 Linux發送HTTP網絡包圖像 sk_buff數據結構解析
Linux發送HTTP網絡包圖像 sk_buff數據結構解析
如果你對Linux是如何實現 對用戶原始的網絡包進行協議頭封裝與解析,為什么會粘包拆包,期間網絡包經歷了哪些緩沖區、經歷了幾次拷貝(CPU、DMA),TCP又是如何實現滑動/擁塞窗口 這幾個話題感興趣的話,不妨看下去吧。
1. Linux發送HTTP網絡包圖像
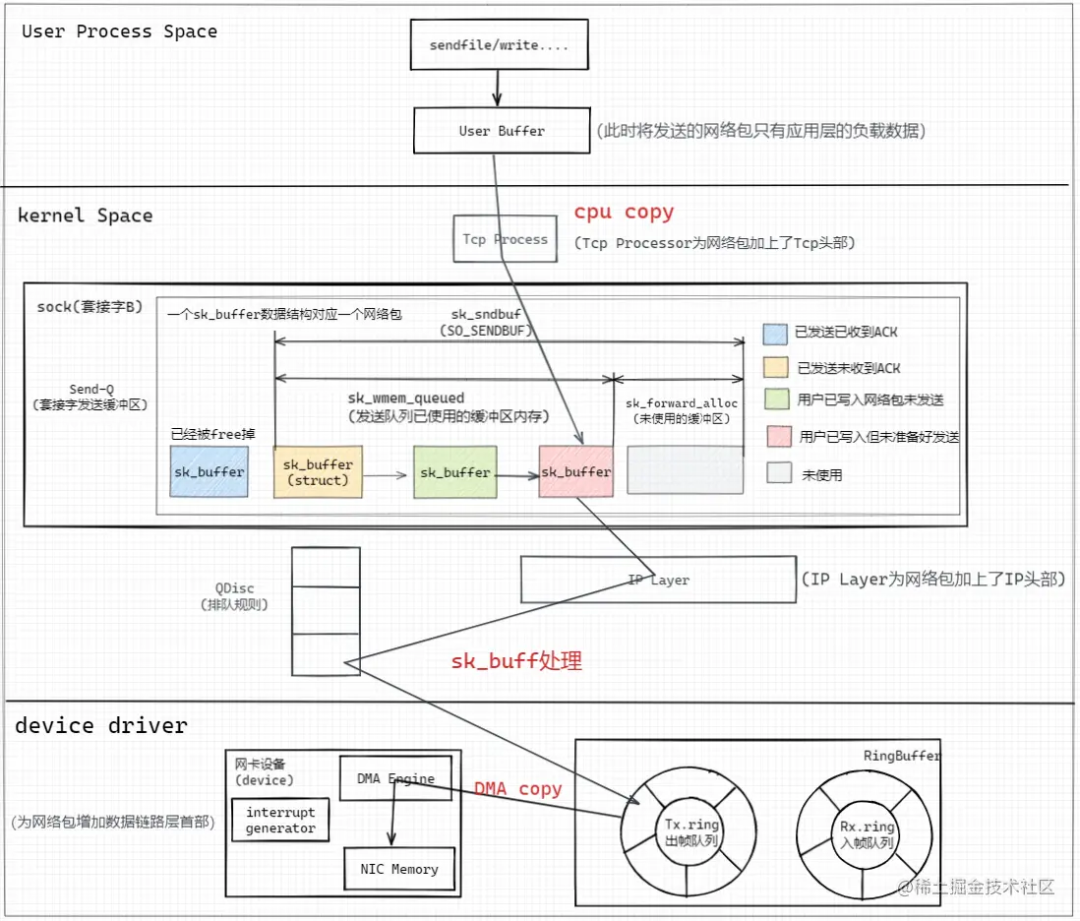
圖像解析
寫入套接字緩沖區(添加TcpHeader)
用戶態進程通過write()系統調用切到內核態將用戶進程緩沖區中的HTTP報文數據通過Tcp Process處理程序為HTTP報文添加TcpHeader,并進行CPU copy寫入套接字發送緩沖區,每個套接字會分別對應一個Send-Q(發送緩沖區隊列)、Recv-Q(接收緩沖區隊列),可以通過ss -nt語句獲取當前的套接字緩沖區的狀態;
# ss -nt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 0 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 1024 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 2048 192.168.183.130:52454 192.168.183.130:14465
......
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 13312 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 14336 192.168.183.130:52454 192.168.183.130:14465
State Recv-Q Send-Q Local Address:Port Peer Address:Port
ESTAB 0 14480 192.168.183.130:52454 192.168.183.130:14465
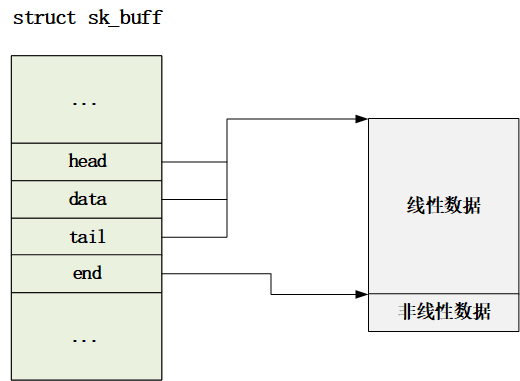
套接字緩沖區發送隊列由一個個struct sk_buff 結構體的鏈表組成,其中一個sk_buff數據結構對應一個網絡包;這個結構體后面會詳細講,是Linux實現網絡協議棧的核心數據結構。
IP層
接著對TCP包在IP Layer層進行網絡包IpHeader的組裝,并經由QDisc(排隊規則)進行轉發;
數據鏈路層/物理層
接著網卡設備通過DMA Engine將內存中RingBuffer的Tx.ring塊中的IP包(sk_buff)copy到網卡自身的內存中,并生成CRC等校驗數據形成數據鏈路包頭部并進行網絡傳輸。
2. sk_buff數據結構解析
通過對sk_buff數據結構解析的過程中,我們回答文章頭部的幾個問題,以及窺見Linux中的一些設計思想;
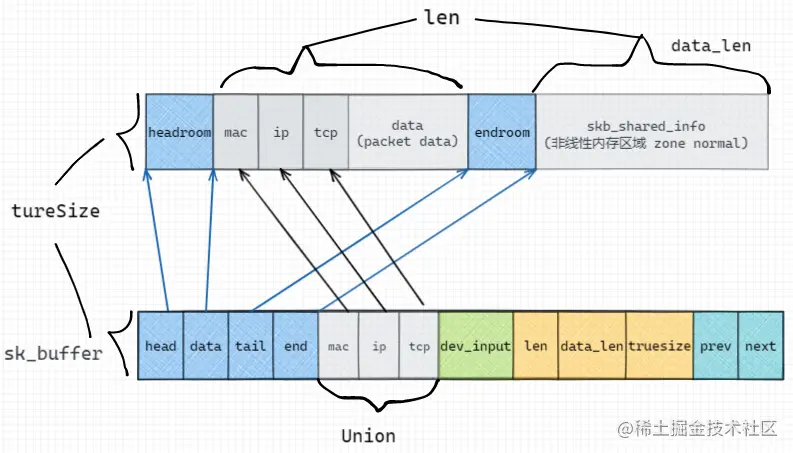
進行協議頭的增添
我們知道,按照網絡棧的設定,發送網絡包時,每經過一層,都會增加對應協議層的協議首部,因此Linux采用在sk_buff中的一個Union結構體進行標識:
struct sk_buff {
union {
struct tcphdr*th; // TCP Header
struct udphdr*uh; // UDP Header
struct icmphdr*icmph; // ICMP Header
struct igmphdr*igmph;
struct iphdr*ipiph; // IPv4 Header
struct ipv6hdr*ipv6h; // IPv6 Header
unsigned char*raw; // MAC Header
} h;
}
結構體中存儲的是指向內存中各種協議的首部地址的指針,而在發送數據包的過程中,sk_buff中的data指針指向最外層的協議頭;
網絡包的大小占用
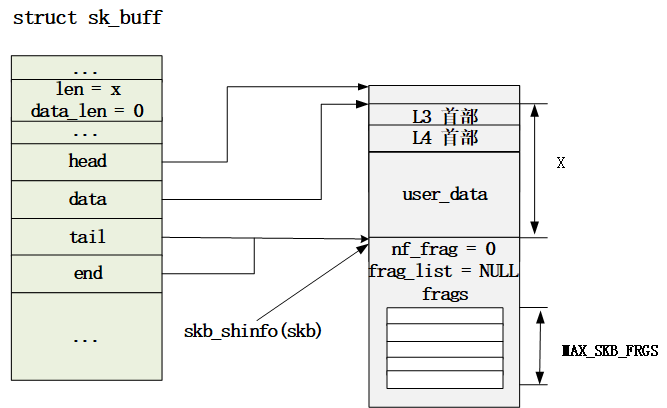
考慮一個包含2bytes的網絡包,需要包括 預留頭(64 bytes) + Mac頭(14bytes) + IP頭(20bytes) + Tcp頭(32bytes) + 有效負載為2bytes(len) + skb_shared_info(320bytes) = 452bytes,向上取整后為512bytes;sk_buff這個存儲結構占用256bytes;則一個2bytes的網絡包需要占用512+256=768bytes(truesize)的內存空間;
因此當發送這個網絡包時:
-
Case1:不存在緩沖區積壓,則新建一個sk_buff進行網絡包的發送;
skb->truesize = 768
skb->datalen = 0 skb_shared_info 結構有效負載 (非線性區域)
skb->len = 2 有效負載 (線性區域 + 非線性區域(datalen),這里暫時不考慮協議頭部)
-
Case2:如果緩沖區積壓(存在未被ACK的已經發送的網絡包-即SEND-Q中存在sk_buff結構),Linux會嘗試將當前包合并到SEND-Q的最后一個sk_buff結構中(粘包);考慮我們上述的768bytes的結構體為SEND-Q的最后一個sk_buff,當用戶進程繼續調用write系統調用寫入2kb的數據時,前一個數據包還未達到MSS/MTU的限制、整個緩沖區的大小未達到SO_SENDBUF指定的限制,會進行包的合并,packet data = 2 + 2,頭部的相關信息都可以進行復用,因為套接字緩沖區與套接字是一一對應的;
tail_skb->truesize = 768
tail_skb->datalen = 0
tail_skb->len = 4 (2 + 2)
發送窗口
我們在創建套接字的時候,通過SO_SENDBUF指定了發送緩沖區的大小,如果設置了大小為2048KB,則Linux在真實創建的時候會設置大小2048*2=4096,因為linux除了要考慮用戶的應用層數據,還需要考慮linux自身數據結構的開銷-協議頭部、指針、非線性內存區域結構等...
sk_buff結構中通過sk_wmem_queued標識發送緩沖區已經使用的內存大小,并在發包時檢查當前緩沖區大小是否小于SO_SENDBUF指定的大小,如果不滿足則阻塞當前線程,進行睡眠,等待發送窗口中有包被ACK后觸發內存free的回調函數喚醒后繼續嘗試發送;
接收窗口(擁塞窗口)
|<---------- RCV.BUFF ---------------->|
1 2 3
|<-RCV.USER->|<--- RCV.WND ---->|
----|------------|------------------|------|----
RCV.NXT
接收窗口主要分為3部分:
-
RCV.USER 為積壓的已經收到但尚未被用戶進程通過read等系統調用獲取的網絡數據包;當用戶進程獲取后窗口的左端會向右移動,并觸發回調函數將該數據包的內存free掉;
-
RCV.WND 為未使用的,推薦返回給該套接字的客戶端發送方當前剩余的可發送的bytes數,即擁塞窗口的大小;
-
第三部分為未使用的,尚未預先內存分配的,并不計算在擁塞窗口的大小中;
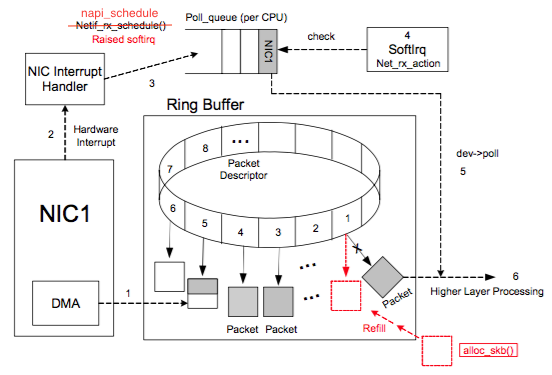
進入網卡驅動層
NIC (network interface card)在系統啟動過程中會向系統注冊自己的各種信息,系統會分配RingBuffer隊列及一塊專門的內核內存區用于存放傳輸上來的數據包。每個 NIC 對應一個R x.ring 和一個 Tx.ring。一個 RingBuffer 上同一個時刻只有一個 CPU 處理數據。
每個網絡包對應的網卡存儲在sk_buff結構的dev_input中;
RingBuffer隊列內存放的是一個個描述符(Descriptor),其有兩種狀態:ready 和 used。
-
初始時 Descriptor 是空的,指向一個空的 sk_buff,處在 ready 狀態。
-
網卡收到網絡包:當NIC有網絡數據包傳入時,DMA負責從NIC取數據,并在Rx.ring上按順序找到下一個ready的Descriptor,將數據存入該 Descriptor指向的sk_buff中,并標記槽為used。
-
網卡發送網絡包:當sk_buff已經在內核空間被寫入完成時,網卡的DMA Engine檢測到Tx.ring有數據包完成時,觸發DMA Copy將數據傳輸到網卡內存中,并封裝MAC幀。
不同的網絡包發送函數有幾次拷貝?
read then write
常見的場景中,當我們要在網絡中發送一個文件,那么首先需要通過read系統調用陷入內核態讀取 PageCache 通過CPU Copy數據頁到用戶態內存中,接著將數據頁封裝成對應的應用層協議報文,并通過write系統調用陷入內核態將應用層報文CPU Copy到套接字緩沖區中,經過TCP/IP處理后形成IP包,最后通過網卡的DMA Engine將RingBuffer Tx.ring中的sk_buff進行DMA Copy到網卡的內存中,并將IP包封裝為幀并對外發送。
PS:如果PageCache中不存在對應的數據頁緩存,則需要通過磁盤DMA Copy到內存中。
因此read then write需要兩次系統調用(4次上下文切換,因為系統調用需要將用戶態線程切換到內核態線程進行執行),兩次CPU Copy、兩次DMA Copy。
sendFile
用戶線程調用sendFile系統調用陷入內核態,sendFile無需拷貝PageCache中的數據頁到用戶態內存中中,而是通過內核線程將 PageCache 中的數據頁直接通過CPU Copy拷貝到套接字緩沖區中,再經由相同的步驟經過一次網卡DMA對外傳輸。
因此sendFile需要一次系統調用,一次CPU Copy;
相比于write,sendFile少了一次PageCache拷貝到內存的開銷,但是需要限制在網絡傳輸的是文件頁,而不是用戶緩沖區中的匿名頁,并且因為完全在內核態進行數據copy,因此無法添加用戶態的協議數據;
Kafka因為基于操作系統文件系統進行數據存儲,并且文件量比較大,因此比較適合通過sendFile進行網絡傳輸的實現;
但是sendFile仍然需要一次內核線程的CPU Copy,因此零拷貝更偏向于無需拷貝用戶態空間中的數據。
mmap + write
相比于sendFile直接在內核態進行文件傳輸,mmap則是通過在進程的虛擬地址空間中映射PageCache,再經過write進行網絡寫入;比較適用于小文件的傳輸,因為mmap并沒有立即將數據拷貝到用戶態空間中,所以較大文件會導致頻繁觸發虛擬內存的 page fault 缺頁異常;
RocketMQ 選擇了 mmap+write 這種零拷貝方式,適用于消息這種小塊文件的數據持久化和傳輸。
原文標題:Linux中一個網絡包的發送/接收流程
文章出處:【微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
-
Linux
+關注
關注
87文章
11292瀏覽量
209332 -
HTTP
+關注
關注
0文章
504瀏覽量
31197 -
數據結構
+關注
關注
3文章
573瀏覽量
40123
原文標題:Linux中一個網絡包的發送/接收流程
文章出處:【微信號:yikoulinux,微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深度解析Linux網絡路徑及sk_buff struct 數據結構
Linux sk_buff四大指針與相關操作

千兆網絡接口在S3C2440A系統中的應用方案
Linux 內核數據結構:位圖(Bitmap)
網卡的Ring Buffer詳解
網卡的Ring Buffer詳解

多CPU下的Ring Buffer處理
sk_buff內存空間布局情況與相關操作(一)
sk_buff內存空間布局情況與相關操作(三)
Linux內核中使用的數據結構





 工商網監
工商網監
評論