") 用NVIDIA CUDA11.2 C ++編譯器提高應(yīng)用性能
用NVIDIA CUDA11.2 C ++編譯器提高應(yīng)用性能
11.2 CUDA C ++編譯器結(jié)合了旨在提高開發(fā)者生產(chǎn)力和 GPU 加速應(yīng)用性能的特性和增強(qiáng)。
編譯器工具鏈將 LLVM 升級(jí)到 7.0 ,這將啟用新功能并有助于改進(jìn) NVIDIA GPU 的編譯器代碼生成。設(shè)備代碼的鏈接時(shí)間優(yōu)化( LTO )(也稱為設(shè)備 LTO )在 CUDA 11. 0 工具包版本中作為預(yù)覽功能引入,現(xiàn)在作為全功能優(yōu)化功能提供。 11. 2 CUDA C ++編譯器可以可選地生成一個(gè)函數(shù),用于為設(shè)備的功能內(nèi)聯(lián)診斷報(bào)告,它可以提供編譯器的內(nèi)聯(lián)決策的洞察力。這些診斷報(bào)告可以幫助高級(jí) CUDA 開發(fā)人員進(jìn)行應(yīng)用程序性能分析和調(diào)優(yōu)工作。
CUDA C ++編譯器默認(rèn)地將設(shè)備函數(shù)內(nèi)嵌到調(diào)用站點(diǎn)。這使得優(yōu)化設(shè)備代碼的匯編級(jí)調(diào)試成為一項(xiàng)困難的任務(wù)。對(duì)于使用 11. 2 CUDA C ++編譯器工具鏈編譯的源代碼,[EZX223]和 NVIEW 計(jì)算調(diào)試器可以在調(diào)用堆棧回溯中顯示內(nèi)聯(lián)設(shè)備功能的名稱,從而改進(jìn)調(diào)試體驗(yàn)。
這些和其他新特性被納入 CUDA C ++ 11. 2 編譯器,我們將在這個(gè)帖子中進(jìn)行深入的跳水。繼續(xù)讀!
使用設(shè)備 LTO 加速應(yīng)用程序性能
CUDA 11.2 的特點(diǎn)是 設(shè)備 LTO ,它為以單獨(dú)編譯模式編譯的設(shè)備代碼帶來了 LTO 的性能優(yōu)勢(shì)。在 CUDA 5 。 0 中, NVIDIA 引入了獨(dú)立編譯模式,以提高開發(fā)人員設(shè)計(jì)和構(gòu)建 GPU 加速應(yīng)用程序的效率。沒有單獨(dú)的編譯模式,編譯器只支持整個(gè)程序編譯模式, CUDA 應(yīng)用程序中的所有設(shè)備代碼必須限制在單個(gè)翻譯單元中。單獨(dú)的編譯模式使您可以自由地跨多個(gè)文件構(gòu)造設(shè)備代碼,包括 GPU 加速的庫(kù)和利用增量構(gòu)建。單獨(dú)的編譯模式允許您關(guān)注源代碼模塊化。
但是,單獨(dú)的編譯模式限制在編譯時(shí)可以執(zhí)行的性能優(yōu)化范圍內(nèi)。諸如跨單個(gè)翻譯單元邊界的設(shè)備函數(shù)內(nèi)聯(lián)之類的優(yōu)化不能在單獨(dú)的編譯模式下執(zhí)行。與整個(gè)程序編譯模式相比,這會(huì)導(dǎo)致在單獨(dú)編譯模式下生成次優(yōu)代碼,尤其是在針對(duì)設(shè)備代碼庫(kù)進(jìn)行鏈接時(shí)。使用設(shè)備 LTO ,在單獨(dú)編譯模式下編譯的應(yīng)用程序的性能與整個(gè)編譯模式相當(dāng)。
LTO 是 CPU 編譯器工具鏈中一個(gè)強(qiáng)大的優(yōu)化功能,我們現(xiàn)在正在使 GPU 加速代碼可以訪問它。對(duì)于單獨(dú)編譯的設(shè)備代碼, Device LTO 支持僅在 NVCC 整個(gè)程序編譯模式下才可能進(jìn)行的設(shè)備代碼優(yōu)化。使用設(shè)備 LTO ,您可以利用源代碼模塊化的好處,而不必犧牲整個(gè)程序編譯的運(yùn)行時(shí)性能好處。
有關(guān)設(shè)備 LTO 性能影響的更多信息,請(qǐng)參閱 利用 NVIDIA CUDA 11.2 設(shè)備鏈路時(shí)間優(yōu)化提高 GPU 應(yīng)用性能 。
優(yōu)化設(shè)備代碼的增強(qiáng)調(diào)試
我們做了一些增強(qiáng),以便在某些情況下更容易調(diào)試優(yōu)化的設(shè)備代碼。
精確調(diào)試
使用 CUDA 11. 2 ,大多數(shù)內(nèi)聯(lián)函數(shù)都可以在 cuda-gdb 和 Nsight 調(diào)試器的調(diào)用堆棧回溯中看到。您擁有性能優(yōu)化代碼路徑的一致回溯,更重要的是,您可以更精確地確定錯(cuò)誤或異常的調(diào)用路徑,即使所有函數(shù)都是內(nèi)聯(lián)的。
圖 1 顯示了一個(gè)場(chǎng)景示例,在調(diào)試異常時(shí),此功能可以節(jié)省大量時(shí)間。
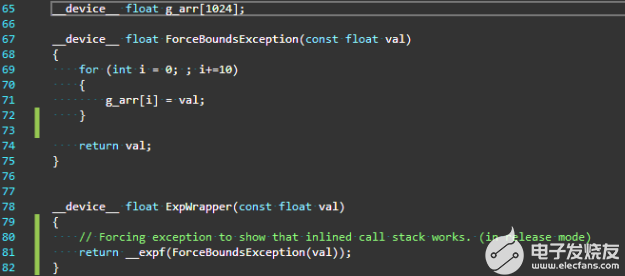
圖 1 在第 71 行強(qiáng)制數(shù)組越界異常的示例代碼
在圖 1 中,函數(shù) ExpWrapper 調(diào)用 ForceBoundsException ,該函數(shù)注入一個(gè)數(shù)組越界異常。因?yàn)楹瘮?shù) ForceBoundsException 與函數(shù) ExpWrapper 定義在同一個(gè)文件中,所以它只是簡(jiǎn)單地內(nèi)聯(lián)在那里。如果沒有對(duì) CUDA 11. 2 中添加的內(nèi)聯(lián)函數(shù)的回溯支持,調(diào)用堆棧將只顯示未內(nèi)聯(lián)在此調(diào)用路徑中的頂級(jí)調(diào)用方。在本例中,它恰好是函數(shù) ExpWrapper 的調(diào)用者,因此異常點(diǎn)處的調(diào)用堆棧如圖 2 所示,排除了所有其他內(nèi)聯(lián)函數(shù)調(diào)用。

圖 2 CUDA 11.2 之前沒有內(nèi)聯(lián)函數(shù)的調(diào)用堆棧報(bào)告行號(hào),沒有完全回溯。
從圖 2 中的調(diào)用堆棧可以明顯看出,調(diào)用堆棧中的信息非常少,無法有意義地調(diào)試最終導(dǎo)致異常點(diǎn)的執(zhí)行路徑。如果不知道函數(shù)是如何內(nèi)聯(lián)的,調(diào)用堆棧中提供的行號(hào) 71 也沒有用處。在一個(gè)三層的深層函數(shù)調(diào)用中,這個(gè)問題看起來很容易找到。隨著堆棧越來越深,這個(gè)問題可能會(huì)迅速升級(jí)。我們知道,這可能是相當(dāng)令人沮喪的。
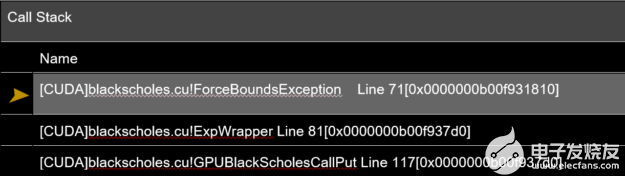
圖 3 在 CUDA 11 。 2 中,一種帶有內(nèi)聯(lián)函數(shù)的調(diào)用堆棧。
在 CUDA 11.2 中, NVIDIA 通過為內(nèi)聯(lián)函數(shù)添加有意義的調(diào)試信息,朝著優(yōu)化代碼的符號(hào)調(diào)試邁出了一步。現(xiàn)在生成的調(diào)用堆棧既精確又有用,包括在每個(gè)級(jí)別調(diào)用的所有函數(shù),包括那些內(nèi)聯(lián)的函數(shù)。這使您不僅可以確定發(fā)生異常的確切函數(shù),還可以消除觸發(fā)異常的確切調(diào)用路徑的歧義。
它變得更好了!
更多的調(diào)試信息,即使是最優(yōu)化的代碼
對(duì)內(nèi)聯(lián)函數(shù)調(diào)試的改進(jìn)不僅是在調(diào)用堆棧回溯上查看內(nèi)聯(lián)函數(shù),而且還擴(kuò)展到源代碼查看。在 CUDA 11. 2 之前,當(dāng)函數(shù)調(diào)用被積極內(nèi)聯(lián)時(shí),反匯編代碼的源代碼視圖是神秘而緊湊的(圖 4 )。
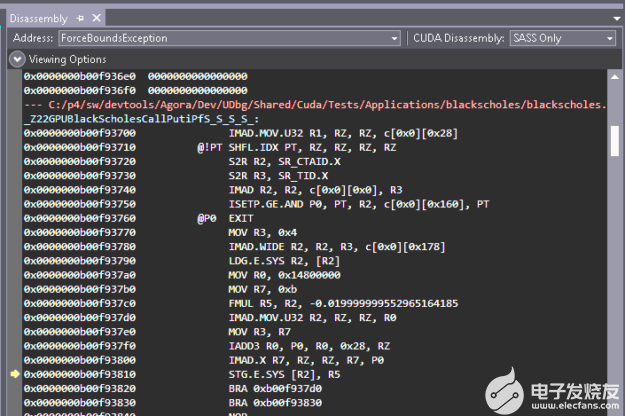
圖 4 CUDA 11. 2 之前的源代碼反匯編視圖
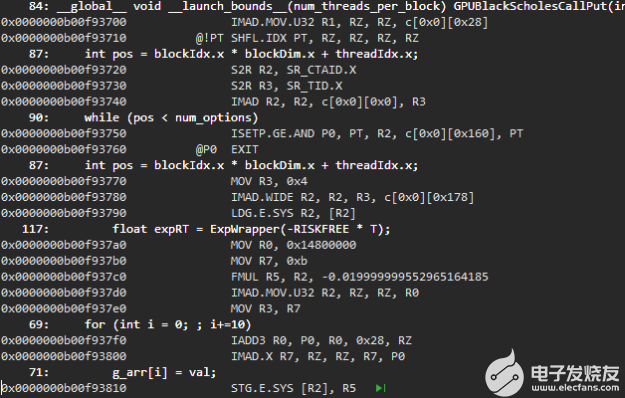
圖 5 CUDA 11 。 2 上啟用源代碼的反匯編代碼視圖。
有更多的調(diào)試信息,包括行信息和源代碼行被標(biāo)記到反匯編代碼段。
圖 5 顯示了 CUDA 11. 2 上相同反匯編代碼段的源代碼視圖。您可以為優(yōu)化的代碼段獲得更詳細(xì)的源代碼視圖,并且可以單步執(zhí)行它們。行信息和源代碼行被標(biāo)記到反匯編源代碼視圖中,即使對(duì)于內(nèi)聯(lián)代碼段也是如此。
要啟用此功能,將 --generate-line-info (或 -lineinfo )選項(xiàng)傳遞給編譯器就足夠了。對(duì)優(yōu)化的設(shè)備代碼進(jìn)行全面的符號(hào)調(diào)試還不可用。在某些情況下,您可能仍然需要使用 -G 選項(xiàng)進(jìn)行調(diào)試。然而,僅僅擁有一個(gè)精確的調(diào)用堆棧和一個(gè)詳細(xì)的源代碼查看就可以決定性地提高調(diào)試性能優(yōu)化代碼的效率,從而提高開發(fā)人員的工作效率。
但還不止這些!
對(duì)診斷報(bào)告內(nèi)聯(lián)的見解
傳統(tǒng)上,當(dāng)編譯器做出應(yīng)用程序開發(fā)人員看不到的基于啟發(fā)式的優(yōu)化決策時(shí),編譯器有點(diǎn)像黑匣子。
其中一個(gè)關(guān)鍵的優(yōu)化就是函數(shù)內(nèi)聯(lián)。如果沒有對(duì)匯編輸出進(jìn)行繁重的后處理,就很難理解內(nèi)聯(lián)的編譯器啟發(fā)式方法。只要知道哪些函數(shù)是內(nèi)聯(lián)的,哪些不是內(nèi)聯(lián)的,就可以節(jié)省很多時(shí)間,這就是我們?cè)?CUDA 11.2 中介紹的。現(xiàn)在您不僅知道函數(shù)何時(shí)沒有內(nèi)聯(lián),而且還知道為什么函數(shù)不能內(nèi)聯(lián)。然后可以重構(gòu)代碼,向函數(shù) de Clara 選項(xiàng)添加內(nèi)聯(lián)關(guān)鍵字,或者執(zhí)行其他源代碼重構(gòu)(如果可能的話)。
您可以通過一個(gè)新選項(xiàng) --optimization-info=inline 獲得關(guān)于優(yōu)化器內(nèi)聯(lián)決策的診斷報(bào)告。啟用內(nèi)聯(lián)診斷時(shí),當(dāng)函數(shù)無法內(nèi)聯(lián)時(shí),優(yōu)化器會(huì)報(bào)告其他診斷。
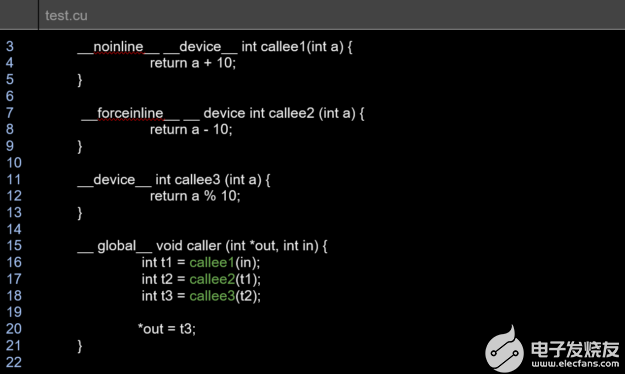
圖 6 樣品測(cè)試。 cu 用于以下內(nèi)聯(lián)診斷生成的文件。
早期樣本的診斷報(bào)告測(cè)試。 cu 文件如下所示:
remark: test.cu:16:12: _Z7callee2i inlined into _Z6callerPii with cost=always
remark: test.cu:17:11: _Z7callee3i inlined into _Z6callerPii with cost=always
remark: test.cu:18:12: _Z7callee1i not inlined into _Z6callerPii because it should never be inlined (cost=never)
在某些情況下,您可能會(huì)得到更詳細(xì)的診斷:
remark: x.cu:312:28: callee not inlined into caller because callee doesn't have forceinline attribute and is too big for auto inlining (CalleeSize=666)
有關(guān)內(nèi)聯(lián)的診斷報(bào)告對(duì)于重構(gòu)代碼以適當(dāng)?shù)厥褂脙?nèi)聯(lián)函數(shù)的性能優(yōu)勢(shì)非常有用。內(nèi)聯(lián)診斷在編譯器運(yùn)行內(nèi)聯(lián)過程時(shí)發(fā)出。當(dāng)從編譯器多次調(diào)用內(nèi)聯(lián)程序時(shí),前一個(gè)過程中未內(nèi)聯(lián)的調(diào)用站點(diǎn)可能會(huì)內(nèi)聯(lián)到后一個(gè)過程中通過。那個(gè) CUDA C ++編譯器文檔解釋了如何在 NVCC 調(diào)用期間使用此選項(xiàng)。
通過并行編譯減少構(gòu)建時(shí)間
可以使用 -gencode/-arch/-code 命令行選項(xiàng)同時(shí)調(diào)用 CUDA C ++編譯器,以編譯多個(gè) GPU 架構(gòu)的 CUDA 設(shè)備代碼。雖然這是一個(gè)方便的特性,但它可能會(huì)導(dǎo)致由于幾個(gè)中間步驟而增加構(gòu)建時(shí)間。
特別地,編譯器需要對(duì) CUDA C ++源代碼進(jìn)行多次處理,并使用不同的 __CUDA__ARCH__ 內(nèi)置宏的值來指定每個(gè)不同的計(jì)算架構(gòu),包括額外的預(yù)處理步驟,其中內(nèi)置的宏未被定義,以編譯主機(jī)平臺(tái)的源代碼。之后,預(yù)處理的 CUDA C ++設(shè)備代碼實(shí)例必須編譯成指定的每個(gè)目標(biāo) GPU 架構(gòu)的機(jī)器代碼。這些步驟目前是連續(xù)進(jìn)行的。
為了減輕由多個(gè)編譯過程產(chǎn)生的編譯時(shí)間的增加,從 CUDA 11 。 2 版本開始, CUDA C ++編譯器支持一個(gè)新的 —threads 《number》 命令行選項(xiàng)(簡(jiǎn)稱-t)來生成單獨(dú)的線程以并行執(zhí)行獨(dú)立編譯傳遞。如果在單個(gè) nvcc 命令中編譯多個(gè)文件, -t 將并行編譯這些文件。 參數(shù)確定 NVCC 編譯器為并行執(zhí)行獨(dú)立編譯步驟而生成的獨(dú)立輔助線程數(shù)。
對(duì)于特殊情況 -t0 ,使用的線程數(shù)是機(jī)器上的 CPU 數(shù)。當(dāng)調(diào)用 NVCC 為多個(gè) GPU 架構(gòu)同時(shí)編譯 CUDA 設(shè)備代碼時(shí),此選項(xiàng)有助于減少總體構(gòu)建時(shí)間。默認(rèn)情況下,這些步驟是連續(xù)執(zhí)行的。
Example
以下命令為兩個(gè)虛擬體系結(jié)構(gòu)生成。 ptx 文件: compute_52 和 compute_70 。對(duì)于 compute_52 ,為兩個(gè) GPU 目標(biāo)生成。 cubin 文件: sm_52 和 sm_60 ;對(duì)于 compute_70 ,為 sm_70. 生成。 cubin 文件
nvcc -gencode arch=compute_52,code=sm_52 -gencode arch=compute_52,code=sm_60 -gencode arch=compute_70,code=sm_70 t.cu
并行編譯有助于在編譯大量應(yīng)用 CUDA C ++設(shè)備代碼到多個(gè) GPU 目標(biāo)的應(yīng)用程序時(shí)減少總體構(gòu)建時(shí)間。如果源代碼主要是 C / C ++主機(jī)代碼,只有少量 CUDA 設(shè)備代碼,或者如果僅以單個(gè)虛擬架構(gòu)/ GPU-SM 組合為目標(biāo),則可能不會(huì)減少整個(gè)構(gòu)建時(shí)間。換句話說,構(gòu)建時(shí)的加速可能會(huì)因程序、編譯目標(biāo)特性以及 NVCC 可以生成的并行編譯線程的數(shù)量而異。
NVCC 啟動(dòng) helper 線程來動(dòng)態(tài)地并行執(zhí)行編譯步驟(如 CUDA 編譯軌跡圖 中所描述的),受編譯步驟之間的序列化依賴關(guān)系的約束,其中編譯步驟僅在其依賴的所有先前步驟完成之后才在單獨(dú)的線程上啟動(dòng)。
圖 7 顯示了當(dāng) NVCC 生成的獨(dú)立編譯線程的限制增加時(shí)( -t N 選項(xiàng)),由于并行編譯而導(dǎo)致的 CUDA 編譯加速是如何變化的。這適用于需要不同級(jí)別的獨(dú)立編譯步驟的編譯軌跡,這些步驟可以并行執(zhí)行。
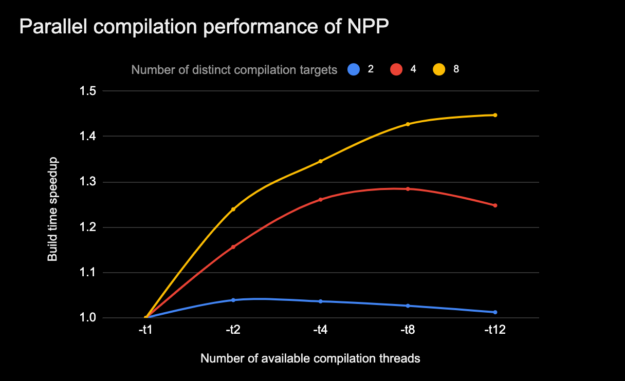
圖 7 為多個(gè) GPU 架構(gòu)編譯 NVIDIA 性能原語( NPP )的并行編譯加速。
CPU 型號(hào): i7-7800X CPU @ 3 。 50GHz # CPU : 12 ,每核線程數(shù): 2 ,每插槽核數(shù): 6 ,內(nèi)存: 31G 。 (所有的編譯都使用 make-j8 )
NVCC 并行線程編譯特性可以與進(jìn)程級(jí)構(gòu)建并行性(即, make -j N )一起使用。但是,必須考慮主機(jī)平臺(tái)的特性,以避免過度訂閱生成系統(tǒng)資源(例如, CPU 核心數(shù)、可用內(nèi)存、其他工作負(fù)載),這可能會(huì)對(duì)總體生成時(shí)間產(chǎn)生負(fù)面影響。
新的編譯器內(nèi)置提示,可以更好地優(yōu)化設(shè)備代碼
CUDA 11 。 2 支持新的內(nèi)置程序,使您能夠向編譯器指示編程提示,以便更好地生成和優(yōu)化設(shè)備代碼。
使用 __builtin_assume_aligned , 可以向編譯器提示指針對(duì)齊,編譯器可以使用指針對(duì)齊進(jìn)行優(yōu)化。類似地, __builtin_assume 和 __assume 內(nèi)置可以用來指示運(yùn)行時(shí)條件,以幫助編譯器生成更好的優(yōu)化代碼。下一節(jié)將深入研究每個(gè)特定的內(nèi)置提示函數(shù)。
void * __builtin_assume_aligned(const void *ptr, size_t align)
void *__builtin_assume_aligned(const void *ptr, size_t align, offset)
__builtin_assume_aligned內(nèi)置函數(shù)可用于向編譯器提示作為指針傳遞的參數(shù)至少與align字節(jié)對(duì)齊。當(dāng)參數(shù)(char *)ptr - offset至少與align字節(jié)對(duì)齊時(shí),可以使用帶有offset的版本。兩個(gè)函數(shù)都返回參數(shù)指針。
編譯器可以使用這種對(duì)齊提示來執(zhí)行某些代碼優(yōu)化,如加載/存儲(chǔ)矢量化,以更好地工作。考慮一下這里顯示的函數(shù)中的示例代碼,該函數(shù)使用內(nèi)置函數(shù)來指示參數(shù)ptr可以假定至少與 16 個(gè)字節(jié)對(duì)齊。
__device int __get(int*ptr)
{
int *v = static_cast
(__builtin_assume_aligned(ptr, 16));
return *v + *(v+1) + *(v+2) + *(v+3);
}
前面的代碼示例在使用nvcc -rdc=true -ptx foo.cu編譯時(shí)沒有內(nèi)置函數(shù),生成了以下 PTX ,其中對(duì)返回表達(dá)式執(zhí)行了四個(gè)單獨(dú)的加載操作。
ld.u32 %r1, [%rd1]; ld.u32 %r2, [%rd1 + 4]; ld.u32 %r4, [%rd1 + 8]; ld.u32 %r6, [%rd1 +12];
當(dāng)使用內(nèi)置函數(shù)向編譯器提示指針是 16 字節(jié)對(duì)齊的時(shí),生成的 PTX 反映了這樣一個(gè)事實(shí):編譯器可以將加載操作組合成一個(gè)向量化的加載操作。
ld.v4.u32 {%r1, %r2, %r3, %r4 }, [%rd1];
由于四個(gè)加載是并行執(zhí)行的,因此單個(gè)矢量化加載操作所需的執(zhí)行時(shí)間更少。這避免了向內(nèi)存子系統(tǒng)發(fā)出多個(gè)請(qǐng)求的開銷,同時(shí)還保持了較小的二進(jìn)制大小。
void * __builtin_assume(bool exp)
__builtin__assume內(nèi)置函數(shù)允許編譯器假定提供的布爾參數(shù)為 true 。如果參數(shù)在運(yùn)行時(shí)不為 true ,則行為未定義。參數(shù)表達(dá)式不能有副作用。盡管 CUDA 11 . 2 文檔指出副作用已被丟棄,但此行為在將來的版本中可能會(huì)發(fā)生更改,因此可移植代碼在提供的表達(dá)式中不應(yīng)產(chǎn)生副作用。
例如,對(duì)于下面的代碼段, CUDA 11 . 2toolkit 編譯器可以用更少的指令優(yōu)化 modulo-16 操作,因?yàn)橹?code style="font-size:inherit;color:inherit;margin:0px;padding:0px;border:0px;font-style:inherit;font-variant:inherit;font-weight:inherit;line-height:inherit;vertical-align:baseline;background-color:rgb(244,244,244);">num變量的值是肯定的。
__device__ int mod16(int num){__builtin_assume(num > 0);return num % 16;}
如下一個(gè)生成的 PTX 代碼示例所示,當(dāng)使用nvcc -rdc=true -ptx編譯示例代碼時(shí),編譯器為模運(yùn)算生成一條 AND 指令。
ld.param.u32 %r1, [_Z5Mod16i_param_0];and.b32 %r2, %r1, 15;st.param.b32 [func_retval0+0], %r2;
如果沒有提示,編譯器必須考慮num值為負(fù)值的可能性,如生成的 PTX 代碼(包括附加指令)所示。
ld.param.u32 %r1, [_Z5Mod16i_param_0];
shr.s32 %r2, %r1, 31;
shr.u32 %r3, %r2, 28;
add.s32 %r4, %r1, %r3;
and.b32 %r2, %r1, 15;
sub.s32 %r6, %r1, %r5
st.param.b32 [func_retval0+0], %r2;
使用時(shí), NVCC 還支持類似的內(nèi)置函數(shù)__assume(bool)cl . exe 文件作為主機(jī)編譯器。
void * __builtin_unreachable(void)
在 CUDA 11 . 3 中,我們將介紹__builtin_unreachable內(nèi)置函數(shù)。這個(gè)內(nèi)置函數(shù)在 CUDA 11 . 3 中引入時(shí),可用于向編譯器指示控制流永遠(yuǎn)不會(huì)到達(dá)調(diào)用此函數(shù)的點(diǎn)。如果控制流在運(yùn)行時(shí)到達(dá)該點(diǎn),則程序具有未定義的行為。此提示可以幫助代碼優(yōu)化器生成更好的代碼:
__device__ int get(int input)
{
switch (input)
{
case 1: return 4;
case 2: return 10;
default: __builtin_unreachable();
}
}
用 CUDA 11 . 3 中的nvcc -rdc=true -ptx編譯早期代碼片段生成的 PTX 將把整個(gè) switch 語句優(yōu)化為一條 SELECT 指令。
ld.param.u32 %r1, [_Z3geti_param_0];
setp.eq.s32 %p1, %r1, 1;
selp.b32 %r2, 4, 10, %p1;
st.param.b32 [func_retval0+0], %r2;
如果沒有__builtin_unreachable調(diào)用,編譯器將生成一個(gè)警告,指出控制流已到達(dá)非 void 函數(shù)的結(jié)尾。通常,必須注入一個(gè)偽返回 0 以避免出現(xiàn)警告消息。
__device__ int get(int input)
{
switch (input)
{
case 1: return 4;
case 2: return 10;
default: return 0;
}
}
添加 return 以避免編譯器警告會(huì)導(dǎo)致更多的 PTX 指令,這也有抑制進(jìn)一步優(yōu)化的潛在副作用。
ld.param.u32 %r1, [_Z3geti_param_0]; setp.eq.s32%p1, %r1, 2; selp.b32%r2, 10, 0, %p1; setp.eq.s32%p2, %r1, 1; selp.b32%r3, 4, %r2, %p2; st.param.b32[func_retval0+0], %r2;
__builtin_assume 和 __builtin_assume_aligned 函數(shù)在內(nèi)部映射到 llvm.assume LLVM 內(nèi)在函數(shù)。有關(guān)過度使用 __builtin_assume *函數(shù)可能產(chǎn)生反作用的更多信息,請(qǐng)參閱 LLVM 語言參考手冊(cè) 。引用:
“ 請(qǐng)注意,優(yōu)化器 MIG ht 限制對(duì) llvm.assume 保留僅用于形成內(nèi)在函數(shù)輸入?yún)?shù)的指令。如果用戶提供的額外信息 llvm.assume 內(nèi)在的并不能導(dǎo)致代碼質(zhì)量的全面提高。因此, llvm.assume 不應(yīng)用于記錄優(yōu)化器可以以其他方式推斷的基本數(shù)學(xué)不變量或?qū)?yōu)化器沒有多大用處的事實(shí)。”
某些主機(jī)編譯器可能不支持早期的內(nèi)置函數(shù)。在這種情況下,必須注意在代碼中調(diào)用內(nèi)置函數(shù)的位置。
下表給出了主機(jī)編譯器為 gcc 時(shí)使用 __builtin_assume 的示例。由于 gcc 不支持此內(nèi)置函數(shù),因此在未定義 __CUDA_ARCH__ 宏的主機(jī)編譯階段,對(duì) __builtin_assume 的調(diào)用不應(yīng)出現(xiàn)在 __device__ 函數(shù)之外。

表 1 當(dāng)主機(jī)編譯器不支持內(nèi)置項(xiàng)時(shí),使用內(nèi)置項(xiàng)的示例。
警告可以被抑制或標(biāo)記為錯(cuò)誤
NVCC 現(xiàn)在支持可以用來管理編譯器診斷的命令行選項(xiàng)。您可以選擇讓編譯器隨診斷消息一起發(fā)出錯(cuò)誤號(hào),并指定編譯器應(yīng)將與錯(cuò)誤號(hào)關(guān)聯(lián)的診斷視為錯(cuò)誤還是完全抑制。這些選項(xiàng)不適用于主機(jī)編譯器或預(yù)處理器發(fā)出的診斷。在將來的版本中,編譯器還將支持 pragmas ,以將特定的警告提升到錯(cuò)誤或抑制它們。
Usage
--display-error-number (-err-no)
顯示 CUDA 前端編譯器生成的任何消息的診斷號(hào)。
--diag-error 《error-number》,。。. (-diag-error)
為 CUDA 前端編譯器生成的指定診斷消息發(fā)出錯(cuò)誤。
--diag-suppress 《error-number》,。。. (-diag-suppress)
抑制 CUDA 前端編譯器生成的指定診斷消息。
Example
設(shè)備函數(shù) hdBar 調(diào)用主機(jī)函數(shù) hostFoo 并且變量 i 在 hostFoo 中未使用的示例代碼:
void hostFoo(void)
{
int i = 0;
}
__host__ __device__ void hdBar(bool cond)
{
if (cond)
hostFoo();
}
以下代碼示例顯示帶有默認(rèn)警告的診斷號(hào):
$nvcc -err-no -ptx warn.cu
warn.cu(1): warning #177-D: variable "i" was declared but never referenced
warn.cu(2): warning #20011-D: calling a __host__ function("hostFoo()") from a __host__ __device__ function("hdBar") is not allowed
以下代碼示例將警告# 20011 升級(jí)為錯(cuò)誤:
$nvcc -err-no -ptx -diag-error 20011 warn.cu
warn.cu(1): warning #177-D: variable "i" was declared but never referenced
warn.cu(2): error: calling a __host__ function("hostFoo()") from a __host__ __device__ function("hdBar") is not allowed
以下代碼示例禁止顯示警告# 20011 :
$nvcc -err-no -ptx -diag-suppress 20011 warn.cu warn.cu(1): warning #177-D: variable "i" was declared but never referenced
NVVM 升級(jí)到 LLVM 7.0
CUDA 11. 2 編譯器工具鏈接收 LLVM7.0 升級(jí)。
升級(jí)到 LLVM 7.0 將打開通向此 LLVM 版本中存在的新功能的大門。它通過利用 LLVM 7 中可用的新優(yōu)化,為進(jìn)一步實(shí)現(xiàn)性能調(diào)整工作提供了更堅(jiān)實(shí)的基礎(chǔ)。
圖 8 顯示了使用包含基于 LLVM7 。 0 的高級(jí) NVVM 優(yōu)化器的 11.2 編譯器工具鏈編譯的 HPC 應(yīng)用程序子集對(duì)基于 Volta 和 Ampere 的 GPU 的運(yùn)行時(shí)性能影響,而 11.1 編譯器工具鏈包含基于 LLVM3.4 的高級(jí) NVVM 優(yōu)化器。
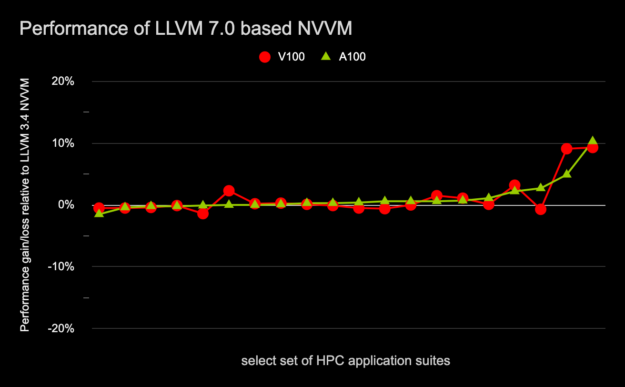
圖 8 HPC 應(yīng)用程序套件的 Geomean 性能增益/損失
相對(duì)于 LLVM3.4 ,基于 A100 和 V100 的 NVVM 。
libnvm 升級(jí)到 LLVM 7 .0
使用 CUDA 11.2 版本, CUDA C ++編譯器, LIbvvm 和 NVRTC 共享庫(kù)都已升級(jí)到 LLVM 7 代碼庫(kù)。 libNVVM 庫(kù)為 LLVM 提供了 GPU 擴(kuò)展,以支持更廣泛的社區(qū),包括編譯器、 DSL 轉(zhuǎn)換器和針對(duì) NVIDIA GPU 上計(jì)算工作負(fù)載的并行應(yīng)用程序。 NVRTC 共享庫(kù)有助于在運(yùn)行時(shí)編譯動(dòng)態(tài)生成的 CUDA C ++源代碼。
由于 libNVVM 庫(kù)包含 llvm7.0 支持, libnvvmapi 和 nvvmir 規(guī)范已修改為與 llvm7.0 兼容。要更新輸入 IR 格式,請(qǐng)參閱已發(fā)布的 NVVM IR 規(guī)范。此 libNVVM 升級(jí)與以前版本中支持的調(diào)試元數(shù)據(jù) IR 不兼容。依賴于調(diào)試元數(shù)據(jù)生成的第三方編譯器應(yīng)該適應(yīng)新的規(guī)范。在這次升級(jí)中, libnvm 也不推薦使用文本 IR 接口。我們建議您使用 LLVM 7.0 位碼格式 。
強(qiáng)。編譯器前端可能需要一個(gè)矮型表達(dá)式來指示在運(yùn)行時(shí)保存變量值的位置。如果沒有對(duì) DWARF 表達(dá)式的適當(dāng)支持,則無法在調(diào)試器中檢查此類變量。 libNVVM 升級(jí)的一個(gè)重要方面是,使用 DWARF 表達(dá)式之類的操作可以更廣泛地表達(dá)這些變量位置。 NVVM IR 現(xiàn)在使用 本質(zhì)與操作 支持此類表達(dá)式。這樣一個(gè)變量的最終位置用這些表達(dá)式用 DWARF 表示
試試 CUDA 11.2 編譯器的功能
CUDA 11.2 工具包包含了一些專注于提高 GPU 性能和提升開發(fā)人員體驗(yàn)的功能。[VZX107 型]
編譯器工具鏈升級(jí)到 LLVM 7 、設(shè)備 LTO 支持和新編譯器內(nèi)置的能力,這些能力可以利用來增強(qiáng) CUDA C ++應(yīng)用程序的性能。
對(duì)內(nèi)聯(lián)設(shè)備函數(shù)的虛擬堆棧回溯支持、關(guān)于函數(shù)內(nèi)聯(lián)決策的編譯器報(bào)告、并行 CUDA 編譯支持以及控制編譯器警告診斷的能力是 CUDA 11.2 工具包中的新功能,旨在提高您的生產(chǎn)效率。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5013瀏覽量
103246 -
編譯器
+關(guān)注
關(guān)注
1文章
1636瀏覽量
49172 -
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13642
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
Triton編譯器如何提升編程效率
Triton編譯器在高性能計(jì)算中的應(yīng)用
Triton編譯器的優(yōu)化技巧
Triton編譯器的優(yōu)勢(shì)與劣勢(shì)分析
Triton編譯器在機(jī)器學(xué)習(xí)中的應(yīng)用
Triton編譯器支持的編程語言
Triton編譯器與其他編譯器的比較
Triton編譯器功能介紹 Triton編譯器使用教程
HighTec C/C++編譯器支持Andes晶心科技RISC-V IP
MSP430優(yōu)化C/C++編譯器v21.6.0.LTS

TMS320C6000優(yōu)化C/C++編譯器v8.3.x
C7000優(yōu)化C/C++編譯器
Keil編譯器優(yōu)化方法
SEGGER編譯器優(yōu)化和安全技術(shù)介紹 支持最新C和C++語言

C語言:嵌入式開發(fā)中的關(guān)鍵編譯器角色





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論