") 如何使用測試數(shù)據(jù)幫助解決原型應(yīng)用程序的技術(shù)和業(yè)務(wù)挑戰(zhàn)
如何使用測試數(shù)據(jù)幫助解決原型應(yīng)用程序的技術(shù)和業(yè)務(wù)挑戰(zhàn)
互聯(lián)汽車是指使用后端系統(tǒng)與其他車輛進行通信的車輛,以增強可用性,實現(xiàn)便捷的服務(wù),并保持分布式軟件的維護和更新。
在大眾汽車公司,我們正在使用 NVIDIA 開發(fā)互聯(lián)汽車,以解決在原生 python 和 pandas 中實現(xiàn)時存在計算效率低下的問題,如地理空間索引和 K 近鄰。
處理駕駛和傳感器數(shù)據(jù)對于聯(lián)網(wǎng)汽車了解其環(huán)境至關(guān)重要。它使連接的車輛能夠執(zhí)行諸如停車點檢測、基于位置的服務(wù)、防盜、通過實時交通推薦路線、車隊管理等任務(wù)。位置信息是大多數(shù)這些用例的關(guān)鍵,需要一個快速的處理管道來支持實時服務(wù)。
全球聯(lián)網(wǎng)汽車的銷量正在迅速增長,而這反過來又增加了可用的數(shù)據(jù)量。根據(jù) Gartner ,平均連接車輛每年將產(chǎn)生 280 PB 的數(shù)據(jù),其中至少一天會產(chǎn)生 4 TB 的數(shù)據(jù)。研究還指出,到 2025 年,將部署約 4 。 7 億輛聯(lián)網(wǎng)車輛。
這篇博文將集中討論處理基于位置的地理空間信息和為聯(lián)網(wǎng)汽車提供必要服務(wù)所需的數(shù)據(jù)管道。
互聯(lián)汽車數(shù)據(jù)的挑戰(zhàn)
使用互聯(lián)汽車數(shù)據(jù)帶來了技術(shù)和業(yè)務(wù)挑戰(zhàn):
需要快速處理大量的流數(shù)據(jù),因為用戶希望獲得近乎實時的體驗,以便及時做出決策。例如,如果一個用戶請求一個停車位,而系統(tǒng)需要 5 分鐘的響應(yīng)時間,那么這個停車位很可能在回答時就已經(jīng)被占用了。更快地處理和分析數(shù)據(jù)是克服這一挑戰(zhàn)的關(guān)鍵因素。
還有數(shù)據(jù)隱私問題需要考慮。連接的車輛必須滿足 通用數(shù)據(jù)保護條例( GDPR ) 。簡而言之, GDPR 要求在數(shù)據(jù)分析之后,不應(yīng)該有機會從分析的數(shù)據(jù)中識別單個用戶。此外,禁止存儲與個人用戶有關(guān)的數(shù)據(jù)(除非用戶書面同意)。匿名化可以通過屏蔽識別單個用戶的數(shù)據(jù)或者通過分組和聚合數(shù)據(jù)來滿足這些要求,這樣就不可能跟蹤用戶。為此,我們需要確保處理聯(lián)網(wǎng)車輛數(shù)據(jù)的軟件符合 GDPR 關(guān)于數(shù)據(jù)匿名化的規(guī)定,這在數(shù)據(jù)處理過程中增加了額外的計算要求。
 采用數(shù)據(jù)科學(xué)方法
采用數(shù)據(jù)科學(xué)方法
RAPIDS 可以解決互聯(lián)汽車的技術(shù)和業(yè)務(wù)難題。開放源碼軟件( OSS )庫和 API 的 RAPIDS 套件使您能夠完全在 GPU 上執(zhí)行端到端的數(shù)據(jù)科學(xué)和分析管道。根據(jù) Apache 2 。 0 , RAPIDS 由 NVIDIA 孵育 許可,并基于廣泛的硬件和數(shù)據(jù)科學(xué)經(jīng)驗。 RAPIDS 利用 NVIDIA CUDA 開關(guān) 原語進行低級計算優(yōu)化,并通過用戶友好的 Python 接口公開 GPU 并行性和高帶寬內(nèi)存速度。
在下面的部分中,我們將討論 RAPIDS (軟件)和 NVIDIA GPU s (硬件)如何使用測試數(shù)據(jù)幫助解決原型應(yīng)用程序的技術(shù)和業(yè)務(wù)挑戰(zhàn)。將評估兩種不同的方法:地理空間索引和 k- 近鄰。
通過使用 RAPIDS ,我們可以將這個管道的速度提高 100 倍。
地理空間索引簡介
地理空間索引是互聯(lián)汽車領(lǐng)域許多算法的基礎(chǔ)。它是將地球的各個區(qū)域劃分成可識別的網(wǎng)格單元的過程。在查詢互聯(lián)汽車產(chǎn)生的海量數(shù)據(jù)時,對搜索空間進行修剪是一種有效的方法。
流行的方法包括 軍用網(wǎng)格參考系統(tǒng) ( MGRS )和 Uber 六邊形層次空間索引 ( Uber H3 )。
在這個數(shù)據(jù)管道示例中,我們使用 Uber H3 在空間上將記錄拆分為一組較小的子集。
以下是將記錄拆分為子集后需要滿足的條件 :
每個子集最多由 N 個記錄組成。這個“ N ”是根據(jù)計算能力限制來選擇的。對于這個實驗,我們考慮“ n ”等于 2500 個記錄。
子集由 subset _ id 表示,它是從 0 開始的自動遞增數(shù)字。
以下是示例輸入數(shù)據(jù),它有兩列–緯度和經(jīng)度:
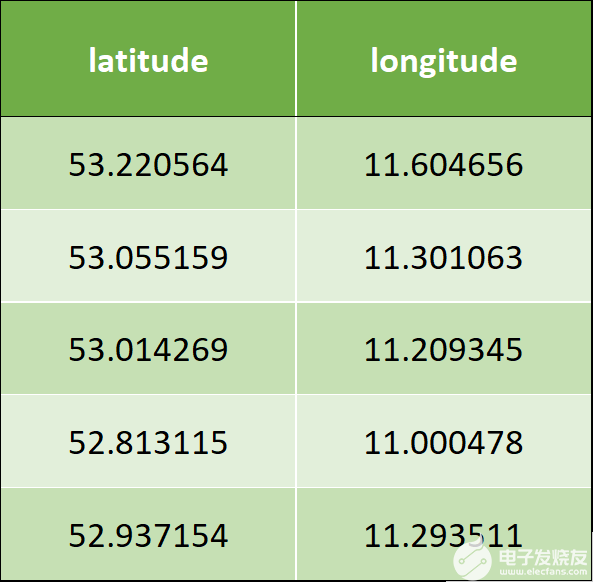
表 1 :輸入數(shù)據(jù)示例。
下面是將 Uber H3 應(yīng)用于用例需要實現(xiàn)的算法
迭代 latitude 和 longitude ,并從分辨率 0 分配 hex_id 。
如果發(fā)現(xiàn)任何包含少于 2500 條記錄的 hex_id ,則從 0 開始遞增地分配 subset_id 。
識別包含超過 2500 條記錄的 hex \ u id 。
以增量分辨率拆分前面的記錄,現(xiàn)在分辨率為 1 。
重復(fù)第 3 步和第 4 步,直到所有記錄都分配給 subset \ u id 和 hex \ u id ,或者直到分辨率達到 15 。
應(yīng)用上述算法后,將產(chǎn)生以下輸出數(shù)據(jù):
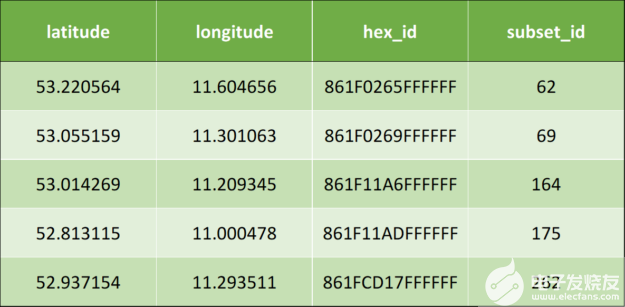
表 2 :應(yīng)用地理空間索引后的輸出數(shù)據(jù)示例。
Uber H3 實現(xiàn)的代碼片段
下面是使用 pandas 實現(xiàn) Uber H3 的代碼片段:
下面是使用pandas實現(xiàn) Uber H3 的代碼片段:
#while loop until all the records are assigned to subset_id while resolution < 16 and df["subset_id"].isnull().any(): #assignment of hex_id df['hex_id']= df.apply(lambda row: h3.geo_to_h3(row["latitude"], row["longitude"], resolution), axis = 1) df_aggreg = df.groupby(by = "hex_id").size().reset_index() df_aggreg.columns = ["hex_id", "value"] #filtering the records that are less than 2500 count hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id'] #assignment of subset_id for index, value in hex_id.items(): df.loc[df['hex_id'] == value, 'subset_id'] = subset_id subset_id += 1 df_return = df_return.append(df[~df['subset_id'].isna()], ignore_index=True) df = df[df['subset_id'].isna()] resolution += 1
下面是使用PySpark實現(xiàn) Uber H3 的代碼片段:
#while loop until all the records are assigned to subset_id while resolution < 16 and (len(df.head(1)) != 0): #assignment of hex_id df = df.rdd.map(lambda x: (x["latitude"], x["longitude"], x["subset_id"],h3.geo_to_h3(x["latitude"], x["longitude"], resolution))) df = sqlContext.createDataFrame(df, schema) df_aggreg = df.groupby("hex_id").count() df_aggreg = df_aggreg.withColumnRenamed("hex_id", "hex_id") .withColumnRenamed("count", "value") #filtering the records that are less than 2500 count hex_id = df_aggreg.filter(df_aggreg.value < 2500) var_hex_id = list(hex_id.select('hex_id').toPandas()['hex_id']) for i in var_hex_id: #assignment of subset_id df = df.withColumn('subset_id',F.when(df.hex_id==i,subset_id) .otherwise(df.subset_id)).select(df.latitude, df.longitude, 'subset_id', df.hex_id) subset_id += 1 df_return = df_return.union(df.filter(df.subset_id != 0)) df = df.filter(df.subset_id == 0) resolution += 1
通過對 Uber H3 模型的 pandas 實現(xiàn),我們發(fā)現(xiàn)了一個非常緩慢的執(zhí)行過程。代碼的執(zhí)行速度太慢導(dǎo)致生產(chǎn)力大大降低,因為只能做很少的實驗。具體目標是將執(zhí)行時間縮短 10 倍。
為了加快管道的速度,我們采取了如下一步一步的方法。
第一步:簡單 CPU 并行版本
這個版本的思想是為 H3 庫處理實現(xiàn)一個簡單的基于多處理的內(nèi)核。處理的第二部分,即根據(jù)數(shù)據(jù)分配子集,是 pandas 庫函數(shù),它不容易并行化。
#Function to assign hex_id def minikernel(df, resolution): df['hex_id'] = np.vectorize(lambda latitude, longitude: h3.geo_to_h3(latitude, longitude, resolution))( np.array(df['latitude']), np.array(df['longitude'])) return df
#while loop until all the records are assigned to subset_id while resolution < 16 and df["subset_id"].isnull().any(): #CPU Parallelization df_chunk = np.array_split(df, n_cores) pool = Pool(n_cores) #assigning hex_id by calling the function minikernel() df_chunk_res=pool.map(partial(minikernel, resolution=resolution), df_chunk) df = pd.concat(df_chunk_res) pool.close() pool.join() df_aggreg = df.groupby(by = "hex_id").size().reset_index() df_aggreg.columns = ["hex_id", "value"] #filtering the records that are less than 2500 count hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id'] for index, value in hex_id.items(): #assignment of subset_id is pandas library function #which cannot be parallelized df.loc[df['hex_id'] == value, 'subset_id'] = subset_id subset_id += 1 df_return = df_return.append(df[~df['subset_id'].isna()], ignore_index=True) df = df[df['subset_id'].isna()] resolution += 1
通過對線程池應(yīng)用簡單的并行化,我們可以顯著減少代碼的第一部分( H3 庫),但第二部分( pandas 庫)是完全單線程的,速度非常慢。
第二步:應(yīng)用 RAPIDS [ZBK9
這里的想法是盡可能多地使用 cuDF 中的標準特性(因此,最輕微的代碼更改)來實現(xiàn)最佳性能。由于 cuDF 現(xiàn)在在 CUDA 統(tǒng)一內(nèi)存上運行,因此不可能簡單地并行化第一部分( H3 庫),因為 cuDF 不處理 CPU 分區(qū)。代碼如下所示。注意,以下代碼在 cuDF 數(shù)據(jù)幀上運行。
#while loop until all the records are assigned to subset_id while resolution < 16 and df["subset_id"].isnull().any(): #assignment of hex_id #df is a cuDF df['hex_id'] = np.vectorize(lambda latitude, longitude: h3.geo_to_h3(latitude, longitude, resolution)) (df['latitude'].to_array(), df['longitude'] .to_array()) df_aggreg = df.groupby('hex_id').size().reset_index() df_aggreg.columns = ["hex_id", "value"] #filtering the records that are less than 2500 count hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id'] for index, value in hex_id.to_pandas().items(): #assignment of subset_id df.loc[df['hex_id'] == value, 'subset_id'] = subset_id subset_id += 1 df_return = df_return.append(df[~df['subset_id'].isna()], ignore_index=True) df = df[df['subset_id'].isna()] resolution += 1
步驟 3 :使用較大的數(shù)據(jù)執(zhí)行簡單的 CPU 并行版本和 cuDF GPU 版本
在這一步中,我們將數(shù)據(jù)量增加了三倍,從 50 萬條記錄增加到 150 萬條記錄,并執(zhí)行一個簡單的 CPU 并行版本及其等價的 cuDF GPU 版本。
第四步:再做一次實驗,復(fù)制到 pandas 和 cuDF
如步驟 2 所述, cuDF 在 CUDA 統(tǒng)一內(nèi)存上運行,由于 cuDF 缺少 CPU 分區(qū),因此無法并行化第一部分( H3 庫)。因此,我們沒有使用函數(shù)數(shù)組\ u split 。為了克服這個挑戰(zhàn),我們首先將 cuDF 轉(zhuǎn)換為 pandas 數(shù)據(jù)幀,然后應(yīng)用函數(shù)數(shù)組\ u split ,然后將分割的塊轉(zhuǎn)換回 cuDF ,并進一步進行 H3 庫處理。
#while loop until all the records are assigned to subset_id while resolution < 16 and df["subset_id"].isnull().any(): #copy to pandas df_temp = df.to_pandas() #CPU Parallelization df_chunk = np.array_split(df_temp, n_cores) pool = Pool(n_cores) df_chunk_res=pool.map(partial(minikernel, resolution=resolution), df_chunk) pool.close() pool.join() df_temp = pd.concat(df_chunk_res) #Back to cuDF df = cudf.DataFrame(df_temp) #assignment of hex_id df['hex_id'] = np.vectorize(lambda latitude, longitude: h3.geo_to_h3(latitude, longitude, resolution)) (df['latitude'].to_array(), df['longitude'] .to_array()) df_aggreg = df.groupby('hex_id').size().reset_index() df_aggreg.columns = ["hex_id", "value"] #filtering the records that are less than 2500 count hex_id = df_aggreg[df_aggreg['value']<2500]['hex_id'] for index, value in hex_id.to_pandas().items(): #assignment of subset_id df.loc[df['hex_id'] == value, 'subset_id'] = subset_id subset_id += 1 df_return = df_return.append(df[~df['subset_id'].isna()], ignore_index=True) df = df[df['subset_id'].isna()] resolution += 1
瀏覽所有上述方法的執(zhí)行時間圖:
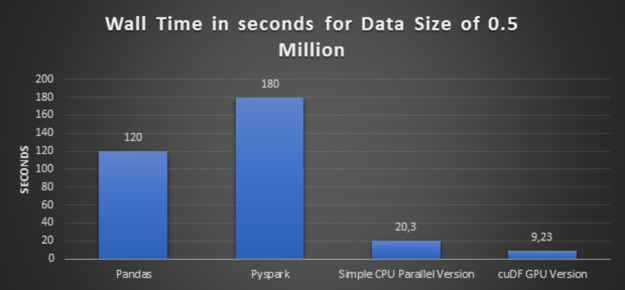
圖 2 :數(shù)據(jù)大小為 50 萬的各種方法的執(zhí)行時間。
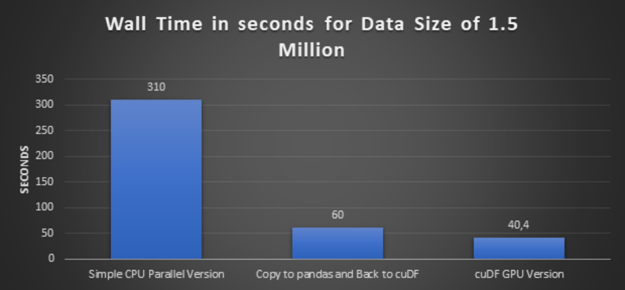
圖 3 :數(shù)據(jù)大小為 150 萬的各種方法的執(zhí)行時間。
加快地理空間指數(shù)計算的經(jīng)驗教訓(xùn)
高性能: 前面的略圖得出的結(jié)論很清楚, cuDF GPU 版本提供了最佳性能。而且數(shù)據(jù)集越大,速度就越快。
代碼適應(yīng)性和易轉(zhuǎn)換性: 請注意,所移植的代碼并不是 GPU 加速的最佳方案。我們正在 CPU 上運行的第三方庫( Uber H3 )上運行比較。為了利用這個庫,我們需要在每個循環(huán)上將數(shù)據(jù)從 GPU 內(nèi)存復(fù)制到 CPU 內(nèi)存,這不是最佳方法。
除此之外,還有一個子集合 id 計算,它也是以行方式進行的,通過更改原始代碼可能會加快計算速度。但代碼仍然沒有改變,因為我們的主要目標之一是檢查代碼的適應(yīng)性以及庫 pandas 和 cuDF 之間的輕松轉(zhuǎn)換。
可重用代碼: 正如您在前面已經(jīng)觀察到的,管道是一組標準化的函數(shù),也可以用作解決其他用例的函數(shù)。
一種 CUDA 加速 K 近鄰分類方法的研究
使用上述方案,而不是通過索引和分組的方式來測量相連車輛的密度——另一種方法是根據(jù)兩個地點之間的地球距離進行地理分類。
我們選擇的分類算法是 K- 近鄰 。最近鄰方法的原理是找到距離數(shù)據(jù)點最近的預(yù)定義數(shù)量的數(shù)據(jù)點( K )。我們將比較基于 CPU 的 KNN 實現(xiàn)與相同算法的 RAPIDS GPU 加速版本。
在我們當前的用例中,我們使用匿名流式連接的汽車數(shù)據(jù)(如前面的業(yè)務(wù)挑戰(zhàn)中所述)。在這里,使用 KNN 對數(shù)據(jù)進行分組和聚合是匿名化的一部分。
然而,對于我們的用例,當我們在地理坐標上分組和聚合時,我們將使用 Haversine 度量,它是唯一可以對地理坐標進行聚類的度量。
在我們的管道中,使用 haversine 作為距離度量的 KNN 的輸入將是地理坐標(緯度、經(jīng)度)和所需的最近數(shù)據(jù)點的數(shù)量。在下面的示例中,將創(chuàng)建 K = 7 。
在下面的例子中,我們展示了以元組(經(jīng)度和緯度)表示的相同數(shù)據(jù)。
輸入數(shù)據(jù)與上一個示例中顯示的元組(經(jīng)度和緯度)相同。
應(yīng)用 KNN 后,通過 KNN 算法計算群集 id : 對于前兩行輸入數(shù)據(jù),集群輸出數(shù)據(jù)如下所示。為了避免混淆,我們用相應(yīng)的顏色標記集群 id 。
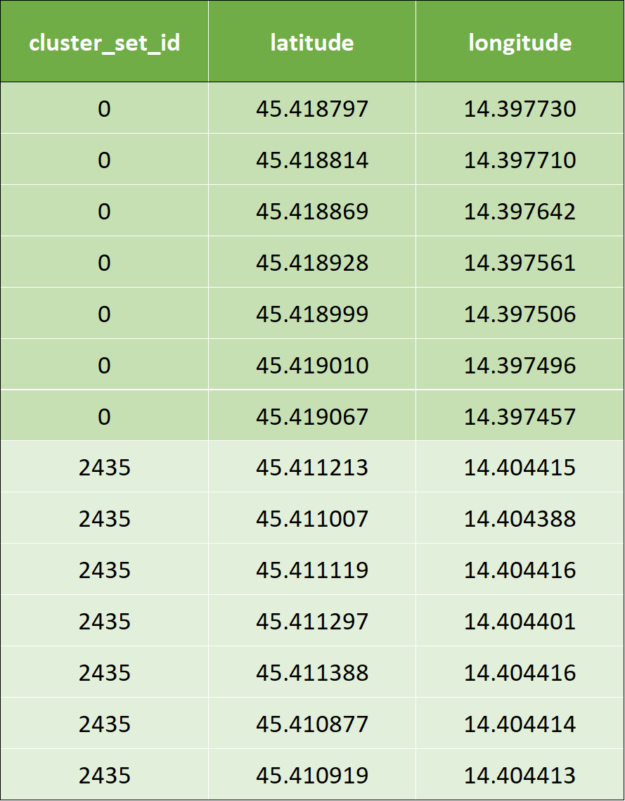
表 3 :應(yīng)用 k 近鄰分類后的樣本輸出數(shù)據(jù)。
以下是使用 pandas 實現(xiàn) KNN 的代碼片段:
nbrs = NearestNeighbors(n_neighbors=7, algorithm='ball_tree', metric = "haversine").fit(coord_array_rad) distances, indices = nbrs.kneighbors(coord_array_rad) # Distance is computed in radians from haversine distances_m = earth_radius * distances # Drop KNN, which are not compliant with minimum distance compliant_distances_mask = (distances_m<KNN_MAX_DISTANCE) .all(axis = 1) compliant_indices = indices[compliant_distances_mask]
采用 KNN 作為分類算法。 KNN 的缺點是它的計算性能,特別是當數(shù)據(jù)量較大時。我們的目的是最終利用 cuML 的 KNN 實現(xiàn)。
之前的實現(xiàn)在相當小的數(shù)據(jù)集中工作,但沒有在 1 。 5 天內(nèi)完成 300 萬條記錄的處理。所以我們阻止了它。
為了轉(zhuǎn)向 CUDA 加速的 KNN 實現(xiàn),我們必須用如下所示的等效度量來模擬 haversine 距離。
第 1 步:圍繞哈弗斯線進行坐標變換
在運行此練習(xí)時,在 cuML 的 KNN 實現(xiàn)中, haversine 距離度量本機不可用。因此,使用歐幾里德距離代替。盡管如此,公平地說,當前版本的 RAPIDS KNN 已經(jīng)支持 haversine 度量。
首先,我們將坐標轉(zhuǎn)換為以米為單位的距離,以便執(zhí)行距離度量計算。[10]這是通過名為 df _ geo ()的函數(shù)實現(xiàn)的,該函數(shù)將在下一步中使用。
歐幾里德距離的一個警告是,它不適用于地球上距離更遠的坐標。相反,它基本上會在地球表面“挖洞”,而不是在地球表面。但是,對于小于等于 100 公里的較小距離,哈弗斯距離和歐幾里德距離之間的差異最小。
步驟 2 :執(zhí)行 KNN 算法
到目前為止,我們已經(jīng)將所有坐標轉(zhuǎn)換為東北坐標格式,在這一步中,可以應(yīng)用實際的 KNN 算法。
我們在下面的設(shè)置中使用了 CUDA 加速 KNN 。我們注意到這個實現(xiàn)執(zhí)行得非常快,絕對值得實現(xiàn)。
#defining the hyperparameters n_neighbors = 7 algorithm = "brute" metric = "euclidean" #Implementation of kNN by calling df_geo() which converts the coordinates #into Northing and Easting coordinate format nbrs = NearestNeighbors(n_neighbors=n_neighbors, algorithm=algorithm, metric=metric).fit(df_geo[['northing', 'easting']]) distances, indices = nbrs.kneighbors(df_geo[['northing', 'easting']])
步驟 3 :執(zhí)行距離掩蔽和過濾
這一部分是在 CPU 上完成的,因為在 GPU 上沒有明顯的加速。
distances = cp.asnumpy(distances.values) indices = cp.asnumpy(indices.values)
#running on CPU KNN_MAX_DISTANCE = 10000 # meters # Drop KNN, which are not compliant with minimum distance compliant_distances_mask = (distances < KNN_MAX_DISTANCE).all(axis = 1) compliant_indices = indices[compliant_distances_mask]
我們的結(jié)果是在 naive pandas 實現(xiàn)的基礎(chǔ)上應(yīng)用到一個有 300 萬個樣本的數(shù)據(jù)集時,加速了 800 倍。
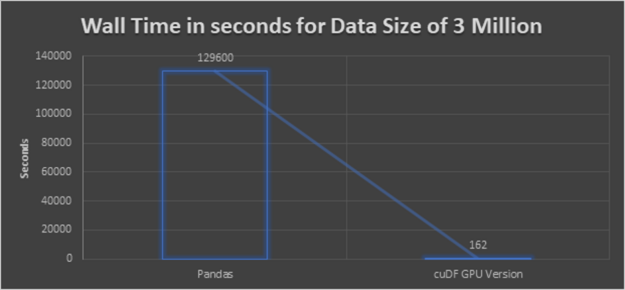
圖 4 :數(shù)據(jù)量為 300 萬的各種方法的執(zhí)行時間。
K 近鄰聚類的經(jīng)驗教訓(xùn)
高性能: 前面的略圖得出的結(jié)論很清楚, cuDF GPU 版本提供了最佳性能。即使數(shù)據(jù)集更大,執(zhí)行也不會像 CPU 執(zhí)行那樣花費很長時間。
比較 cuML 和 scikit 的 KNN : 基于 cuML 的實現(xiàn)速度極快。但是我們不得不多走一英里來模擬缺失的距離指標。考慮到所取得的性能提升,做比要求更多的事情絕對值得。同時, haversine 距離在 RAPIDS AI 中受支持,并且與 scikit 實現(xiàn)一樣方便。
我們利用歐幾里德距離和北向東距的方法來克服缺失的哈弗斯距離。根據(jù)我們代碼中的研究“ 在相當長的距離上——可能長達幾千公里或更多,歐幾里德開始錯誤的計算 ”,我們將距離限制為 10 公里。通過使用北距 – 東距,我們首先需要轉(zhuǎn)換坐標。由于整體性能更好,我們可以接受轉(zhuǎn)換坐標所需的時間。
代碼適應(yīng)性和易轉(zhuǎn)換性: 除北距 – 東距功能外。
剩下的代碼類似于 CPU 代碼,仍然獲得了更好的性能。我們沒有更改代碼,因為我們的主要目標之一也是檢查代碼的適應(yīng)性以及庫 pandas 和 cuDF 之間的輕松轉(zhuǎn)換。
可重用代碼: 正如您在前面已經(jīng)觀察到的, pipeline 是一組標準化的函數(shù),也可以用作解決其他用例的函數(shù)。
概括
本文總結(jié)了 RAPIDS 如何通過在兩個模型(即地理空間索引( Uber H3 )和 K 近鄰分類( KNN ))上對數(shù)據(jù)管道進行評估,從而將數(shù)據(jù)管道的速度提高 100 倍。此外,我們分析了 NVIDIA RAPIDS AI 相對于前兩種模型在性能、代碼適應(yīng)性和可重用性等方面的優(yōu)缺點。我們的結(jié)論是 RAPIDS 肯定是一種流數(shù)據(jù)處理技術(shù)(連接的汽車數(shù)據(jù))。它提供了更快的數(shù)據(jù)處理的好處,這是流數(shù)據(jù)分析的關(guān)鍵因素。而且, RAPIDS 支持大量的機器學(xué)習(xí)算法。加速的 RAPIDS cuDF 和 cuML 庫的 API 與 pandas 保持相似,以實現(xiàn)簡單的轉(zhuǎn)換。改造現(xiàn)有的 ML 管道并使其受益于 cuDF 和 cuML 非常容易。
何時選擇 RAPIDS 而不是標準 Python 和 pandas :
當應(yīng)用程序需要更快的數(shù)據(jù)處理時。
如果您確信該代碼在 GPU 中運行比在 CPU 中運行有好處。
如果推薦的算法作為 cuML 的一部分可用。
本文針對汽車工程師、數(shù)據(jù)工程師、大數(shù)據(jù)架構(gòu)師、項目經(jīng)理和行業(yè)顧問,他們對探索或處理數(shù)據(jù)科學(xué)的可能性以及使用 Python 分析數(shù)據(jù)感興趣。
關(guān)于作者
Chaitanya Kumar Dondapati 目前在德國慕尼黑大眾汽車數(shù)據(jù)實驗室擔任數(shù)據(jù)科學(xué)家。他的興趣包括數(shù)據(jù)分析、大數(shù)據(jù)、可視化分析和物聯(lián)網(wǎng)。在加入大眾之前,他為思科、貝爾直升機和曼恩等多家國際客戶提供咨詢服務(wù)。
Miguel Martinez 是 NVIDIA 的高級深度學(xué)習(xí)數(shù)據(jù)科學(xué)家,他專注于 RAPIDS 和 Merlin 。此前,他曾指導(dǎo)過 Udacity 人工智能納米學(xué)位的學(xué)生。他有很強的金融服務(wù)背景,主要專注于支付和渠道。作為一個持續(xù)而堅定的學(xué)習(xí)者, Miguel 總是在迎接新的挑戰(zhàn)。
Dai Yang 是 NVIDIA 的高級解決方案架構(gòu)師。他負責使用 GPU 和網(wǎng)絡(luò)產(chǎn)品定制客戶優(yōu)化的解決方案,重點關(guān)注工業(yè)、汽車和 HPC 客戶。 Dai 積極參與 EMEA 地區(qū) DGX 解決方案的規(guī)劃、部署和培訓(xùn)。在加入 NVIDIA 之前,戴是慕尼黑工業(yè)大學(xué)的研究助理,在那里他研究了高性能計算的各個方面,并為 MPI 標準擴展了 MPI 論壇的草案。戴是在 ISC2020 漢斯梅爾獎獲獎團隊的一部分。
Adolf Hohl 是 NVIDIA EMEA automotive SA 企業(yè)團隊的高級經(jīng)理,專注于 GPU —用于自主車輛( AV )開發(fā)和測試的加速人工智能基礎(chǔ)設(shè)施以及企業(yè)人工智能。他的興趣在于為了 AV 的進步和安全而利用大規(guī)模計算。阿道夫持有佛雷堡大學(xué) IT 安全博士學(xué)位。
審核編輯:郭婷
-
傳感器
+關(guān)注
關(guān)注
2551文章
51099瀏覽量
753572 -
汽車電子
+關(guān)注
關(guān)注
3026文章
7955瀏覽量
167040 -
NVIDIA
+關(guān)注
關(guān)注
14文章
4986瀏覽量
103056
發(fā)布評論請先 登錄
相關(guān)推薦
電力驅(qū)動測試系統(tǒng)的技術(shù)原理和應(yīng)用
android手機上emulate應(yīng)用程序的方法
AWTK-WEB 快速入門(2) - JS 應(yīng)用程序

一文聊聊自動駕駛測試技術(shù)的挑戰(zhàn)與創(chuàng)新

AWTK-WEB 快速入門(1) - C 語言應(yīng)用程序
中國電信完成6G天地一體化原型樣機測試
使用TPA3128d2,增益上選擇了26DB,測試數(shù)據(jù)時發(fā)現(xiàn)只有22DB是為什么?
電源模塊測試系統(tǒng)ATE的數(shù)據(jù)報告與數(shù)據(jù)分析功能
所有的labview應(yīng)用程序的三要素是什么
StreaReady是用來接收nfc的數(shù)據(jù)還是應(yīng)用程序的數(shù)據(jù)?
Anthropic推出iPhone應(yīng)用程序和業(yè)務(wù)層
使用Redis和Spring?Ai構(gòu)建rag應(yīng)用程序


應(yīng)用程序中的服務(wù)器錯誤怎么解決?
通過實時加速器技術(shù)實現(xiàn)實時應(yīng)用程序的 Windows





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論