 緩解模型訓練成本過高的問題
緩解模型訓練成本過高的問題
我們都知道,為了讓以深度神經網絡為基礎的模型更快地訓練,人們提出了單機多卡、多機多卡等分布式訓練的方式,那么,在模型預測推理階段,有什么方法可以加速推理呢?遺憾的是,并行/分布式的加速方法并不適用于模型推理階段。
但這并不意味著沒有方法可以加速模型的推理。既然多核的方式不行,可以考慮在單核上面的加速,比如減小模型大小(即模型壓縮)。
模型壓縮可以分為模型剪枝(pruning)和模型蒸餾(distillation)。由于模型中的參數對模型推理的貢獻天生就是不平等的,我們可以利用剪枝將貢獻度不高的模型參數剪去,從而減小模型大小,但剪枝帶來的加速比并不高,最多只有2~3倍的速度提升;蒸餾的方法可以帶來較大的加速比,推理精度也不會有太大的損失,但通常情況下,蒸餾會用到大量無標簽的數據預訓練學生模型(student),然后用任務相關的帶標簽數據進一步微調或蒸餾學生模型,但是,預訓練階段又可能會花費大量的時間。
那么有沒有什么方法既能獲得較大的加速比和較低的精度損失,又可以緩解模型訓練成本過高的問題呢?
最近丹琦女神組提出了解決這一問題的方法,讓我們一起來看看吧。
論文標題:
Structured Pruning Learns Compact and Accurate Models
論文鏈接:
https://arxiv.org/pdf/2204.00408.pdf
github地址:
https://github.com/princeton-nlp/CoFiPruning
背景介紹
在介紹這篇論文提出的方法之前,還需要簡單說明下作者研究的背景。
作者提出的模型壓縮方法針對的是原模型(教師模型)為transformer 架構的模型壓縮。眾所周知, transformer 由多個塊組成,每個塊由一個多頭自注意力(multi-head self-attention,MHA)和兩個前饋神經網絡(FFN)組成。其中, MHAs 和 FFNs 的參數量比為 1:2。在 GPU 上,兩者的推理時間基本相同,而在 CPU 上, FFNs 則會耗費更多的推理時間。
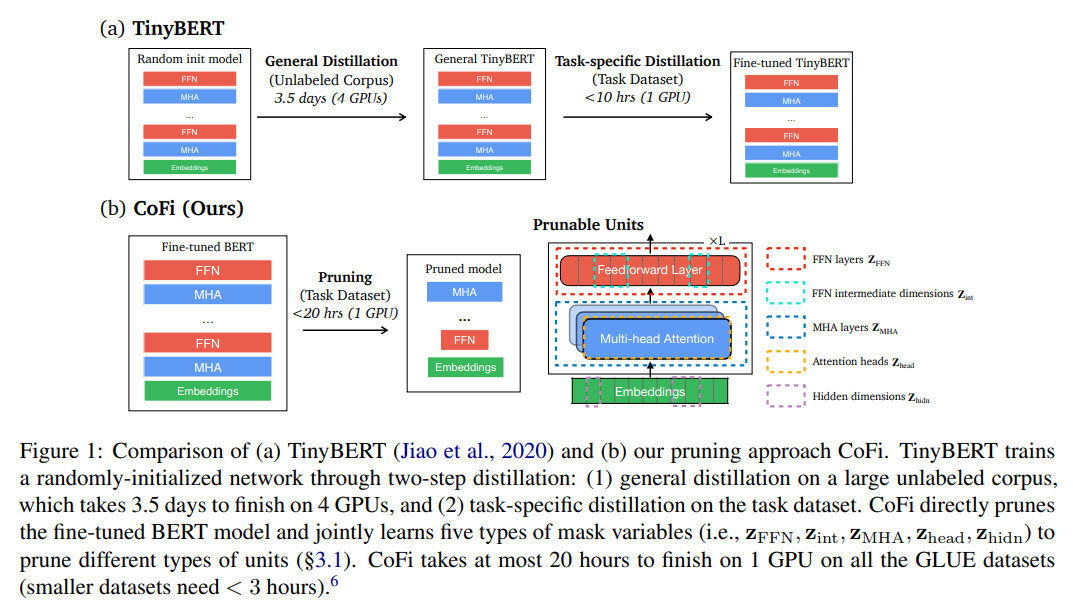
正如前面所述,模型壓縮可以歸納為兩種方法:知識蒸餾和剪枝。知識蒸餾在通常情況下,需要預先定義一個結構固定的學生網絡(當然,也有一些嘗試動態學生網絡的研究),通過用大量無標簽數據預訓練學生網絡的方式進行模型參數初始化,然后用任務特定的帶標簽數據微調學生模型,當然,學生模型的初始化方式可以有很多種,例如用教師模型的某些層初始化學生模型等,但基本的解決思想是一致的。
剪枝則指的是從原模型中去除冗余的參數,按照剪枝的粒度可以分為以下幾種:
層剪枝(layer pruning):從模型中刪去整個 block 塊(包括 MHA 和 FFN ),一些研究表明,去除 50% 的層并不會有太多的精度下降,而且還可以獲得 2X 的加速比;
頭剪枝(head pruning):通過 mask 矩陣只保留一部分 head,但研究表明,這種做法并不能帶來較大的加速比,當僅保留一個 head 的時候,加速比為 1.4X;
前饋神經網絡剪枝(FFN pruning):去除整個 FFN 層或者去除 FFN 層的某些維度;
更加細粒度的塊和非結構化的剪枝:去除 MHA 和 FFN 中更小的塊或者去除某些參數權重,目前這種做法很難優化模型,也難以獲得推理加速
除此之外,還可以將剪枝和蒸餾融合起來,但目前,該方法具體實現尚不清晰。
結構化剪枝方法 CoFi
為獲得較大的加速比和較低的精度損失,以及緩解模型訓練成本過高的問題,作者提出了結構化剪枝方法CoFi(Coarse- andFine-grained Pruning),方法由兩個部分組成:粗粒度和細粒度的剪枝以及從原模型(未剪枝)到剪枝模型的逐層蒸餾
粗粒度和細粒度的剪枝
在頭剪枝(head pruning)中,經常通過由 組成的 mask 矩陣來保留一部分 head ,但是,當 mask 矩陣全為 0,即去除掉所有的 head 時,會使模型優化變得困難。為此,作者為每一層的 MHA 和 FFN 引入兩個掩碼變量 和 ,多頭自注意力和前饋神經網絡可以表示為:
其中, 是輸入向量, 是 head 數量, , , , 分別是 query、key、value 和輸出的權重矩陣, 是 attention 函數, 和 分別是 FFN 的兩個權重, 和 分別是掩碼矩陣變量。
作者用 和 控制每一層的 MHA 和 FFN 是否剪枝以及 和 控制每一層的 MHA 和 FFN 中的哪些 head 和哪些維度需要剪枝。
除此之外,作者還對 和 的輸出在維度上作剪枝操作。具體做法是將掩碼變量 應用到模型中所有的權重矩陣,掩碼跨層共享的原因是作者考慮到模型中的殘差使得隱向量中的每個維度都可以連接到下一層相應的維度。
此外,作者定義了預期稀疏度:
其中, 是整個模型大小, 是 block 層數, 是隱藏層維度, 是多頭自注意力的每個 head 的向量維度, 是前饋網絡的維度,一般情況下,。
模型訓練階段,所有的掩碼元素的值處于之間,推理階段,會將低于閾值的掩碼變量映射為 0,得到最終的剪枝模型,其中,閾值由每個權重矩陣的預期稀疏度確定。
從原模型到剪枝模型的蒸餾
考慮到將剪枝和蒸餾融合可以提高性能,作者提出了用于剪枝的逐層蒸餾方法。與一般的蒸餾做法不同,作者沒有預先定義從教師網絡到學生網絡的固定的層映射,而是動態地搜索兩者之間的層映射。具體來說,假設 表示準備將知識蒸餾到學生網絡的教師網絡的層的集合, 是層映射函數,表示從教師網絡的第 層映射到的學生網絡的層,那么,隱藏層的蒸餾 可以定義為:
其中, 是線性變換矩陣, 和 分別是第 層學生網絡和第 層教師網絡的隱藏層表示。 定義如下:
其中,計算兩個層集合之間的距離(MSE)的操作是可以并行執行的。通過上面的層映射函數,教師網絡和學生網絡之間的層映射總是按照最有利于剪枝的方向進行。
最后,作者將逐層蒸餾和來自預測層(模型輸出)的蒸餾結合起來,得到最終的loss:
其中, 是超參, 和 分別是學生模型和教師模型的輸出概率分布。
實驗
數據集
作者使用的是 GLUE 數據集和 SQuAD v1.1 數據集,其中, GLUE 數據集包括 SST2、MNLI、QQP、QNLI、MRPC、CoLA、STS-B 和 RTE 八個數據集。
在四個相對較大的 GLUE 數據集(包括 MNLI、QNLI、SST-2 和 QQP)以及 SQuAD 數據集上,作者訓練了 20 個 epoch,并對最終的學生網絡微調了額外 20 個 epoch。在前 20 個 epoch 中,作者使用蒸餾的目標函數對模型進行微調 1 個 epoch,然后在 2 個 epoch 之內使模型達到期望的目標稀疏度。而對于四個較小的 GLUE 數據集,作者訓練了 100 個 epoch 并微調 20 個 epoch。作者用蒸餾目標函數微調模型 4 個epoch,并在接下來的 20 個 epoch 內將模型剪枝到期望的目標稀疏度。在達到目標稀疏度后,還會在剩余的訓練 epoch 階段繼續剪枝以搜索性能更好的網絡結構。
作者在每個數據集上依次訓練并微調不同目標稀疏度的模型。此外,作者在實驗中發現,訓練結束后的微調可以有效地保持模型不會有太大的精度損失。
模型對比
作者將 、、、、 作為 baseline,對比了 CoFi 和 baseline 在不同的加速比和模型大小的情況下準確率(acc)和 f1 的變化
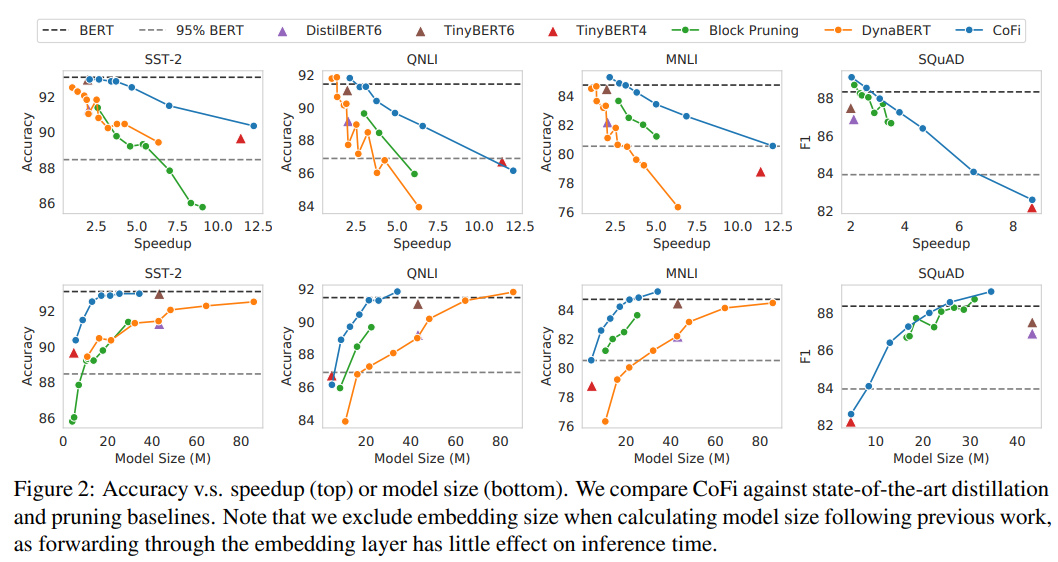
可以看到,在相同的加速比或相同的模型大小下,作者提出的方法 CoFi 都可以獲得更高的準確率(acc)或 f1
此外,作者還展示了 CoFi 和 的對比結果。
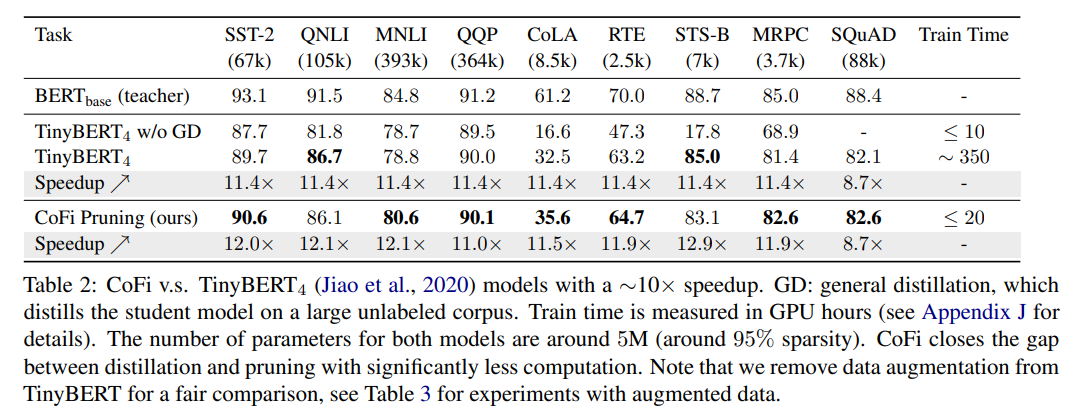
其中, 使用大量無標簽數據通過預訓練的方式初始化學生網絡,和大規模預訓練語言模型一樣,這種從大規模語料庫中獲取通用知識的方式對學生模型性能有著十分重要的作用,但預訓練會花費太多的時間,如下圖所示:
從表 2 可以看到,CoFi 可以獲得和 基本一致的加速比和略高的模型預測準確度,與此同時,CoFi 模型的訓練時間較 得到了大幅的縮減,也證明了以蒸餾目標函數訓練的剪枝方法在模型壓縮方面是經濟且高效的。
除此之外,作者還使用相同的任務特定的數據分別為 和 CoFi 做數據增強,并對比了數據增強后的模型性能。
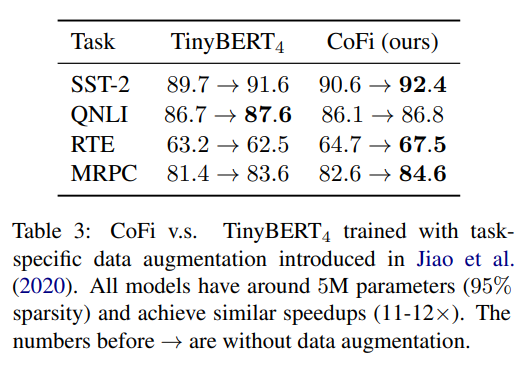
可以看到,數據增強后,CoFi 也基本有著高于 的模型性能。
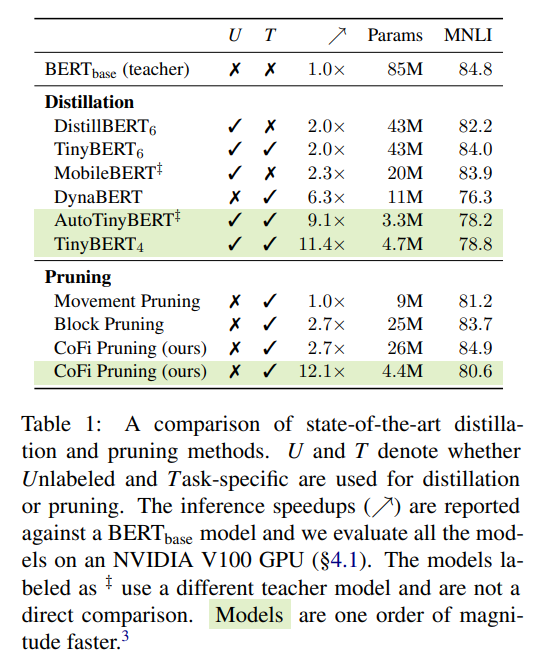
▲sota剪枝和蒸餾方法的性能對比
消融實驗
作者做了一系列的消融實驗,證明了 CoFi 各個模塊的有效性。實驗結果如下所示:
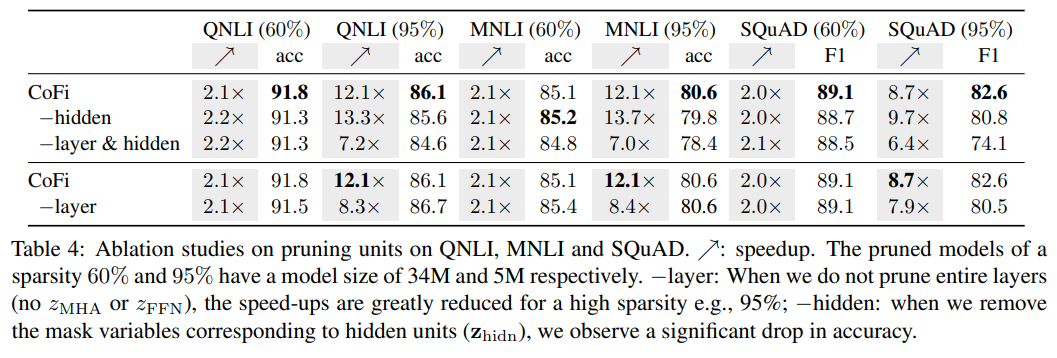
▲CoFi消融實驗-剪枝單元
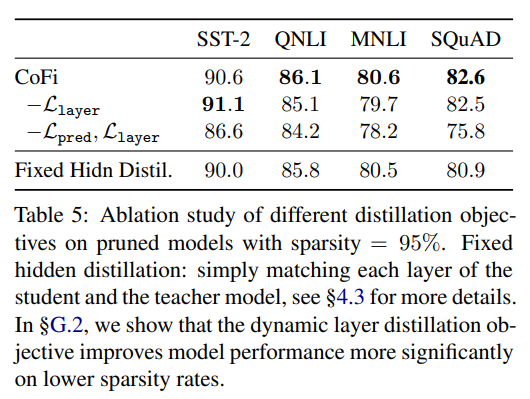
▲CoFi消融實驗-蒸餾目標函數
剪枝后的模型的結構
作者研究了經過 CoFi 剪枝后得到的模型的結構,作者分別在五個數據集上在不同的目標稀疏度下訓練微調得到剪枝后的模型,并對模型的 FFN 層的平均中間維度以及 MHA 層的 head 平均剩余數量做了統計,結果如下:
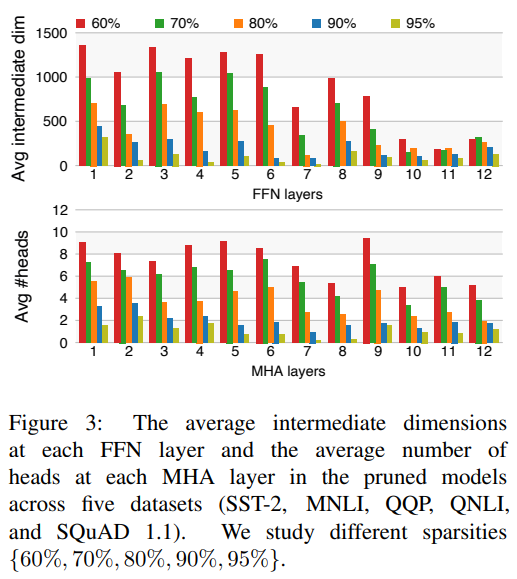
可以看到:
幾乎在所有的稀疏度下,前饋神經網絡層都存在明顯的剪枝,這表明 FFN 層比 MHA 層存在更多的冗余信息;
CoFi 傾向于更多地剪枝上層網絡結構
作者還詳細地展示了不同數據集下經 CoFi 剪枝后的模型的具體結構,下圖展示的是每個模型每層 MHA 和 FFN 模塊的保留情況。盡管模型大小基本一致,但不同的數據集卻訓練出結構存在明顯差異的模型,從側面也證明了不同的數據集存在不同的最優學生模型。
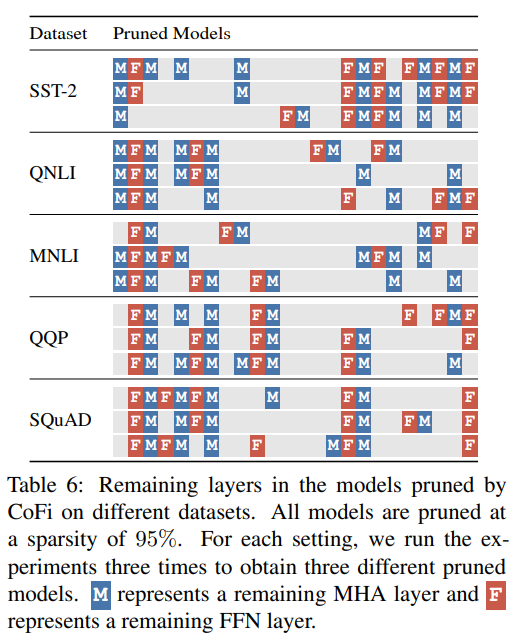
▲經CoFi剪枝后的模型不同層子模塊保留情況
總結
作者提出的結構化剪枝方法 CoFi 在幾乎沒有太多精度損失的情況下,達到了 10 倍以上的加速比,同時,和常規的蒸餾做法相比,避免了因使用大量無標簽數據預訓練模型而帶來的訓練成本過高的問題,按作者的話來說,該方法可以是蒸餾的一個有效替代品。
當然,作者也指出,盡管 CoFi 可以應用到任務無關的模型的剪枝中,比如大規模預訓練語言模型,但由于上游剪枝方案設計的復雜性,作者還是將 CoFi 的應用場景限制到任務相關的模型壓縮中。試想下,如果可以將任務無關的模型壓縮到可以部署到移動設備或者可穿戴智能設備上,那么,世界又會是一番怎樣的景象呢?不知道這是不是丹琦女神給我們新開的一個“坑”呢?
審核編輯 :李倩
-
cpu
+關注
關注
68文章
10872瀏覽量
211993 -
神經網絡
+關注
關注
42文章
4772瀏覽量
100838 -
模型
+關注
關注
1文章
3254瀏覽量
48878
原文標題:ACL'22 | 陳丹琦提出CoFi模型剪枝,加速10倍,精度幾乎無損
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論