 利用Apache Spark和RAPIDS Apache加速Spark實踐
利用Apache Spark和RAPIDS Apache加速Spark實踐
這是描述預測客戶流失的端到端藍圖的系列文章的第三部分。在前幾期文章中,我們已經討論了機器學習系統的一些挑戰,這些挑戰直到您投入生產時才會出現:在 第一期付款 中,我們介紹了我們的用例,并描述了一個加速的數據聯合管道;在 第二期 中,我們展示了高級分析如何適應機器學習生命周期的其余部分。
在第三期文章中,我們將介紹應用程序的分析和聯合組件,并解釋如何充分利用 Apache Spark 和 RAPIDS Apache 加速器 Spark 的一些最佳實踐。
架構( Architecture )評審
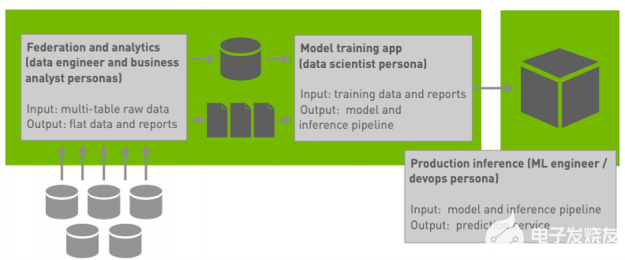
圖 1 :我們的藍圖架構的高級概述。
回想一下,我們的 blueprint 應用程序(圖 1 )包括一個聯邦工作負載和一對分析工作負載。
聯合工作負載 生成了一個關于每個客戶的非規范化寬數據表,這些數據來自于五個與客戶賬戶不同方面相關的規范化觀察表的數據匯總。
第一次分析工作量 為每個特性生成一個機器可讀的值分布和域的摘要報告。
第二次分析工作量 生成一系列關于客戶結果的說明性業務報告 我們的第一期 包含有關聯合工作負載的其他詳細信息, 我們的第二期 包含有關分析工作負載的其他詳細信息。
我們將這三個工作負載作為一個具有多個階段的 Spark 應用程序來實現:
應用程序將 HDFS 中多個表(存儲為拼花文件)的原始數據聯合到一個寬表中。
因為寬表比原始數據小得多,所以應用程序然后通過合并到較少的分區并將數值轉換為適合 ML 模型訓練的類型來重新格式化寬輸出。此階段的輸出是 ML 模型訓練的源數據。
然后,應用程序針對合并和轉換的寬表運行分析工作負載,首先生成機器可讀的摘要報告,然后生成匯總和數據立方體報告的集合。
性能注意事項
并行執行
50 多年來,提高并行執行的適用性一直是計算機系統高性能最重要的考慮因素之一 ( 我們有點武斷地選擇在 1967 年確定 托馬蘇洛算法 的開發,它為無處不在的超標量處理奠定了基礎,因為在這一點上,對并行性的關注變得實用而不僅僅是理論上的。)在分析員、數據科學家、數據和 ML 工程師以及應用程序開發人員的日常工作中,對并行性的關注通常表現為以下幾種方式之一;我們現在來看看。
向外擴展時,在集群上執行工作
如果您使用的是橫向擴展框架,請盡可能在集群上而不是在單個節點上執行工作。在 Spark 的情況下,這意味著在執行器上執行 Spark 作業中的代碼,而不是在驅動程序上執行串行代碼。 一般來說,在驅動程序中使用 Spark 的 API 而不是宿主語言代碼將使您獲得大部分的成功,但是您需要確保所使用的 Spark API 實際上是在執行器上并行執行的。
操作集合,而不是元素;在列上,而不是行上
開發并行性和提高性能的一般最佳實踐是使用一次對集合執行操作的專用庫,而不是一次對元素執行操作。在 Spark 的情況下,這意味著使用數據幀和列操作,而不是迭代 rdd 分區中的記錄;在 Python 數據生態系統和 RAPIDS 。 ai 中,這意味著使用在單個庫調用中對整個數組和矩陣進行操作的 矢量化操作 ,而不是在 Python 中使用顯式循環。最關鍵的是,這兩種方法也適用于 GPU 加速。
分攤 I / O 和數據加載的成本
I / O 和數據加載成本很高,因此在盡可能多的并行操作中分攤它們的成本是有意義的。 我們可以通過直接降低數據傳輸成本和在數據加載后盡可能多地處理數據來提高性能。在 Spark 中,這意味著使用列格式,在從穩定存儲導入時只過濾一次關系,并在 I / O 或無序操作之間執行盡可能多的工作。
通過抽象提高性能
一般來說,提高分析師和開發人員在應用程序、查詢和報表中使用的抽象級別,可以讓運行時和框架找到開發人員沒有(或無法)預料到的并行執行機會。
使用 Spark 的數據幀
例如,在 Spark 中使用數據幀并主要針對高級數據幀 API 進行開發有許多好處,包括執行速度更快、查詢的語義保持優化、對存儲和 I / O 的需求減少,以及相對于使用基于 RDD 的代碼顯著改善了內存占用。但除了這些好處之外,還有一個更深層次的優勢:因為數據幀接口是高級的,而且 Spark 允許插件改變查詢優化器的行為,所以 RAPIDS Apache 加速器 Spark 有可能用在 GPU 上運行的等效但實際上更快的操作替換某些數據幀操作。
透明加速 Spark 查詢
用插件替換 Spark 的查詢規劃器的一些功能是抽象能力的一個特別引人注目的例子:在能夠在 GPU 上運行 Spark 查詢之前幾年編寫的應用程序仍然可以通過使用 Spark 3 。 1 和 RAPIDS 加速器來利用 GPU 加速。
保持清晰的抽象
盡管使用新的運行時加速未修改的應用程序的潛力是針對高級抽象進行開發的一個主要優勢,但實際上,對于開發團隊來說,維護清晰的抽象很少比按時交付工作項目更重要。由于多種原因,抽象背后的細節常常會泄漏到產品代碼中;雖然這可能會引入技術債務并產生無數工程后果,但它也會限制高級運行時的適用性,以優化干凈地使用抽象的程序。
考慮適合 GPU 加速的操作
為了從 Spark 中獲得最大的收益,在圍繞 Spark 的數據幀抽象的應用程序中償還技術債務(例如,通過將部分查詢實現為 RDD 操作)是有意義的。 不過,為了充分利用先進的基礎設施,在不破壞抽象的情況下考慮執行環境的細節通常是有意義的。 為了從 NVIDIA GPU 和 RAPIDS Apache 加速器 Spark 獲得盡可能好的性能,首先要確保您的代碼不會圍繞抽象工作,然后考慮或多或少適合 GPU 執行的類型和操作,這樣您就可以確保盡可能多的應用程序在 GPU 上運行。下面我們將看到一些這樣的例子。
類型和操作
并不是每一個操作都能被 GPU 加速。當有疑問時,運行作業時將 spark.rapids.sql.explain 設置為 NOT_ON_GPU 并檢查記錄到標準輸出的解釋總是有意義的。在本節中,我們將指出一些常見的陷阱,包括需要配置支持的十進制算法和操作。
小心十進制算術
十進制計算機算法支持高達給定精度限制的精確運算,可以避免和檢測溢出,并像人類在執行鉛筆和紙張計算時那樣舍入數字。盡管十進制算法是許多數據處理系統(尤其是金融數據)的重要組成部分,但它對分析系統提出了特殊的挑戰。為了避免溢出,十進制運算的結果必須擴大到包括所有可能的結果;在結果比系統特定限制更寬的情況下,系統必須檢測溢出。在 cpu 上使用 Spark 的情況下,這涉及將操作委托給 Java 標準庫中的 BigDecimal 類 ,并且精度限制為 38 位十進制數字或 128 位。 Apache 的 RAPIDS 加速器 Spark 目前可以加速計算多達 18 位或 64 位的十進制值。
我們已經評估了客戶流失藍圖的兩種配置:一種使用浮點值表示貨幣金額(如我們在 第一期 中所描述的那樣),另一種使用十進制值表示貨幣金額(這是我們當前報告的性能數字所針對的配置)。由于其語義和健壯性,十進制算法比浮點算法成本更高,但只要所涉及的所有十進制類型都在 64 位以內,就可以通過 RAPIDS 加速器插件來加速。
配置 RAPIDS 加速器以啟用更多操作
RAPIDS 加速器對于在 GPU 上執行 MIG ht 表現出較差性能或返回與基于 CPU 的加速器略有不同的結果的操作持保守態度。因此,一些可以加速的操作在默認情況下可能不會加速,許多實際應用程序需要使這些操作能夠看到最佳性能。我們在 我們的第一期 中看到了這種現象的一個例子,其中我們必須通過將 true 設置為 true ,在 Spark 配置中顯式啟用浮點聚合操作。類似地,當我們將工作負載配置為使用十進制算法時,我們需要通過將 spark.rapids.sql.decimalType.enabled 設置為 true 來啟用十進制加速。
插件文檔 列出了配置支持或不支持的操作,以及在默認情況下啟用或禁用某些操作的原因。除了浮點聚合和十進制支持之外,生產 Spark 工作負載極有可能受益于以下幾類操作:
鑄造作業 ,特別是從字符串到日期或數字類型,或從浮點類型到十進制類型。
某些 Unicode 字符不支持字符串大小寫(例如“ SELECT UPPER(name) FROM EMPLOYEES ”),更改大小寫也會更改字符寬度(以字節為單位),但許多應用程序不使用此類字符[或者通過將 Spark 。 RAPIDS 。 sql 。 compatibleops 。 enabled 設置為 true 來啟用它們和其他幾個。
從 CSV 文件中讀取特定類型;雖然插件( Spark 。 RAPIDS 。 sql 。 format 。 CSV 。 enabled )中當前默認啟用了讀取 CSV 文件,但讀取某些類型的無效值(尤其是數字類型、日期和小數)在 GPU 和 CPU 上會有不同的行為,因此需要單獨啟用每個類型的讀取。
加快從 CSV 文件接收數據
CSV 閱讀需要額外的注意:它是昂貴的,加速它可以提高許多工作的性能。然而,由于在 RAPIDS 加速器下讀取 CSV 的行為可能與在 cpu 上執行時的 Spark 行為不同,并且由于實際 CSV 文件質量的巨大動態范圍,因此驗證在 GPU 上讀取 CSV 文件的結果尤為重要。一個快速但有價值的健全性檢查是確保在 GPU 上讀取 CSV 文件返回的空值數與在 CPU 上讀取相同的文件返回的空值數相同。當然,如果可能的話,使用像 Parquet 或 ORC 這樣的自文檔結構化輸入格式而不是 CSV 有很多好處。
避免查詢優化的意外后果
RAPIDS 加速器將 物理查詢計劃 轉換為將某些操作符委派給 GPU 。 但是,在 Spark 生成物理計劃時,它已經對邏輯計劃執行了幾個轉換,這可能涉及重新排序操作。 因此,開發人員或分析人員聲明的接近查詢或數據幀操作末尾的操作可能會從查詢計劃的葉移向根。
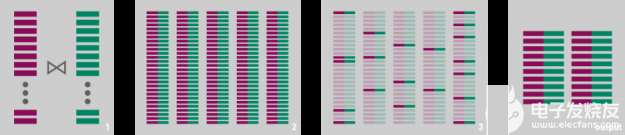
圖 2 : 一種執行數據幀查詢的描述,該查詢連接兩個數據幀,然后過濾結果。 如果謂詞具有足夠的選擇性,則大多數輸出元組將被丟棄。
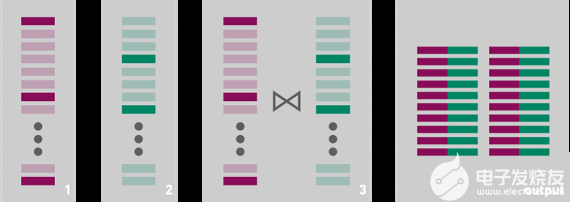
圖 3 : 執行數據幀查詢的描述,在連接結果之前過濾兩個輸入關系。 如果可以對每個輸入關系獨立地計算謂詞,那么此查詢執行將產生與圖 2 中的查詢執行相同的結果,效率將大大提高。
一般來說,這種轉換可以提高性能。 例如,考慮一個查詢,該查詢連接兩個數據幀,然后過濾結果: 如果可能的話,在執行連接之前執行過濾器通常會更有效。 這樣做將減少連接的基數,消除最終不必要的比較,減少內存壓力,甚至可能減少連接中需要考慮的數據幀分區的數量。 然而,這種優化可能會產生違反直覺的后果: 如果向查詢計劃的根移動的操作僅在 CPU 上受支持,或者如果它生成的值的類型在 GPU 上不受支持,則主動查詢重新排序可能會對 GPU 的性能產生負面影響。 當這種情況發生時,在 CPU 上執行的查詢計劃的百分比可能比嚴格需要的要大。 您通常可以解決這個問題,并通過將查詢劃分為兩個分別執行的部分來提高性能,從而強制在查詢計劃的葉子附近僅 CPU 的操作僅在原始查詢的可加速部分在 GPU 上運行之后執行。
結論
在第三期文章中,我們詳細介紹了如何充分利用 Apache Spark 和 Apache RAPIDS 加速器 Spark 。 大多數團隊都會通過干凈地使用 Spark 的數據幀抽象來實現最大的好處。 但是,一些應用程序可能會受益于細微的調整,特別是考慮 RAPIDS 加速器的執行模型并避免不受支持的操作的保留語義的代碼更改。 未來幾期文章將討論數據科學發現工作流和機器學習生命周期的其余部分。
關于作者
William Benton在NVIDIA數據科學產品小組工作,他熱衷于使機器學習從業人員可以輕松地從先進的基礎架構中受益,并使組織可以管理機器學習系統。 在擔任過以前的職務時,他定義了與數據科學和機器學習有關的產品戰略和專業服務產品,領導了數據科學家和工程師團隊,并為與數據,機器學習和分布式系統有關的開源社區做出了貢獻。
審核編輯:郭婷
-
加速器
+關注
關注
2文章
796瀏覽量
37840 -
NVIDIA
+關注
關注
14文章
4978瀏覽量
102989 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565
發布評論請先 登錄
相關推薦
spark為什么比mapreduce快?
廣汽能源與泰國Spark EV簽訂合作框架協議
spark運行的基本流程
Spark基于DPU的Native引擎算子卸載方案

關于Spark的從0實現30s內實時監控指標計算
淺談存內計算生態環境搭建以及軟件開發
云服務器apache如何配置解析php文件?
如何利用DPU加速Spark大數據處理? | 總結篇
Spark基于DPU Snappy壓縮算法的異構加速方案
RDMA技術在Apache Spark中的應用

基于DPU和HADOS-RACE加速Spark 3.x
Apache服務器和Nginx服務器
Apache Doris聚合函數源碼解析
米哈游大數據云原生實踐






 工商網監
工商網監
評論