") 智慧病房手勢(shì)識(shí)別解決方案
智慧病房手勢(shì)識(shí)別解決方案
新一年的集創(chuàng)賽已如火如荼的展開(kāi)~
為了讓大家更多的了解該賽事,小編整理了2021年的優(yōu)秀作品供學(xué)習(xí)分享
在每周一為大家分享獲獎(jiǎng)作品,記得來(lái)看連載喲 ~
團(tuán)隊(duì)介紹
參賽單位:上海交通大學(xué)
隊(duì)伍名稱(chēng):芯靈手巧
指導(dǎo)老師:王琴、景乃鋒
參賽隊(duì)員:林圣凱、林新源、莫志文
總決賽獎(jiǎng)項(xiàng):二等獎(jiǎng)
1.項(xiàng)目概述
1.1 選題背景
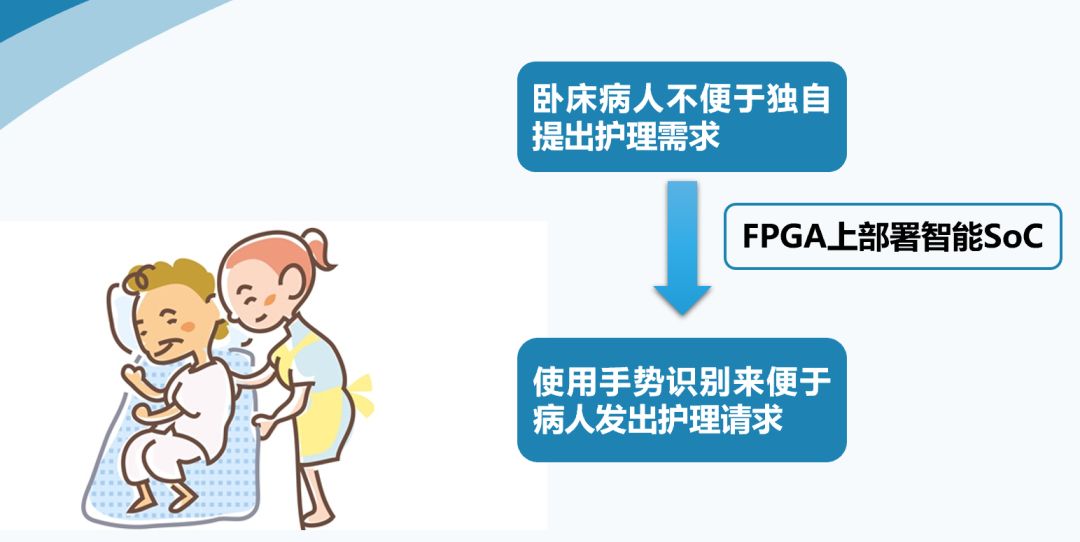
我們的選題背景是考慮到很多臥床病人不便于獨(dú)自向醫(yī)護(hù)人員提出護(hù)理請(qǐng)求,因此我們想到在FPGA上部署智能SOC,實(shí)現(xiàn)手勢(shì)識(shí)別功能,從而使病人可以使用手勢(shì)來(lái)發(fā)出護(hù)理請(qǐng)求。
1.2 方案設(shè)計(jì)
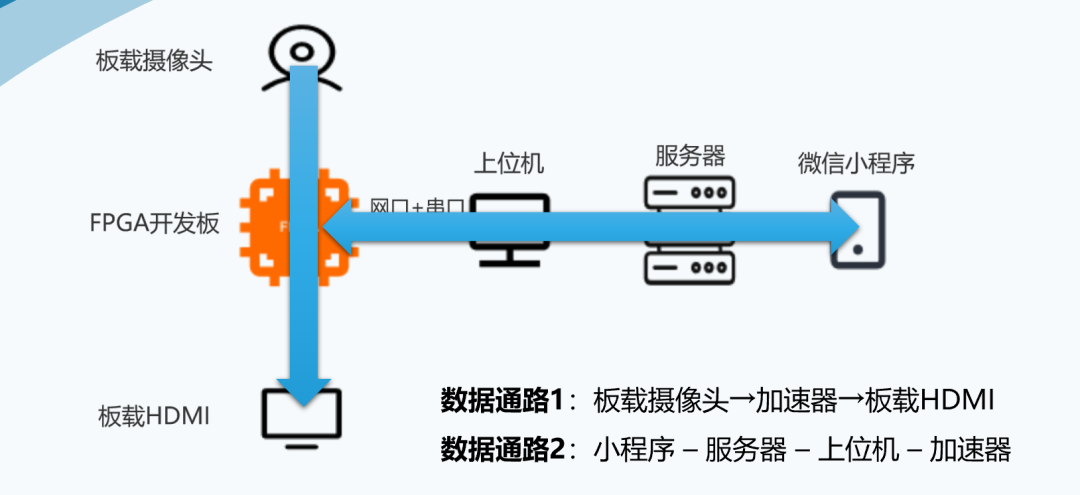
我們共實(shí)現(xiàn)了兩套方案,其中一套數(shù)據(jù)通路是從板載攝像頭輸入,HDMI顯示圖像,加速器處理后將結(jié)果上傳上位機(jī)
另一套是由小程序采集圖像,經(jīng)服務(wù)器、上位機(jī)傳至加速器,再經(jīng)由原路返回小程序
1.3 項(xiàng)目工作
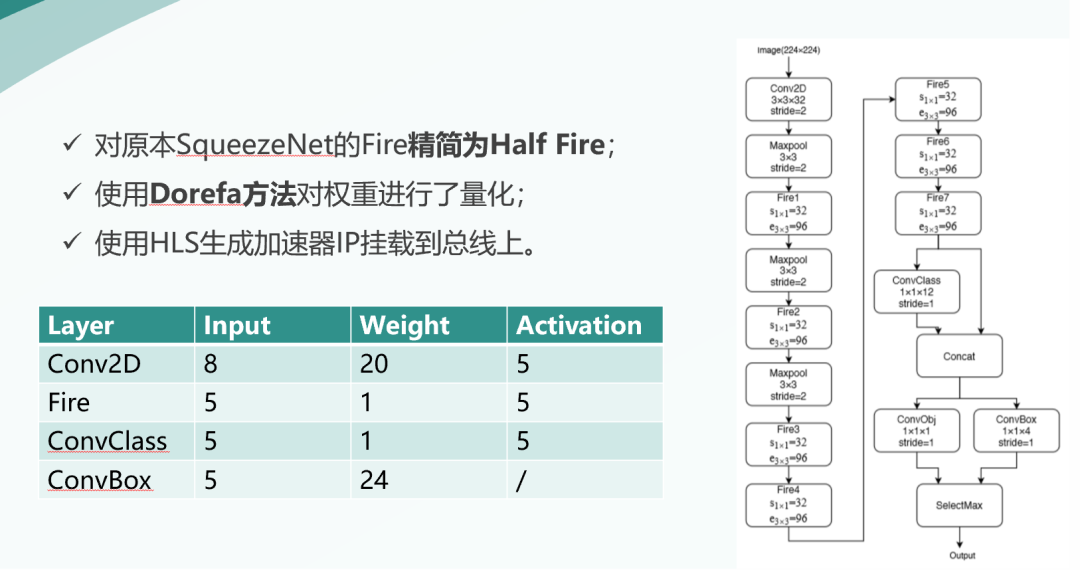
我們完成了賽方要求實(shí)現(xiàn)的所有基本功能,如表所示。
另外,我們超額完成了網(wǎng)口輸入視頻流功能、針對(duì)醫(yī)療應(yīng)用場(chǎng)景的上位機(jī)與小程序設(shè)計(jì),同時(shí)我們的系統(tǒng)支持不同權(quán)重用于不同應(yīng)用,使得系統(tǒng)應(yīng)用拓展性進(jìn)一步提升。

1.4 性能參數(shù)
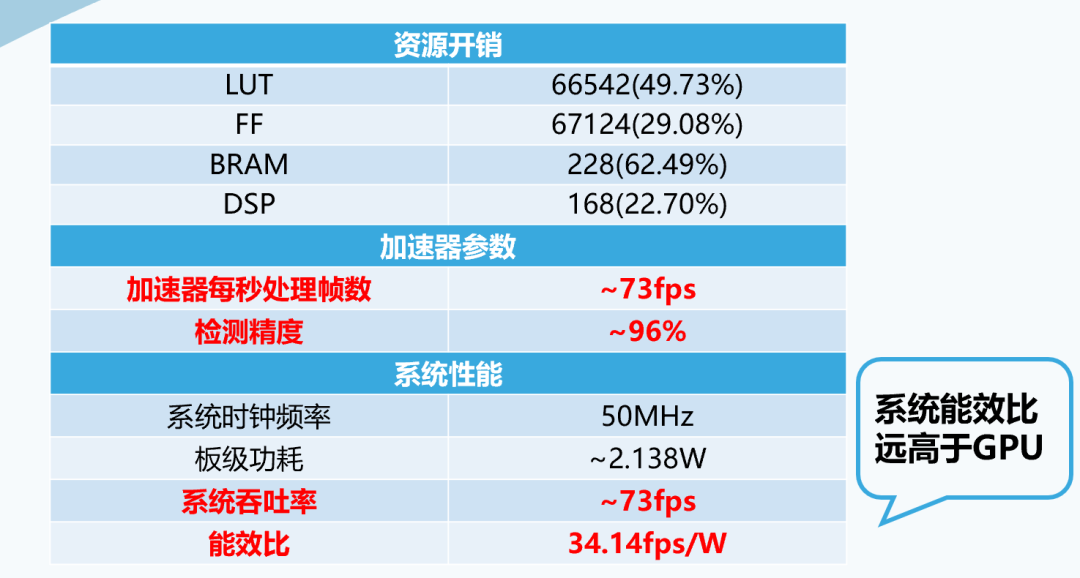
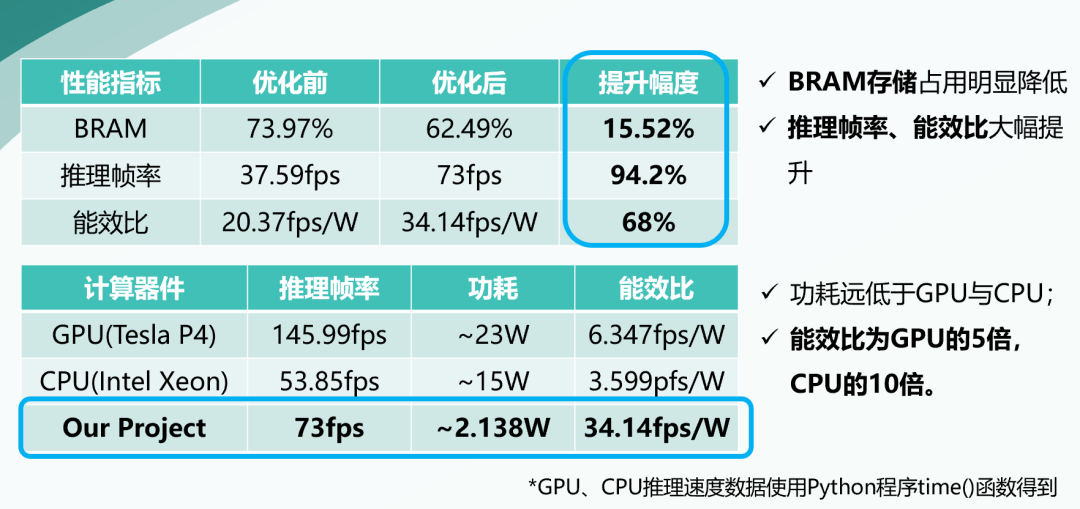
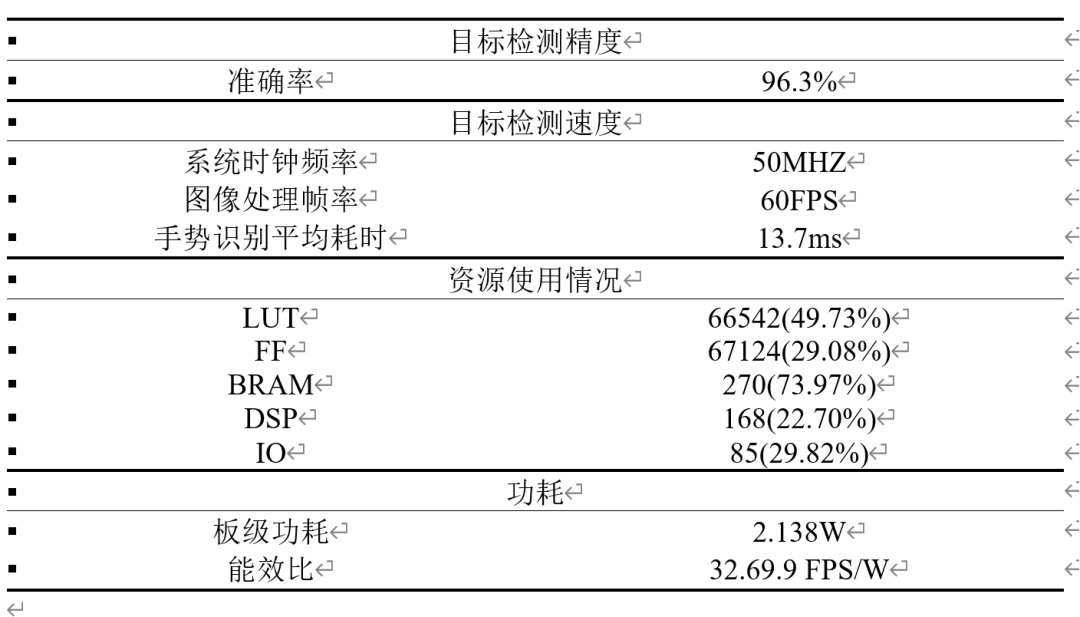
我們的項(xiàng)目已經(jīng)在Artix-7 200T開(kāi)發(fā)板上實(shí)現(xiàn),在資源開(kāi)銷(xiāo)方面,我們使用了200t開(kāi)發(fā)板三成以下的寄存器和DSP,大約一半的查找表,以及約六成的BRAM。我們的加速器可以每秒處理73幀左右,在測(cè)試集上的檢測(cè)精度達(dá)到了約96%。我們的系統(tǒng)工作在50MHz的時(shí)鐘頻率,vivado實(shí)現(xiàn)之后顯示其板級(jí)功耗為2.138W,可計(jì)算出能效比為34.14fps/W,經(jīng)過(guò)測(cè)試,該能效比遠(yuǎn)遠(yuǎn)高于使用GPU或CPU推理時(shí)的能效比。
2.硬件介紹
2.1 整體架構(gòu)
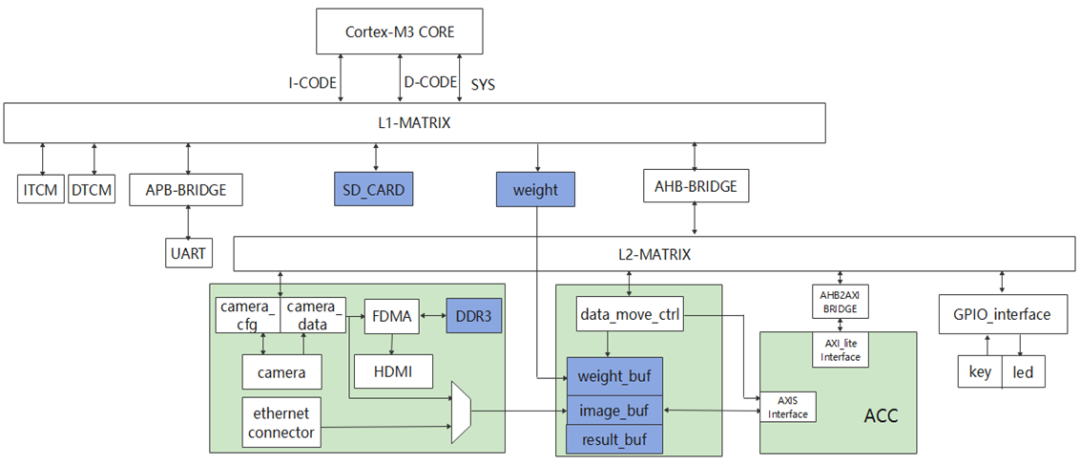
我們的整體系統(tǒng)包括圖像采集與顯示子系統(tǒng)以及加速器子系統(tǒng)兩大部分。
2.2 圖像輸入與顯示子系統(tǒng)
我們的圖像采集與顯示子系統(tǒng) 可以經(jīng)由攝像頭或網(wǎng)口輸入圖像,經(jīng)過(guò)MUX選擇之后送入加速器。由此我們實(shí)現(xiàn)了多數(shù)據(jù)通路功能。
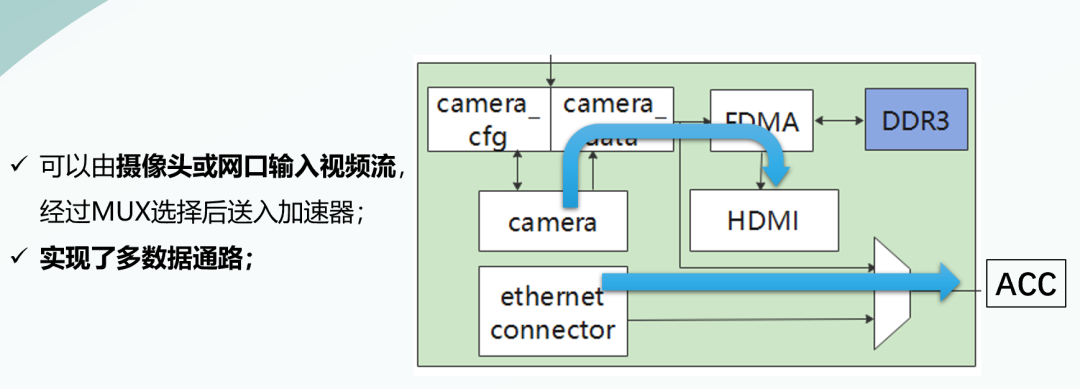
特別地,我們的網(wǎng)口支持360Mbps的網(wǎng)口速率,并在板上實(shí)現(xiàn)了UDP、IP、MAC層的接收功能,該部分電路與板載的PHY芯片配合實(shí)現(xiàn)了完整以太網(wǎng)接收功能。

2.3 加速器子系統(tǒng)
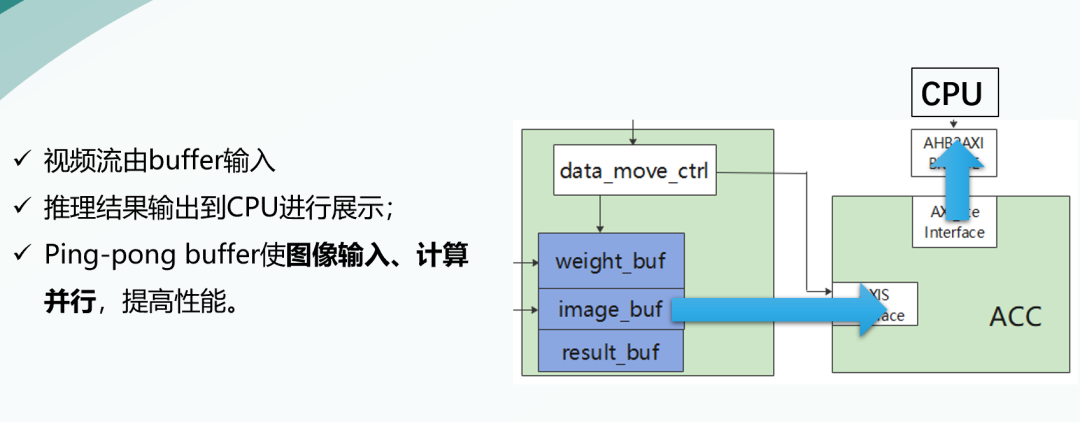
加速器子系統(tǒng)包括加速器及外圍緩存。
視頻流由buffer輸入,推理結(jié)果輸出到CPU進(jìn)行展示。
我們使用了Ping-pong buffer使圖像輸入、計(jì)算并行,提高性能。
2.4 加速器子系統(tǒng)的優(yōu)化
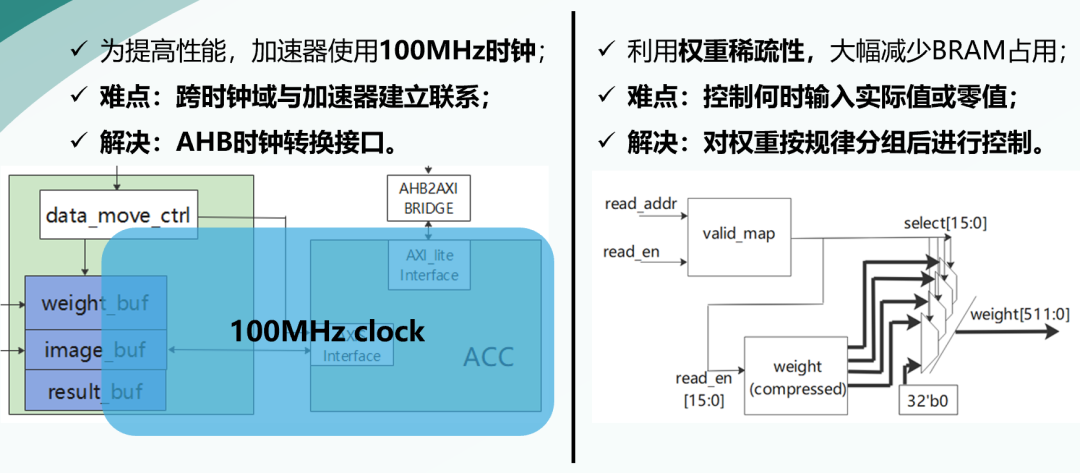
在復(fù)賽之后,我們團(tuán)隊(duì)對(duì)系統(tǒng)進(jìn)行了優(yōu)化。為提高性能,加速器使用100MHz的時(shí)鐘,為了解決跨時(shí)鐘域與加速器通信的問(wèn)題,我們使用AHB時(shí)鐘轉(zhuǎn)換接口控制加速器。我們利用加速器權(quán)重稀疏性,大幅減少BRAM占用。
為解決權(quán)重輸入的控制問(wèn)題,我們對(duì)權(quán)重按規(guī)律分組之后,降低了控制難度。
經(jīng)過(guò)了上述優(yōu)化,我們通過(guò)劃分時(shí)鐘域提升了推理幀率,提升幅度達(dá)94.2%,同時(shí)我們的能效比相比之前提升達(dá)68%;我們利用權(quán)重稀疏性減少了15.52%的BRAM占用。由此我們的加速器子系統(tǒng)在板上資源占用和性能等方面均取得了明顯的改善。最終,經(jīng)過(guò)我們的實(shí)際對(duì)GPU與CPU的能效比進(jìn)行測(cè)試,我們的SoC系統(tǒng)的能效比遠(yuǎn)高于GPU和CPU的能效比,是GPU的5倍,CPU的十倍。我們SoC的優(yōu)化效果顯著。
3.軟件工作介紹
3.1 加速器結(jié)構(gòu)
我們的加速器是基于SqueezeNet設(shè)計(jì),將原本的Fire模塊進(jìn)行了一定程度的精簡(jiǎn),去除了原本Fire模塊中的一些卷積核。
同時(shí)我們使用Dorefa方法對(duì)網(wǎng)絡(luò)參數(shù)進(jìn)行低比特量化,我們將大多數(shù)權(quán)重量化至1bit,輸入和輸出量化為5bit。
加速器使用HLS編寫(xiě),并綜合之后生成IP,掛載到了總線上。
3.2 數(shù)據(jù)集準(zhǔn)備
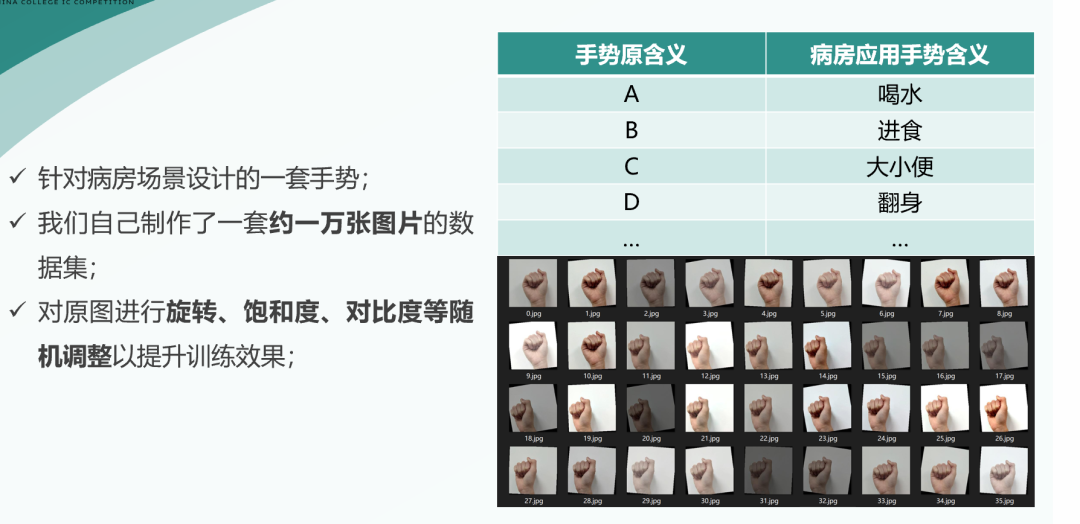
我們?cè)O(shè)計(jì)了基于美國(guó)手語(yǔ)字母的一套手勢(shì),我們將原本的字母的含義映射到病房場(chǎng)景下的各種具體含義,如右表所示。
為了訓(xùn)練神經(jīng)網(wǎng)絡(luò),我們自己制作了一套大約一萬(wàn)張圖片的數(shù)據(jù)集,之后隨機(jī)進(jìn)行旋轉(zhuǎn)、飽和度、對(duì)比度等調(diào)整以提升訓(xùn)練效果,最終效果如右下圖所示。
3.3 加速器訓(xùn)練結(jié)果
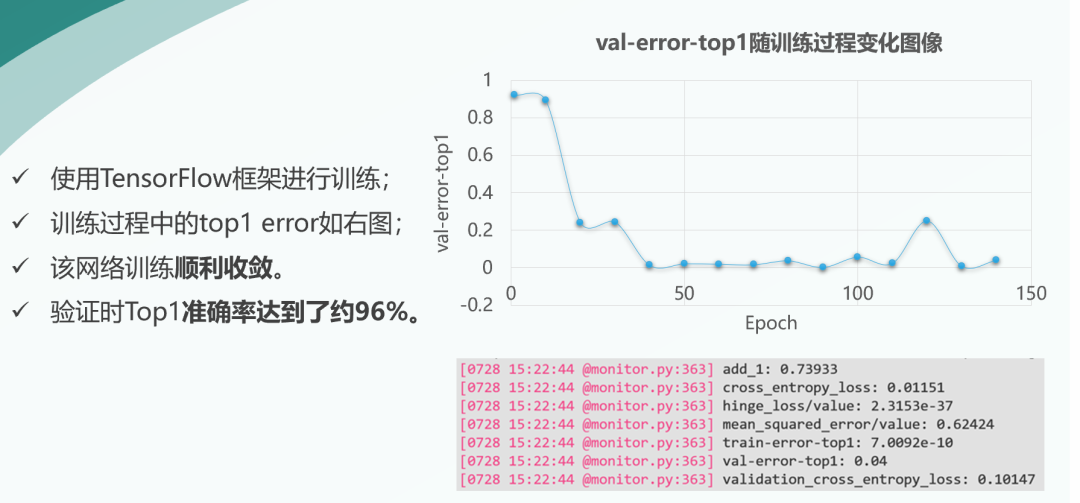
之后我們使用TensorFlow框架進(jìn)行訓(xùn)練,訓(xùn)練過(guò)程中,Top1錯(cuò)誤率如右圖所示,由圖可見(jiàn),訓(xùn)練過(guò)程順利收斂。最終我們訓(xùn)練Top1準(zhǔn)確率達(dá)到了約96%
3.4 上位機(jī)與小程序
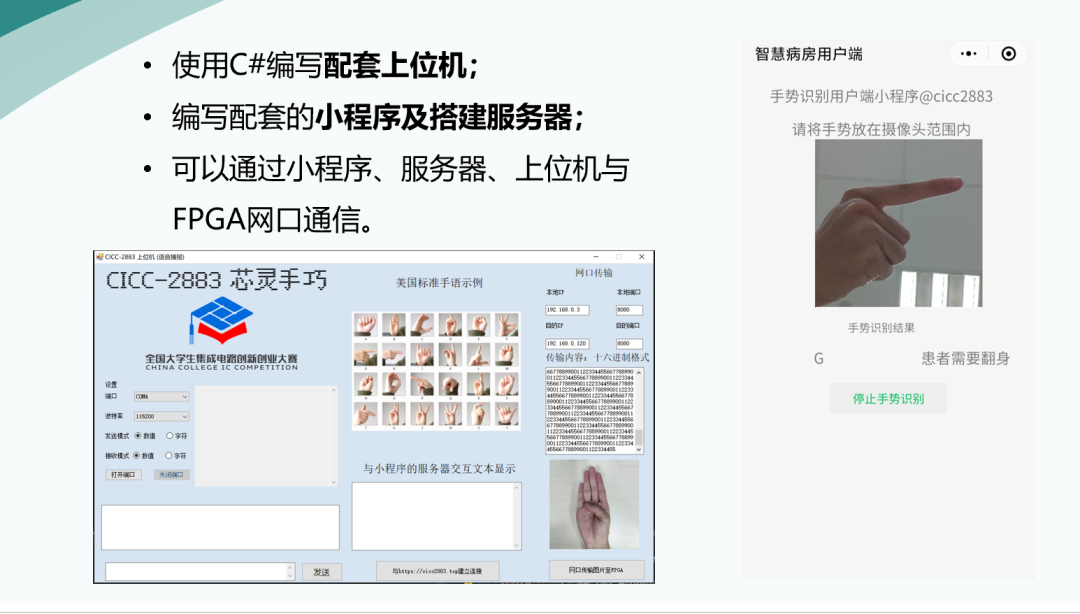
為了提升系統(tǒng)的實(shí)際應(yīng)用效果,我們使用C#編寫(xiě)了配套的上位機(jī),編寫(xiě)了配套的小程序并搭建了服務(wù)器。最終我們實(shí)現(xiàn)了可以通過(guò)小程序、服務(wù)器、上位機(jī)與FPGA網(wǎng)口通信。
4.仿真與上板測(cè)試
我們分別對(duì)SoC、DDR、DATA\_CACHE、加速器模塊、SD卡、網(wǎng)口模塊的進(jìn)行了modelsim 仿真與上板測(cè)試結(jié)果或是上板之后利用 Vivado 下的集成邏輯
分析儀(ILA) 對(duì)于關(guān)鍵信號(hào)線的抓取與驗(yàn)證。在通過(guò)以下各個(gè)模塊的仿真與驗(yàn)證之后, 我們認(rèn)為相應(yīng)模塊的配置與運(yùn)行結(jié)果都是符合預(yù)期的。
4.1 SoC基本功能仿真
在整個(gè)項(xiàng)目開(kāi)始之初,我們?cè)趍odelsim對(duì)SoC基本系統(tǒng)進(jìn)行了RTL仿真,結(jié)果如圖4-1所示,在上電復(fù)位后,系統(tǒng)總線有相應(yīng)變化,說(shuō)明SoC基本系統(tǒng)已正常運(yùn)行。

4.2 DDR模塊
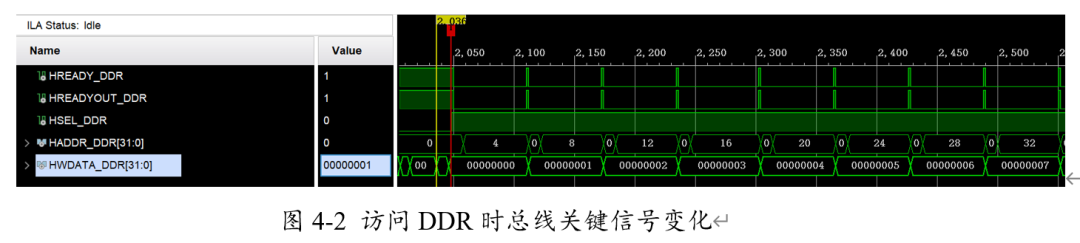
通過(guò)使用AHBlite-AXI轉(zhuǎn)接橋,我們將DDR掛載在L1總線矩陣上,并用ila對(duì)關(guān)鍵信號(hào)進(jìn)行抓取。如圖4-2所示:當(dāng)總線向DDR連續(xù)寫(xiě)入數(shù)據(jù)時(shí),總線的READY和READYOUT的實(shí)現(xiàn)正確握手,數(shù)據(jù)也正確傳遞到DDR的相應(yīng)地址。
4.3 SD卡模塊
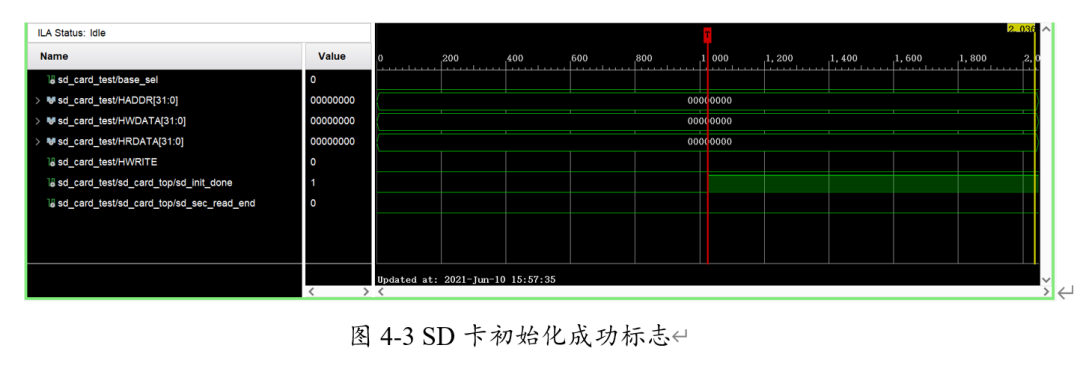
SD卡在上電后自動(dòng)進(jìn)行初始化,在一定時(shí)間后可以抓到sd_init_done信號(hào)變?yōu)楦唠娖剑硎維D卡正常初始化完成。
隨后,依次配置SD卡的讀扇區(qū)地址并開(kāi)始設(shè)置開(kāi)始讀取到片上BRAM。該過(guò)程總線信號(hào)如下。

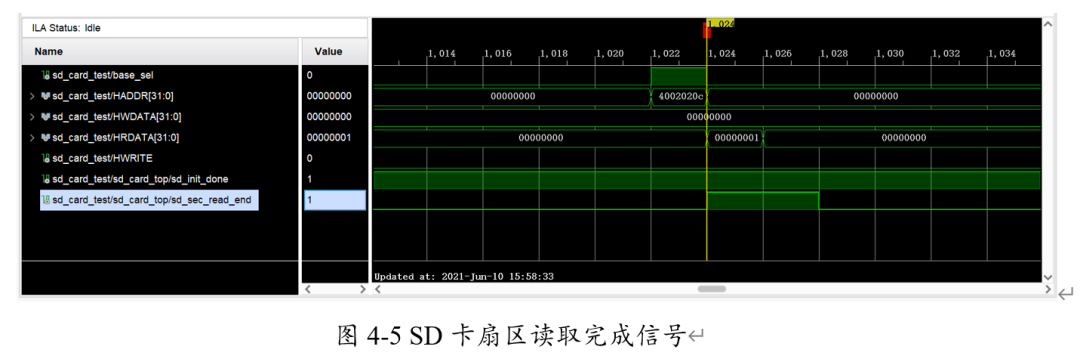
當(dāng)SD卡一個(gè)扇區(qū)讀取到片上完成時(shí),會(huì)拉高sd_sec_read_end,表示當(dāng)前扇區(qū)已經(jīng)讀取完成,如圖4-5。
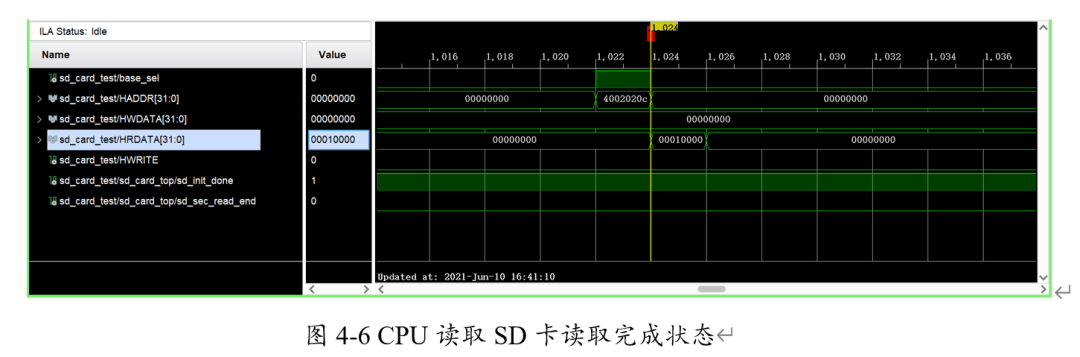
之后CPU便可以查詢到SD卡模塊相應(yīng)寄存器的變化為0x00010000,此即讀取完成狀態(tài),如圖4-6。
在之后,CPU就可以直接讀取暫存有扇區(qū)數(shù)據(jù)的BRAM,如圖4-7。這樣SD卡一個(gè)讀取過(guò)程已經(jīng)完成,此后循環(huán)此過(guò)程即可。至此SD卡正常工作狀態(tài)已經(jīng)得到驗(yàn)證。

4.4 加速器模塊
對(duì)于加速器模塊,我們進(jìn)行了從TensorFlow平臺(tái)測(cè)試,HLS C仿真,HLS C/RTL協(xié)同仿真,加速器搭載在最小系統(tǒng)仿真等非常規(guī)范的設(shè)計(jì)流程。
首先是TensorFlow平臺(tái)測(cè)試,如下圖所示:
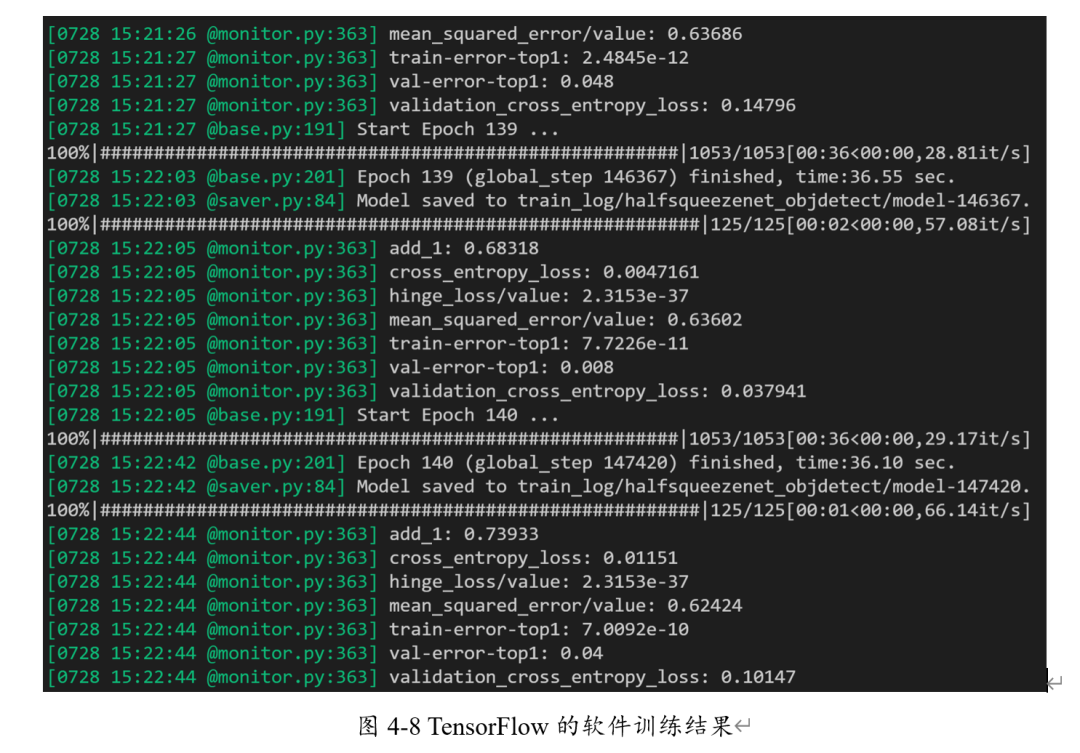
如上圖所示,幾次測(cè)試的Top1-錯(cuò)誤率分別為4.8%, 0.8%與4.0%,平均為4.73%。
接著,我們編寫(xiě)了HalfSqueezeNet的HLS C代碼,并對(duì)其進(jìn)行了多輪C仿真驗(yàn)證其正確性。下圖為舉例說(shuō)明。
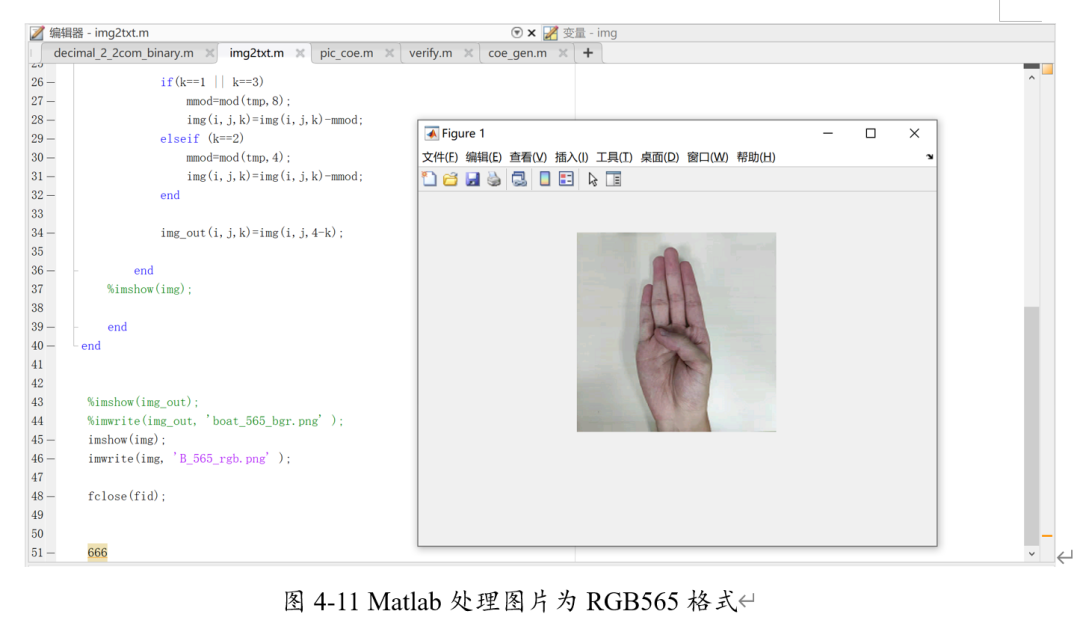
送入的圖像為如下所示。

美國(guó)標(biāo)準(zhǔn)手語(yǔ)如下:American Sign Language。

對(duì)比可知,這是手勢(shì)B。將其通過(guò)matlab轉(zhuǎn)化為565RGB圖像,使其與實(shí)際攝像頭送入的圖片格式相同。
對(duì)其進(jìn)行C仿真。(console中的紅框表示是C仿真)
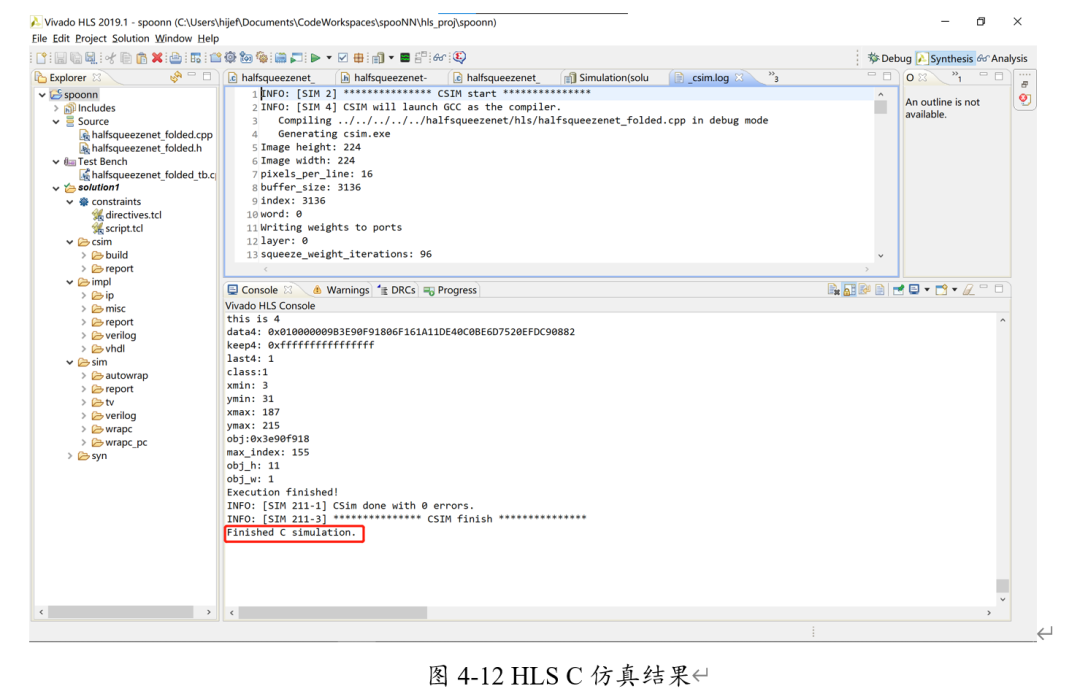
可以看出,C仿真的所得到結(jié)果為class=1,由于我們?cè)O(shè)置class=0為A,class=1為B……以此類(lèi)推。對(duì)比美國(guó)標(biāo)準(zhǔn)手勢(shì)圖,可以得知手勢(shì)的分類(lèi)結(jié)果是正確的。
接下來(lái)進(jìn)行C/RTL協(xié)同仿真。(console中的紅框表示是協(xié)同仿真)
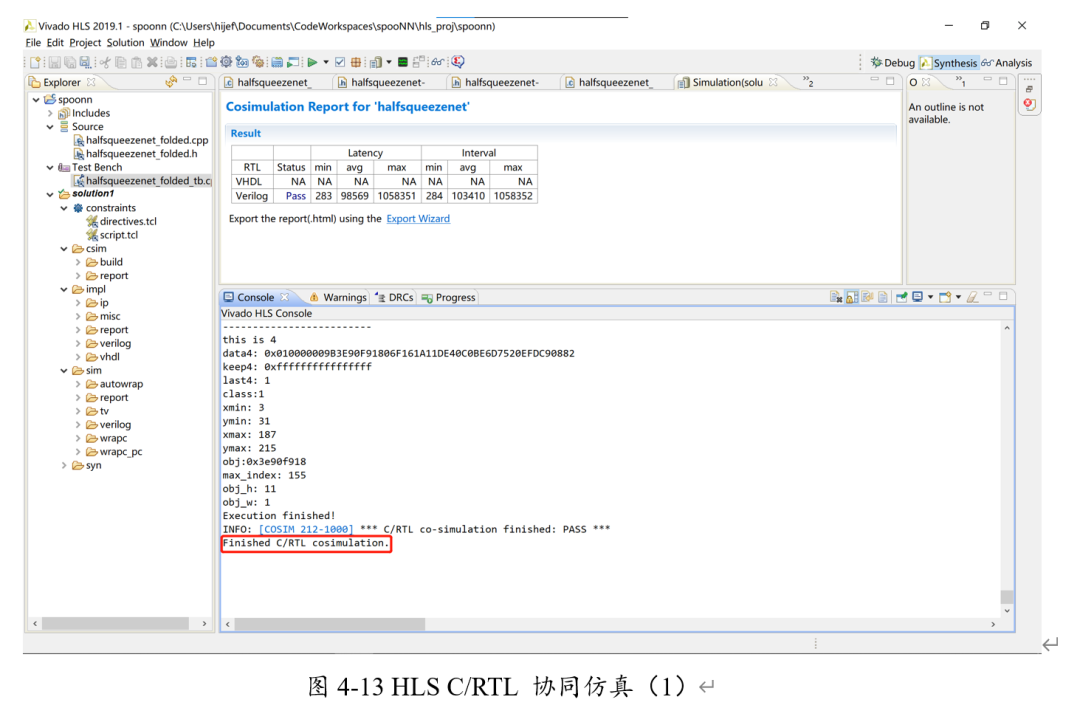
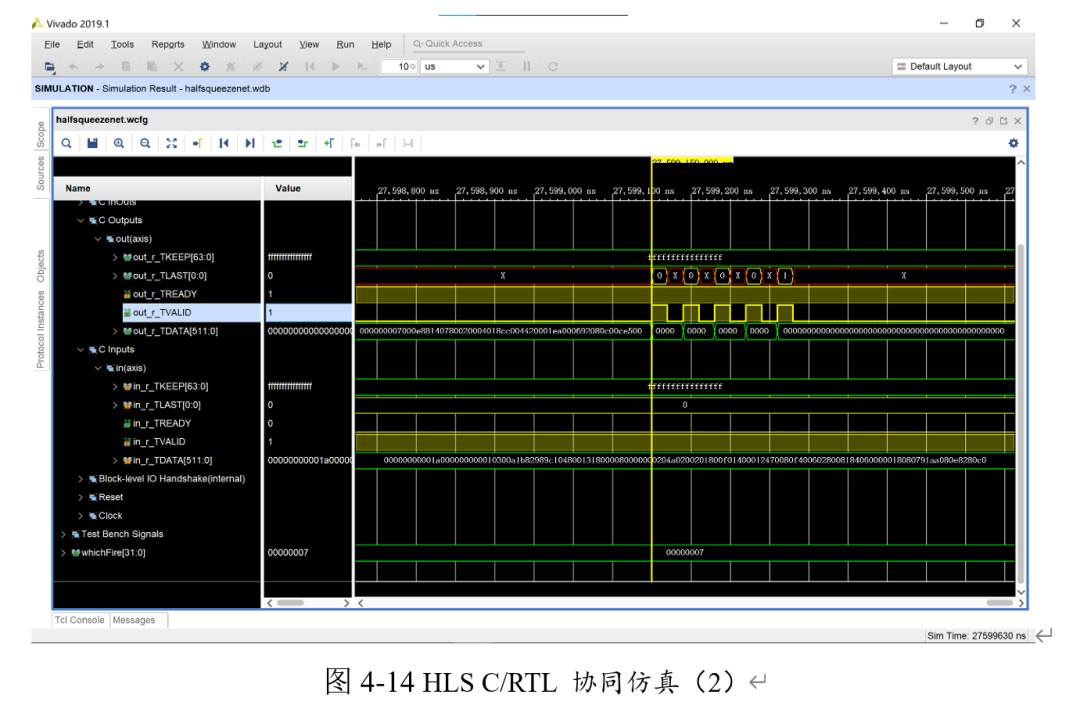
可以看出,分類(lèi)所得的class=1,即手勢(shì)B,結(jié)果正確。
最后進(jìn)行最小系統(tǒng)仿真。在搭建完最小系統(tǒng)之后,我們HLS生成的AXI lite與AXI Stream規(guī)范進(jìn)行配置,并將圖片和權(quán)重轉(zhuǎn)化為COE格式送入BRAM例化。最終所得的結(jié)果如下。
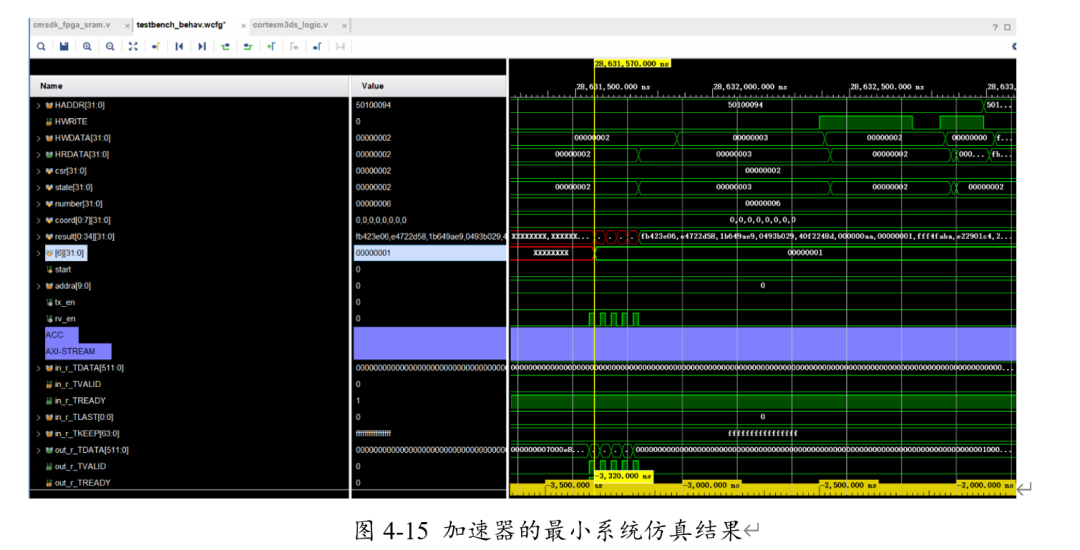
可以看出,最終result[6]的結(jié)果為1,即表明最終所得的分類(lèi)結(jié)果為B。
以上,HalfSqueezeNet的TensorFlow測(cè)試、C仿真、C/RTL協(xié)同仿真、最小系統(tǒng)仿真全部完成,我們有充分的理由相信加速器是可信可靠的。
4.5 網(wǎng)口模塊
對(duì)于網(wǎng)口模塊,我們對(duì)網(wǎng)口的最小系統(tǒng)通過(guò)抓市面上已有的網(wǎng)口調(diào)試助手向FPGA發(fā)送數(shù)據(jù)時(shí)抓ILA信號(hào)驗(yàn)證了FPGA網(wǎng)口模塊的正確性;接著我們自己用C#編寫(xiě)了帶網(wǎng)口傳輸功能的上位機(jī),并通過(guò)抓ILA來(lái)驗(yàn)證上位機(jī)功能的正確性。
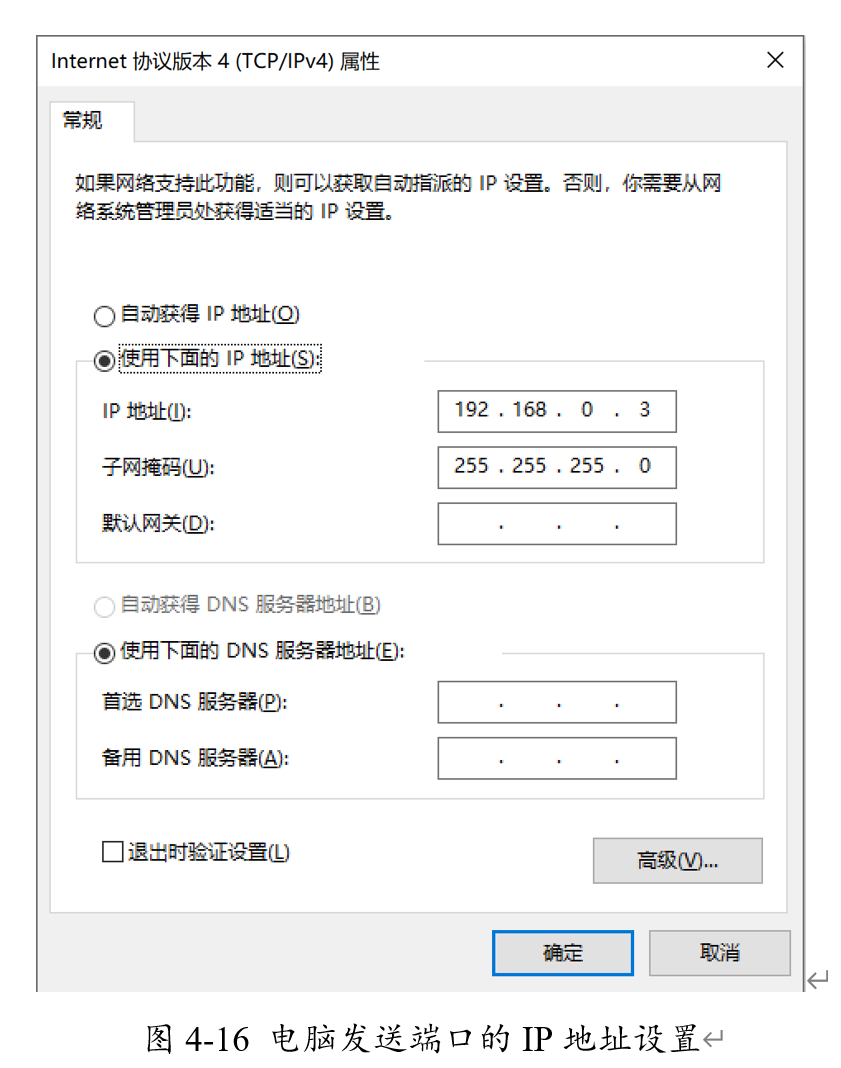
首先在系統(tǒng)中將電腦的網(wǎng)口發(fā)送端口設(shè)置IP為與FPGA中相同的IP地址,從而使得能順利通過(guò)FPGA中我們編寫(xiě)的UDP協(xié)議校驗(yàn)。
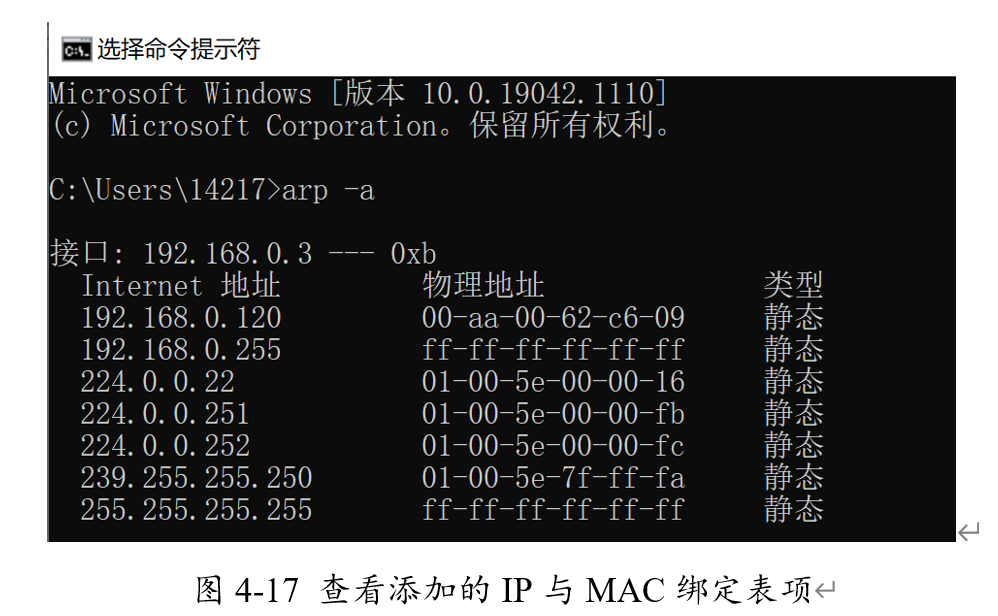
接著,我們?cè)赾md命令行中添加新的靜態(tài)表項(xiàng),將FPGA的IP地址192.168.0.120設(shè)置為對(duì)應(yīng)的MAC地址設(shè)置為00-AA-00-62-C6-09。
利用arp -a命令查看綁定的IP與MAC地址,可以看到對(duì)應(yīng)的表項(xiàng)已成功添加。
下載并打開(kāi)網(wǎng)口調(diào)試助手,設(shè)置發(fā)送端口與目的端口。發(fā)現(xiàn)可以成功打開(kāi)端口。

點(diǎn)擊數(shù)據(jù)發(fā)送,在wireshark上可以抓到對(duì)應(yīng)的長(zhǎng)度為22422bytes的udp數(shù)據(jù)包,其源IP地址為192.168.0.3,目的IP地址為192.168.0.120,信息與之前所設(shè)置的可以完全匹配。(下圖No.5)
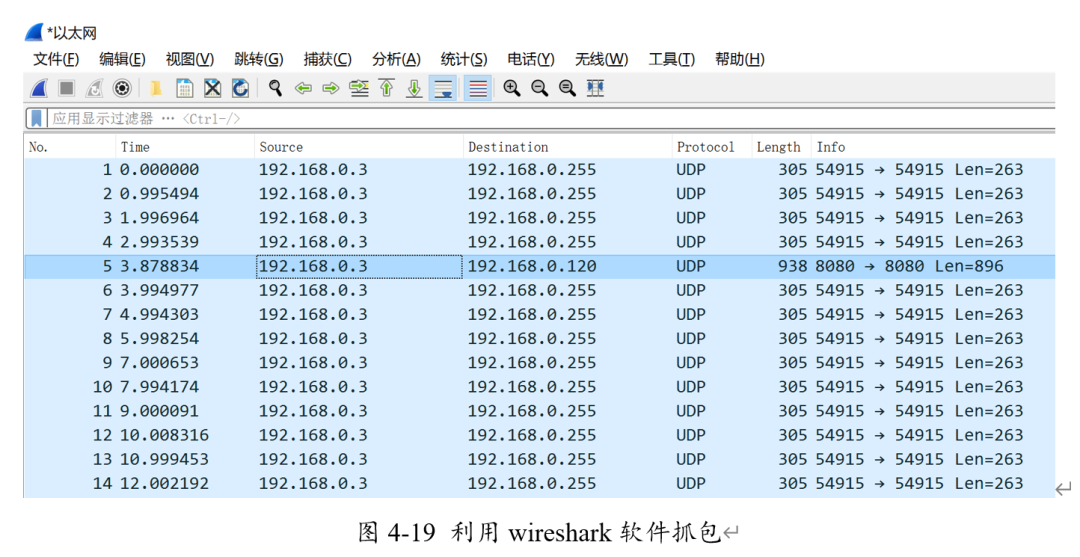
此時(shí)向FPGA燒入帶有ILA的最小系統(tǒng)比特流,觀察數(shù)據(jù)。發(fā)現(xiàn)可以收到電腦發(fā)出的UDP包,且數(shù)據(jù)與長(zhǎng)度匹配。
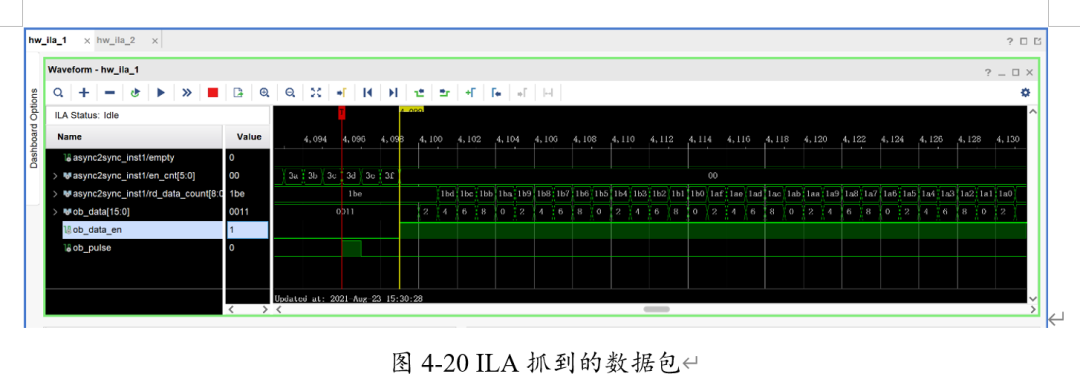
至此,已經(jīng)可以驗(yàn)證FPGA上的網(wǎng)口是正確無(wú)誤的;接著需要編寫(xiě)上位機(jī)程序。我們利用Visual Studio的C#作為開(kāi)發(fā)環(huán)境,編寫(xiě)了帶有網(wǎng)口傳輸、串口打印、與服務(wù)器進(jìn)行HTTP協(xié)議通信的上位機(jī)。其界面如下:
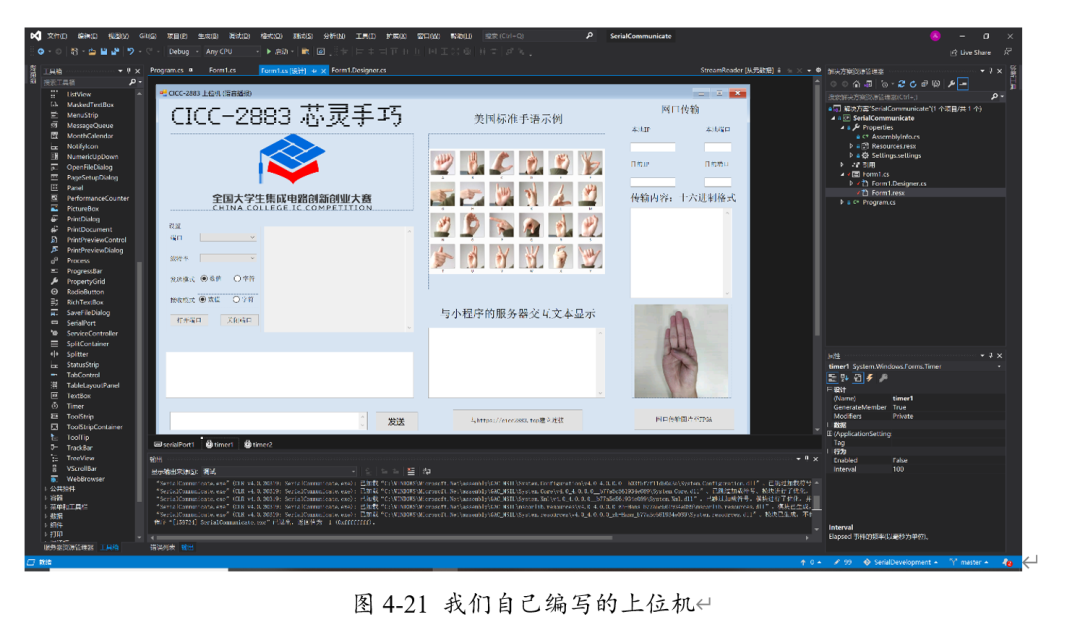
設(shè)置對(duì)應(yīng)的源IP、端口號(hào)與目的IP、端口號(hào),并生成需要發(fā)送的byte流。點(diǎn)擊發(fā)送。
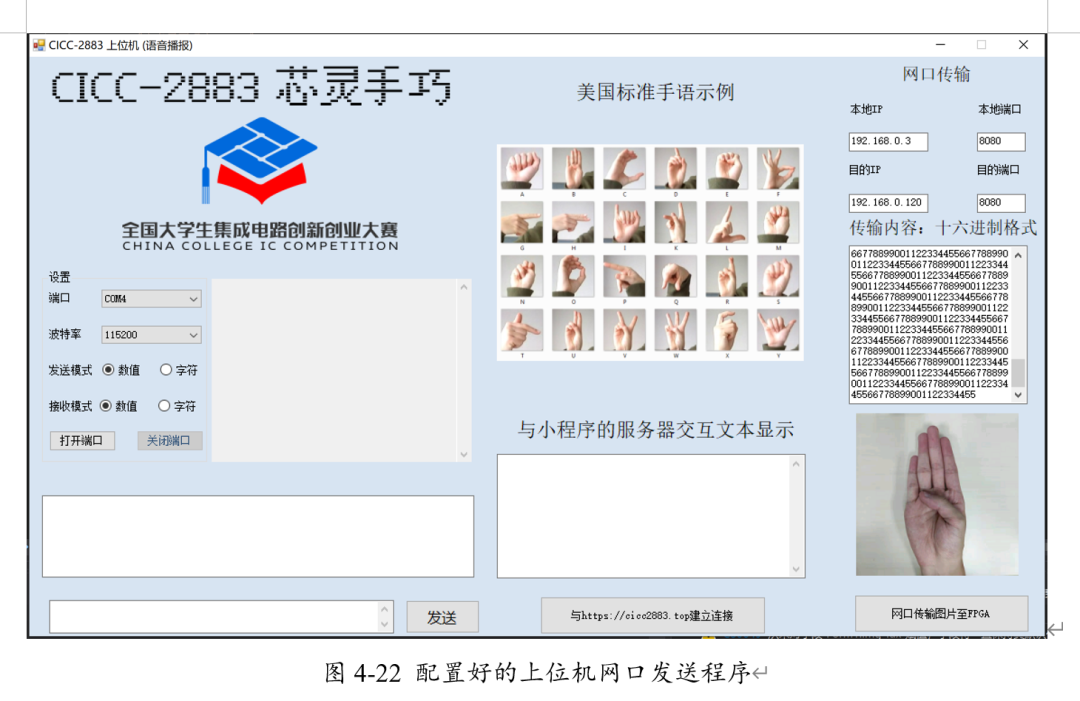
此時(shí),在ILA中再次抓取數(shù)據(jù)。
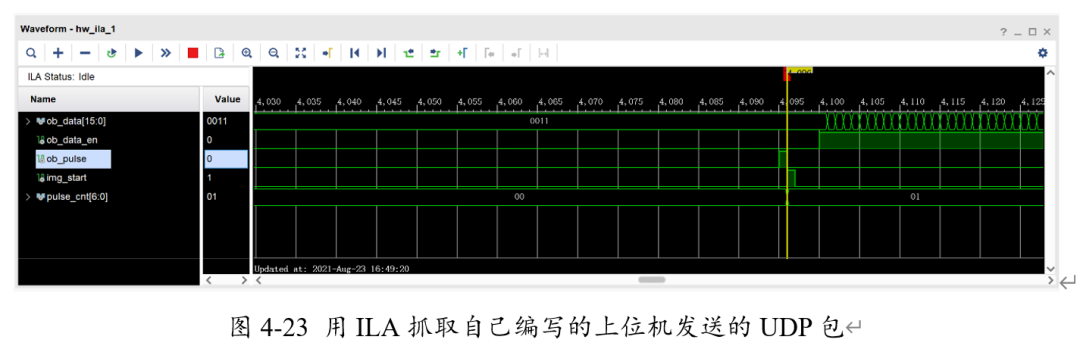
可以看到,數(shù)據(jù)能夠被正確讀取。考慮到一個(gè)UDP包能傳輸?shù)淖止?jié)數(shù)有限,我們最終設(shè)置每次傳輸224X2個(gè)RGB565數(shù)據(jù),即每次傳輸896個(gè)bytes,共計(jì)傳輸112次來(lái)完成一張圖片傳輸?shù)膮f(xié)議。其中,Img_start信號(hào)為FPGA中每張圖片開(kāi)始傳輸?shù)男盘?hào)。
至此,網(wǎng)口部分的驗(yàn)證已經(jīng)全部完成。
4.5 整體測(cè)試結(jié)果
5.項(xiàng)目總結(jié)
目前該項(xiàng)目在FPGA平臺(tái)上實(shí)現(xiàn)了基于Arm Cortex-M3 DesignStart處理器的面向無(wú)人值守的信號(hào)處理SoC,可以應(yīng)用于智慧病房檢測(cè)等各種無(wú)人系統(tǒng)的應(yīng)用,非常契合賽題的要求,且由于系統(tǒng)的通用性,有著廣大的潛在應(yīng)用場(chǎng)景。
該目標(biāo)檢測(cè)SoC基于Arm處理器,采用了兩級(jí)AHB總線結(jié)構(gòu),系統(tǒng)中掛載了圖像采集與顯示模塊,SD卡模塊,DDR模塊,加速器模塊等,系統(tǒng)使用攝像頭采集圖像送入加速器與HDMI模塊分別進(jìn)行目標(biāo)檢測(cè)與顯示,在我們的設(shè)計(jì)之下,在系統(tǒng)工作過(guò)程中軟硬件得以良好協(xié)同。我們的系統(tǒng)可以實(shí)現(xiàn)對(duì)視頻流實(shí)時(shí)、穩(wěn)定地檢測(cè)與顯示。
由于FPGA的資源十分有限,我們選用了伯克利&斯坦福團(tuán)隊(duì)提出的SqueezeNet網(wǎng)絡(luò),該網(wǎng)絡(luò)專(zhuān)為移動(dòng)或嵌入式場(chǎng)景開(kāi)發(fā),在保持一定精度的前提下降低了網(wǎng)絡(luò)大小。同時(shí),為了使該網(wǎng)絡(luò)可以做成硬件加速器,對(duì)該網(wǎng)絡(luò)又進(jìn)一步采用了融合BN層,參數(shù)歸一化和網(wǎng)絡(luò)結(jié)構(gòu)精簡(jiǎn)(刪除Fire模塊中的1X1卷積)等手段使得真正上板的網(wǎng)絡(luò)進(jìn)一步減小而精度的下降尚可接受。另外,由于不同網(wǎng)絡(luò)層之間大多結(jié)構(gòu)相同,我們?cè)贖LS的網(wǎng)絡(luò)中采取了折疊結(jié)構(gòu)實(shí)現(xiàn),使用軟硬件協(xié)同控制加速器工作時(shí)的數(shù)據(jù)流向,進(jìn)一步大大節(jié)省了有限的板上資源。我們利用數(shù)據(jù)增強(qiáng)的 DAC SDC 數(shù)據(jù)集對(duì)網(wǎng)絡(luò)進(jìn)行了訓(xùn)練,并對(duì)權(quán)重進(jìn)行量化。該數(shù)據(jù)集面向無(wú)人機(jī)場(chǎng)景,均為無(wú)人機(jī)拍攝的圖片,待識(shí)別物體被分為 12 類(lèi)。
在實(shí)際部署中,為進(jìn)一步節(jié)省片上資源,我們對(duì) SqueezeNet 網(wǎng)絡(luò)進(jìn)行了簡(jiǎn)化, 并采用折疊架構(gòu)。SqueezeNet 主要由若干個(gè) Fire 模塊構(gòu)成,我們僅設(shè)計(jì)一個(gè)簡(jiǎn)化的、參數(shù)可配置的 Fire 模塊,稱(chēng)之為 HalfFire 模塊。通過(guò)對(duì)加速器的配置來(lái)控制 HalfFire 模塊的例化和數(shù)據(jù)流的走向。數(shù)據(jù)通過(guò)若干次加速器(每次的配置參數(shù)均不同)處理后,即可得到檢測(cè)結(jié)果。折疊架構(gòu)節(jié)省了大量的片上資源,便于目標(biāo)檢測(cè)與分類(lèi) SoC 系統(tǒng)在邊緣端的部署。
通過(guò)實(shí)驗(yàn)測(cè)試,該加速器可實(shí)現(xiàn)軟件平均準(zhǔn)確率 96.27%的檢測(cè)精度; 完成一幀圖像的處理平均耗時(shí) 28.6 ms,系統(tǒng)吞吐率 34.97 FPS;系統(tǒng)的板級(jí)動(dòng)態(tài) 功耗為 1.697 W,完成一幀圖像的處理耗能 0.0468 J,能效比為 21.35 FPS/W。同時(shí),系統(tǒng)性能相比于 CPU 加速比顯著,相比于 GPU 能效比提升顯著。綜合來(lái)看,系統(tǒng)的性能指標(biāo)優(yōu)勢(shì)顯著,達(dá)到了2017年IEEE國(guó)際一流會(huì)議/期刊發(fā)表論文相當(dāng)水平。
該項(xiàng)目在 FPGA 平臺(tái)上實(shí)現(xiàn)了目標(biāo)檢測(cè) SoC 的部署,結(jié)合上位機(jī)的串口與語(yǔ)音播報(bào),可實(shí)現(xiàn)對(duì)病房實(shí)時(shí)、穩(wěn)定的檢測(cè),滿足患者的各項(xiàng)需求。該項(xiàng)目實(shí)際作為一套通用的加速器平臺(tái)系統(tǒng)可部署于邊緣端,除用于智慧病房檢測(cè)外,還可通過(guò)在SD卡存入訓(xùn)練好的各套權(quán)重,最終用于智能視頻監(jiān)控、聾啞人友好的無(wú)接觸智慧電梯等各個(gè)場(chǎng)景,具備較高的通用性,市場(chǎng)前景廣闊。
6.參賽體會(huì)
參加集創(chuàng)賽作為一段寶貴的實(shí)踐經(jīng)驗(yàn),我們收獲頗豐。我們團(tuán)隊(duì)大致可以總結(jié)出如下幾條參賽經(jīng)驗(yàn):
1. 扎扎實(shí)實(shí)一步步仿真、驗(yàn)證每部分電路,再嘗試整合。SoC設(shè)計(jì)是一個(gè)很?chē)?yán)謹(jǐn)細(xì)致的工程,有任何一個(gè)地方有再小的一個(gè)bug都會(huì)導(dǎo)致系統(tǒng)整體的錯(cuò)誤表現(xiàn)。就像我們?cè)趶?fù)賽前,因?yàn)榻o一些子系統(tǒng)加了新特性之后,比較急切想整合驗(yàn)證效果,便跳過(guò)了子系統(tǒng)的仿真驗(yàn)證,直接全都掛到總線上就開(kāi)始驗(yàn)證,結(jié)果出現(xiàn)了問(wèn)題。團(tuán)隊(duì)一起檢查了一段時(shí)間之后最終還是決定先給各個(gè)子系統(tǒng)分別仿真驗(yàn)證,確定子系統(tǒng)沒(méi)問(wèn)題之后再整合。最后果然在這個(gè)過(guò)程中發(fā)現(xiàn)是一個(gè)子系統(tǒng)存在bug。這次經(jīng)歷讓我們得到了深刻的教訓(xùn):心急吃不了熱豆腐,凡事還是要踏踏實(shí)實(shí)一步一步走。
2. 一切以上板結(jié)果正確為最終標(biāo)準(zhǔn)。在本次競(jìng)賽的制作過(guò)程中,同樣是復(fù)賽前,我們有幾個(gè)子系統(tǒng)通過(guò)了小系統(tǒng)仿真,之后我們都覺(jué)得這部分應(yīng)該已經(jīng)沒(méi)問(wèn)題了,當(dāng)時(shí)覺(jué)得既然是同樣的代碼仿真過(guò)了上板應(yīng)該也沒(méi)問(wèn)題。但是我們團(tuán)隊(duì)就遇到了一次盡管仿真正確但上板結(jié)果不對(duì)的情況,最終只能根據(jù)ILA抓信號(hào)的結(jié)果來(lái)debug,而且打亂了我們?cè)镜捻?xiàng)目計(jì)劃。在這之后我們更深刻地理解了指導(dǎo)老師經(jīng)常催促我們趕緊上板驗(yàn)證的原因。我們懂得了仿真永遠(yuǎn)只是理論驗(yàn)證,功能驗(yàn)證,而硬件即使做得再完美也有不理想的現(xiàn)象,就完全可能導(dǎo)致與仿真結(jié)果對(duì)不上的問(wèn)題。
3. 多學(xué)多看多思考,多看看廠商給出的技術(shù)文檔,以及留出充足的時(shí)間來(lái)對(duì)硬件進(jìn)行debug。以網(wǎng)口的學(xué)習(xí)作為經(jīng)驗(yàn),首先是要學(xué)習(xí)最基礎(chǔ)的RGMII協(xié)議以及UDP協(xié)議,然后根據(jù)開(kāi)發(fā)板的說(shuō)明文檔查到網(wǎng)口的PHY芯片型號(hào)RTL8211EL,然后再根據(jù)相應(yīng)的文檔學(xué)習(xí)芯片的引腳配置。中間也遇到了許多問(wèn)題,例如開(kāi)始沒(méi)有發(fā)現(xiàn)PHY芯片的reset需要至少1ms的時(shí)間,或是有一個(gè)引腳約束xdc文件分配錯(cuò)了卻遲遲沒(méi)有發(fā)現(xiàn),這些都是需要預(yù)留充足的時(shí)間來(lái)debug的。其他模塊的編寫(xiě)我想也大致如此,都需要首先對(duì)協(xié)議本身進(jìn)行學(xué)習(xí),然后根據(jù)開(kāi)發(fā)板的不同型號(hào)對(duì)相應(yīng)引腳進(jìn)行配置,最后通過(guò)仿真測(cè)試以及上板抓ILA進(jìn)行測(cè)試驗(yàn)證,通過(guò)后就可以整合進(jìn)整個(gè)系統(tǒng)了。
7.參賽隊(duì)員介紹
林圣凱
本人2018年進(jìn)入上海交通大學(xué)開(kāi)始大學(xué)本科學(xué)業(yè),所學(xué)專(zhuān)業(yè)為微電子科學(xué)與工程。本人成績(jī)優(yōu)異,曾獲何宜慈博士紀(jì)念獎(jiǎng)學(xué)金以及多次校級(jí)B類(lèi)獎(jiǎng)學(xué)金;并且在本科期間積極參加科研工作,從事過(guò)網(wǎng)絡(luò)系統(tǒng)、量子身份認(rèn)證以及集成電路SoC設(shè)計(jì)等方向的科研工作。
在本次集創(chuàng)賽中,我自己對(duì)于SoC的基礎(chǔ)知識(shí)與認(rèn)識(shí)有了大幅度提升,真正做到了學(xué)以致用。我覺(jué)得這個(gè)過(guò)程就是一個(gè)解決問(wèn)題與挑戰(zhàn)自己的過(guò)程。我相信我會(huì)以此為起點(diǎn),在未來(lái)的科研工作中繼續(xù)對(duì)自己提出更高的挑戰(zhàn),并將其一一擊破。
林新源
我是芯靈手巧組的林新源,是一枚對(duì)集成電路設(shè)計(jì)尤其是系統(tǒng)級(jí)設(shè)計(jì)感興趣的大三學(xué)生。這是最壞的時(shí)代,也是最好的時(shí)代,我希望自己能夠在國(guó)家需要的,且自己喜歡的集成電路設(shè)計(jì)領(lǐng)域做一些有意義的事情。于我而言,集創(chuàng)賽是個(gè)起點(diǎn),在這過(guò)程中學(xué)到的知識(shí)還有完成過(guò)程中的態(tài)度心境將讓我未來(lái)受益匪淺。將來(lái),我將去清華大學(xué)電子系攻讀博士,繼續(xù)攀登新的高峰。
莫志文
我是CICC2883芯靈手巧組的莫志文,是一名上海交大微電子學(xué)院的大三學(xué)生,曾獲國(guó)家級(jí)獎(jiǎng)學(xué)金、校A級(jí)獎(jiǎng)學(xué)金、三好學(xué)生等榮譽(yù),成績(jī)位列專(zhuān)業(yè)第一。我平日里課業(yè)之外喜歡音樂(lè)、足球與騎行。我對(duì)數(shù)字芯片設(shè)計(jì)頗有興趣,并即將保研至本系直博繼續(xù)攻讀數(shù)字芯片設(shè)計(jì)。我期待著未來(lái)在本領(lǐng)域深耕并作出一些屬于自己的貢獻(xiàn)。以此次集創(chuàng)賽作為契機(jī),我學(xué)到了許多知識(shí),也在管中窺豹——可見(jiàn)一斑中感受到了數(shù)字IC設(shè)計(jì)智慧的博大精深。
恰逢如此的歷史時(shí)機(jī),我堅(jiān)信我們這一代人可以扛起這份責(zé)任。長(zhǎng)風(fēng)破浪會(huì)有時(shí),直掛云帆濟(jì)滄海!
原文標(biāo)題:【2021集創(chuàng)賽作品分享】第四期 | 基于Arm核的智慧病房手勢(shì)識(shí)別方案
文章出處:【微信公眾號(hào):安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
審核編輯:湯梓紅
-
ARM
+關(guān)注
關(guān)注
134文章
9084瀏覽量
367382 -
soc
+關(guān)注
關(guān)注
38文章
4161瀏覽量
218162 -
手勢(shì)識(shí)別
+關(guān)注
關(guān)注
8文章
225瀏覽量
47786
原文標(biāo)題:【2021集創(chuàng)賽作品分享】第四期 | 基于Arm核的智慧病房手勢(shì)識(shí)別方案
文章出處:【微信號(hào):Ithingedu,微信公眾號(hào):安芯教育科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
手勢(shì)識(shí)別技術(shù)原理及解決方案
基于Microchip的手勢(shì)識(shí)別耳機(jī)解決方案

紅外手勢(shì)識(shí)別方案 紅外手勢(shì)感應(yīng)模塊 紅外識(shí)別紅外手勢(shì)識(shí)別
紅外手勢(shì)識(shí)別方案 紅外手勢(shì)感應(yīng)模塊 紅外識(shí)別
智慧物業(yè)解決方案
ELMOS用于手勢(shì)識(shí)別的光電傳感器E527.16
手勢(shì)識(shí)別PCBA-手勢(shì)控制零接觸抗菌水龍頭開(kāi)發(fā)方案
智慧水利整體解決方案
史上最牛高速手勢(shì)識(shí)別系統(tǒng)解決方案
醫(yī)院智慧病房的整體解決方案解析
基于ToF傳感器的3D手勢(shì)識(shí)別解決方案
手勢(shì)識(shí)別技術(shù)及其應(yīng)用
智能手勢(shì)化妝鏡手勢(shì)識(shí)別模組芯片底部填充膠應(yīng)用案例






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論