") 如何在CUDA C/C++中實(shí)現(xiàn)數(shù)據(jù)傳輸和其他操作的重疊
如何在CUDA C/C++中實(shí)現(xiàn)數(shù)據(jù)傳輸和其他操作的重疊
在上一期的 C / C ++ 文章 中,我們討論了如何在主機(jī)和設(shè)備之間高效地傳輸數(shù)據(jù)。在這篇文章中,我們討論了如何將數(shù)據(jù)傳輸與主機(jī)上的計(jì)算、設(shè)備上的計(jì)算相重疊,在某些情況下,主機(jī)和設(shè)備之間的其他數(shù)據(jù)傳輸。實(shí)現(xiàn)數(shù)據(jù)傳輸和其他操作之間的重疊需要使用 CUDA 流,所以首先讓我們了解一下流。
CUDA 流
CUDA 中的 stream 是按照主機(jī)代碼發(fā)出的順序在設(shè)備上執(zhí)行的操作序列。雖然流中的操作被保證按規(guī)定的順序執(zhí)行,但是不同流中的操作可以被交錯(cuò),并且在可能的情況下,它們甚至可以并發(fā)運(yùn)行。
默認(rèn)流
CUDA 中的所有設(shè)備操作(內(nèi)核和數(shù)據(jù)傳輸)都在一個(gè)流中運(yùn)行。如果沒有指定流,則使用默認(rèn)流(也稱為“空流”)。默認(rèn)流與其他流不同,因?yàn)樗顷P(guān)于設(shè)備上操作的同步流:在所有先前發(fā)出的操作 在設(shè)備上的任何流中 完成之前,默認(rèn)流中的任何操作都不會(huì)開始,并且默認(rèn)流中的操作必須在任何其他操作(在設(shè)備上的任何流中)之前完成就要開始了。
請(qǐng)注意, 2015 年發(fā)布的 CUDA 7 引入了一個(gè)新的選項(xiàng),即每個(gè)主機(jī)線程使用單獨(dú)的默認(rèn)流,并將每個(gè)線程的默認(rèn)流視為常規(guī)流(即它們不與其他流中的操作同步)。在文章 GPU 專業(yè)提示: CUDA 7 流簡(jiǎn)化并發(fā) 中閱讀更多關(guān)于這種新行為的信息。
讓我們看一些使用默認(rèn)流的簡(jiǎn)單代碼示例,并從主機(jī)和設(shè)備的角度討論操作是如何進(jìn)行的。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); increment<<<1,N>>>(d_a) cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
在上面的代碼中,從設(shè)備的角度來看,所有三個(gè)操作都被發(fā)布到同一個(gè)(默認(rèn))流中,并將按照它們發(fā)出的順序執(zhí)行。
從主機(jī)的角度看,隱式數(shù)據(jù)傳輸是阻塞或同步傳輸,而內(nèi)核啟動(dòng)是異步的。由于第一行上的主機(jī)到設(shè)備的數(shù)據(jù)傳輸是同步的, CPU 線程在主機(jī)到設(shè)備的傳輸完成之前不會(huì)到達(dá)第二行的內(nèi)核調(diào)用。一旦內(nèi)核被發(fā)出, CPU 線程將移動(dòng)到第三行,但由于設(shè)備端的執(zhí)行順序,該行上的傳輸無法開始。
內(nèi)核從主機(jī)的角度啟動(dòng)的異步行為使得重疊的設(shè)備和主機(jī)計(jì)算非常簡(jiǎn)單。我們可以修改代碼以添加一些獨(dú)立的 CPU 計(jì)算,如下所示。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); increment<<<1,N>>>(d_a) myCpuFunction(b) cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);
在上面的代碼中,一旦 increment() 內(nèi)核在設(shè)備上啟動(dòng), CPU 線程就執(zhí)行 myCpuFunction() ,它在 CPU 上的執(zhí)行與在 GPU 上的內(nèi)核執(zhí)行重疊。無論是主機(jī)功能還是設(shè)備內(nèi)核先完成,都不會(huì)影響后續(xù)的設(shè)備到主機(jī)的傳輸,只有在內(nèi)核完成后才會(huì)開始,從設(shè)備的角度來看,上一個(gè)例子沒有什么變化,設(shè)備完全不知道 myCpuFunction() 。
非默認(rèn)流
在下面的代碼中, CUDA C / C ++的非默認(rèn)流被聲明、創(chuàng)建和銷毀。
cudaStream_t stream1; cudaError_t result; result = cudaStreamCreate(&stream1) result = cudaStreamDestroy(stream1)
為了向非默認(rèn)流發(fā)出數(shù)據(jù)傳輸,我們使用了cudaMemcpyAsync()函數(shù),它類似于前一篇文章中討論的cudaMemcpy()函數(shù),但將流標(biāo)識(shí)符作為第五個(gè)參數(shù)。
result = cudaMemcpyAsync(d_a, a, N, cudaMemcpyHostToDevice, stream1)
cudaMemcpyAsync() 在主機(jī)上是非阻塞的,因此在發(fā)出傳輸之后,控制權(quán)立即返回到主機(jī)線程。此例程有 cudaMemcpy2DAsync() 和 cudaMemcpy3DAsync() 變體,它們可以在指定的流中異步傳輸 2D 和 3D 數(shù)組部分。
為了向非默認(rèn)流發(fā)出內(nèi)核,我們將流標(biāo)識(shí)符指定為第四個(gè)執(zhí)行配置參數(shù)(第三個(gè)執(zhí)行配置參數(shù)分配共享設(shè)備內(nèi)存,我們將在后面討論;現(xiàn)在使用 0 )。
increment<<<1,N,0,stream1>>>(d_a)
與流同步
由于非默認(rèn)流中的所有操作相對(duì)于宿主代碼都是非阻塞的,因此您將遇到需要將宿主代碼與流中的操作同步的情況。“重錘”的方法是使用 cudaDeviceSynchronize() ,它會(huì)阻止主機(jī)代碼,直到之前在設(shè)備上發(fā)出的所有操作都完成為止。在大多數(shù)情況下,這是一種過度殺戮,并且會(huì)由于整個(gè)設(shè)備和主機(jī)線程的暫停而影響性能。
CUDA 流 API 有多種不太嚴(yán)格的同步主機(jī)與流的方法。函數(shù) cudaStreamSynchronize(stream) 可用于阻止主機(jī)線程,直到指定流中以前發(fā)出的所有操作都已完成。函數(shù) cudaStreamQuery(stream) 測(cè)試向指定流發(fā)出的所有操作是否已完成,而不阻止主機(jī)執(zhí)行。函數(shù) cudaEventSynchronize(event) 和 cudaEventQuery(event) 的行為與它們的流對(duì)應(yīng)項(xiàng)相似,只是它們的結(jié)果基于是否記錄了指定的事件,而不是基于指定的流是否空閑。您還可以使用 cudaStreamWaitEvent ( event )在單個(gè)流中同步特定事件的操作(即使事件記錄在不同的流中,或者記錄在不同的設(shè)備上)。
重疊的內(nèi)核執(zhí)行和數(shù)據(jù)傳輸
前面我們演示了如何將默認(rèn)流中的內(nèi)核執(zhí)行與主機(jī)上的代碼執(zhí)行重疊。但我們?cè)谶@篇文章中的主要目標(biāo)是向您展示如何將內(nèi)核執(zhí)行與數(shù)據(jù)傳輸重疊。要做到這一點(diǎn)有幾個(gè)要求。
設(shè)備必須能夠“并發(fā)復(fù)制和執(zhí)行”。這可以從 cudaDeviceProp 結(jié)構(gòu)的 deviceOverlap 字段或從 CUDA SDK / Toolkit 附帶的 deviceQuery 示例的輸出中進(jìn)行查詢。幾乎所有具有計(jì)算能力 1 。 1 及更高版本的設(shè)備都具有此功能。
要重疊的內(nèi)核執(zhí)行和數(shù)據(jù)傳輸必須同時(shí)發(fā)生在 different 、 non-default 流中。
數(shù)據(jù)傳輸所涉及的主機(jī)內(nèi)存必須是 pinned 內(nèi)存。
因此,讓我們從上面修改我們的簡(jiǎn)單主機(jī)代碼,以使用多個(gè)流,看看是否可以實(shí)現(xiàn)任何重疊。這個(gè)例子的完整代碼是 在 Github 上提供 。在修改后的代碼中,我們將大小為 N 的數(shù)組分解為 streamSize 元素的塊。由于內(nèi)核對(duì)所有元素都是獨(dú)立操作的,因此每個(gè)塊都可以獨(dú)立處理。使用的(非默認(rèn))流數(shù)為 nStreams=N/streamSize 。有多種方法可以實(shí)現(xiàn)數(shù)據(jù)的域分解和處理;一種方法是循環(huán)使用數(shù)組中每個(gè)塊的所有操作,如本示例代碼所示。
for (int i = 0; i < nStreams; ++i) { int offset = i * streamSize; cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]); kernel<<>>(d_a, offset); cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, stream[i]); }
另一種方法是將類似的操作批處理在一起,首先發(fā)出所有主機(jī)到設(shè)備的傳輸,然后是所有的內(nèi)核啟動(dòng),然后是所有設(shè)備到主機(jī)的傳輸,如下面的代碼所示。
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset],
streamBytes, cudaMemcpyHostToDevice, cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
kernel<<>>(d_a, offset);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&a[offset], &d_a[offset],
streamBytes, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToHost, stream[i]);
}
上面顯示的兩個(gè)異步方法都會(huì)產(chǎn)生正確的結(jié)果,并且在這兩種情況下,依賴操作都會(huì)按照它們需要執(zhí)行的順序發(fā)布到同一個(gè)流。但根據(jù)所使用的 GPU 的特定代數(shù),這兩種方法的性能截然不同。在 Tesla C1060 (計(jì)算能力 1 。 3 )上運(yùn)行測(cè)試代碼(來自 Github )給出以下結(jié)果。
Device : Tesla C1060 Time for sequential transfer and execute (ms ): 12.92381 max error : 2.3841858E -07 Time for asynchronous V1 transfer and execute (ms ): 13.63690 max error : 2.3841858E -07 Time for asynchronous V2 transfer and execute (ms ): 8.84588 max error : 2.3841858E -07
在 Tesla C2050 (計(jì)算能力 2 . 0 )上,我們得到以下結(jié)果。
Device : Tesla C2050 Time for sequential transfer and execute (ms ): 9.984512 max error : 1.1920929e -07 Time for asynchronous V1 transfer and execute (ms ): 5.735584 max error : 1.1920929e -07 Time for asynchronous V2 transfer and execute (ms ): 7.597984 max error : 1.1920929e -07
這里第一次報(bào)告的是使用阻塞傳輸?shù)捻樞騻鬏敽蛢?nèi)核執(zhí)行,我們將其作為異步加速比較的基線。為什么這兩種異步策略在不同的體系結(jié)構(gòu)上表現(xiàn)不同?要破解這些結(jié)果,我們需要更多地了解 CUDA 設(shè)備如何調(diào)度和執(zhí)行任務(wù)。 CUDA 設(shè)備包含用于各種任務(wù)的引擎,這些引擎在發(fā)出操作時(shí)對(duì)操作進(jìn)行排隊(duì)。不同引擎中的任務(wù)之間的依賴關(guān)系得到維護(hù),但是在任何引擎中,所有外部依賴關(guān)系都會(huì)丟失;每個(gè)引擎隊(duì)列中的任務(wù)將按照它們的發(fā)出順序執(zhí)行。 C1060 有一個(gè)拷貝引擎和一個(gè)內(nèi)核引擎。在 C1060 上執(zhí)行示例代碼的時(shí)間線如下圖所示。
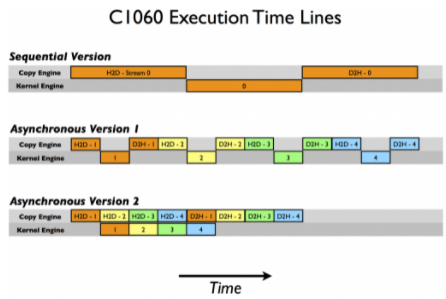
在這個(gè)示意圖中,我們假設(shè)主機(jī)到設(shè)備傳輸、內(nèi)核執(zhí)行和設(shè)備到主機(jī)傳輸所需的時(shí)間大致相同(選擇內(nèi)核代碼是為了實(shí)現(xiàn)這一點(diǎn))。正如順序內(nèi)核所期望的那樣,任何操作中都沒有重疊。對(duì)于我們代碼的第一個(gè)異步版本,復(fù)制引擎中的執(zhí)行順序是: H2D stream ( 1 )、 D2H stream ( 1 )、 H2D stream ( 2 )、 D2H stream ( 2 )等等。這就是為什么我們?cè)?C1060 上使用第一個(gè)異步版本時(shí)看不到任何加速:任務(wù)是按照排除內(nèi)核執(zhí)行和數(shù)據(jù)傳輸重疊的順序被發(fā)送到復(fù)制引擎的。然而,對(duì)于版本 2 ,在所有主機(jī)到設(shè)備的傳輸在任何設(shè)備到主機(jī)的傳輸之前發(fā)出,重疊是可能的,如較低的執(zhí)行時(shí)間所示。根據(jù)我們的示意圖,我們期望異步版本 2 的執(zhí)行時(shí)間是順序版本的 8 / 12 ,或者 8 。 7ms ,這在前面給出的計(jì)時(shí)結(jié)果中得到了確認(rèn)。
在 C2050 上,兩個(gè)功能相互作用導(dǎo)致與 C1060 不同的行為。 C2050 有兩個(gè)復(fù)制引擎,一個(gè)用于主機(jī)到設(shè)備的傳輸,另一個(gè)用于設(shè)備到主機(jī)的傳輸,以及一個(gè)內(nèi)核引擎。下圖說明了我們的示例在 C2050 上的執(zhí)行。
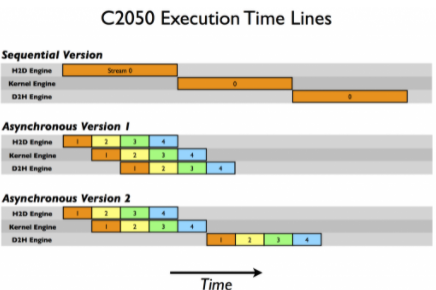
有兩個(gè)復(fù)制引擎解釋了為什么異步版本 1 在 C2050 上實(shí)現(xiàn)了很好的加速:流[i] 不阻止流中數(shù)據(jù)的主機(jī)到設(shè)備傳輸 [i + 1]中數(shù)據(jù)的主機(jī)到設(shè)備的傳輸,因?yàn)?C2050 上的每個(gè)復(fù)制方向都有一個(gè)單獨(dú)的引擎。示意圖預(yù)測(cè)了執(zhí)行情況相對(duì)于順序版本,時(shí)間被縮短一半,這大致就是我們的計(jì)時(shí)結(jié)果顯示的。
但是在 C2050 上的異步版本 2 中觀察到的性能下降呢?這與 C2050 并發(fā)運(yùn)行多個(gè)內(nèi)核的能力有關(guān)。當(dāng)多個(gè)內(nèi)核在不同(非默認(rèn))流中背靠背地發(fā)出時(shí),調(diào)度程序嘗試啟用這些內(nèi)核的并發(fā)執(zhí)行,結(jié)果會(huì)延遲通常在每個(gè)內(nèi)核完成后出現(xiàn)的信號(hào)(這負(fù)責(zé)啟動(dòng)設(shè)備到主機(jī)的傳輸),直到所有內(nèi)核完成。因此,雖然在第二個(gè)版本的異步代碼中,主機(jī)到設(shè)備的傳輸和內(nèi)核的執(zhí)行之間有重疊,但是內(nèi)核執(zhí)行和設(shè)備到主機(jī)的傳輸之間沒有重疊。示意圖預(yù)測(cè)異步版本 2 的總時(shí)間是順序版本的 9 / 12 ,即 7 。 5 毫秒,這一點(diǎn)由我們的計(jì)時(shí)結(jié)果證實(shí)。
CUDA Fortran 異步數(shù)據(jù)傳輸 中提供了關(guān)于本文中使用的示例的更詳細(xì)的描述,好消息是對(duì)于具有計(jì)算能力 3 。 5 ( K20 系列)的設(shè)備, Hyper-Q 特性消除了定制發(fā)布順序的需要,因此上述任何一種方法都可以工作。我們將在以后的文章中討論使用開普勒特性,但是現(xiàn)在,這里是在 Tesla K20c GPU 上運(yùn)行示例代碼的結(jié)果。如您所見,這兩個(gè)異步方法在同步代碼上實(shí)現(xiàn)了相同的加速。
Device : Tesla K20c Time for sequential transfer and execute (ms): 7.101760 max error : 1.1920929e -07 Time for asynchronous V1 transfer and execute (ms): 3.974144 max error : 1.1920929e -07 Time for asynchronous V2 transfer and execute (ms): 3.967616 max error : 1.1920929e -07
概括
這篇文章和 上一個(gè) 討論了如何優(yōu)化主機(jī)和設(shè)備之間的數(shù)據(jù)傳輸。上一篇文章集中討論了如何最小化執(zhí)行這種傳輸?shù)臅r(shí)間,這篇文章介紹了流,以及如何使用流通過并發(fā)執(zhí)行副本和內(nèi)核來屏蔽數(shù)據(jù)傳輸時(shí)間。
在一篇關(guān)于流的文章中,我應(yīng)該提到,雖然使用默認(rèn)流可以方便地開發(fā)代碼,但同步代碼更簡(jiǎn)單,最終您的代碼應(yīng)該使用非默認(rèn)流或 CUDA 7 對(duì)每線程默認(rèn)流的支持(讀 GPU 專業(yè)提示: CUDA 7 流簡(jiǎn)化并發(fā) )。這在編寫庫時(shí)尤其重要。如果庫中的代碼使用默認(rèn)流,那么最終用戶就沒有機(jī)會(huì)將數(shù)據(jù)傳輸與庫內(nèi)核執(zhí)行重疊。
現(xiàn)在您已經(jīng)知道如何在主機(jī)和設(shè)備之間高效地移動(dòng)數(shù)據(jù),所以我們將研究如何在 下一篇文章 中的內(nèi)核中高效地訪問數(shù)據(jù)。
關(guān)于作者
Mark Harris 是 NVIDIA 杰出的工程師,致力于 RAPIDS 。 Mark 擁有超過 20 年的 GPUs 軟件開發(fā)經(jīng)驗(yàn),從圖形和游戲到基于物理的模擬,到并行算法和高性能計(jì)算。當(dāng)他還是北卡羅來納大學(xué)的博士生時(shí),他意識(shí)到了一種新生的趨勢(shì),并為此創(chuàng)造了一個(gè)名字: GPGPU (圖形處理單元上的通用計(jì)算)。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5012瀏覽量
103238 -
gpu
+關(guān)注
關(guān)注
28文章
4752瀏覽量
129042 -
C++
+關(guān)注
關(guān)注
22文章
2111瀏覽量
73703
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
MPU數(shù)據(jù)傳輸協(xié)議詳解
ptp對(duì)實(shí)時(shí)數(shù)據(jù)傳輸的影響
PCIe數(shù)據(jù)傳輸協(xié)議詳解
socket 數(shù)據(jù)傳輸效率提升技巧
CAN總線數(shù)據(jù)傳輸速率設(shè)置
LORA模塊的數(shù)據(jù)傳輸速率
網(wǎng)絡(luò)數(shù)據(jù)傳輸速率的單位是什么

高速串行總線,數(shù)據(jù)鏈傳輸離不開它!#高速串行總線 #電路知識(shí) #數(shù)據(jù)傳輸
C++中實(shí)現(xiàn)類似instanceof的方法

邊OTG邊充電芯片如何實(shí)現(xiàn)充電與數(shù)據(jù)傳輸并行?
以太網(wǎng)接口的數(shù)據(jù)傳輸原理詳解
探索SPI單線傳輸模式中時(shí)鐘線與數(shù)據(jù)傳輸的簡(jiǎn)化

GMSL技術(shù) 實(shí)現(xiàn)高帶寬、低延遲和高可靠性數(shù)據(jù)傳輸# ADI# GMSL# 汽車# 數(shù)據(jù)傳輸
DTU的多種協(xié)議,解鎖數(shù)據(jù)傳輸的無限可能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論