") Elasticsearch寫入優(yōu)化記錄,從3000到8000/s
Elasticsearch寫入優(yōu)化記錄,從3000到8000/s
背景
優(yōu)化前,寫入速度平均3000條/s,一遇到壓測,寫入速度驟降,甚至es直接頻率gc、oom等;優(yōu)化后,寫入速度平均8000條/s,遇到壓測,能在壓測結(jié)束后30分鐘內(nèi)消化完數(shù)據(jù),各項指標(biāo)回歸正常。
生產(chǎn)配置
這里我先把自己優(yōu)化的結(jié)果貼出來,后面有參數(shù)的詳解:
elasticsearch.yml中增加如下設(shè)置
indices.memory.index_buffer_size:20%
indices.memory.min_index_buffer_size:96mb
#Searchpool
thread_pool.search.size:5
thread_pool.search.queue_size:100
#這個參數(shù)慎用!強(qiáng)制修改cpu核數(shù),以突破寫線程數(shù)限制
#processors:16
#Bulkpool
#thread_pool.bulk.size:16
thread_pool.bulk.queue_size:300
#Indexpool
#thread_pool.index.size:16
thread_pool.index.queue_size:300
indices.fielddata.cache.size:40%
discovery.zen.fd.ping_timeout:120s
discovery.zen.fd.ping_retries:6
discovery.zen.fd.ping_interval:30s
索引優(yōu)化配置:
PUT/_template/elk
{
"order":6,
"template":"logstash-*",#這里配置模板匹配的Index名稱
"settings":{
"number_of_replicas":0,#副本數(shù)為0,需要查詢性能高可以設(shè)置為1
"number_of_shards":6,#分片數(shù)為6,副本為1時可以設(shè)置成5
"refresh_interval":"30s",
"index.translog.durability":"async",
"index.translog.sync_interval":"30s"
}
}
優(yōu)化參數(shù)詳解
精細(xì)設(shè)置全文域: string類型字段默認(rèn)會分詞,不僅會額外占用資源,而且會影響創(chuàng)建索引的速度。所以,把不需要分詞的字段設(shè)置為not_analyzed
禁用_all字段: 對于日志和apm數(shù)據(jù),目前沒有場景會使用到
副本數(shù)量設(shè)置為0: 因為我們目前日志數(shù)據(jù)和apm數(shù)據(jù)在es只保留最近7天的量,全量日志保存在hadoop,可以根據(jù)需要通過spark讀回到es – 況且副本數(shù)量是可以隨時修改的,區(qū)別分片數(shù)量
使用es自動生成id: es對于自動生成的id有優(yōu)化,避免了版本查找。因為其生成的id是唯一的
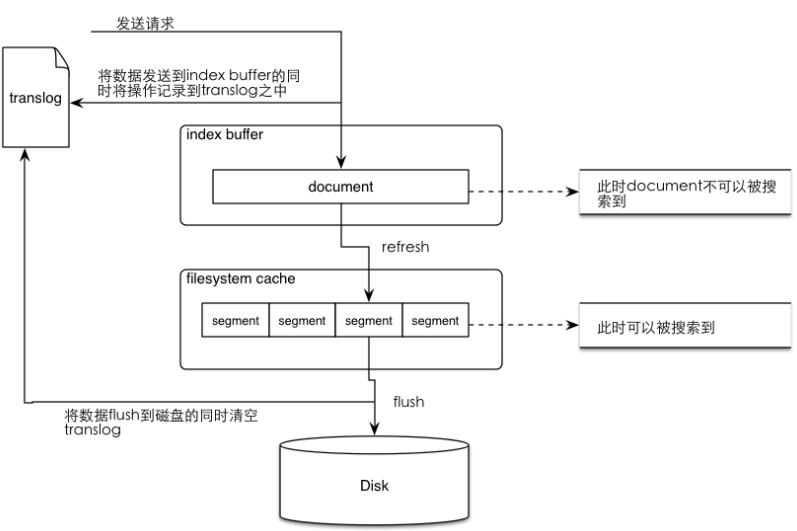
設(shè)置index.refresh_interval: 索引刷新間隔,默認(rèn)為1s。因為不需要如此高的實(shí)時性,我們修改為30s – 擴(kuò)展學(xué)習(xí):刷新索引到底要做什么事情
設(shè)置段合并的線程數(shù)量:
curl-XPUT'your-es-host:9200/nginx_log-2018-03-20/_settings'-d'{
"index.merge.scheduler.max_thread_count":1
}'
段合并的計算量龐大,而且還要吃掉大量磁盤I/O。合并在后臺定期操作,因為他們可能要很長時間才能完成,尤其是比較大的段
機(jī)械磁盤在并發(fā)I/O支持方面比較差,所以我們需要降低每個索引并發(fā)訪問磁盤的線程數(shù)。這個設(shè)置允許max_thread_count + 2個線程同時進(jìn)行磁盤操作,也就是設(shè)置為1允許三個線程
擴(kuò)展學(xué)習(xí):什么是段(segment)?如何合并段?為什么要合并段?(what、how、why)
1.設(shè)置異步刷盤事務(wù)日志文件:
"index.translog.durability":"async",
"index.translog.sync_interval":"30s"
對于日志場景,能夠接受部分?jǐn)?shù)據(jù)丟失。同時有全量可靠日志存儲在hadoop,丟失了也可以從hadoop恢復(fù)回來
2.elasticsearch.yml中增加如下設(shè)置:
indices.memory.index_buffer_size:20%
indices.memory.min_index_buffer_size:96mb
已經(jīng)索引好的文檔會先存放在內(nèi)存緩存中,等待被寫到到段(segment)中。緩存滿的時候會觸發(fā)段刷盤(吃i/o和cpu的操作)。默認(rèn)最小緩存大小為48m,不太夠,最大為堆內(nèi)存的10%。對于大量寫入的場景也顯得有點(diǎn)小。
擴(kuò)展學(xué)習(xí):數(shù)據(jù)寫入流程是怎么樣的(具體到如何構(gòu)建索引)?
1.設(shè)置index、merge、bulk、search的線程數(shù)和隊列數(shù)。例如以下elasticsearch.yml設(shè)置:
#Searchpool
thread_pool.search.size:5
thread_pool.search.queue_size:100
#這個參數(shù)慎用!強(qiáng)制修改cpu核數(shù),以突破寫線程數(shù)限制
#processors:16
#Bulkpool
thread_pool.bulk.size:16
thread_pool.bulk.queue_size:300
#Indexpool
thread_pool.index.size:16
thread_pool.index.queue_size:300
2.設(shè)置filedata cache大小,例如以下elasticsearch.yml配置:
indices.fielddata.cache.size:15%
filedata cache的使用場景是一些聚合操作(包括排序),構(gòu)建filedata cache是個相對昂貴的操作。所以盡量能讓他保留在內(nèi)存中
然后日志場景聚合操作比較少,絕大多數(shù)也集中在半夜,所以限制了這個值的大小,默認(rèn)是不受限制的,很可能占用過多的堆內(nèi)存
擴(kuò)展學(xué)習(xí):什么是filedata?構(gòu)建流程是怎樣的?為什么要用filedata?(what、how、why)
1.設(shè)置節(jié)點(diǎn)之間的故障檢測配置,例如以下elasticsearch.yml配置:
discovery.zen.fd.ping_timeout:120s
discovery.zen.fd.ping_retries:6
discovery.zen.fd.ping_interval:30s
大數(shù)量寫入的場景,會占用大量的網(wǎng)絡(luò)帶寬,很可能使節(jié)點(diǎn)之間的心跳超時。并且默認(rèn)的心跳間隔也相對過于頻繁(1s檢測一次)
此項配置將大大緩解節(jié)點(diǎn)間的超時問題
后記
這里僅僅是記錄對我們實(shí)際寫入有提升的一些配置項,沒有針對個別配置項做深入研究。
擴(kuò)展學(xué)習(xí)后續(xù)填坑。基本都遵循(what、how、why)原則去學(xué)習(xí)。
-End-
審核編輯 :李倩
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7002瀏覽量
88943 -
Elasticsearch
+關(guān)注
關(guān)注
0文章
28瀏覽量
2826
原文標(biāo)題:Elasticsearch 寫入優(yōu)化記錄,從3000到8000/s
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
從RF到HDMI:傳統(tǒng)接口的現(xiàn)代優(yōu)化

從RF到HDMI:傳統(tǒng)接口的現(xiàn)代優(yōu)化
Elasticsearch 再次開源

大功率電源EMC測試整改:從設(shè)計到測試的全面優(yōu)化

從匿名瀏覽到數(shù)據(jù)安全:代理IP用戶心聲全記錄
高增益八木天線:從設(shè)計到優(yōu)化的信號增強(qiáng)
如何向EEPROM寫入數(shù)字
從記錄到管理:單北斗工作記錄儀如何優(yōu)化工作流程

軟件系統(tǒng)的數(shù)據(jù)檢索設(shè)計
求助,關(guān)于AD8000 cir文件的導(dǎo)入問題求解
從PLC到云端,ZP3000系列網(wǎng)關(guān)助力工業(yè)數(shù)字化轉(zhuǎn)型

KV-8000/7000/5000/3000/1000系列指令參考手冊
紫光展銳UNISOC S8000用科技助力步步高學(xué)習(xí)機(jī)S8智慧教育
怎樣才能使用范圍(0x8004-0xBFFC)進(jìn)行I2C寫入呢?
淺談代碼優(yōu)化與過度設(shè)計





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論