


在最近的計算機視覺研究中,ViT的出現迅速改變了各種架構設計工作:ViT利用自然語言處理中的Self-Attention實現了最先進的圖像分類性能,MLP-Mixer利用簡單的多層感知器也實現了具有競爭性的結果。相比之下,一些研究也表明,精心設計的卷積神經網絡(CNNs)可以實現媲美ViT的先進性能,而無需借助這些新想法。在這種背景下,人們對什么是適合于計算機視覺的歸納偏差越來越感興趣。
在這里,作者提出Sequencer,一個全新且具有競爭性的架構,可以替代ViT,為分類問題提供了一個全新的視角。與ViT不同,Sequencer使用LSTM(而不是Self-Attention)對遠程依賴關系進行建模。
作者還提出了一個二維的Sequencer模塊,其中一個LSTM被分解成垂直和水平的LSTM,以提高性能。
雖然結構簡單,但是經過實驗表明,Sequencer的表現令人印象深刻:Sequencer2D-L在ImageNet-1K上僅使用54M參數,實現84.6%的top-1精度。不僅如此,作者還證明了它在雙分辨率波段上具有良好的可遷移性和穩健性。
1背景
Vision Transformer成功的原因被認為是由于Self-Attention建模遠程依賴的能力。然而,Self-Attention對于Transformer執行視覺任務的有效性有多重要還不清楚。事實上,只基于多層感知器(MLPs)的MLP-Mixer被提議作為ViTs的一個有吸引力的替代方案。
此外,一些研究表明,精心設計的CNN在計算機視覺方面仍有足夠的競爭力。因此,確定哪些架構設計對計算機視覺任務具有內在的有效性是當前研究的一大熱點。本文通過提出一種新穎的、具有競爭力的替代方案,為這一問題提供了一個新的視角。
本文提出了Sequencer體系結構,使用LSTM(而不是Self-Attention)進行序列建模。Sequencer的宏觀架構設計遵循ViTs,迭代地應用Token Mixing和Channel Mixing,但Self-Attention被基于LSTMs的Self-Attention層取代。特別是,Sequencer使用BiLSTM作為一個構建塊。簡單的BiLSTM表現出一定的性能水平,而Sequencer可以通過使用類似Vision Permutator(ViP)的思想進一步提高。ViP的關鍵思想是平行處理垂直軸和水平軸。
作者還引入了2個BiLSTM,用于并行處理上/下和左/右方向。這種修改提高了Sequencer的效率和準確性,因為這種結構減少了序列的長度,并產生一個有空間意義的感受野。
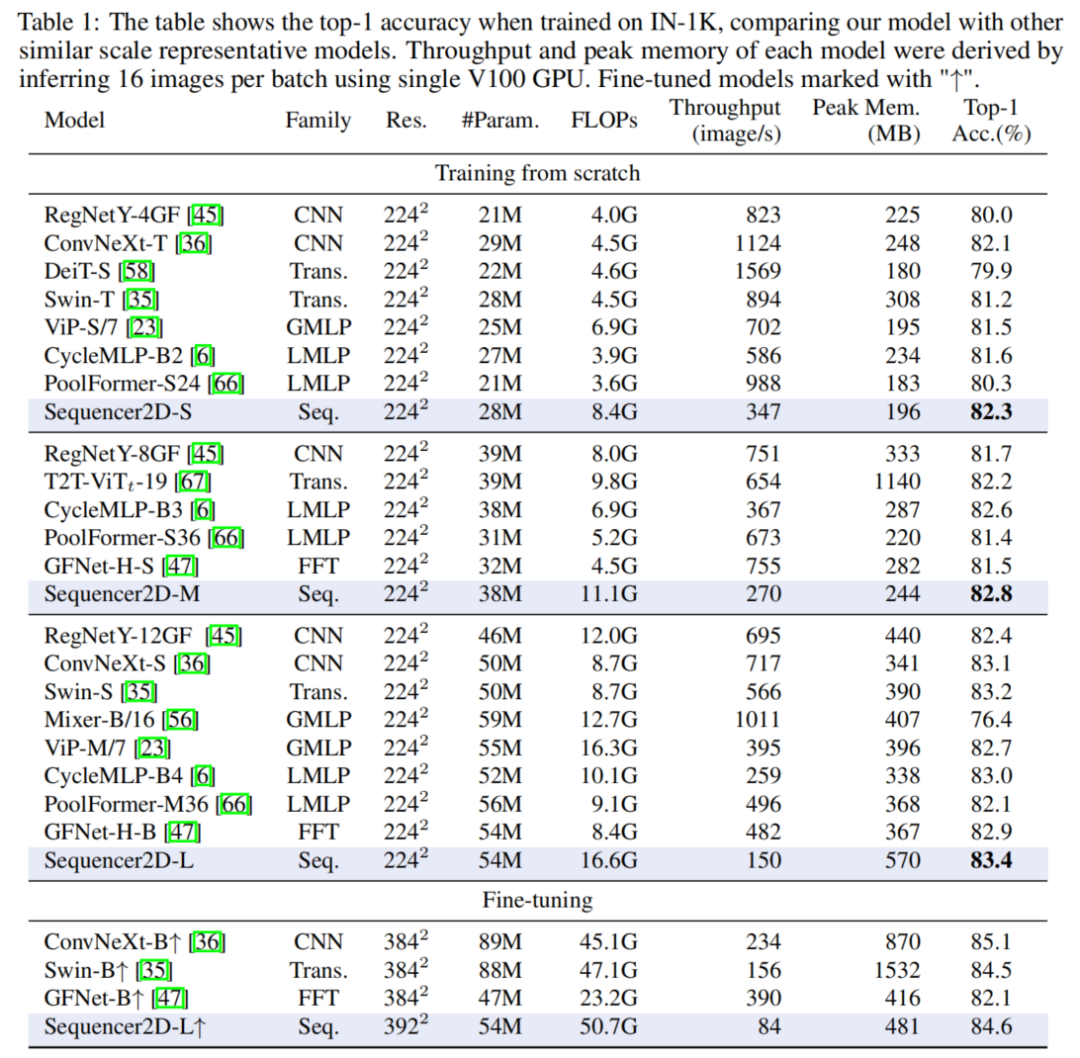
在ImageNet-1K數據集上進行預訓練時,新的Sequencer架構的性能優于類似規模的Swin和ConvNeXt等高級架構。它還優于其他無注意力和無CNN的架構,如MLP-Mixer和GFNet,使Sequencer在視覺任務中的Self-Attention具有吸引力的新替代方案。
值得注意的是,Sequencer還具有很好的領域穩健性以及尺度穩定性,即使在推理過程中輸入的分辨率增加了一倍,也能強烈防止精度退化。此外,對高分辨率數據進行微調的Sequencer可以達到比Swin-B更高的精度。在峰值內存上,在某些情況下,Sequencer往往比ViTs和cnn更經濟。雖然由于遞歸,Sequencer需要比其他模型更多的FLOPs,但更高的分辨率提高了峰值內存的相對效率,提高了在高分辨率環境下的精度/成本權衡。因此,Sequencer作為一種實用的圖像識別模型也具有吸引人的特性。
2全新范式
2.1 LSTM的原理
LSTM是一種特殊的遞歸神經網絡(RNN),用于建模序列的長期依賴關系。Plain LSTM有一個輸入門,它控制存儲輸入,一個控制前單元狀態的遺忘的遺忘門,以及一個輸出門,它控制當前單元狀態的單元輸出。普通LSTM的公式如下:
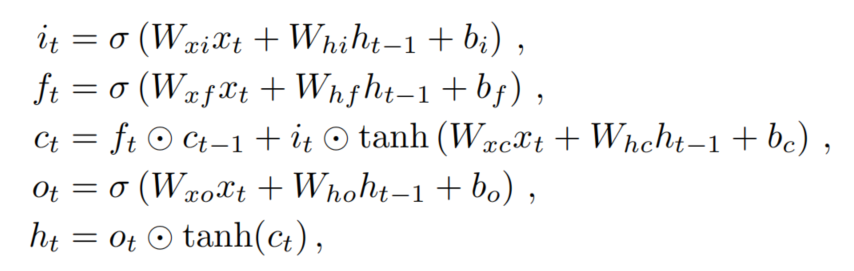
其中σ是logistic sigmoid function,是Hadamard product。
BiLSTM對于預期相互依賴的序列是有利的。一個BiLSTM由2個普通的LSTM組成。設為輸入,為反向重排。和分別是用相應的LSTM處理和得到的輸出。設為按原順序重新排列的輸出,BiLSTM的輸出如下:
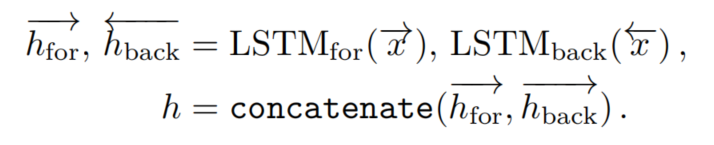
假設和具有相同的隱藏維數D,這是BiLSTM的超參數。因此,向量h的維數為二維。
2.2 Sequencer架構
1、架構總覽
本文用LSTM取代Self-Attention層:提出了一種新的架構,旨在節省內存和參數,同時具有學習遠程建模的能力。
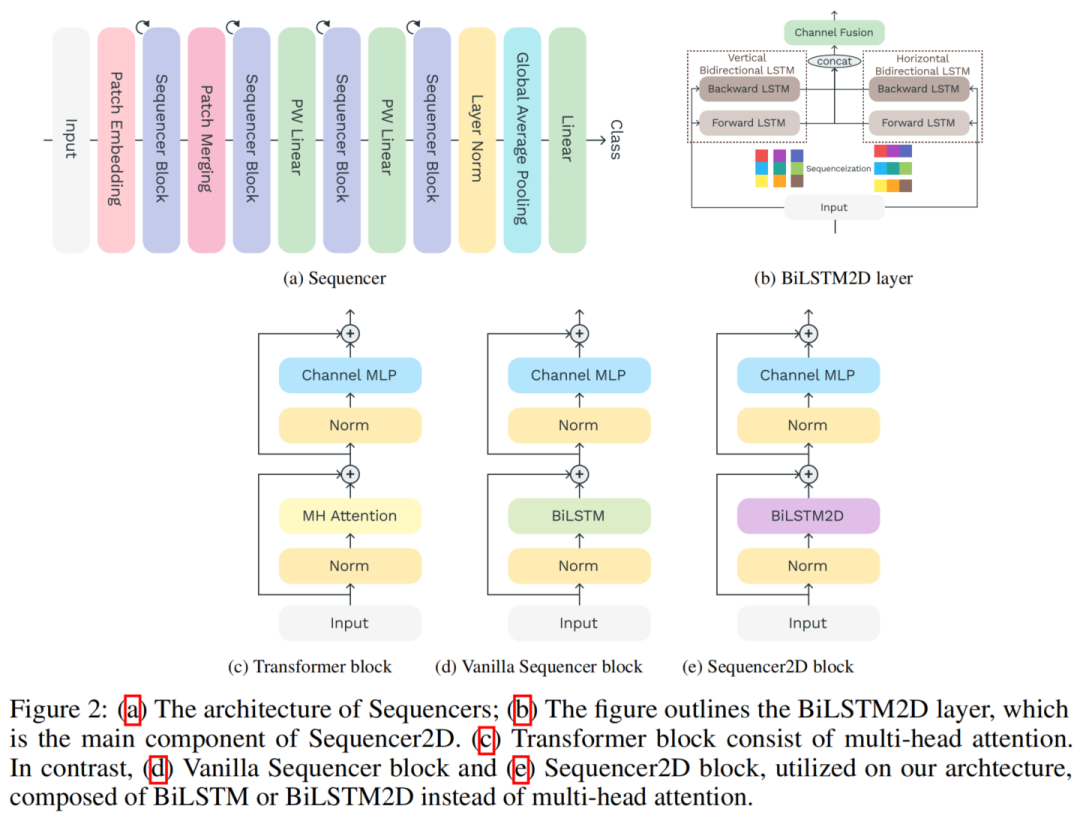
圖2a顯示了Sequencer體系結構的整體結構。Sequencer架構以不重疊的Patches作為輸入,并將它們投影到特征圖上。Sequencer Block是Sequencer的核心組件,由以下子組件組成:
BiLSTM層可以經濟、全局地Mixing空間信息
MLP用于Channel Mixing
當使用普通BiLSTM層時,Sequencer Block稱為Vanilla Sequencer block;當使用BiLSTM2D層作為Sequencer Block時,Sequencer Block稱為Sequencer2D block。最后一個塊的輸出通過全局平均池化層送到線性分類器。
2、BiLSTM2D layer
作者提出了BiLSTM2D層作為一種有效Mixing二維空間信息的技術。它有2個普通的BiLSTM,一個垂直的BiLSTM和一個水平的BiLSTM。
對于輸入被視為一組序列,其中是垂直方向上的Token數量,W是水平方向上的序列數量,C是通道維度。所有序列都輸入到垂直BiLSTM中,共享權重和隱藏維度D:
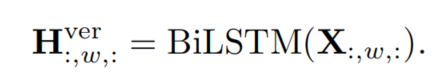
用與上述相似的方式,被視為一組序列,所有序列被輸入到水平BiLSTM中,共享權重和隱藏維度D:
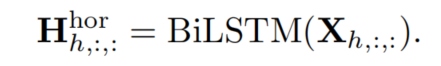
然后將合并到中,同時將合并到。最后送入FC層。這些流程制定如下:

偽代碼如下:

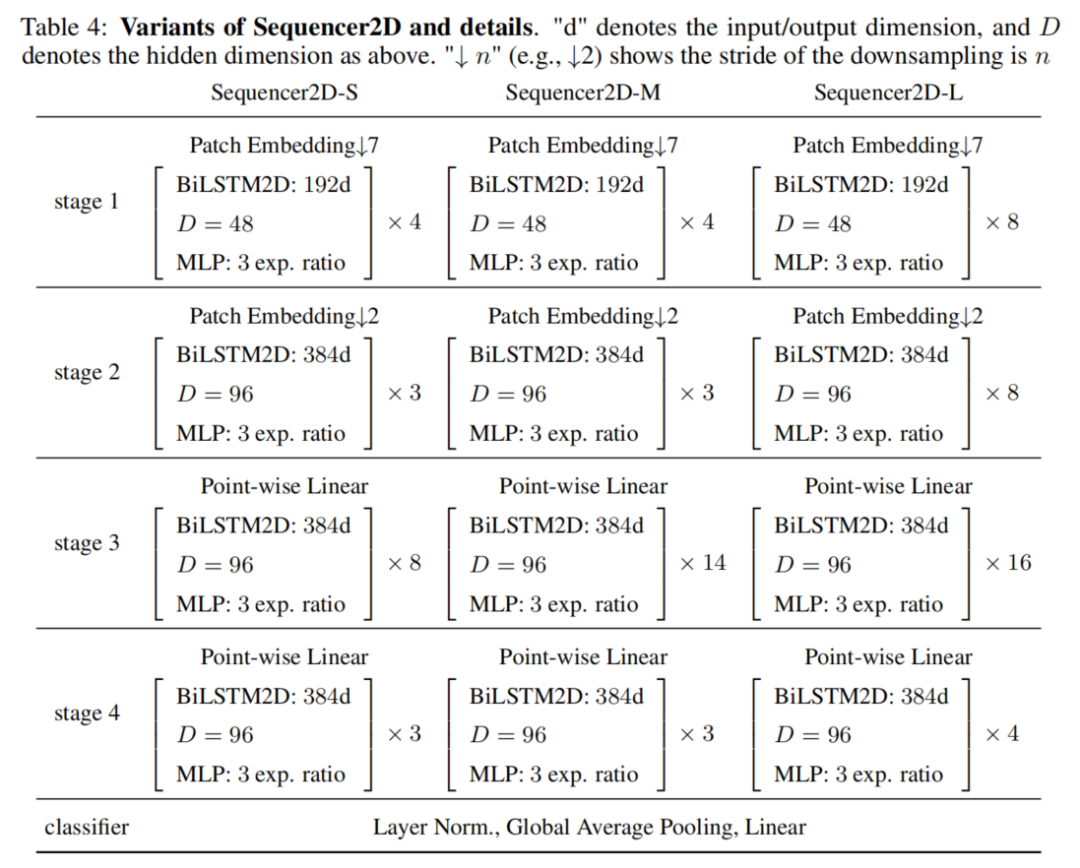
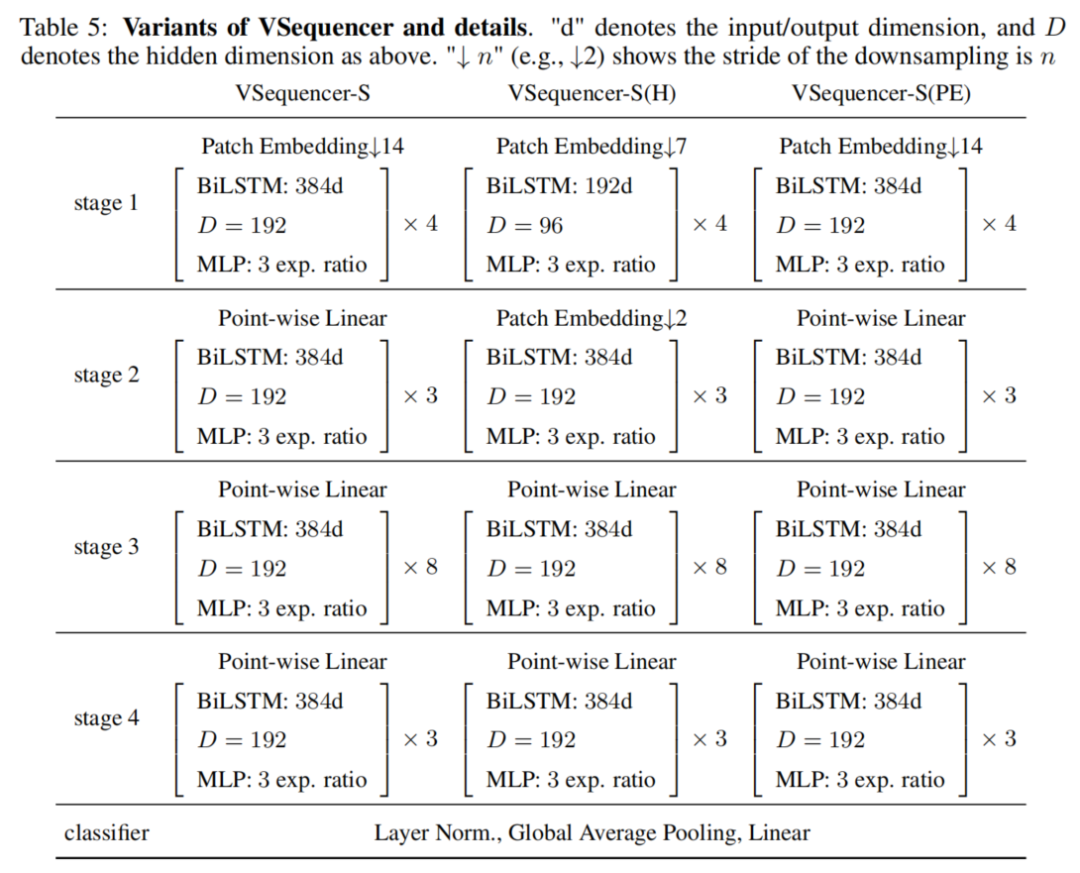
3、架構變體
為了比較由Sequencer 2D組成的不同深度的模型,本文準備了3種不同深度的模型:18、24和36。模型的名稱分別為Sequencer2D-S、Sequencer2D-M和Sequencer2D-L。隱藏維度設置為D=C/4。
3實驗
3.1 ImageNet-1K
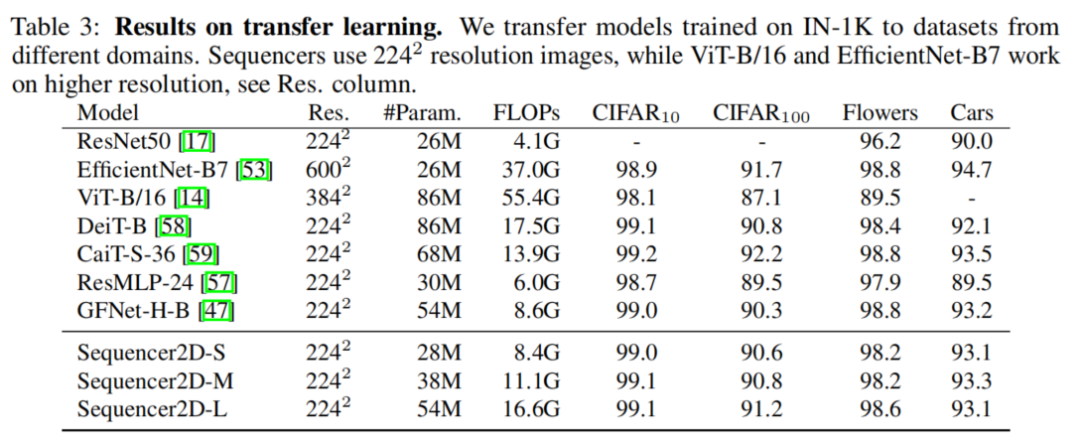
3.2 遷移學習
3.3 穩健性實驗

3.4 可視化分析
一般來說,CNN具有局部化的、逐層擴展的感受野,而沒有移動窗口的ViT捕獲的是全局依賴。相比之下,作者Sequencer不清楚信息是如何處理的。因此作者計算了ResNet-50、DeiT-S和Sequencer2D-S的ERF,如圖5所示。

Sequencer2D-S的ERFs在所有層中形成十字形。這一趨勢使其不同于DeiT-S和ResNet-50等著名模型。更值得注意的是,在淺層中,Sequencer2D-S比ResNet-50的ERF更寬,盡管沒有DeiT那么寬。這一觀察結果證實了Sequencer中的lstm可以像預期的那樣建模長期依賴關系,并且Sequencer可以識別足夠長的垂直或水平區域。因此,可以認為,Sequencer識別圖像的方式與CNN或ViT非常不同。
審核編輯 :李倩
-
計算機視覺
+關注
關注
9文章
1708瀏覽量
46674 -
LSTM
+關注
關注
0文章
60瀏覽量
4021
原文標題:CV全新范式 | LSTM在CV領域殺出一條血路,完美超越Swin與ConvNeXt等前沿算法
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論