通過CMAKE_CUDA_STANDARD或target_compile_features命令輕松地要求特定版本的 CUDA 編譯器。為了使target_compile_features更容易與 CUDA 一起使用, CMake 使用了 CUDA C ++的同一組 C ++特征關鍵字。下面的代碼展示了如何請求 C ++ 11 對particles目標的支持,這意味著粒子目標所使用的任何 CUDA 文件都會被 CUDA C ++ 11 啟用(--std=c++11參數]nvcc]編譯。
# Request that particles be built with --std=c++11 # As this is a public compile feature anything that links to particles # will also build with -std=c++11 target_compile_features(particles PUBLIC cxx_std_11)
啟用位置無關代碼
在處理大型項目時,通常會生成一個或多個共享庫。作為共享庫一部分的每個對象文件通常都需要在啟用位置獨立代碼的情況下進行編譯,這是通過設置fPIC編譯器標志來完成的。不幸的是,并非所有編譯器都支持fPIC,因此 CMake 在構建共享庫時自動啟用位置無關的代碼,從而避免了這個問題。對于將鏈接到共享庫的靜態庫,需要通過如下設置POSITION_INDEPENDENT_CODEtarget 屬性顯式地啟用位置無關的代碼。
set_target_properties(particles PROPERTIES POSITION_INDEPENDENT_CODE ON)
CMake 3 . 8 支持 CUDA 編譯的POSITION_INDEPENDENT_CODE屬性,并在請求時構建所有可重新定位的主機端代碼。對于那些希望在跨平臺項目或內部共享庫中使用 CUDA 的項目,或者希望支持深奧的 C ++編譯器的項目,這是一個好消息。
可分離匯編
默認情況下, CUDA 編譯器使用整個程序編譯。實際上,這意味著所有設備函數和變量都需要位于單個文件或編譯單元中。單獨編譯和鏈接是在 CUDA 5 . 0 中引入的,它允許將 CUDA 程序的組件編譯成單獨的對象。為了使其正常工作,任何使用可分離編譯的庫或可執行文件都有兩個鏈接階段。首先它必須為包含 CUDA 設備代碼的所有對象執行設備鏈接,然后必須執行主機端鏈接,包括上一個鏈接階段的結果。
可分離編譯不僅允許項目維護一個代碼結構,其中獨立的函數被保存在不同的位置,它還有助于提高增量構建性能(所有基于 CMake 的項目的一個特性)。增量構建只允許重新編譯和鏈接已修改的單元,這減少了構建時間。可分離編譯的主要缺點是,對于駐留在不同編譯位中的函數的調用,某些函數調用優化被禁用,因為編譯器不知道被調用函數的詳細信息。
CMake 現在基本上理解了獨立編譯和設備鏈接的概念。隱式地, CMake 會盡可能長時間地延遲 CUDA 代碼的設備鏈接,因此,如果您使用可重定位的 CUDA 代碼生成靜態庫,則設備鏈接將被推遲,直到靜態庫鏈接到共享庫或可執行文件。這是一個顯著的改進,因為現在可以將 CUDA 代碼組合到多個靜態庫中,這在 CMake 中以前是不可能的。要控制 CMake 中的可分離編譯,請按如下方式打開目標的CUDA_SEPARABLE_COMPILATION屬性。
set_target_properties(particles PROPERTIES CUDA_SEPARABLE_COMPILATION ON)
 高級提示
高級提示
PTX 生成
如果要將 PTX 文件打包用于加載時 JIT 編譯,而不是將 CUDA 代碼編譯到庫或可執行文件的集合中,則可以啟用CUDA_PTX_COMPILATION屬性,如下例所示。本例將一些.cu文件編譯為 PTX ,然后指定安裝位置。
add_library(CudaPTX OBJECT kernelA.cu kernelB.cu) set_property(TARGET CudaPTX PROPERTY CUDA_PTX_COMPILATION ON) install(TARGETS CudaPTX OBJECTS DESTINATION bin/ptx )
為了使 PTX 生成成為可能,對 CMake 進行了擴展,以便所有對象庫都能夠在生成器表達式中安裝、導出、導入和引用。這也使得 PTX 文件能夠被 bin2c 等工具轉換或處理,然后作為 C 字符串嵌入到庫或可執行文件中。這是一個基本的例子。
審核編輯:郭婷
-
代碼
+關注
關注
30文章
4779瀏覽量
68524 -
應用程序
+關注
關注
37文章
3265瀏覽量
57677
發布評論請先 登錄
相關推薦
android手機上emulate應用程序的方法

AWTK-WEB 快速入門(1) - C 語言應用程序

【xG24 Matter開發套件試用體驗】+開機啟動
使用Redis和Spring?Ai構建rag應用程序

應用程序中的服務器錯誤怎么解決?
使用ADS .NET Framework構建一個應用程序,.s (匯編文件)文件無法編譯的原因?
鴻蒙開發【編譯構建】講解
請問一下CMake和Make之間的區別有哪些?
u8g2應用程序無法在moduStoolBox中構建是為什么?
Modustoolbox3.1離線時無法構建模板應用程序怎么辦?
如何構建linux開發環境和編譯軟件工程、應用程序
解決方案工具包QE顯示[RX,RA]V3.2.0:用于顯示應用程序的開發輔助工具
![解決方案<b class='flag-5'>工具</b>包QE顯示[RX,RA]V3.2.0:用于顯示<b class='flag-5'>應用程序</b>的開發輔助<b class='flag-5'>工具</b>](https://file.elecfans.com/web1/M00/D9/4E/pIYBAF_1ac2Ac0EEAABDkS1IP1s689.png)





 工商網監
工商網監
評論