") 未來CPU處理器技術(shù)演進(jìn)路線
未來CPU處理器技術(shù)演進(jìn)路線
本文選自“2022年國產(chǎn)服務(wù)器CPU研究框架”。后摩爾定律時代,單靠制程工藝的提升帶來的性能受益已經(jīng)十分有限,Dennard Scaling規(guī)律約束,芯片功耗急劇上升,晶體管成本不降反升;單核的性能已經(jīng)趨近極限,多核架構(gòu)的性能提升亦在放緩。AIoT時代來臨,下游算力需求呈現(xiàn)多樣化及碎片化,通用處理器難以應(yīng)對。
1)從通用到專用:面向不同的場景特點定制芯片,XPU、FPGA、DSA、ASIC應(yīng)運(yùn)而生。
2)從底層到頂層:軟件、算法、硬件架構(gòu)。架構(gòu)的優(yōu)化能夠極大程度提升處理器性能,例如AMD Zen3將分離的兩塊16MB L3 Cache合并成一塊32MB L3 Cache,再疊加改進(jìn)的分支預(yù)測、更寬的浮點unit等,便使其單核心性能較Zen2提升19%。
3)異構(gòu)與集成:蘋果M1 Ultra芯片的推出帶來啟迪,利用逐步成熟的3D封裝、片間互聯(lián)等技術(shù),使多芯片有效集成,似乎是延續(xù)摩爾定律的最佳實現(xiàn)路徑。
主流芯片廠商已開始全面布局:Intel已擁有CPU、FPGA、IPU產(chǎn)品線,正加大投入GPU產(chǎn)品線,推出最新的Falcon Shores架構(gòu),打磨異構(gòu)封裝技術(shù);NvDIA則接連發(fā)布多芯片模組(MCM,Multi-Chip Module)Grace系列產(chǎn)品,預(yù)計即將投入量產(chǎn);AMD則于近日完成對塞靈思的收購,預(yù)計未來走向CPU+FPGA的異構(gòu)整合。
此外,英特爾、AMD、Arm、高通、臺積電、三星、日月光、Google云、Meta、微軟等十大行業(yè)主要參與者聯(lián)合成立了Chiplet標(biāo)準(zhǔn)聯(lián)盟,正式推出通用Chiplet的高速互聯(lián)標(biāo)準(zhǔn)“Universal Chiplet InterconnectExpress”(通用小芯片互連,簡稱“UCIe”)。
在UCIe的框架下,互聯(lián)接口標(biāo)準(zhǔn)得到統(tǒng)一。各類不同工藝、不同功能的Chiplet芯片,有望通過2D、2.5D、3D等各種封裝方式整合在一起,多種形態(tài)的處理引擎共同組成超大規(guī)模的復(fù)雜芯片系統(tǒng),具有高帶寬、低延遲、經(jīng)濟(jì)節(jié)能的優(yōu)點。
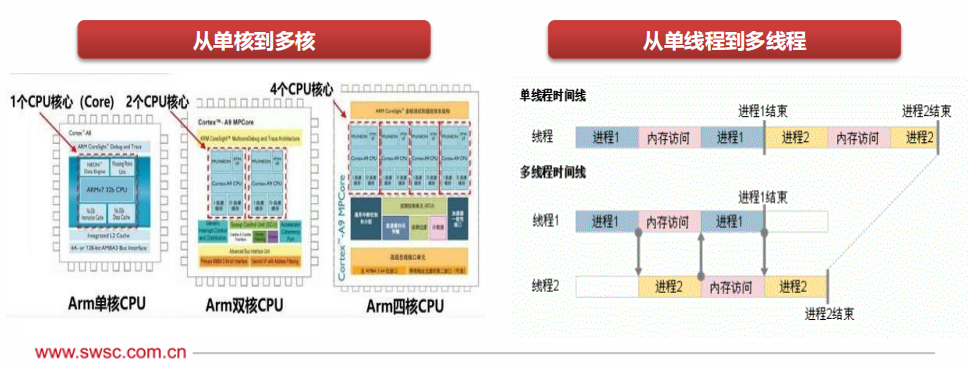
以多核提升性能功耗比:多核處理器把多個處理器核集成到同一個芯片之上,每個單元的計算性能密度得以大幅提升。同時,原有的外圍部件可以被多個CPU系統(tǒng)共享,可帶來更高的通信帶寬和更短的通信時延,多核處理器在并行性方面具有天然的優(yōu)勢,通過動態(tài)調(diào)節(jié)電壓/頻率、負(fù)載優(yōu)化分布等,可有效降低功耗,提升性能。
以多線程提升總體性能:通過復(fù)制處理器上的結(jié)構(gòu)狀態(tài),讓同一個處理器上的多個線程同步執(zhí)行并共享處理器的執(zhí)行資源,可以極小的硬件代價獲得相當(dāng)比例的總體性能和吞吐量提高。
微架構(gòu)的改進(jìn)
眾多算數(shù)單元、邏輯單元、寄存器在三態(tài)總線和單項總線,以及各個控制線的連接下共同組成CPU微架構(gòu)。不同的微架構(gòu)設(shè)計,對CPU性能和效能的提升發(fā)揮著直觀重要的作用。
微架構(gòu)的升級,一般涉及到指令集拓展、硬件虛擬化、大內(nèi)存、亂序執(zhí)行等等一系列復(fù)雜的工作,還涉及到編譯器、函數(shù)庫等軟件層次的修改,牽一發(fā)而動全身。
摩爾定律放緩
摩爾定律于上世紀(jì)60年代提出,直至2011年前,計算機(jī)元器件的小型化是提升處理性能的主要因素。2011年后,摩爾定律開始放緩,制硅工藝的改進(jìn)將不再提供顯著的性能提升。
“Tick-Tock”模式失效
自2007年開始,英特爾開始實施“Tick-Tock”發(fā)展模式,以兩年為周期,在奇數(shù)年(Tick)推出新制成工藝,在偶數(shù)年(Tock)推出新架構(gòu)的微處理器。
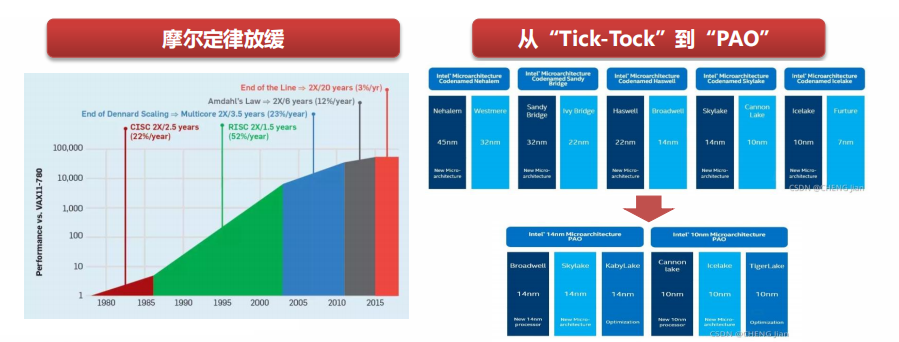
在14nm轉(zhuǎn)10nm接連推遲后,英特爾自2016年起宣布停止 “Tick-Tock”處理器升級周期,改為處理器升級的三步戰(zhàn)略:制程工藝(Process)-架構(gòu)更新(Architecture)-優(yōu)化(Optimization)。
后摩爾時代,頂層優(yōu)化或更為重要
新的底層優(yōu)化路徑被提出,例如3D堆疊、量子計算、光子學(xué)、超導(dǎo)電路、石墨烯芯片等,技術(shù)目前仍處于起步階段,但后續(xù)有望突破現(xiàn)有想象空間。
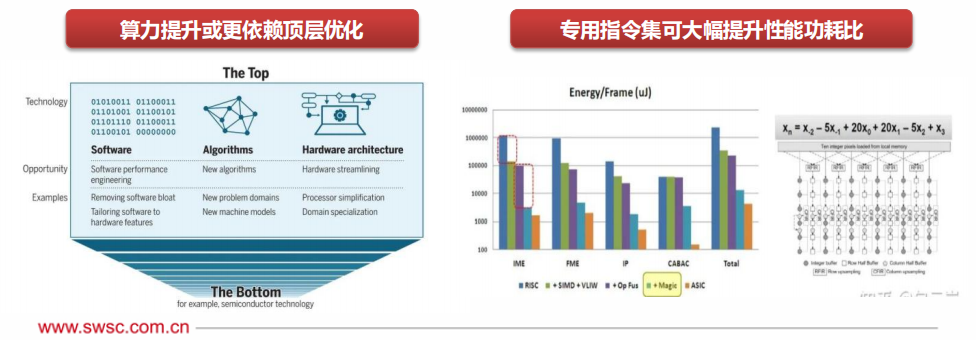
根據(jù)MIT在《Science》發(fā)布的文章,后摩爾定律時代,算力提升將更大程度上來源于計算堆棧的「頂層」,即軟件、算法和硬件架構(gòu)。
通用指令集為了覆蓋更多應(yīng)用,往往需要支持上千條指令,導(dǎo)致流水線前端設(shè)計(取指、譯 碼、分支預(yù)測等變得十分復(fù)雜),對性能功耗會產(chǎn)生負(fù)面影響。
領(lǐng)域?qū)S弥噶罴纱蟠鬁p少指令數(shù)量,并且能夠增大操作粒度,融合訪存優(yōu)化,實現(xiàn)數(shù)量級提高性能功耗比。
新興場景出現(xiàn),CPU從通用向?qū)S冒l(fā)展
1972年,戈登·貝爾(Gordon Bell)提出,每隔10年,會出現(xiàn)新一類計算機(jī)(新編程平臺、 ,新網(wǎng)絡(luò)連接、新用戶接口,新使用方式且更廉價),形成新的產(chǎn)業(yè)。1987 年, 原日立公司總工程師牧村次夫(Tsugio Makimoto) 提出,半導(dǎo)體產(chǎn)品未來可能將沿著“標(biāo)準(zhǔn)化”與“定制化”交替發(fā)展的路線前進(jìn),大約每十年波動一次。
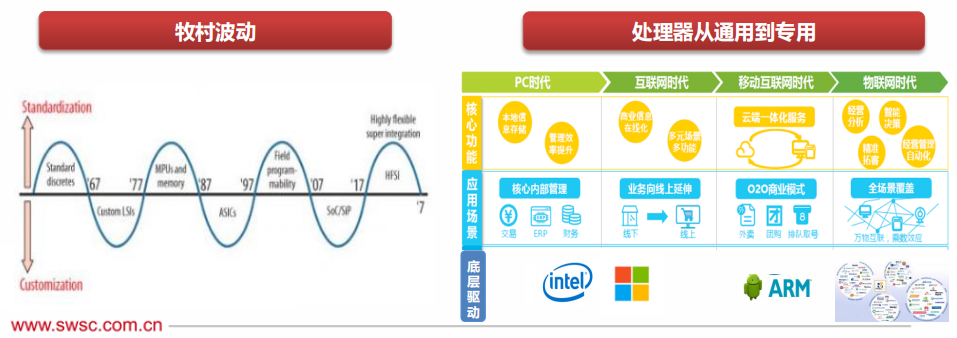
經(jīng)歷了桌面PC、互聯(lián)網(wǎng)時代和移動互聯(lián)網(wǎng)時代后,“萬物智聯(lián)”已成為新的風(fēng)向標(biāo),AIoT正掀起世界信息產(chǎn)業(yè)革命第三次浪潮。而AIoT最明顯的特征是需求碎片化,現(xiàn)有的通用處理器設(shè)計方法難以有效應(yīng)對定制化需求。
通用與性能,難以兼得
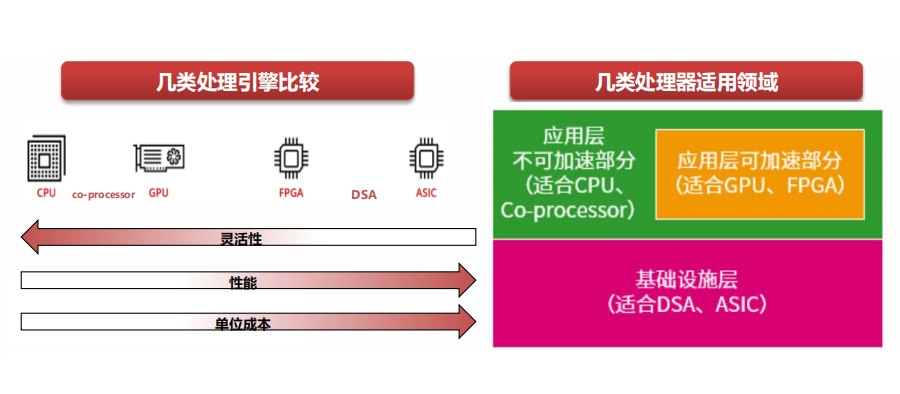
CPU是最通用的處理器引擎,指令最為基礎(chǔ),具有最好的靈活性。Coprocessor,是基于CPU的擴(kuò)展指令集的運(yùn)行引擎,如ARM的NEON、Intel的AVX、AMX擴(kuò)展指令集和相應(yīng)的協(xié)處理器。
GPU,本質(zhì)上是很多小CPU核的并行,因此NP、Graphcore的IPU等都和GPU處于同一層次的處理器類型。
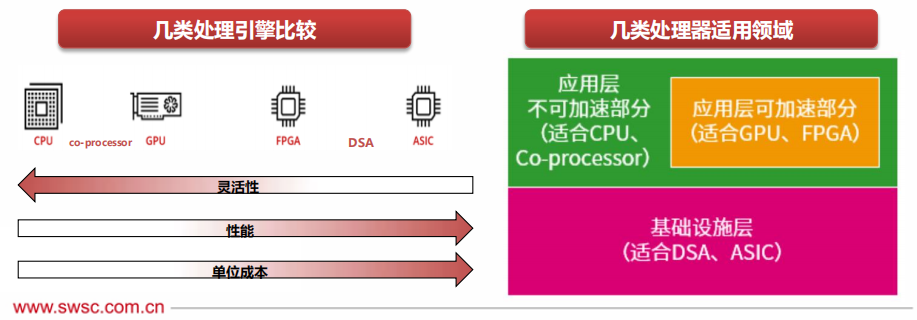
FPGA,從架構(gòu)上來說,可以用來實現(xiàn)定制的ASIC引擎,但因為硬件可編程的能力,可以切換到其他ASIC引 擎,具有一定的彈性可編程能力。
DSA,是接近于ASIC的設(shè)計,但具有一定程度上的可編程。覆蓋的領(lǐng)域和場景比ASIC要大,但依然存在太多的領(lǐng)域需要特定的DSA去覆蓋。
ASIC,是完全不可編程的定制處理引擎,理論上最復(fù)雜的“指令”以及最高的性能效率。因為覆蓋的場景非常小,因此需要數(shù)量眾多的ASIC處理引擎,才能覆蓋各類場景。
后摩爾定律時代,展望CPU未來發(fā)展之路
不可逆轉(zhuǎn)的SoC集成:由于集成電路集成度不斷提高,將完整計算機(jī)所有不同的功能塊一次直接集成于一顆芯片上的 SoC 片上就成為整個半導(dǎo)體行業(yè)發(fā)展的一個趨勢,可以顯著降低系統(tǒng)成本和功耗,提高系統(tǒng)可靠性。M1 并不是傳統(tǒng)意義上的 CPU,而是一顆SoC。CPU采用了8核心,包括4個高性能核心和4個高能效核心。每個高性能核心都提供出色的單線程任務(wù)處理性能,并在允許的范圍內(nèi)將能耗降至最低。
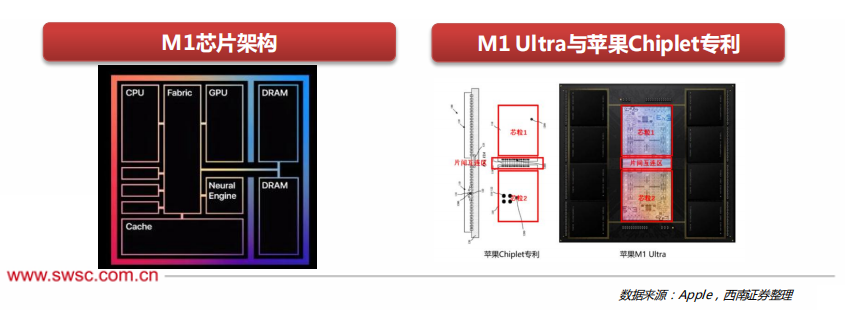
異構(gòu)能力的大幅提升:M1還采用了統(tǒng)一內(nèi)存架構(gòu)(UMA),CPU、GPU、神經(jīng)引擎、緩存、DRAM內(nèi)存全部通過Fabric高速總線連接在一起,得益于此,SoC中的所有模塊都可以訪問相同的數(shù)據(jù),而無需在多個內(nèi)存池之間復(fù)制數(shù)據(jù),帶寬更高、延遲更低,大大提高了處理器的性能和電源效率。此外,最新一代的M1 Ultra本質(zhì)上是兩個M1 MAX的有效組合,通過UltraFusion架構(gòu),提供高達(dá)128G統(tǒng)一內(nèi)存,相較M1的GPU性能提高8倍。
蘋果M1處理器完成了一次從多芯片走向一體化的過程,這也是蘋果打造完整PC生態(tài)鏈的必經(jīng)之路,讓我們看見了CPU未來發(fā)展的更多可能性。
后摩爾時代,異構(gòu)與集成
海外芯片巨頭積極布局異構(gòu)計算:英特爾現(xiàn)已布局CPU、FPGA、IPU、GPU產(chǎn)品線,并接連公布Alder Lake、Falcon Shores等新架構(gòu);英偉達(dá)接連發(fā)布多芯片模組(MCM,Multi-ChipModule)Grace系列產(chǎn)品,預(yù)計即將投入量產(chǎn);AMD則于近日完成對塞靈思的收購,預(yù)計未來走向CPU+FPGA的異構(gòu)整合。
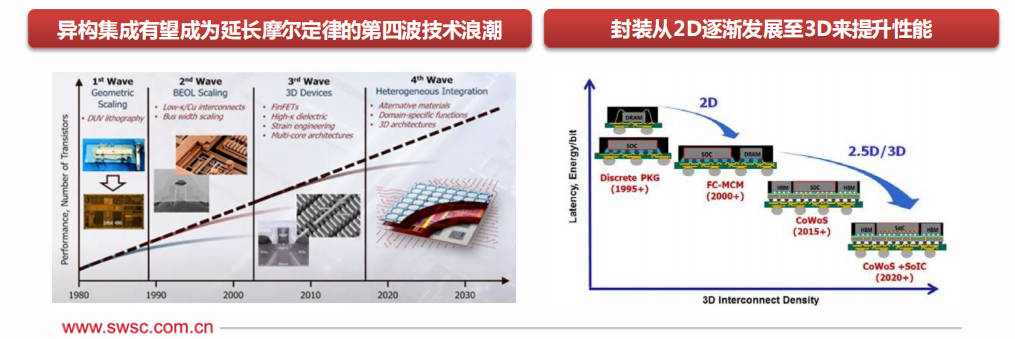
晶圓廠和封裝廠亦積極投入異構(gòu)集成:異構(gòu)計算需要有先進(jìn)的集成封裝技術(shù),得益于近十年來先進(jìn)封裝與芯片堆疊技術(shù)的發(fā)展,例如3D堆疊、SiP等,也使得異構(gòu)集成成為了大幅存在可能。目前,2.5D封裝技術(shù)已發(fā)展較為成熟,例如臺積電的CoWoS,三星的I-Cube,3D封裝成為各大晶圓廠發(fā)力方向。英特爾已開始量產(chǎn)Foveros技術(shù),三星已完成X-Cube的驗證,臺積電亦提出了SoiC的整合方案。
CPU+XPU已廣泛應(yīng)用,但仍有優(yōu)化空間。傳統(tǒng)的異構(gòu)計算架構(gòu)存在IO路徑較長,輸入輸出資源損耗等固有問題,并且仍然無法完全兼顧極致性能與靈活性。
Chiplet聯(lián)盟組建,探索超異構(gòu)可能性。2022年3月3日,英特爾、AMD、Arm、高通、臺積電、三星、日月光、Google云、Meta、微軟等十大行業(yè)巨頭聯(lián)合成立了Chiplet標(biāo)準(zhǔn)聯(lián)盟,正式推出了通用Chiplet的高速互聯(lián)標(biāo)準(zhǔn)“Universal Chiplet Interconnect Express”(通用小芯片互連,簡稱“UCIe”)。

在UCIe的框架下,互聯(lián)接口標(biāo)準(zhǔn)得到統(tǒng)一。各類不同工藝、不同功能的Chiplet芯片,有望通過2D、2.5D、3D等各種封裝方式整合在一起,多種形態(tài)的處理引擎共同組成超大規(guī)模的復(fù)雜芯片系統(tǒng),具有高帶寬、低延遲、經(jīng)濟(jì)節(jié)能的優(yōu)點。
邊緣計算服務(wù)器是解決AIoT時代“算力荒”的必備產(chǎn)物
云計算無法滿足海量、實時的處理需求。伴隨人工智能、5G、物聯(lián)網(wǎng)等技術(shù)的逐漸成熟,算力需求從數(shù)據(jù)中心不斷延伸至邊緣,以產(chǎn)生更快的網(wǎng)絡(luò)服務(wù)響應(yīng),滿足行業(yè)在實時業(yè)務(wù)、應(yīng)用智能、安全與隱私保護(hù)等方面的基本需求。

市場規(guī)模爆發(fā)式增長。根據(jù)IDC,中國邊緣計算服務(wù)器整體市場規(guī)模達(dá)到33.1億美元,較2020年增長23.9%,預(yù)計2020-2025年CAGR將達(dá)到22.2%,高于全球的20.2%。
定制服務(wù)器快速增加。當(dāng)前通用服務(wù)器和邊緣定制服務(wù)器占比分別為87.1%和12.9%,隨著邊緣應(yīng)用場景的逐漸豐富,為適應(yīng)復(fù)雜多樣的部署環(huán)境和業(yè)務(wù)需求,對于具有特定外形尺寸、低能耗、更寬工作溫度以及其他特定設(shè)計的邊緣定制服務(wù)器的需求將快速增加。IDC預(yù)計邊緣定制服務(wù)器將保持76.7%的復(fù)合增速,2025年滲透率將超過40%。
根據(jù)業(yè)務(wù)場景多樣定制,集成化是趨勢
區(qū)別于數(shù)據(jù)中心服務(wù)器,邊緣服務(wù)器配置并不一味追求最高計算性能、最大存儲、最大擴(kuò)展卡數(shù)量等參數(shù),而是在有限空間里面盡量提供配置靈活性。當(dāng)前邊緣服務(wù)器多用于工業(yè)制造等領(lǐng)域,需根據(jù)具體環(huán)境(高壓、低溫、極端天氣)等選擇主板、處理器等,下游需求呈現(xiàn)碎片化,未有統(tǒng)一的標(biāo)準(zhǔn)。
伴隨越來越多的計算、存儲需求被下放至邊緣端,當(dāng)前趨勢通常涉及更緊密的加速集成,以滿足包括AI算力在內(nèi)的多種需求。超大規(guī)模云提供商正在開始研究分類體系結(jié)構(gòu),為了減少熟悉的多租戶方法不可避免的碎片化,其中計算、存儲、網(wǎng)絡(luò)和內(nèi)存成為一組可組合的結(jié)構(gòu),機(jī)柜式架構(gòu)(RSA)分別部署了CPU、GPU、硬件加速、RAM、存儲和網(wǎng)絡(luò)容量。
云服務(wù)器正在全球范圍內(nèi)取代傳統(tǒng)服務(wù)器
云服務(wù)器的發(fā)展使中國成為全球服務(wù)器大國。隨著移動終端、云計算等新一代信息技術(shù)的發(fā)展和應(yīng)用,企業(yè)和政府正陸續(xù)將業(yè)務(wù)從傳統(tǒng)數(shù)據(jù)中心向云數(shù)據(jù)中心遷移。雖然目前中國云計算領(lǐng)域市場相比美國相對落后,但近年來我國的云計算發(fā)展速度顯著高于全球云計算市場增長速度,預(yù)計未來仍將保持這一趨勢。

面向不同需求,提供多樣性算力。一般小型網(wǎng)站請求處理數(shù)據(jù)較少,多采用1、2核CPU;地方門戶、小型行業(yè)網(wǎng)站,需要4核以上的CPU;而電商平臺,影視類網(wǎng)站等,則需要16核以上的CPU。此外,云服務(wù)器亦提供靈活的擴(kuò)容、升級等服務(wù),一般均支持異構(gòu)類算力的加載。
CPU+ASIC,云服務(wù)器異構(gòu)趨勢明顯
在傳統(tǒng)的計算機(jī)虛擬化架構(gòu)中,業(yè)務(wù)層為虛擬機(jī),管理層為宿主機(jī),業(yè)務(wù)和管理共存于CPU運(yùn)行,導(dǎo)致CPU大概只有七成的資源能夠提供給用戶。
AWS創(chuàng)造性進(jìn)行架構(gòu)重構(gòu),將業(yè)務(wù)和管理分離到兩個硬件實體中,業(yè)務(wù)運(yùn)行在CPU,管理則運(yùn)行在NITRO芯片中,既將虛擬化的損耗挪到定制的Nitro系統(tǒng)上,又提高了安全性。
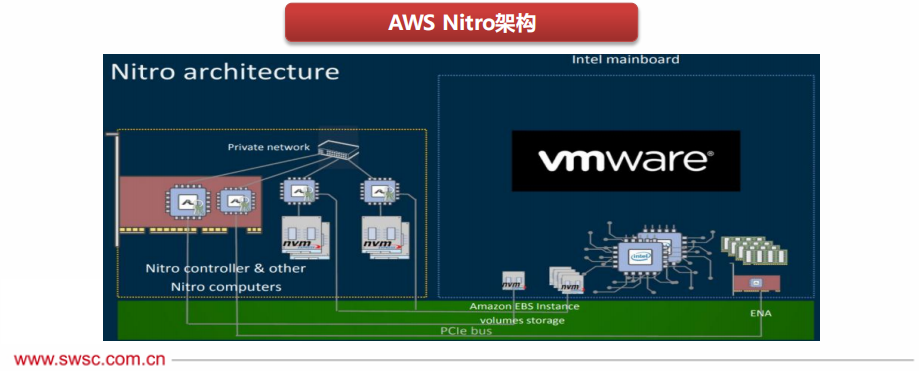
Nitro架構(gòu)不僅性能強(qiáng)大,而且特別靈活,可以基于一些常用的Hypervisor(如qemu-kvm,vmware)運(yùn)行虛擬機(jī),甚至可以直接裸跑操作系統(tǒng),可節(jié)省30%CPU資源。
ARM或成重要挑戰(zhàn)者,英偉達(dá)推出首款數(shù)據(jù)中心專屬CPU GRACE
公有云巨頭價格競爭激烈,國內(nèi)一線城市能耗管控嚴(yán)格,ARM移動端的優(yōu)勢和低能耗特征是超大型數(shù)據(jù)中心解決節(jié)能和成本問題的重要方案之一;國內(nèi)自主可控趨勢背景下,若能夠搭建強(qiáng)有力的生態(tài)聯(lián)盟,是未來可能顛覆原有格局的最有力挑戰(zhàn)者。

英偉達(dá)宣布推出首款面向AI基礎(chǔ)設(shè)施和高性能計算的數(shù)據(jù)中心專屬CPU——NvDIA Grace,由兩個CPU芯片通過最新一代NVLink-C2C技術(shù)互聯(lián)組成。
Grace基于最新的ARMv9架構(gòu),單個socket擁有144個CPU核心,利用糾錯碼(ECC)等機(jī)制提供當(dāng)今領(lǐng)先服務(wù)器芯片兩倍的內(nèi)存帶寬和能效,兼容性亦十分突出,可運(yùn)行NvDIA所有的軟件堆棧和平臺,包括NvDIA RTX、HPC、Omniverse等。
從CPU到CPU+DPU
DPU,即數(shù)據(jù)處理單元(Data Processing Unit),主要作為CPU的卸載引擎,主要處理網(wǎng)絡(luò)數(shù)據(jù)和IO數(shù)據(jù),并提供帶寬壓縮、安全加密、網(wǎng)絡(luò)功能虛擬化等功能,以釋放CPU的算力到上層應(yīng)用。
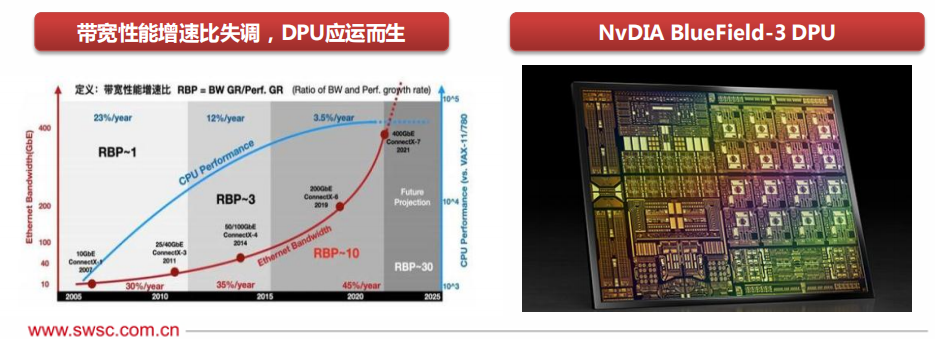
2013年,AWS研發(fā)的的Nitro和阿里云研發(fā)的X-Dragon均可看作DPU前身;英偉達(dá)在2020年正式發(fā)布一款命名為“DPU”的產(chǎn)品,將其定義為CPU和GPU之后的第三顆主力芯片,DPU的出現(xiàn)是異構(gòu)計算的另一個階段性標(biāo)志。
DPU是CPU和GPU的良好補(bǔ)充,據(jù)英偉達(dá)預(yù)測,每臺服務(wù)器可能沒有GPU,但必須有DPU,用于數(shù)據(jù)中心的DPU的量將達(dá)到和數(shù)據(jù)中心服務(wù)器等量的級別。
從CPU到CPU+XPU
AI模型通過數(shù)千億的參數(shù)進(jìn)行訓(xùn)練,增強(qiáng)包含數(shù)萬億字節(jié)的深度推薦系統(tǒng),其復(fù)雜性和規(guī)模正呈現(xiàn)爆炸式增長。這些龐大的模型正在挑戰(zhàn)當(dāng)今系統(tǒng)的極限,僅憑CPU的優(yōu)化難以滿足其性能需求。
因此,AI服務(wù)器主要采用異構(gòu)形式,表現(xiàn)形態(tài)多為機(jī)架式。在異構(gòu)方式上,可以為CPU+GPU、CPU+FPGA、CPU+TPU、CPU+ASIC或CPU+多種加速卡。

現(xiàn)在市面上的AI服務(wù)器普遍采用CPU+GPU的形式,因為GPU與CPU不同,采用的是并行計算的模式,擅長梳理密集型的數(shù)據(jù)運(yùn)算,如圖形渲染、機(jī)器學(xué)習(xí)等。繼續(xù)擴(kuò)展模型以實現(xiàn)高度準(zhǔn)確性和實用性,需要能夠快速訪問大型內(nèi)存池并使 CPU 和 GPU 緊密耦合。
從CPU到CPU+TPU
TPU,即張量處理單元(Tensor Processing Unit),是Google為加速深度學(xué)習(xí)所開發(fā)的專用集成電路(DSA),采用專用CISC指令集,自定義改良邏輯、線路、運(yùn)算單元、內(nèi)存系統(tǒng)架構(gòu)、片上互聯(lián)等,并針對Tensorflow等開源框架進(jìn)行優(yōu)化。
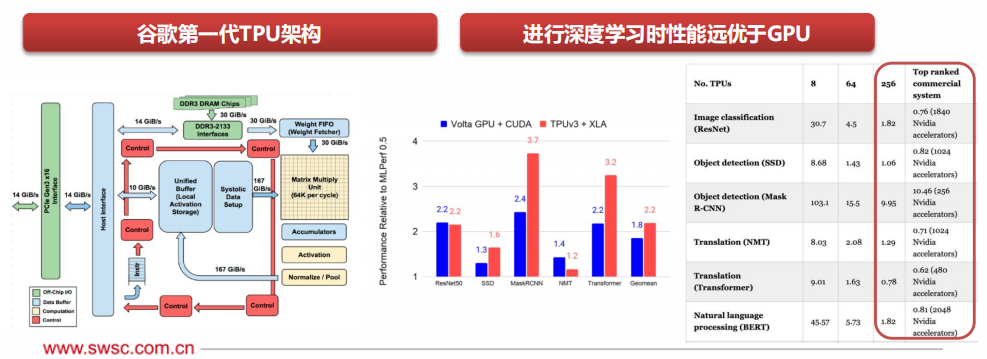
2015年起,谷歌發(fā)布TPUv1,應(yīng)用于Alpha Go等特定內(nèi)部項目;2018年,谷歌發(fā)布TPUv3,開始向第三方出售,TPU開始逐漸走向商用。
2021年,谷歌發(fā)布TPUv4i,其性能相較第三代TPU提升2.7倍;256塊TPU僅用1.82分鐘便完成NLP領(lǐng)域著名的“BERT”模型訓(xùn)練,而同樣條件下,利用Nvdia A100 GPU則需要3.36分鐘。
審核編輯 :李倩
-
處理器
+關(guān)注
關(guān)注
68文章
19273瀏覽量
229724 -
芯片
+關(guān)注
關(guān)注
455文章
50756瀏覽量
423342 -
摩爾定律
+關(guān)注
關(guān)注
4文章
634瀏覽量
79009
原文標(biāo)題:未來CPU處理器技術(shù)演進(jìn)路線
文章出處:【微信號:AI_Architect,微信公眾號:智能計算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
未來10年智能傳感器怎么發(fā)展?美國發(fā)布最新MEMS路線圖

NPU與傳統(tǒng)處理器的區(qū)別是什么
微處理機(jī)和微處理器的區(qū)別
微處理器與CPU的關(guān)系
AMD全新處理器擴(kuò)大數(shù)據(jù)中心CPU的領(lǐng)先地位
ARM處理器和CPU有什么區(qū)別
簡述微處理器的發(fā)展歷史
處理器的定義和種類






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論