") 機(jī)器翻譯中細(xì)粒度領(lǐng)域自適應(yīng)的數(shù)據(jù)集和基準(zhǔn)實(shí)驗(yàn)
機(jī)器翻譯中細(xì)粒度領(lǐng)域自適應(yīng)的數(shù)據(jù)集和基準(zhǔn)實(shí)驗(yàn)
01
—
研究動(dòng)機(jī)
近年來,神經(jīng)機(jī)器翻譯(Neural Machine Translation, NMT)研究取得了重大的進(jìn)展。從大規(guī)模平行數(shù)據(jù)中學(xué)習(xí)具有大規(guī)模參數(shù)的通用神經(jīng)機(jī)器翻譯模型已經(jīng)比較成熟。當(dāng)需要處理特定場(chǎng)景中的翻譯任務(wù)時(shí),人們廣泛采用領(lǐng)域自適應(yīng)技術(shù)將一個(gè)通用領(lǐng)域的神經(jīng)機(jī)器翻譯模型遷移到目標(biāo)領(lǐng)域。
然而現(xiàn)有領(lǐng)域自適應(yīng)研究考慮的領(lǐng)域仍比較粗糙,例如法律、醫(yī)療、科技、字幕等領(lǐng)域。事實(shí)上,在這些領(lǐng)域下還存在著非常多的細(xì)粒度領(lǐng)域。例如,科技領(lǐng)域下還包含著自動(dòng)駕駛(Autonomous Vehicles, AV)、AI教育(AI Education, AIE)、實(shí)時(shí)網(wǎng)絡(luò)通信(Real-Time Networks, RTN)、智能手機(jī)(Smart Phone, SP)等等細(xì)粒度領(lǐng)域。即使這些領(lǐng)域都屬于科技領(lǐng)域,但是在這些領(lǐng)域中卻存在著不同的翻譯現(xiàn)象。在詞級(jí)別,以中文“卡”字為例,它在不同的細(xì)粒度科技領(lǐng)域中其實(shí)對(duì)應(yīng)著不同的英文翻譯(表格1)。在句子級(jí)別,在科技領(lǐng)域(FGraDA)和通用領(lǐng)域(CWMT)的分布存在著較大的差異的同時(shí)(圖1的左圖),科技領(lǐng)域內(nèi)部的細(xì)粒度領(lǐng)域的分布仍然存在著一定的差異(圖1的右圖)。
表格1中文“卡”在幾個(gè)科技細(xì)粒度領(lǐng)域?qū)?yīng)的翻譯

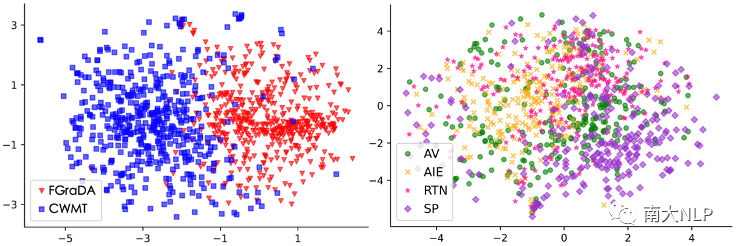
圖1數(shù)據(jù)分布差異可視化分析
細(xì)粒度領(lǐng)域自適應(yīng)問題是一個(gè)重要的實(shí)際應(yīng)用問題。當(dāng)研發(fā)人員需要為某個(gè)特定主題提供翻譯服務(wù)(比如為某個(gè)主題的會(huì)議提供翻譯)時(shí),往往需要在特定的細(xì)粒度領(lǐng)域上取得更好的翻譯性能。在這些場(chǎng)景中,細(xì)粒度領(lǐng)域的專業(yè)性、研發(fā)部署的預(yù)算要求使得人們難以獲取大規(guī)模的細(xì)粒度領(lǐng)域平行數(shù)據(jù),這進(jìn)一步加大了建模細(xì)粒度領(lǐng)域的難度。當(dāng)細(xì)粒度領(lǐng)域建模不準(zhǔn)確時(shí),NMT模型很容易出現(xiàn)翻譯錯(cuò)誤,包括專有名詞錯(cuò)誤、一詞多義錯(cuò)誤、漏譯錯(cuò)誤等(表格2)。為了精確建模細(xì)粒度領(lǐng)域、解決細(xì)粒度領(lǐng)域自適應(yīng)問題,需要思考如何從多樣的非平行數(shù)據(jù)中挖掘有效的目標(biāo)領(lǐng)域信息。
表格2三種典型翻譯錯(cuò)誤及樣例

02
—
貢獻(xiàn)
本文構(gòu)建了一份細(xì)粒度領(lǐng)域自適應(yīng)的中英機(jī)器翻譯數(shù)據(jù)集(FGraDA)。該數(shù)據(jù)集并不是為特定領(lǐng)域的翻譯提供數(shù)據(jù)支持,而是展示了一個(gè)包含多個(gè)細(xì)粒度領(lǐng)域的實(shí)際場(chǎng)景,制作了評(píng)估領(lǐng)域翻譯效果的驗(yàn)證集和測(cè)試集數(shù)據(jù),并提供了實(shí)際應(yīng)用中可能面臨的多種類型的數(shù)據(jù)資源。希望該數(shù)據(jù)集可以支持在細(xì)粒度領(lǐng)域自適應(yīng)方向的研究。
在FGraDA數(shù)據(jù)集上,我們比較了現(xiàn)有的部分自適應(yīng)方法,可以作為后續(xù)研究工作的實(shí)驗(yàn)基準(zhǔn);也分析了現(xiàn)有方法在進(jìn)行細(xì)粒度領(lǐng)域自適應(yīng)時(shí)存在的一些缺陷,希望能為后續(xù)研究工作提供參考。
03
—
數(shù)據(jù)集構(gòu)建
為了模擬真實(shí)場(chǎng)景,我們以四個(gè)有代表性的會(huì)議(CCF-GAIR, GIIS, RTC, Apple-Events)為基礎(chǔ)構(gòu)建FGraDA數(shù)據(jù)集。這四個(gè)會(huì)議對(duì)應(yīng)的領(lǐng)域分別是:自動(dòng)駕駛、AI教育、實(shí)時(shí)網(wǎng)絡(luò)通信、智能手機(jī),這些領(lǐng)域都屬于科技領(lǐng)域下的細(xì)分領(lǐng)域。我們?yōu)槊總€(gè)領(lǐng)域配備了詞典資源、wiki資源、驗(yàn)證集、測(cè)試集(數(shù)據(jù)規(guī)模如表格3所示)。詞典資源和wiki資源作為獲取成本較低的非平行資源,包含著豐富的領(lǐng)域信息,用于細(xì)粒度領(lǐng)域建模及自適應(yīng)。驗(yàn)證集和測(cè)試集則用于評(píng)估自適應(yīng)效果。下面將具體介紹這些資源的構(gòu)建過程。
表格3FGraDA數(shù)據(jù)集各領(lǐng)域數(shù)據(jù)規(guī)模報(bào)告

詞典相比于平行句對(duì)是一種獲取成本更低的資源。與此同時(shí),詞典資源可以提供領(lǐng)域詞語的翻譯信息,這對(duì)于處理細(xì)粒度領(lǐng)域翻譯任務(wù)是非常有幫助的。因此,我們?yōu)槊總€(gè)領(lǐng)域人工標(biāo)注了一定規(guī)模的雙語詞典資源。表格4中展示了一些我們標(biāo)注的詞典條目示例。標(biāo)注完成后,我們請(qǐng)語言專家確認(rèn)了詞典的準(zhǔn)確性和可靠性。
表格4詞典條目示例

Wiki資源是機(jī)器翻譯研究中的一種重要的可利用資源。鑒于領(lǐng)域詞典中包含大量的領(lǐng)域詞語,我們利用這些英文領(lǐng)域詞語抽取細(xì)粒度領(lǐng)域相關(guān)的wiki頁面。具體來說,我們首先抽取標(biāo)題中包含領(lǐng)域詞語的wiki頁面作為種子頁面(seed page)。這些種子頁面中的內(nèi)容是與細(xì)粒度領(lǐng)域高度相關(guān)的,并且這些頁面中的部分內(nèi)容還會(huì)鏈接到其他相關(guān)頁面(如圖2所示)。因此我們利用這種天然存在的鏈接關(guān)系,收集種子頁面所鏈接到的一跳頁面(one-hop-link page),進(jìn)一步擴(kuò)充wiki資源。最終,抽取出的種子頁面和一跳頁面共同構(gòu)成了細(xì)粒度領(lǐng)域相關(guān)的wiki資源(數(shù)據(jù)規(guī)模如表格5所示)。該資源不僅包含了大量的單語文本,還包含了諸如鏈接關(guān)系的結(jié)構(gòu)知識(shí),具有非常大的利用價(jià)值。
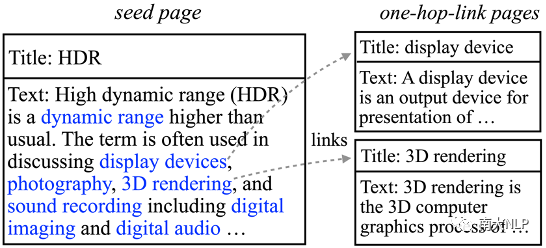
圖2Wiki資源示例
表格5Wiki資源數(shù)據(jù)規(guī)模報(bào)告
最后,為了評(píng)估細(xì)粒度領(lǐng)域自適應(yīng)效果,我們?yōu)楦鱾€(gè)細(xì)粒度領(lǐng)域標(biāo)注了平行數(shù)據(jù)作為驗(yàn)證集和測(cè)試集。我們從上面提到的四個(gè)會(huì)議上收集了70個(gè)小時(shí)的錄音,然后使用內(nèi)部工具將其轉(zhuǎn)錄為文本。隨后我們進(jìn)行了數(shù)據(jù)清洗和數(shù)據(jù)脫敏,去除了文本語料中領(lǐng)域無關(guān)的句子和涉及隱私的人名、公司名。最終,經(jīng)過語言專家標(biāo)注,一共在四個(gè)領(lǐng)域上得到了4767條中英平行句對(duì)。我們把每個(gè)領(lǐng)域的平行數(shù)據(jù)分為兩部分:200條作為驗(yàn)證集,剩下的作為測(cè)試集。我們可以看到,僅僅是收集少量平行數(shù)據(jù)用于評(píng)估就需要花費(fèi)大量的人力、物力代價(jià)。在這種情況下,期望收集更多的平行數(shù)據(jù)用于自適應(yīng)學(xué)習(xí)是不現(xiàn)實(shí)的,因此本數(shù)據(jù)集也沒有提供這種資源。
04
—
基線結(jié)果
我們?cè)贔GraDA數(shù)據(jù)集上比較了部分現(xiàn)有自適應(yīng)方法(實(shí)驗(yàn)結(jié)果如表格6所示)。實(shí)驗(yàn)結(jié)果表明現(xiàn)有方法能夠利用數(shù)據(jù)集中提供的資源取得一定的提升,并且綜合使用詞典資源和wiki資源取得的提升最多。但是,這些方法在部分領(lǐng)域上的翻譯性能仍然較弱。為了進(jìn)一步對(duì)自適應(yīng)效果進(jìn)行分析,我們統(tǒng)計(jì)了表現(xiàn)最好的基線方法在測(cè)試集上的句子級(jí)別BLEU的分布情況(如圖3所示)。分布情況顯示自適應(yīng)模型在大部分句子上的翻譯狀況還不理想(BLEU分?jǐn)?shù)低于20),這也表明細(xì)粒度領(lǐng)域的翻譯效果仍然有待提升。
表格6基線方法在細(xì)粒度領(lǐng)域上的翻譯性能(BLEU)
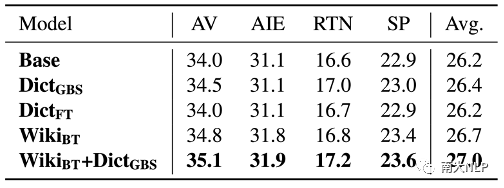
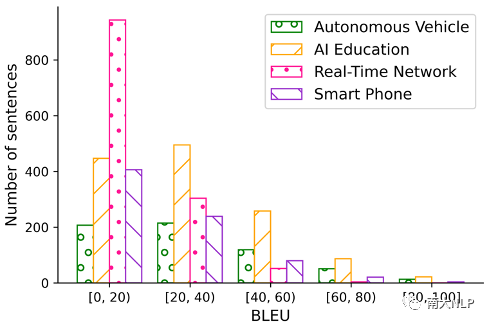
圖3句子級(jí)別BLEU分布情況
05
—
有待解決的挑戰(zhàn)
在詞典資源方面,我們發(fā)現(xiàn)現(xiàn)有的領(lǐng)域自適應(yīng)方法還無法充分利用這些詞語翻譯知識(shí)。我們?cè)跍y(cè)試集上統(tǒng)計(jì)了領(lǐng)域詞典條目的翻譯準(zhǔn)確率(實(shí)驗(yàn)結(jié)果如表格7所示)。實(shí)驗(yàn)結(jié)果表明,即使采用詞約束解碼算法Grid Beam Search(GBS),自適應(yīng)模型也無法100%正確翻譯出領(lǐng)域詞典中的領(lǐng)域詞語。為了進(jìn)一步分析在細(xì)粒度領(lǐng)域自適應(yīng)中使用詞典資源的挑戰(zhàn),我們嘗試了調(diào)節(jié)GBS算法中的權(quán)重超參數(shù)(實(shí)驗(yàn)結(jié)果如圖4所示)。實(shí)驗(yàn)結(jié)果表明盡管我們可以調(diào)節(jié)GBS算法中的權(quán)重超參數(shù)強(qiáng)制模型翻譯出更多領(lǐng)域詞語,但是翻譯結(jié)果的BLEU分?jǐn)?shù)會(huì)大幅下降。這說明,簡單地通過詞約束解碼的方式并不能翻譯好領(lǐng)域詞語,如何更好地利用領(lǐng)域詞典仍然有待探索。
表格7領(lǐng)域詞典條目翻譯準(zhǔn)確率(%)
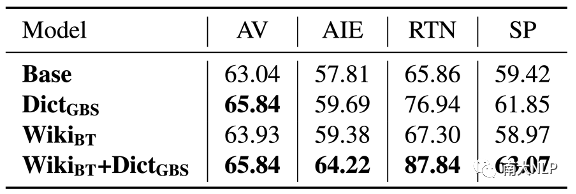
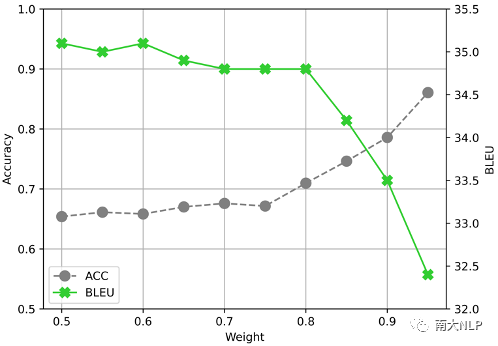
圖4不同權(quán)重下詞典詞語翻譯準(zhǔn)確率和BLEU分?jǐn)?shù)的變化情況
在wiki資源方面,現(xiàn)有的領(lǐng)域自適應(yīng)方法主要將wiki頁面中包含的文本作為單語數(shù)據(jù)使用,忽視了wiki頁面中包含的各種結(jié)構(gòu)化知識(shí)。這些知識(shí)對(duì)于理解領(lǐng)域詞語語義可能會(huì)起到非常重要的作用。我們?cè)谶@里列舉出兩種重要的結(jié)構(gòu)化知識(shí):(1)wiki頁面正文的第一句話通常是標(biāo)題的定義。以圖2中的頁面標(biāo)題“HDR”為例,正文的第一句話“High dynamic range (HDR) is a dynamic range higher than usual”,這是“HDR”的定義,可以幫助理解HDR的含義。(2)當(dāng)前wiki頁面中鏈接到其他wiki頁面的詞語往往和當(dāng)前wiki頁面的標(biāo)題是高度相關(guān)的。同樣以圖2中的頁面標(biāo)題“HDR”為例,該頁面中包含的“dynamic range”,“display devices”,“photography”等詞語都是和“HDR”高度相關(guān)的,也可以幫助理解“HDR”的含義。
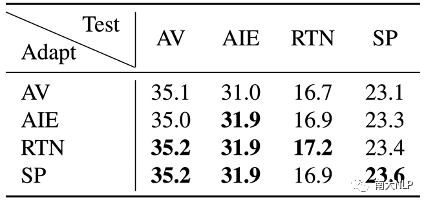
在領(lǐng)域?qū)蛹?jí)方面,現(xiàn)有的領(lǐng)域自適應(yīng)方法只考慮使用目標(biāo)領(lǐng)域?qū)?yīng)的領(lǐng)域資源進(jìn)行領(lǐng)域自適應(yīng),忽略了利用相近細(xì)粒度領(lǐng)域中的資源。為了量化細(xì)粒度領(lǐng)域之間的近似關(guān)系,我們?cè)u(píng)估了適應(yīng)到各個(gè)領(lǐng)域的模型在另外三個(gè)領(lǐng)域的翻譯性能(實(shí)驗(yàn)結(jié)果如表格8所示)。從翻譯性能的差異可以看出細(xì)粒度領(lǐng)域之間有的差距較大,有的差距較小。如何利用相近細(xì)粒度領(lǐng)域中的資源輔助當(dāng)前目標(biāo)細(xì)粒度領(lǐng)域建模,以及如何利用粗細(xì)粒度領(lǐng)域間的層級(jí)關(guān)系仍然是值得探究的問題。
表格8遷移到不同細(xì)粒度領(lǐng)域上的模型翻譯性能對(duì)比(BLEU)
06
—
總結(jié)
本文從實(shí)際問題出發(fā),構(gòu)建了細(xì)粒度領(lǐng)域自適應(yīng)機(jī)器翻譯數(shù)據(jù)集FGraDA。我們?cè)贔GraDA 數(shù)據(jù)集對(duì)比了現(xiàn)有的部分領(lǐng)域自適應(yīng)方法,發(fā)現(xiàn)細(xì)粒度領(lǐng)域的翻譯效果仍然有待提升。進(jìn)一步的分析顯示FGraDA數(shù)據(jù)集中提供的多樣非平行資源中仍然存在著非常多有待挖掘的、對(duì)自適應(yīng)有益的信息。如何從各種不同資源中挖掘、利用這些信息建模細(xì)粒度領(lǐng)域,實(shí)現(xiàn)細(xì)粒度領(lǐng)域自適應(yīng)是一個(gè)有待研究的重要課題。
審核編輯 :李倩
-
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14880 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24689
原文標(biāo)題:LREC'22 | 機(jī)器翻譯中細(xì)粒度領(lǐng)域自適應(yīng)的數(shù)據(jù)集和基準(zhǔn)實(shí)驗(yàn)
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
空間光調(diào)制器自適應(yīng)激光光束整形
Perforce Helix Core通過ISO 26262認(rèn)證!為汽車軟件開發(fā)團(tuán)隊(duì)提供無限可擴(kuò)展性、細(xì)粒度安全性、文件快速訪問等

如何設(shè)定機(jī)器人語義地圖的細(xì)粒度級(jí)別
步進(jìn)電機(jī)如何自適應(yīng)控制?步進(jìn)電機(jī)如何細(xì)分驅(qū)動(dòng)控制?
偏置備用運(yùn)行中自適應(yīng)定時(shí)控制裝置的分析與風(fēng)險(xiǎn)評(píng)估

如何在自己的固件中增加wifi自適應(yīng)性相關(guān)功能,以通過wifi自適應(yīng)認(rèn)證測(cè)試?
如何理解機(jī)器學(xué)習(xí)中的訓(xùn)練集、驗(yàn)證集和測(cè)試集
杭州中天微系統(tǒng):自適應(yīng)時(shí)鐘頻率控制領(lǐng)域創(chuàng)新技術(shù)獲碩果
什么是自適應(yīng)光學(xué)?自適應(yīng)光學(xué)原理與方法的發(fā)展
TCP協(xié)議技術(shù)之自適應(yīng)重傳
語音數(shù)據(jù)集:智能駕駛中車內(nèi)語音識(shí)別技術(shù)的基石
ICLR 2024 清華/新國大/澳門大學(xué)提出一模通吃的多粒度圖文組合檢索MUG:通過不確定性建模,兩行代碼完成部署

Spring Boot和飛騰派融合構(gòu)建的農(nóng)業(yè)物聯(lián)網(wǎng)系統(tǒng)-改進(jìn)自適應(yīng)加權(quán)融合算法
創(chuàng)想焊縫跟蹤系統(tǒng)在爾必地機(jī)器人自適應(yīng)焊接中的應(yīng)用案例






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論