 CUDA和NVIDIA Ampere微體系結構GPUs
CUDA和NVIDIA Ampere微體系結構GPUs
基于 NVIDIA Ampere GPU 架構的新型 NVIDIA A100 GPU 在加速計算方面實現了最大的一代飛躍。 A100 GPU 具有革命性的硬件功能,我們很高興宣布 CUDA 11 與 A100 結合使用。
CUDA 11 使您能夠利用新的硬件功能來加速 HPC 、基因組學、 5G 、渲染、深度學習、數據分析、數據科學、機器人技術和更多不同的工作負載。
CUDA 11 包含了從平臺系統軟件到您開始開發 GPU 加速應用程序所需的所有功能。本文概述了此版本中的主要軟件功能:
支持 NVIDIA Ampere GPU 架構,包括新的 NVIDIA A100 GPU ,用于加速 AI 和 HPC 數據中心的擴展和擴展;具有 NVSwitch 結構的多 GPU 系統,如 DGX A100 型 和 HGX A100 型 。
多實例 GPU ( MIG )分區功能,這對云服務提供商( csp )提高 GPU 利用率特別有利。
新的第三代張量核心加速混合精度,不同數據類型的矩陣運算,包括 TF32 和 Bfloat16 。
用于任務圖、異步數據移動、細粒度同步和二級緩存駐留控制的編程和 API 。
CUDA 庫中用于線性代數、 fft 和矩陣乘法的性能優化。
Nsight 產品系列的更新,用于跟蹤、分析和調試 CUDA 應用程序。
全面支持所有主要的 CPU 體系結構,跨 x86 趶 64 、 Arm64 服務器和電源體系結構。
一篇文章不能公正地反映 CUDA 11 中提供的每一個特性。在這篇文章的最后,有一些鏈接到 GTC 數字會議,這些會議提供了對新的 CUDA 特性的深入探討。
CUDA 和 NVIDIA Ampere微體系結構 GPUs
NVIDIA Ampere GPU 微體系結構采用 TSMC 7nm N7 制造工藝制造,包括更多的流式多處理器( SMs )、更大更快的內存以及與第三代 NVLink 互連帶寬,以提供巨大的計算吞吐量。
A100 的 40 GB ( 5 站點)高速 HBM2 內存的帶寬為 1 。 6 TB /秒,比 V100 快 1 。 7 倍以上。 A100 上 40 MB 的二級緩存幾乎比 Tesla V100 大 7 倍,提供 2 倍以上的二級緩存讀取帶寬。 CUDA 11 在 A100 上提供了新的專用二級緩存管理和駐留控制 API 。 A100 中的短消息包括一個更大更快的一級緩存和共享內存單元(每平方米 192 千字節),提供 1.5 倍于沃爾塔 V100GPU 的總容量。
A100 配備了專門的硬件單元,包括第三代張量核心、更多視頻解碼器( NVDEC )單元、 JPEG 解碼器和光流加速器。所有這些都被各種 CUDA 庫用來加速 HPC 和 AI 應用程序。
接下來的幾節將討論 NVIDIA A100 中引入的主要創新,以及 CUDA 11 如何使您充分利用這些功能。 CUDA 11 為每個人提供了一些東西,無論你是管理集群的平臺 DevOps 工程師,還是編寫 GPU 加速應用程序的軟件開發人員。
多實例
MIG 功能可以將單個 A100 GPU 物理劃分為多個 GPUs 。它允許多個客戶機(如 vm 、容器或進程)同時運行,同時在這些程序之間提供錯誤隔離和高級服務質量( QoS )。

圖 1 A100 中的新 MIG 功能。
A100 是第一款 GPU 可以通過 NVLink 擴展到完整的 GPU ,也可以通過降低每個 GPU 實例的成本,使用 MIG 擴展到許多用戶。 MIG 支持多個用例來提高 GPU 的利用率。這可能是 CSP 租用單獨的 GPU 實例,在 GPU 上運行多個推理工作負載,托管多個 Jupyter 筆記本會話進行模型探索,或者在組織中的多個內部用戶(單個租戶、多用戶)之間共享 GPU 的資源。
nvidia-smi 對 CUDA 是透明的,現有的 CUDA 程序可以在 MIG 下運行,以減少編程工作量。 CUDA 11 允許使用 NVIDIA 管理庫( NVML )或其命令行界面 NVIDIA ( nvidia-smi MIG 子命令)在 Linux 操作系統上配置和管理 MIG 實例。
使用啟用了 MIG 的 集裝箱工具包 和 A100 ,您還可以使用 Docker 運行 GPU 容器(使用從 Docker 19 。 03 開始的 --gpus 選項)或使用 NVIDIA 設備插件 擴展 Kubernetes 容器平臺。
下面的命令顯示了使用 nvidia-smi 進行的 MIG 管理:
# List gpu instance profiles: # nvidia-smi mig -i 0 -lgip +-------------------------------------------------------------------------+ | GPU instance profiles: | | GPU Name ID Instances Memory P2P SM DEC ENC | | Free/Total GiB CE JPEG OFA | |=========================================================================| | 0 MIG 1g.5gb 19 0/7 4.95 No 14 0 0 | | 1 0 0 | +-------------------------------------------------------------------------+ | 0 MIG 2g.10gb 14 0/3 9.90 No 28 1 0 | | 2 0 0 | +-------------------------------------------------------------------------+ | 0 MIG 3g.20gb 9 0/2 19.81 No 42 2 0 | | 3 0 0 | +-------------------------------------------------------------------------+ | 0 MIG 4g.20gb 5 0/1 19.81 No 56 2 0 | | 4 0 0 | +-------------------------------------------------------------------------+ | 0 MIG 7g.40gb 0 0/1 39.61 No 98 5 0 | | 7 1 1 | +-------------------------------------------------------------------------+
系統軟件平臺支持
為企業級應用程序 NVIDIA 引入了新的恢復功能,避免了 NVIDIA A100 對內存使用的影響。先前架構上不可糾正的 ECC 錯誤將影響 GPU 上所有正在運行的工作負載,需要重置 GPU 。
在 A100 上,影響僅限于遇到錯誤并被終止的應用程序,而其他正在運行的 CUDA 工作負載不受影響。 GPU 不再需要重置來恢復。 NVIDIA 驅動程序執行動態頁面黑名單以標記頁面不可用,以便當前和新的應用程序不會訪問受影響的內存區域。
當 GPU 被重置時,作為常規 GPU / VM 服務窗口的一部分, A100 配備了一種稱為行重映射的新硬件機制,它用備用單元替換內存中降級的單元,并避免在物理內存地址空間中造成任何漏洞。
帶有 CUDA 11 的 NVIDIA 驅動程序現在報告了與帶內(使用 NVML / NVIDIA -smi )和帶外(使用系統 BMC )行重映射相關的各種度量。 A100 包括新的帶外功能,包括更多可用的 GPU 和 NVSwitch 遙測、控制和改進的 GPU 和 BMC 之間的總線傳輸數據速率。
為了提高多 GPU 系統(如 DGX A100 和 HGX A100 )的彈性和高可用性,系統軟件支持禁用發生故障的 GPU 或 NVSwitch 節點的能力,而不是像前幾代系統中那樣禁用整個基板。
CUDA 11 是第一個為 Arm 服務器添加生產支持的版本。通過將 Arm 的 節能 CPU 體系結構 與 CUDA 相結合, Arm 生態系統將受益于 GPU ——一種針對各種用例的加速計算:從邊緣、云、游戲到超級計算機。 CUDA 11 支持 Marvell 的高性能 基于 ThunderX2 服務器,并與 Arm 和生態系統中的其他硬件和軟件合作伙伴密切合作,以快速支持 GPUs 。
第三代多精度張量核
NVIDIA A100 中每個 SM 的四個大張量核(總共 432 個張量核)為所有數據類型提供更快的矩陣乘法累加( MMA )操作: Binary 、 INT4 、 INT8 、 FP16 、 Bfloat16 、 TF32 和 FP64 。
您可以通過不同的深度學習框架、 CUDA C ++模板抽象來訪問張量核, CUTLASS 、 CUDA 庫 cuBLAS 、 CuSOLVER 、 CursSuror 或 TensorRT 。
CUDA C ++利用張量矩陣( WMMA ) API 使張量核可用。這種便攜式 API 抽象公開了專門的矩陣加載、矩陣乘法和累加運算以及矩陣存儲操作,以有效地使用 CUDA C ++程序的張量核。 WMMA 的所有函數和數據類型都可以在 nvcuda::wmma 命名空間中使用。您還可以使用 mma_sync PTX 指令直接訪問 A100 的張量核心(即具有計算能力 compute _及更高版本的設備)。
CUDA 11 增加了對新的輸入數據類型格式的支持: Bfloat16 、 TF32 和 FP64 。 Bfloat16 是另一種 FP16 格式,但精度降低,與 FP32 數值范圍匹配。它的使用會降低帶寬和存儲需求,從而提高吞吐量。 BFLAT16 作為一個新的 CUDA C ++ __nv_bfloat16 數據類型在 CUDA α BF16 。 H 中通過 WMMA 公開,并由各種 CUDA 數學庫支持。
TF32 是一種特殊的浮點格式,用于張量核心。 TF32 包括一個 8 位指數(與 FP32 相同)、 10 位尾數(精度與 FP16 相同)和一個符號位。這是默認的數學模式,允許您在不改變模型的情況下,獲得超過 FP32 的 DL 訓練加速。最后, A100 為 MMA 操作帶來了雙精度( FP64 )支持, WMMA 接口也支持這種支持。
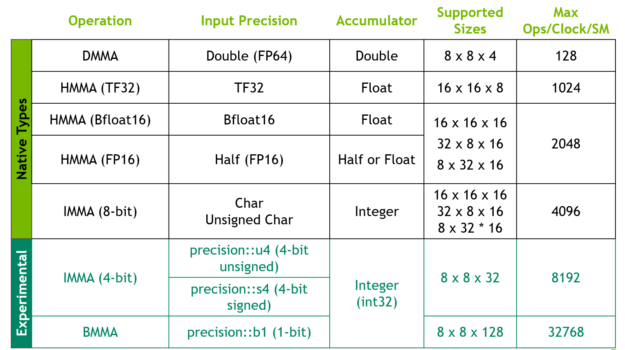
圖 2 矩陣運算支持的數據類型、配置和性能表。
編程 NVIDIA Ampere架構 GPUs
為了提高 GPU 的可編程性和利用 NVIDIA A100 GPU 的硬件計算能力, CUDA 11 包括內存管理、任務圖加速、新指令和線程通信結構的新 API 操作。下面我們來看看這些新操作,以及它們如何使您能夠利用 A100 和 NVIDIA Ampere微體系結構。
內存管理
最大化 GPU 內核性能的優化策略之一是最小化數據傳輸。如果內存駐留在全局內存中,將數據讀入二級緩存或共享內存 MIG ht 的延遲需要幾百個處理器周期。
例如,在 GV100 上,共享內存提供的帶寬比全局內存快 17 倍,比 L2 快 3 倍。因此,一些具有生產者 – 消費者范式的算法可以觀察到在內核之間的 L2 中持久化數據的性能優勢,從而獲得更高的帶寬和性能。
在 A100 上, CUDA 11 提供了 API 操作,以留出 40 MB 二級緩存的一部分來持久化對全局內存的數據訪問。持久訪問優先使用二級緩存的這一預留部分,而全局內存的正常或流式訪問只能在持久訪問未使用的情況下使用這部分二級緩存。
L2 持久性可以設置為在 CUDA 流或 CUDA 圖內核節點中使用。在留出二級緩存區域時,需要考慮一些問題。例如,在不同的流中并發執行的多個 CUDA 內核在具有不同的訪問策略窗口時,共享二級預留緩存。下面的代碼示例顯示為持久性預留二級緩存比率。
cudaGetDeviceProperties( &prop, device_id); // Set aside 50% of L2 cache for persisting accesses size_t size = min( int(prop.l2CacheSize * 0.50) , prop.persistingL2CacheMaxSize ); cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size); // Stream level attributes data structure cudaStreamAttrValue attr ;? attr.accessPolicyWindow.base_ptr = /* beginning of range in global memory */ ;? attr.accessPolicyWindow.num_bytes = /* number of bytes in range */ ;? // hitRatio causes the hardware to select the memory window to designate as persistent in the area set-aside in L2 attr.accessPolicyWindow.hitRatio = /* Hint for cache hit ratio */ // Type of access property on cache hit attr.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting;? // Type of access property on cache miss attr.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; cudaStreamSetAttribute(stream,cudaStreamAttributeAccessPolicyWindow,&attr);
虛擬內存管理 API 操作 已經擴展到支持對固定的 GPU 內存的壓縮,以減少 L2 到 DRAM 的帶寬。這對于深度學習訓練和推理用例非常重要。使用 cuMemCreate 創建可共享內存句柄時,將向 API 操作提供分配提示。
算法(如 3D 模板或卷積)的有效實現涉及內存復制和計算控制流模式,其中數據從全局內存傳輸到線程塊的共享內存,然后進行使用該共享內存的計算。全局到共享內存的復制擴展為從全局內存讀取到寄存器,然后寫入共享內存。
CUDA 11 允許您利用一種新的異步復制( async-copy )范式。它本質上是將數據從全局復制到共享內存與計算重疊,并避免使用中間寄存器或一級緩存。異步復制的好處是:控制流不再遍歷內存管道兩次,不使用中間寄存器可以減少寄存器壓力,增加內核占用。在 A100 上,異步復制操作是硬件加速的。
下面的代碼示例顯示了一個使用異步復制的簡單示例。生成的代碼雖然性能更好,但可以通過對多批異步復制操作進行管道化來進一步優化。這種額外的流水線可以消除代碼中的一個同步點。
異步復制是在 CUDA 11 中作為實驗特性提供的,并且使用協作組集合公開。 CUDA C ++程序設計指南 包括在 A100 中使用多級流水線和硬件加速屏障操作的異步復制的更高級示例。
//Without async-copy using namespace nvcuda::experimental;
__shared__ extern int smem[];? // algorithm loop iteration
?while ( ... ) {? __syncthreads(); // load element into shared mem for ( i = ... ) {? // uses intermediate register // {int tmp=g[i]; smem[i]=tmp;} smem[i] = gldata[i]; ? }?
//With async-copy using namespace nvcuda::experimental;
__shared__ extern int smem[];? pipeline pipe; // algorithm loop iteration
?while ( ... ) {? __syncthreads(); // load element into shared mem for ( i = ... ) {? // initiate async memory copy memcpy_async(smem[i], gldata[i], pipe); ? }? // wait for async-copy to complete pipe.commit_and_wait(); __syncthreads();? /* compute on smem[] */? }?
任務圖加速
CUDA 10 中引入的 CUDA 圖 代表了使用 CUDA 提交工作的新模型。圖由一系列操作組成,如內存拷貝和內核啟動,它們由依賴關系連接,并在執行時單獨定義。
圖形支持定義一次重復運行的執行流。它們可以減少累積的啟動開銷并提高應用程序的整體性能。對于深度學習應用程序來說尤其如此,這些應用程序可能會啟動多個內核,任務大小和運行時會減少,或者任務之間可能存在復雜的依賴關系。
從 A100 開始, GPU 提供任務圖硬件加速來預取網格啟動描述符、指令和常量。與以前的 GPUs 如 V100 相比,在 A100 上使用 CUDA 圖改善了內核啟動延遲。
CUDA Graph API 操作現在有了一個輕量級的機制,可以支持對實例化圖的就地更新,而不需要重新構建圖。在圖的重復實例化過程中,節點參數(如內核參數)通常會在圖拓撲保持不變的情況下發生變化。 Graph API 操作提供了一種更新整個圖形的機制,您可以使用更新的節點參數提供拓撲相同的 cudaGraph_t 對象,或者顯式更新單個節點。
另外, CUDA 圖現在支持協同內核啟動( cuLaunchCooperativeKernel ),包括與 CUDA 流進行奇偶校驗的流捕獲。
線集體
以下是 CUDA 11 添加到 合作小組 中的一些增強,這些增強在 CUDA 9 中引入。協作組是一種集體編程模式,旨在使您能夠顯式地表達線程可以在其中通信的粒度。這使得 CUDA 內的新的協作并行模式得以實現。
在 CUDA 11 中,協作組集體公開了新的 A100 硬件特性,并添加了幾個 API 增強。
A100 引入了一個新的 reduce 指令,它對每個線程提供的數據進行操作。這是一個新的使用協作組的集合,它提供了一個可移植的抽象,也可以在舊的體系結構上使用。 reduce 操作支持算術(例如 add )和邏輯(例如和)操作。下面的代碼示例顯示 reduce 集合。
// Simple Reduction Sum
#include ... const int threadId = cta.thread_rank(); int val = A[threadId]; // reduce across tiled partition reduceArr[threadId] = cg::reduce(tile, val, cg::plus()); // synchronize partition cg::sync(cta); // accumulate sum using a leader and return sum
協作組提供了集體操作( labeled_partition ),將父組劃分為一維子組,在這些子組中線程被合并在一起。這對于試圖通過條件語句的基本塊跟蹤活動線程的控制流特別有用。
例如,可以使用 labeled_partition 在一個 warp 級別組(不限制為 2 的冪)中形成多個分區,并在原子加法操作中使用。 labeled_partition API 操作計算條件標簽,并將具有相同標簽值的線程分配到同一組中。
下面的代碼示例顯示自定義線程分區:
// Get current active threads (that is, coalesced_threads())
cg::coalesced_group active = cg::coalesced_threads(); // Match threads with the same label using match_any() int bucket = active.match_any(value); cg::coalesced_group subgroup = cg::labeled_partition(active, bucket); // Choose a leader for each partition (for example, thread_rank = 0)
// if (subgroup.thread_rank() == 0) { threadId = atomicAdd(&addr[bucket], subgroup.size()); } // Now use shfl to transfer the result back to all threads in partition
return (subgroup.shfl(threadId, 0));
CUDA C ++語言及其編譯器改進
CUDA 11 也是第一個正式將 CUB 作為 CUDA 工具包一部分的版本。 CUB 現在是支持的 CUDA C ++核心庫之一。
CUDA 11 的 nvcc 公司 的一個主要特性是支持鏈路時間優化( LTO ),以提高單獨編譯的性能。 LTO 使用 --dlink-time-opt 或 -dlto 選項,在編譯期間存儲中間代碼,然后在鏈接時執行更高級別的優化,例如跨文件內聯代碼。
nvcc 公司 在 CUDA 11 中添加了對 ISO C ++ 17 的支持,并支持 PGI 、 GCC 、 CLAN 、 ARM 和微軟 VisualStudio 上的新主機編譯器。如果您想嘗試尚未支持的主機編譯器, CUDA 在編譯構建工作流期間支持一個新的 nvcc 公司 標志。 --allow-unsupported-compiler 添加了其他新功能,包括:
改進的 lambda 支持
依賴文件生成增強功能( -MD , -MMD 選項)
傳遞選項到主機編譯器
圖 4 CUDA 11 中的平臺支撐。
CUDA 庫
CUDA 11 中的庫通過使用線性代數、信號處理、基本數學運算和圖像處理中常見的 api 中的最新和最好的 A100 硬件特性,繼續推動性能和開發人員生產力的邊界。
在整個線性代數庫中,您將看到 A100 上提供的全系列精度的張量核心加速度,包括 FP16 、 Bfloat16 、 TF32 和 FP64 。這包括 cuBLAS 中的 BLAS3 運算, cuSOLVER 中的因子分解和稠密線性解算器,以及 cuTENSOR 中的張量收縮。
除了提高精度范圍外,對矩陣維數和張量核心加速度對齊的限制也被取消。為了達到適當的精度,加速現在是自動的,不需要用戶選擇加入。 cuBLAS 的啟發式算法在 A100 上使用 MIG 在 GPU 實例上運行時自動適應資源。
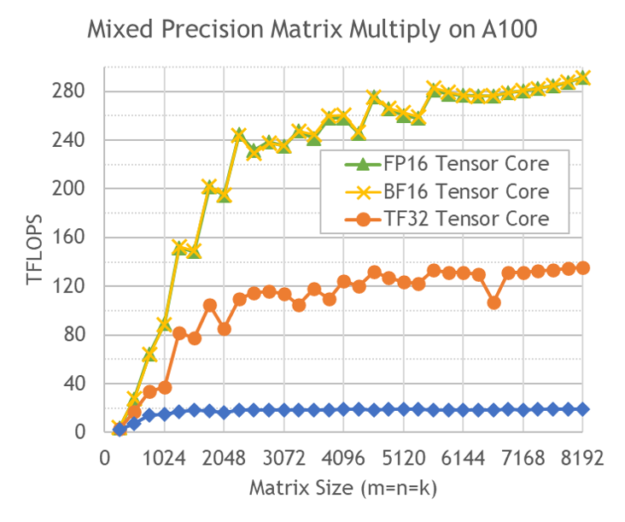
圖 6 用 cuBLAS 對 A100 進行混合精度矩陣乘法。
彎刀 、 CUDA C ++模板用于高性能 GEMM 的抽象,支持 A100 提供的各種精度模式。有了 CUDA 11 , Cutless 現在達到了 95% 以上的性能與 cuBLAS 相當。這允許您編寫您自己的自定義 CUDA 內核來編程 NVIDIA GPUs 中的張量核心。
cuFFT 利用了 A100 中更大的共享內存大小,從而在較大的批處理大小下為單精度 fft 帶來更好的性能。最后,在多個 GPU A100 系統上,與 V100 相比, cuFFT 可擴展并提供 2 倍于 GPU 的性能。
nvJPEG 是一個用于 JPEG 解碼的 GPU 加速庫。它與數據擴充和圖像加載庫 NVIDIA DALI 一起,可以加速圖像分類模型,特別是計算機視覺的深度學習訓練。圖書館加速了深度學習工作流的圖像解碼和數據擴充階段。
A100 包括一個 5 核硬件 JPEG 解碼引擎, nvJPEG 利用硬件后端對 JPEG 圖像進行批處理。專用硬件塊的 JPEG 加速緩解了 CPU 上的瓶頸,并允許更好的 GPU 利用率。
選擇硬件解碼器是由給定圖像的 nvjpegDecode 自動完成的,或者通過使用 nvjpegCreateEx init 函數顯式選擇硬件后端來完成的。 nvJPEG 提供基線 JPEG 解碼的加速,以及各種顏色轉換格式,例如 yuv420 、 422 和 444 。
圖 8 顯示,與僅使用 CPU 處理相比,這將使圖像解碼速度提高 18 倍。如果您使用 DALI ,您可以直接受益于這種硬件加速,因為 nvJPEG 是抽象的。
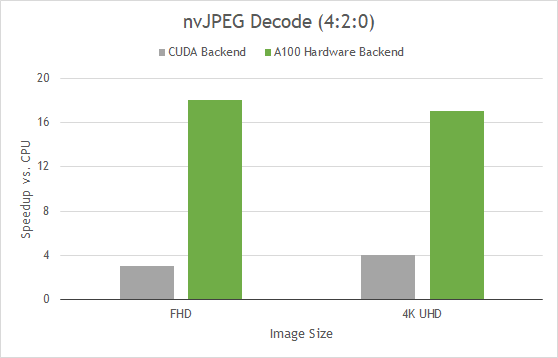
圖 9 nvJPEG 加速比 CPU 。
(第 128 批使用 Intel Platinum 8168 @ 2GHz 3 。 7GHz Turbo HT ;使用 TurboJPEG )
在 CUDA 數學庫中,有許多特性比一篇文章所能涵蓋的還要多。
開發人員工具
CUDA 11 繼續為現有的開發人員工具組合添加豐富的功能,其中包括熟悉的 Visual Studio 插件和 NVIDIA Nsight 集成 for Visual Studio ,以及 Eclipse 和 Nsight Eclipse 插件版。它還包括獨立的工具,如用于內核評測的 Nsight Compute 和用于系統范圍性能分析的 Nsight 系統。 Nsight Compute 和 Nsight 系統現在在 CUDA 支持的三種 CPU 架構上都得到支持: x86 、 POWER 和 Arm64 。
Nsight Compute for CUDA 11 的一個關鍵特性是能夠生成應用程序的屋頂線模型。 Roofline 模型是一種直觀直觀的方法,可以讓您通過將浮點性能、算術強度和內存帶寬組合到二維圖中來了解內核特性。
通過查看 Roofline 模型,可以快速確定內核是受計算限制還是內存受限。您還可以了解進一步優化的潛在方向,例如,靠近屋頂線的內核可以優化利用計算資源。
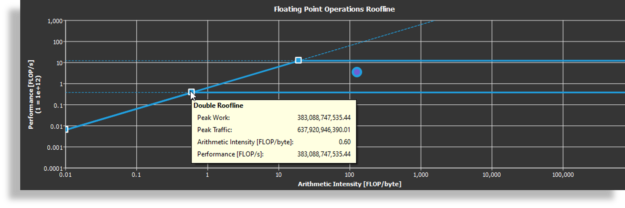
圖 11 Nsight 計算中的屋頂線模型。
CUDA 11 包括 Compute Sanitizer ,這是下一代的功能正確性檢查工具,它為內存訪問和競爭條件提供運行時檢查。 Compute Sanitizer 旨在替代 cuda-memcheck 工具。
下面的代碼示例顯示了計算消毒劑檢查內存訪問的示例。
//Out-of-bounds Array Access __global__ void oobAccess(int* in, int* out)
{ int bid = blockIdx.x; int tid = threadIdx.x; if (bid == 4) { out[tid] = in[dMem[tid]]; }
} int main()
{ ... // Array of 8 elements, where element 4 causes the OOB std::array hMem = {0, 1, 2, 10, 4, 5, 6, 7}; cudaMemcpy(d_mem, hMem.data(), size, cudaMemcpyHostToDevice); oobAccess<<<10, Size>>>(d_in, d_out); cudaDeviceSynchronize(); ... $ /usr/local/cuda-11.0/Sanitizer/compute-sanitizer --destroy-on-device-error kernel --show-backtrace no basic
========= COMPUTE-SANITIZER
Device: Tesla T4
========= Invalid __global__ read of size 4 bytes
========= at 0x480 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Memcheck/basic/basic.cu:40:oobAccess(int*,int*)
========= by thread (3,0,0) in block (4,0,0)
========= Address 0x7f551f200028 is out of bounds
下面的代碼示例顯示了用于競爭條件檢查的計算消毒劑示例。
//Contrived Race Condition Example __global__ void Basic()
{ __shared__ volatile int i; i = threadIdx.x;
} int main()
{ Basic<<<1,2>>>(); cudaDeviceSynchronize(); ... $ /usr/local/cuda-11.0/Sanitizer/compute-sanitizer --destroy-on-device-error kernel --show-backtrace no --tool racecheck --racecheck-report hazard raceBasic
========= COMPUTE-SANITIZER
========= ERROR: Potential WAW hazard detected at __shared__ 0x0 in block (0,0,0) :
========= Write Thread (0,0,0) at 0x100 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Racecheck/raceBasic/raceBasic.cu:11:Basic(void)
========= Write Thread (1,0,0) at 0x100 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Racecheck/raceBasic/raceBasic.cu:11:Basic(void)
========= Current Value : 0, Incoming Value : 1
=========
========= RACECHECK SUMMARY: 1 hazard displayed (1 error, 0 warnings)
最后,盡管 CUDA 11 不再支持在 macOS 上運行應用程序,但我們正在為 macOS 主機上的用戶提供開發工具:
使用 cuda-gdb 進行遠程目標調試
NVIDIA Visual Profiler
Nsight Eclipse 插件
用于遠程分析或跟蹤的 Nsight 工具系列
摘要
CUDA 11 為在 NVIDIA A100 上構建應用程序提供了基礎開發環境,用于構建 NVIDIA Ampere GPU 體系結構和強大的服務器平臺,用于 AI 、數據分析和 HPC 工作負載,這些平臺均用于內部( DGX A100 型 )和云( HGX A100 型 )部署。
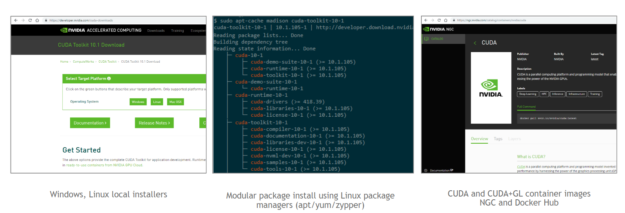
圖 12 得到 CUDA 11 的不同方法。
CUDA 11 現在可用。和往常一樣,您可以通過多種方式獲得 CUDA 11 : 下載 本地安裝程序包,使用包管理器進行安裝,或者從各種注冊中心獲取容器。對于企業部署, CUDA 11 還包括 RHEL8 的 驅動程序打包改進 ,使用模塊化流來提高穩定性并減少安裝時間。
關于作者
Pramod Ramarao 是 NVIDIA 加速計算的產品經理。他領導 CUDA 平臺和數據中心軟件的產品管理,包括容器技術。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4994瀏覽量
103195 -
gpu
+關注
關注
28文章
4743瀏覽量
129008 -
CUDA
+關注
關注
0文章
121瀏覽量
13641
發布評論請先 登錄
相關推薦
【「RISC-V體系結構編程與實踐」閱讀體驗】-- SBI及NEMU環境
【「RISC-V體系結構編程與實踐」閱讀體驗】-- 前言與開篇

名單公布!【書籍評測活動NO.45】RISC-V體系結構編程與實踐(第二版)
嵌入式系統的體系結構包括哪些
工業控制計算機的體系結構是什么
嵌入式微處理器體系結構 嵌入式微處理器原理與應用
NVIDIA推出兩款基于NVIDIA Ampere架構的全新臺式機GPU
嵌入式微處理器體系結構有幾種
WiMAX MAC層基礎知識:WiMAX網絡體系結構

智能化的計算機體系結構設計方案
《RVfpga:理解計算機體系結構》3.0 版本更新上線






 工商網監
工商網監
評論