 使用人工智能開發最精確的零售預測解決方案
使用人工智能開發最精確的零售預測解決方案
Jupyter 筆記本使用 RAPIDS 的最佳實踐
一家全球領先的零售商已經投入巨資成為 世界上最具競爭力的科技公司之一。
準確 而且及時 需要 預測數以百萬計的商品組合對服務至關重要 他們的 每周有數百萬的客戶。他們成功預測的關鍵是 RAPIDS ,一個 GPU 加速庫的開源套件 RAPIDS 幫助他們撕破了大規模數據,并將預測精度提高了幾個百分點——它現在在減少基礎設施 GPU 占用的基礎上運行速度快了幾個數量級。 這使他們能夠對購物者的趨勢作出實時反應,并有更多的正確的產品上架,減少缺貨情況,并增加銷售。
使用 RAPIDS ,數據從業者可以加速 NVIDIA GPU 上的管道,將數據操作(包括數據加載、處理和培訓)從幾天減少到幾分鐘。 RAPIDS 通過構建 論與整合 流行的 分析生態系統,如 PyData 公司 和 Apache Spark ,使用戶能夠立即看到好處。 與類似的基于 CPU 的實現相比, RAPIDS 提供 50 倍的性能 改進 對于經典的數據分析和機器學習( ML )過程 按比例 這大大降低了大型數據科學操作的總體擁有成本( TCO )。
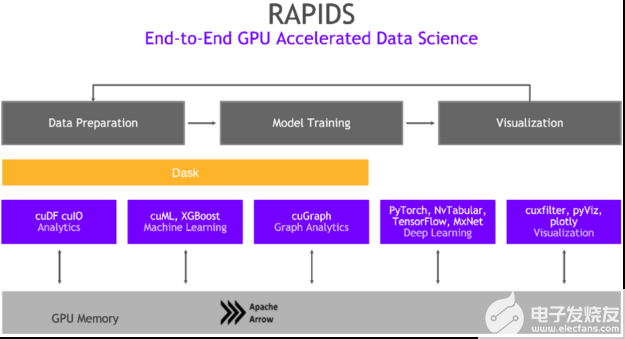
圖 1 。帶有 GPU 和 RAPIDS 的數據科學管道 。
為了學習和解決復雜的數據科學和人工智能挑戰, 零售業領導者經常利用一個叫做“ Kaggle 競賽 ”。 Kaggle 是一個平臺,匯集了數據科學家和其他開發人員,以解決公司發布的具有挑戰性和有趣的問題。 事實上,在過去的一年里,已經有超過 20 個解決零售業挑戰的競賽。
利用 RAPIDS 和最佳實踐進行預測競賽, NVIDIA Kaggle 大師 Kazuki Onodera 在啟動市場籃分析卡格爾競賽中獲得第二名,采用復雜特征工程、梯度增強樹模型和比賽 F1 評價指標的特殊建模。 一路上,我們記錄了最佳實踐 對于 ETL ,特征工程, 建筑 以及為建立基于人工智能的零售預測定制最佳模型 解決方案。
這篇博文將引導讀者了解 Kaggle 競賽 解釋提高零售業預測的數據科學最佳實踐。 具體來說,這篇博客文章解釋了 Instacart 市場籃子分析 Kaggle 的競爭目標,介紹了 RAPIDS ,然后提供了一個工作流,展示了如何直觀地瀏覽數據、開發功能、訓練模型和運行預測。然后,本文將深入探討一些先進的特征工程技術,包括模型可解釋性和超參數優化( HPO )。
要更詳細地了解該方法,請參閱小野寺五典( Kazuki Onodera )對 Medium.com 的精彩訪談。
在 NVIDIA GTC 2021 年 加入 Paul Hendricks ,在那里他主持了一個關于 使用 NVIDIA RAPIDS 數據科學庫進行零售預測的 ETL 、特征工程和模型開發的最佳實踐 的會議。
訪問此 Jupyter 筆記本 ,我們將在 Instacart 市場籃子分析 Kaggle 競爭的背景下分享這些 GPU 加速預測的最佳實踐。
預測挑戰
Instacart 市場籃子分析競爭面臨挑戰 Kaggle 預測哪種食品是消費者會在何時再次購買。舉例來說,想象一下,當你用完牛奶的時候,或者你知道的時候,牛奶已經準備好要加入你的購物車了 是的 是時候再儲備你最喜歡的冰淇淋了。
這種對理解時態行為模式的關注使得這個問題與標準項目推薦有很大的不同,標準項目推薦要求用戶 需要 而且偏好通常被認為在短時間內是相對恒定的。而 Netflix MIG 如果你想看另一部電影,那就沒問題了 喜歡 你剛才看的那個, 是的 不太清楚的是,如果你昨天買的話,你會想重新訂購一批新鮮的杏仁黃油或衛生紙。
問題概述
這項競爭的目標是預測雜貨店的再訂購:給定用戶的購買歷史(一組訂單,以及每個訂單中購買的產品),他們以前購買的哪些產品將在下一個訂單中重新購買?
這個問題與一般的推薦問題有點不同,在一般的推薦問題中,我們經常面臨一個冷啟動的問題,即為新用戶和需要的新項目進行預測 我們已經 從未見過。例如,電影網站可能需要推薦新電影并為新用戶提供建議。
這個問題的連續性和基于時間的性質也讓它變得有趣:我們如何考慮用戶上次購買商品以來的時間?用戶是否有特定的購買模式,他們是否在一天的不同時間購買不同種類的商品?
首先, 我們會的 首先加載一些我們將在本筆記本中使用的模塊,并為任何模塊設置隨機種子 隨機數發生器 我們會用的。
RAPIDS 概述
數據科學家通常處理兩種類型的數據:非結構化數據和結構化數據。非結構化數據通常以文本、圖像或視頻的形式出現。結構化數據——顧名思義——以結構化的形式出現,通常由表或 CSV 表示。我們將把大部分教程的重點放在處理這些類型的數據上。
Python 生態系統中有許多用于結構化表格數據的工具,但很少有工具像 pandas 那樣被廣泛使用 pandas 表示表中的數據,允許數據科學家操作數據以執行許多有用的操作,如過濾、轉換、聚合、合并、可視化等等。
pandas 非常適合處理適合系統內存的小型數據集。然而,數據集越來越大,數據科學家正在處理越來越復雜的工作負載,因此需要加速計算。
cuDF 是 RAPIDS 生態系統中的一個包,使數據科學家能夠輕松地將現有的 pandas 工作流程從 CPU 遷移到 GPU,計算可以利用 GPU 提供的巨大平行性。
熟悉數據
本次競爭的數據集包含多個文件,這些文件捕獲了 Instacart 用戶一段時間內的訂單,競爭的目標是預測用戶是否會重新訂購產品,特別是這些客戶將重新訂購哪些產品。從 Kaggle 數據描述中,我們看到我們有超過 300 萬份雜貨訂單,客戶群超過 200000 名 Instacart 用戶。對于每個用戶,我們提供 4 到 100 個訂單,每個訂單中購買的產品的順序,以及他們訂單的時間和訂單之間時間的相對度量。 還提供了 下訂單當天的星期和小時,以及訂單之間的相對時間度量。
我們的 產品, 過道,和 部門 數據集由關于我們的產品、通道和 部門 分別。每個數據集(產品、通道、部門和訂單等)都有該數據集中每個實體的唯一標識符映射,例如訂單 id 表示訂單數據集中的唯一訂單,產品 id 表示產品數據集中的唯一產品,稍后我們將使用這些唯一標識符將所有這些單獨的數據集組合成一個一致的視圖,用于探索性數據分析、特征工程和建模。
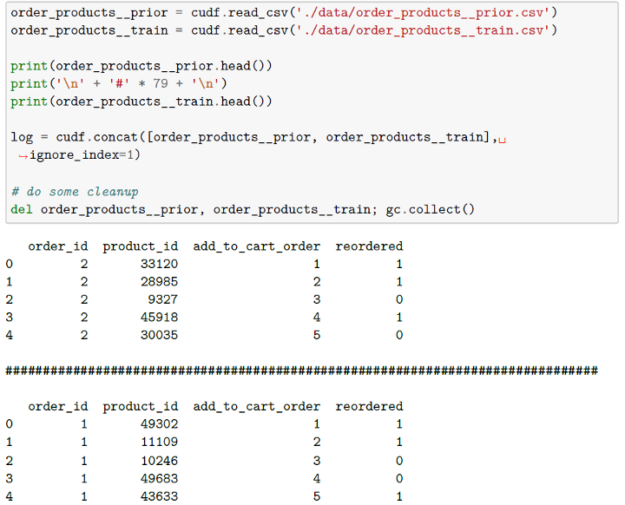
下面,我們將讀取數據并使用 cuDF 檢查不同的表。

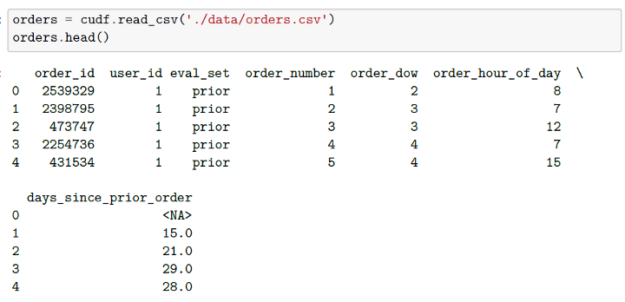
另外, 我們會的 讀入我們的 [orders] 數據集。 第一個 表示 訂單所屬的集合(之前、訓練、測試)。 附加 文件指定每個訂單中購買的產品。 同樣,從數據的 Kaggle 描述中,我們可以看到 order_products__prior.csv 包含所有客戶的先前訂單內容。“ reordered ”列表示客戶有包含該產品的上一個訂單。我們被告知有些訂單沒有重新訂購的商品。
探索數據
當我們考慮數據科學工作流程時,最重要的步驟之一是 探索性數據分析。這是我們檢查數據并尋找線索和見解的地方 特征 我們可以使用(或需要創建) 喂 我們的模型。 探索數據的方法有很多種,每個問題的每個探索性數據分析都是不同的 – 然而,它仍然非常重要,因為它通知我們的功能工程流程,最終確定我們的模型有多準確。
在 這個 筆記本,我們看一天中幾個不同的橫截面。具體來說,我們 檢查訂單數量的分布、一周中的天數和客戶通常下訂單的時間、訂單數量的分布 數 自上次訂單以來的天數,以及所有訂單和唯一客戶中最受歡迎的項目(重復數據消除) 為了 忽略那些擁有“最喜歡”的商品并重復訂購的客戶)。
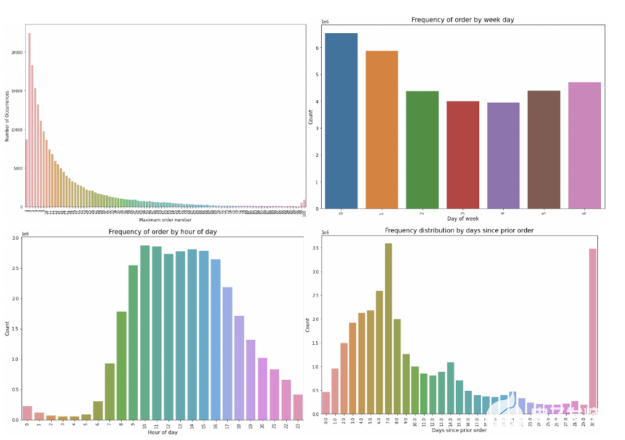
圖 2 。探索數據
從這里我們看到 分別地 那就是:
訂單不少于 4 個,最多 100 個。
訂單很高 星期六和星期日 0 和 1 )和低。
大多數 訂單是在 白天。 和客戶 主要是每周或每月訂購一次 ( 見第 7 天和第 30 天的峰值)。
對產品流行度進行了類似的探索性分析 [ 在筆記本中提供 。
特征工程
如果說探索性數據分析是我們數據科學工作流程中最重要的部分,那么特征工程則是緊隨其后的第二部分。在這里,我們確定哪些特性應該輸入到模型中,并在需要的地方創建特性 相信 他們 MIG 能夠幫助模型更好地進行預測。
圖 3 :機器學習是一個迭代過程。
我們首先確定我們的唯一用戶 X 項 組合 把它們分類。 我們會的 創建一個數據集,其中每個用戶映射到他們最近的訂單號、星期幾和小時數,以及自該訂單以來的天數。 以及 我們會的 延伸 我們的 數據集,創建標簽 和特點 稍后將在我們的機器學習模型中使用,例如:
用戶訂購了多少種產品?
用戶在一個購物車中訂購了多少產品?
用戶從哪些部門訂購了產品?
用戶何時訂購產品(星期幾)?
此用戶以前是否至少訂購過一次此產品?
一個用戶下了多少包含此項的訂單?
解決業務問題(培訓和預測)
許多機器學習算法的數學運算通常是矩陣乘法。這些類型的操作是高度并行化的,并且可以使用 GPU 大大加速 RAPIDS 使以加速方式構建機器學習模型變得很容易,同時仍然使用幾乎相同的界面 學習和 XGBoost 。
創建模型的方法有很多種——可以使用線性回歸模型、支持向量機、基于樹的模型(如 Random Forest 和 XGBoost ),甚至可以使用神經網絡。一般來說,基于樹的模型往往比神經網絡更好地處理用于預測的表格數據。神經網絡的工作原理是將輸入(特征空間)映射到另一個復雜的邊界空間,并確定哪些值應該屬于該邊界空間中的那些點(回歸、分類)。另一方面,基于樹的模型通過獲取數據、識別列,然后在該列中找到一個分割點來映射值,同時優化精度。我們可以使用不同的列創建多棵樹,甚至在每棵樹中創建不同的列。
基于樹的模型除了具有更好的精度性能外,還非常容易實現 解釋 ( 對預測或決策很重要 結果 根據預測 必須 可能出于合規性和法律原因,需要解釋和證明 例如 金融、保險、醫療)。基于樹的模型非常健壯,即使在 有 一小組數據點。
在下面的部分中, 我們會的 為我們的 XGBoost 模型設置不同的參數,并訓練五個不同的模型——每個模型都在不同的用戶子集上,以避免對特定的用戶集進行過度擬合。
import xgboost as xgb
NFOLD = 5
PARAMS = {
'max_depth':8,
'eta':0.1,
'colsample_bytree':0.4,
'subsample':0.75,
'silent':1,
'nthread':40,
'eval_metric':'logloss',
'objective':'binary:logistic',
'tree_method':'gpu_hist'
}
models = []
for i in range(NFOLD):
train_ = train[train.user_id % NFOLD != i]
valid_ = train[train.user_id % NFOLD == i]
dtrain = xgb.DMatrix(train_.drop(['user_id', 'product_id', 'label'], axis=1), train_['label'])
dvalid = xgb.DMatrix(valid_.drop(['user_id', 'product_id', 'label'], axis=1), valid_['label'])
model = xgb.train(PARAMS, dtrain, 9999, [(dtrain, 'train'),(dvalid, 'valid')],
early_stopping_rounds=50, verbose_eval=5)
models.append(model)
break
有 幾個 在 XGBoost 可以運行之前應該設置的參數。
一般參數與我們使用哪個助推器進行助推器有關,通常是樹模型或線性模型。
助推器參數取決于您選擇的助推器。
學習任務參數決定了學習場景。例如,回歸任務可以對排序任務使用不同的參數。
特征重要性
一次 我們已經 通過訓練我們的模型,我們或許想看看內部的工作原理,并了解哪些我們精心設計的特性對預測的貢獻最大。這稱為特征重要性。基于樹的預測模型的優點之一是了解 不同的 重要性 我們的特色很簡單。
與 理解力 如果我們的特征有助于模型的準確性,我們可以選擇刪除 不是嗎 重要或嘗試迭代和創建新特性,重新訓練和重新評估這些新特性是否更重要。 最終,能夠快速迭代并在此工作流中嘗試新事物將導致最精確的模型和最大的投資回報率(對于預測,通常是由于減少缺貨和庫存不足而節省成本)。 傳統上,由于計算強度的原因,迭代會花費大量的時間。 RAPIDS 允許用戶通過 NVIDIA 加速計算進行模型迭代,因此用戶可以快速迭代并確定性能最佳的模型。
在筆記本的功能重要性部分 , 我們定義了方便代碼來訪問每個模型中特性的重要性。然后,我們傳入我們訓練的模型列表,逐一迭代,并平均所有模型中每個變量的重要性。最后,我們想象 特征 使用水平條形圖的重要性。
我們特別看到,我們的三個特征對我們的預測貢獻最大:
user \ u product \ u size –用戶下了多少個包含此項目的訂單?
用戶\ u 產品\ u t-1 –此用戶以前是否至少訂購過一次此產品?
訂單號–用戶創建的訂單數。
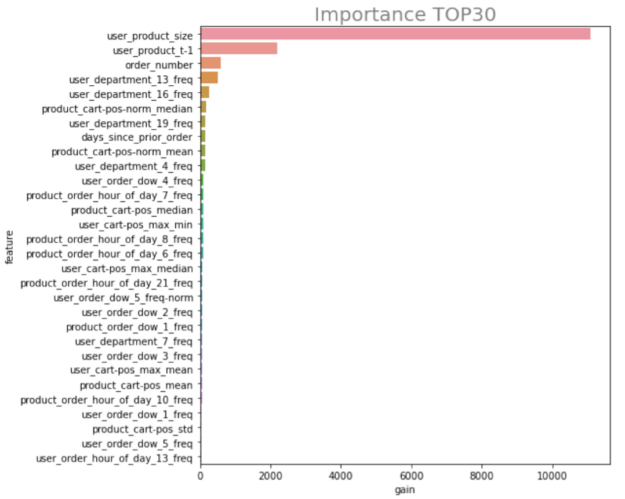
圖 4 :確定頂部特征。
所有這些都是有道理的,符合我們對問題的理解。以前下過訂單的客戶更可能重復該產品的訂單,而多次下該產品訂單的用戶更可能重新訂購。此外,客戶創建的訂單數量與其重新訂購的可能性相關。
代碼使用了特性重要性的默認 XGBoost 實現——但是我們可以自由選擇任何實現或技術。 一種奇妙的技術(也是由 NVIDIA Kaggle 大師艾哈邁特發明的) Erdem )稱為 LOFO 。
從 LOFO GitHub 頁面的描述中,我們可以看到 LOFO ( Leave One Feature Out ) Importance 根據選擇的度量來計算一組特征的重要性,對于選擇的模型,通過迭代地從集合中刪除每個特征,并評估模型的性能,以及選擇的驗證方案,基于選定的指標。 LOFO 首先評估包含所有輸入特性的模型的性能,然后一次迭代刪除一個特性,重新編譯模型,并在驗證集上評估其性能。
這種方法使我們能夠有效地確定哪些特性對模型很重要。與其他重要類型相比, LOFO 有幾個優點:
它不支持顆粒特征。
它 概括 以及看不見的測試集。
它是模型不可知論的。
它對包含時影響性能的特性給予負面的重視。
超參數 優化( HPO )
在培訓 XGBoost 模型時,我們使用了以下參數:
PARAMS = { 'max_depth':8, 'eta':0.1, 'colsample_bytree':0.4, 'subsample':0.75, 'silent':1, 'nthread':40, 'eval_metric':'logloss', 'objective':'binary:logistic', 'tree_method':'gpu_hist' }
其中,只有少數可能會改變并影響我們模型的準確性: [最大深度, eta ,,, ColSample , bytree ,] 和 subsample 。然而,這些可能不是最理想的參數。用最優化模型識別和訓練模型的藝術和科學 超參數 稱為超參數優化。
雖然沒有可以按下的魔法按鈕來自動識別最佳超參數,但是有一些技術可以讓您探索所有可能的超參數值的范圍,快速測試它們,并找到最接近的值。
對這些技術的全面探索超出了本筆記本的范圍。然而, RAPIDS 集成到許多 云 ML 框架 做 HPO 以及許多不同的 開源 工具。能夠使用 RAPIDS 提供的令人難以置信的加速,可以讓您非常快速地完成 ETL 、特性工程和模型培訓工作流程 實驗 – 最終通過大的超參數空間實現快速的 HPO 探索,并顯著降低總體擁有成本( TCO )。
結論
在這個博客里,我們 瀏覽了 Kaggle 競賽的各個部分,解釋了數據科學在改善零售業預測方面的最佳實踐。 具體來說,博文解釋道 Instacart Market Basket Analysis Kaggle 的競爭目標介紹了 RAPIDS ,然后提供了一個工作流,展示了如何可視化地探索數據、開發功能、訓練模型和運行預測。 然后 檢驗過的 具有模型可解釋性和超參數優化( HPO )的特征工程技術。
關于作者
Kazuki Onodera 目前在NVIDIA擔任高級深度學習數據科學家。在此之前,Kazuki在德納擔任數據科學家。Kazuki 自 2019 年以來一直是卡格爾競賽大師,并擁有五項前兩名的比賽排名。
Paul Hendricks 是NVIDIA的高級解決方案設計師,幫助零售商開展深度學習和人工智能計劃。Paul 的背景主要是零售業,過去六年來,他與許多財富 500 強零售公司合作,實施數據科學和人工智能解決方案。
Ahmet Erdem 是 Nvidia 的高級數據科學家,擁有計算機工程和人工智能背景。他以前在機器人和軟件工程方面有經驗。作為 Nvidia Kaggle 大師團隊的一員,他喜歡解決各種機器學習問題,但他的主要重點是深入學習非結構化的表格數據。除了比賽,他還擁有幾個開源項目。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4994瀏覽量
103159 -
gpu
+關注
關注
28文章
4743瀏覽量
128992 -
機器學習
+關注
關注
66文章
8422瀏覽量
132714
發布評論請先 登錄
相關推薦
智慧零售:國產工控主板在智慧零售終端中的關鍵作用
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
WiFi藍牙模塊促進傳統零售數字化轉型:智能零售體驗再升級
Sainsbury與微軟合作,探索AI零售新紀元
5G智能物聯網課程之Aidlux下人工智能開發(SC171開發套件V2)
廣和通亮相2024 CHINASHOP,聚焦智慧零售革新

廣和通攜智慧零售模組及解決方案亮相2024 CHINASHOP
廣和通亮相2024中國零售業博覽會
2024中國零售業博覽會盛大開幕,廣和通展示創新智慧零售解決方案
廣和通攜系列智慧零售模組及解決方案亮相2024 CHINASHOP
廣和通SC208系列智能模組賦能智慧零售全場景
WiFi模塊引領零售數字化轉型:智能零售體驗再定義
嵌入式人工智能的就業方向有哪些?
IBM最新全球調研:零售消費體驗滿意度普遍較低,中國消費者對使用人工智能購物的興趣強烈
億緯鋰能攜智能零售電源全面解決方案亮相美國零售業聯盟展覽會






 工商網監
工商網監
評論