 HashMap奪命14問,你能堅持到第幾問?
HashMap奪命14問,你能堅持到第幾問?
1. HashMap的底層數據結構是什么?
在JDK1.7中和JDK1.8中有所區別:
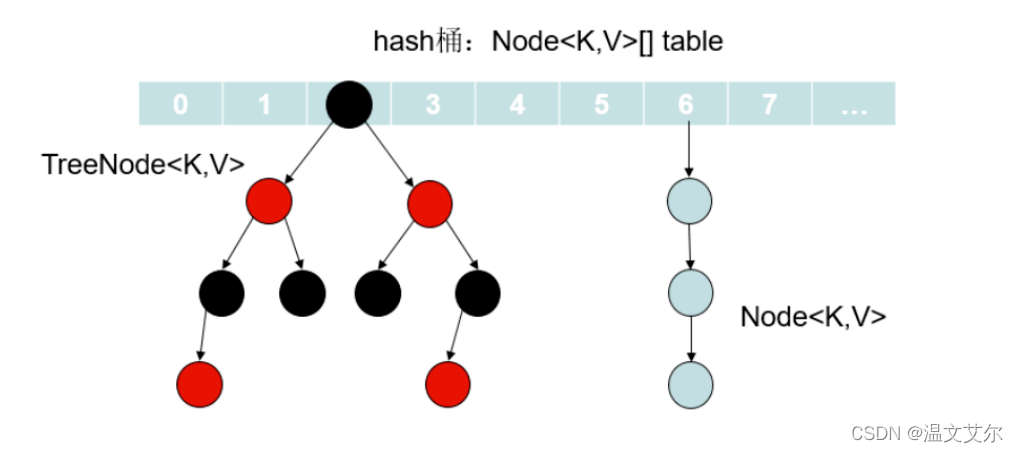
在JDK1.7中,由”數組+鏈表“組成,數組是HashMap的主體,鏈表則是主要為了解決哈希沖突而存在的。
在JDK1.8中,有“數組+鏈表+紅黑樹”組成。當鏈表過長,則會嚴重影響HashMap的性能,紅黑樹搜索時間復雜度是O(logn),而鏈表是O(n)。因此,JDK1.8對數據結構做了進一步的優化,引入了紅黑樹,鏈表和紅黑樹在達到一定條件會進行轉換:
當鏈表超過8且數組長度(數據總量)超過64才會轉為紅黑樹
將鏈表轉換成紅黑樹前會判斷,如果當前數組的長度小于64,那么會選擇先進行數組擴容,而不是轉換為紅黑樹,以減少搜索時間。
2. 說一下HashMap的特點
hashmap存取是無序的
鍵和值位置都可以是null,但是鍵位置只能是一個null
鍵位置是唯一的,底層的數據結構是控制鍵的
jdk1.8前數據結構是:鏈表+數組jdk1.8之后是:數組+鏈表+紅黑樹
閾值(邊界值)>8并且數組長度大于64,才將鏈表轉換成紅黑樹,變成紅黑樹的目的是提高搜索速度,高效查詢
3. 解決hash沖突的辦法有哪些?HashMap用的哪種?
解決Hash沖突方法有:開放定址法、再哈希法、鏈地址法(HashMap中常見的拉鏈法)、簡歷公共溢出區。HashMap中采用的是鏈地址法。
開放定址法也稱為再散列法,基本思想就是,如果p=H(key)出現沖突時,則以p為基礎,再次hash,p1=H(p),如果p1再次出現沖突,則以p1為基礎,以此類推,直到找到一個不沖突的哈希地址pi。因此開放定址法所需要的hash表的長度要大于等于所需要存放的元素,而且因為存在再次hash,所以只能在刪除的節點上做標記,而不能真正刪除節點
再哈希法(雙重散列,多重散列),提供多個不同的hash函數,R1=H1(key1)發生沖突時,再計算R2=H2(key1),直到沒有沖突為止。這樣做雖然不易產生堆集,但增加了計算的時間。
鏈地址法(拉鏈法),將哈希值相同的元素構成一個同義詞的單鏈表,并將單鏈表的頭指針存放在哈希表的第i個單元中,查找、插入和刪除主要在同義詞鏈表中進行,鏈表法適用于經常進行插入和刪除的情況。
建立公共溢出區,將哈希表分為公共表和溢出表,當溢出發生時,將所有溢出數據統一放到溢出區
注意開放定址法和再哈希法的區別是
開放定址法只能使用同一種hash函數進行再次hash,再哈希法可以調用多種不同的hash函數進行再次hash
4. 為什么要在數組長度大于64之后,鏈表才會進化為紅黑樹
在數組比較小時如果出現紅黑樹結構,反而會降低效率,而紅黑樹需要進行左旋右旋,變色,這些操作來保持平衡,同時數組長度小于64時,搜索時間相對要快些,總之是為了加快搜索速度,提高性能
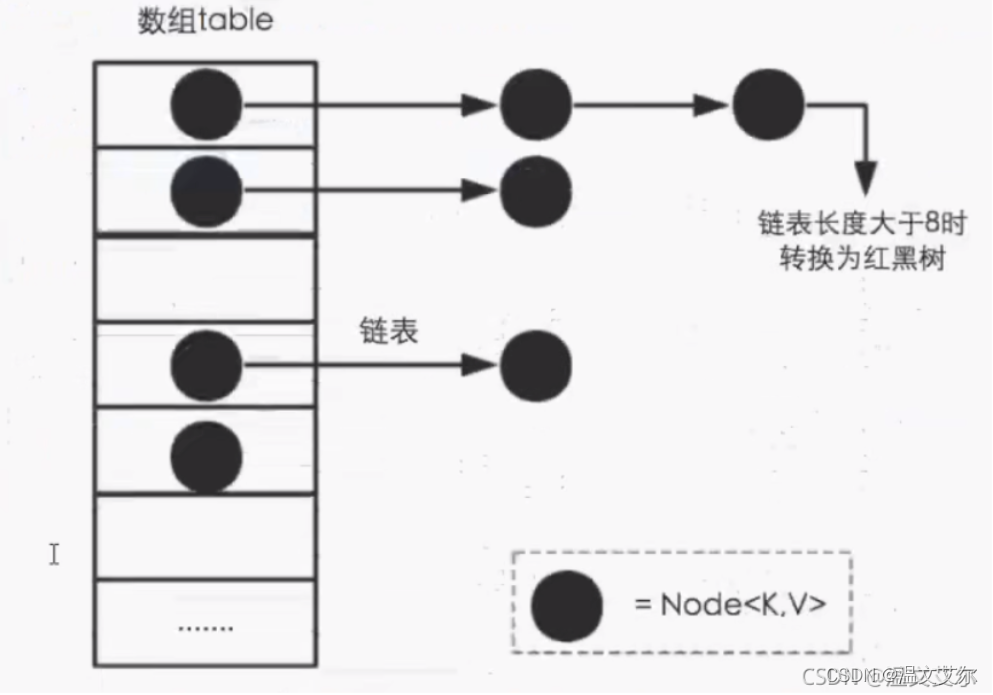
JDK1.8以前HashMap的實現是數組+鏈表,即使哈希函數取得再好,也很難達到元素百分百均勻分布。當HashMap中有大量的元素都存放在同一個桶中時,這個桶下有一條長長的鏈表,此時HashMap就相當于單鏈表,假如單鏈表有n個元素,遍歷的時間復雜度就從O(1)退化成O(n),完全失去了它的優勢,為了解決此種情況,JDK1.8中引入了紅黑樹(查找的時間復雜度為O(logn))來優化這種問題
5. 為什么加載因子設置為0.75,初始化臨界值是12?
HashMap中的threshold是HashMap所能容納鍵值對的最大值。計算公式為length*LoadFactory。也就是說,在數組定義好長度之后,負載因子越大,所能容納的鍵值對個數也越大
loadFactory越趨近于1,那么數組中存放的數據(entry也就越來越多),數據也就越密集,也就會有更多的鏈表長度處于更長的數值,我們的查詢效率就會越低,當我們添加數據,產生hash沖突的概率也會更高
默認的loadFactory是0.75,loadFactory越小,越趨近于0,數組中個存放的數據(entry)也就越少,表現得更加稀疏
0.75是對空間和時間效率的一種平衡選擇
如果負載因子小一些比如是0.4,那么初始長度16*0.4=6,數組占滿6個空間就進行擴容,很多空間可能元素很少甚至沒有元素,會造成大量的空間被浪費
如果負載因子大一些比如是0.9,這樣會導致擴容之前查找元素的效率非常低
loadfactory設置為0.75是經過多重計算檢驗得到的可靠值,可以最大程度的減少rehash的次數,避免過多的性能消耗
6. 哈希表底層采用何種算法計算hash值?還有哪些算法可以計算出hash值?
hashCode方法是Object中的方法,所有的類都可以對其進行使用,首先底層通過調用hashCode方法生成初始hash值h1,然后將h1無符號右移16位得到h2,之后將h1與h2進行按位異或(^)運算得到最終hash值h3,之后將h3與(length-1)進行按位與(&)運算得到hash表索引
其他可以計算出hash值的算法有
平方取中法
取余數
偽隨機數法
7. 當兩個對象的hashCode相等時會怎樣
hashCode相等產生hash碰撞,hashCode相等會調用equals方法比較內容是否相等,內容如果相等則會進行覆蓋,內容如果不等則會連接到鏈表后方,鏈表長度超過8且數組長度超過64,會轉變成紅黑樹節點
8. 何時發生哈希碰撞和什么是哈希碰撞,如何解決哈希碰撞?
只要兩個元素的key計算的hash碼值相同就會發生hash碰撞,jdk8之前使用鏈表解決哈希碰撞,jdk8之后使用鏈表+紅黑樹解決哈希碰撞
9. HashMap的put方法流程
以jdk8為例,簡要流程如下:
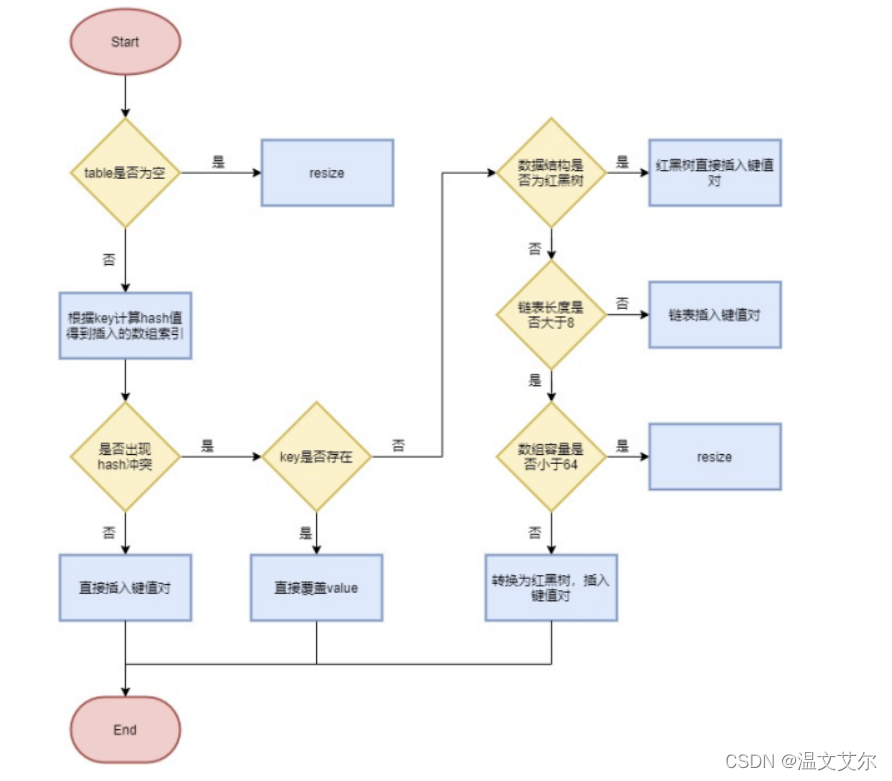
首先根據key的值計算hash值,找到該元素在數組中存儲的下標
如果數組是空的,則調用resize進行初始化;
如果沒有哈希沖突直接放在對應的數組下標里
如果沖突了,且key已經存在,就覆蓋掉value
如果沖突后是鏈表結構,就判斷該鏈表是否大于8,如果大于8并且數組容量小于64,就進行擴容;如果鏈表節點數量大于8并且數組的容量大于64,則將這個結構轉換成紅黑樹;否則,鏈表插入鍵值對,若key存在,就覆蓋掉value
如果沖突后,發現該節點是紅黑樹,就將這個節點掛在樹上
10. HashMap的擴容方式
HashMap在容量超過負載因子所定義的容量之后,就會擴容。java里的數組是無法自己擴容的,將HashMap的大小擴大為原來數組的兩倍
我們來看jdk1.8擴容的源碼
final Node《K,V》[] resize() {
//oldTab:引用擴容前的哈希表
Node《K,V》[] oldTab = table;
//oldCap:表示擴容前的table數組的長度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//獲得舊哈希表的擴容閾值
int oldThr = threshold;
//newCap:擴容之后table數組大小
//newThr:擴容之后下次觸發擴容的條件
int newCap, newThr = 0;
//條件成立說明hashMap中的散列表已經初始化過了,是一次正常擴容
if (oldCap 》 0) {
//判斷舊的容量是否大于等于最大容量,如果是,則無法擴容,并且設置擴容條件為int最大值,
//這種情況屬于非常少數的情況
if (oldCap 》= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}//設置newCap新容量為oldCap舊容量的二倍(《《1),并且《最大容量,而且》=16,則新閾值等于舊閾值的兩倍
else if ((newCap = oldCap 《《 1) 《 MAXIMUM_CAPACITY &&
oldCap 》= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr 《《 1; // double threshold
}
//如果oldCap=0并且邊界值大于0,說明散列表是null,但此時oldThr》0
//說明此時hashMap的創建是通過指定的構造方法創建的,新容量直接等于閾值
//1.new HashMap(intitCap,loadFactor)
//2.new HashMap(initCap)
//3.new HashMap(map)
else if (oldThr 》 0) // initial capacity was placed in threshold
newCap = oldThr;
//這種情況下oldThr=0;oldCap=0,說明沒經過初始化,創建hashMap
//的時候是通過new HashMap()的方式創建的
else {
// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//newThr為0時,通過newCap和loadFactor計算出一個newThr
if (newThr == 0) {
//容量*0.75
float ft = (float)newCap * loadFactor;
newThr = (newCap 《 MAXIMUM_CAPACITY && ft 《 (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({“rawtypes”,“unchecked”})
//根據上面計算出的結果創建一個更長更大的數組
Node《K,V》[] newTab = (Node《K,V》[])new Node[newCap];
//將table指向新創建的數組
table = newTab;
//本次擴容之前table不為null
if (oldTab != null) {
//對數組中的元素進行遍歷
for (int j = 0; j 《 oldCap; ++j) {
//設置e為當前node節點
Node《K,V》 e;
//當前桶位數據不為空,但不能知道里面是單個元素,還是鏈表或紅黑樹,
//e = oldTab[j],先用e記錄下當前元素
if ((e = oldTab[j]) != null) {
//將老數組j桶位置為空,方便回收
oldTab[j] = null;
//如果e節點不存在下一個節點,說明e是單個元素,則直接放置在新數組的桶位
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//如果e是樹節點,證明該節點處于紅黑樹中
else if (e instanceof TreeNode)
((TreeNode《K,V》)e).split(this, newTab, j, oldCap);
//e為鏈表節點,則對鏈表進行遍歷
else { // preserve order
//低位鏈表:存放在擴容之后的數組的下標位置,與當前數組下標位置一致
//loHead:低位鏈表頭節點
//loTail低位鏈表尾節點
Node《K,V》 loHead = null, loTail = null;
//高位鏈表,存放擴容之后的數組的下標位置,=原索引+擴容之前數組容量
//hiHead:高位鏈表頭節點
//hiTail:高位鏈表尾節點
Node《K,V》 hiHead = null, hiTail = null;
Node《K,V》 next;
do {
next = e.next;
//oldCap為16:10000,與e.hsah做&運算可以得到高位為1還是0
//高位為0,放在低位鏈表
if ((e.hash & oldCap) == 0) {
if (loTail == null)
//loHead指向e
loHead = e;
else
loTail.next = e;
loTail = e;
}
//高位為1,放在高位鏈表
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
//低位鏈表已成,將頭節點loHead指向在原位
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
//高位鏈表已成,將頭節點指向新索引
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
擴容之后原位置的節點只有兩種調整
保持原位置不動(新bit位為0時)
散列原索引+擴容大小的位置去(新bit位為1時)
擴容之后元素的散列設置的非常巧妙,節省了計算hash值的時間,我們來看一 下具體的實現

當數組長度從16到32,其實只是多了一個bit位的運算,我們只需要在意那個多出來的bit為是0還是1,是0的話索引不變,是1的話索引變為當前索引值+擴容的長度,比如5變成5+16=21
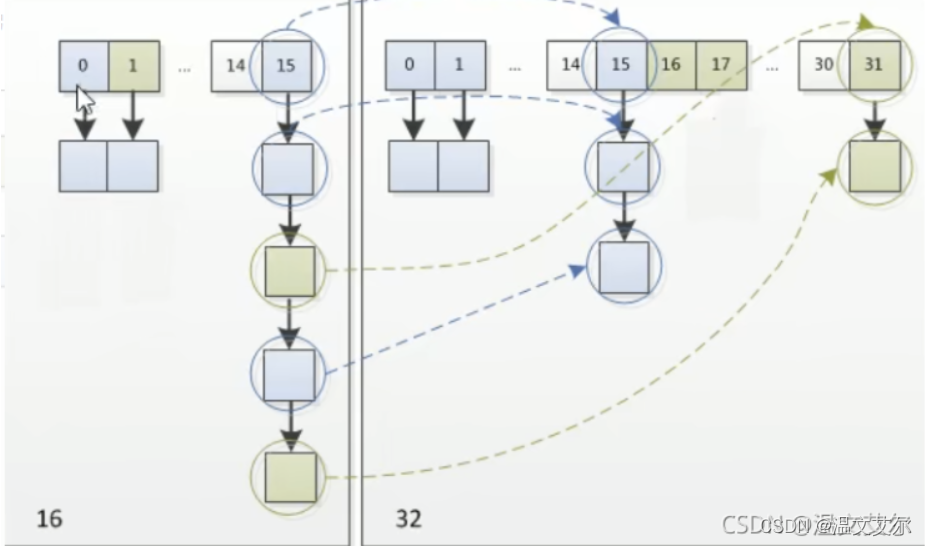
這樣的擴容方式不僅節省了重新計算hash的時間,而且保證了當前桶中的元素總數一定小于等于原來桶中的元素數量,避免了更嚴重的hash沖突,均勻的把之前沖突的節點分散到新的桶中去
11. 一般用什么作為HashMap的key?
一般用Integer、String這種不可變類當HashMap當key
因為String是不可變的,當創建字符串時,它的hashcode被緩存下來,不需要再次計算,相對于其他對象更快
因為獲取對象的時候要用到equals()和hashCode()方法,那么鍵對象正確的重寫這兩個方法是非常重要的,這些類很規范的重寫了hashCode()以及equals()方法
12. 為什么Map桶中節點個數超過8才轉為紅黑樹?
8作為閾值作為HashMap的成員變量,在源碼的注釋中并沒有說明閾值為什么是8
在HashMap中有這樣一段注釋說明,我們繼續看
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD)。 And when they become too small (due to * removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) / * factorial(k)).
翻譯
因為樹節點的大小大約是普通節點的兩倍,所以我們只在箱子包含足夠的節點時才使用樹節點(參見TREEIFY_THRESHOLD)。當他們邊的太小(由于刪除或調整大小)時,就會被轉換回普通的桶,在使用分布良好的hashcode時,很少使用樹箱。 理想情況下,在隨機哈希碼下,箱子中節點的頻率服從泊松分布第一個值是:
* 0:
0.60653066 * 1:
0.30326533 * 2:
0.07581633 * 3:
0.01263606 * 4:
0.00157952 * 5:
0.00015795 * 6:
0.00001316 * 7:
0.00000094 * 8:
0.00000006 * more:
less than 1 in ten million
樹節點占用空間是普通Node的兩倍,如果鏈表節點不夠多卻轉換成紅黑樹,無疑會耗費大量的空間資源,并且在隨機hash算法下的所有bin節點分布頻率遵從泊松分布,鏈表長度達到8的概率只有0.00000006,幾乎是不可能事件,所以8的計算是經過重重科學考量的
從平均查找長度來看,紅黑樹的平均查找長度是logn,如果長度為8,則logn=3,而鏈表的平均查找長度為n/4,長度為8時,n/2=4,所以閾值8能大大提高搜索速度
當長度為6時紅黑樹退化為鏈表是因為logn=log6約等于2.6,而n/2=6/2=3,兩者相差不大,而紅黑樹節點占用更多的內存空間,所以此時轉換最為友好
13. HashMap為什么線程不安全?
多線程下擴容死循環。JDK1.7中的HashMap使用頭插法插入元素,在多線程的環境下,擴容的時候有可能導致環形鏈表的出現,形成死循環。因此JDK1.8使用尾插法插入元素,在擴容時會保持鏈表元素原本的順序,不會出現環形鏈表的問題
多線程的put可能導致元素的丟失。多線程同時執行put操作,如果計算出來的索引位置是相同的,那會造成前一個key被后一個key覆蓋,從而導致元素的丟失。此問題在JDK1.7和JDK1.8中都存在
put和get并發時,可能導致get為null。線程1執行put時,因為元素個數超出threshold而導致rehash,線程2此時執行get,有可能導致這個問題,此問題在JDK1.7和JDK1.8中都存在
14. 計算hash值時為什么要讓低16bit和高16bit進行異或處理
我們計算索引需要將hashCode值與length-1進行按位與運算,如果數組長度很小,比如16,這樣的值和hashCode做異或實際上只有hashCode值的后4位在進行運算,hash值是一個隨機值,而如果產生的hashCode值高位變化很大,而低位變化很小,那么有很大概率造成哈希沖突,所以我們為了使元素更好的散列,將hash值的高位也利用起來
舉個例子
如果我們不對hashCode進行按位異或,直接將hash和length-1進行按位與運算就有可能出現以下的情況

如果下一次生成的hashCode值高位起伏很大,而低位幾乎沒有變化時,高位無法參與運算

可以看到,兩次計算出的hash相等,產生了hash沖突
所以無符號右移16位的目的是使高混亂度地區與地混亂度地區做一個中和,提高低位的隨機性,減少哈希沖突。
-End-
審核編輯 :李倩
-
數組
+關注
關注
1文章
417瀏覽量
25939 -
鏈表
+關注
關注
0文章
80瀏覽量
10558 -
hashmap
+關注
關注
0文章
14瀏覽量
2285
原文標題:HashMap奪命14問,你能堅持到第幾問?
文章出處:【微信號:AndroidPush,微信公眾號:Android編程精選】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
阿里通義千問代碼模型全系列開源
玩轉大模型 企業AI著陸新正解 神州問學AI原生賦能平臺正式發布

阿里云發布通義千問2.5
通義千問推出1100億參數開源模型
問界汽車3月交付31727輛,問界新M7降價2萬元
說個大事:問界 M9 來了!






 工商網監
工商網監
評論