 Linux系統如何解析ELF文件
Linux系統如何解析ELF文件
大家好,我是 ELF 文件,大名叫 Executable and Linkable Format。
經常在 Linux 系統中開發的小伙伴們,對于我肯定是再熟悉不過了,特別是那些需要了解編譯、鏈接的家伙們,估計已經把我研究的透透的。
為了結識更多的小伙伴,今天呢,就是我的開放日,我會像洋蔥一樣,一層一層地撥開我的心,讓更多的小伙伴來了解我,歡迎大家前來圍觀。
以前啊,我看到有些小伙伴在研究我的時候,看一下頭部的匯總信息,然后再瞅幾眼 Section 的布局,就當做熟悉我了。
從科學的態度上來說,這是遠遠不夠的,未達究竟。
當你面對編譯、鏈接的詳細過程時,還是會一臉懵逼。
今天,我會從字節碼的顆粒度,毫無保留、開誠布公、知無不言、言無不盡、赤膽忠心、一片丹心、鞠躬盡瘁、死而后已的把自己剖析一遍,讓各位看官大開眼界、大飽眼福。
您了解這些知識之后呢,在今后繼續學習編譯、鏈接的底層過程,以及一個可執行程序在從硬盤加載到內存、一直到 main 函數的執行,心中就會非常的敞亮。
也就是說,掌握了 ELF 文件的結構和內容,是理解編譯、鏈接和程序執行的基礎。
你們不是有一句俗話嘛:磨刀不誤砍柴工!
好了,下面我們就開始吧!
文件很單純,復雜的是人
作為一種文件,那么肯定就需要遵守一定的格式,我也不例外。
從宏觀上看,可以把我拆卸成四個部分:
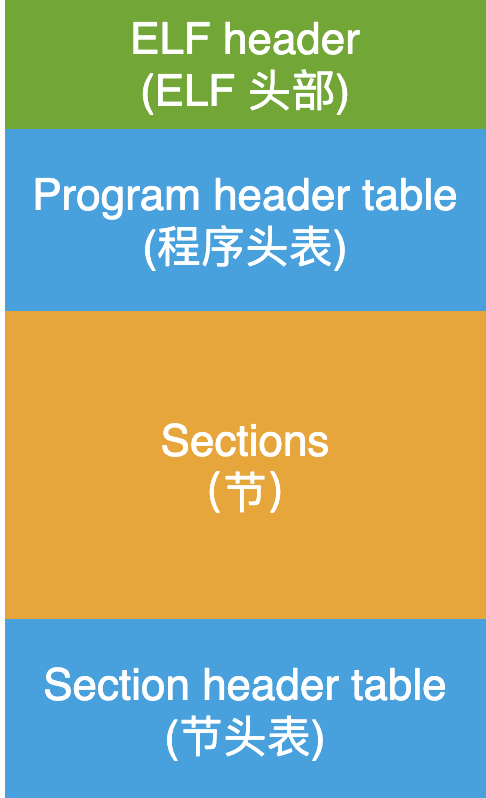
圖中的這幾個概念,如果不明白的話也沒關系,下面我會逐個說明的。
在 Linux 系統中,一個 ELF 文件主要用來表示 3 種類型的文件:
既然可以用來表示 3 種類型的文件,那么在文件中,肯定有一個地方用來區分這 3 種情況。
也許你已經猜到了,在我的頭部內容中,就存在一個字段,用來表示:當前這個 ELF 文件,它到底是一個可執行文件?是一個目標文件?還是一個共享庫文件?
另外,既然我可以用來表示 3 種類型的文件,那么就肯定是在 3 種不同的場合下被使用,或者說被不同的家伙來操作我:
可執行文件:被操作系統中的加載器從硬盤上讀取,載入到內存中去執行;
目標文件:被鏈接器讀取,用來產生一個可執行文件或者共享庫文件;
共享庫文件:在動態鏈接的時候,由 ld-linux.so 來讀取;
就拿鏈接器和加載器來說吧,這兩個家伙的性格是不一樣的,它們看我的眼光也是不一樣的。
鏈接器在看我的時候,它的眼睛里只有 3 部分內容:

也就是說,鏈接器只關心 ELF header, Sections 以及 Section header table 這 3 部分內容。
加載器在看我的時候,它的眼睛里是另外的 3 部分內容:

加載器只關心 ELF header, Program header table 和 Segment 這 3 部分內容。
對了,從加載器的角度看,對于中間部分的 Sections, 它改了個名字,叫做 Segments(段)。換湯不換藥,本質上都是一樣一樣的。
可以理解為:一個 Segment 可能包含一個或者多個 Sections,就像下面這樣:
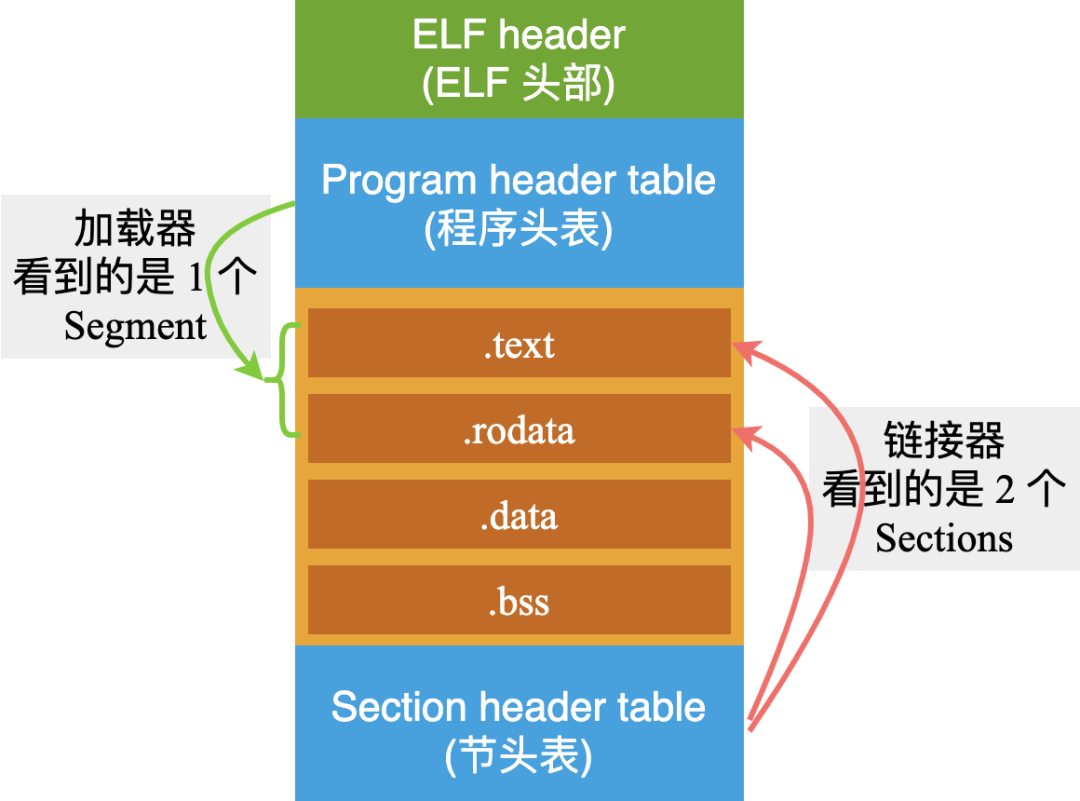
這就好比超市里的貨架上擺放的商品:有礦泉水、可樂、啤酒,巧克力,牛肉干,薯片。
從理貨員的角度看:它們屬于 6 種不同的商品;但是從超市經理的角度看,它們只屬于 2 類商品:飲料和零食。
怎么樣?現在對我已經有一個總體的印象了吧?
其實只要掌握到 2 點內容就可以了:
一個 ELF 文件一共由 4 個部分組成;
鏈接器和加載器,它們在使用我的時候,只會使用它們感興趣的部分;
還有一點差點忘記給你提個醒了:在 Linux 系統中,會有不同的數據結構來描述上面所說的每部分內容。
我知道有些小伙伴比較性急,我先把這幾個結構體告訴你。
初次見面,先認識一下即可,千萬不要深究哦。
描述 ELF header 的結構體:

描述 Program header table 的結構體:

描述 Section header table 的結構體:

ELF header(ELF 頭)
頭部內容,就相當于是一個總管,它決定了這個完整的 ELF 文件內部的所有信息,比如:
這是一個 ELF 文件;
一些基本信息:版本,文件類型,機器類型;
Program header table(程序頭表)的開始地址,在整個文件的什么地方;
Section header table(節頭表)的開始地址,在整個文件的什么地方;
你是不是有點納悶,好像沒有說 Sections(從鏈接器角度看) 或者 Segments(從加載器角度看) 在 ELF 文件的什么地方。
為了方便描述,我就把 Sections 和 Segments 全部統一稱為 Sections 啦!
其實是這樣的,在一個 ELF 文件中,存在很多個 Sections,這些 Sections 的具體信息,是在 Program header table 或者 Section head table 中進行描述的。
就拿 Section head table 來舉例吧:
假如一個 ELF 文件中一共存在 4 個 Section: .text、.rodata、.data、.bss,那么在 Section head table 中,將會有 4 個 Entry(條目)來分別描述這 4 個 Section 的具體信息(嚴格來說,不止 4 個 Entry,因為還存在一些其他輔助的 Sections),就像下面這樣:
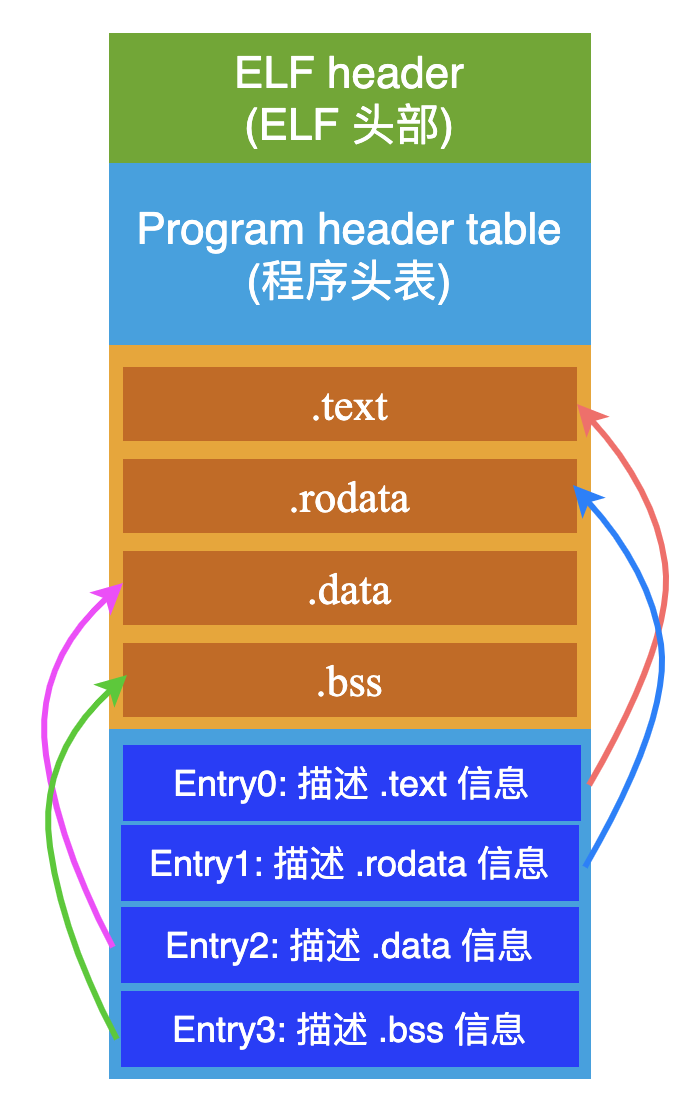
在開頭我就說了,我要用字節碼的粒度,扒開來給你看!
為了不耍流氓,我還是用一個具體的代碼示例來描述,只有這樣,你才能看到實實在在的字節碼。
程序的功能比較簡單:
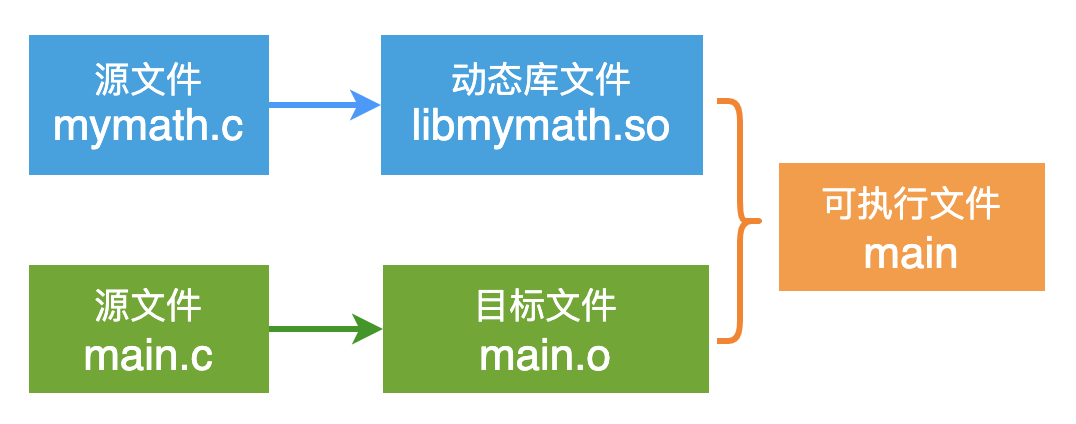
// mymath.c
int my_add(int a, int b)
{
return a + b;
}
// main.c
#include
extern int my_add(int a, int b);
int main()
{
int i = 1;
int j = 2;
int k = my_add(i, j);
printf("k = %d
", k);
}
從剛才的描述中可以知道:動態庫文件 libmymath.so, 目標文件 main.o 和 可執行文件 main,它們都是 ELF 文件,只不過屬于不同的類型。
這里就以可執行文件 main 來拆解它!
我們首先用指令 readelf -h main 來看一下 main 文件中,ELF header 的信息。
readelf 這個工具,可是一個好東西啊!一定要好好的利用它。
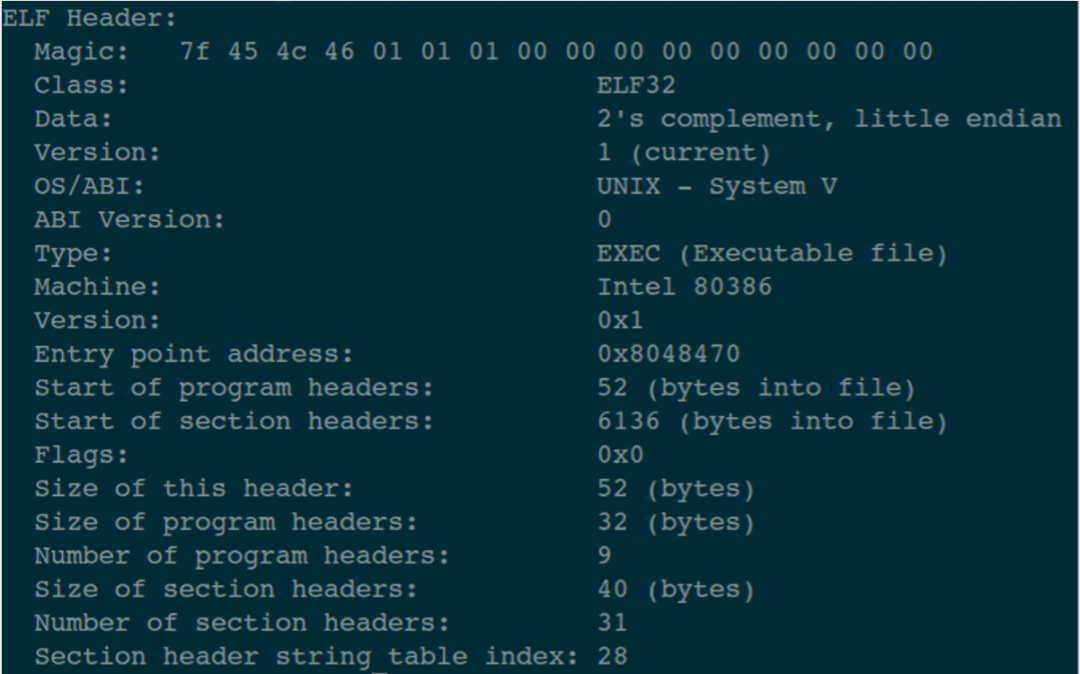
這張圖中顯示的信息,就是 ELF header 中描述的所有內容了。這個內容與結構體 Elf32_Ehdr 中的成員變量是一一對應的!
有沒有發現圖中第 15 行顯示的內容:Size of this header: 52 (bytes)。
也就是說:ELF header 部分的內容,一共是 52 個字節。那么我就把開頭的這 52 個字節碼給你看一下。
這回,我用 od -Ax -t x1 -N 52 main 這個指令來讀取 main 中的字節碼,簡單解釋一下其中的幾個選項:
-Ax: 顯示地址的時候,用十六進制來表示。如果使用 -Ad,意思就是用十進制來顯示地址;
-t -x1: 顯示字節碼內容的時候,使用十六進制(x),每次顯示一個字節(1);
-N 52:只需要讀取 52 個字節;

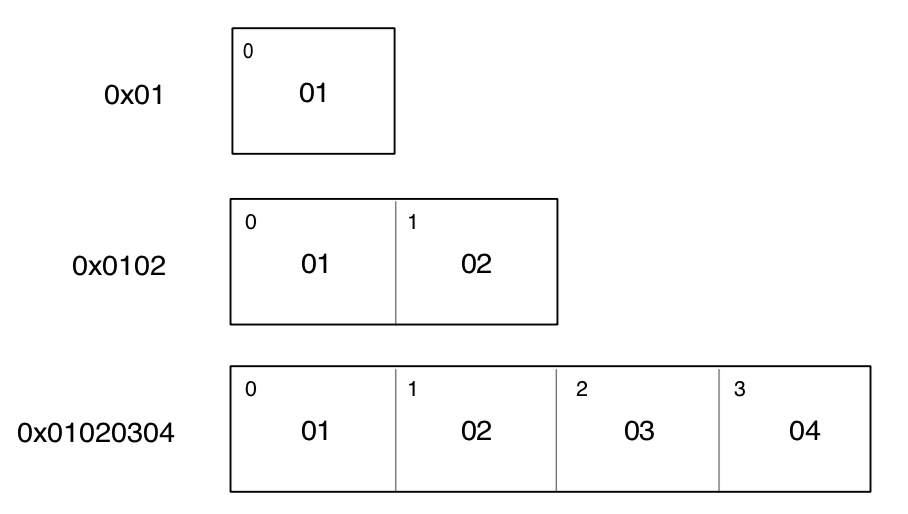
這 52 個字節的內容,你可以對照上面的結構體中每個字段來解釋了。
首先看一下前 16 個字節。
在結構體中的第一個成員是 unsigned char e_ident[EI_NIDENT];,EI_NIDENT 的長度是 16,代表了 EL header 中的開始 16 個字節,具體含義如下:
0 - 15 個字節
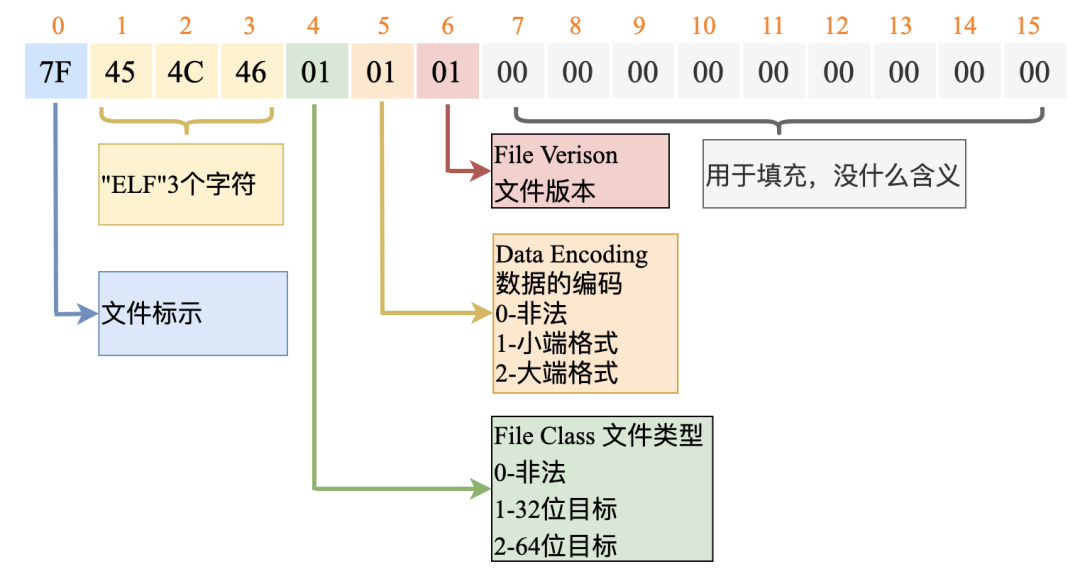
怎樣樣?我以這樣的方式徹底暴露自己,向你表白,足以表現出我的誠心了吧?!
如果被感動了,別忘記在文章的最底部,點擊一下在看和收藏,也非常感謝您轉發給身邊的小伙伴。贈人玫瑰,手留余香!
為了權威性,我把官方文檔對于這部分的解釋也貼給大家看一下:
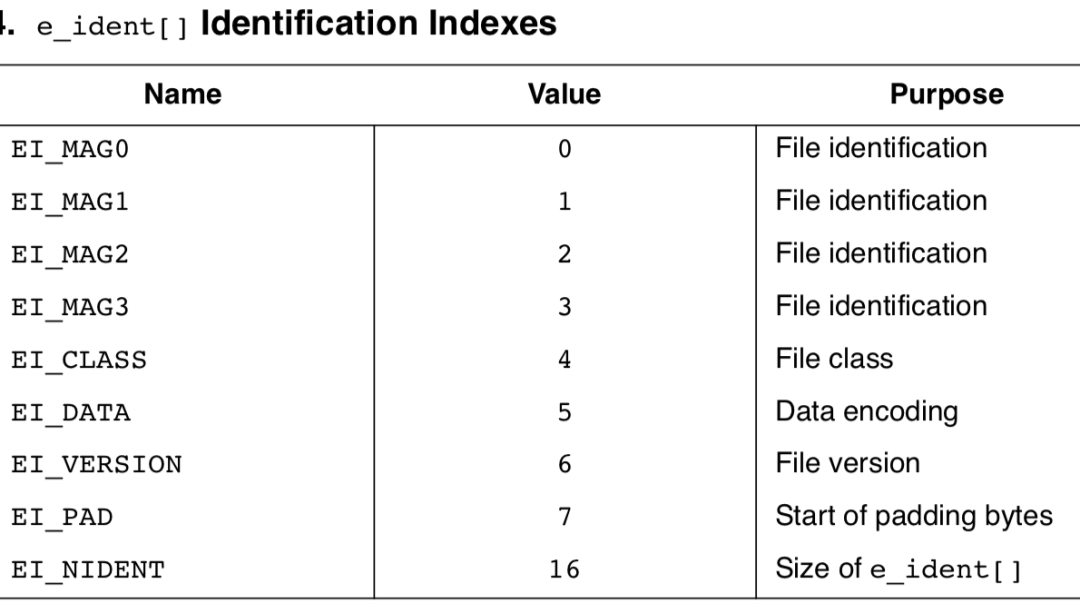
關于大端、小端格式,這個 main 文件中顯示的是 1,代表小端格式。啥意思呢,看下面這張圖就明白了:
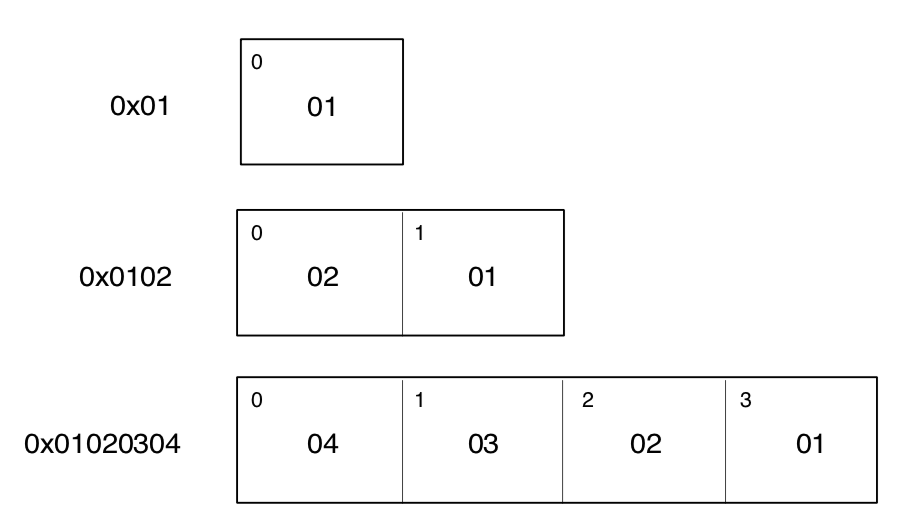
那么再來看一下大端格式:
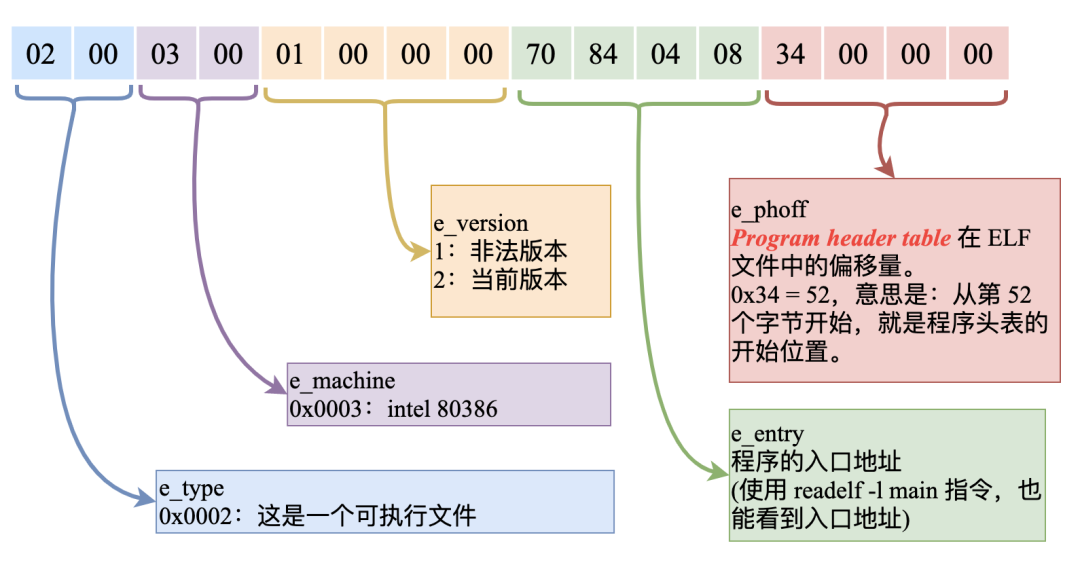
好了,下面我們繼續把剩下的 36 個字節(52 - 16 = 32),也以這樣的字節碼含義畫出來:
16 - 31 個字節:
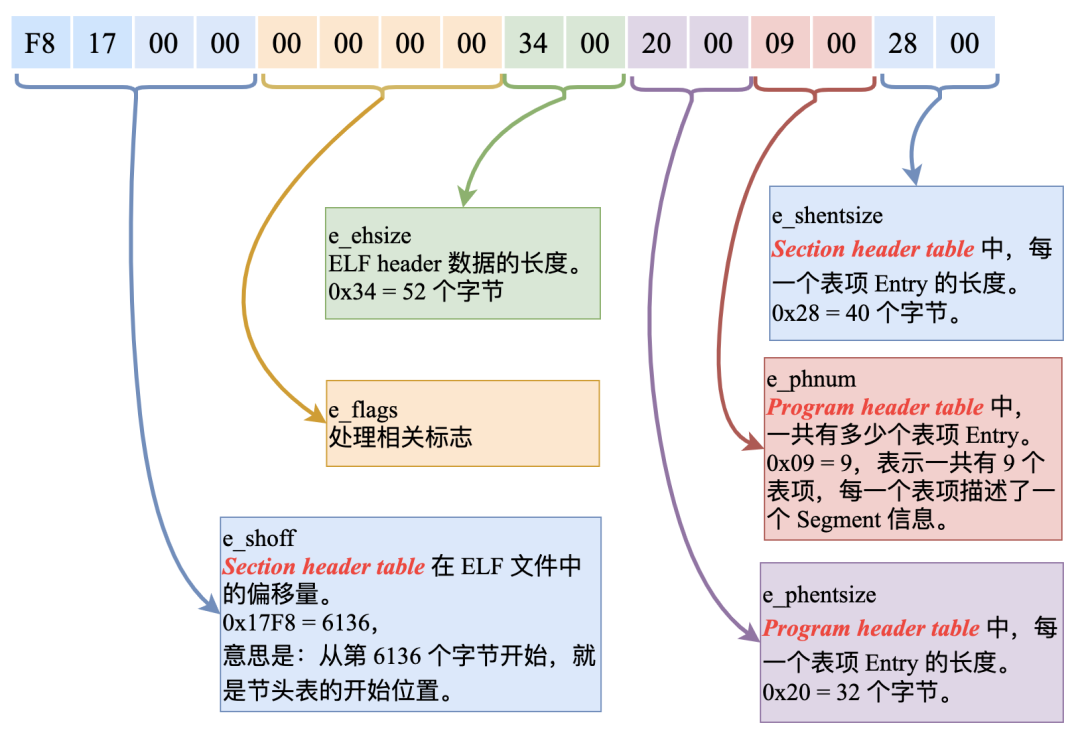
32 - 47 個字節:
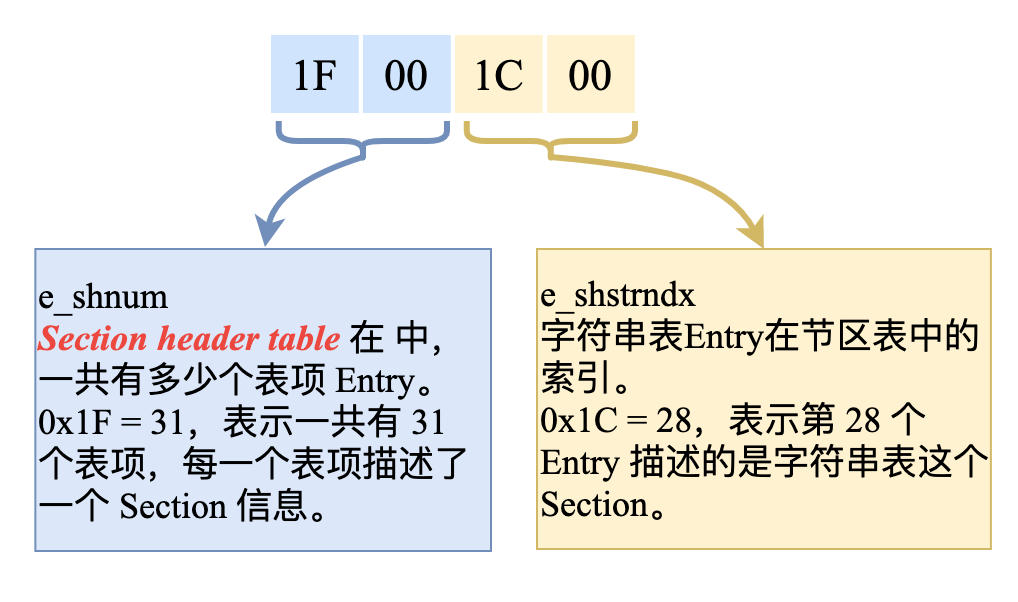
48 - 51 個字節:
具體的內容就不用再解釋了,一切都在感情深、一口悶,話不多說,都在酒里~~ 哦不對,重點都在圖里!
字符串表表項 Entry
在一個 ELF 文件中,存在很多字符串,例如:變量名、Section名稱、鏈接器加入的符號等等,這些字符串的長度都是不固定的,因此用一個固定的結構來表示這些字符串,肯定是不現實的。
于是,聰明的人類就想到:把這些字符串集中起來,統一放在一起,作為一個獨立的 Section 來進行管理。
在文件中的其他地方呢,如果想表示一個字符串,就在這個地方寫一個數字索引:表示這個字符串位于字符串統一存儲地方的某個偏移位置,經過這樣的按圖索驥,就可以找到這個具體的字符串了。
比如說啊,下面這個空間中存儲了所有的字符串:
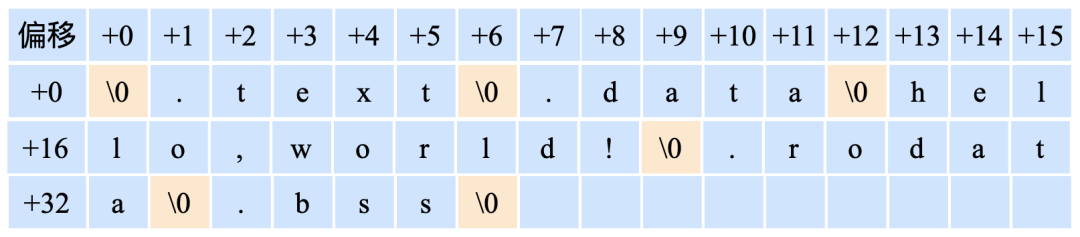
在程序的其他地方,如果想引用字符串 “hello,world!”,那么就只需要在那個地方標明數字 13 就可以了,表示:這個字符串從偏移 13 個字節處開始。
那么現在,咱們再回到這個 main 文件中的字符串表,
在 ELF header 的最后 2 個字節是 0x1C 0x00,它對應結構體中的成員 e_shstrndx,意思是這個 ELF 文件中,字符串表是一個普通的 Section,在這個 Section 中,存儲了 ELF 文件中使用到的所有的字符串。
既然是一個 Section,那么在 Section header table 中,就一定有一個表項 Entry 來描述它,那么是哪一個表項呢?
這就是 0x1C 0x00 這個表項,也就是第 28 個表項。
這里,我們還可以用指令 readelf -S main 來看一下這個 ELF 文件中所有的 Section 信息:
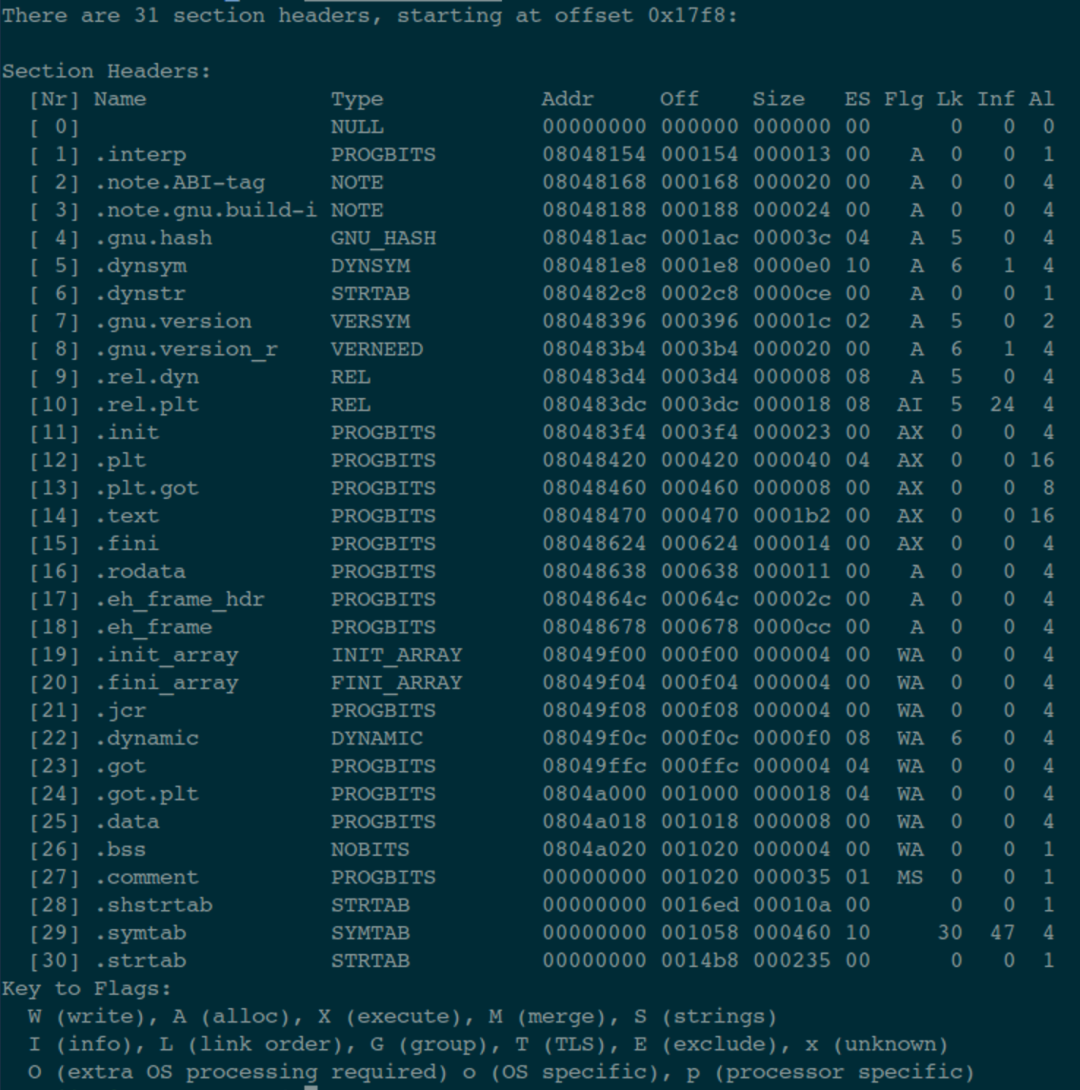
其中的第 28 個 Section,描述的正是字符串表 Section:

可以看出來:這個 Section 在 ELF 文件中的偏移地址是 0x0016ed,長度是 0x00010a 個字節。
下面,我們從 ELF header 的二進制數據中,來推斷這信息。
讀取字符串表 Section 的內容
那我就來演示一下:如何通過 ELF header 中提供的信息,把字符串表這個 Section 給找出來,然后把它的字節碼打印出來給各位看官瞧瞧。
要想打印字符串表 Section 的內容,就必須知道這個 Section 在 ELF 文件中的偏移地址。
要想知道偏移地址,只能從 Section head table 中第 28 個表項描述信息中獲取。
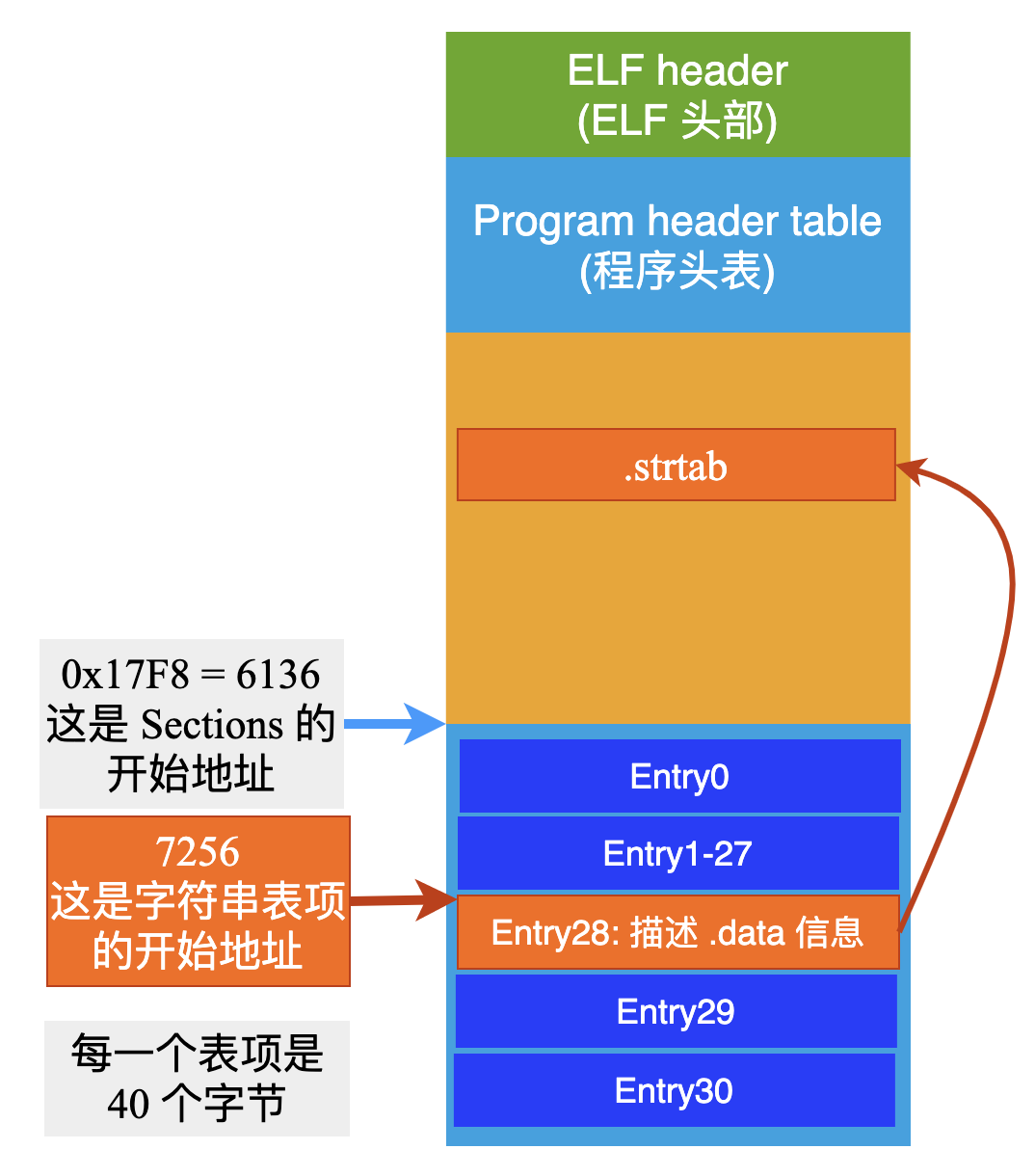
要想知道第 28 個表項的地址,就必須知道 Section head table 在 ELF 文件中的開始地址,以及每一個表項的大小。
正好最后這 2 個需求信息,在 ELF header 中都告訴我們了,因此我們倒著推算,就一定能成功。
ELF header 中的第 32 到 35 字節內容是:F8 17 00 00(注意這里的字節序,低位在前),表示的就是 Section head table 在 ELF 文件中的開始地址(e_shoff)。
0x000017F8 = 6136,也就是說 Section head table 的開始地址位于 ELF 文件的第 6136 個字節處。
知道了開始地址,再來算一下第 28 個表項 Entry 的地址。
ELF header 中的第 46、47 字節內容是:28 00,表示每個表項的長度是 0x0028 = 40 個字節。
注意這里的計算都是從 0 開始的,因此第 28 個表項的開始地址就是:6136 + 28 * 40 = 7256,也就是說用來描述字符串表這個 Section 的表項,位于 ELF 文件的 7256 字節的位置。
既然知道了這個表項 Entry 的地址,那么就扒開來看一下其中的二進制內容:
執行指令:od -Ad -t x1 -j 7256 -N 40 main。
其中的 -j 7256 選項,表示跳過前面的 7256 個字節,也就是我們從 main 這個 ELF 文件的 7256 字節處開始讀取,一共讀 40 個字節。

這 40 個字節的內容,就對應了 Elf32_Shdr 結構體中的每個成員變量:
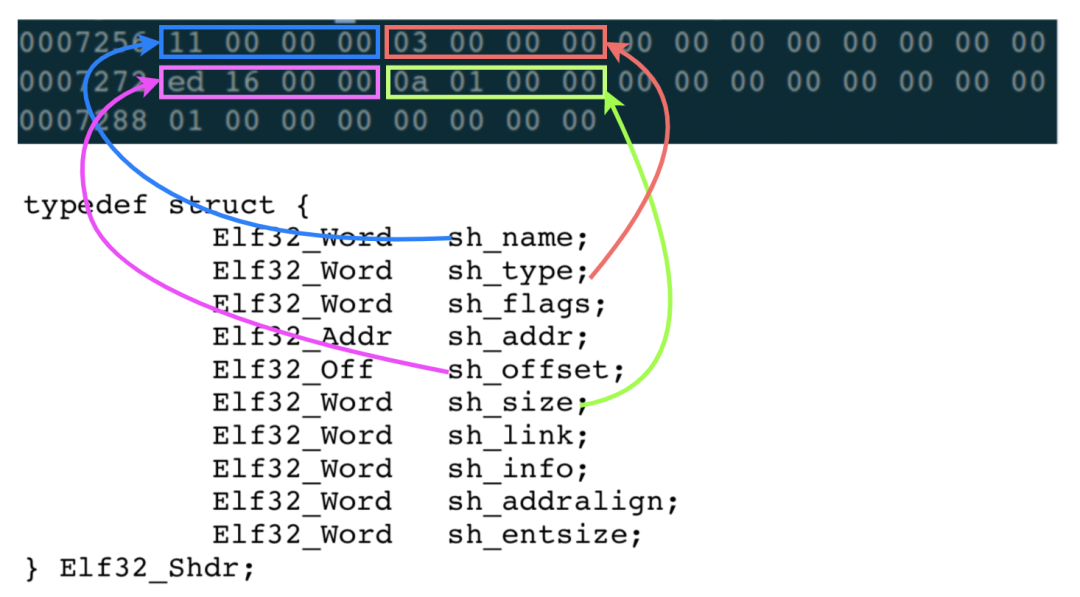
這里主要關注一下上圖中標注出來的 4 個字段:
sh_name: 暫時不告訴你,馬上就解釋到了;
sh_type:表示這個 Section 的類型,3 表示這是一個 string table;
sh_offset: 表示這個 Section,在 ELF 文件中的偏移量。0x000016ed = 5869,意思是字符串表這個 Section 的內容,從 ELF 文件的 5869 個字節處開始;
sh_size:表示這個 Section 的長度。0x0000010a = 266 個字節,意思是字符串表這個 Section 的內容,一共有 266 個字節。
還記得剛才我們使用 readelf 工具,讀取到字符串表 Section 在 ELF 文件中的偏移地址是 0x0016ed,長度是 0x00010a 個字節嗎?
與我們這里的推斷是完全一致的!
既然知道了字符串表這個 Section 在 ELF 文件中的偏移量以及長度,那么就可以把它的字節碼內容讀取出來。
執行指令: od -Ad -t c -j 5869 -N 266 main,所有這些參數應該不用再解釋了吧?!
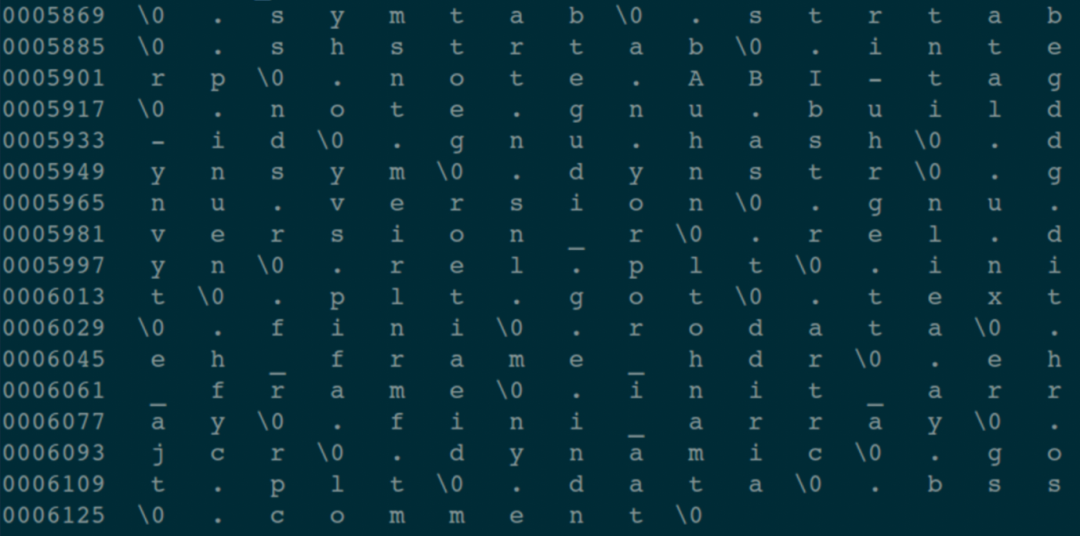
看一看,瞧一瞧,是不是這個 Section 中存儲的全部是字符串?
剛才沒有解釋 sh_name 這個字段,它表示字符串表這個 Section 本身的名字,既然是名字,那一定是個字符串。
但是這個字符串不是直接存儲在這里的,而是存儲了一個索引,索引值是 0x00000011,也就是十進制數值 17。
現在我們來數一下字符串表 Section 內容中,第 17 個字節開始的地方,存儲的是什么?
不要偷懶,數一下,是不是看到了:“.shstrtab” 這個字符串(?是字符串的分隔符)?!
好了,如果看到這里,你全部都能看懂,那么關于字符串表這部分的內容,說明你已經完全理解了,給你一百個贊!!!
讀取代碼段的內容
從下面的這張圖(指令:readelf -S main):
可以看到代碼段是位于第 14 個表項中,加載(虛擬)地址是 0x08048470,它位于 ELF 文件中的偏移量是 0x000470,長度是 0x0001b2 個字節。
那我們就來試著讀一下其中的內容。
首先計算這個表項 Entry 的地址:6136 + 14 * 40 = 6696。
然后讀取這個表項 Entry,讀取指令是 od -Ad -t x1 -j 6696 -N 40 main:

同樣的,我們也只關心下面這 5 個字段內容:
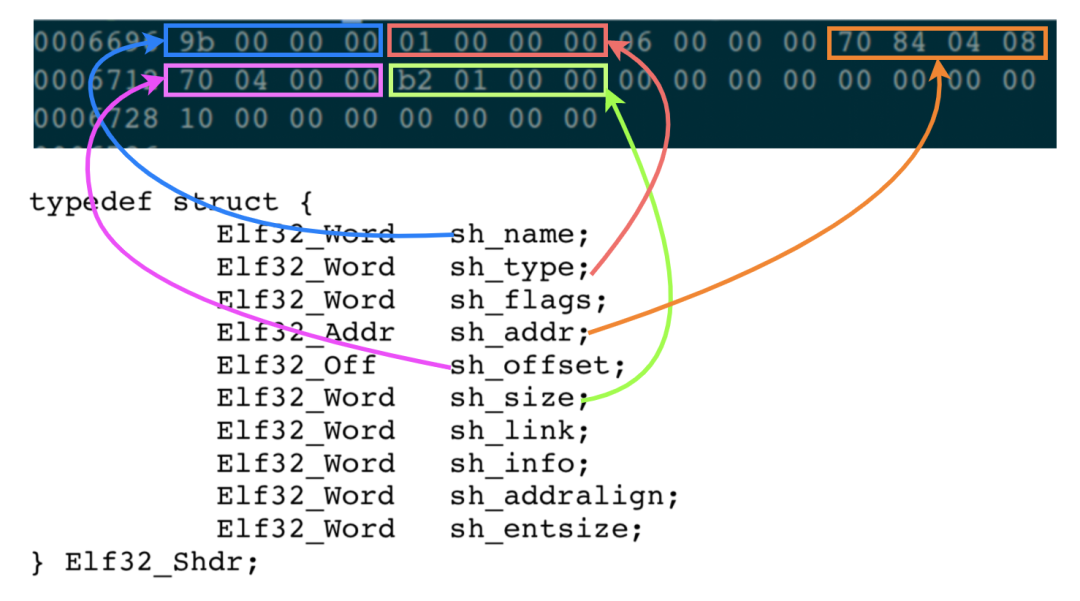
sh_name: 這回應該清楚了,表示代碼段的名稱在字符串表 Section 中的偏移位置。0x9B = 155 字節,也就是在字符串表 Section 的第 155 字節處,存儲的就是代碼段的名字。回過頭去找一下,看一下是不是字符串 “.text”;
sh_type:表示這個 Section 的類型,1(SHT_PROGBITS) 表示這是代碼;
sh_addr:表示這個 Section 加載的虛擬地址是 0x08048470,這個值與 ELF header 中的 e_entry 字段的值是相同的;
sh_offset: 表示這個 Section,在 ELF 文件中的偏移量。0x00000470 = 1136,意思是這個 Section 的內容,從 ELF 文件的 1136 個字節處開始;
sh_size:表示這個 Section 的長度。0x000001b2 = 434 個字節,意思是代碼段一共有 434 個字節。
以上這些分析結構,與指令 readelf -S main 讀取出來的完全一樣!
PS: 在查看字符串表 Section 中的字符串時,不要告訴我,你真的是從 0 開始數到 155 啊!可以計算一下:字符串表的開始地址是 5869(十進制),加上 155,結果就是 6024,所以從 6024 開始的地方,就是代碼段的名稱,也就是 “.text”。
知道了以上這些信息,我們就可以讀取代碼段的字節碼了.使用指令:od -Ad -t x1 -j 1136 -N 434 main 即可。
內容全部是黑乎乎的的字節碼,我就不貼出來了。
Program header
文章的開頭,我就介紹了:我是一個通用的文件結構,鏈接器和加載器在看待我的時候,眼光是不同的。
為了對 Program header 有更感性的認識,我還是先用 readelf 這個工具來從總體上看一下 main 文件中的所有段信息。
執行指令:readelf -l main,得到下面這張圖:
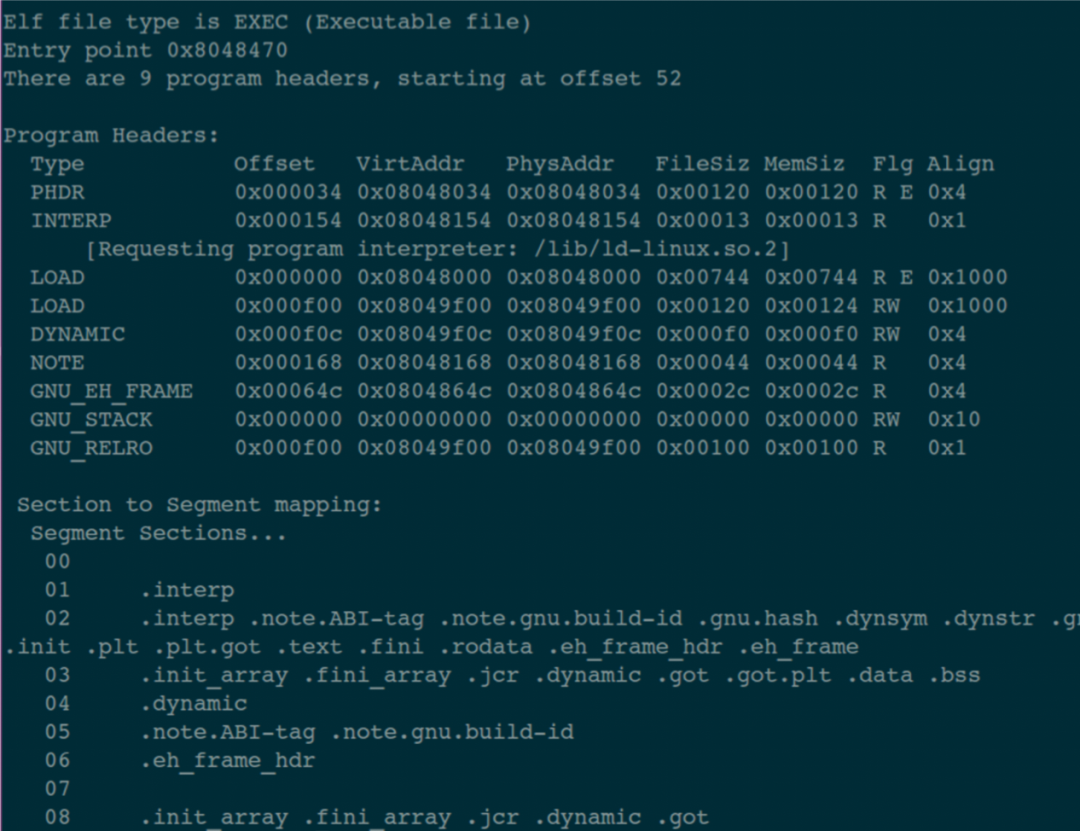
顯示的信息已經很明白了:
這是一個可執行程序;
入口地址是 0x8048470;
一共有 9 個 Program header,是從 ELF 文件的 52 個偏移地址開始的;
布局如下圖所示:
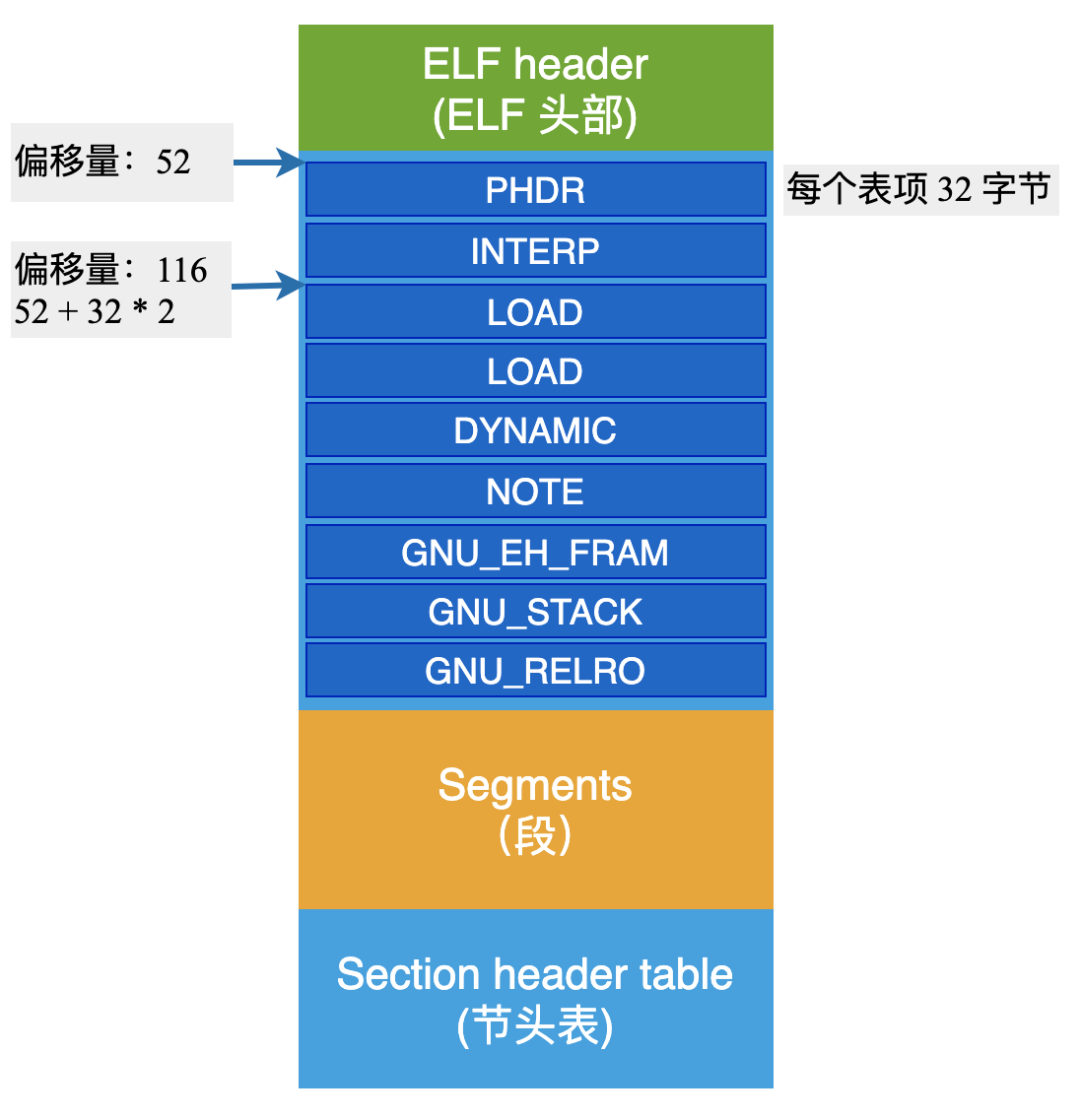
開頭我還告訴過你:Section 與 Segment 本質上是一樣的,可以理解為:一個 Secgment 由一個或多個 Sections 組成。
從上圖中可以看到,第 2 個 program header 這個段,由那么多的 Section 組成,這下更明白一些了吧?!
從圖中還可以看到,一共有 2 個 LOAD 類型的段:

我們來讀取第一個 LOAD 類型的段,當然還是扒開其中的二進制字節碼。
第一步的工作是,計算這個段表項的地址信息。
從 ELF header 中得知如下信息:
字段 e_phoff :Program header table 位于 ELF 文件偏移 52 個字節的地方。
字段 e_phentsize: 每一個表項的長度是 32 個字節;
字段 e_phnum: 一共有 9 個表項 Entry;
通過計算,得到可讀、可執行的 LOAD 段,位于偏移量 116 字節處。
執行讀取指令:od -Ad -t x1 -j 116 -N 32 main:

按照上面的慣例,我還是把其中幾個需要關注的字段,與數據結構中的成員變量進行關聯一下:
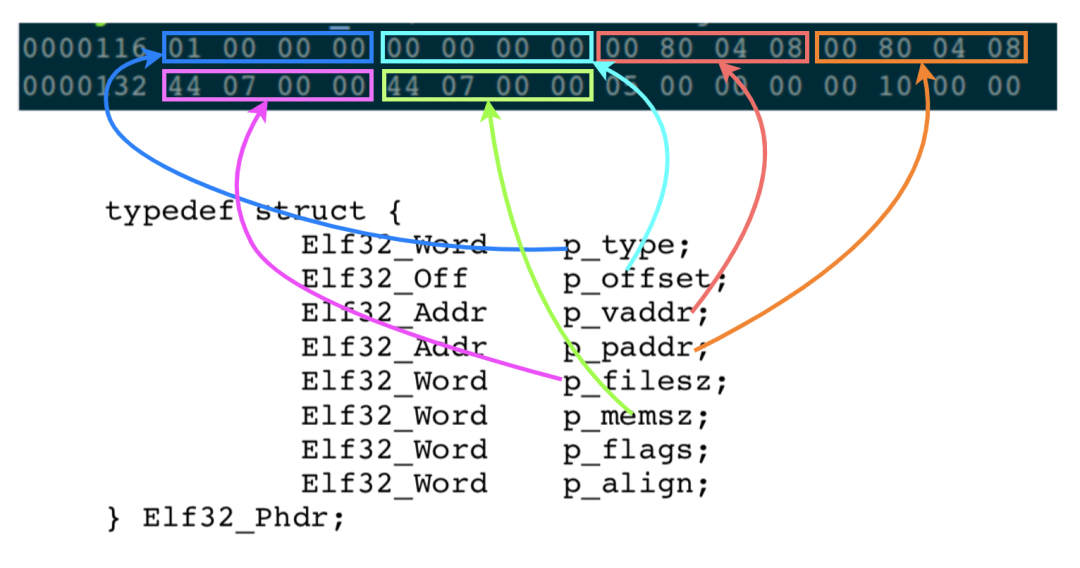
p_type: 段的類型,1: 表示這個段需要加載到內存中;
p_offset: 段在 ELF 文件中的偏移地址,這里值為 0,表示這個段從 ELF 文件的頭部開始;
p_vaddr:段加載到內存中的虛擬地址 0x08048000;
p_paddr:段加載的物理地址,與虛擬地址相同;
p_filesz: 這個段在 ELF 文件中,占據的字節數,0x0744 = 1860 個字節;
p_memsz:這個段加載到內存中,需要占據的字節數,0x0744= 1860 個字節。注意:有些段是不需要加載到內存中的;
經過上述分析,我們就知道:從 ELF 文件的第 1 到 第 1860 個字節,都是屬于這個 LOAD 段的內容。
在被執行時,這個段需要被加載到內存中虛擬地址為 0x08048000 這個地方,從這里開始,又是一個全新的故事了。
再回顧一下
到這里,我已經像洋蔥一樣,把自己的層層外衣都扒開,讓你看到最細的顆粒度了,這下子,您是否對我有足夠的了解了呢?
其實只要抓住下面 2 個重點即可:
ELF header 描述了文件的總體信息,以及兩個 table 的相關信息(偏移地址,表項個數,表項長度);
每一個 table 中,包括很多個表項 Entry,每一個表項都描述了一個 Section/Segment 的具體信息。
鏈接器和加載器也都是按照這樣的原理來解析 ELF 文件的,明白了這些道理,后面在學習具體的鏈接、加載過程時,就不會迷路啦!
原文標題:Linux 系統中編譯、鏈接的基石 - ELF 文件:扒開它的層層外衣,從字節碼的粒度來探索
文章出處:【微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
-
Linux系統
+關注
關注
4文章
593瀏覽量
27392 -
程序
+關注
關注
117文章
3785瀏覽量
81004 -
ELF文件
+關注
關注
0文章
14瀏覽量
7134
原文標題:Linux 系統中編譯、鏈接的基石 - ELF 文件:扒開它的層層外衣,從字節碼的粒度來探索
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
為什么STM32CubeMonitor 1.2.0不解析在Release模式下的.elf 文件中全局變量呢
i.MX6ULL——ElfBoard ELF1板卡 windows 與 ubuntu 系統互傳文件 的方法
Linux文件系統課程

Linux日志文件系統解析
嵌入式bin文件和elf文件重點
簡單介紹一下Linux中ELF格式文件
Linux下可執行文件格式
Linux文件系統解析
單片機燒錄hex文件是如何解析

如何關聯ELF輸出文件并使用vivado對系統進行行為仿真
用于讀取ELF格式文件的詳細信息的命令:readelf命令





 工商網監
工商網監
評論