 如何通過組件配置為深度學習培訓選擇企業服務器
如何通過組件配置為深度學習培訓選擇企業服務器
深度學習已經成為執行許多人工智能任務的最常見的神經網絡實現。數據科學家使用 TensorFlow 和 PyTorch 等軟件框架來開發和運行 DL 算法。
到目前為止,已經有很多關于深度學習的文章,你可以從許多來源找到更詳細的信息。有關良好的高層總結,請參見 人工智能、機器學習和深度學習之間有什么區別?
開始深度學習的一種流行方式是在云中運行這些框架。然而,隨著企業開始增長和成熟其人工智能專業技能,他們會尋找在自己的數據中心運行這些框架的方法,以避免基于云的人工智能的成本和其他挑戰。
在本文中,我將討論如何為 深度學習培訓選擇企業服務器。我回顧了這個獨特工作負載的具體計算需求,然后討論了如何通過組件配置的最佳選擇來滿足這些需求。
DL 培訓的系統要求
深度學習培訓通常被設計為數據處理管道。必須首先根據數據格式、大小和其他因素準備原始輸入數據。
數據通常也會經過預處理,以便相同的輸入可以以不同的方式呈現給模型,這取決于數據科學家所確定的將提供更強大的訓練集的內容。例如,圖像可以隨機旋轉,以便模型學習識別對象,而不考慮方向。然后將準備好的數據輸入 DL 算法。
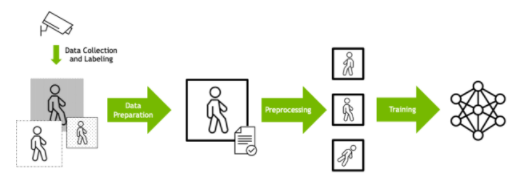
圖 1 深度學習培訓數據管道
了解了 DL 培訓的工作原理后,以下是以最快、最有效的方式執行此任務的具體計算需求。
深度學習的核心是 GPU 。計算網絡每一層的值的過程最終是一組龐大的矩陣乘法。每個層的數據通常可以并行處理,各層之間有協調步驟。
GPU 設計用于以大規模并行方式執行矩陣乘法,并已被證明是實現 深度學習的巨大速度 的理想選擇。
對于訓練,模型的大小是驅動因素,因此具有更大更快內存的 GPU ,比如 NVIDIA A100 GPU 核心張量 ,能夠更快地處理成批的訓練數據。
中央處理器
DL 訓練所需的數據準備和預處理計算通常在 CPU 上執行,盡管 recent innovations 已經使越來越多的計算能夠在 GPU 上執行。
使用高性能的 CPU 以足夠快的速度維持這些操作是至關重要的,這樣 GPU 就不會因為等待數據而感到饑餓。 CPU 應該是企業級的,例如來自英特爾至強可擴展處理器系列或 AMD EPYC 系列,而且 CPU 內核與 GPU 的比例應該足夠大,以保持流水線運行。
系統存儲器
特別是對于當今最大的機型, DL 訓練只有在有大量輸入數據可供訓練時才有效。這些數據從存儲器中批量檢索,然后由 CPU 在系統內存中處理,然后再饋送到 GPU 。
為了保持該進程以持續的速度運行,系統內存應該足夠大,以便 CPU 處理的速率可以與 GPU 處理數據的速率相匹配。這可以用系統內存與 GPU 內存的比率來表示(在服務器中的所有 GPU 中)。
不同的模型和算法需要不同的比率,但最好有更高的比率,這樣 GPU 就永遠不會等待數據。
網絡適配器
隨著 DL 模型變得越來越大,已經開發出了多種技術來執行訓練,多個 GPU 一起工作。當一臺服務器中安裝了多個 GPU 時,它們可以通過 PCIe 總線相互通信,盡管可以使用 NVLink 和 NVSwitch 等更專業的技術來實現最高性能。
Multi- GPU 培訓也可以擴展到跨多臺服務器的工作。在這種情況下,網絡適配器成為服務器設計的關鍵組件。在執行多節點 DL 訓練時,需要高帶寬 Ethernet 或 InfiniBand 適配器來最大限度地減少由于數據傳輸而產生的瓶頸。
DL 框架利用 NCCL 等庫以最佳和性能的方式執行 GPU 之間的協調。 GPUDirect RDMA 等技術使數據能夠從網絡直接傳輸到 GPU ,而無需通過 CPU ,從而消除了延遲源。
理想情況下,系統中每一兩個 GPU 就應該有一個網絡適配器,以便在必須傳輸數據時最大限度地減少爭用。
存儲
DL 培訓數據通常駐留在外部存儲陣列上。服務器上的 NVMe 驅動器通過提供緩存數據的方法,可以大大加快培訓過程。
DL I / O 模式通常由讀取訓練數據的多次迭代組成。訓練的第一步(或 epoch )讀取用于開始訓練模型的數據。如果在節點上提供了足夠的本地緩存,則后續的數據傳遞可以避免從遠程存儲中重新讀取數據。
為了避免從遠程存儲中提取數據時發生爭用,每個 CPU 應該有一個 NVMe 驅動器。
PCIe 拓撲
由于 CPU 、 GPU 和網絡之間存在復雜的相互作用,因此應該清楚的是,具有減少 DL 培訓管道中任何潛在瓶頸的連接設計對于實現最佳性能至關重要。
如今,大多數企業服務器使用 PCIe 作為組件之間的通信手段。 PCIe 總線上的主要流量發生在以下路徑上:
從系統內存到 GPU
在多次 GPU 培訓期間,在相同服務器上的 GPU 之間
在多節點培訓期間 GPU 與網絡適配器之間
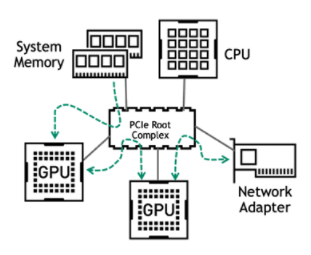
圖 2 主 PCIe 數據通信路徑
用于深度學習的服務器應具有平衡的 PCIe 拓撲結構, GPU 均勻分布在 CPU 插槽和 PCIe 根端口上。在所有情況下,每個 GPU 的 PCIe 通道數應為支持的最大數量。
如果存在多個 GPU ,且 CPU 的 PCIe 通道數量不足以容納所有通道,則可能需要 PCIe 交換機。在這種情況下, PCIe 交換機層的數量應限制為一層或兩層,以最小化 PCIe 延遲。
類似地,網絡適配器和 NVMe 驅動器應與 GPU 處于同一 PCIe 交換機或 PCIe 根復合體之下。在使用 PCIe 交換機的服務器配置中,這些設備應與 GPU 位于同一 PCIe 交換機下,以獲得最佳性能。
選擇支持 DL 培訓的經過驗證的系統
設計一個為 DL 培訓而優化的服務器很復雜。 NVIDIA 已經發布了 關于為各種類型的加速工作負載配置服務器的指南 ,基于多年在這些工作負載方面的經驗,并與開發人員合作優化代碼。
為了讓你更容易上手,NVIDIA 開發了 NVIDIA-Certified Systems 程序。系統供應商合作伙伴已使用特定的 NVIDIA GPU 和網絡適配器配置并測試了多種形式的服務器型號,以驗證 優化設計以獲得最佳性能 的有效性。
驗證還包括生產部署的其他重要功能,如可管理性、安全性和可伸縮性。系統經過針對不同工作負載類型的一系列類別認證。 合格系統目錄 有一份由 NVIDIA partners 提供的經 NVIDIA 認證的系統列表。數據中心類別的服務器已經過驗證,可以為 DL 培訓提供最佳性能。
NVIDIA 人工智能企業
除了合適的硬件,企業客戶還希望為 AI 工作負載選擇受支持的軟件解決方案。 NVIDIA 人工智能企業 是一套端到端、云計算原生的人工智能和數據分析軟件。它經過優化,因此每個組織都可以擅長人工智能,經過認證可以部署在從企業數據中心到公共云的任何地方。人工智能企業包括全球企業支持,以便人工智能項目保持正常運行。
當您在優化配置的服務器上運行 NVIDIA AI Enterprise 時,您可以放心,您正在從硬件和軟件投資中獲得最佳回報。
總結
在本文中,我向您展示了如何為 深度學習培訓 選擇具有特定計算需求的企業服務器。希望您已經學會了如何通過組件配置的最佳選擇來滿足這些需求。
關于作者
Charu Chaubal 在NVIDIA 企業計算平臺集團從事產品營銷工作。他在市場營銷、客戶教育以及技術產品和服務的售前工作方面擁有 20 多年的經驗。 Charu 曾在云計算、超融合基礎設施和 IT 安全等多個領域工作。作為 VMware 的技術營銷領導者,他幫助推出了許多產品,這些產品共同發展成為數十億美元的業務。此前,他曾在 Sun Microsystems 工作,在那里他設計了分布式資源管理和 HPC 基礎設施軟件解決方案。查魯擁有化學工程博士學位,并擁有多項專利。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4979瀏覽量
102994 -
云計算
+關注
關注
39文章
7774瀏覽量
137355 -
服務器
+關注
關注
12文章
9124瀏覽量
85331
發布評論請先 登錄
相關推薦
SMTP服務器配置教程
恒訊科技分享:獨立服務器的選擇技巧

新手小白怎么通過云服務器跑pytorch?
gpu服務器與cpu服務器的區別對比,終于知道怎么選了!
云存儲服務器怎么配置
新手小白怎么學GPU云服務器跑深度學習?
企業在選擇大帶寬服務器時需要考慮哪些其他因素?
OpenBSD中如何配置和使用虛擬專用服務器?
linux服務器和windows服務器
選擇服務器硬件配置需要注意什么?
如何通過WebDAV服務器訪問NAS





 工商網監
工商網監
評論