 C語言代碼優化的一些技巧
C語言代碼優化的一些技巧
1、選擇合適的算法和數據結構
選擇一種合適的數據結構很重要,如果在一堆隨機存放的數中使用了大量的插入和刪除指令,那使用鏈表要快得多。數組與指針語句具有十分密切的關系,一般來說,指針比較靈活簡潔,而數組則比較直觀,容易理解。對于大部分的編譯器,使用指針比使用數組生成的代碼更短,執行效率更高。
在許多種情況下,可以用指針運算代替數組索引,這樣做常常能產生又快又短的代碼。與數組索引相比,指針一般能使代碼速度更快,占用空間更少。使用多維數組時差異更明顯。下面的代碼作用是相同的,但是效率不一樣。
數組索引 指針運算For(;;){ p=arrayA=array[t++]; for(;;){a=*(p++);。。。。。。。。。。。。。。。} }
指針方法的優點是,array的地址每次裝入地址p后,在每次循環中只需對p增量操作。在數組索引方法中,每次循環中都必須根據t值求數組下標的復雜運算。
2、使用盡量小的數據類型
能夠使用字符型(char)定義的變量,就不要使用整型(int)變量來定義;能夠使用整型變量定義的變量就不要用長整型(long int),能不使用浮點型(float)變量就不要使用浮點型變量。當然,在定義變量后不要超過變量的作用范圍,如果超過變量的范圍賦值,C編譯器并不報錯,但程序運行結果卻錯了,而且這樣的錯誤很難發現。
在ICCAVR中,可以在Options中設定使用printf參數,盡量使用基本型參數(%c、%d、%x、%X、%u和%s格式說明符),少用長整型參數(%ld、%lu、%lx和%lX格式說明符),至于浮點型的參數(%f)則盡量不要使用,其它C編譯器也一樣。在其它條件不變的情況下,使用%f參數,會使生成的代碼的數量增加很多,執行速度降低。
3、減少運算的強度
(1)、查表(游戲程序員必修課)
一個聰明的游戲大蝦,基本上不會在自己的主循環里搞什么運算工作,絕對是先計算好了,再到循環里查表。看下面的例子:
舊代碼:
long factorial(int i){if (i == 0)return 1;elsereturn i * factorial(i - 1);}
新代碼:
static long factorial_table[] = {1, 1, 2, 6, 24, 120, 720 /* etc */ };long factorial(int i){return factorial_table[i];}
如果表很大,不好寫,就寫一個init函數,在循環外臨時生成表格。
(2)求余運算
a=a%8;
可以改為:
a=a&7;
說明:位操作只需一個指令周期即可完成,而大部分的C編譯器的“%”運算均是調用子程序來完成,代碼長、執行速度慢。通常,只要求是求2n方的余數,均可使用位操作的方法來代替。
(3)平方運算
a=pow(a, 2.0);
可以改為:
a=a*a;
說明:在有內置硬件乘法器的單片機中(如51系列),乘法運算比求平方運算快得多,因為浮點數的求平方是通過調用子程序來實現的,在自帶硬件乘法器的AVR單片機中,如ATMega163中,乘法運算只需2個時鐘周期就可以完成。既使是在沒有內置硬件乘法器的AVR單片機中,乘法運算的子程序比平方運算的子程序代碼短,執行速度快。
如果是求3次方,如:
a=pow(a,3.0);
更改為:
a=a*a*a;
則效率的改善更明顯。
(4)用移位實現乘除法運算
a=a*4;b=b/4;
可以改為:
a=a<<2;b=b>>2;
通常如果需要乘以或除以2n,都可以用移位的方法代替。在ICCAVR中,如果乘以2n,都可以生成左移的代碼,而乘以其它的整數或除以任何數,均調用乘除法子程序。用移位的方法得到代碼比調用乘除法子程序生成的代碼效率高。實際上,只要是乘以或除以一個整數,均可以用移位的方法得到結果,如:
a=a*9
可以改為:
a=(a<<3)+a
采用運算量更小的表達式替換原來的表達式,下面是一個經典例子:
舊代碼:
x = w % 8;y = pow(x, 2.0);z = y * 33;for (i = 0;i < MAX;i++){h = 14 * i;printf("%d", h);}
新代碼:
x = w & 7; /* 位操作比求余運算快*/y = x * x; /* 乘法比平方運算快*/z = (y << 5) + y; /* 位移乘法比乘法快 */for (i = h = 0; i < MAX; i++){h += 14; /* 加法比乘法快 */printf("%d",h);}
(5)避免不必要的整數除法
整數除法是整數運算中最慢的,所以應該盡可能避免。一種可能減少整數除法的地方是連除,這里除法可以由乘法代替。這個替換的副作用是有可能在算乘積時會溢出,所以只能在一定范圍的除法中使用。
不好的代碼:
int i, j, k, m;m = i / j / k;
推薦的代碼:
int i, j, k, m;m = i / (j * k);
(6)使用增量和減量操作符
在使用到加一和減一操作時盡量使用增量和減量操作符,因為增量符語句比賦值語句更快,原因在于對大多數CPU來說,對內存字的增、減量操作不必明顯地使用取內存和寫內存的指令,比如下面這條語句:
x=x+1;
模仿大多數微機匯編語言為例,產生的代碼類似于:
move A,x ;把x從內存取出存入累加器Aadd A,1 ;累加器A加1store x ;把新值存回x
如果使用增量操作符,生成的代碼如下:
incr x ;x加1
顯然,不用取指令和存指令,增、減量操作執行的速度加快,同時長度也縮短了。
(7)使用復合賦值表達式
復合賦值表達式(如a-=1及a+=1等)都能夠生成高質量的程序代碼。
(8)提取公共的子表達式
在某些情況下,C++編譯器不能從浮點表達式中提出公共的子表達式,因為這意味著相當于對表達式重新排序。
需要特別指出的是,編譯器在提取公共子表達式前不能按照代數的等價關系重新安排表達式。這時,程序員要手動地提出公共的子表達式(在VC.NET里有一項“全局優化”選項可以完成此工作,但效果就不得而知了)。
不好的代碼:
float a, b, c, d, e, f;。。。e = b * c / d;f = b / d * a;
推薦的代碼:
float a, b, c, d, e, f;。。。const float t(b / d);e = c * t;f = a * t;
不好的代碼:
float a, b, c, e, f;。。。e = a / c;f = b / c;
推薦的代碼:
float a, b, c, e, f;。。。const float t(1.0f / c);e = a * t;f = b * t;
4、結構體成員的布局
很多編譯器有“使結構體字,雙字或四字對齊”的選項。但是,還是需要改善結構體成員的對齊,有些編譯器可能分配給結構體成員空間的順序與他們聲明的不同。但是,有些編譯器并不提供這些功能,或者效果不好。
所以,要在付出最少代價的情況下實現最好的結構體和結構體成員對齊,建議采取下列方法:
(1)按數據類型的長度排序
把結構體的成員按照它們的類型長度排序,聲明成員時把長的類型放在短的前面。編譯器要求把長型數據類型存放在偶數地址邊界。
在申明一個復雜的數據類型 (既有多字節數據又有單字節數據) 時,應該首先存放多字節數據,然后再存放單字節數據,這樣可以避免內存的空洞。編譯器自動地把結構的實例對齊在內存的偶數邊界。
(2)把結構體填充成最長類型長度的整倍數
把結構體填充成最長類型長度的整倍數。照這樣,如果結構體的第一個成員對齊了,所有整個結構體自然也就對齊了。下面的例子演示了如何對結構體成員進行重新排序:
不好的代碼,普通順序:
struct{char a[5];long k;double x;} baz;
推薦的代碼,新的順序并手動填充了幾個字節:
struct{double x;long k;char a[5];char pad[7];} baz;
這個規則同樣適用于類的成員的布局。
(3)按數據類型的長度排序本地變量
當編譯器分配給本地變量空間時,它們的順序和它們在源代碼中聲明的順序一樣,和上一條規則一樣,應該把長的變量放在短的變量前面。如果第一個變量對齊了,其它變量就會連續的存放,而且不用填充字節自然就會對齊。有些編譯器在分配變量時不會自動改變變量順序,有些編譯器不能產生4字節對齊的棧,所以4字節可能不對齊。
下面這個例子演示了本地變量聲明的重新排序:
不好的代碼,普通順序
short ga, gu, gi;long foo, bar;double x, y, z[3];char a, b;float baz;
推薦的代碼,改進的順序
double z[3];double x, y;long foo, bar;float baz;short ga, gu, gi;
(4)把頻繁使用的指針型參數拷貝到本地變量
避免在函數中頻繁使用指針型參數指向的值。因為編譯器不知道指針之間是否存在沖突,所以指針型參數往往不能被編譯器優化。這樣數據不能被存放在寄存器中,而且明顯地占用了內存帶寬。
注意,很多編譯器有“假設不沖突”優化開關(在VC里必須手動添加編譯器命令行/Oa或/Ow),這允許編譯器假設兩個不同的指針總是有不同的內容,這樣就不用把指針型參數保存到本地變量。否則,請在函數一開始把指針指向的數據保存到本地變量。如果需要的話,在函數結束前拷貝回去。
不好的代碼:
// 假設 q != rvoid isqrt(unsigned long a, unsigned long* q, unsigned long* r){*q = a;if (a > 0){while (*q > (*r = a / *q)){*q = (*q + *r) >> 1;}}*r = a - *q * *q;}
推薦的代碼:
// 假設 q != rvoid isqrt(unsigned long a, unsigned long* q, unsigned long* r){unsigned long qq, rr;qq = a;if (a > 0){while (qq > (rr = a / qq)){qq = (qq + rr) >> 1;}}rr = a - qq * qq;*q = qq;*r = rr;}
5、循環優化
(1)充分分解小的循環
要充分利用CPU的指令緩存,就要充分分解小的循環。特別是當循環體本身很小的時候,分解循環可以提高性能。
注意,很多編譯器并不能自動分解循環。不好的代碼:
// 3D轉化:把矢量 V 和 4x4 矩陣 M 相乘for (i = 0;i < 4;i ++){r[i] = 0;for (j = 0;j < 4;j ++){r[i] += M[j][i]*V[j];}}
推薦的代碼:
r[0] = M[0][0]*V[0] + M[1][0]*V[1] + M[2][0]*V[2] + M[3][0]*V[3];r[1] = M[0][1]*V[0] + M[1][1]*V[1] + M[2][1]*V[2] + M[3][1]*V[3];r[2] = M[0][2]*V[0] + M[1][2]*V[1] + M[2][2]*V[2] + M[3][2]*V[3];r[3] = M[0][3]*V[0] + M[1][3]*V[1] + M[2][3]*V[2] + M[3][3]*v[3];
(2)提取公共部分
對于一些不需要循環變量參加運算的任務可以把它們放到循環外面,這里的任務包括表達式、函數的調用、指針運算、數組訪問等,應該將沒有必要執行多次的操作全部集合在一起,放到一個init的初始化程序中進行。
(3)延時函數
通常使用的延時函數均采用自加的形式:

將其改為自減延時函數:
void delay (void){unsigned int i;for (i=1000;i>0;i--) ;}
兩個函數的延時效果相似,但幾乎所有的C編譯對后一種函數生成的代碼均比前一種代碼少1~3個字節,因為幾乎所有的MCU均有為0轉移的指令,采用后一種方式能夠生成這類指令。在使用while循環時也一樣,使用自減指令控制循環會比使用自加指令控制循環生成的代碼更少1~3個字母。
但是,在循環中有通過循環變量“i”讀寫數組的指令時,使用預減循環有可能使數組超界,要引起注意。
(4)while循環和do…while循環
用while循環時有以下兩種循環形式:
unsigned int i;i=0;while (i<1000){i++;//用戶程序}
或:
unsigned int i;i=1000;do{i--;//用戶程序}while (i>0);
在這兩種循環中,使用do…while循環編譯后生成的代碼的長度短于while循環。
(5)循環展開
這是經典的速度優化,但許多編譯程序(如gcc -funroll-loops)能自動完成這個事,所以現在你自己來優化這個顯得效果不明顯。
舊代碼:
for (i = 0; i < 100; i++){do_stuff(i);}
新代碼:
for (i = 0; i < 100; ){do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;do_stuff(i); i++;}
可以看出,新代碼里比較指令由100次降低為10次,循環時間節約了90%。不過注意:對于中間變量或結果被更改的循環,編譯程序往往拒絕展開(怕擔責任唄),這時候就需要你自己來做展開工作了。
還有一點請注意,在有內部指令cache的CPU上(如MMX芯片),因為循環展開的代碼很大,往往cache溢出,這時展開的代碼會頻繁地在CPU 的cache和內存之間調來調去,又因為cache速度很高,所以此時循環展開反而會變慢。還有就是循環展開會影響矢量運算優化。
(6)循環嵌套
把相關循環放到一個循環里,也會加快速度。
舊代碼:
for (i = 0; i < MAX; i++) /* initialize 2d array to 0's */for (j = 0; j < MAX; j++)a[i][j] = 0.0;for (i = 0; i < MAX; i++) /* put 1's along the diagonal */a[i][i] = 1.0;
新代碼:
for (i = 0; i < MAX; i++) /* initialize 2d array to 0's */{for (j = 0; j < MAX; j++)a[i][j] = 0.0;a[i][i] = 1.0; /* put 1's along the diagonal */}
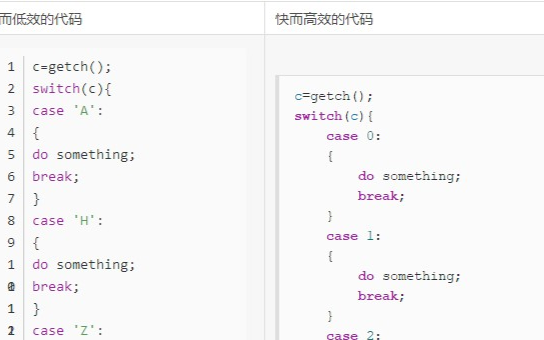
(7)Switch語句中根據發生頻率來進行case排序
Switch 可能轉化成多種不同算法的代碼。其中最常見的是跳轉表和比較鏈/樹。當switch用比較鏈的方式轉化時,編譯器會產生if-else-if的嵌套代碼,并按照順序進行比較,匹配時就跳轉到滿足條件的語句執行。所以,可以對case的值依照發生的可能性進行排序,把最有可能的放在第一位,這樣可以提高性能。
此外,在case中推薦使用小的連續的整數,因為在這種情況下,所有的編譯器都可以把switch 轉化成跳轉表。
不好的代碼:
int days_in_month, short_months, normal_months, long_months;。。。。。。switch (days_in_month){case 28:case 29:short_months ++;break;case 30:normal_months ++;break;case 31:long_months ++;break;default:cout << "month has fewer than 28 or more than 31 days" << endl;break;}
推薦的代碼:
int days_in_month, short_months, normal_months, long_months;。。。。。。switch (days_in_month){case 31:long_months ++;break;case 30:normal_months ++;break;case 28:case 29:short_months ++;break;default:cout << "month has fewer than 28 or more than 31 days" << endl;break;}
(8)將大的switch語句轉為嵌套switch語句
當switch語句中的case標號很多時,為了減少比較的次數,明智的做法是把大switch語句轉為嵌套switch語句。把發生頻率高的case 標號放在一個switch語句中,并且是嵌套switch語句的最外層,發生相對頻率相對低的case標號放在另一個switch語句中。比如,下面的程序段把相對發生頻率低的情況放在缺省的case標號內。
pMsg=ReceiveMessage();switch (pMsg->type){case FREQUENT_MSG1:handleFrequentMsg();break;case FREQUENT_MSG2:handleFrequentMsg2();break;。。。。。。case FREQUENT_MSGn:handleFrequentMsgn();break;default: //嵌套部分用來處理不經常發生的消息switch (pMsg->type){case INFREQUENT_MSG1:handleInfrequentMsg1();break;case INFREQUENT_MSG2:handleInfrequentMsg2();break;。。。。。。case INFREQUENT_MSGm:handleInfrequentMsgm();break;}}
如果switch中每一種情況下都有很多的工作要做,那么把整個switch語句用一個指向函數指針的表來替換會更加有效,比如下面的switch語句,有三種情況:
enum MsgType{Msg1, Msg2, Msg3}switch (ReceiveMessage(){case Msg1;。。。。。。case Msg2;。。。。。case Msg3;。。。。。}
為了提高執行速度,用下面這段代碼來替換這個上面的switch語句。
/*準備工作*/int handleMsg1(void);int handleMsg2(void);int handleMsg3(void);/*創建一個函數指針數組*/int (*MsgFunction [])()={handleMsg1, handleMsg2, handleMsg3};/*用下面這行更有效的代碼來替換switch語句*/status=MsgFunction[ReceiveMessage()]();
(9)循環轉置
有些機器對JNZ(為0轉移)有特別的指令處理,速度非常快,如果你的循環對方向不敏感,可以由大向小循環。
舊代碼:
for (i = 1; i <= MAX; i++){。。。}
新代碼:
i = MAX+1;while (--i){。。。}
不過千萬注意,如果指針操作使用了i值,這種方法可能引起指針越界的嚴重錯誤(i = MAX+1;)。當然,你可以通過對i做加減運算來糾正,但這樣就起不到加速的作用,除非類似于以下情況:
舊代碼:
char a[MAX+5];for (i = 1; i <= MAX; i++){*(a+i+4)=0;}
新代碼:
i = MAX+1;while (--i){*(a+i+4)=0;}
(10)公用代碼塊
一些公用處理模塊,為了滿足各種不同的調用需要,往往在內部采用了大量的if-then-else結構,這樣很不好,判斷語句如果太復雜,會消耗大量的時間的,應該盡量減少公用代碼塊的使用(任何情況下,空間優化和時間優化都是對立的--東樓)。
當然,如果僅僅是一個(3==x)之類的簡單判斷,適當使用一下,也還是允許的。記住,優化永遠是追求一種平衡,而不是走極端。
(11)提升循環的性能
要提升循環的性能,減少多余的常量計算非常有用(比如,不隨循環變化的計算)。
不好的代碼(在for()中包含不變的if()):
for( i 。。。){if( CONSTANT0 ){DoWork0( i );// 假設這里不改變CONSTANT0的值}else{DoWork1( i );// 假設這里不改變CONSTANT0的值}}
推薦的代碼:
if( CONSTANT0 ){for( i 。。。){DoWork0( i );}}else{for( i 。。。){DoWork1( i );}}
如果已經知道if()的值,這樣可以避免重復計算。雖然不好的代碼中的分支可以簡單地預測,但是由于推薦的代碼在進入循環前分支已經確定,就可以減少對分支預測的依賴。
(12)選擇好的無限循環
在編程中,我們常常需要用到無限循環,常用的兩種方法是while (1)和for (;;)。這兩種方法效果完全一樣,但那一種更好呢:C語言while(1) 和 for ( ; ; )的區別。然我們看看它們編譯后的代碼:
編譯前:
while (1);
編譯后:
mov eax,1test eax,eaxje foo+23hjmp foo+18h
編譯前:
for (;;);
編譯后:
jmp foo+23h
顯然,for (;;)指令少,不占用寄存器,而且沒有判斷、跳轉,比while (1)好。
6、提高CPU的并行性
(1)使用并行代碼
盡可能把長的有依賴的代碼鏈分解成幾個可以在流水線執行單元中并行執行的沒有依賴的代碼鏈。很多高級語言,包括C++,并不對產生的浮點表達式重新排序,因為那是一個相當復雜的過程。
需要注意的是,重排序的代碼和原來的代碼在代碼上一致并不等價于計算結果一致,因為浮點操作缺乏精確度。在一些情況下,這些優化可能導致意料之外的結果。幸運的是,在大部分情況下,最后結果可能只有最不重要的位(即最低位)是錯誤的。
不好的代碼:
double a[100], sum;int i;sum = 0.0f;for (i=0;i<100;i++)sum += a[i];
推薦的代碼:
double a[100], sum1, sum2, sum3, sum4, sum;int i;sum1 = sum2 = sum3 = sum4 = 0.0;for (i = 0;i < 100;i += 4){sum1 += a[i];sum2 += a[i+1];sum3 += a[i+2];sum4 += a[i+3];}sum = (sum4+sum3)+(sum1+sum2);
要注意的是:使用4路分解是因為這樣使用了4段流水線浮點加法,浮點加法的每一個段占用一個時鐘周期,保證了最大的資源利用率。
(2)避免沒有必要的讀寫依賴
當數據保存到內存時存在讀寫依賴,即數據必須在正確寫入后才能再次讀取。雖然AMD Athlon等CPU有加速讀寫依賴延遲的硬件,允許在要保存的數據被寫入內存前讀取出來,但是,如果避免了讀寫依賴并把數據保存在內部寄存器中,速度會更快。在一段很長的又互相依賴的代碼鏈中,避免讀寫依賴顯得尤其重要。如果讀寫依賴發生在操作數組時,許多編譯器不能自動優化代碼以避免讀寫依賴。
所以,推薦程序員手動去消除讀寫依賴,舉例來說,引進一個可以保存在寄存器中的臨時變量。這樣可以有很大的性能提升。下面一段代碼是一個例子:
不好的代碼:
float x[VECLEN], y[VECLEN], z[VECLEN];。。。。。。for (unsigned int k = 1;k < VECLEN;k ++){x[k] = x[k-1] + y[k];}for (k = 1;k{x[k] = z[k] * (y[k] - x[k-1]);}
推薦的代碼:
float x[VECLEN], y[VECLEN], z[VECLEN];。。。。。。float t(x[0]);for (unsigned int k = 1;k < VECLEN;k ++){t = t + y[k];x[k] = t;}t = x[0];for (k = 1;k <;VECLEN;k ++){t = z[k] * (y[k] - t);x[k] = t;}
7、循環不變計算
對于一些不需要循環變量參加運算的計算任務可以把它們放到循環外面,現在許多編譯器還是能自己干這件事,不過對于中間使用了變量的算式它們就不敢動了,所以很多情況下你還得自己干。對于那些在循環中調用的函數,凡是沒必要執行多次的操作通通提出來,放到一個init函數里,循環前調用。另外盡量減少喂食次數,沒必要的話盡量不給它傳參,需要循環變量的話讓它自己建立一個靜態循環變量自己累加,速度會快一點。
還有就是結構體訪問,東樓的經驗,凡是在循環里對一個結構體的兩個以上的元素執行了訪問,就有必要建立中間變量了(結構這樣,那C++的對象呢?想想看),看下面的例子:
舊代碼:
total=a->b->c[4]->aardvark+a->b->c[4]->baboon+a->b->c[4]->cheetah+a->b->c[4]->dog;
新代碼:
struct animals * temp = a->b->c[4];total = temp->aardvark + temp->baboon + temp->cheetah + temp->dog;
一些老的C語言編譯器不做聚合優化,而符合ANSI規范的新的編譯器可以自動完成這個優化,看例子:
float a, b, c, d, f, g;。。。a = b / c * d;f = b * g / c;
這種寫法當然要得,但是沒有優化
float a, b, c, d, f, g;。。。a = b / c * d;f = b / c * g;
如果這么寫的話,一個符合ANSI規范的新的編譯器可以只計算b/c一次,然后將結果代入第二個式子,節約了一次除法運算。
8、函數優化
(1)Inline函數
在C++中,關鍵字Inline可以被加入到任何函數的聲明中。這個關鍵字請求編譯器用函數內部的代碼替換所有對于指出的函數的調用。
這樣做在兩個方面快于函數調用:第一,省去了調用指令需要的執行時間;第二,省去了傳遞變元和傳遞過程需要的時間。但是使用這種方法在優化程序速度的同時,程序長度變大了,因此需要更多的ROM。使用這種優化在Inline函數頻繁調用并且只包含幾行代碼的時候是最有效的。
(2)不定義不使用的返回值
函數定義并不知道函數返回值是否被使用,假如返回值從來不會被用到,應該使用void來明確聲明函數不返回任何值。
(3)減少函數調用參數
使用全局變量比函數傳遞參數更加有效率。這樣做去除了函數調用參數入棧和函數完成后參數出棧所需要的時間。然而決定使用全局變量會影響程序的模塊化和重入,故要慎重使用。
(4)所有函數都應該有原型定義
一般來說,所有函數都應該有原型定義。原型定義可以傳達給編譯器更多的可能用于優化的信息。
(5)盡可能使用常量(const)
盡可能使用常量(const)。C++ 標準規定,如果一個const聲明的對象的地址不被獲取,允許編譯器不對它分配儲存空間。這樣可以使代碼更有效率,而且可以生成更好的代碼。
(6)把本地函數聲明為靜態的(static)
如果一個函數只在實現它的文件中被使用,把它聲明為靜態的(static)以強制使用內部連接。否則,默認的情況下會把函數定義為外部連接。這樣可能會影響某些編譯器的優化——比如,自動內聯。
9、采用遞歸
與LISP之類的語言不同,C語言一開始就病態地喜歡用重復代碼循環,許多C程序員都是除非算法要求,堅決不用遞歸。
事實上,C編譯器們對優化遞歸調用一點都不反感,相反,它們還很喜歡干這件事。只有在遞歸函數需要傳遞大量參數,可能造成瓶頸的時候,才應該使用循環代碼,其他時候,還是用遞歸好些。
10、變量
(1)register變量
在聲明局部變量的時候可以使用register關鍵字。這就使得編譯器把變量放入一個多用途的寄存器中,而不是在堆棧中,合理使用這種方法可以提高執行速度。函數調用越是頻繁,越是可能提高代碼的速度。
在最內層循環避免使用全局變量和靜態變量,除非你能確定它在循環周期中不會動態變化,大多數編譯器優化變量都只有一個辦法,就是將他們置成寄存器變量,而對于動態變量,它們干脆放棄對整個表達式的優化。盡量避免把一個變量地址傳遞給另一個函數,雖然這個還很常用。C語言的編譯器們總是先假定每一個函數的變量都是內部變量,這是由它的機制決定的,在這種情況下,它們的優化完成得最好。但是,一旦一個變量有可能被別的函數改變,這幫兄弟就再也不敢把變量放到寄存器里了,嚴重影響速度。
看例子:
a = b();c(&d);
因為d的地址被c函數使用,有可能被改變,編譯器不敢把它長時間的放在寄存器里,一旦運行到c(&d),編譯器就把它放回內存,如果在循環里,會造成N次頻繁的在內存和寄存器之間讀寫d的動作,眾所周知,CPU在系統總線上的讀寫速度慢得很。比如你的賽楊300,CPU主頻300,總線速度最多66M,為了一個總線讀,CPU可能要等4-5個周期,得。。得。。得。。想起來都打顫。
(2)同時聲明多個變量優于單獨聲明變量
(3)短變量名優于長變量名,應盡量使變量名短一點
(4)在循環開始前聲明變量
11、使用嵌套的if結構
在if結構中如果要判斷的并列條件較多,最好將它們拆分成多個if結構,然后嵌套在一起,這樣可以避免無謂的判斷。
說明:
上面的優化方案由王全明收集整理。很多資料來源于網上,出處不祥,在此對所有作者一并致謝!
該方案主要是考慮到在嵌入式開發中對程序執行速度的要求特別高,所以該方案主要是為了優化程序的執行速度。
注意:優化是有側重點的,優化是一門平衡的藝術,它往往要以犧牲程序的可讀性或者增加代碼長度為代價。
-
嵌入式
+關注
關注
5082文章
19104瀏覽量
304829 -
代碼
+關注
關注
30文章
4779瀏覽量
68525 -
數據結構
+關注
關注
3文章
573瀏覽量
40123
原文標題:長文 | 總結嵌入式C語言代碼優化方法
文章出處:【微信號:c-stm32,微信公眾號:STM32嵌入式開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
C語言優化小技巧
Linux內核中GNU C擴展的一些常用C語言語法分析


嵌入式系統C語言的特點及程序設計中代碼優化的技巧
C語言高效編程與代碼優化
C語言的一些常用標準庫分享
嵌入式C語言代碼優化經驗與方法
通過RealSense代碼說明一些C語言問題





 工商網監
工商網監
評論