 如何在主機和主機之間實現數據傳輸優化
如何在主機和主機之間實現數據傳輸優化
主機和設備之間的傳輸是 GPU 計算中數據移動最慢的一個環節,所以您應該注意盡量減少傳輸。遵循這篇文章中的指導方針可以幫助你確保必要的轉移是有效的。當您移植或編寫新的 CUDA C / C ++代碼時,我建議您從現有主機指針開始可分頁的傳輸。正如我前面提到的,當您編寫更多的設備代碼時,您將消除一些中間傳輸,因此您在移植早期所花費的優化傳輸的任何努力都可能被浪費。另外,我建議您不要使用 CUDA 事件或其他計時器插入代碼來測量每次傳輸所花費的時間,而是建議您使用 nvprof, 命令行 CUDA 探查器,或者使用可視化分析工具,如 NVIDIA 可視化探查器(也包括在 CUDA 工具箱中)。
這篇文章的重點是提高數據傳輸的效率。在 下一篇文章 中,我們討論了如何將數據傳輸與計算和其他數據傳輸重疊。
在 C + C ++系列 之前的 帖子 中,我們為該系列的主要推力奠定了基礎:如何優化 CUDA C / C ++代碼。本文就如何在主機和主機之間高效地傳輸數據展開討論。設備內存和 GPU 之間的峰值帶寬遠高于主機內存和設備內存之間的峰值帶寬(例如,在 GPU NVIDIA C2050 上為 144 GB / s ),而在 PCIe x16 Gen2 上為 8 GB / s 。這種差異意味著主機和 GPU 設備之間的數據傳輸的實現可能會影響或破壞應用程序的整體性能。讓我們從主機數據傳輸的一般原則開始。
盡可能減少主機和設備之間傳輸的數據量,即使這意味著在 GPU 上運行內核,與在主機 CPU 上運行內核相比,其速度幾乎沒有或幾乎沒有。
使用頁鎖定(或“固定”)內存時,主機和設備之間的帶寬可能更高。
將許多小的傳輸批處理到一個較大的傳輸中執行得更好,因為它消除了每個傳輸的大部分開銷。
主機和設備之間的數據傳輸有時可能與內核執行和其他數據傳輸重疊。
在這篇文章中,我們將研究上面的前三條準則,并在下一篇文章中專門討論重疊數據傳輸。首先,我想談談如何在不修改源代碼的情況下測量數據傳輸所花費的時間。
用 nvprof 測量數據傳輸時間
為了測量每次數據傳輸所花費的時間,我們可以在每次傳輸前后記錄一個 CUDA 事件,并使用 cudaEventElapsedTime() ,正如我們所描述的 在上一篇文章中 , CUDA 工具箱中包含的命令行 CUDA 探查器(從 CUDA 5 開始)。讓我們用下面的代碼示例來嘗試一下,您可以在 CUDA 中找到它。
int main() { const unsigned int N = 1048576; const unsigned int bytes = N * sizeof(int); int *h_a = (int*)malloc(bytes); int *d_a; cudaMalloc((int**)&d_a, bytes); memset(h_a, 0, bytes); cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice); cudaMemcpy(h_a, d_a, bytes, cudaMemcpyDeviceToHost); return 0; }
為了分析這段代碼,我們只需使用nvcc編譯它,然后用程序文件名作為參數運行nvprof。
$ nvcc profile.cu -o profile_test $ nvprof ./profile_test
當我在臺式電腦上運行時,它有一個 geforcegtx680 ( GK104GPU ,類似于 Tesla K10 ),我得到以下輸出。
$ nvprof ./a.out ======== NVPROF is profiling a.out... ======== Command: a.out ======== Profiling result: Time(%) Time Calls Avg Min Max Name 50.08 718.11us 1 718.11us 718.11us 718.11us [CUDA memcpy DtoH] 49.92 715.94us 1 715.94us 715.94us 715.94us [CUDA memcpy HtoD]
如您所見, nvprof 測量每個 CUDA memcpy 調用所花費的時間。它報告每個調用的平均、最小和最長時間(因為我們只運行每個副本一次,所有時間都是相同的)。 nvprof 非常靈活,所以請確保 查看文檔 。
nvprof 是 CUDA 5 中的新功能。如果您使用的是早期版本的 CUDA ,那么可以使用舊的“命令行分析器”,正如 Greg Ruetsch 在他的文章 如何在 CUDA Fortran 中優化數據傳輸 中所解釋的那樣。
最小化數據傳輸
我們不應該只使用內核的 GPU 執行時間相對于其 CPU 實現的執行時間來決定是運行 GPU 還是 CPU 版本。我們還需要考慮在 PCI-e 總線上移動數據的成本,尤其是當我們最初將代碼移植到 CUDA 時。因為 CUDA 的異構編程模型同時使用了 CPU 和 GPU ,代碼可以一次移植到 CUDA 一個內核。在移植的初始階段,數據傳輸可能支配整個執行時間。將數據傳輸所花費的時間與內核執行的時間分開記錄是值得的。正如我們已經演示過的,使用命令行探查器很容易做到這一點。隨著我們移植更多的代碼,我們將刪除中間傳輸并相應地減少總體執行時間。
固定主機內存
默認情況下,主機( CPU )的數據分配是可分頁的。 GPU 無法直接從可分頁主機內存訪問數據,因此當調用從可分頁主機內存到設備內存的數據傳輸時, CUDA 驅動程序必須首先分配一個臨時頁鎖定或“固定”主機數組,將主機數據復制到固定數組,然后將數據從固定數組傳輸到設備內存,如下圖所示。
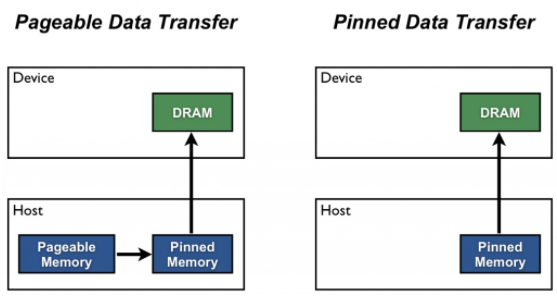
如圖中所示,固定內存用作從設備到主機的傳輸的臨時區域。通過直接將主機數組分配到固定內存中,可以避免在可分頁主機數組和固定主機數組之間進行傳輸的開銷。使用 CUDA 或 cudaHostAlloc() 在 CUDA C / C ++中分配被鎖定的主機內存,并用 cudaFreeHost() 解除它。固定內存分配可能會失敗,因此應該始終檢查錯誤。下面的代碼摘要演示如何分配固定內存以及錯誤檢查。
cudaError_t status = cudaMallocHost((void**)&h_aPinned, bytes); if (status != cudaSuccess) printf("Error allocating pinned host memory ");
使用主機固定內存的數據傳輸使用與可分頁內存傳輸相同的cudaMemcpy()語法。我們可以使用下面的“帶寬測試”程序(Github 上也有)來比較可分頁和固定的傳輸速率。
#include#include // Convenience function for checking CUDA runtime API results // can be wrapped around any runtime API call. No-op in release builds. inline cudaError_t checkCuda(cudaError_t result) { #if defined(DEBUG) || defined(_DEBUG) if (result != cudaSuccess) { fprintf(stderr, "CUDA Runtime Error: %s\n", cudaGetErrorString(result)); assert(result == cudaSuccess); } #endif return result; } void profileCopies(float *h_a, float *h_b, float *d, unsigned int n, char *desc) { printf("\n%s transfers\n", desc); unsigned int bytes = n * sizeof(float); // events for timing cudaEvent_t startEvent, stopEvent; checkCuda( cudaEventCreate(&startEvent) ); checkCuda( cudaEventCreate(&stopEvent) ); checkCuda( cudaEventRecord(startEvent, 0) ); checkCuda( cudaMemcpy(d, h_a, bytes, cudaMemcpyHostToDevice) ); checkCuda( cudaEventRecord(stopEvent, 0) ); checkCuda( cudaEventSynchronize(stopEvent) ); float time; checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) ); printf(" Host to Device bandwidth (GB/s): %f\n", bytes * 1e-6 / time); checkCuda( cudaEventRecord(startEvent, 0) ); checkCuda( cudaMemcpy(h_b, d, bytes, cudaMemcpyDeviceToHost) ); checkCuda( cudaEventRecord(stopEvent, 0) ); checkCuda( cudaEventSynchronize(stopEvent) ); checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) ); printf(" Device to Host bandwidth (GB/s): %f\n", bytes * 1e-6 / time); for (int i = 0; i < n; ++i) { if (h_a[i] != h_b[i]) { printf("*** %s transfers failed ***\n", desc); break; } } // clean up events checkCuda( cudaEventDestroy(startEvent) ); checkCuda( cudaEventDestroy(stopEvent) ); } int main() { unsigned int nElements = 4*1024*1024; const unsigned int bytes = nElements * sizeof(float); // host arrays float *h_aPageable, *h_bPageable; float *h_aPinned, *h_bPinned; // device array float *d_a; // allocate and initialize h_aPageable = (float*)malloc(bytes); // host pageable h_bPageable = (float*)malloc(bytes); // host pageable checkCuda( cudaMallocHost((void**)&h_aPinned, bytes) ); // host pinned checkCuda( cudaMallocHost((void**)&h_bPinned, bytes) ); // host pinned checkCuda( cudaMalloc((void**)&d_a, bytes) ); // device for (int i = 0; i < nElements; ++i) h_aPageable[i] = i; memcpy(h_aPinned, h_aPageable, bytes); memset(h_bPageable, 0, bytes); memset(h_bPinned, 0, bytes); // output device info and transfer size cudaDeviceProp prop; checkCuda( cudaGetDeviceProperties(&prop, 0) ); printf("\nDevice: %s\n", prop.name); printf("Transfer size (MB): %d\n", bytes / (1024 * 1024)); // perform copies and report bandwidth profileCopies(h_aPageable, h_bPageable, d_a, nElements, "Pageable"); profileCopies(h_aPinned, h_bPinned, d_a, nElements, "Pinned"); printf("n"); // cleanup cudaFree(d_a); cudaFreeHost(h_aPinned); cudaFreeHost(h_bPinned); free(h_aPageable); free(h_bPageable); return 0; }
數據傳輸速率取決于主機系統的類型(主板, CPU 和芯片組)以及 GPU 。在我的筆記本電腦上,它有 Intel Core i7-2620MCPU ( 2 . 7GHz , 2 個 Sandy Bridge 內核, 4MB L3 緩存)和 NVIDIA NVS 4200MGPU ( 1 費米 SM ,計算能力 2 . 1 , PCI-e Gen2 x16 ),運行BandwidthTest會產生以下結果。如您所見,固定傳輸的速度是可分頁傳輸的兩倍多。
Device: NVS 4200M Transfer size (MB): 16 Pageable transfers Host to Device bandwidth (GB/s): 2.308439 Device to Host bandwidth (GB/s): 2.316220 Pinned transfers Host to Device bandwidth (GB/s): 5.774224 Device to Host bandwidth (GB/s): 5.958834
更快速的 3GHz 處理器( 3GHz , 3GHz )和 3K 處理器( 3GHz )相比,我們可以更快地使用 3K 處理器( 3GHz )和 3GHz 處理器。這大概是因為更快的 CPU (和芯片組)降低了主機端的內存復制成本。
Device: GeForce GTX 680 Transfer size (MB): 16 Pageable transfers Host to Device bandwidth (GB/s): 5.368503 Device to Host bandwidth (GB/s): 5.627219 Pinned transfers Host to Device bandwidth (GB/s): 6.186581 Device to Host bandwidth (GB/s): 6.670246
不應過度分配固定內存。這樣做會降低整體系統性能,因為這會減少操作系統和其他程序可用的物理內存量。多少是太多是很難預先判斷的,所以對于所有優化,測試您的應用程序和它們運行的系統,以獲得最佳性能參數。
批量小轉移
由于與每個傳輸相關聯的開銷,最好將多個小傳輸一起批處理到單個傳輸中。通過使用一個臨時數組(最好是固定的)并將其與要傳輸的數據打包,這很容易做到。
對于二維數組傳輸,可以使用 cudaMemcpy2D() 。
cudaMemcpy2D(dest, dest_pitch, src, src_pitch, w, h, cudaMemcpyHostToDevice)
這里的參數是指向第一個目標元素和目標數組間距的指針,指向第一個源元素和源數組間距的指針,要傳輸的子矩陣的寬度和高度,以及 memcpy 類型。還有一個 cudaMemcpy3D() 函數用于傳輸秩為三的數組部分。
關于作者
Mark Harris 是 NVIDIA 杰出的工程師,致力于 RAPIDS 。 Mark 擁有超過 20 年的 GPUs 軟件開發經驗,從圖形和游戲到基于物理的模擬,到并行算法和高性能計算。當他還是北卡羅來納大學的博士生時,他意識到了一種新生的趨勢,并為此創造了一個名字: GPGPU (圖形處理單元上的通用計算)。
審核編輯:郭婷
-
gpu
+關注
關注
28文章
4729瀏覽量
128890 -
計時器
+關注
關注
1文章
420瀏覽量
32689
發布評論請先 登錄
相關推薦
PCIe數據傳輸協議詳解
socket 數據傳輸效率提升技巧
CAN總線數據傳輸速率設置
LORA模塊的數據傳輸速率
網絡數據傳輸速率的單位是什么
usb主機模式和設備模式的區別
SD NAND應用存儲功能描述(5)數據傳輸
二總線——MCU有線數據傳輸
探索SPI單線傳輸模式中時鐘線與數據傳輸的簡化

DTU的多種協議,解鎖數據傳輸的無限可能






 工商網監
工商網監
評論