 如何使用NVIDIA TAO快速準確地訓練AI模型
如何使用NVIDIA TAO快速準確地訓練AI模型
越來越多的要求制造商在其生產過程中達到高質量控制標準。傳統上,制造商依靠人工檢查來保證產品質量。然而,手動檢查成本高昂,通常只覆蓋一小部分生產樣本,最終導致生產瓶頸、生產率降低和效率降低。
通過人工智能和計算機視覺實現缺陷檢測自動化,制造商可以徹底改變其質量控制流程。然而,制造商和全自動化之間存在一個主要障礙。構建一個 AI 系統和生產就緒的應用程序是困難的,通常需要一個熟練的 AI 團隊來訓練和微調模型。一般制造商不采用這種專業技術,而是采用手動檢查。
本項目的目標是展示如何使用NVIDIA轉移學習工具包( TLT )和預訓練模型快速建立制造過程中更精確的質量控制。這個項目是在沒有人工智能專家或數據科學家的情況下完成的。為了了解 NVIDIA TLT 在為商業質量控制目的培訓人工智能系統方面的有效性,使用公開的 dataset 鋼焊接工藝,從 NGC 目錄(一個 GPU 優化的人工智能和 HPC 軟件中心)重新培訓預培訓的 ResNet-18 模型,使用 TLT 。我們比較了人工智能研究團隊先前發表的一項工作中,在數據集上從頭開始構建的模型和由此產生的模型的準確性。
NVIDIA TLT 操作簡便、速度快,不具備人工智能專業知識的工程師可以輕松使用。我們觀察到 NVIDIA TLT 的設置速度更快,結果更準確,宏觀平均 F1 成績 為 97% ,而之前發布的數據集“從頭開始構建”的結果為 78% 。
這篇文章探討了 NVIDIA TLT 如何快速準確地訓練 AI 模型,展示了 AI 和轉移學習如何改變圖像和視頻分析以及工業流程的部署方式。
具有 NVIDIA TLT 的工作流
NVIDIA TLT 是 NVIDIA 訓練、調整和優化( TAO )平臺 的核心組件,遵循零編碼范式快速跟蹤 AI 開發。 TLT 附帶了一套隨時可用的 Jupyter 筆記本、 Python 腳本和配置規范以及默認參數值,使您能夠快速輕松地開始培訓和微調數據集。
為了開始使用 NVIDIA TLT ,我們遵循了以下 快速入門指南說明 。
我們下載了 Docker 容器和 TLT Jupyter 筆記本。
我們將數據集映射到 Docker 容器上。
我們開始了第一次培訓,調整了默認的培訓參數,如網絡結構、網絡大小、優化器等,直到我們對結果感到滿意。
數據集
這個項目中使用的數據集是由伯明翰大學的研究人員為他們的論文 基于可見 spectrum 攝像機和機器學習的 SS304 TIG 焊接過程缺陷自動分類 創建的。
該數據集由超過 45K 的灰度焊接圖像組成,可通過 Kaggle 獲得。數據集描述了一類正確執行: good_weld 。鎢極惰性氣體( TIG )焊接過程中可能出現五類缺陷: 燒穿、污染、未熔合、未保護氣體、, 和 high_travel_speed 。

圖 1 來自培訓數據集的焊接圖像示例
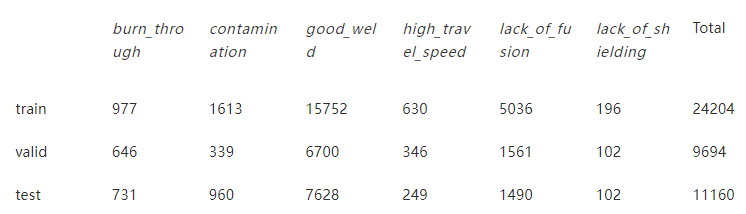
表 1 列車、驗證和測試數據集的圖像分布
與許多工業數據集一樣,該數據集是相當不平衡的,因為很難收集低可能性出現的缺陷的數據。表 1 顯示了列車、驗證和測試數據集的類別分布。
圖 2 顯示了測試數據集中的不平衡。測試數據集包含的 good_weld 圖像比 lack_of_shielding 多 75 倍。
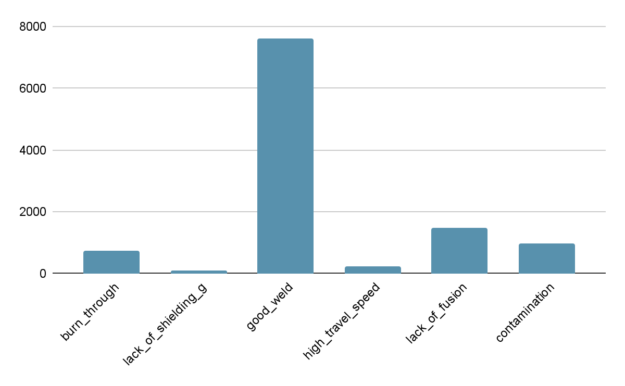
圖 2 TIG 鋼焊接試驗數據集的類別分布 。
使用 NVIDIA TLT
所采用的方法側重于最小化開發時間和調優時間,同時確保精度適用于生產環境。 TLT 與示例筆記本附帶的標準配置文件結合使用。設置、培訓和調整在 8 小時內完成。
我們進行了有關網絡深度和訓練次數的參數掃描。我們觀察到,改變默認的學習率并不能改善結果,因此我們沒有進一步研究這一點,而是將其保留在默認值。經過 30 個階段的訓練,學習率為 0 。 006 ,從 NGC 目錄中獲得的預訓練 ResNet-18 模型獲得了最佳結果。
查看 krygol/304SteelWeldingClassification GitHub repo 中的逐步方法。
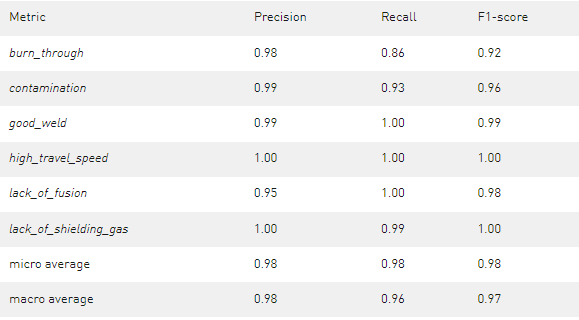
表 2 經過 30 個時期的訓練,學習率為 0 。 006 ,預訓練的 ResNet-18 獲得的結果
獲得的結果在所有班級中都相當好。一些 lack_of_fusion 氣體圖像被錯誤分類為 burn_through 和 污染 圖像。在訓練更深層次的 ResNet50 時也觀察到了這種效果,這更容易將 lack_of_fusion 誤分類為另一個缺陷類。
與原始方法的比較
伯明翰大學的研究人員選擇了不同的人工智能工作流。他們手動準備數據集,通過欠采樣來減少不平衡。他們還將圖像重新縮放到不同的大小,并選擇自定義網絡結構。
他們使用了一個完全連接的神經網絡( Full-con6 ),即具有兩個隱藏層的神經網絡。他們還實現了一個卷積神經網絡( Conv6 ),其中有三個卷積層,每個卷積層后跟一個最大池層和一個完全連接層作為最終隱藏層。他們沒有像 ResNet 那樣使用跳過連接。
TLT 獲得的結果與伯明翰大學研究人員定制實施的結果相比更令人印象深刻。
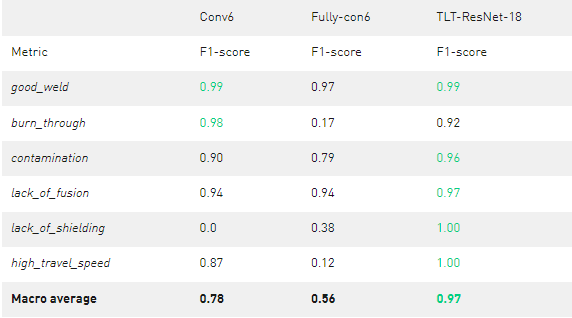
表 3 定制網絡與 TLT ResNet-18 的比較
Conv6 的平均表現較好,宏觀平均 F1 為 0 。 78 ,但在識別 lack_of_shielding 氣體缺陷方面完全失敗 。 con6 的平均表現較差,宏觀平均 F1 為 0 。 56 。 FULL-con6 可以對一些 lack_of_shielding 氣體圖像進行分類,但是 burn_through 和 高速行駛 圖像存在問題。 FULL-con6 和 Conv6 都有明顯的弱點,這將使它們無法獲得生產準備就緒的資格。
每個班級的最佳 F1 成績在表中以綠色標出。如您所見, TLT 訓練的 ResNet-18 模型提供了更好的結果,宏觀平均值為 0 。 97 。
結論
我們在 TLT 方面有著豐富的經驗,總體而言, TLT 是用戶友好且有效的。它設置速度快,易于使用,并且在較短的計算時間內產生可接受的結果。根據我們的經驗,我們相信 TLT 為不是 AI 專家但希望在生產環境中使用 AI 的工程師提供了巨大的優勢。在制造環境中使用 TLT 自動化質量控制不會帶來性能成本,應用程序通常可以與默認設置一起使用,并進行一些小的調整,以超越自定義體系結構。
利用 NVIDIA TLT 快速準確地訓練人工智能模型的探索表明,人工智能在工業過程中具有巨大的潛力。
關于作者
Konstantin Rygol 是 AI 和 HPC 在波士頓存儲和服務器解決方案有限公司的首席工程師。他擁有挪威卑爾根大學的物理碩士學位。在研究原子物理學期間,他對 HPC 和 AI 產生了濃厚的熱情。他現在是 NVIDIA 深度學習培訓中心的講師,致力于將人工智能引入德國市場。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4978瀏覽量
102987 -
服務器
+關注
關注
12文章
9123瀏覽量
85324 -
AI
+關注
關注
87文章
30728瀏覽量
268886
發布評論請先 登錄
相關推薦
GPU是如何訓練AI大模型的
NVIDIA Isaac Sim滿足模型的多樣化訓練需求
NVIDIA AI助力實現更好的癌癥檢測
如何訓練自己的AI大模型
如何訓練ai大模型
ai模型訓練需要什么配置
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型






 工商網監
工商網監
評論