 如何使用FIL后端部署XGBOOST模型
如何使用FIL后端部署XGBOOST模型
深度神經網絡在多個領域的成功促使人們對如何有效地部署這些模型以用于實際應用進行了大量思考和努力。然而,盡管基于樹的模型(包括隨機森林和梯度增強模型)在表格數據分析中 continued dominance 非常重要,而且對于解釋性非常重要的用例非常重要,但加速部署基于樹的模型(包括隨機森林和梯度增強模型)的努力卻沒有受到太多關注。
隨著 DoorDash 和 CapitalOne 等組織轉向基于樹的模型來分析大量關鍵任務數據,提供工具以幫助部署此類模型變得簡單、高效和高效變得越來越重要。
NVIDIA Triton 推理服務器 提供在 CPU 和 GPU 上部署深度學習模型的完整解決方案,支持多種框架和模型執行后端,包括 PyTorch 、 TensorFlow 、 ONNX 、 TensorRT 等。從 21.06.1 版開始,為了補充 NVIDIA Triton 推理服務器現有的深度學習功能,新的 林推理庫( FIL )后端 提供了對樹模型的支持,例如 XGBoost 、 LightGBM 、 Scikit-Learn RandomForest , RAPIDS 卡米爾森林 ,以及 Treelite 支持的任何其他型號。
基于 RAPIDS 森林推理庫 (NVIDIA ),NVIDIA Triton 推理服務器 FIL 后端允許用戶利用 NVIDIA Triton 推理服務器的相同特性,以達到 deep learning 模型的最優吞吐量/延遲,以在相同的系統上部署基于樹的模型。
在本文中,我們將簡要介紹NVIDIA Triton 推理服務器本身,然后深入介紹如何使用 FIL 后端部署 XGBOOST 模型的示例。使用 NVIDIA GPU ,我們將看到,我們不必總是在部署更精確的模型或保持延遲可控之間做出選擇。
在示例筆記本中,通過利用 FIL 后端的 GPU 加速推理,在一臺配備八臺 V100 GPU 的 NVIDIA DGX-1 服務器上,我們將能夠部署比 CPU 更復雜的欺詐檢測模型,同時將 p99 延遲保持在 2ms 以下, still 每秒提供超過 400K 的推斷( 630MB / s ),或者比 CPU 上的吞吐量高 20 倍。
NVIDIA Triton 推理服務器
NVIDIA Triton 推理服務器為 machine learning 模型的實時服務提供了完整的開源解決方案。 NVIDIA Triton 推理服務器旨在使性能模型部署過程盡可能簡單,它為在實際應用中嘗試部署 ML 算法時遇到的許多最常見問題提供了解決方案,包括:
多框架 支持 : 支持所有最常見的深度學習框架和序列化格式,包括 PyTorch 、 TensorFlow 、 ONNX 、 TensorRT 、 OpenVINO 等。隨著 FIL 后端的引入, NVIDIA Triton 推理服務器還提供對 XGBoost 、 LightGBM 、 Scikit Learn / cuML RandomForest 和任何框架中的 Treelite 序列化模型的支持。
Dynamic Batching : 允許用戶指定一個批處理窗口,并將在該窗口中收到的任何請求整理成更大的批處理,以優化吞吐量。
多種查詢類型 :優化多種查詢類型的推理:實時、批處理、流式,還支持模型集成。
使用 NVIDIA 管道和集合 推理服務器部署的 管道和集合 Triton 型號可以通過復雜的管道或集成進行連接,以避免客戶端和服務器之間,甚至主機和設備之間不必要的數據傳輸。
CPU 模型執行 : 雖然大多數用戶希望利用 GPU 執行帶來的巨大性能提升,但 NVIDIA Triton 推理服務器允許您在 CPU 或 GPU 上運行模型,以滿足您的特定部署需求和資源可用性。
Dynamic Batching [VZX337 ]如果NVIDIA Triton 推理服務器不提供對部分管道的支持,或者如果需要專門的邏輯將各種模型鏈接在一起,則可以使用自定義 Python 或C++后端精確地添加所需的邏輯。
Run anywhere :在擴展的云或數據中心、企業邊緣,甚至在嵌入式設備上。它支持用于人工智能推理的裸機和虛擬化環境(如 VMware vSphere )。
Kubernetes 和 AI 平臺支持 :
作為 Docker 容器提供,并可輕松與 Kubernetes 平臺集成,如 AWS EKS 、谷歌 GKE 、 Azure AKS 、阿里巴巴 ACK 、騰訊 TKE 或紅帽 OpenShift 。
可在 Amazon SageMaker 、 Azure ML 、 Google Vertex AI 、阿里巴巴 AI 彈性算法服務平臺和騰訊 TI-EMS 等托管 CloudAI 工作流平臺上使用。
Enterprise support : NVIDIA AI 企業軟件套件包括對 NVIDIA Triton 推理服務器的全面支持,例如訪問 NVIDIA AI 專家以獲得部署和管理指導、安全修復和維護發布的優先通知、長期支持( LTS )選項和指定的支持代理。
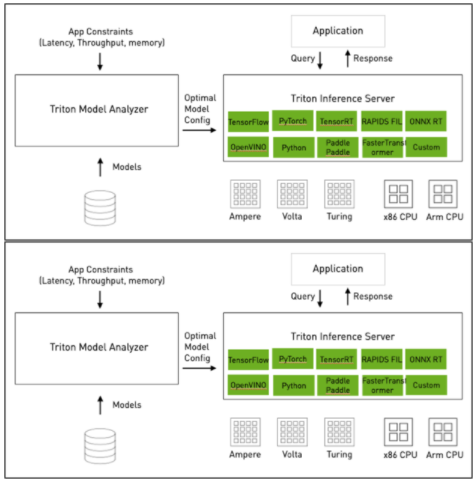
圖 1:NVIDIA Triton 推理服務器架構圖。
為了更好地了解如何利用 FIL 后端的這些特性來部署樹模型,我們來看一個特定的用例。
示例: FIL 后端的欺詐檢測
為了在 NVIDIA Triton 推理服務器中部署模型,我們需要一個配置文件,指定有關部署選項和序列化模型本身的一些細節。模型當前可以按以下任意格式序列化:
XGBoost 二進制格式
XGBoost JSON
LightGBM 文本格式
Treelite 二進制檢查點文件
在下面的筆記本中,我們將介紹部署欺詐檢測模型過程的每個步驟,從培訓模型到編寫配置文件以及優化部署參數。在此過程中,我們將演示 GPU 部署如何在保持最小延遲的同時顯著提高吞吐量。此外,由于 FIL 可以輕松地擴展到非常大和復雜的模型,而不會大幅增加延遲,因此我們將看到,對于任何給定的延遲預算,在 GPU 上部署比 CPU 上更復雜和準確的模型是可能的。
筆記本:
抱歉,出了點問題。 Reload?
抱歉,我們無法顯示此文件。
抱歉,此文件無效,無法顯示。
查看器需要 iframe 。
view raw正如我們在本筆記本中所看到的, NVIDIA Triton 推理服務器的 FIL 后端允許我們使用序列化的模型文件和簡單的配置文件輕松地為樹模型提供服務。如果沒有 NVIDIA Triton 推理服務器,那些希望服務于其他框架中的 XGBoost 、 LightGBM 或隨機林模型的人通常會求助于吞吐量延遲性能差且不支持多個框架的手動搖瓶服務器。 NVIDIA Triton 推理服務器的動態批處理和并發模型執行自動最大化吞吐量,模型分析器有助于選擇最佳部署配置。手動選擇可能需要數百種組合,并且可能會延遲模型的展開。有了 FIL 后端,我們可以為來自所有這些框架的模型提供服務,而無需定制代碼和高度優化的性能。
結論
使用 FIL 后端,NVIDIA Triton 推理服務器現在提供了一個高度優化的實時服務的森林模型,無論是在他們自己或旁邊的深度學習模型。雖然支持 CPU 和 GPU 執行,但我們可以利用 GPU 加速來保持低延遲和高吞吐量,即使對于復雜的模型也是如此。正如我們在示例筆記本中看到的,這意味著即使延遲預算很緊,也不需要通過退回到更簡單的模型來降低模型的準確性。
如果您想嘗試部署自己的 XGBOST 、 LITGBM 、 SKEXCEL 或 CUML 森林模型進行實時推理,那么您可以很容易地從 Docker container 、NVIDIA 的 GPU 優化的 AI 軟件目錄中拉取 NVIDIA NVIDIA AI 企業套件 推理服務器 Docker container 。您可以在 FIL 后端文檔 中找到入門所需的一切。如果準備部署到 Kubernetes 集群, NVIDIA Triton 還提供了 Helm charts 示例。對于希望在實際工作負載下試用 Triton 推理服務器的企業, NVIDIA LaunchPad 計劃提供了一組在 Triton 中使用 Triton 的精心策劃的實驗室。
Krieger 說:“ STAR 的獨特之處在于,它是第一個在軟組織中規劃、調整和執行手術計劃的機器人系統,只需極少的人工干預。”。
關于作者
William Hicks 是NVIDIA RAPIDS 團隊的高級軟件工程師。希克斯擁有布蘭代斯大學物理學碩士學位和布朗大學文學藝術碩士學位。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4999瀏覽量
103227 -
gpu
+關注
關注
28文章
4747瀏覽量
129021 -
服務器
+關注
關注
12文章
9221瀏覽量
85599
發布評論請先 登錄
相關推薦
企業AI模型部署攻略
AI模型部署邊緣設備的奇妙之旅:目標檢測模型

AI模型部署邊緣設備的奇妙之旅:如何實現手寫數字識別
企業AI模型部署怎么做
NVIDIA NIM助力企業高效部署生成式AI模型
llm模型本地部署有用嗎
PerfXCloud大模型開發與部署平臺開放注冊
使用TVM量化部署模型報錯NameError: name \'GenerateESPConstants\' is not defined如何解決?
大模型端側部署加速,都有哪些芯片可支持?
基于stm32h743IIK在cubeai上部署keras模型,模型輸出結果都是同一組概率數組,為什么?
模擬后端是什么意思
使用CUBEAI部署tflite模型到STM32F0中,模型創建失敗怎么解決?
源2.0適配FastChat框架,企業快速本地化部署大模型對話平臺






 工商網監
工商網監
評論