") 使用DeepSpeed和Megatron驅(qū)動(dòng)MT-NLG語言模型
使用DeepSpeed和Megatron驅(qū)動(dòng)MT-NLG語言模型
我們很高興地介紹由 DeepSpeed 和 Megatron 驅(qū)動(dòng)的 Megatron 圖靈自然語言生成模型( MT-NLG ),這是迄今為止訓(xùn)練過的最大和最強(qiáng)大的單片 transformer 語言模型,具有 5300 億個(gè)參數(shù)。這是微軟和 NVIDIA 共同努力的結(jié)果,旨在推動(dòng)人工智能自然語言生成的最新發(fā)展。
作為圖靈 NLG 17B和Megatron-LM的繼承者, MT-NLG 的參數(shù)數(shù)量是該類型現(xiàn)有最大模型的 3 倍,并且在廣泛的自然語言任務(wù)中表現(xiàn)出無與倫比的準(zhǔn)確性,例如:
完井預(yù)測(cè)
閱讀理解
常識(shí)推理
自然語言推理
詞義消歧
基于 105 層 transformer 的 MT-NLG 在零拍、一拍和少拍設(shè)置方面改進(jìn)了現(xiàn)有的最先進(jìn)模型,并為大規(guī)模語言模型在模型規(guī)模和質(zhì)量方面設(shè)置了新標(biāo)準(zhǔn)。
大規(guī)模語言模型
近年來,自然語言處理( NLP )中基于 transformer 的語言模型在大規(guī)模計(jì)算、大型數(shù)據(jù)集以及用于訓(xùn)練這些模型的高級(jí)算法和軟件的推動(dòng)下,取得了快速的進(jìn)步。
具有大量參數(shù)、更多數(shù)據(jù)和更多訓(xùn)練時(shí)間的語言模型可以獲得更豐富、更細(xì)致的語言理解。因此,他們能夠很好地概括有效的零分或少分學(xué)習(xí)者,在許多 NLP 任務(wù)和數(shù)據(jù)集上具有較高的準(zhǔn)確性。令人興奮的下游應(yīng)用包括摘要、自動(dòng)對(duì)話生成、翻譯、語義搜索和代碼自動(dòng)完成。最先進(jìn)的 NLP 模型中的參數(shù)數(shù)量以指數(shù)速度增長(zhǎng)并不奇怪(圖 1 )。
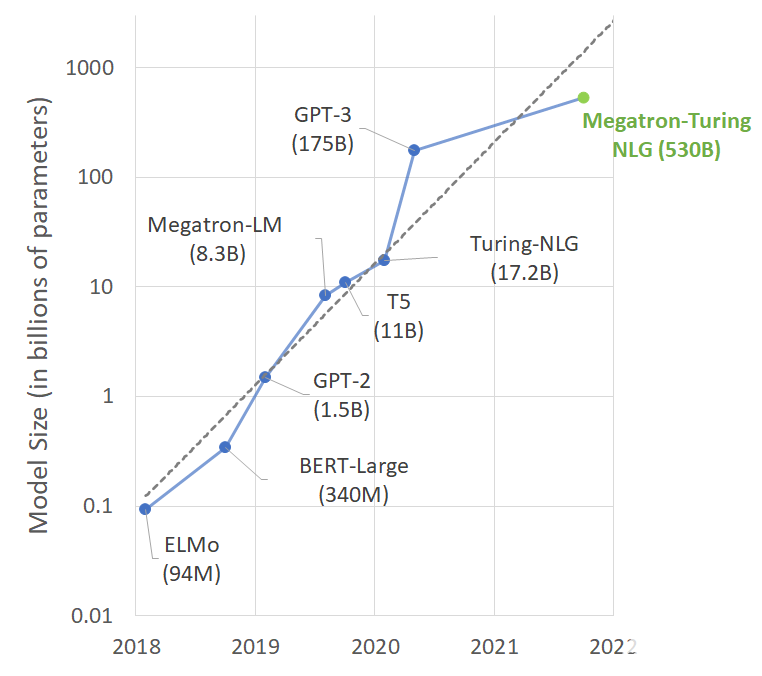
圖 1 。最新 NLP 模型的尺寸隨時(shí)間的趨勢(shì)
然而,培訓(xùn)此類模型具有挑戰(zhàn)性,主要原因有兩個(gè):
即使是最大的 GPU 內(nèi)存中也無法擬合這些模型的參數(shù)。
如果不特別注意優(yōu)化算法、軟件和硬件堆棧,那么所需的大量計(jì)算操作可能會(huì)導(dǎo)致訓(xùn)練時(shí)間過長(zhǎng)。
通過沿所有 AI 軸的眾多創(chuàng)新和突破,訓(xùn)練 MT-NLG 變得可行。例如, NVIDIA 與微軟緊密合作,通過將最先進(jìn)的 GPU 加速培訓(xùn)基礎(chǔ)設(shè)施與尖端的分布式學(xué)習(xí)軟件堆棧融合,實(shí)現(xiàn)了前所未有的培訓(xùn)效率。我們用數(shù)千億的代幣構(gòu)建了高質(zhì)量的自然語言培訓(xùn)語料庫,并共同開發(fā)了培訓(xùn)配方,以提高優(yōu)化效率和穩(wěn)定性。
在這篇文章中,我們?cè)敿?xì)闡述了培訓(xùn)的各個(gè)方面,并描述了我們的方法和結(jié)果。
大規(guī)模培訓(xùn)基礎(chǔ)設(shè)施
由 NVIDIA A100 Tensor Core GPU s 和 HDR InfiniBand 網(wǎng)絡(luò)提供支持,最先進(jìn)的超級(jí)計(jì)算集群,如 NVIDIA Selene和 Microsoft Azure NDv4具有足夠的計(jì)算能力,可以在合理的時(shí)間范圍內(nèi)訓(xùn)練具有數(shù)萬億參數(shù)的模型。然而,要充分發(fā)揮這些超級(jí)計(jì)算機(jī)的潛力,就需要跨越數(shù)千 GPU 的并行性,在內(nèi)存和計(jì)算上都要高效且可擴(kuò)展。
孤立地說,現(xiàn)有的并行策略(如數(shù)據(jù)、管道或張量切片)在內(nèi)存和計(jì)算效率方面存在權(quán)衡,不能用于以這種規(guī)模訓(xùn)練模型。
數(shù)據(jù)并行實(shí)現(xiàn)了良好的計(jì)算效率,但它復(fù)制了模型狀態(tài),無法利用聚合分布式內(nèi)存。
張量切片需要 GPU 之間的大量通信,這將計(jì)算效率限制在無法使用高帶寬 NVLink 的單個(gè)節(jié)點(diǎn)之外。
管道并行可以跨節(jié)點(diǎn)高效擴(kuò)展。然而,為了提高計(jì)算效率,它需要大批量、粗粒度并行和完美的負(fù)載平衡,而這在規(guī)模上是不可能的。
軟件設(shè)計(jì)
通過 NVIDIA Megatron-LM和 Microsoft DeepSpeed之間的合作,我們創(chuàng)建了一個(gè)高效、可擴(kuò)展的 3D 并行系統(tǒng),能夠?qū)⒒跀?shù)據(jù)、管道和張量切片的并行性結(jié)合在一起,以應(yīng)對(duì)這些挑戰(zhàn)。
通過結(jié)合張量切片和管道并行,我們可以在最有效的區(qū)域內(nèi)操作它們。更具體地說,該系統(tǒng)使用 Megatron LM 的張量切片在節(jié)點(diǎn)內(nèi)縮放模型,并使用 DeepSpeed 的管道并行性跨節(jié)點(diǎn)縮放模型。
例如,對(duì)于 5300 億個(gè)模型,每個(gè)模型副本跨越 280 NVIDIA A100 GPU s ,在節(jié)點(diǎn)內(nèi)進(jìn)行 8 路張量切片,在節(jié)點(diǎn)間進(jìn)行 35 路管道并行。然后,我們使用 DeepSpeed 的數(shù)據(jù)并行性進(jìn)一步擴(kuò)展到數(shù)千 GPU 秒。
硬件系統(tǒng)
模型訓(xùn)練是在基于 NVIDIA DGX SuperPOD 的Selene超級(jí)計(jì)算機(jī)上以混合精度進(jìn)行的,該超級(jí)計(jì)算機(jī)由 560 臺(tái) DGX A100 服務(wù)器供電,這些服務(wù)器與 HDR InfiniBand 以全脂樹配置聯(lián)網(wǎng)。每個(gè) DGX A100 有八個(gè) NVIDIA A100 80GB 張量核 GPU s ,通過NVLink 和 NVSwitch相互完全連接。 Microsoft 在 Azure NDv4 云超級(jí)計(jì)算機(jī)上使用了類似的參考體系結(jié)構(gòu)。
系統(tǒng)吞吐量
我們?cè)?Selene 上的 280 、 350 和 420 臺(tái) DGX A100 服務(wù)器上考慮了 5300 億參數(shù)模型(批量大小為 1920 )的系統(tǒng)端到端吞吐量。我們觀察到迭代時(shí)間分別為 60 。 1 、 50 。 2 和 44 。 4 秒。它們分別對(duì)應(yīng)于每 GPU 126 、 121 和 113 萬億次/秒。
訓(xùn)練數(shù)據(jù)集和模型配置
我們使用了 transformer 解碼器的體系結(jié)構(gòu),這是一個(gè)從左到右生成的 transformer 語言模型,包含 5300 億個(gè)參數(shù)。層、隱藏維度和注意頭的數(shù)量分別為 105 、 20480 和 128 。
我們使用了 8 路張量和 35 路流水線并行。序列長(zhǎng)度為 2048 ,全局批量大小為 1920 。在最初的 120 億個(gè)培訓(xùn)代幣中,我們逐漸將批量大小增加了 32 ,從 32 開始,直到最終的批量大小達(dá)到 1920 。在我們的培訓(xùn)中,我們使用了 10 億代幣來提高學(xué)習(xí)率 w ARM 。
我們?cè)谙惹肮ぷ髂嵌训幕A(chǔ)上構(gòu)建了我們的訓(xùn)練數(shù)據(jù)集。首先,我們從一堆數(shù)據(jù)中選擇了相對(duì)質(zhì)量最高的數(shù)據(jù)集子集(圖 2 中的前 11 行)。然后,按照與生成Pile-CC類似的方法,我們下載并過濾了兩個(gè)最近的通用爬網(wǎng)( CC )快照。
我們對(duì) CC 數(shù)據(jù)采取的步驟包括從原始 HTML 文件中提取文本,使用經(jīng)過高質(zhì)量數(shù)據(jù)訓(xùn)練的分類器對(duì)提取的文檔進(jìn)行評(píng)分,以及根據(jù)其評(píng)分對(duì)文檔進(jìn)行過濾。為了使培訓(xùn)多樣化,我們還收集了RealNews和CC-Stories數(shù)據(jù)集。
在構(gòu)建培訓(xùn)數(shù)據(jù)集時(shí),文檔重復(fù)數(shù)據(jù)消除是必要的,因?yàn)橄嗤膬?nèi)容可以出現(xiàn)在不同數(shù)據(jù)集的多個(gè)文檔中。我們?cè)谖臋n級(jí)別使用模糊重復(fù)數(shù)據(jù)消除過程,使用最小哈希 LSH 計(jì)算稀疏文檔圖,并在其中連接組件以識(shí)別重復(fù)文檔。
然后,在從每個(gè)連接組件中的重復(fù)文檔中選擇代表性文檔時(shí),我們使用基于數(shù)據(jù)集質(zhì)量的優(yōu)先級(jí)順序。最后,我們使用基于n -gram 的過濾從訓(xùn)練數(shù)據(jù)集中刪除下游任務(wù)數(shù)據(jù),以避免污染。
最后,我們得到了一組 15 個(gè)數(shù)據(jù)集,共包含 3390 億個(gè)令牌。在培訓(xùn)期間,我們選擇根據(jù)圖 2 中給出的可變采樣權(quán)重將數(shù)據(jù)集混合到異構(gòu)批次中,重點(diǎn)是更高質(zhì)量的數(shù)據(jù)集。我們?cè)?2700 億代幣上訓(xùn)練模型。
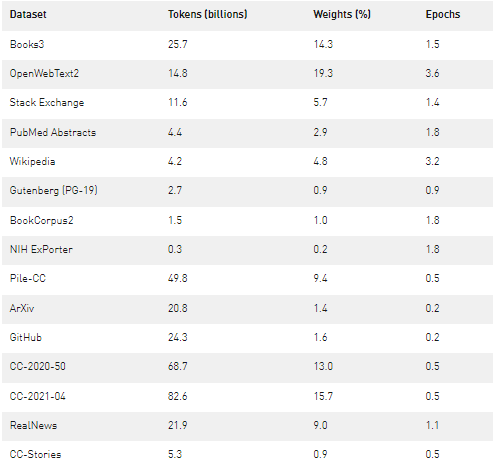
表 1 。用于訓(xùn)練 MT-NLG 模型的數(shù)據(jù)集。前 11 行來自 Pile 數(shù)據(jù)集,后面是兩個(gè)通用爬網(wǎng)( CC )快照、 RealNews 和 CC Stories 數(shù)據(jù)集
成果和成就
最近在語言模型( LM )方面的研究表明,一個(gè)強(qiáng)的預(yù)訓(xùn)練模型通常可以在廣泛的 NLP 任務(wù)中進(jìn)行競(jìng)爭(zhēng),而無需微調(diào)。
為了了解擴(kuò)大 LMs 如何增強(qiáng)其零炮或少炮學(xué)習(xí)能力,我們?cè)u(píng)估了 MT-NLG ,并證明它在多個(gè) NLP 任務(wù)類別中建立了新的頂級(jí)結(jié)果。為了確保評(píng)估的全面性,我們選擇了八項(xiàng)任務(wù),涵蓋五個(gè)不同領(lǐng)域:
在文本預(yù)測(cè)任務(wù) LAMBADA 中,模型預(yù)測(cè)給定段落的最后一個(gè)單詞。
在閱讀理解任務(wù) RACE-h 和 BoolQ 中,該模型根據(jù)給定的段落生成問題的答案。
在常識(shí)推理任務(wù) PiQA 、 HellaSwag 和 Winogrande 中,每個(gè)任務(wù)都需要一定程度的常識(shí)知識(shí),而不僅僅是語言的統(tǒng)計(jì)模式。
對(duì)于自然語言推理,兩個(gè)硬基準(zhǔn) ANLI-R2 和 HANS 針對(duì)過去模型的典型故障案例。
詞義消歧任務(wù) WiC 從上下文評(píng)估對(duì)一詞多義的理解。
為了鼓勵(lì)再現(xiàn)性,我們以開源項(xiàng)目lm-evaluation-harness為基礎(chǔ)進(jìn)行評(píng)估設(shè)置,并根據(jù)需要進(jìn)行特定于任務(wù)的更改,以使我們的設(shè)置與之前的工作更緊密地結(jié)合起來。我們?cè)诹愦巍⒁淮魏蜕倭糠排谠O(shè)置下評(píng)估 MT-NLG ,而不搜索最佳放炮數(shù)。
表 2 顯示了精度度量的結(jié)果。如果測(cè)試集是公開的,我們就對(duì)它進(jìn)行評(píng)估;否則,我們會(huì)在開發(fā)集上報(bào)告數(shù)字。這導(dǎo)致在測(cè)試集上報(bào)告 LAMBADA 、 RACE-h 和 ANLI-R2 ,并在開發(fā)集上報(bào)告其他任務(wù)。
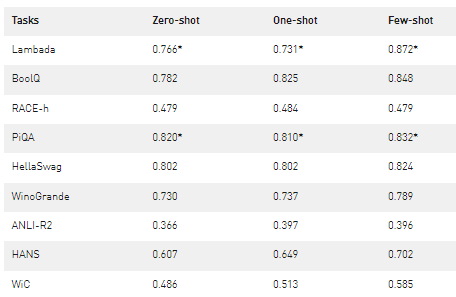
表 2 。使用 MT-NLG 進(jìn)行零次、一次和少量放炮評(píng)估的準(zhǔn)確度結(jié)果。 MT-NLG 在所有三種設(shè)置(用*表示)中建立了 PiQA-dev 集和 LAMBADA 測(cè)試集的最新結(jié)果,并在其他類別的類似單片模型中優(yōu)于結(jié)果。
以少鏡頭表演為例。與之前發(fā)表的工作相比,我們發(fā)現(xiàn)了令人鼓舞的改進(jìn)。這對(duì)于涉及比較或發(fā)現(xiàn)兩個(gè)句子之間關(guān)系的任務(wù)(例如, WiC 和 ANLI )尤其如此,對(duì)于以前的模型來說,這是一個(gè)具有挑戰(zhàn)性的任務(wù)類別。我們觀察到大多數(shù)任務(wù)在零次和一次評(píng)估中也有類似的改進(jìn)。我們還應(yīng)該注意到,與以前的模型相比,此模型在更少的令牌上進(jìn)行訓(xùn)練,這表明較大模型的學(xué)習(xí)速度更快。
對(duì)于 HANS 數(shù)據(jù)集,我們沒有發(fā)現(xiàn)任何報(bào)告數(shù)據(jù)集范圍度量的基線。根據(jù)漢斯紙的分析,MNLI上訓(xùn)練的 BERT 基線在其一半子類別上表現(xiàn)接近完美,而在另一半子類別上表現(xiàn)接近零。這表明它們強(qiáng)烈地依賴于本文所確定的虛假句法啟發(fā)法。
雖然我們的模型仍在掙扎,但它預(yù)測(cè),在零次射擊中,一半以上的情況是正確的,而當(dāng)我們僅給出一次和四次射擊時(shí),情況會(huì)進(jìn)一步改善。最后,在零拍、一拍和少拍設(shè)置下,我們的模型在 PiQA 開發(fā)集和 LAMBADA 測(cè)試集上建立了最佳結(jié)果。
除了報(bào)告基準(zhǔn)任務(wù)的聚合指標(biāo)外,我們還定性分析了模型輸出,并得出了有趣的發(fā)現(xiàn)(圖 4 )。我們觀察到,該模型可以從上下文(示例 1 )推斷出基本的數(shù)學(xué)運(yùn)算,即使在符號(hào)嚴(yán)重混淆的情況下(示例 2 )。雖然該模型并沒有宣稱自己是算術(shù),但它似乎超出了算術(shù)記憶的范疇。
我們還展示了來自 HANS 任務(wù)的示例(圖 4 中的最后一行),其中我們將包含簡(jiǎn)單語法結(jié)構(gòu)的任務(wù)作為問題提出,并提示模型給出答案。盡管結(jié)構(gòu)簡(jiǎn)單,但現(xiàn)有的自然語言推理( NLI )模型通常很難處理此類輸入。微調(diào)模型經(jīng)常從 NLI 數(shù)據(jù)集中的系統(tǒng)偏差中發(fā)現(xiàn)某些句法結(jié)構(gòu)和蘊(yùn)涵關(guān)系之間的虛假關(guān)聯(lián)。在這種情況下, MT-NLG 在沒有微調(diào)的情況下具有競(jìng)爭(zhēng)力。

表 3 。不同句法結(jié)構(gòu)下數(shù)學(xué)運(yùn)算和自然語言推理的 MT-NLG 示例
語言模型中的偏見
盡管巨型語言模型正在推動(dòng)語言生成技術(shù)的發(fā)展,但它們也面臨著偏見和毒性等問題。人工智能社區(qū)正在積極研究如何理解和消除語言模型中的這些問題,包括微軟和 NVIDIA 。
我們對(duì) MT-NLG 的觀察是,該模型從訓(xùn)練數(shù)據(jù)中提取刻板印象和偏見。微軟和 NVIDIA 致力于解決這個(gè)問題。我們鼓勵(lì)繼續(xù)研究,以幫助量化模型的偏差。
此外,在生產(chǎn)場(chǎng)景中使用 MT-NLG 必須確保采取適當(dāng)措施,以減輕和減少對(duì)用戶的潛在 h ARM 。所有工作都應(yīng)遵循微軟負(fù)責(zé)任的人工智能原則中的原則。這些原則強(qiáng)調(diào)公平、可靠性和安全性、隱私和安全性、包容性、透明度和問責(zé)制被視為開發(fā)和使用人工智能的負(fù)責(zé)任和值得信賴的方法的關(guān)鍵基石。
結(jié)論
我們生活在一個(gè)人工智能進(jìn)步遠(yuǎn)遠(yuǎn)超過摩爾定律的時(shí)代。我們繼續(xù)看到新一代的 GPU 以閃電般的速度互聯(lián),提供了更多的計(jì)算能力。與此同時(shí),我們繼續(xù)看到人工智能模型的超尺度化帶來了更好的性能,似乎看不到盡頭。
將這兩種趨勢(shì)結(jié)合在一起的是軟件創(chuàng)新,它推動(dòng)了優(yōu)化和效率的界限。 MT-NLG 是超級(jí)計(jì)算機(jī) NVIDIA Selene 或 Microsoft Azure NDv4 與 Megatron LM 和 DeepSpeed 的軟件突破一起用于訓(xùn)練大型語言 AI 模型的一個(gè)例子。
我們今天所獲得的質(zhì)量和結(jié)果是在開啟人工智能在自然語言中的全部承諾的過程中向前邁出的一大步。 DeepSpeed 和 Megatron LM 的創(chuàng)新將有利于現(xiàn)有和未來的人工智能模型開發(fā),并使大型人工智能模型更便宜、訓(xùn)練速度更快。
我們期待著 MT-NLG 將如何塑造未來的產(chǎn)品,并激勵(lì)社區(qū)進(jìn)一步推動(dòng) NLP 的邊界。旅程漫長(zhǎng),遠(yuǎn)未完成,但我們對(duì)可能發(fā)生的事情和未來的事情感到興奮。
關(guān)于作者
Paresh Kharya 是 NVIDIA 加速計(jì)算的產(chǎn)品管理和營銷高級(jí)總監(jiān)。他專注于 NVIDIA 數(shù)據(jù)中心產(chǎn)品,包括用于 AI 和 HPC 的服務(wù)器 GPU 、 CPU 和 NVIDIA 計(jì)算軟件平臺(tái)。此前,帕雷什在高科技行業(yè)擔(dān)任過多種業(yè)務(wù)角色,包括 Adobe 的產(chǎn)品管理和 tech Mahindra 的業(yè)務(wù)開發(fā)。帕雷什擁有印度管理學(xué)院的工商管理碩士學(xué)位和印度國家理工學(xué)院的計(jì)算機(jī)科學(xué)學(xué)士學(xué)位。
Ali Alvi 是微軟圖靈團(tuán)隊(duì)的團(tuán)隊(duì)項(xiàng)目經(jīng)理,該團(tuán)隊(duì)是一個(gè)跨公司的深度學(xué)習(xí)/人工智能項(xiàng)目。他們正在開發(fā)和生產(chǎn)跨 Microsoft 產(chǎn)品套件( Outlook 、 Word 、 PowerPoint 、 SharePoint 、 Bing 、 Dynamics 、 Maps 等)的雄心勃勃的深度學(xué)習(xí)功能。他的重點(diǎn)包括非結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)的 QA 、搜索相關(guān)模型、機(jī)器閱讀理解、自然語言表示、自然語言生成、通過向量空間嵌入的文檔和查詢表示、對(duì)話和對(duì)話 AI 以及多模態(tài) AI 模型。此前,他是微軟推出第一款可穿戴設(shè)備微軟樂隊(duì)的團(tuán)隊(duì)成員。他領(lǐng)導(dǎo) Microsoft Band 和 Health 的應(yīng)用程序、體驗(yàn)和開發(fā)平臺(tái)。 Ali 從拉合爾管理科學(xué)大學(xué)( LUMS )獲得計(jì)算機(jī)科學(xué)學(xué)士學(xué)位,輔修數(shù)學(xué)和經(jīng)濟(jì)學(xué)。阿里自 2001 年以來一直在微軟工作。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
4990瀏覽量
103106 -
gpu
+關(guān)注
關(guān)注
28文章
4742瀏覽量
128969 -
人工智能
+關(guān)注
關(guān)注
1791文章
47314瀏覽量
238625
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
大語言模型開發(fā)框架是什么
大語言模型開發(fā)語言是什么
大語言模型如何開發(fā)
如何利用大型語言模型驅(qū)動(dòng)的搜索為公司創(chuàng)造價(jià)值

大模型LLM與ChatGPT的技術(shù)原理
大語言模型(LLM)快速理解

大語言模型:原理與工程時(shí)間+小白初識(shí)大語言模型
【大語言模型:原理與工程實(shí)踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實(shí)踐】大語言模型的評(píng)測(cè)
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》2.0
【大語言模型:原理與工程實(shí)踐】大語言模型的基礎(chǔ)技術(shù)
【大語言模型:原理與工程實(shí)踐】揭開大語言模型的面紗
【大語言模型:原理與工程實(shí)踐】探索《大語言模型原理與工程實(shí)踐》
基于NVIDIA Megatron Core的MOE LLM實(shí)現(xiàn)和訓(xùn)練優(yōu)化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論