") 經(jīng)典圖像分類算法AlexNet介紹
經(jīng)典圖像分類算法AlexNet介紹
本期開小灶Heyro將帶領大家進入下一趟旅程——基于卷積神經(jīng)網(wǎng)絡的圖像分類算法講解,從而幫助大家了解在卷積神經(jīng)網(wǎng)絡結構下衍生出的被用于圖像分類的經(jīng)典算法。
在了解圖像分類算法以前,我們先來了解“何為圖像分類”。
圖像分類的核心是從給定的分類集合中給圖像分配一個標簽的任務。簡言之,我們需要對一個輸入圖像進行分析后返回一個對應的分類標簽,標簽來自預先定義的可能類別集。圖像分類的任務即為正確給出輸入圖像的類別或輸出不同類別的概率。例如,我們先假設一個含有可能類別的類別集:
Categories = {cat, dog, fox}
然后,我們向分類系統(tǒng)提供一張狐貍犬的圖片。
經(jīng)過分類系統(tǒng)的處理,最終輸出可以是單一標簽dog,也可以是基于概率的多個標簽,例如cat:1%, dog:94%,fox:5% 。
計算機并不能像人類一樣快速通過視覺系統(tǒng)識別出圖像信息的語義。對于計算機而言,RGB圖像是由一個個像素數(shù)值構成的高維矩陣(張量)。計算機識別圖像的任務即尋找一個函數(shù)關系,該函數(shù)可將高維矩陣信息映射到一個具體的類別標簽中。利用計算機實現(xiàn)圖像分類目的過程隨即衍生出圖像分類算法。
圖像分類算法的起源——神經(jīng)認知機
傳統(tǒng)的圖像識別模型一般包括:底層特征學習>特征編碼>空間約束>分類器設計>模型融合等幾個流程。
2012年Alex Krizhevsky提出的CNN(卷積神經(jīng)網(wǎng)絡)模型在ImageNet大規(guī)模視覺識別比賽(ILSVRC)中脫穎而出,其效果大大超越了傳統(tǒng)的圖像識別方法,該模型被稱為AlexNet。
基于卷積神經(jīng)網(wǎng)絡的圖像分類算法起源最早可追溯到日本學者福島邦彥提出的neocognition(神經(jīng)認知機)神經(jīng)網(wǎng)絡模型。
福島邦彥于1978年至1984年研制了用于手寫字母識別的多層自組織神經(jīng)網(wǎng)絡——認知機。福島邦彥在認知機中引入了最大值檢出等概念。簡言之,當網(wǎng)格中某種神經(jīng)元損壞時,該神經(jīng)元立即可由其他神經(jīng)元來代替。由此一來,認知機就具有較好的容錯能力。
但是,認知機的網(wǎng)絡較為復雜,它對輸入的大小變換及平移、旋轉等變化并不敏感。雖然它能夠識別復雜的文字,但卻需要大量的處理單元和連接,這使得其硬件實現(xiàn)較為困難。
而福島邦彥在1980年提出的“神經(jīng)認知機”神經(jīng)網(wǎng)絡模型卻能夠很好地應對以上問題。
該模型借鑒了生物的視覺神經(jīng)系統(tǒng)。它對模式信號的識別優(yōu)于認知機。無論輸入信號發(fā)生變換、失真,抑或被改變大小等,神經(jīng)認知機都能對輸入信號進行處理。但是,該模型被提出后一直未受到較大關注,直至AlexNet在ILSVRC中大獲全勝,卷積神經(jīng)網(wǎng)絡的潛力才為業(yè)界所認知。
深度學習算法
自AlexNet之后,深度學習的發(fā)展極為迅速,網(wǎng)絡深度也在不斷地快速增長,隨后出現(xiàn)了VGG(19層)、GoogleNet(22層)、ResNet(152層),以及SENet(252層)等深度學習算法。
隨著模型深度和結構設計的發(fā)展,ImageNet分類的Top-5錯誤率也越來越低。在ImageNet上1000種物體的分類中,ResNet的Top-5錯誤率僅為3.57%。在同樣的數(shù)據(jù)集上,人眼的識別錯誤率約為5.1%,換言之,目前深度學習模型的識別能力已經(jīng)超過了人眼。
在卷積神經(jīng)網(wǎng)絡的歷史上,比較有里程碑意義的算法包括AlexNet、VGG、Inception (GoogleNet是Inception系列中的一員),以及ResNet。
在本期開小灶中,我們將首先為大家介紹經(jīng)典圖像分類算法AlexNet。
AlexNet 網(wǎng)絡結構
作為G. Hinton代表作的AlexNet是深度學習領域最重要的成果之一。下面讓我們一起從左到右依次認識這個結構。
在AlexNet網(wǎng)絡結構(如下圖所示)中,輸入為一個224×224大小的RGB圖像。
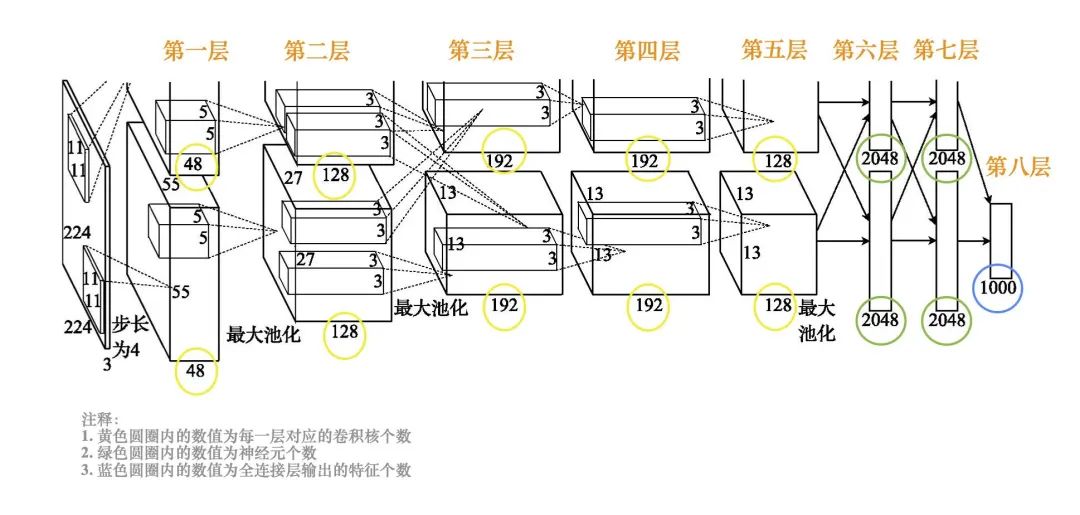
AlexNet網(wǎng)絡結構
第一層卷積,用48個11×11×3的卷積核計算出48個55×55大小的特征圖,用另外48個11×11×3的卷積核計算出另外48個55×55大小的特征圖,這兩個分支的卷積步長都是4,通過卷積把圖像的大小從224′224減小為55×55。第一層卷積之后,進行局部響應歸一化 (LRN) 以及步長為2、池化窗口為3×3的最大池化,池化輸出的特征圖大小為27×27。
第二層卷積,用兩組各128個5×5×48的卷積核對兩組輸入的特征圖分別進行卷積處理,輸出兩組各128個27×27的特征圖。第二層卷積之后,做局部響應歸一化和步長為2、池化窗口為3×3的最大池化,池化輸出的特征圖大小為13×13。
第三層卷積,將兩組特征圖合為一組。采用192個3×3×256的卷積核對所有輸入特征圖做卷積運算,再用另外192個3×3×256的卷積核對所有輸入特征圖做卷積運算,輸出兩組各192個13×13的特征圖。
第四層卷積,對兩組輸入特征圖分別用192個3×3×192的卷積核做卷積運算。
第五層卷積,對兩組輸入特征圖分別用128個3×3×192的卷積核做卷積運算。第五層卷積之后,做步長為2、池化窗口為3×3的最大池化,池化輸出的特征圖大小為6×6。
第六層和第七層的全連接層都有兩組神經(jīng)元(每組2048個神經(jīng)元)。
第八層的全連接層輸出1000種特征并送到softmax中,softmax輸出分類的概率。
AlexNet 技術創(chuàng)新點
相較于傳統(tǒng)人工神經(jīng)網(wǎng)絡而言,AlexNet的技術創(chuàng)新體現(xiàn)在四個方面。
其一為Dropout(隨機失活)。Dropout于2012年由G. Hinton等人提出。該方法通過隨機舍棄部分隱層節(jié)點來緩解過擬合。目前,Dropout已經(jīng)成為深度學習訓練常用的技巧之一。
使用Dropout進行模型訓練的過程為:a. 以一定概率隨機舍棄部分隱層神經(jīng)元,即將這些神經(jīng)元的輸出設置為0;b.一小批訓練樣本經(jīng)過正向傳播后,在反向傳播更新權重時不更新其中與被舍棄神經(jīng)元相連的權重;c. 恢復被刪除神經(jīng)元,并輸入另一小批訓練樣本;d. 重復步驟a ~ c ,直到處理完所有訓練樣本。
其二為LRN(局部響應歸一化)。LRN對同一層的多個輸入特征圖在每個位置上做局部歸一化,從而提升高響應特征并抑制低響應特征。LRN的輸入是卷積層輸出特征圖經(jīng)過ReLU激活函數(shù)后的輸出。但近年來業(yè)界發(fā)現(xiàn)LRN層作用有限,因此目前使用LRN的研究并不多。
其三是Max Pooling(最大池化)。最大池化可以避免特征被平均池化模糊,從而提高特征的魯棒性。在AlexNet之前,很多研究用平均池化;從AlexNet開始,業(yè)界公認最大池化的效果比較好。
其四是ReLU激活函數(shù)。在AlexNet之前,常用的激活函數(shù)是sigmoid和tanh。而ReLU函數(shù)很簡單,我們在之前的開小灶中為大家講解過ReLU激活函數(shù)的特征,即輸入小于0時輸出0,輸入大于0時輸出等于輸入。看似非常簡單的ReLU函數(shù)卻在訓練時帶來了非常好的效果,這是業(yè)界在AlexNet之前未曾料想到的。AlexNet在卷積層和全連接層的輸出均使用ReLU激活函數(shù),從而有效提高訓練時的收斂速度。
AlexNet通過把看似平凡的技術組合起來取得了驚人的顯著效果。
正是由于AlexNet采用了深層神經(jīng)網(wǎng)絡的訓練思路,并輔以ReLU函數(shù)、Dropout及數(shù)據(jù)擴充等操作,使得圖像識別真正走向了與深度學習結合發(fā)展的方向。
原文標題:基于卷積神經(jīng)網(wǎng)絡的圖像分類算法講解
文章出處:【微信公眾號:機器視覺智能檢測】歡迎添加關注!文章轉載請注明出處。
審核編輯:湯梓紅
-
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4771瀏覽量
100719 -
算法
+關注
關注
23文章
4607瀏覽量
92840
原文標題:基于卷積神經(jīng)網(wǎng)絡的圖像分類算法講解
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
使用卷積神經(jīng)網(wǎng)絡進行圖像分類的步驟
主動學習在圖像分類技術中的應用:當前狀態(tài)與未來展望

圖像識別算法有哪幾種
圖像識別算法都有哪些方法
圖像識別算法的提升有哪些
圖像識別算法的優(yōu)缺點有哪些
圖像識別算法的核心技術是什么
經(jīng)典卷積網(wǎng)絡模型介紹
計算機視覺怎么給圖像分類
一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
OpenAI發(fā)布圖像檢測分類器,可區(qū)分AI生成圖像與實拍照片
基于FPGA的常見的圖像算法模塊總結

FPGA圖像處理-CLAHE算法介紹(一)
CNN圖像分類策略





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論