") NVIDIA Jetson TX2為邊緣提供雙倍的智能
NVIDIA Jetson TX2為邊緣提供雙倍的智能
在舊金山舉行的 AI 聚會(huì)上,NVIDIA 推出了 Jetson TX2 和 JetPack 3.0 AI SDK。Jetson 是世界領(lǐng)先的低功耗嵌入式平臺(tái),可為各地的邊緣設(shè)備提供服務(wù)器級的 AI 計(jì)算性能。Jetson TX2 具有集成的 256 核 NVIDIA Pascal GPU、六核 ARMv8 64 位 CPU 復(fù)合體和 8GB 具有 128 位接口的 LPDDR4 內(nèi)存。CPU 綜合體結(jié)合了雙核 NVIDIA Denver 2 和四核 Arm Cortex-A57。Jetson TX2 模塊(如圖 1 所示)適合 50 x 87 毫米、85 克和 7.5 瓦的典型能源使用量的小尺寸、重量和功率 (SWaP) 占位面積。
物聯(lián)網(wǎng) (IoT) 設(shè)備通常用作中繼數(shù)據(jù)的簡單網(wǎng)關(guān)。他們依靠云連接來執(zhí)行繁重的工作和數(shù)字運(yùn)算。邊緣計(jì)算是一種新興的范式,它使用本地計(jì)算在數(shù)據(jù)源上進(jìn)行分析。Jetson TX2 具有超過 TFLOP/s 的性能,非常適合將高級 AI 部署到互聯(lián)網(wǎng)連接較差或昂貴的遠(yuǎn)程現(xiàn)場位置。Jetson TX2 還提供近乎實(shí)時(shí)的響應(yīng)能力和最小的延遲——這對于需要關(guān)鍵任務(wù)自主權(quán)的智能機(jī)器而言至關(guān)重要。
Jetson TX2 基于 16nm NVIDIA Tegra“Parker”片上系統(tǒng) (SoC)(圖 2 顯示了框圖)。Jetson TX2 在深度學(xué)習(xí)推理方面的能效是其前身 Jetson TX1 的兩倍,并提供比英特爾至強(qiáng)服務(wù)器 CPU 更高的性能。這種效率的飛躍重新定義了將高級人工智能從云端擴(kuò)展到邊緣的可能性。
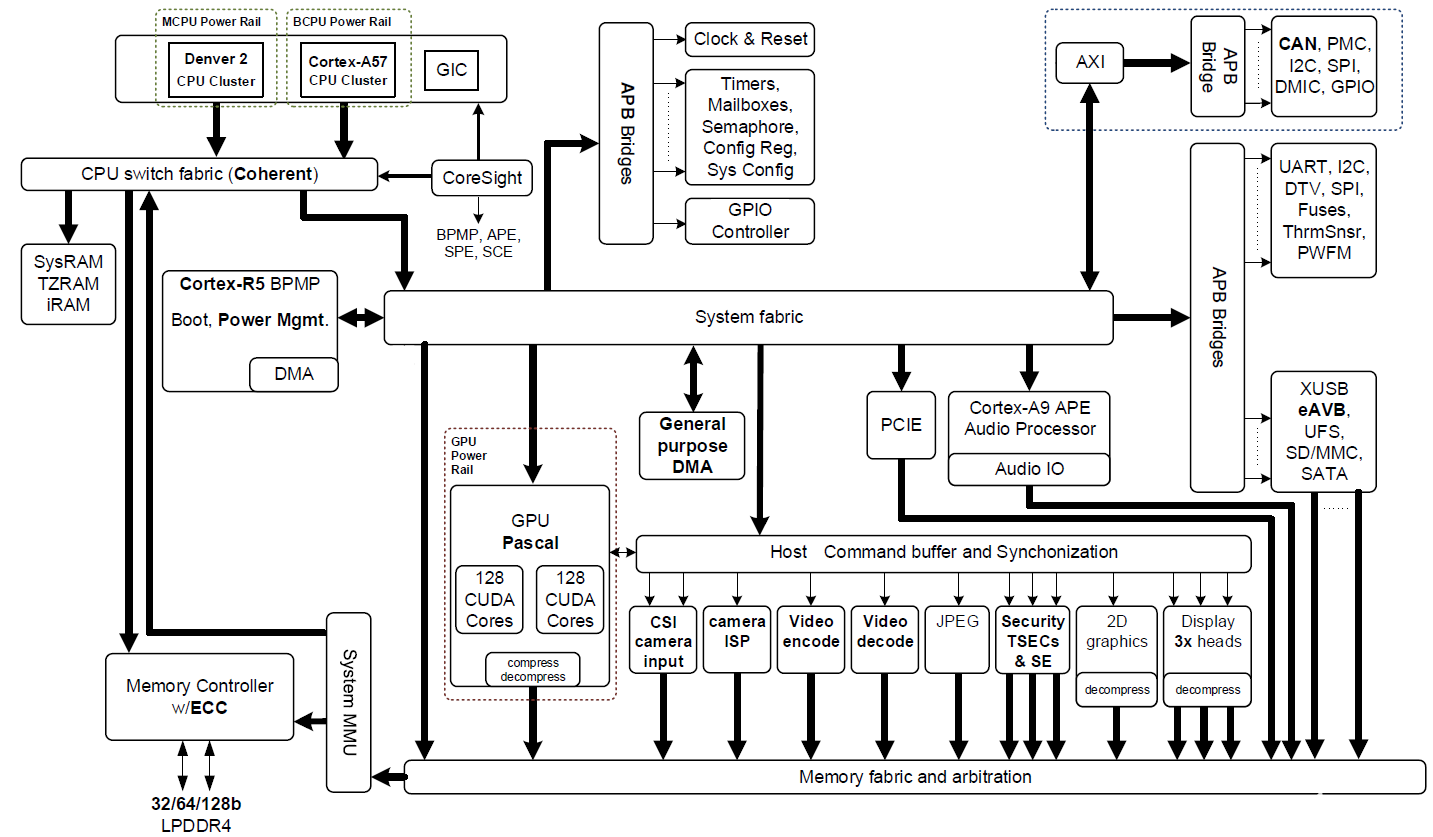
圖 2:NVIDIA Jetson TX2 Tegra “Parker” SoC 框圖,具有集成的 NVIDIA Pascal GPU、NVIDIA Denver 2 + Arm Cortex-A57 CPU 集群和多媒體加速引擎(點(diǎn)擊圖片查看完整分辨率)。
Jetson TX2 具有多個(gè)多媒體流引擎,可通過卸載傳感器采集和分發(fā)來為其 Pascal GPU 提供數(shù)據(jù)。這些多媒體引擎包括六個(gè)專用 MIPI CSI-2 攝像頭端口,每個(gè)通道的帶寬高達(dá) 2.5 Gb/s,雙圖像服務(wù)處理器 (ISP) 的處理速度為 1.4 gigapixels/s,以及支持 H.265 的 4K 視頻編解碼器每秒 60 幀。
Jetson TX2 使用 NVIDIA cuDNN 和 TensorRT 庫加速尖端的深度神經(jīng)網(wǎng)絡(luò) (DNN) 架構(gòu),并支持 循環(huán)神經(jīng)網(wǎng)絡(luò) (RNN)、 長短期記憶網(wǎng)絡(luò) (LSTM)和在線 強(qiáng)化學(xué)習(xí)。其雙 CAN 總線控制器可實(shí)現(xiàn)自動(dòng)駕駛集成,以控制使用 DNN 感知周圍世界并在動(dòng)態(tài)環(huán)境中安全運(yùn)行的機(jī)器人和無人機(jī)。Jetson TX2 軟件通過 NVIDIA 的 JetPack 3.0 和 Linux For Tegra (L4T) 板級支持包 (BSP) 提供。
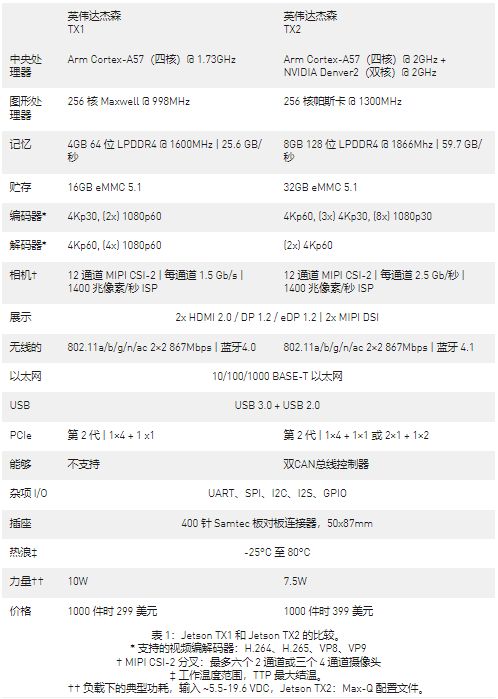
表 1 比較了 Jetson TX2 與上一代 Jetson TX1 的特性。
性能翻倍,效率翻倍
在我 關(guān)于 JetPack 2.3 的帖子中,我展示了 NVIDIA TensorRT 如何以比桌面級 CPU 高 18 倍的效率提高 Jetson TX1 深度學(xué)習(xí)推理性能。TensorRT 通過使用圖形優(yōu)化、內(nèi)核融合、 半精度浮點(diǎn)計(jì)算 (FP16)和架構(gòu)自動(dòng)調(diào)整來優(yōu)化生產(chǎn)網(wǎng)絡(luò)以顯著提高性能。除了利用 Jetson TX2 對 FP16 的硬件支持外,NVIDIA TensorRT 還能夠同時(shí)批量處理多個(gè)圖像,從而獲得更高的性能。
Jetson TX2 和 JetPack 3.0 共同將 Jetson 平臺(tái)的性能和效率提升到一個(gè)全新的水平,為用戶提供獲得兩倍于 Jetson TX1 的效率或高達(dá)兩倍于 AI 應(yīng)用程序性能的選項(xiàng)。這種獨(dú)特的功能使 Jetson TX2 成為需要在邊緣高效 AI 的產(chǎn)品和需要在邊緣附近獲得高性能的產(chǎn)品的理想選擇。Jetson TX2 還與 Jetson TX1 直接兼容,并為使用 Jetson TX1 設(shè)計(jì)的產(chǎn)品提供了輕松升級的機(jī)會(huì)。
為了對 Jetson TX2 和 JetPack 3.0 的性能進(jìn)行基準(zhǔn)測試,我們將其與服務(wù)器級 CPU、Intel Xeon E5-2690 v4 進(jìn)行比較,并使用 GoogLeNet 深度圖像識(shí)別網(wǎng)絡(luò)測量深度學(xué)習(xí)推理吞吐量(每秒圖像數(shù))。如圖 3 所示,以不到 15 W 的功率運(yùn)行的 Jetson TX2 優(yōu)于以近 200 W 的功率運(yùn)行的 CPU,從而在邊緣實(shí)現(xiàn)數(shù)據(jù)中心級 AI 功能。
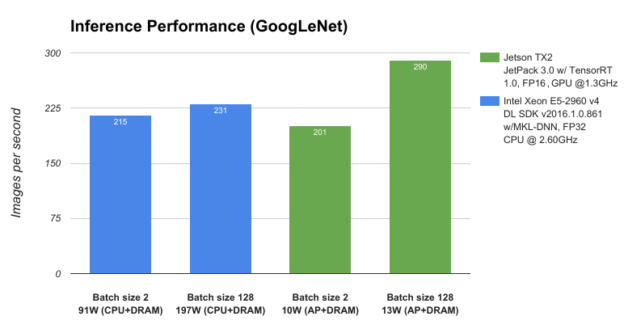
圖 3:在 NVIDIA Jetson TX2 和 Intel Xeon E5-2960 v4 上分析的 GoogLeNet 網(wǎng)絡(luò)架構(gòu)的性能。
Jetson TX2 這種卓越的 AI 性能和效率源于新的 Pascal GPU 架構(gòu)和動(dòng)態(tài)能量配置文件(Max-Q 和 Max-P)、JetPack 3.0 附帶的優(yōu)化深度學(xué)習(xí)庫以及大內(nèi)存帶寬的可用性。
Max-Q 和 Max-P
Jetson TX2 旨在實(shí)現(xiàn) 7.5W 功率下的峰值處理效率。這種性能水平(稱為 Max-Q)代表了功率/吞吐量曲線的峰值。模塊上的每個(gè)組件(包括電源)都經(jīng)過優(yōu)化,可在此時(shí)提供最高效率。GPU 的 Max-Q 頻率為 854 MHz,而 Arm A57 CPU 的 Max-Q 頻率為 1.2 GHz。JetPack 3.0 中的 L4T BSP 包括用于將 Jetson TX2 設(shè)置為 Max-Q 模式的預(yù)設(shè)平臺(tái)配置。JetPack 3.0 還包括一個(gè)新的命令行工具nvpmodel ,用于在運(yùn)行時(shí)切換配置文件。
雖然動(dòng)態(tài)電壓和頻率縮放 (DVFS) 允許 Jetson TX2 的 Tegra “Parker” SoC 在運(yùn)行時(shí)根據(jù)用戶負(fù)載和功耗調(diào)整時(shí)鐘速度,但 Max-Q 配置設(shè)置了時(shí)鐘上限以確保應(yīng)用程序正常運(yùn)行僅在最有效的范圍內(nèi)。表 2 顯示了 Jetson TX2 和 Jetson TX1 在運(yùn)行 GoogLeNet 和 AlexNet 深度學(xué)習(xí)基準(zhǔn)時(shí)的性能和能效。在 Max-Q 模式下運(yùn)行的 Jetson TX2 的性能與在最大時(shí)鐘頻率下運(yùn)行的 Jetson TX1 的性能相似,但僅消耗一半的功率,從而使能效提高了一倍。
盡管大多數(shù)功率預(yù)算有限的平臺(tái)將從 Max-Q 行為中獲益最多,但其他平臺(tái)可能更喜歡使用最大時(shí)鐘來獲得峰值吞吐量,盡管功耗更高且效率降低。DVFS 可以配置為以一系列其他時(shí)鐘速度運(yùn)行,包括降頻和超頻。Max-P 是另一種預(yù)設(shè)平臺(tái)配置,可在不到 15W 的情況下實(shí)現(xiàn)最大系統(tǒng)性能。當(dāng)啟用 Arm A57 集群或 Denver 2 集群時(shí),GPU 的 Max-P 頻率為 1122 MHz,CPU 的 Max-P 頻率為 2 GHz;同時(shí)啟用兩個(gè)集群時(shí),Max-P 頻率為 1.4 GHz。您還可以創(chuàng)建具有中頻目標(biāo)的自定義平臺(tái)配置,以便在您的應(yīng)用程序的峰值效率和峰值性能之間取得平衡。
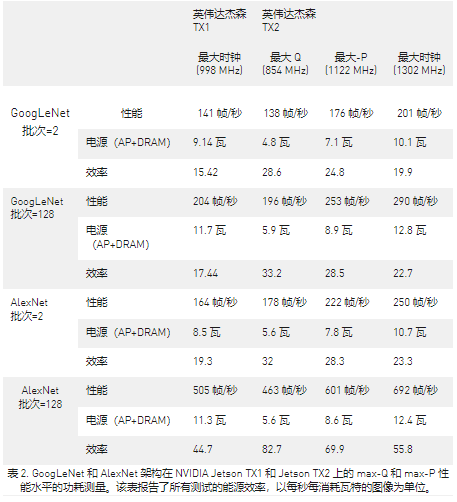
Jetson TX2 執(zhí)行 GoogLeNet 推理的速度高達(dá) 33.2 圖像/秒/瓦,效率幾乎是 Jetson TX1 的兩倍,比英特爾至強(qiáng)效率高近 20 倍。
端到端人工智能應(yīng)用
Jetson TX2 的高效性能不可或缺的是兩個(gè) Pascal 流式多處理器 (SM),每個(gè)處理器具有 128 個(gè) CUDA 內(nèi)核。Pascal GPU 架構(gòu)提供了重大的 性能改進(jìn)和功耗優(yōu)化。TX2 的 CPU 復(fù)合體包括一個(gè)雙核 7 路超標(biāo)量 NVIDIA Denver 2,通過動(dòng)態(tài)代碼優(yōu)化實(shí)現(xiàn)高單線程性能,以及一個(gè)面向多線程的四核 Arm Cortex-A57。
連貫的 Denver 2 和 A57 CPU 各有一個(gè) 2MB L2 高速緩存,并通過 NVIDIA 設(shè)計(jì)的高性能互連結(jié)構(gòu)進(jìn)行鏈接,以使兩個(gè) CPU 在異構(gòu)多處理器 (HMP) 環(huán)境中同時(shí)運(yùn)行。一致性機(jī)制允許任務(wù)根據(jù)動(dòng)態(tài)性能需求自由遷移,有效利用 CPU 內(nèi)核之間的資源,減少開銷。
Jetson TX2 是自主機(jī)器端到端 AI 管道的理想平臺(tái)。Jetson 用于流式傳輸實(shí)時(shí)高帶寬數(shù)據(jù):它可以同時(shí)從多個(gè)傳感器攝取數(shù)據(jù),并在 GPU 上處理數(shù)據(jù)后執(zhí)行媒體解碼/編碼、網(wǎng)絡(luò)和低級命令和控制協(xié)議。圖 4 顯示了使用一系列高速接口(包括 CSI、PCIe、USB3 和千兆以太網(wǎng))連接傳感器的常見管道配置。CUDA 預(yù)處理和后處理階段通常包括色彩空間轉(zhuǎn)換(成像 DNN 通常使用 BGR 平面格式)和網(wǎng)絡(luò)輸出的統(tǒng)計(jì)分析。

圖 4:端到端 AI 管道,包括傳感器采集、處理、命令和控制。
Jetson TX2 的內(nèi)存和帶寬是 Jetson TX1 的兩倍,能夠同時(shí)捕獲和處理額外的高帶寬數(shù)據(jù)流,包括立體攝像機(jī)和 4K 超高清輸入和輸出。通過管道深度學(xué)習(xí)和計(jì)算機(jī)視覺將來自不同來源和光譜域的多個(gè)傳感器融合在一起,提高自主導(dǎo)航期間的感知和態(tài)勢感知。
Jetson TX2 開發(fā)人員套件入門
首先,NVIDIA 提供了 Jetson TX2 開發(fā)人員套件 ,其中包括一個(gè)參考 mini-ITX 載板(170 毫米 x 170 毫米)和一個(gè) 5 兆像素的 MIPI CSI-2 攝像頭模塊。開發(fā)工具包包括文檔和設(shè)計(jì)原理圖以及 JetPack-L4T 的免費(fèi)軟件更新。圖 5 展示了開發(fā)人員套件,顯示了 Jetson TX2 模塊和標(biāo)準(zhǔn) PC 連接,包括 USB3、HDMI、RJ45 千兆以太網(wǎng)、SD 卡和 PCIe x4 插槽,這使得為 Jetson 開發(fā)應(yīng)用程序變得容易。
要從開發(fā)轉(zhuǎn)向定制部署平臺(tái),您可以修改開發(fā)工具包載板和相機(jī)模塊的參考設(shè)計(jì)文件以創(chuàng)建定制設(shè)計(jì)。或者,Jetson 生態(tài)系統(tǒng)合作伙伴提供現(xiàn)成的解決方案,用于部署 Jetson TX1 和 Jetson TX2 模塊,包括微型載體、外殼和攝像頭。NVIDIA 開發(fā)者論壇 提供技術(shù)支持和與 Jetson 構(gòu)建者和 NVIDIA 工程師社區(qū)合作的場所。 表 3 列出了主要文檔和有用的資源。

Jetson TX2 開發(fā)人員套件可通過NVIDIA 在線商店預(yù)訂,價(jià)格為 599 美元 。北美和歐洲將于 3 月 14 日開始發(fā)貨,其他地區(qū)也將陸續(xù)發(fā)貨。還提供 Jetson TX2 教育折扣 :299 美元適用于學(xué)術(shù)機(jī)構(gòu)的附屬機(jī)構(gòu)。NVIDIA 已將 Jetson TX1 開發(fā)者套件的價(jià)格降至 499 美元。
JetPack 3.0 SDK
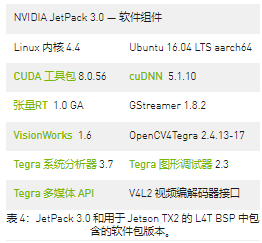
最新的 NVIDIA JetPack 3.0 使 Jetson TX2 能夠使用行業(yè)領(lǐng)先的 AI 開發(fā)人員工具和硬件加速 API(見表 4),包括構(gòu)建在 Linux 之上的 NVIDIA CUDA Toolkit 8.0 版、cuDNN、TensorRT、VisionWorks、GStreamer 和 OpenCV內(nèi)核 v4.4、L4T R27.1 BSP 和 Ubuntu 16.04 LTS。Jetpack 3.0 包括用于交互式分析和調(diào)試的 Tegra System Profiler 和 Tegra Graphics Debugger 工具。Tegra Multimedia API 包括低級攝像頭捕獲和 Video4Linux2 (V4L2) 編解碼器接口。閃爍時(shí),JetPack 會(huì)自動(dòng)使用選定的軟件組件配置 Jetson TX2,從而實(shí)現(xiàn)開箱即用的完整環(huán)境。
Jetson 是用于部署 Caffe、Torch、Theano 和 TensorFlow 等深度學(xué)習(xí)框架的高性能嵌入式解決方案。這些和許多其他深度學(xué)習(xí)框架已經(jīng)將 NVIDIA 的 cuDNN 庫與 GPU 加速集成在一起,并且只需極少的遷移工作即可在 Jetson 上進(jìn)行部署。Jetson 采用 NVIDIA 的共享軟件和硬件架構(gòu),通常在 PC 和服務(wù)器環(huán)境中使用,以在整個(gè)企業(yè)中無縫擴(kuò)展和部署從云和數(shù)據(jù)中心到邊緣設(shè)備的應(yīng)用程序。
兩天的演示
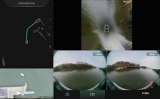
NVIDIA 為期兩天的演示 計(jì)劃旨在幫助任何人開始部署深度學(xué)習(xí)。NVIDIA 提供計(jì)算機(jī)視覺原語,包括圖像識(shí)別、對象檢測+定位、分割和使用DIGITS訓(xùn)練的 神經(jīng)網(wǎng)絡(luò)模型。您可以將這些網(wǎng)絡(luò)模型部署到 Jetson,以使用NVIDIA TensorRT進(jìn)行高效的深度學(xué)習(xí)推理 。兩天演示提供示例流應(yīng)用程序,以幫助您試驗(yàn)實(shí)時(shí)攝像頭饋送和真實(shí)世界數(shù)據(jù),如圖 6 所示。
GitHub 上提供了為期兩天的演示代碼 ,以及易于遵循的分步說明,用于測試和重新訓(xùn)練網(wǎng)絡(luò)模型,為您的自定義主題擴(kuò)展視覺原語。這些教程說明了 DIGITS 工作流的強(qiáng)大概念,向您展示如何在云或 PC 上迭代訓(xùn)練網(wǎng)絡(luò)模型,然后將它們部署到 Jetson 以進(jìn)行運(yùn)行時(shí)推理和進(jìn)一步的數(shù)據(jù)收集。
使用預(yù)先訓(xùn)練的網(wǎng)絡(luò)和遷移學(xué)習(xí),此工作流可以輕松地根據(jù)您的任務(wù)定制基礎(chǔ)網(wǎng)絡(luò),并使用自定義對象類。一旦針對某個(gè)原語或應(yīng)用程序證明了特定的網(wǎng)絡(luò)架構(gòu),給定包含新對象的示例訓(xùn)練數(shù)據(jù),為特定用戶定義的應(yīng)用程序重新調(diào)整用途或重新訓(xùn)練它通常會(huì)容易得多。
正如 這篇 Parallel Forall 博客文章中所討論的,NVIDIA 已為 DIGITS 5 添加了對分段網(wǎng)絡(luò)的支持,現(xiàn)在可用于 Jetson TX2 和為期兩天的演示。分割原語使用全卷積 Alexnet 架構(gòu) (FCN-Alexnet) 對視野中的單個(gè)像素進(jìn)行分類。由于分類發(fā)生在像素級別,而不是圖像識(shí)別中的圖像級別,因此分割模型能夠提取對其周圍環(huán)境的全面理解。這克服了自主導(dǎo)航機(jī)器人和無人機(jī)所面臨的重大障礙,這些機(jī)器人和無人機(jī)可以直接使用分割場進(jìn)行路徑規(guī)劃和避障。
分段引導(dǎo)的自由空間檢測使地面車輛能夠安全地導(dǎo)航地平面,而無人機(jī)則可以視覺識(shí)別并跟隨地平線和天空平面,以避免與障礙物和地形發(fā)生碰撞。感知和避免功能是智能機(jī)器與其環(huán)境安全交互的關(guān)鍵。在 Jetson TX2 上使用 TensorRT 處理機(jī)載計(jì)算要求高的分段網(wǎng)絡(luò)對于避免事故所需的低響應(yīng)延遲至關(guān)重要。
兩天演示包括使用 FCN-Alexnet 的航空分割模型,以及相應(yīng)的地平線第一人稱視圖 (FPV) 數(shù)據(jù)集。空中分割模型可用作無人機(jī)和自主導(dǎo)航的示例。您可以使用自定義數(shù)據(jù)輕松擴(kuò)展模型,以識(shí)別用戶定義的類,如著陸墊和工業(yè)設(shè)備。以這種方式增強(qiáng)后,您可以將其部署到配備 Jetson 的無人機(jī)上,例如 Teal 和 Aerialtronics的無人機(jī)。
為了鼓勵(lì)開發(fā)其他自主飛行控制模式,我在 GitHub 上發(fā)布了空中訓(xùn)練數(shù)據(jù)集、分割模型和工具。NVIDIA Jetson TX2 和 為期兩天的演示 讓您可以比以往更輕松地開始使用該領(lǐng)域的高級深度學(xué)習(xí)解決方案。
Jetson 生態(tài)系統(tǒng)
Jetson TX2 的模塊化外形使其可部署到各種環(huán)境和場景中。來自 Jetson TX2 開發(fā)人員套件的 NVIDIA 開源參考載體設(shè)計(jì)為縮小或修改設(shè)計(jì)以滿足個(gè)別項(xiàng)目要求提供了一個(gè)起點(diǎn)。一些小型化載體具有與 Jetson 模塊本身相同的 50x87mm 占用空間,從而實(shí)現(xiàn)緊湊的組裝,如圖 8 所示。使用 NVIDIA 提供的文檔和設(shè)計(jì)資料制作您自己的產(chǎn)品,或嘗試現(xiàn)成的解決方案。4 月,NVIDIA 將分別以 299 美元和 399 美元的價(jià)格提供 Jetson TX1 和 TX2 模塊,批量為 1000 件或更多。

圖 8:適用于 Jetson TX2 和 Jetson TX1 的 ConnectTech
生態(tài)系統(tǒng)合作伙伴 ConnectTech 和 Auvidea 提供與 Jetson TX1 和 TX2 共享插座兼容的可部署微型載體和外殼,如圖 8 所示。成像合作伙伴 Leopard Imaging 和 Ridge Run 提供相機(jī)和多媒體支持。加固專家 Abaco Systems 和 Wolf Advanced Technology 提供 MIL 規(guī)格認(rèn)證,可在惡劣環(huán)境中運(yùn)行。
可擴(kuò)展陣列在 1U 中提供 24 個(gè) Jetson 插槽,具有 10 Gb 網(wǎng)絡(luò)、被動(dòng)冷卻和節(jié)能綠色 HPC。
除了旨在部署到現(xiàn)場的緊湊型載體和外殼之外,Jetson 生態(tài)系統(tǒng)的范圍還超出了典型嵌入式應(yīng)用程序的范圍。Jetson TX2 的多核 Arm/GPU 架構(gòu)和卓越的計(jì)算效率也引起了高性能計(jì)算 (HPC) 行業(yè)的關(guān)注。高密度 1U 機(jī)架式服務(wù)器現(xiàn)在可提供 10 Gb 以太網(wǎng)和多達(dá) 24 個(gè) Jetson 模塊。圖 9 顯示了一個(gè)示例可擴(kuò)展陣列服務(wù)器。Jetson 的低功耗和被動(dòng)冷卻對于輕量級、可擴(kuò)展的云任務(wù)(包括低功耗 Web 服務(wù)器、多媒體處理和分布式計(jì)算)具有吸引力。
邊緣的人工智能
Jetson TX2 無與倫比的嵌入式計(jì)算能力將尖端 DNN 和下一代 AI 帶入了板載邊緣設(shè)備。Jetson TX2 以高能效提供服務(wù)器級性能,觸手可及。它的原始深度學(xué)習(xí)性能比英特爾至強(qiáng)高出 1.25 倍,計(jì)算效率高出近 20 倍。Jetson 緊湊的占地面積、計(jì)算能力和具有深度學(xué)習(xí)的 JetPack 軟件堆棧使開發(fā)人員能夠使用 AI 解決 21 世紀(jì)的挑戰(zhàn)。
關(guān)于作者
Dustin 是 NVIDIA Jetson 團(tuán)隊(duì)的一名開發(fā)人員推廣員。Dustin 擁有機(jī)器人技術(shù)和嵌入式系統(tǒng)方面的背景,喜歡在社區(qū)中提供幫助并與 Jetson 合作開展項(xiàng)目。
審核編輯:郭婷
-
嵌入式
+關(guān)注
關(guān)注
5082文章
19107瀏覽量
304832 -
AI
+關(guān)注
關(guān)注
87文章
30746瀏覽量
268896 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113
發(fā)布評論請先 登錄
相關(guān)推薦
u-blox深化與NVIDIA Jetson和NVIDIA DRIVE Hyperion平臺(tái)合作
初創(chuàng)公司借助NVIDIA Metropolis和Jetson提高生產(chǎn)線效率
使用NVIDIA Jetson打造機(jī)器人導(dǎo)盲犬
使用機(jī)器學(xué)習(xí)和NVIDIA Jetson邊緣AI和機(jī)器人平臺(tái)打造機(jī)器人導(dǎo)盲犬
NVIDIA JetPack 6.0版本的關(guān)鍵功能

留形科技借助NVIDIA平臺(tái)提供高效精確的三維重建解決方案
NVIDIA Jetson Orin系列邊緣計(jì)算主機(jī)

如何在tx2部署模型
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持
NVIDIA 通過 Holoscan 為 NVIDIA IGX 提供企業(yè)軟件支持,實(shí)現(xiàn)邊緣實(shí)時(shí)醫(yī)療、工業(yè)和科學(xué) AI 應(yīng)用

Nvidia Jetson Nano + CYW55573/AWXB327MA-PUR M.2無法使用操作系統(tǒng)內(nèi)置的網(wǎng)絡(luò)管理器管理Wi-Fi如何解決?
除英偉達(dá)Jetson系列外,AI邊緣計(jì)算盒子還能搭載哪些算力芯片
NVIDIA AI賦能水面自動(dòng)駕駛技術(shù),實(shí)現(xiàn)多種標(biāo)準(zhǔn)落地應(yīng)用
NVIDIA Jetson為嵌入式計(jì)算領(lǐng)域探索AI可能

FPGA模擬MIPI相機(jī)接入Jetson方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論