 NVIDIA A100張量核心GPU的內部和新特性研究
NVIDIA A100張量核心GPU的內部和新特性研究
在 2020 年 NVIDIA GTC 主題演講中, NVIDIA 創始人兼 CEO 黃仁勛介紹了基于新 NVIDIA 安培 GPU 架構的新 NVIDIA A100 GPU 。這篇文章介紹了新的 A100 GPU 內部,并描述了 NVIDIA 安培架構 GPUs 的重要新特性。
現代云數據中心運行的計算密集型應用程序的多樣性推動了 NVIDIA GPU – 加速云計算的爆炸式發展。這些密集型應用包括 AI 深度學習( DL )培訓和推理、數據分析、科學計算、基因組學、邊緣視頻分析和 5G 服務、圖形渲染、云游戲等。從擴大人工智能培訓和科學計算,到擴展推理應用程序,再到實現實時對話人工智能, NVIDIA GPUs 提供了必要的馬力,以加速當今云數據中心中運行的大量復雜和不可預測的工作負載。
NVIDIA GPUs 是推動人工智能革命的領先計算引擎,為人工智能訓練和推理工作提供了巨大的加速。此外, NVIDIA GPUs 加速了許多類型的 HPC 和數據分析應用程序和系統,使您能夠有效地分析、可視化并將數據轉化為洞察力。 NVIDIA 加速計算平臺是世界上許多最重要和發展最快的行業的核心。
介紹了 NVIDIA A100 張量核 GPU
NVIDIA A100 張量核心 GPU 基于新的 NVIDIA 安培 GPU 架構,并建立在以前的 NVIDIA Tesla V100GPU 的能力之上。它添加了許多新功能,為 HPC 、 AI 和數據分析工作負載提供了顯著更快的性能。
A100 為在單臺和多臺 GPU 工作站、服務器、群集、云數據中心、邊緣系統和超級計算機上運行的 GPU 計算和 DL 應用程序提供了強大的擴展能力。 A100 GPU 能夠構建彈性、多功能和高吞吐量的數據中心。
A100 GPU 包括革命性的新 多實例 ( MIG )虛擬化和 GPU 分區功能,這對云服務提供商( csp )尤其有利。當配置為 MIG 操作時, A100 允許 CSP 提高其 GPU 服務器的利用率,在不增加額外成本的情況下,可提供最多 7 倍的 GPU 實例。強大的故障隔離使他們能夠安全可靠地劃分單個 A100 GPU 。
A100 增加了一個強大的新的第三代張量核心,在增加了對 DL 和 HPC 數據類型的全面支持的同時,增加了一個新的稀疏特性,使吞吐量進一步翻倍。
A100 中新的 TensorFloat-32 ( TF32 ) Tensor 核心操作為在 DL 框架和 HPC 中加速 FP32 輸入/輸出數據提供了一條簡單的途徑,比 V100 FP32 FMA 操作快 10 倍,在稀疏的情況下運行速度快 20 倍。對于 FP16 / FP32 混合精度 DL , A100 張量核心提供了 V100 的 2 。 5 倍性能,隨著稀疏性增加到 5 倍。
新的 Bfloat16 ( BF16 )/ FP32 混合精度張量核心操作以與 FP16 / FP32 混合精度相同的速率運行。 INT8 、 INT4 的張量核心加速和二進制舍入支持 DL 推斷, A100 稀疏 INT8 運行速度比 V100 INT8 快 20 倍。對于 HPC , A100 張量核心包括新的符合 IEEE 標準的 FP64 處理,其 FP64 性能是 V100 的 2 。 5 倍。
NVIDIA A100 GPU 的設計不僅可以加速大型復雜的工作負載,還可以有效地加速許多較小的工作負載。 A100 支持構建能夠滿足不可預測的工作負載需求的數據中心,同時提供細粒度的工作負載調配、更高的 GPU 利用率和改進的 TCO 。
NVIDIA A100 GPU 為 AI 訓練和推理工作負載提供了超過 V100 的超常加速,如圖 2 所示。類似地,圖 3 顯示了跨不同 HPC 應用程序的顯著性能改進。
主要特點
基于 TSMC 7nm N7 制造工藝制造的 NVIDIA 安培架構的 GA100 GPU 為 A100 供電,包括 542 億個晶體管,芯片尺寸為 826 平方毫米。
A100 GPU 多處理器流媒體
基于 NVIDIA 安培架構的 A100 張量核心 GPU 中的新型流式多處理器( SM )顯著提高了性能,建立在 Volta 和 Turing SM 架構中引入的功能的基礎上,并添加了許多新功能。
A100 第三代張量核心增強了操作數共享,提高了效率,并添加了強大的新數據類型,包括:
加速 FP32 數據處理的 TF32 張量核心指令
符合 IEEE 標準的 FP64 高性能計算機張量核心指令
BF16 張量核心指令的吞吐量與 FP16 相同
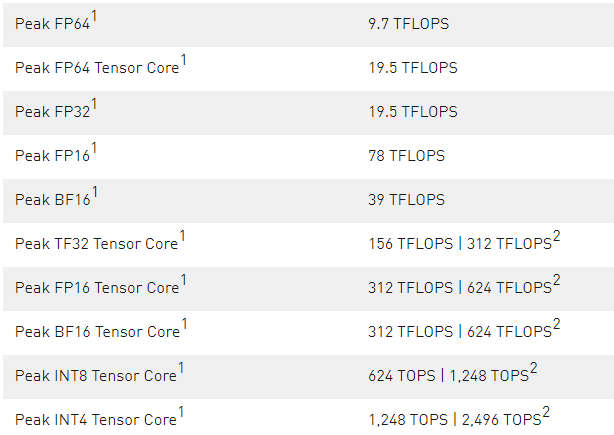
表 1 。 A100 張量芯 GPU 性能規格
1 ) 峰值速率基于 GPU 的升壓時鐘。
2 ) 使用新稀疏特性的有效 TFLOPS / TOPS 。
在 A100 張量核中新的稀疏性支持可以利用 DL 網絡中的細粒度結構稀疏性,將張量核操作的吞吐量提高一倍。稀疏特性將在本文后面的 A100 引入細粒結構稀疏性 部分詳細描述。
A100 中更大更快的一級緩存和共享內存單元提供了 1 。 5 倍于 V100 的總容量( 192 KB 對 128 KB / SM ),從而為許多 HPC 和 AI 工作負載提供額外的加速。
其他一些新的 SM 特性提高了效率和可編程性,并降低了軟件復雜性。
40 GB HBM2 和 40 MB 二級緩存
為了滿足其巨大的計算吞吐量, NVIDIA A100 GPU 擁有 40GB 的高速 HBM2 內存,內存帶寬為 1555GB / s ,與 Tesla V100 相比增加了 73% 。此外, A100 GPU 擁有更多的片上內存,包括 40 MB 的二級緩存( L2 ),比 V100 大近 7 倍,以最大限度地提高計算性能。 A100 二級緩存采用新的分區交叉結構,提供了 V100 2 。 3 倍的二級緩存讀取帶寬。
為了優化容量利用率, NVIDIA 安培體系結構提供二級緩存駐留控制,以管理要保留或從緩存中移出的數據。 A100 還增加了計算數據壓縮功能,使 DRAM 帶寬和 L2 帶寬提高了 4 倍, L2 容量提高了 2 倍。
多實例
新的多實例 GPU ( MIG )特性允許 A100 張量核心 GPU 安全地劃分為多達七個獨立的 GPU 實例,用于 CUDA 應用程序,為多個用戶提供單獨的 GPU 資源,以加速其應用程序。
在 MIG 中,每個實例的處理器在整個內存系統中都有獨立的獨立路徑。片上交叉條端口、二級緩存庫、內存控制器和 DRAM 地址總線都被唯一地分配給單個實例。這確保了單個用戶的工作負載可以在具有相同的二級緩存分配和 DRAM 帶寬的情況下以可預測的吞吐量和延遲運行,即使其他任務正在沖擊自己的緩存或使其 DRAM 接口飽和。
MIG 提高了 GPU 的硬件利用率,同時在不同的客戶機(如 vm 、容器和進程)之間提供了定義的 QoS 和隔離。 MIG 對于具有多租戶用例的 csp 尤其有利。它確保了一個客戶機不會影響其他客戶機的工作或日程安排,此外還為客戶機提供了增強的安全性和 GPU 利用率保證。
第三代 NVIDIA NVLink
在 A100 GPUs 中實現的第三代 NVIDIA 高速 NVLink 互連和新的 NVIDIA NVSwitch 顯著提高了多 GPU 的可擴展性、性能和可靠性。由于每個 GPU 和交換機有更多的鏈路,新的 NVLink 提供了更高的 GPU -GPU 通信帶寬,并改進了錯誤檢測和恢復功能。
第三代 NVLink 每對信號的數據傳輸速率為 50Gbit / s ,幾乎是 V100 中 25 。 78Gbits / sec 的兩倍。單個 A100 NVLink 在每個方向提供 25 GB /秒的帶寬,類似于 V100 ,但與 V100 相比,每個鏈路只使用一半的信號對。 A100 的鏈路總數增加到 12 個,而 V100 的總帶寬為 6 個,總帶寬為 600 GB /秒,而 V100 的總帶寬為 300 GB /秒。
支持 NVIDIA Magnum IO 和 Mellanox 互連解決方案
A100 Tensor Core GPU 與 NVIDIA Magnum IO 和 Mellanox 最先進的 InfiniBand 和以太網互連解決方案完全兼容,以加快多節點連接。
Magnum IO API 集成了計算、網絡、文件系統和存儲,以最大限度地提高多節點加速系統的 I / O 性能。它與 CUDA -X 庫接口,以加速從人工智能、數據分析到可視化等各種工作負載的 I / O 。
帶 SR-IOV 的 PCIe Gen 4
A100 GPU 支持 PCI Express Gen 4 ( PCIe Gen 4 ),通過為 x16 連接提供 31 。 5 GB /秒而不是 15 。 75 GB /秒,將 PCIe 3 。 0 / 3 。 1 的帶寬提高了一倍。更快的速度尤其有利于 A100 GPUs 連接到支持 PCIe 4 。 0 的 CPU 并支持快速網絡接口,如 200 Gbit / s InfiniBand 。
A100 還支持單根輸入/輸出虛擬化( SR-IOV ),允許為多個進程或虛擬機共享和虛擬化單個 PCIe 連接。
改進了錯誤和故障檢測、隔離和控制
通過檢測、包含并經常糾正錯誤和錯誤,而不是強制 GPU 重置來最大限度地提高 GPU 的正常運行時間和可用性是至關重要的。在大型多 GPU 集群和單 GPU 多租戶環境(如 MIG 配置)中尤其如此。 A100 張量核心 GPU 包括新技術,用于改進錯誤/故障屬性、隔離和控制,如本文后面深入的架構部分所述。
異步復制
A100 GPU 包含了一個新的異步復制指令,該指令將數據直接從全局內存加載到 SM 共享內存中,從而消除了使用中間寄存器文件( RF )的需要。異步復制減少了寄存器文件帶寬,更有效地使用內存帶寬,并減少了功耗。顧名思義,異步復制可以在 SM 執行其他計算時在后臺完成。
異步屏障
A100 GPU 在共享內存中提供了硬件加速屏障。這些屏障可用 CUDA 11 ,形式如下ISO C ++符合障礙物。異步屏障將屏障到達和等待操作分開可用于將全局內存中的異步副本與 SM 中的計算重疊到共享內存中。它們可用于使用 CUDA 線程實現生產者 – 消費者模型。屏障還提供機制來同步不同粒度的 CUDA 線程,而不僅僅是扭曲或塊級別。
任務圖加速
CUDA 任務圖為向 GPU 提交工作提供了一個更有效的模型。任務圖由一系列操作組成,如內存復制和內核啟動,這些操作通過依賴關系連接起來。任務圖支持定義一次并重復運行的執行流。預定義的任務圖允許在單個操作中啟動任意數量的內核,極大地提高了應用程序的效率和性能。 A100 添加了新的硬件功能,使任務圖中網格之間的路徑明顯更快。
A100 GPU 硬件架構
NVIDIA GA100 GPU 由多個 GPU 處理簇( GPC )、紋理處理簇( TPC )、流式多處理器( SMs )和 HBM2 內存控制器組成。
GA100 GPU 的全面實施包括以下單元:
8 個 GPC , 8 個 TPC / GPC , 2 個 SMs / TPC , 16 個 SMs / GPC ,每滿 128 個 SMsGPU
64 個 FP32 CUDA 核/ SM ,每滿 GPU 個 8192 個 FP32 CUDA 個核
4 個第三代張量核心/ SM ,每滿 512 個第三代張量核心 GPU
6 個 HBM2 堆棧, 12 個 512 位內存控制器
GA100 GPU 的 A100 張量核 GPU 實現 包括以下單元:
7 個 GPC , 7 或 8 個 TPC / GPC , 2 個 SMs / TPC ,最多 16 個 SMs / GPC , 108 個 SMs
64 個 FP32 CUDA 芯/ SM ,每個 GPU 個 6912 個 FP32 CUDA 個芯
4 個第三代張量核心/ SM ,每個 GPU 432 個第三代張量核心
5 個 HBM2 堆棧, 10 個 512 位內存控制器
A100 SM 建筑
新的 A100 SM 顯著提高了性能,建立在 Volta 和 Turing SM 架構中引入的特性之上,并添加了許多新功能和增強功能。
A100 SM 圖如圖 5 所示。 Volta 和 Turing 每個 SM 有 8 個張量核心,每個張量核心每個時鐘執行 64 個 FP16 / FP32 混合精度融合乘法加法( FMA )操作。 A100 SM 包括新的第三代張量核心,每個時鐘執行 256 個 FP16 / FP32 FMA 操作。 A100 每平方米有四個張量核心,總共每時鐘提供 1024 個密集的 FP16 / FP32 FMA 操作,與 Volta 和 Turing 相比,每平方米的計算馬力增加了 2 倍。
這里將簡要介紹 SM 的主要功能,并在本文后面詳細介紹:
第三代張量核心:
所有數據類型的加速,包括 FP16 、 BF16 、 TF32 、 FP64 、 INT8 、 INT4 和 Binary 。
新的張量核心稀疏特性利用了深度學習網絡中的細粒度結構稀疏性,使標準張量核心操作的性能提高了一倍。
A100 中的 TF32 Tensor 核心操作為 DL 框架和 HPC 中的 FP32 輸入/輸出數據提供了一條簡單的途徑,比 V100 FP32 FMA 操作快 10 倍,在 sparity 中運行速度快 20 倍。
FP16 / FP32 混合精密張量核心操作為 DL 提供了前所未有的處理能力,比 V100 張量核心操作運行速度快 2 。 5 倍,且稀疏性增加到 5x 。
BF16 / FP32 混合精度張量核心運算的運行速度與 FP16 / FP32 混合精度相同。
FP64 張量核心操作為 HPC 提供了前所未有的雙精度處理能力,運行速度比 V100 FP64 DFMA 操作快 2 。 5 倍。
具有稀疏性的 INT8 張量核心操作為 DL 推理提供了前所未有的處理能力,運行速度比 V100 INT8 操作快 20 倍。
192 KB 的共享內存和一級數據緩存,比 V100 SM 大 1 。 5 倍。
新的異步復制指令將數據直接從全局內存加載到共享內存中,可以選擇繞過一級緩存,并且不需要使用中間寄存器文件( RF )。
基于共享內存的新型屏障單元(異步的barriers )用于新的異步復制指令。
L2 緩存管理和駐留控制的新說明。
CUDA 合作組支持的新的扭曲級縮減指令。
許多可編程性改進以降低軟件復雜性。
圖 6 比較了 V100 和 A100 FP16 張量核心操作,還比較了 V100 FP32 、 FP64 和 INT8 標準操作與各自的 A100 TF32 、 FP64 和 INT8 張量核心操作。吞吐量是根據 GPU 聚合的,其中 A100 對 FP16 、 TF32 和 INT8 使用稀疏張量核心操作。左上角的圖表顯示了兩個 V100 FP16 張量核心,因為 V100 SM 每個 SM 分區有兩個張量核心,而 A100 SM 則有兩個張量核心。
圖 6 。 A100 張量核心操作與 V100 張量核心操作以及不同數據類型的標準操作進行比較。
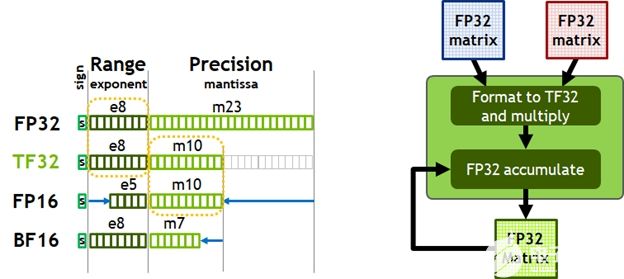
圖 7 。 TensorFloat-32 ( TF32 )提供 FP32 的范圍,精度為 FP16 (左)。支持 tfa032 格式的自動輸入和輸出。
今天,人工智能訓練的默認數學是 FP32 ,沒有張量核心加速度。 NVIDIA Ampere 架構引入了對 TF32 的新支持,使 AI 訓練能夠在默認情況下使用張量核心,而不需要用戶的努力。非張量運算繼續使用 FP32 數據路徑,而 TF32 張量核心讀取 FP32 數據并使用與 FP32 相同的范圍,內部精度降低,然后生成標準 IEEE FP32 輸出。 TF32 包括一個 8 位指數(與 FP32 相同)、 10 位尾數(精度與 FP16 相同)和 1 個符號位。
與 Volta 一樣,自動混合精度( AMP )允許您使用混合精度與 FP16 進行 AI 訓練,只需幾行代碼更改。使用 AMP , A100 的張量核心性能比 TF32 快 2 倍。
綜上所述,用于 DL 培訓的 NVIDIA 安培架構數學的用戶選擇如下:
默認情況下,使用 TF32 張量核心,不需要調整用戶腳本。與 A100 上的 FP32 相比,吞吐量提高了 8 倍,與 V100 上的 FP32 相比,吞吐量提高了 10 倍。
應采用 FP16 或 BF16 混合精度訓練,以獲得最大訓練速度。與 TF32 相比,吞吐量提高了 2 倍,與 A100 上的 FP32 相比提高了 16 倍,與 V100 上的 FP32 相比提高了 20 倍。
A100 張量核加速高性能混凝土
高性能計算機應用的性能需求正在迅速增長。許多科學和研究學科的應用都依賴于雙精度( FP64 )計算。
為了滿足 HPC 計算快速增長的計算需求, A100 GPU 支持張量運算,加速符合 IEEE 標準的 FP64 計算,其 FP64 性能是 NVIDIA Tesla V100GPU 的 2 。 5 倍。
A100 上新的雙精度矩陣乘法加法指令取代了 V100 上的 8 條 DFMA 指令,減少了指令獲取、調度開銷、寄存器讀取、數據路徑功耗和共享內存讀取帶寬。
A100 中的每個 SM 計算 64 個 FP64 FMA 操作/時鐘(或 128 個 FP64 操作/時鐘),這是 Tesla V100 吞吐量的兩倍。 A100 Tensor Core GPU 具有 108 條短信息,可提供 19 。 5 TFLOPS 的峰值 FP64 吞吐量,是 Tesla V100 的 2 。 5 倍。
隨著對這些新格式的支持, A100 張量核心可以用于加速 HPC 工作負載、迭代求解器和各種新的 AI 算法。
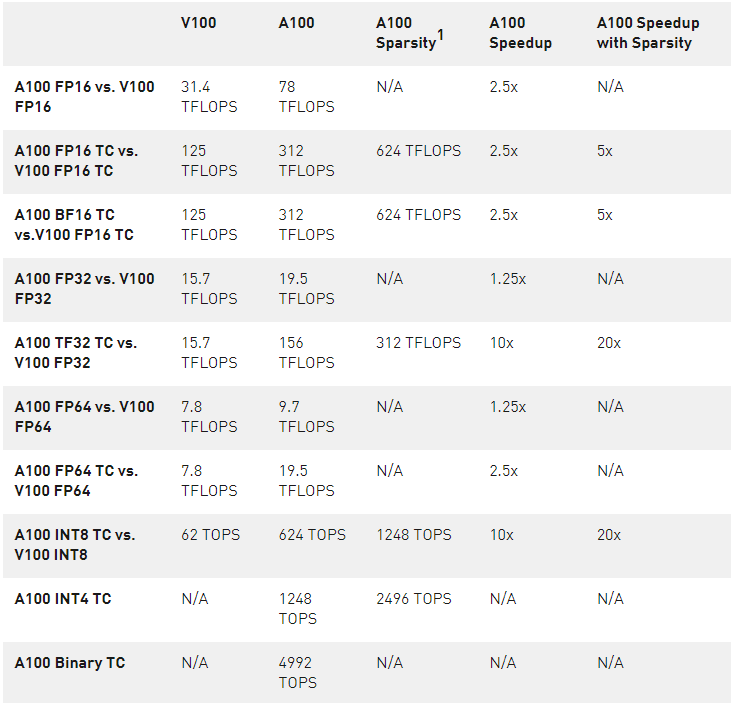
表 2 。 A100 加速超過 V100 ( TC =張量核心, GPUs 在各自的時鐘速度)。
1 ) 使用新稀疏性特征的有效 TOPS / TFLOPS
A100 引入細粒結構稀疏性
在 A100 GPU 中, NVIDIA 引入了細粒度結構稀疏性,這是一種新的方法,可以使深層神經網絡的計算吞吐量翻倍。
在深度學習中,稀疏性是可能的,因為個體權重的重要性在學習過程中不斷演化,到網絡訓練結束時,只有一部分權值在確定學習輸出時有意義。剩下的重量不再需要了。
細粒度的結構化稀疏性對允許的稀疏模式施加了一個約束,使硬件能夠更有效地對輸入操作數進行必要的對齊。由于深度學習網絡能夠在基于訓練反饋的訓練過程中自適應權值, NVIDIA 工程師發現,一般來說,結構約束不會影響訓練網絡的推理精度。這使得可以推斷稀疏加速度。
對于訓練加速,需要在訓練過程的早期引入稀疏性以提供性能上的好處,而在不損失精度的情況下加速訓練是一個活躍的研究領域。
稀疏矩陣定義
結構是通過一個新的 2 : 4 稀疏矩陣定義來實現的,該定義允許每四個輸入向量中有兩個非零值。 A100 支持行上的 2 : 4 結構化稀疏性,如圖 9 所示。
由于矩陣的明確結構,它可以被有效地壓縮,并減少近 2 倍的內存存儲和帶寬。
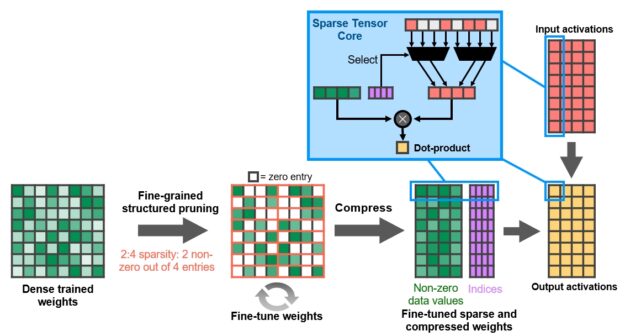
圖 9 。 A100 細粒度結構化稀疏度使用 4 取 2 的非零模式對訓練的權重進行修剪,然后使用一個簡單而通用的方法對非零權重進行微調。權重被壓縮,數據占用空間和帶寬減少了 2 倍, A100 稀疏張量核心通過跳過零將數學吞吐量翻倍。
NVIDIA 已經開發出一種簡單而通用的方法來分離深層神經網絡進行推理使用這種 2 : 4 結構稀疏模式。 首先使用密集權值訓練網絡,然后應用細粒度結構剪枝,最后通過附加的訓練步驟對剩余的非零權值進行微調。這種方法在基于視覺、目標檢測、分割、自然語言建模和翻譯等數十個網絡的評估的基礎上,幾乎沒有損失推理精度。
A100 Tensor Core GPU 包含新的稀疏張量核心指令,這些指令跳過對零值的條目的計算,從而使張量核心計算吞吐量翻倍。圖 9 顯示了張量核心如何使用壓縮元數據(非零索引)將壓縮后的權重與適當選擇的用于輸入到張量核心點積計算的激活匹配。
組合一級數據緩存和共享內存
NVIDIA Tesla V100 首次引入, NVIDIA 結合了一級數據緩存和共享內存子系統架構,顯著提高了性能,同時還簡化了編程,減少了達到或接近峰值應用程序性能所需的調整。將數據緩存和共享內存功能組合到單個內存塊中,可以為兩種類型的內存訪問提供最佳的總體性能。
一級數據緩存和共享內存的組合容量在 A100 中為 192 KB / SM ,而在 V100 中為 128 KB / SM 。
同時執行 FP32 和 INT32 操作
與 V100 和圖靈 GPUs 類似, A100 SM 還包括獨立的 FP32 和 INT32 核,允許在全吞吐量的情況下同時執行 FP32 和 INT32 操作,同時也增加指令發出吞吐量。
許多應用程序都有內部循環,執行指針算術(整數內存地址計算)與浮點計算相結合,這有利于 FP32 和 INT32 指令的同時執行。下一次迭代( intfp32 )可以同時更新當前循環中的每一個循環的指針。
A100 HBM2 DRAM 子系統
隨著 HPC 、 AI 和 analytics 數據集的不斷增長,以及尋找解決方案的問題變得越來越復雜,需要更多的 GPU 內存容量和更高的內存帶寬。
Tesla P100 是世界上第一個支持高帶寬 HBM2 內存技術的 GPU 體系結構,而 Tesla V100 提供了更快、更高效、更高容量的 HBM2 實現。 A100 再次提高了 HBM2 性能和容量的標準。
HBM2 內存由位于與 GPU 相同的物理包上的內存堆棧組成,與傳統的 GDDR5 / 6 內存設計相比,提供了大量的功耗和面積節省,允許在系統中安裝更多的 GPUs 。有關 HBM2 技術基本細節的更多信息,請參閱 NVIDIA Tesla P100 :有史以來最先進的數據中心加速器 白皮書。
A100 GPU 在其 SXM4 風格的電路板上包括 40 GB 的快速 HBM2 DRAM 內存。內存被組織成五個活動的 HBM2 堆棧,每個堆棧有八個內存片。 A100 HBM2 的數據速率為 1215 MHz ( DDR ),可提供 1555 GB /秒的內存帶寬,比 V100 內存帶寬高出 1 。 7 倍多。
ECC 內存彈性
A100 HBM2 存儲子系統支持單糾錯雙錯誤檢測( SECDED )糾錯碼( ECC )來保護數據。 ECC 為對數據損壞敏感的計算應用程序提供了更高的可靠性。在大型集群計算環境中,這一點尤為重要, GPUs 處理大型數據集或長時間運行應用程序。 A100 中的其他密鑰存儲結構也受 SECDED ECC 的保護,包括二級緩存和一級緩存以及所有 SMs 中的寄存器文件。
A100 二級緩存
A100 GPU 包含 40 MB 二級緩存,比 V100 L2 大 6 。 7 倍緩存。那個二級緩存分為兩個分區,以實現更高的帶寬和更低的延遲內存訪問。每個二級分區在直接連接到分區的 gpc 中為 SMs 訪問內存而本地化和緩存數據。這種結構使 A100 比 V100 的 L2 帶寬增加了 2 。 3 倍。硬件緩存一致性在整個 GPU 中維護 CUDA 編程模型,應用程序自動利用新的二級緩存的帶寬和延遲優勢。
二級緩存是 gpc 和 SMs 的共享資源,位于 gpc 之外。 A100 L2 緩存大小的大幅增加顯著提高了許多 HPC 和 AI 工作負載的性能,因為現在可以以比讀取和寫入 HBM2 內存更高的速度緩存和重復訪問更多的數據集和模型。一些受 DRAM 帶寬限制的工作負載將受益于更大的二級緩存,例如使用小批量的深度神經網絡。
為了優化容量利用率, NVIDIA 安培體系結構提供二級緩存駐留控制,以管理要保留或從緩存中移出的數據。您可以留出一部分二級緩存用于持久數據訪問。
例如,對于 DL 推斷工作負載,可以在 L2 中持久地緩存 ping-pong 緩沖區,以加快數據訪問速度,同時避免對 DRAM 的寫回。對于生產者 – 消費者鏈,如在 DL 培訓中發現的那些,二級緩存控件可以跨讀寫數據依賴關系優化緩存。在 LSTM 網絡中,遞歸權值可以優先緩存并在 L2 中重用。
NVIDIA Ampere 架構增加了計算數據壓縮,以加速非結構化稀疏性和其他可壓縮數據模式。二級壓縮使 DRAM 讀/寫帶寬提高了 4 倍,二級讀取帶寬提高了 4 倍,二級容量提高了 2 倍。
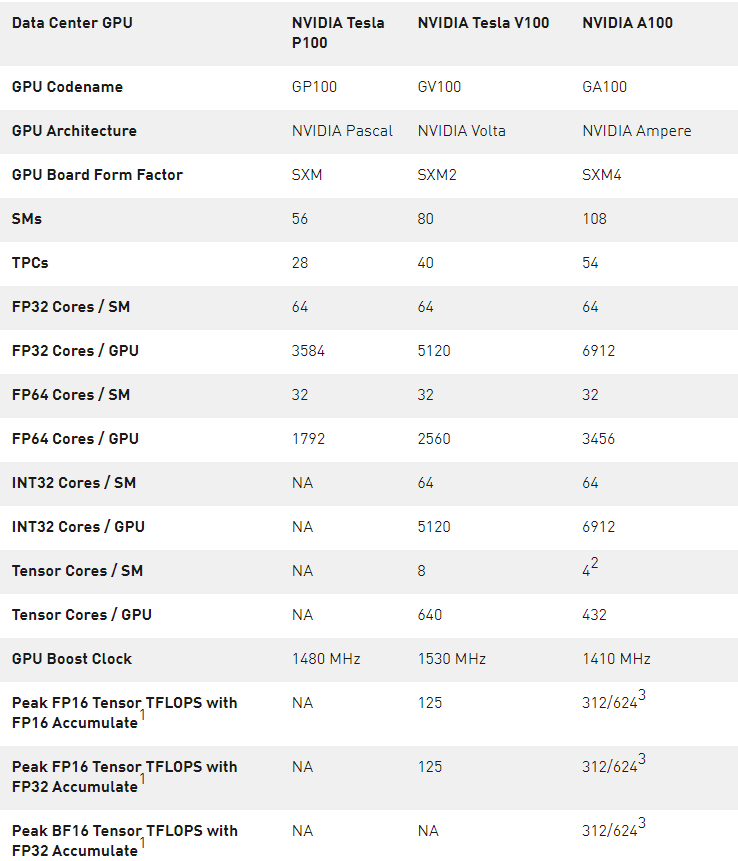
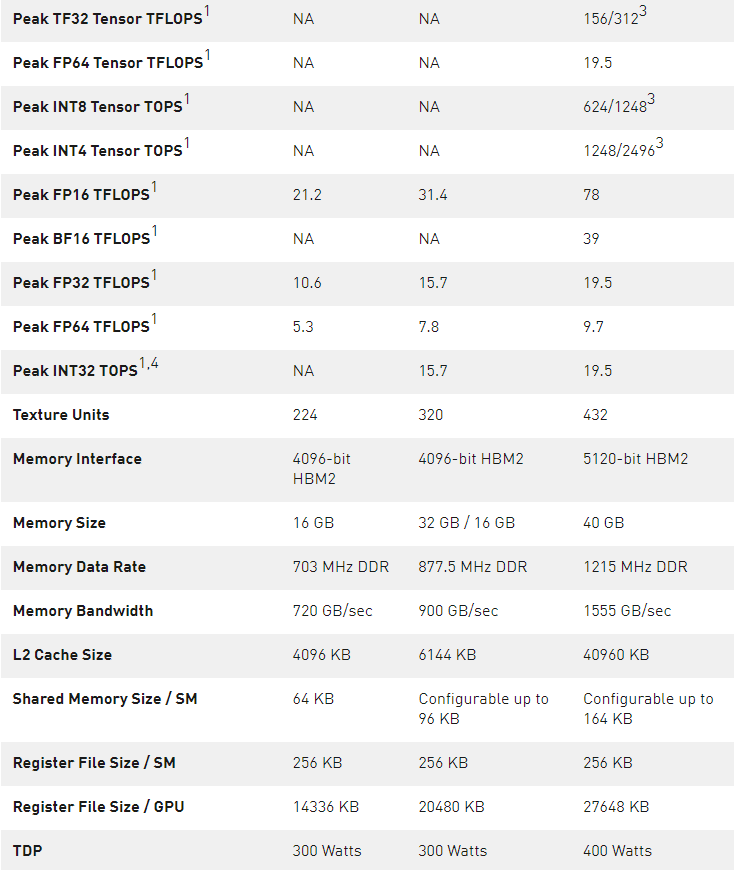
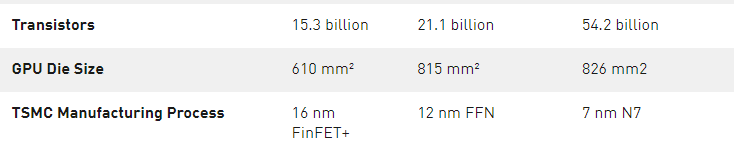
表 3 。 NVIDIA 數據中心 GPUs 比較。
1 ) 峰值速率基于 GPU 的升壓時鐘。
2 ) A100 SM 中的四個張量核心的原始 FMA 計算能力是 GV100 SM 中八個張量核心的 2 倍。
3 ) 使用新的稀疏特性的有效頂部/ TFLOPS 。
4 ) TOPS =基于 IMAD 的整數數學
注: 因為 A100 張量核心 GPU 設計安裝在高性能服務器和數據中心機架上,為 AI 和 HPC 計算工作負載供電,因此它不包括用于光線跟蹤加速的顯示連接器、 NVIDIA RT 核心或 NVENC 編碼器。
計算能力
支持新的計算能力 GPU 。表 4 比較了 NVIDIA GPU 體系結構的不同計算能力的參數。
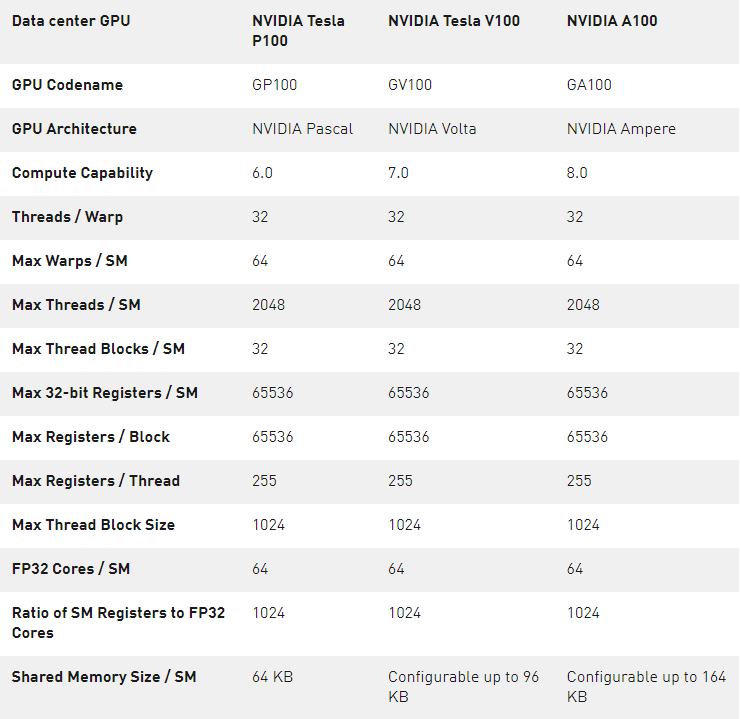
表 4 。計算能力: GP100 vs 。 GV100 vs 。 GA100 。
MIG 體系結構
盡管許多數據中心的工作負載在規模和復雜性上都在不斷擴展,但有些加速任務的要求并不高,例如早期開發或在低批量規模下對簡單模型進行推理。數據中心管理者的目標是保持高資源利用率,因此理想的數據中心加速器不只是變大,它還可以有效地加速許多較小的工作負載。
新的 MIG 特性可以將每個 A100 劃分為多達 7 個 GPU 實例以實現最佳利用率,有效地擴展了對每個用戶和應用程序的訪問。
圖 10 顯示了 Volta MPS 如何允許多個應用程序同時在不同的 GPU 執行資源( SMs )上執行。但是,由于內存系統資源是在所有應用程序之間共享的,因此,如果一個應用程序對 DRAM 帶寬有很高的要求或其請求在二級緩存中超額訂閱,則可能會干擾其他應用程序。
圖 11 中顯示的 A100 [……]訴訟。 新 MIG 功能可以將單個 GPU 劃分為多個名為 GPU 的 GPU 分區每個實例的 SMs 在整個內存系統中都有獨立的獨立路徑——片上交叉條端口、二級緩存庫、內存控制器和 DRAM 地址總線都是唯一分配給單個實例的。這確保了單個用戶的工作負載可以在具有相同的二級緩存分配和 DRAM 帶寬的情況下以可預測的吞吐量和延遲運行,即使其他任務正在沖擊自己的緩存或使其 DRAM 接口飽和。
利用這種能力,MIG 可以對可用的 GPU 計算資源進行分區,以提供定義的服務質量(QoS ),為不同的客戶機(如 VM 、容器、進程等)提供故障隔離。它允許多個 GPU 實例在單個物理 A100 GPU 上并行運行。 MIG 還保持 CUDA 編程模型不變,以最小化編程工作量。
CSP 可以使用 MIG 來提高其 GPU 服務器的利用率,在不增加成本的情況下提供最多 7 倍的 GPU 實例。 MIG 支持 csp 所需的必要的 QoS 和隔離保證,以確保一個客戶端( VM 、容器、進程)不會影響來自另一個客戶端的工作或調度。
CSP 通常根據客戶使用模式對其硬件進行分區。只有當硬件資源在運行時提供一致的帶寬、適當的隔離和良好的性能時,有效的分區才有效。
使用基于 NVIDIA Ampere 架構的 GPU ,您可以看到和調度新的虛擬 GPU 實例上的作業,就像它們是物理的 GPUs 。 MIG 與 Linux 操作系統及其管理程序一起工作。用戶可以使用諸如 Docker Engine 之類的運行時來運行帶有 MIG 的容器,并且很快就會支持使用 Kubernetes 的容器編排。
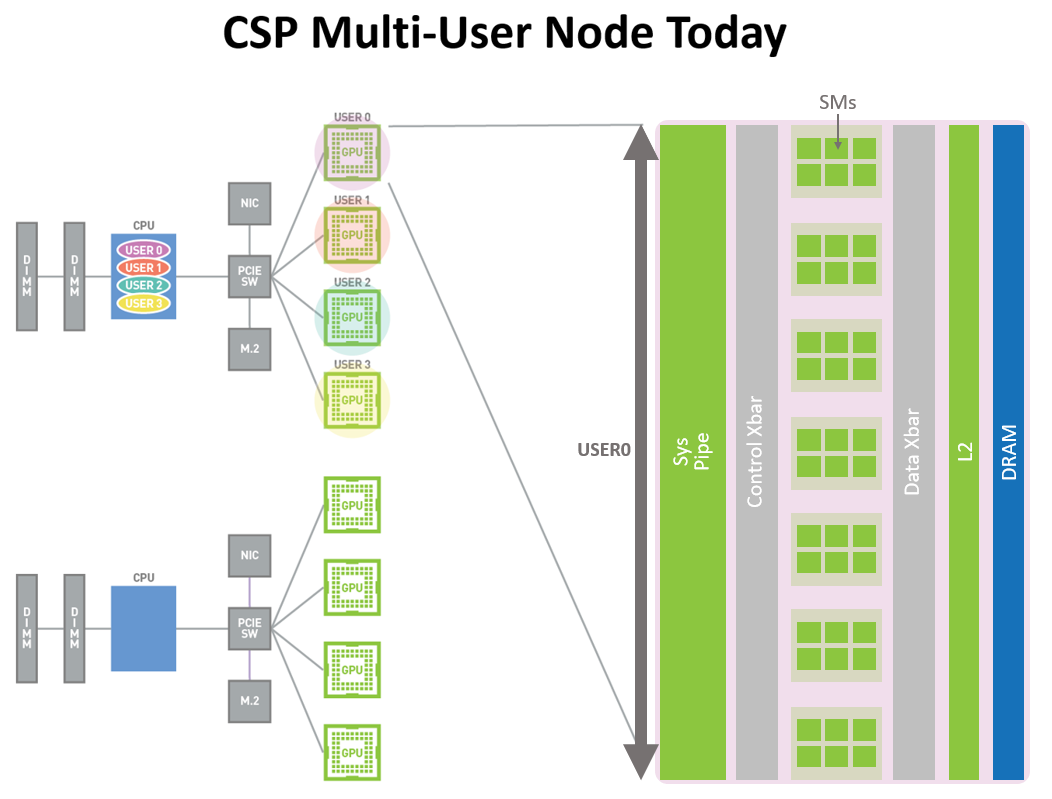
圖 10 。今天的 CSP 多用戶節點( A100 之前)。加速的 GPU 實例只能在完全物理 GPU 粒度下用于不同組織的用戶,即使用戶應用程序不需要完整的 GPU 。
錯誤和故障檢測、隔離和控制
通過檢測、包含并經常糾正錯誤和錯誤,而不是強制 GPU 重置來提高 GPU 的正常運行時間和可用性是至關重要的。這在大型多 GPU 集群和單 GPU 多租戶環境(如 MIG 配置)中尤其重要。
NVIDIA 安培架構 A100 GPU 包括改進錯誤/故障屬性的新技術(將導致錯誤的應用程序歸為屬性)、隔離(隔離故障應用程序,使其不會影響運行在同一 GPU 或 GPU 集群中的其他應用程序),和控制(確保一個應用程序中的錯誤不會泄漏并影響其他應用程序)。這些故障處理技術對于 MIG 環境尤其重要,以確保共享單個 GPU 的客戶端之間的適當隔離和安全性。
NVLink connected GPUs 現在具有更強大的錯誤檢測和恢復功能。遠程 GPU 的頁面錯誤通過 NVLink 發送回源 GPU 。遠程訪問故障通信對于大型 GPU 計算集群來說是一個關鍵的彈性特性,可以幫助確保一個進程或虛擬機中的故障不會導致其他進程或虛擬機停機。
A100 GPU 還包括其他幾個新的和改進的硬件功能,可以提高應用程序的性能。有關更多信息,請參閱即將發布的 NVIDIA A100 張量核 GPU 體系結構 白皮書。
CUDA 11NVIDIA 安培結構 GPUs 的進步
數以千計的 GPU 加速應用程序構建在 NVIDIA CUDA 并行計算平臺上。 CUDA 的靈活性和可編程性使其成為研究和部署新的 DL 和并行計算算法的首選平臺。
NVIDIA 安培架構 GPUs 旨在提高 GPU 的可編程性和性能,同時降低軟件復雜性。 NVIDIA 安培架構 GPUs 和 CUDA 編程模型的進步加快了程序執行,并降低了許多操作的延遲和開銷。
新的 CUDA 11 特性為第三代張量核心、稀疏性、 CUDA 圖、多實例 GPUs 、二級緩存駐留控制以及 NVIDIA 安培架構的其他一些新功能提供編程和 API 支持。
有關 CUDA 新特性的更多信息,請參閱即將發布的 NVIDIA A100 張量核 GPU 體系結構 白皮書。有關新 DGX A100 系統的詳細信息,請參見 用 NVIDIA DGX A100 定義人工智能創新 。有關開發人員專區的更多信息,請參閱 NVIDIA 開發者 ,有關 CUDA 的更多信息,請參閱新的 CUDA 編程指南 。
結論
NVIDIA 的任務是加速我們這個時代的達芬奇和愛因斯坦的工作。科學家、研究人員和工程師致力于利用高性能計算( HPC )和人工智能解決世界上最重要的科學、工業和大數據挑戰。
NVIDIA A100 Tensor Core GPU 在我們的加速數據中心平臺上實現了下一個巨大的飛躍,在各個規模上都提供了無與倫比的加速度,使這些創新者能夠在有生之年完成一生的工作。 A100 支持許多應用領域,包括 HPC 、基因組學、 5G 、渲染、深度學習、數據分析、數據科學和機器人技術。
今天,推進最重要的 HPC 和 AI 應用程序個性化醫療、會話式人工智能和深度推薦系統需要研究人員大刀闊斧。 A100 為 NVIDIA 數據中心平臺提供動力,該平臺包括 MellanoxHDR InfiniBand 、 NVSwitch 、 NVIDIA HGX A100 和用于擴展的 Magnum IO SDK 。這個集成的技術團隊有效地擴展到數萬個 GPUs ,以前所未有的速度訓練最復雜的人工智能網絡。
A100 GPU 的新 MIG 功能可以將每個 A100 劃分為多達七個 GPU 加速器以實現最佳利用率,有效提高了 GPU 資源利用率和 GPU 訪問更多用戶和 GPU 加速應用程序。憑借 A100 的多功能性,基礎設施經理可以最大限度地利用其數據中心中的每個 GPU ,以滿足不同規模的性能需求,從最小的作業到最大的多節點工作負載。
關于作者
Ronny Krashinsky 設計 NVIDIA GPU 已有 10 年。他開始了他的 NVIDIA 研究生涯,后來加入了流式多處理器團隊,設計了 voltasm 。羅尼是 100 個深度學習特性的首席架構師,他現在管理著 NVIDIA 的深度學習架構路線圖。
Olivier Giroux 已經完成了十個 GPU 和六個由 NVIDIA 發布的 SM 體系結構。他是一位杰出的建筑師,專注于 GPU 程序語義,并主持 ISOC C ++子群的并發和并行。
Stephen Jones 是 CUDA 的架構師之一,他致力于定義語言、平臺和運行它的硬件,以滿足從高性能計算到人工智能的并行編程需求。在任職之前,他領導著 SpaceX 公司的模擬與分析小組,致力于火箭發動機的大規模模擬。他曾在其他不同的行業工作過,包括網絡、 CAD / CAM 和科學計算。自 2008 年以來,他一直是 CUDA 的一員。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4990瀏覽量
103106 -
gpu
+關注
關注
28文章
4742瀏覽量
128969 -
人工智能
+關注
關注
1791文章
47314瀏覽量
238625
發布評論請先 登錄
相關推薦
英偉達a100和h100哪個強?英偉達A100和H100的區別
強核問世:NVIDIA發布全球最強GPU——A100 80GB GPU
NVIDIA A100,中國頂級云服務提供商和系統制造商的上佳之選
NVIDIA發布了首款基于NVIDIA Ampere架構的GPU ——NVIDIA A100 GPU
英偉達最新的NVIDIA DGX A100被命名為通用的AI集成架構系統
英偉達 A100 GPU 全面上市,推理性能比 CPU 快 237 倍
NVIDIA推出A100 80GB GPU,助力實現新一輪AI和科學技術突破
NVIDIA推出了基于A100的DGX A100
NVIDIA發布A100 80GB加速卡
Microsoft Azure推出VIDIA A100 GPU VM系列
英偉達a100和h100哪個強?
英偉達A100和A40的對比
英偉達A100的簡介
英偉達h800和a100的區別





 工商網監
工商網監
評論