 如何使用DPDK和GPUdev增強內聯數據包處理
如何使用DPDK和GPUdev增強內聯數據包處理
使用 GPU 對網絡數據包進行內聯處理是一種數據包分析技術,可用于許多不同的應用領域:信號處理、網絡安全、信息收集、輸入重建等。
這些應用程序類型的主要要求是盡快將接收到的數據包移動到 GPU 內存中,以觸發負責對其執行并行處理的 CUDA 內核。
總體思路是創建一個連續的異步管道,能夠將數據包從網卡直接接收到 GPU 內存中。您還可以使用 CUDA 內核來處理傳入的數據包,而無需同步 GPU 和 CPU 。
有效的應用程序工作流包括使用無鎖通信機制在以下播放器組件之間創建一個協調的連續異步管道:
network controller 向 GPU 內存提供接收到的網絡數據包
CPU 用于查詢網絡控制器以獲取有關接收到的數據包的信息
GPU 用于接收數據包信息并直接將其處理到 GPU 內存中
圖 1 顯示了使用 NVIDIA GPU 和 ConnectX 網卡的加速內聯數據包處理應用程序的典型數據包工作流場景。
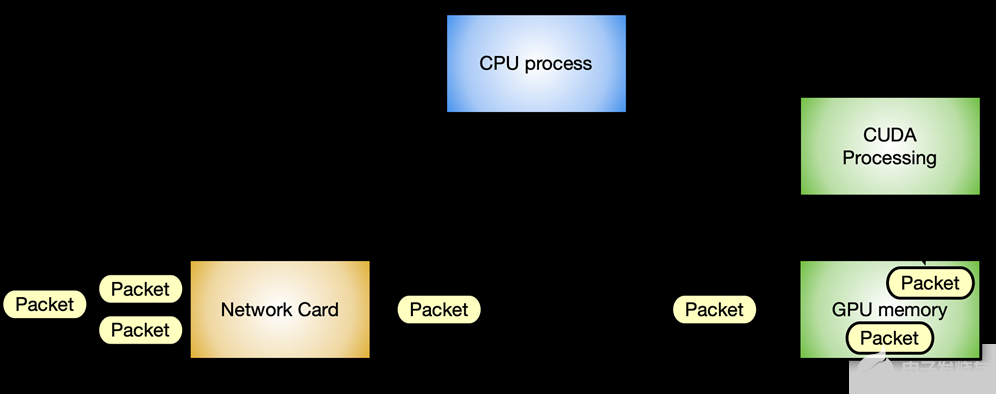
圖 1 。典型的內聯數據包處理工作流場景
在這種情況下,避免延遲是至關重要的。不同組件之間的通信越優化,系統的響應速度就越快,吞吐量也就越高。每一步都必須在所需資源可用時以內聯方式進行,而不會阻塞任何其他等待的組件。
您可以清楚地識別兩種不同的流:
Data flow :通過 PCIe 總線在網卡和 GPU 之間交換優化的數據(網絡數據包)。
Control flow : CPU 協調 GPU 和網卡。
數據流
關鍵是優化網絡控制器和 GPU 之間的數據移動(發送或接收數據包)。它可以通過 GPUDirect RDMA 技術實現,該技術使用 PCI Express 總線接口的標準功能,在 NVIDIA GPU 和第三方對等設備(如網卡)之間實現直接數據路徑。
GPUDirect RDMA 依賴于 NVIDIA GPU 在 PCI Express 基址寄存器( BAR )區域上公開部分設備內存的能力。有關更多信息,請參閱 CUDA 工具包文檔中的 使用 GPUDirect-RDMA 開發 Linux 內核模塊 。 在現代服務器平臺上對 GPUDirect-RDMA 進行基準測試 文章對使用不同系統拓撲的標準 IB 謂詞執行網絡操作(發送和接收)時的 GPUDirect RDMA 帶寬和延遲進行了更深入的分析。
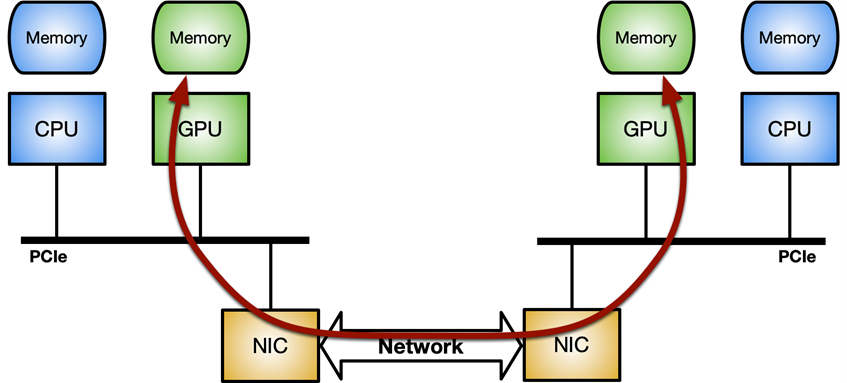
圖 2 。 NVIDIA GPUDirect RDMA 使用 PCI Express 的標準功能,為 GPU 和第三方對等設備之間的數據交換提供了直接路徑
要在 Linux 系統上啟用 GPUDirect RDMA ,需要 nvidia-peermem 模塊(在 CUDA 11.4 及更高版本中提供)。圖 3 顯示了最大化 GPUDirect RDMA 內部吞吐量的理想系統拓撲:在 GPU 和 NIC 之間使用專用 PCIe 交換機,而不是通過與其他組件共享的系統 PCIe 連接。
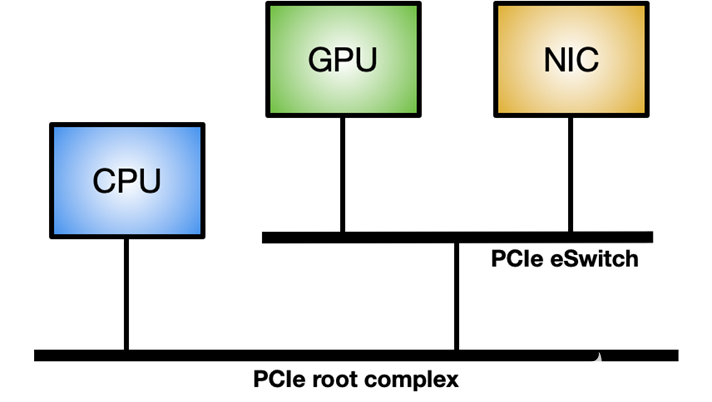
圖 3 。理想的拓撲結構,最大限度地提高網絡控制器和 GPU 之間的內部數據吞吐量
控制流
CPU 是網絡控制器和 GPU 之間協調和同步活動的主要參與者,用于喚醒 NIC ,將數據包接收到 GPU 內存中,并通知 CUDA 工作負載有新數據包可供處理。
在處理 GPU 時,強調 CPU 和 GPU 之間的異步非常重要。例如,假設一個簡單的應用程序在主循環中執行以下三個步驟:
接收數據包。
處理數據包。
發回修改過的數據包。
在本文中,我將介紹在這種應用程序中實現控制流的四種不同方法,包括優缺點。
方法 1
圖 4 顯示了最簡單但最不有效的方法:單個 CPU 線程負責接收數據包,啟動 CUDA 內核來處理它們,等待 CUDA 內核完成,并將修改后的數據包發送回網絡控制器。

圖 4 。單個 CPU 將數據包傳遞到 CUDA 內核并等待完成以執行下一步的工作流
如果數據包處理不是那么密集,那么這種方法的性能可能會比只使用 CPU 處理數據包而不使用 GPU 更差。例如,您可能具有高度的并行性來解決數據包上的一個困難且耗時的算法。
方法 2
在這種方法中,應用程序將 CPU 工作負載分成兩個 CPU 線程:一個用于接收數據包并啟動 GPU 處理,另一個用于等待 GPU 處理完成并通過網絡傳輸修改后的數據包(圖 5 )。
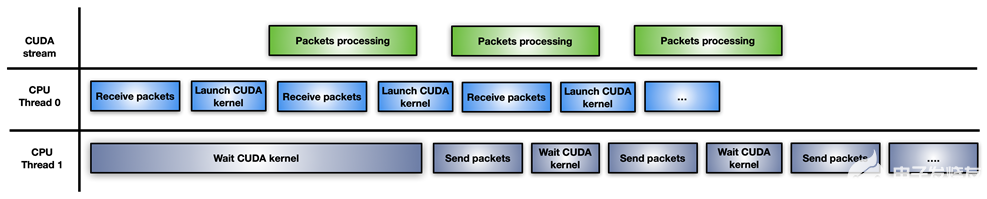
圖 5 。拆分 CPU 線程以通過 GPU 處理數據包
這種方法的一個缺點是,每次累積數據包的突發都會啟動一個新的 CUDA 內核。 CPU 必須為每次迭代支付 CUDA 內核啟動延遲。如果 GPU 被淹沒,數據包處理可能不會立即執行,從而導致延遲。
方法 3
圖 6 顯示了第三種方法,它涉及使用 CUDA 持久內核。
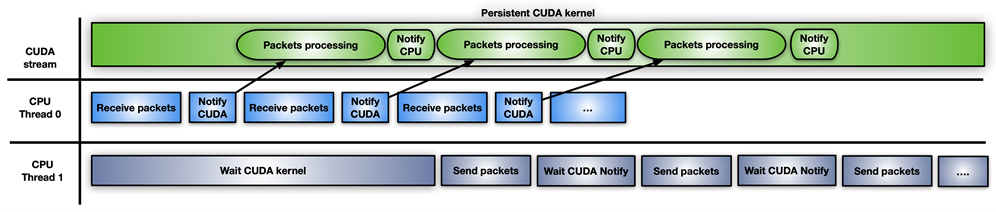
圖 6 。使用持久 CUDA 內核進行內聯數據包處理。
CUDA 持久內核是一個預啟動的內核,它正忙著等待來自 CPU 的通知:新數據包已經到達并準備好進行處理。當數據包準備好后,內核通知第二個 CPU 線程它可以向前發送數據包。
實現此通知系統的最簡單方法是使用忙等待標志更新機制在 CPU 和 GPU 之間共享一些內存。雖然 GPUDirect RDMA 旨在從第三方設備直接訪問 GPU 內存,但您可以使用這些 API 創建 GPU 內存的完全有效的 CPU 映射。 CPU 驅動的拷貝的優點是所涉及的開銷小。現在可以通過 GDRCopy 庫啟用此功能。
直接映射 GPU 內存進行信令,可以從 CPU 修改內存,并在輪詢期間降低 GPU 的延遲成本。您也可以將該標志放在從 GPU 可見的 CPU 固定內存中,但 CUDA 內核輪詢 CPU 內存標志將消耗更多 PCIe 帶寬并增加總體延遲。
這種快速解決方案的問題在于它有風險,而且 CUDA 編程模型不支持它。 GPU 內核不能被搶占。如果寫得不正確,持久內核可能會永遠循環。此外,長期運行的持久內核可能會失去與其他 CUDA 內核、 CPU 活動、內存分配狀態等的同步。
它還擁有 GPU 資源(例如,流式多處理器),如果 GPU 真的忙于其他任務,這可能不是最好的選擇。如果您使用 CUDA 持久內核,那么您的應用程序必須具有良好的處理能力。
方法 4
最后一種方法是前兩種方法的混合解決方案:使用 CUDA 流內存操作 要等待或更新通知標志,請在 CUDA 流上預啟動一個 CUDA 內核,每接收一組數據包。
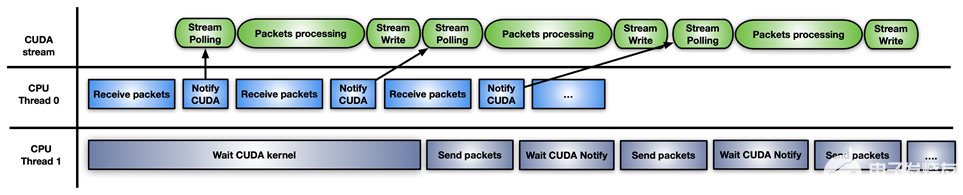
圖 7 。使用模型組合的內聯數據包處理的混合方法
這種方法的不同之處在于 GPU HW (使用cuStreamWaitValue)輪詢內存標志,而不是阻塞 GPU 流式多處理器,并且只有在數據包準備就緒時才會觸發數據包的處理內核。
類似地,當處理內核結束時,cuStreamWriteValue通知負責發送數據包的 CPU 線程數據包已被處理。
這種方法的缺點是,應用程序必須不時地用cuStreamWriteValue+cuStreamWaitValue內核+ CUDA 的新序列重新填充 GPU ,以避免在空流沒有準備好處理更多數據包的情況下浪費執行時間。這里的 CUDA 圖是在流上重新發布的好方法。
不同的方法適用于不同的應用程序模式。
DPDK 和 GPUdev
數據平面開發工具包 ( DPDK )是一組庫,用于幫助加速在各種 CPU 體系結構和不同設備上運行的數據包處理工作負載。
在 DPDK 21.11 中, NVIDIA 引入了一個名為 GPUdev 的新庫,以在 DPDK 的上下文中引入 GPU 的概念,并增強 CPU 、網卡和 GPU 之間的對話。 GPUdev 在 DPDK 22.03 中擴展了更多功能。
圖書館的目標如下:
介紹從 DPDK 通用庫管理的 GPU 設備的概念。
實現基本的 GPU 內存交互,隱藏特定于 GPU 的實現細節。
減少網卡、 GPU 設備和 CPU 之間的間隙,增強通信。
將 DPDK 集成簡化為 GPU 應用程序。
通過通用層公開 GPU 特定于驅動程序的功能。
對于特定于 NVIDIA 的 GPU , GPUdev 庫功能通過 CUDA 驅動程序 DPDK 庫 。要為 NVIDIA GPU 啟用所有gpudev可用功能, DPDK 必須構建在具有 CUDA 庫和 GDRCopy 的系統上。
有了這個新庫提供的功能,您可以輕松地通過 GPU 實現內聯數據包處理,同時處理數據流和控制流。
DPDK 在 mempool 中接收數據包,這是一個連續的內存塊。通過以下指令序列,您可以啟用 GPUDirect RDMA 在 GPU 內存中分配 mempool ,并將其注冊到設備網絡中。
struct rte_pktmbuf_extmem gpu_mem; gpu_mem.buf_ptr = rte_gpu_mem_alloc(gpu_id, gpu_mem.buf_len, alignment)); /* Make the GPU memory visible to DPDK */ rte_extmem_register(gpu_mem.buf_ptr, gpu_mem.buf_len, NULL, gpu_mem.buf_iova, NV_GPU_PAGE_SIZE); /* Create DMA mappings on the NIC */ rte_dev_dma_map(rte_eth_devices[PORT_ID].device, gpu_mem.buf_ptr, gpu_mem.buf_iova, gpu_mem.buf_len)); /* Create the actual mempool */ struct rte_mempool *mpool = rte_pktmbuf_pool_create_extbuf(... , &gpu_mem, ...);
圖 8 顯示了 mempool 的結構:
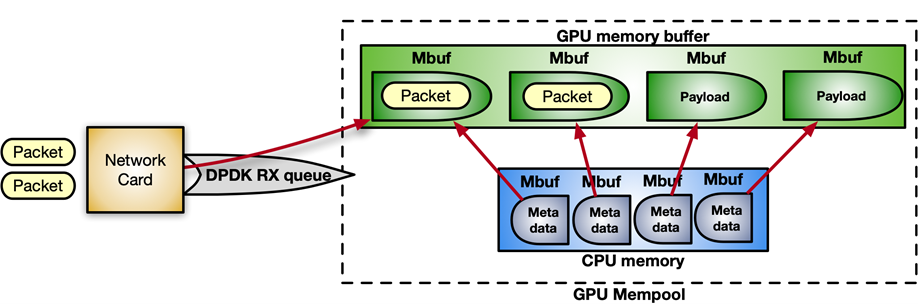
圖 8 用于內聯數據包處理的 mempool 結構
對于控制流,要啟用 CPU 和 GPU 之間的通知機制,可以使用gpudev通信列表:在 CPU 內存和 CUDA 內核之間的共享內存結構。列表中的每一項都可以保存接收到的數據包的地址(mbufs),以及一個用于更新處理該項狀態的標志(數據包就緒、處理完成等)。
struct rte_gpu_comm_list { /** DPDK GPU ID that will use the communication list. */ uint16_t dev_id; /** List of mbufs populated by the CPU with a set of mbufs. */ struct rte_mbuf **mbufs; /** List of packets populated by the CPU with a set of mbufs info. */ struct rte_gpu_comm_pkt *pkt_list; /** Number of packets in the list. */ uint32_t num_pkts; /** Status of the packets’ list. CPU pointer. */ enum rte_gpu_comm_list_status *status_h; /** Status of the packets’ list. GPU pointer. */ enum rte_gpu_comm_list_status *status_d;
};
偽代碼示例:
struct rte_mbuf * rx_mbufs[MAX_MBUFS]; int item_index = 0; struct rte_gpu_comm_list *comm_list = rte_gpu_comm_create_list(gpu_id, NUM_ITEMS); while(exit_condition) { ... // Receive and accumulate enough packets nb_rx += rte_eth_rx_burst(port_id, queue_id, &(rx_mbufs[0]), rx_pkts); // Populate next item in the communication list. rte_gpu_comm_populate_list_pkts(&(p_v->comm_list[index]), rx_mbufs, nb_rx); ... index++; }
為簡單起見,假設應用程序遵循 CUDA 持久內核場景, CUDA 內核上的輪詢端看起來類似于以下代碼示例:
__global__ void cuda_persistent_kernel(struct rte_gpu_comm_list *comm_list, int comm_list_entries) { int item_index = 0; uint32_t wait_status; /* GPU kernel keeps checking exit condition as it can’t be preempted. */ while (!exit_condition()) { wait_status = RTE_GPU_VOLATILE(comm_list[item_index].status_d[0]); if (wait_status != RTE_GPU_COMM_LIST_READY) continue; if (threadIdx.x < comm_list[item_index]->num_pkts) { /* Each CUDA thread processes a different packet. */ packet_processing(comm_list[item_index]->addr, comm_list[item_index]->size, ..); } __syncthreads(); /* Notify packets in the items have been processed */ if (threadIdx.x == 0) { RTE_GPU_VOLATILE(comm_list[item_index].status_d[0]) = RTE_GPU_COMM_LIST_DONE; __threadfence_system(); } /* Wait for new packets on the next communication list entry. */ item_index = (item_index+1) % comm_list_entries; } }

圖 9 持久內核中輪詢端偽代碼的工作流示例
NVIDIA 使用 DPDK gpudev庫進行內聯數據包處理的一個具體用例位于 空中應用框架 中,用于構建高性能、軟件定義的 5G 應用程序。在這種情況下,必須在 GPU 內存中接收數據包,并根據 5G 特定的數據包頭重新排序,這樣可以在重新排序的有效負載上開始信號處理。
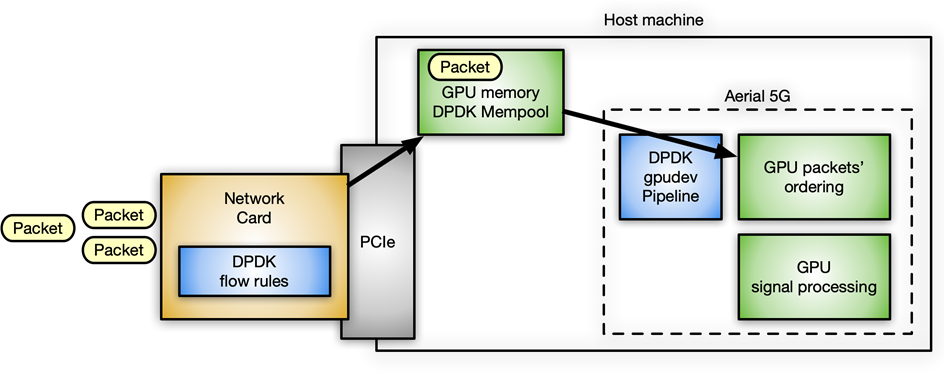
圖 10 使用 DPDK 的內聯數據包處理用例 gpudev 在空中 5G 軟件中
l2fwd nv 應用程序
為了提供如何實現內聯數據包處理和使用 DPDK gpudev庫的實際示例,l2fwd-nv示例代碼已在 /NVIDIA/l2fwd-nv GitHub repo 上發布。這是使用 GPU 功能增強的普通 DPDK l2fwd示例的擴展。應用程序布局是接收數據包,交換每個數據包的 MAC 地址(源和目的地),并傳輸修改后的數據包。
L2fwd-nv為本文討論的所有方法提供了一個實現示例,以供比較:
CPU 僅限
CUDA 每組數據包的內核數
CUDA 持久內核
CUDA 圖
例如,圖 11 顯示了帶有 DPDK gpudev對象的 CUDA 持久內核的時間線。
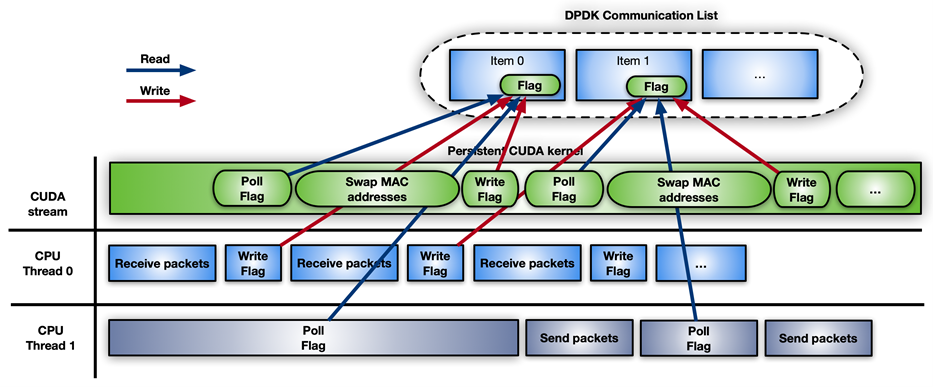
圖 11 使用 DPDK 的 CUDA 持久內核的時間線示例gpudev objects
為了測量l2fwd-nv相對于 DPDK testpmd數據包生成器的性能,圖 12 中使用了兩個與 CPU 背靠背連接的千兆字節服務器: Intel Xeon Gold 6240R 、 PCIe gen3 專用交換機、 Ubuntu 20.04 、 MOFED 5.4 和 CUDA 11.4 。
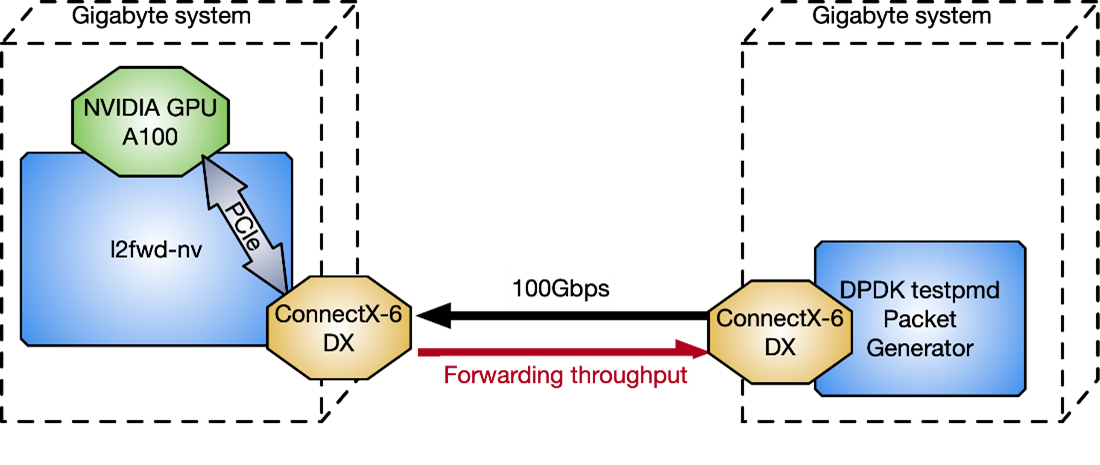
圖 12 測試 l2fwd nv 性能的兩個千兆字節服務器配置
圖 13 顯示,當為數據包使用 CPU 或 GPU 內存時,峰值 I / O 吞吐量是相同的,因此使用其中一個不會帶來固有的損失。這里的數據包被轉發而不被修改。
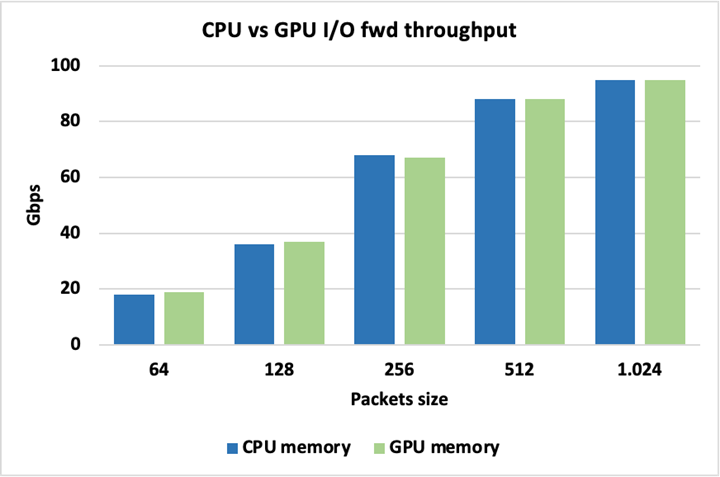
圖 13 峰值 I / O 吞吐量是相同的
為了突出不同 GPU 數據包處理方法之間的差異,圖 14 顯示了方法 2 ( CUDA 內核/數據包集)和方法 3 ( CUDA 持久內核)之間的吞吐量比較。這兩種方法都將數據包大小保持在 1024 字節,在觸發 GPU 工作以交換數據包的 MAC 地址之前,改變累積數據包的數量。
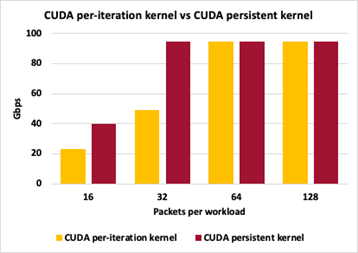
圖 14 GPU 數據包處理方法之間的差異
對于這兩種方法,每次迭代 16 個數據包會導致控制平面中的交互過多,并且無法達到峰值吞吐量。由于每次迭代 32 個數據包,持久化內核可以跟上峰值吞吐量,而每次迭代的單個啟動仍然有太多的控制平面開銷。對于每次迭代 64 和 128 個數據包,這兩種方法都能夠達到峰值 I / O 吞吐量。這里的吞吐量測量不是零丟失數據包。
結論
在本文中,我討論了使用 GPU 優化內聯數據包處理的幾種方法。根據應用程序的需要,您可以應用多個工作流模型,以減少延遲,從而提高性能。 DPDK gpudev 庫還有助于簡化您的編碼工作,以在最短的時間內獲得最佳結果。
其他需要考慮的因素,取決于應用程序,包括在觸發數據包處理之前,在接收端積累足夠的數據包需要花費多少時間,有多少線程可用于盡可能多地增強不同任務之間的并行性,以及內核在執行中應該持續多長時間。
關于作者
Elena Agostini與意大利國家研究委員會( National Research Council of Italy )合作,獲得了羅馬大學( University of Rome “ La Sapienza ”)計算機科學與工程博士學位。她目前是 NVIDIA 的高級軟件工程師。她的研究興趣包括高性能互連、 GPUDirect 技術、網絡協議、快速數據包處理和 DOCA 。 Elena 目前的重點是應用于 Aeror 的 NVIDA GPUDirect 技術,這是一組 SDK ,可實現 GPU 加速、軟件定義的 5G 無線 RAN 。她也是 DPDK 的撰稿人。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
4981瀏覽量
103000 -
gpu
+關注
關注
28文章
4729瀏覽量
128902 -
CUDA
+關注
關注
0文章
121瀏覽量
13620
發布評論請先 登錄
相關推薦
mtu配置步驟詳解 mtu與數據包丟失的關系
艾體寶干貨 OIDA之四:掌握數據包分析-分析的藝術
esp8266怎么做才能每秒發送更多的數據包呢?
使用AT SAVETRANSLINK時UDP數據包丟失怎么解決?
能否在ESP結束之前通過串行端口停止傳入的UDP數據包的傳輸以解析下一個UDP數據包?
如何直接從phy mac層發送和接收802.11數據包?
請問如何使用AT CIPSEND或AT CIPSENDBUF發送多個數據包?
如何在AIROC GUI上獲取良好數據包和總數據包?
請問高端網絡芯片如何處理數據包呢?
物聯數據棧網關是什么?
STM32H7接收數據包異常,一包接收的數據出現兩包發送的內容怎么解決?
DPDK在AI驅動的高效數據包處理應用






 工商網監
工商網監
評論