") BEVSegFormer創(chuàng)造了新的BEV分割SOTA
BEVSegFormer創(chuàng)造了新的BEV分割SOTA
對(duì)自動(dòng)駕駛而言,BEV(鳥瞰圖)下的語義分割是一項(xiàng)重要任務(wù)。盡管這項(xiàng)工作已經(jīng)吸引了大量的研究,但靈活處理自動(dòng)駕駛車輛上的任意相機(jī)配置(單個(gè)或多個(gè)攝像頭),仍然是一項(xiàng)挑戰(zhàn)。
為此,Nullmax的感知團(tuán)隊(duì)提出了BEVSegFormer,這一基于Transformer的BEV語義分割方法,可面向任意配置的相機(jī)進(jìn)行BEV語義分割。
這項(xiàng)研究的題目為《BEVSegFormer: Bird's Eye View Semantic Segmentation From Arbitrary Camera Rigs》,論文鏈接:https://arxiv.org/abs/2203.04050。
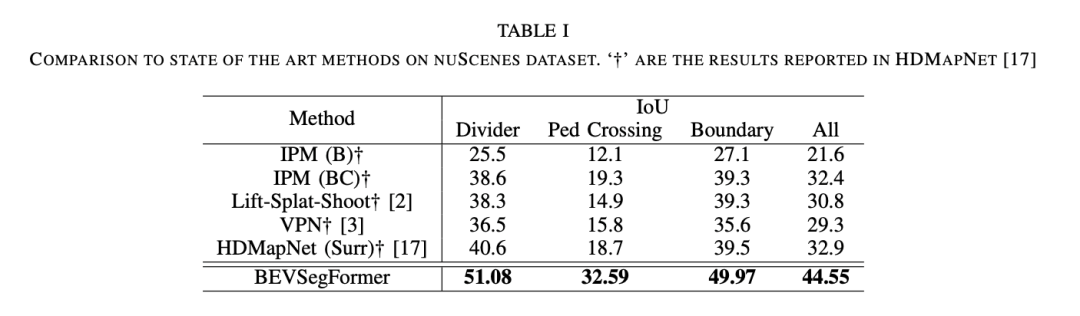
為了評(píng)估這一算法的效果,Nullmax在nuScenes公開數(shù)據(jù)集以及Nullmax的自采數(shù)據(jù)集上進(jìn)行了驗(yàn)證。實(shí)驗(yàn)結(jié)果表明,BEVSegFormer對(duì)任意相機(jī)配置的BEV語義分割,具有出色的性能表現(xiàn)。并且在nuScenes驗(yàn)證集上,BEVSegFormer創(chuàng)造了新的BEV分割SOTA。
在接下來的工作中,我們還計(jì)劃針對(duì)自動(dòng)駕駛以及BEV語義分割的一些其他挑戰(zhàn),展開進(jìn)一步的研究。
歡迎對(duì)計(jì)算機(jī)視覺及自動(dòng)駕駛感知感興趣的小伙伴加入我們,一起探索!
01
關(guān)于BEVSegFormer
在自動(dòng)駕駛或者機(jī)器人導(dǎo)航系統(tǒng)中,以BEV形式對(duì)感知信息進(jìn)行表征,具有至關(guān)重要的作用,因?yàn)樗梢詾橐?guī)劃和控制提供諸多的便利。
比如,在無地圖導(dǎo)航方案中,構(gòu)建本地BEV地圖,不僅成為了高精地圖外的另一種選擇,并且對(duì)于包括智體行為預(yù)測(cè)以及運(yùn)動(dòng)規(guī)劃等感知系統(tǒng)下游任務(wù)而言,也非常重要。而利用相機(jī)的輸入進(jìn)行BEV語義分割,通常被視為構(gòu)建本地BEV地圖的第一步。
為此,傳統(tǒng)方法一般會(huì)先在圖像空間生成分割結(jié)果,然后通過逆透視變換(IPM)函數(shù)轉(zhuǎn)換到BEV空間。雖然這是一種連接圖像空間和BEV空間的簡(jiǎn)單直接的方法,但它需要準(zhǔn)確的相機(jī)內(nèi)外參,或者實(shí)時(shí)的相機(jī)位姿估計(jì)。所以,視圖變換的實(shí)際效果有可能比較差。
以車道線分割為例,在一些挑戰(zhàn)性場(chǎng)景中,比如遮擋或者遠(yuǎn)處區(qū)域,使用IPM的傳統(tǒng)方法提供的結(jié)果就不夠準(zhǔn)確,如圖所示。

近年來,深度學(xué)習(xí)方法已被研究用于BEV語義分割。Lift-Splat-Shoot通過逐像素深度估計(jì)結(jié)果完成了從圖像視圖到BEV的視圖變換。不過使用深度估計(jì),也增加了視圖變換過程的復(fù)雜度。此外,有一些方法應(yīng)用MLP或者FC算子來進(jìn)行視圖變換。這些固定的視圖變換方法,學(xué)習(xí)圖像空間和BEV空間之間的固定映射,因此不依賴于輸入的數(shù)據(jù)。
而基于Transformer的方法,是在BEV空間下進(jìn)行感知的另一個(gè)研究方向。在目標(biāo)檢測(cè)任務(wù)中,DETR3D引入了一種3D邊界框檢測(cè)方法,直接從多個(gè)相機(jī)圖像的2D特征生成3D空間中的預(yù)測(cè)。3D空間和2D圖像空間之間的視圖變換,通過交叉注意模塊的3D到2D查詢來實(shí)現(xiàn)。
受此啟發(fā),我們提出了BEVSegFormer,通過在Transformer中使用交叉注意機(jī)制進(jìn)行BEV到圖像的查詢,來計(jì)算視圖變換。
BEVSegFormer由3個(gè)主要的組件組成:
共享的主干網(wǎng)絡(luò),用于提取任意相機(jī)的特征圖;
Transformer編碼器,通過自注意模塊嵌入特征圖;
BEV Transformer解碼器,通過交叉注意機(jī)制處理BEV查詢,輸出最終的BEV語義分割結(jié)果。
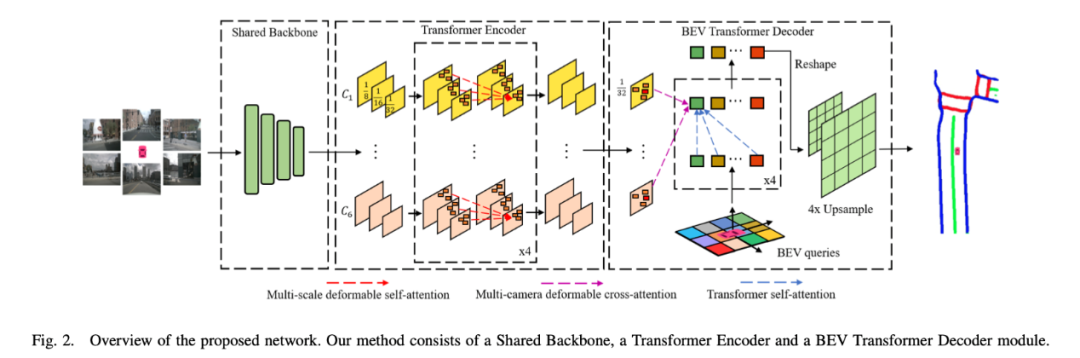
具體來說,BEVSegFormer首先是使用了共享的主干網(wǎng)絡(luò),對(duì)來自任意相機(jī)的圖像特征進(jìn)行編碼,然后通過基于可變形Transformer的編碼器對(duì)這些特征進(jìn)行增強(qiáng)。
除此之外,BEVSegFormer還引入了一個(gè)BEV Transformer解碼器模塊,對(duì)BEV語義分割的結(jié)果進(jìn)行解析,以及一種高效的多相機(jī)可變形注意單元,完成BEV到圖像的視圖變換。
最后,根據(jù)BEV中的網(wǎng)格布局對(duì)查詢進(jìn)行重塑,并進(jìn)行上采樣,以有監(jiān)督的方式生成語義分割結(jié)果。
我們分別在nuScenes公開數(shù)據(jù)集以及Nullmax的自采數(shù)據(jù)集上,檢驗(yàn)了BEVSegFormer的算法效果。實(shí)驗(yàn)結(jié)果表明,BEVSegFormer在nuScenes驗(yàn)證集上創(chuàng)造了新的BEV分割SOTA。通過消融實(shí)驗(yàn),當(dāng)中每個(gè)組件的效果也得到了驗(yàn)證。
02
加入我們
在這項(xiàng)研究中,我們?yōu)榱藨?yīng)對(duì)自動(dòng)駕駛車輛上任意相機(jī)配置的BEV語義分割挑戰(zhàn),提出了BEVSegFormer。
接下來,我們還計(jì)劃在自動(dòng)駕駛當(dāng)中,基于Transformer探索內(nèi)存效率更高、解釋性更強(qiáng)的BEV語義分割方法。
歡迎對(duì)BEV、Transformer在自動(dòng)駕駛中的感知任務(wù)感興趣,以及希望從事于計(jì)算機(jī)視覺和自動(dòng)駕駛感知研發(fā)的同學(xué),加入Nullmax感知團(tuán)隊(duì)。
在這里,你可以直接參與到大量自動(dòng)駕駛量產(chǎn)項(xiàng)目的落地,以及最前沿技術(shù)的預(yù)研當(dāng)中,為你的idea和技術(shù)找到一個(gè)充分施展的舞臺(tái)!
審核編輯 :李倩
-
自動(dòng)駕駛
+關(guān)注
關(guān)注
784文章
13784瀏覽量
166397 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121113
原文標(biāo)題:當(dāng)BEV語義分割遇上了Transformer,故事的結(jié)局是新的SOTA
文章出處:【微信號(hào):Nullmax,微信公眾號(hào):Nullmax紐勱】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
淺析基于自動(dòng)駕駛的4D-bev標(biāo)注技術(shù)

自動(dòng)駕駛中一直說的BEV+Transformer到底是個(gè)啥?

語義分割25種損失函數(shù)綜述和展望

畫面分割器怎么調(diào)試
畫面分割器怎么連接
關(guān)于\"OPA615\"的SOTA的跨導(dǎo)大小的疑問求解
圖像語義分割的實(shí)用性是什么
圖像分割和語義分割的區(qū)別與聯(lián)系
圖像分割與語義分割中的CNN模型綜述
NB81是否支持OneNet SOTA功能?應(yīng)該如何激活SOTA?
旋變位置不變的情況下,當(dāng)使能SOTA功能與關(guān)閉SOTA功能時(shí),APP中DSADC采樣得到的旋變sin和cos兩者值不一樣,為什么?
BEV和Occupancy自動(dòng)駕駛的作用

頂刊TPAMI最全綜述!深入自動(dòng)駕駛BEV感知的魔力!
自動(dòng)駕駛領(lǐng)域中,什么是BEV?什么是Occupancy?

基于LSS范式的BEV感知算法優(yōu)化部署詳解

- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論