 跨圖像關系型KD方法語義分割任務-CIRKD
跨圖像關系型KD方法語義分割任務-CIRKD
語義分割任務作為計算機視覺中的基礎任務之一,其目的是對圖像中的每一個像素進行分類。該任務也被廣泛應用于實踐,例如自動駕駛和醫學圖像分割。現有流行的用于語義分割任務的模型,例如DeepLab和PSPNet系列,雖然獲得了很好的分割精度,但是所需的算力成本較高。本文考慮使用知識蒸餾(Knowledge Distillation,KD)算法來緩解這個問題。KD作為模型壓縮里的一項重要技術,其核心思想是將教師模型中學習的知識作為監督信號來訓練學生模型,使得學生模型得到更好的性能。雖然現有的語義分割知識蒸餾方法能夠對學生網絡的性能進行提升,但是這些方法通常是從單張圖像中提取知識,忽略了跨圖像之間的關系信息也是一種有價值的知識。
最近,地平線-中科院提出了一種新穎的跨圖像關系型KD方法用于語義分割任務-CIRKD。該方法嘗試在語義分割任務中建模pixel-to-pixel和pixel-to-region這兩種對比關系作為KD的監督信號。本文主要從方法介紹以及實驗結果對提出的CIRKD進行講解。
KD作為一種思想已被廣泛應用,尤其是圖像分類任務。但是先前的工作表明直接將圖像分類KD方法直接遷移到語義分割任務是不可行的,因為它們沒有考慮到語義分割的結構化信息。一些經典的語義分割KD工作于是去嘗試捕捉到一些上下文信息來建模結構化知識,比如pixel相似度,pixel與region向量的相似度關系,但是這些方法通常在單張圖像內部進行信息提取,難以捕捉到更加廣泛的上下文依賴。
于是,我們提出一種跨圖像的知識蒸餾方法來建模圖像間的依賴,從而使得網絡能夠捕捉到更加豐富的結構化信息。具體地,本工作建模數據集中的全部圖像之間建模pixel-to-pixel以及pixel-to-region的對比關系作為知識。動機在于一個好的教師模型可以產生更好的全局pixel依賴以及特征空間。CIRKD引導學生模型去模仿教師網絡產生的更好的結構化語義關系,因此提升了語義分割表現。
具體方法
本方法分別從mini-batch和memory的角度對結構化關系進行建模。
1. 基于mini-batch的pixel-to-pixel蒸餾
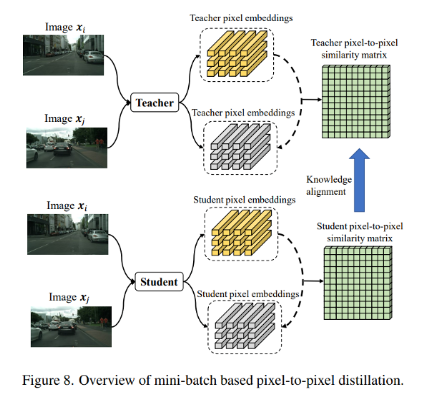
首先是在batch中建模關系,將圖像產生的特征圖在spatial維度上進行分離,產生pixel-wise的特征向量。針對某一個pixel點的特征向量作為錨樣本,其他pixel點特征向量(包括當前圖像和其他圖像)作為對比樣本,可以得到相似度矩陣。基于此方法,在教師端和學生端都可以產生對應的相似度矩陣,然后通過KL散度進行逼近,使得學生可以學到教師的相似度矩陣:
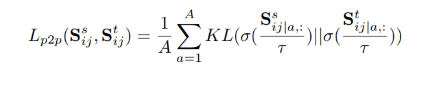
一個batch內的圖像進行兩兩之間的關系矩陣求取和遷移:
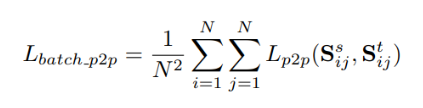
整個過程的示意圖如下所示:
2. 基于memory的pixel-to-pixel蒸餾
相對于基于mini-batch的對比性關系求取,這里采用一個memory bank來存儲對比向量,使得每一個錨樣本都可以得到充足的對比樣本。針對某一個pixel點的特征向量作為錨樣本,每次訓練隨機從memory bank中采樣大量的pixel特征向量來構造對比樣本,通過相乘分別得到教師和學生的相似度矩陣:
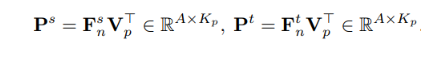
使用KL散度的誤差形式將教師和學生的pixel-to-pixel相似度矩陣進行對齊:
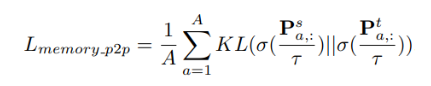
3. 基于memory的pixel-to-region蒸餾
離散化的pixel特征向量不能充分在捕捉到圖像內容,因此本方法利用memory對region向量進行存儲。region向量產生自對來自相同類別的pixel向量做一個平均。針對某一個pixel點的特征向量作為錨樣本,每次訓練隨機從memory bank中采樣大量的region特征向量來構造對比樣本,通過相乘分別得到教師和學生的相似度矩陣:
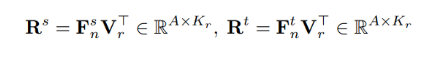
使用KL散度的誤差形式將教師和學生的pixel-to-region相似度矩陣進行對齊:
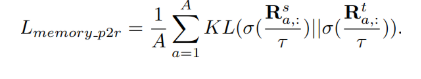
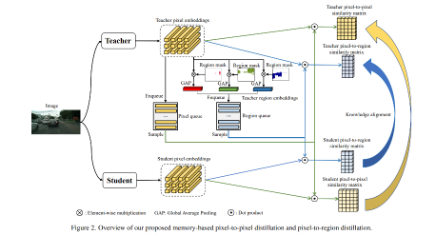
基于memory進行KD的整體示意圖如下所示:
最終的訓練誤差則是將以上3部分誤差相加在一起:
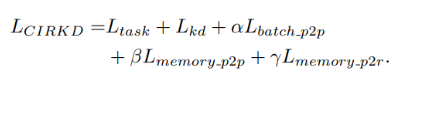
實驗結果
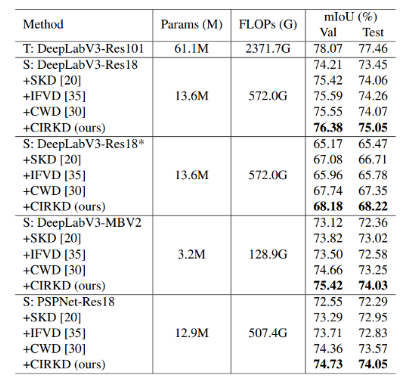
實驗在流行的Cityscapes場景分割數據集上進行,相比于其他流行的語義分割KD方法,CIRKD獲得了一致最佳的表現。
在一些case study上進行可視化,本方法能夠得到最好的分割表現。
審核編輯:彭靜
-
數據
+關注
關注
8文章
7002瀏覽量
88943 -
存儲
+關注
關注
13文章
4296瀏覽量
85801 -
地平線
+關注
關注
0文章
340瀏覽量
14941
發布評論請先 登錄
相關推薦



基于SEGNET模型的圖像語義分割方法
圖像語義分割的概念與原理以及常用的方法
語義分割標注:從認知到實踐

PyTorch教程-14.9. 語義分割和數據集






 工商網監
工商網監
評論