 最新版本CUDA 11 . 5工具包的基本新功能
最新版本CUDA 11 . 5工具包的基本新功能
NVIDIA 宣布 CUDA 開發環境的最新版本 CUDA 11 . 5 。 CUDA 11 . 5 專注于增強您的 CUDA 應用程序的編程模型和性能。 CUDA 繼續推動 GPU 加速的邊界,并為 HPC 、可視化、 AI 、 ML 和 DL 中的新應用打下基礎,和數據科學。
CUDA 11 . 5 有幾個重要特性。這篇文章概述了關鍵功能:
-
CUDA 編程模型增強
- 掃描合作小組中的集體
- 標準化整數格式
- 塊壓縮格式
- C ++中可配置的緩存提示
- MPS 增強功能(客戶端內存限制)
- WSL 上的 CUDA 驅動程序更新
- CUDA Python GA
- NVIDIA 開普勒驅動器的棄用
- CUDA C ++(有關更多信息,請參閱使用 CUDA C ++編譯輔助工具減少應用程序構建時間)
- NSight 計算/系統工具
CUDA 11 . 5 附帶 R510 驅動程序,該驅動程序是一個長期支援科. CUDA 11 . 5 可供下載。
CUDA 編程模型增強
此版本引入了關鍵的增強功能,以提高 CUDA 圖形的可用性和性能,而無需對應用程序進行任何修改或任何其他用戶干預。它還提高了多進程服務( MPS )的易用性。我們在 CUDA 編程指南中對異步編程模型進行了形式化。
掃描合作小組中的集體
與reductions和障礙,前綴和(也稱為scans)一起,它們是并行計算的基石。掃描操作采用二進制運算符(通常為加法),并在輸入數組上累積應用該運算符進行迭代。掃描可以是inclusive,包括所有元素x[0]…x[n],或在范圍{0,x[0]…x[n-1]}上迭代的exclusive。
例如,使用輸入數組[3 1 7 0 4 1 6 3]的+運算符進行獨占掃描將導致以下結果:
[0 3 4 11 11 15 16 22]
CUDA 11 . 5 添加了一個新的頭
| Inclusive Scan | Exclusive Scan | Description |
template |
templateT exclusive_scan(const Group& g, T&& val, OpType&& op); |
Perform scan using user supplied binary operator. |
template |
template |
Same as above with assumed op == plus |
在所有情況下,返回類型必須與輸入值類型匹配。
規范化整數數據類型
標準化有符號和無符號 8 位和 16 位數據類型是 GPU 編程語言最廣泛支持的一些紋理格式。 CUDA 一段時間以來一直支持將這些格式用于紋理對象,但在 11 . 5 版本中,我們擴展了對這些數據類型的現有支持,使與其他外部 API 的互操作更加直觀。
我們在驅動程序和運行時 API 中引入了新的 CUDA 數組格式。驅動程序 API 公開了 12 種新的數組格式,如下所示:
CU_AD_FORMAT_UNORM_INT8X{1|2|4}
CU_AD_FORMAT_UNORM_INT16X{1|2|4}
CU_AD_FORMAT_SNORM_INT8X{1|2|4}
CU_AD_FORMAT_SNORM_INT16X{1|2|4}
這些可用于創建 1 、 2 或 4 通道 CUDA 陣列。運行時 API 同樣公開了 12 種新的等效通道格式:
cudaChannelFormatKindUnsignedNormalized8X{1|2|4}
cudaChannelFormatKindSignedNormalized8X{1|2|4}
cudaChannelFormatKindUnsignedNormalized16X{1|2|4}
cudaChannelFormatKindSignedNormalized16X{1|2|4}
這些還可用于創建 1 、 2 或 4 通道、 8 位或 16 位通道寬度 CUDA 陣列。此外,您現在可以從外部 API (如 DirectX12 / 11 或 Vulkan )導入匹配的格式化紋理,并將其映射為 CUDA 數組。使用資源視圖創建紋理對象時,格式 texel 大小必須與數組 texel 大小匹配。
對于紋理對象,可以創建和訪問它們,如以下代碼示例所示:
cudaArray_t array;
cudaChannelFormatDesc formatDesc = {8, 8, 0, 0, cudaChannelFormatKindUnsignedNormalized8X2};
cudaMallocArray(&array, formatDesc, width, height);
cudaTextureDesc texDesc = {0};
texDesc.addressMode[0] = texDesc.addressMode[1] = cudaAddressModeClamp ;
// (3) Create CUDA texture object
cudaResourceDesc resDesc = {0};
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array = array;
cudaCreateTextureObject(&texObj, &resDesc, &texDesc, NULL);
// Read from texture object in a kernel as follows:
// float4 texel = tex2D(texture, x, y);
// (6) Release all resources
cudaDestroyTextureObject(texObj);
cudaFreeArray(array);
同樣,對于曲面對象:
cudaArray_t array;
cudaChannelFormatDesc formatDesc = {16, 16, 16, 16, cudaChannelFormatKindSignedNormalized16X4};
cudaMallocArray(&array, formatDesc, width, height);
// (3) Create CUDA surface object
cudaResourceDesc resDesc = {0};
resDesc.resType = cudaResourceTypeArray;
resDesc.res.array = array;
cudaCreateSurfaceObject(&surfObj, &resDesc);
// Read/Write to/from surface object in a kernel as follows
// Read:
// short4 texel = surf2DRead(surface, xInBytes, y);
// Unformatted stores:
// surf2DWrite(texel, surface, xInBytes, y);
// Formatted stores: (Formatted surface stores are currently not exposed in CUDA runtime device functions)
// sust.p.2d.v4.b32
// (6) Release all resources
cudaDestroySurfaceObject(surfObj);
cudaFreeMipmappedArray(array);
對塊壓縮數據類型的支持
在所有圖形編程語言和框架中,用于減小紋理大小的最常見有損壓縮技術之一是使用塊壓縮( BC )紋理格式。使用這些格式可以顯著節省紋理的內存占用。有幾種 BC 格式,每種格式都有其獨特的優點和缺點,通常稱為 BCn 格式。
NVIDIA GPU 體系結構本機支持 BCn 格式,并且通過紋理資源視圖在 CUDA 中的支持有限。現在,我們在驅動程序和運行時 API 中引入新的 BC CUDA 數組格式。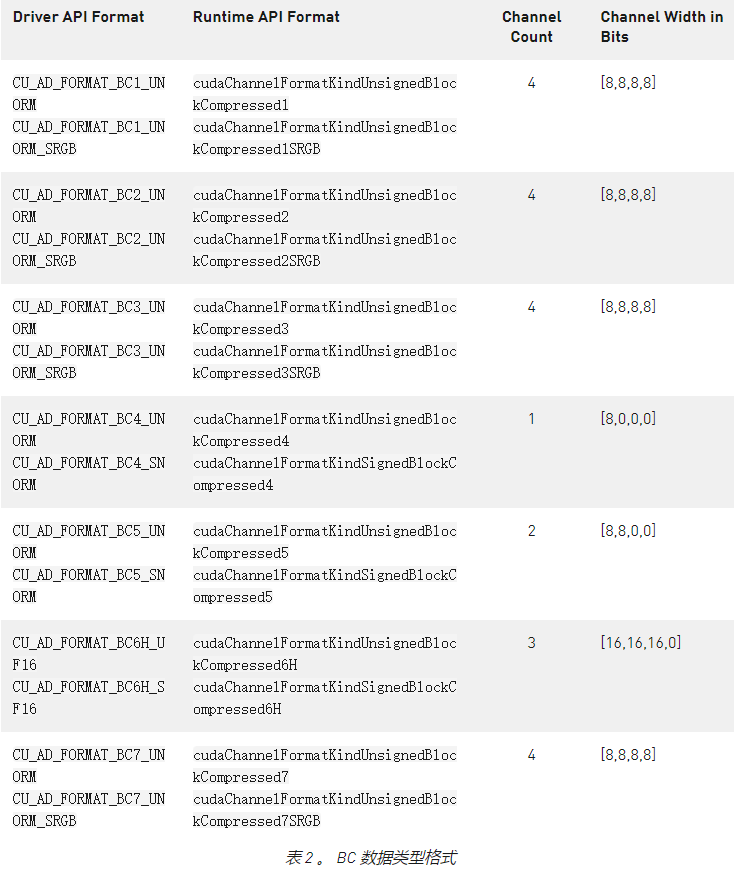
這些格式可用于使用cuArray[3D]Create運行時 API 或cuArray[3D]Create驅動程序 API 創建 BCn 格式的cuMipmappedArrayCreate數組。類似地,可以使用 CUDA 運行時 API 或cuMipmappedArrayCreate驅動程序 API 創建 CUDA mipmapped 數組。使用這些格式創建 CUDA 陣列時,陣列范圍必須是壓縮塊大小的倍數( 2D 為 4×4 , 3D 為 4x4x1 )。這些陣列還可用于創建紋理對象。
C ++中可配置的緩存提示
在在 CUDA 11 . 4 中發現新功能中,我們引入了一個 PTX ISA 擴展,為駐留在 GPU 上的數據向編譯器和運行時提供緩存提示。在 CUDA 11 . 5 中,我們將此能力擴展到帶有注釋指針的 C ++。它們充當普通指針,并應用附加屬性。
注釋指針是使用
cuda::access_property::normal (evict_normal_demote)
cuda::access_property::streaming (evict_first)
cuda::access_property::persisting (evict_last)
cuda::access_property::shared (shared memory)
cuda::access_property::global (evict_normal)
例如,在內核代碼中,聲明和使用帶注釋的指針可能類似于以下代碼:
static __device__
void my_kernel(int * in, int * out) {
cuda::access_property ap(cuda::access_property::persisting{});
// Retrieve global id
int i = blockIdx.x * blockDim.x + threadIdx.x;
cuda::annotated_ptr in_ann{in, ap};
cuda::annotated_ptr out_ann{out, ap};
...
}
MPS 增強功能(客戶端內存限制)
當 GPU 的計算能力超過任何單個應用程序時,運行共享同一 GPU 硬件的多個應用程序進程可能會很有吸引力。多進程服務( MPS )運行時體系結構控制多個獨立進程同時使用單個 GPU 。
但是,當多個獨立進程共享 GPU 時,設置總體內存分配限制通常很有用,以避免任何單個進程占用過多的可用 GPU 內存。
在 CUDA 11 . 5 中,我們引入了一組新的控制機制,使您能夠限制 MPS 客戶端進程的固定內存分配。您可以通過默認的全局限制層次結構控制內存分配。
默認全局限制
可以使用設備的set_default_device_pinned_mem_limit控制命令顯式啟用默認全局內存限制。設置此命令將在將來生成的所有 MPS 服務器的所有 MPS 客戶端上強制執行設備固定內存限制。
$nvidia-cuda-mps-control set_default_device_pinned_mem_limit 0 2G
每服務器限制:對于內存資源限制的細粒度控制,可以使用set_device_pinned_mem_limit控制命令在特定 MPS 服務器上選擇性地設置限制。設置此命令將在特定 MPS 服務器的所有 MPS 客戶端上強制執行設備固定內存限制。
$nvidia-cuda-mps-control set_device_pinned_mem_limit 1 1G
每個客戶限額:前面兩種控制機制為特定 MPS 服務器的所有 MPS 客戶端設置了一個總體限制。希望更好地控制資源限制的用戶;也就是說,在每個 MPS 客戶端的基礎上,可以通過為每個客戶端進程分別設置CUDA_MPS_PINNED_DEVICE_MEM_LIMIT環境變量來實現。
此環境變量與 CUDA \ u VISIBLE \ u 設備具有相同的語義。值字符串可以包含逗號分隔的設備序號和設備 UUID ,每個設備的內存限制由等號(=)分隔。
$export CUDA_MPS_PINNED_DEVICE_MEM_LIMIT="0=1G,1=2G,GPU-7ce23cd8-5c91-34a1-9e1b-28bd1419ce90=1024M"
WSL 驅動程序上的 CUDA
用于英特爾 x86 體系結構的 NVIDIA Windows GPU 驅動程序將支持 WSL2 ,并可在 Windows 11 的 Windows Insider Preview ( WIP )程序之外訪問。
CUDA Python
Python CUDA 為現有工具包和庫的驅動程序和運行時 API 提供Cython綁定和 Python 包裝,以簡化基于 GPU 的加速處理。 Python 是科學、工程、數據分析和深度學習應用程序中最流行的編程語言之一。 CUDA Python 的目標是將 Python 生態系統統一為一組接口,提供 Python 對 CUDA 主機 API 的全面覆蓋和訪問。
庫開發人員可以直接從 Python 使用 CUDA Python 與 CUDA 的低級接口。我們很高興地宣布,從 11 . 5 版開始, CUDA Python 已普遍提供,可以使用 PIP 或 Conda 安裝。 CUDA 支持的所有平臺都支持該庫。
其他增強功能
除了前面討論的關鍵功能外, CUDA 11 . 5 中還有一些增強功能,有助于改進基線功能和可用性。
多線程提交吞吐量
在 11 . 5 中,我們減少了 CPU 線程之間 CUDA API 的序列化開銷。默認情況下,將啟用這些更改。但是,為了幫助對潛在更改可能導致的問題進行分類,我們提供了一個環境變量CUDA_REDUCE_API_SERIALIZATION,以關閉這些更改。這是前面討論的基礎更改之一,有助于 CUDA 圖的性能改進。
NVIDIA 開普勒驅動器的棄用
NVIDIA 開普勒微體系結構于 2012 年首次引入,并已逐步淘汰。對于所有基于開普勒 NVIDIA 的 SKU ,我們已經從 R495 版本開始取消了對驅動程序的支持。但是, CUDA 工具包開發工具和對 NVIDIA 開普勒 SKU 的支持將在未來的 CUDA 11 . x 版本中繼續。
C ++語言對 CUDA 的支持
作為本版本的一部分,有一些 CUDA 11 . 5 支持的關鍵 C ++語言增強。
- CUDA C ++編譯器支持 NVRTC 和 PTX 中的并發編譯,以提高編譯時間。編譯器現在還可以檢測并消除未使用的 CUDA 內核,通過更好的代碼優化減少編譯時間、二進制大小和總體性能。
- 對 128 位整數值的有限支持作為用戶反饋的預覽功能發布,同時引入了 NVRTC 的靜態庫版本,并擴展了主機編譯器支持以包括 Clang 12 . 0 。
- CUDA C++編譯器具有我們在[VZX57 ]帖子中深入研究的特性。
- NVIDIA C ++標準庫( LIbCu +++) 1 . 5 . 0 被 CUDA 11 . 4 發布。
- 推力 1 . 12 . 0 具有新的推力::通用_矢量 API ,使您能夠使用推力的 CUDA 統一內存。
NSight 開發人員工具
NVIDIA NSight 開發工具: NSight System 2021 . 4 、 NSight Compute 2021 . 3 和 NSight Graphics 2021 . 4 . 2 現在提供了新版本,用于通過分析和調試 CUDA 代碼提高性能。
新發布的?NSight 系統 2021 . 4改進了對 Windows 、 Direct3D12 和 Vulkan 支持的評測。此版本添加了一些功能,以幫助更好地理解操作系統中斷時的進程執行,并添加了數據捕獲以識別數據包隊列瓶頸。特色包括:
- Windows ISR 和 DPC 跟蹤
- GPU 基于硬件的調度跟蹤
- Windows Direct3D12
- Vulkan 與 WDDM 事件的相關性
- NVTX 事件分類支持
- 多種系統環境的多報告加載
NSight Compute 2021 . 3 添加了一些功能,以幫助用戶了解其 CUDA 內核的性能。新的占用率計算器活動對 CUDA 內核的資源利用率進行建模,以便您可以交互式地調整模型參數,以查看它們如何影響占用率。屋頂折線圖現在支持分層脫機,它表示除設備內存之外的內存層次中的其他級別。您可以查看內核是否存在與緩存訪問請求相關的瓶頸。
還有其他改進,包括更多可配置的基線比較、從 CLI 查看源代碼級信息以及其他 SSH 功能。
 圖 1 。占用率計算器
圖 1 。占用率計算器最新的 NSight 圖形 2021 . 4 . 2 現在包括對 Windows 11 的支持。這意味著您現在可以使用downloadDirect3D 和 Vulkan 的 NVIDIA 圖形調試器和探查器,在最前沿的 Windows 版本上創建驚人的 3D 圖形。
關于作者
Rob Armstrong 是 CUDA 工具包的主要技術產品經理。 20 多年來,他一直專注于使用異構硬件平臺加速軟件,并對計算機體系結構和硬件/軟件交互特別感興趣。
Arthy Sundaram 是 CUDA 平臺的技術產品經理。她擁有哥倫比亞大學計算機科學碩士學位。她感興趣的領域是操作系統、編譯器和計算機體系結構。
Fred Oh 是 CUDA 、 CUDA on WSL 和 CUDA Python 的高級產品營銷經理。弗雷德擁有加州大學戴維斯分校計算機科學和數學學士學位。他的職業生涯開始于一名 UNIX 軟件工程師,負責將內核服務和設備驅動程序移植到 x86 體系結構。他喜歡《星球大戰》、《星際迷航》和 NBA 勇士隊。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102990 -
應用程序
+關注
關注
37文章
3265瀏覽量
57679 -
開發環境
+關注
關注
1文章
225瀏覽量
16610
發布評論請先 登錄
相關推薦
特斯拉發布“完全自動駕駛”軟件最新版本FSDV13.2
解析NVIDIA JetPack 6.1的新功能

淺談Xpedition 2409版本的新功能
品英Pickering最新版本的微波開關設計工具, 增強了仿真能力和原理圖設計功能

NVIDIA Parabricks v4.3.1版本的新功能
GUI Guider V1.8.0全新版本正式上線
單元測試工具TESSY 新版本亮點速覽:提供測試駕駛艙視圖、超級覆蓋率、代碼訪問分析、增強覆蓋率審查
谷歌DeepMind發布人工智能模型AlphaFold最新版本
CANoe新版本18正式發布

用的IAR For STM8最新版本3.10.2 ,編譯提示錯誤的原因?
請問最新版本的FOC SDK不支持ACIM電機嗎?
關于博達透傳工具新版本升級公告

STM32CubeMX安裝最新版本V6.9,Motor Control Workbench生成項目工程總是顯示STM32CubeMX not found的原因?
STMCWB最新版本是否支持絕對值編碼器?只能通過MCLIB庫手動增加嗎?
TSMaster 2024年1月最新版本,新功能太實用






 工商網監
工商網監
評論