 使用Python構建基于web應用程序的交互式儀表板
使用Python構建基于web應用程序的交互式儀表板
使用 Plotly 的 Dash 、 RAPIDS 和 Data shader ,用戶可以構建 viz 儀表板,既可以呈現 3 億多行的數據集,又可以保持高度的交互性,而無需預先計算聚合。
使用 RAPIDS cuDF 和 Plotly Dash 在 GPU 上進行實時交互式可視化分析
Dash 是來自 Plotly 的一個開源框架,用于使用 Python 構建基于 web 應用程序的交互式儀表板。此外,開放源碼軟件( OSS )庫的 RAPIDS 套件提供了完全在 GPU 上執行端到端數據科學和分析管道的自由。將這兩個項目結合起來,即使在單個 GPU 上,也可以實現對數千兆字節數據集的實時、交互式可視化分析。
此人口普查可視化使用 dashapi 生成圖表及其回調函數。相反, RAPIDS cuDF 被用來加速這些回調,以實現實時聚合和查詢操作。
使用 2010 年人口普查數據的修改版本,結合 2006-2010 年美國社區調查數據(獲得了 fantastic IPUMS.org 的許可),我們將 美國的每一個人 映射到位于相當于一個城市街區的單個點(隨機)。因此,每個人都有與之相關聯的獨特的人口統計屬性,這些屬性支持以前不可能的細粒度過濾和數據發現。我們的 GitHub 上公開了代碼、安裝細節和數據警告。
第 1 部分:可視化的數據準備
雖然不是最新的數據集,但我們選擇使用 2010 年人口普查,因為它具有高地理空間分辨率、大尺寸和可用性。經過一些修改, 3.08 億行× 7 列( int8 型) 的最終數據集足夠大,足以說明 GPU 加速的好處。
Census 2010 SF1 +形狀文件數據
我們決定把重點放在人口普查數據集上;最明顯的選擇是搜索 census.gov 網站,其中包括許多表格文件供下載。最適用的概要文件 1 有一個人口計數部分,其屬性包括性別、年齡、種族等。但是,該數據集是按 普查區水平 列表的,而不是按單個級別(出于各種隱私原因)。結果是 只有 211267 排, 每個街區一個,包括性別、年齡、種族。
我們選擇使用人口普查塊邊界形狀文件來擴展行計數,以使所有塊的人口計數相等。然后,在邊界內隨機分配一個 lat long ,并為每個人創建一個唯一的行。為每個狀態執行此操作的腳本可以在 Plotly-dash-rapids-census-demo 中找到。切換到由 IPUMS NHGIS 站點上的 數據查找工具 提供的更為用戶友好的數據集文件( SF1 和 tiger 邊界文件)可以加快這個過程。
在整個數據挖掘過程中,除了重復檢查每個匹配塊的聚合外,我們還使用我們自己的 cuxfilter 進行快速原型制作和視覺精度檢查。在本例中,為 3.08 億行創建一個交互式地理散點圖非常簡單:
import cuxfilter
import cudf
df = cudf.read_parquet(‘。/data/census_data.parquet/*’)
#create cuxfilter dataframe
cux_df = cuxfilter.DataFrame.from_dataframe(df)
chart0 = cuxfilter.charts.scatter_geo(x=‘x’, y=‘y’)
chart1 = cuxfilter.charts.bar(‘age’)
chart2 = cuxfilter.charts.bar(‘sex’)
d = cux_df.dashboard([chart0, chart1, chart2], layout=cuxfilter.layouts.feature_and_double_base
)
d.show()
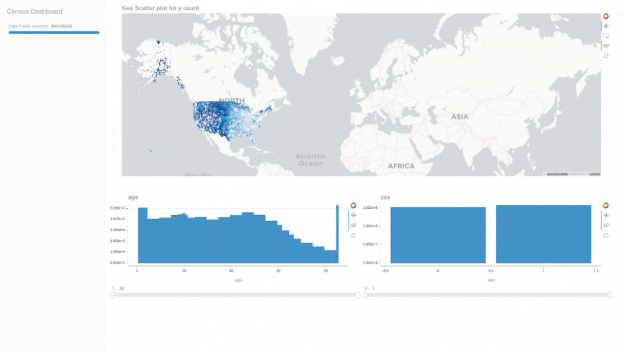
圖 1 : Cuxfilter census dashboard ver 。 1
ACS 2006 – 2010 數據
出于好奇,我們是否可以結合其他有趣的屬性進行交叉篩選,例如收入、教育程度和工人階級,我們添加了 5 年的 2006-2010 年美國社區調查( ACS )數據集。該數據集在普查區塊組上聚合(比普查區塊大一級)。因此,我們決定在塊組上進行聚合,并將其任意分布到每個個體上,同時仍保持塊組級別的聚合值。修改后的數據集包括:
按年齡劃分的性別。
按教育程度分列的 25 歲及以上人口的性別。
16 歲及以上人口過去 12 個月收入(按 2010 年通貨膨脹調整后的美元計算)的性別。
按工人階級分列的 16 歲及以上平民就業人口的性別。
公共列是 Sex ,用于合并所有數據集。然而,雖然這種方法提供了其他有趣的屬性來進行過濾,但結果有幾個注意事項:
在地理位置或單個列上進行交叉過濾將為所有其他列生成準確的計數。
同時交叉過濾多個非地理列不一定會產生真實的計數。
與個人相關的屬性只是統計性的,不能反映真實的人。但是,當匯總到人口普查區塊組級別或更高級別時,它們是準確的。
執行該過程的筆記本可以在 plotly-dash-rapids-census-demo 上找到。最終的數據集如下所示:
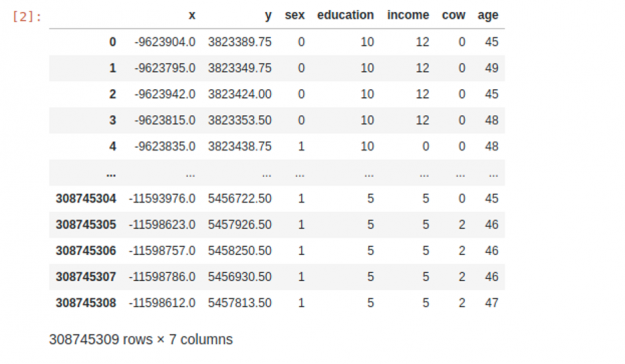
圖 2 :最終普查數據集的 Dataframe 視圖。
下面是一個用于驗證數據集值的快速 cuxfilter 儀表板:
import cuxfilter
import cudf
df = cudf.read_parquet(‘。/data/census_data.parquet/*’)
#create cuxfilter dataframe
cux_df = cuxfilter.DataFrame.from_dataframe(df)
#declare charts
chart0 = cuxfilter.charts.scatter_geo(x=‘x’, y=‘y’)
chart1 = cuxfilter.charts.bar(‘age’)
chart2 = cuxfilter.charts.bar(‘sex’)
chart3 = cuxfilter.charts.bar(‘cow’)
chart4 = cuxfilter.charts.bar(‘income’)
chart5 = cuxfilter.charts.bar(‘education’)
d = cux_df.dashboard(
[chart0, chart1, chart2, chart3, chart4, chart5],
layout=cuxfilter.layouts.feature_and_five_edge,
)
d.show()
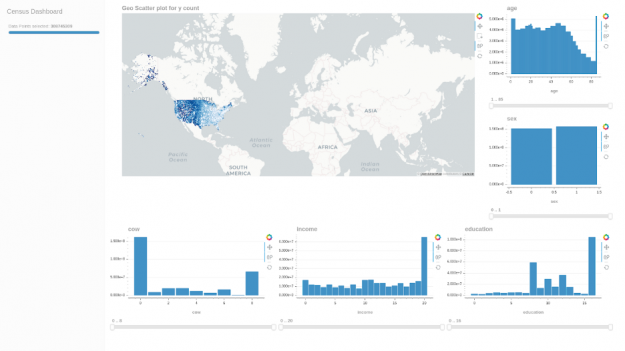
圖 3 : Cuxfilter census dashboard ver 。 2 。
資源鏈接:
最終修改數據集 (~ 2 。 9 GB 焦油拼花文件)
所有數據準備代碼 ( GitHub )
第 2 部分:使用 Plotly Dash 構建交互式儀表板
Dash 支持在儀表板中添加單獨的 Plotly chart 對象,以及使用 Python 為每個對象圖形、選擇和布局單獨回調。例如,儀表板中基于上述數據集的圖表如下:
Scattermapbox :個體的種群分布
此圖表由兩層組成:
Scattermapbox 層。
Datashader 在上面生成了一個輸出圖像。
‘data’: [{
‘type’: ‘scattermapbox’,
‘lat’: lat, ‘lon’: lon,
}],
‘layout’: {
‘mapbox’: {
…
‘layers‘: [{
“sourcetype”: “image”,
“source”: datashader_output_img,
}],
}
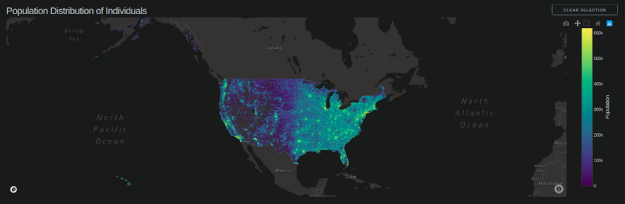
圖 4 :美國人口的破折號數據陰影+地圖框聚集人口過剩計數。
圖表更新回調在以下位置觸發:
“重新布局數據”(向內滾動、向外滾動、鼠標平移)根據縮放級別重新渲染數據陰影圖像,以便分辨率保持不變。
下拉選擇“顏色依據”。
教育、收入、工人階級和年齡圖表的方框選擇。
地圖上的方框選擇。
條形圖:教育程度、收入、工人階級、年齡
‘data’: [
{‘type’: bar, ‘x’: Education, ‘y’: Count},
{‘type’: bar, ‘x’: Education, ‘y’: Count},
{‘type’: bar, ‘x’: Education, ‘y’: Count},
{‘type’: bar, ‘x’: Education, ‘y’: Count}
]
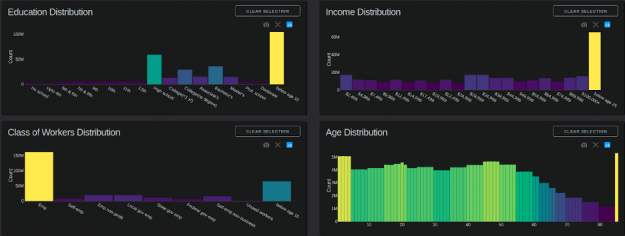
圖 5 :教育、收入、工人階級和年齡直方圖。
圖表更新回調在以下位置觸發:
教育、收入、工人階級和年齡圖表的方框選擇。
地圖上的方框選擇。
下拉選擇“顏色依據”。
GPU 的適用范圍和幫助方式:
此儀表板中的每個圖表都從 GPU 加速到 cuDF :使用 GPU – 加速模式,在 24GB NVIDIA Titan NVIDIA RTX 上進行過濾或縮放交互通常需要 0.2 – 2 秒。在高端 CPU 和 64GB 系統內存上運行,相同的交互通常需要 10-80 秒。通常, cuDF GPU 模式比 pandas CPU 模式快 20 倍以上 根據圖表。 20 倍的不同之處在于將報表儀表板轉換為交互式可視分析應用程序。
數據可視化是一個迭代設計過程
盡管像人口普查中這樣一個記錄良好且可用的數據集,但了解這些數據并制定一個 viz 來有效地與之交互似乎總是比對數據集 MIG 的任何初步研究都要花費更長的時間。
與所有數據可視化一樣,最終結果通常取決于在可用的數據和圖表、您試圖傳達的故事以及您正在通過的媒介(和硬件)之間找到適當的平衡。例如,我們對列格式進行了多次迭代,以確保 GPU 的使用可靠地保持在 24GB 單個 GPU 限制之下,同時仍然允許多個圖表之間的平滑交互。
處理數據是復雜的,而處理大型數據集則更為復雜,但通過將 Plotly Dash 與 RAPIDS 相結合,我們可以提高分析師和數據科學家的能力。這些庫允許用戶在熟悉的環境中工作,并生成更大、更快、更具交互性的可視化應用程序,為開箱即用的生產做好準備—將傳統可視化分析的邊界推向高性能計算領域。
關于作者
Ajay Thorve 是 NVIDIA 的軟件工程師, RAPIDS 組織的可視化團隊的一部分。 Ajay 的背景是全棧開發和數據科學,主要興趣包括 JavaScript / TypeScript 和 Python 。目前, Ajay 在 RAPIDS viz 團隊的工作主要集中在為 cuXfilter 和 node- RAPIDS 項目做出貢獻。
審核編輯:郭婷
-
python
+關注
關注
56文章
4793瀏覽量
84633 -
數據集
+關注
關注
4文章
1208瀏覽量
24691
發布評論請先 登錄
相關推薦
AWTK-WEB 快速入門(2) - JS 應用程序

AWTK-WEB 快速入門(1) - C 語言應用程序
交互式ups和在線UPS不同點,超過限值

使用OpenVINO GenAI API在C++中構建AI應用程序
交互式低延遲音頻解碼器

使用 TPS1HC100-Q1 高效驅動汽車儀表板負載應用說明

華納云:java web和java有什么區別java web和java有什么區別

深耕交互式人工智能領域,聲通科技為用戶提供更加智能的解決方案
使用Redis和Spring?Ai構建rag應用程序

使用Docker部署Go Web應用程序步驟
市場前景向好,交互式人工智能提供商聲通科技迎廣闊發展空間
聲通科技全棧交互式人工智能,助力企業智能化升級
鑒源實驗室 | Web應用程序常見漏洞淺析
web前端開發和前端開發的區別
如何構建linux開發環境和編譯軟件工程、應用程序





 工商網監
工商網監
評論