 利用MLPerf 推理 1.1提升NVIDIA績效領導力
利用MLPerf 推理 1.1提升NVIDIA績效領導力
人工智能繼續推動跨行業的突破性創新,包括消費互聯網、醫療保健和生命科學、金融服務、零售、制造和超級計算。研究人員繼續推動快速發展的模型在規模、復雜度和多樣性方面的發展。此外,其中許多復雜的大規模模型需要為聊天機器人、數字助理和欺詐檢測等人工智能支持的服務提供實時結果。
考慮到人工智能推理的廣泛用途,評估性能對開發人員和基礎設施管理人員提出了許多挑戰。對于數據中心、 edge 和移動平臺上的 AI 推理, MLPerf 推理 1.1 是一個行業標準基準,用于衡量計算機視覺、醫學成像、自然語言和推薦系統的性能。這些基準由人工智能行業領導者組成的聯盟制定,為人工智能培訓和推理提供了當今最全面的同行評審績效數據集。
要在這一基準測試中完成大量測試,需要一個具有強大生態系統支持的全堆棧平臺,無論是框架還是網絡。 NVIDIA 是唯一一家提交所有數據中心和邊緣測試并提供全面領先性能的公司。
這項工作的一個重要副產品是,這些優化中的許多已經進入了推理開發工具,如TensorRT和 NVIDIA Triton 。用于高性能深度學習推理的 TensorRT SDK 包括一個深度學習推理優化器和運行時,為深度學習推理應用程序提供低延遲和高吞吐量。
Triton 推理服務器軟件簡化了人工智能模型在大規模生產中的部署。這種開源推理服務軟件使團隊能夠在任何基于 GPU 或 CPU 的基礎設施上從本地存儲或云平臺的任何框架部署經過培訓的人工智能模型。
按數字
在數據中心和邊緣兩大類中, NVIDIA 憑借 NVIDIA A100 張量核 GPU 和 NVIDIA A30 張量核 GPU 在性能測試中名列榜首。自從 MLPerf 推斷 0.7 的結果發布以來,在過去一年中, NVIDIA 僅通過軟件改進就提高了 50% 的性能。
在另一個行業中, NVIDIA 首次使用基于 GPU – 加速 ARM 的服務器提交數據中心類別,該服務器支持所有工作負載,并提供與類似配置的基于 x86 的服務器相同的結果。這些基于 ARM 的新提交為 GPU 加速 ARM 服務器創造了新的性能世界記錄。這標志著這些平臺的一個重要里程碑,因為它們現在已經在同行評審的行業標準基準中證明了自己,以提供市場領先的性能。它還展示了 NVIDIA ARM 軟件生態系統的性能、多功能性和就緒性,以應對數據中心的計算挑戰。

圖 1 。使用 Ampere Altra CPU s 的基于 ARM 的服務器提供的性能與類似配置的基于 x86 的服務器相當
MLPerf v1.1 推理關閉;每個加速器的性能源自使用數據中心脫機中報告的加速器計數的各個提交的最佳 MLPerf 結果。 x86 服務器: 1.1-034 、 ARM 服務器: 1.1-033 MLPerf 名稱和徽標是商標。
綜觀整體表現, NVIDIA 全面領先。圖 2 顯示了服務器場景的結果,其中使用泊松分布為測試中的系統生成推理工作,以更緊密地模擬真實世界的工作負載模式。
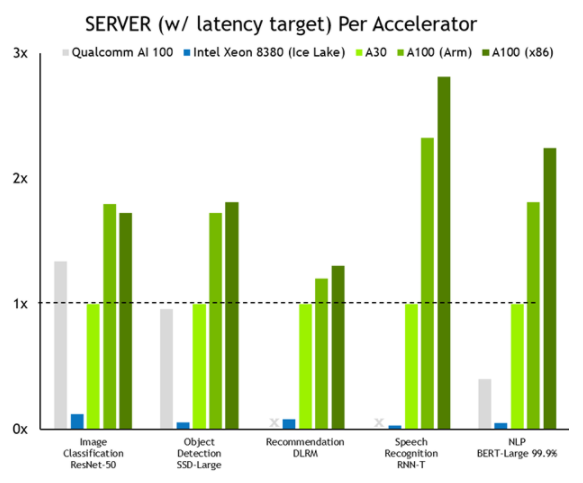
圖 2 。 NVIDIA 與 CPU 純服務器的性能比較
MLPerf v1.1 推理關閉;使用數據中心脫機和服務器中報告的加速器計數,從各個提交的最佳 MLPerf 結果中得出每個加速器的性能。高通 AI 100 : 1.1-057 和 1.1-058 ,英特爾至強 8380 : 1.1-023 和 1.1-024 , NVIDIA A30 : 1.1-43 , NVIDIA A100 ( ARM ): 1.1-033 , NVIDIA A100 ( x86 ): 1.1-047 。 MLPerf 名稱和徽標是商標。
NVIDIA 比 CPU 純服務器的性能全面提高了 104 倍。這種性能優勢轉化為對更大、更復雜的模型以及在對話 AI 、推薦系統和數字助理中實時作業中運行的多個模型進行推理的能力。
結果背后的優化
我們的工程團隊實施了一些優化,使這些偉大的結果成為可能。首先,基于 ARM 的服務器和基于 x86 的服務器的所有這些結果都是使用 TensorRT 8 生成的,現在普遍可用。特別令人感興趣的是雙內核的非冪函數的使用,這是為了加速工作負載而實現的,比如 BERT – 大型單流場景測試。
NVIDIA 提交利用添加到 NVIDIA Triton 推理服務器的新主機策略功能。您可以在配置 NVIDIA Triton 服務器時指定主機策略,以在服務器應用程序中啟用線程和內存固定。利用此功能, NVIDIA Triton 可以為系統中的每個 GPU 指定輸入的最佳位置。最佳位置可以基于系統的非統一內存體系結構( NUMA )配置,在這種情況下,每個 NUMA 節點上都有一個查詢樣本庫。
您還可以使用主機策略啟用“從設備啟動”配置設置,服務器將在選擇執行的 GPU 上拾取輸入。此設置還可以將網絡輸入直接輸入 GPU 內存,完全繞過 CPU 和系統內存副本。
推理能力三人組: TensorRT , NVIDIA Triton 和 NGC
NVIDIA 推理領導力來自于構建最優秀的人工智能加速器,用于培訓和推理。但同樣重要的是支持所有 AI 框架和 800 多個 HPC 應用程序的 NVIDIA 端到端、全棧軟件生態系統。
所有這些軟件都可以在NGC、 NVIDIA 集線器上獲得,該集線器帶有 GPU ——用于深度學習、機器學習和 HPC 的優化軟件。 NGC 負責所有管道,因此數據科學家、開發人員和研究人員可以專注于構建解決方案、收集 i NSight 并提供業務價值。
NGC 可通過您首選的云提供商的市場免費獲得。在那里,您可以找到 TensorRT 和 NVIDIA Triton 的最新版本,這兩個版本都有助于生成最新的 MLPerf 推斷 1.1 結果。
關于作者
Dave Salvator 是 NVIDIA 旗下 Tesla 集團的高級產品營銷經理,專注于超規模、深度學習和推理。
Jesus Corbal San Adrian 是 NVIDIA 計算架構組的杰出工程師,專注于深度學習推理 GPU 分析和優化。
Madhumitha Sridhara 是 TensorRT 團隊的高級軟件工程師,專注于使用 Triton 推理服務器的 NVIDIA MLPerf推理提交。她擁有卡內基梅隆大學計算機工程碩士學位和印度卡納塔克邦蘇拉特卡爾國家理工學院電子和通信工程學士學位。
審核編輯:郭婷
-
人工智能
+關注
關注
1791文章
47350瀏覽量
238753 -
機器學習
+關注
關注
66文章
8422瀏覽量
132714 -
深度學習
+關注
關注
73文章
5504瀏覽量
121222 -
MLPerf
+關注
關注
0文章
35瀏覽量
645
發布評論請先 登錄
相關推薦
借助NVIDIA GPU提升魯班系統CAE軟件計算效率
納芯微電子榮獲“戰略性人才發展與領導力培育卓越獎”

NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

魔搭社區借助NVIDIA TensorRT-LLM提升LLM推理效率
英偉達推出全新NVIDIA AI Foundry服務和NVIDIA NIM推理微服務
博聯智能榮獲“2024全屋智能領導力品牌”獎
DigiKey 在 2024 EDS 領導力峰會上斬獲供應商授予的多個最高獎項

英偉達推出AI模型推理服務NVIDIA NIM
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
沃爾沃利用英偉達的SoC和AI來提升自動駕駛的安全性
萊迪思Avant? FPGA平臺榮獲2024年環境和能源領導力獎






 工商網監
工商網監
評論