

巧了。
我也聽說過。
但我不接受它的建議,硬是單表裝了1億條數據。
這時候,我們組里新來的實習生看到了之后,天真無邪的問我:"單表不是建議最大兩千萬嗎?為什么這個表都放了1個億還不分庫分表"?
我能說我是因為懶嗎?我當初設計時哪里想到這表竟然能漲這么快。。。
我不能。
說了等于承認自己是開發組里的毒瘤,雖然我確實是,但我不能承認。
我如坐針氈,如芒刺背,如鯁在喉。
開始了一波騷操作。
"我這么做是有道理的"
"雖然這個表很大,但你有沒有發現它查詢其實還是很快"
"這個2kw是個建議值,我們要來看下這個2kw是怎么來的"
數據庫單表行數最大多大?
我們先看下單表行數理論最大值是多少。
建表的SQL是這么寫的,
CREATETABLE`user`(
`id`int(10)unsignedNOTNULLAUTO_INCREMENTCOMMENT'主鍵',
`name`varchar(100)NOTNULLDEFAULT''COMMENT'名字',
`age`int(11)NOTNULLDEFAULT'0'COMMENT'年齡',
PRIMARYKEY(`id`),
KEY`idx_age`(`age`)
)ENGINE=InnoDBAUTO_INCREMENT=100037DEFAULTCHARSET=utf8;
其中id就是主鍵。主鍵本身唯一,也就是說主鍵的大小可以限制表的上限。
如果主鍵聲明為int大小,也就是32位,那么能支持2^32-1,也就是21個億左右。
如果是bigint,那就是2^64-1,但這個數字太大,一般還沒到這個限制之前,磁盤先受不了。
搞離譜點。
如果我把主鍵聲明為 tinyint,一個字節,8位,最大2^8-1,也就是255。
CREATETABLE`user`(
`id`tinyint(2)unsignedNOTNULLAUTO_INCREMENTCOMMENT'主鍵',
`name`varchar(100)NOTNULLDEFAULT''COMMENT'名字',
`age`int(11)NOTNULLDEFAULT'0'COMMENT'年齡',
PRIMARYKEY(`id`),
KEY`idx_age`(`age`)
)ENGINE=InnoDBAUTO_INCREMENT=0DEFAULTCHARSET=utf8;
如果我想插入一個id=256的數據,那就會報錯。
mysql>INSERTINTO`tmp`(`id`,`name`,`age`)VALUES(256,'',60);
ERROR1264(22003):Outofrangevalueforcolumn'id'atrow1
也就是說,tinyint主鍵限制表內最多255條數據。
索引的結構
索引內部是用的B+樹,這個也是八股文老股了,大家估計也背得很熟了。
為了不讓大家有過于強烈的審丑疲勞,今天我嘗試從另外一個角度給大家講講這玩意。
頁的結構
假設我們有這么一張user數據表。
 user表
user表其中id是唯一主鍵。
這看起來的一行行數據,為了方便,我們后面就叫它們record吧。
這張表看起來就跟個excel表格一樣。excel的數據在硬盤上是一個xx.excel的文件。
而上面user表數據,在硬盤上其實也是類似,放在了user.ibd文件下。含義是user表的innodb data文件,專業點,又叫表空間。
雖然在數據表里,它們看起來是挨在一起的。但實際上在user.ibd里他們被分成很多小份的數據頁,每份大小16k。
類似于下面這樣。
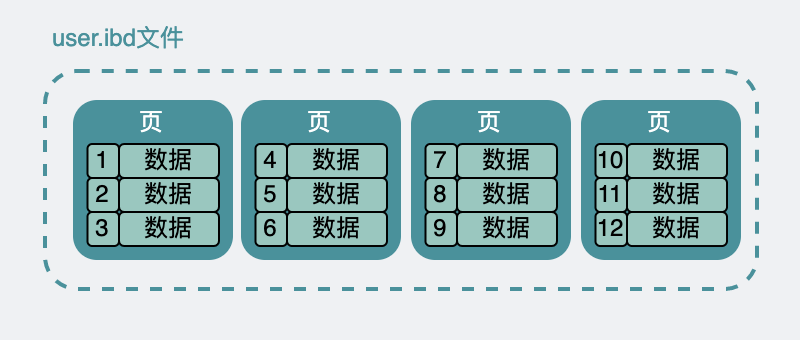 ibd文件內部有大量的頁
ibd文件內部有大量的頁我們把視角聚焦一下,放到頁上面。
整個頁16k,不大,但record這么多,一頁肯定放不下,所以會分開放到很多頁里。并且這16k,也不可能全用來放record對吧。
因為record們被分成好多份,放到好多頁里了,為了唯一標識具體是哪一頁,那就需要引入頁號(其實是一個表空間的地址偏移量)。同時為了把這些數據頁給關聯起來,于是引入了前后指針,用于指向前后的頁。這些都被加到了頁頭里。
頁是需要讀寫的,16k說小也不小,寫一半電源線被拔了也是有可能發生的,所以為了保證數據頁的正確性,還引入了校驗碼。這個被加到了頁尾。
那剩下的空間,才是用來放我們的record的。而record如果行數特別多的話,進入到頁內時挨個遍歷,效率也不太行,所以為這些數據生成了一個頁目錄,具體實現細節不重要。只需要知道,它可以通過二分查找的方式將查找效率從O(n) 變成O(lgn)。
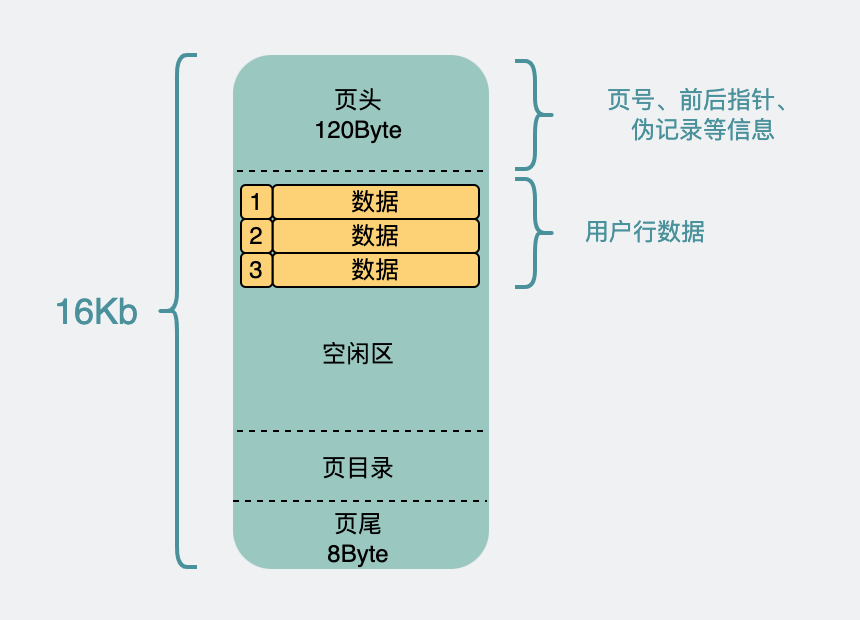 頁結構
頁結構從頁到索引
如果想查一條record,我們可以把表空間里每一頁都撈出來,再把里面的record撈出來挨個判斷是不是我們要找的。
行數量小的時候,這么操作也沒啥問題。
行數量大了,性能就慢了,于是為了加速搜索,我們可以在每個數據頁里選出主鍵id最小的record,而且只需要它們的主鍵id和所在頁的頁號。組成新的record,放入到一個新生成的一個數據頁中,這個新數據頁跟之前的頁結構沒啥區別,而且大小還是16k。
但為了跟之前的數據頁進行區分。數據頁里加入了頁層級(page level)的信息,從0開始往上算。于是頁與頁之間就有了上下層級的概念,就像下面這樣。
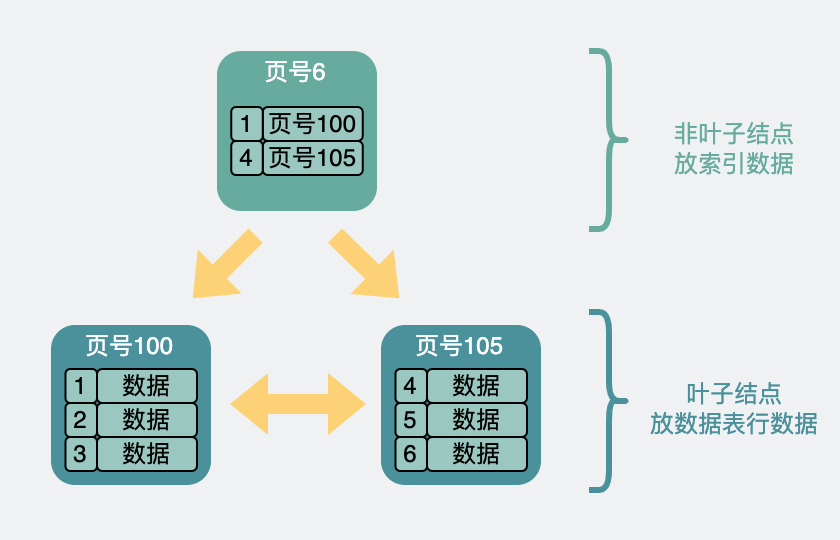 兩層B+樹結構
兩層B+樹結構突然頁跟頁之間看起來就像是一棵倒過來的樹了。也就是我們常說的B+樹索引。
最下面那一層,page level 為0,也就是所謂的葉子結點,其余都叫非葉子結點。
上面展示的是兩層的樹,如果數據變多了,我們還可以再通過類似的方法,再往上構建一層。就成了三層的樹。
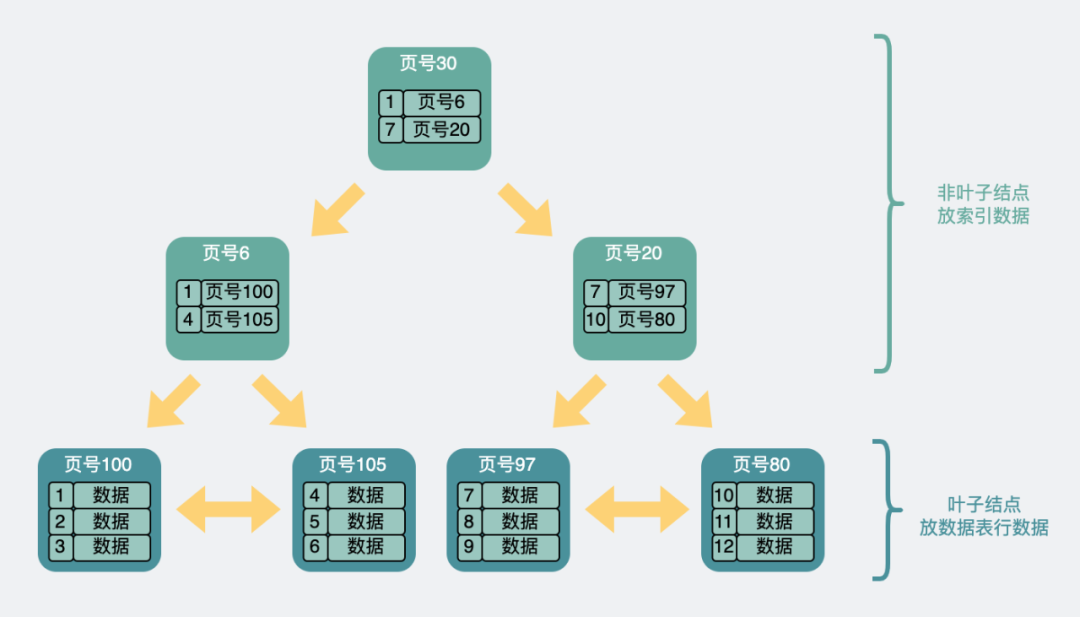
那現在我們就可以通過這樣一棵B+樹加速查詢。舉個例子。
比方說我們想要查找行數據5。會先從頂層頁的record們入手。record里包含了主鍵id和頁號(頁地址)。看下圖黃色的箭頭,向左最小id是1,向右最小id是7。那id=5的數據如果存在,那必定在左邊箭頭。
于是順著的record的頁地址就到了6號數據頁里,再判斷id=5>4,所以肯定在右邊的數據頁里,于是加載105號數據頁。在數據頁里找到id=5的數據行,完成查詢。
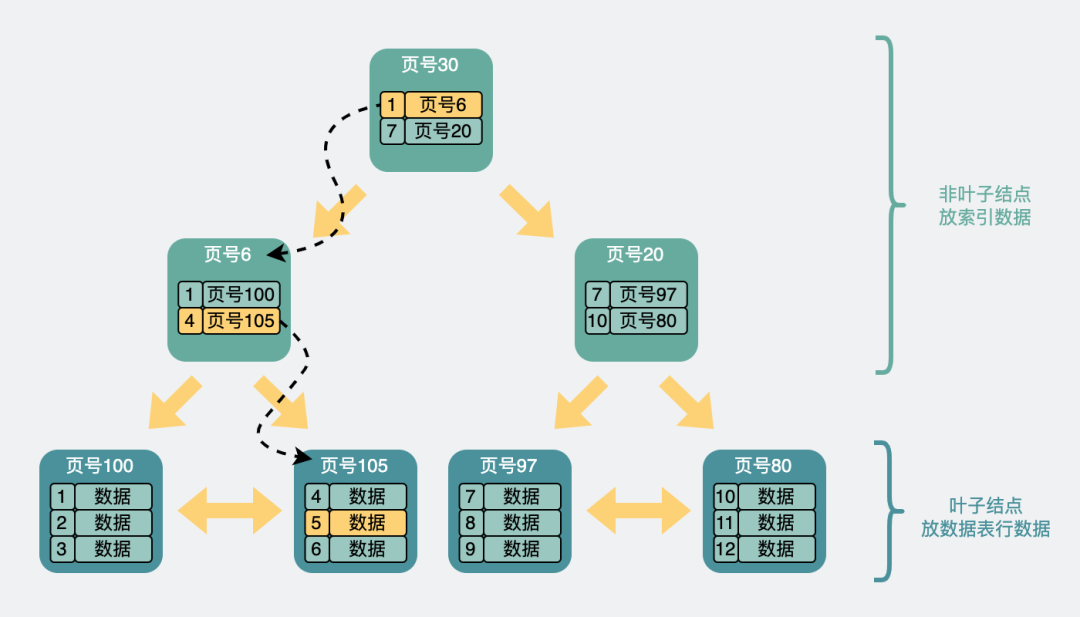 B+樹查詢過程
B+樹查詢過程另外需要注意的是,上面的頁的頁號并不是連續的,它們在磁盤里也不一定是挨在一起的。
這個過程中查詢了三個頁,如果這三個頁都在磁盤中(沒有被提前加載到內存中),那么最多需要經歷三次磁盤IO查詢,它們才能被加載到內存中。B+樹承載的記錄數量
從上面的結構里可以看出B+樹的最末級葉子結點里放了record數據。而非葉子結點里則放了用來加速查詢的索引數據。
也就是說
同樣一個16k的頁,非葉子節點里每一條數據都指向一個新的頁,而新的頁有兩種可能。
-
如果是末級葉子節點的話,那么里面放的就是一行行record數據。
-
如果是非葉子節點,那么就會循環繼續指向新的數據頁。
假設
-
非葉子結點內指向其他內存頁的指針數量為
x -
葉子節點內能容納的record數量為
y -
B+樹的層數為
z
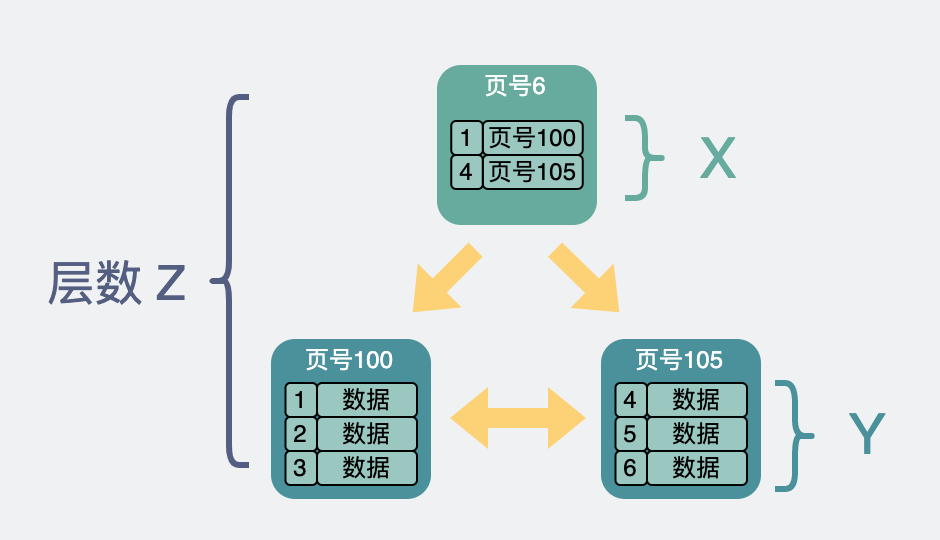 總行數的計算方法
總行數的計算方法
那這棵B+樹放的行數據總量等于 (x ^ (z-1)) * y。
x怎么算
我們回去看數據頁的結構。
頁結構非葉子節點里主要放索引查詢相關的數據,放的是主鍵和指向頁號。
主鍵假設是bigint(8Byte),而頁號在源碼里叫FIL_PAGE_OFFSET(4Byte),那么非葉子節點里的一條數據是12Byte左右。
整個數據頁16k, 頁頭頁尾那部分數據全加起來大概128Byte,加上頁目錄毛估占1k吧。那剩下的15k除以12Byte,等于1280,也就是可以指向x=1280頁。
我們常說的二叉樹指的是一個結點可以發散出兩個新的結點。m叉樹一個節點能指向m個新的結點。這個指向新節點的操作就叫扇出(fanout)。
而上面的B+樹,它能指向1280個新的節點,恐怖如斯,可以說扇出非常高了。
y的計算
葉子節點和非葉子節點的數據結構是一樣的,所以也假設剩下15kb可以發揮。
葉子節點里放的是真正的行數據。假設一條行數據1kb,所以一頁里能放y=15行。
行總數計算
回到 (x ^ (z-1)) * y 這個公式。
已知x=1280,y=15。
假設B+樹是兩層,那z=2。則是(1280 ^ (2-1)) * 15 ≈ 2w
假設B+樹是三層,那z=3。則是(1280 ^ (3-1)) * 15 ≈ 2.5kw
行數超一億就慢了嗎?
上面假設單行數據用了1kb,所以一個數據頁能放個15行數據。
如果我單行數據用不了這么多,比如只用了250byte。那么單個數據頁能放60行數據。
那同樣是三層B+樹,單表支持的行數就是 (1280 ^ (3-1)) * 60 ≈ 1個億。
你看我一個億的數據,其實也就三層B+樹,在這個B+樹里要查到某行數據,最多也是三次磁盤IO。所以并不慢。
這就很好的解釋了文章開頭,為什么我單表1個億,但查詢性能沒啥大毛病。B樹承載的記錄數量
既然都聊到這里了,我們就順著這個話題多聊一些吧。
我們都知道,現在mysql的索引都是B+樹,而有一種樹,跟B+樹很像,叫B樹,也叫B-樹。
它跟B+樹最大的區別在于,B+樹只在末級葉子結點處放數據表行數據,而B樹則會在葉子和非葉子結點上都放。
于是,B樹的結構就類似這樣
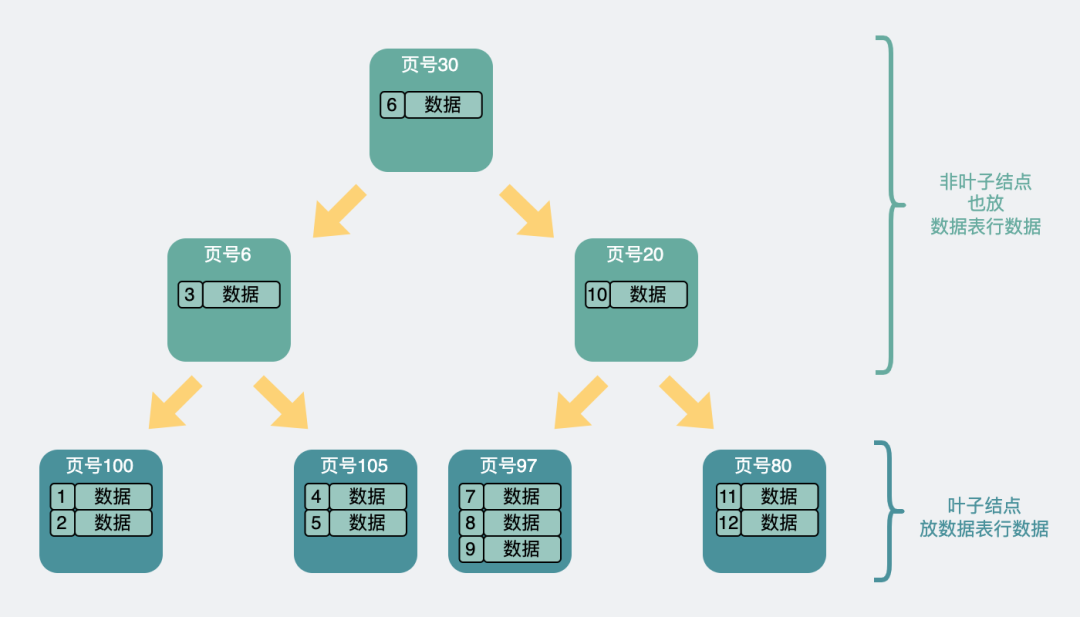 B樹結構
B樹結構B樹將行數據都存在非葉子節點上,假設每個數據頁還是16kb,掐頭去尾每頁剩15kb,并且一條數據表行數據還是占1kb,就算不考慮各種頁指針的情況下,也只能放個15條數據。數據頁扇出明顯變少了。
計算可承載的總行數的公式也變成了一個等比數列。
15+15^2+15^3+...+15^z
其中z還是層數的意思。
為了能放2kw左右的數據,需要z>=6。也就是樹需要有6層,查一次要訪問6個頁。假設這6個頁并不連續,為了查詢其中一條數據,最壞情況需要進行6次磁盤IO。
而B+樹同樣情況下放2kw數據左右,查一次最多是3次磁盤IO。
磁盤IO越多則越慢,這兩者在性能上差距略大。
為此,B+樹比B樹更適合成為mysql的索引。總結
-
B+樹葉子和非葉子結點的數據頁都是16k,且數據結構一致,區別在于葉子節點放的是真實的行數據,而非葉子結點放的是主鍵和下一個頁的地址。
-
B+樹一般有兩到三層,由于其高扇出,三層就能支持2kw以上的數據,且一次查詢最多1~3次磁盤IO,性能也還行。
-
存儲同樣量級的數據,B樹比B+樹層級更高,因此磁盤IO也更多,所以B+樹更適合成為mysql索引。
-
索引結構不會影響單表最大行數,2kw也只是推薦值,超過了這個值可能會導致B+樹層級更高,影響查詢性能。
-
單表最大值還受主鍵大小和磁盤大小限制。
參考資料
《MYSQL內核:INNODB存儲引擎 卷1》
最后
雖然我在單表里塞了1億條數據,但這個操作的前提是,我很清楚這不會太影響性能。
這波解釋,毫無破綻,無懈可擊。
到這里,連我自己都被自己說服了。想必實習生也是。
可惡,這該死的毒瘤竟然有些"知識淵博"。
審核編輯 :李倩
-
SQL
+關注
關注
1文章
777瀏覽量
44421 -
數據庫
+關注
關注
7文章
3868瀏覽量
65019
原文標題:為什么大家說 mysql 數據庫單表最大兩千萬?依據是啥?
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫數據恢復—SQL Server附加數據庫提示“錯誤 823”的數據恢復案例
數據庫數據恢復——MySQL數據庫誤刪除表記錄的數據恢復案例

MySQL數據庫的安裝
云數據庫是哪種數據庫類型?
如何使用cmp進行數據庫管理的技巧
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

Oracle數據恢復—異常斷電后Oracle數據庫啟庫報錯的數據恢復案例
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

軟件系統數據庫的分庫分表設計
數據庫數據恢復—SqlServer數據庫底層File Record被截斷為0的數據恢復案例
數據庫數據恢復—SQL Server數據庫所在分區空間不足報錯的數據恢復案例
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例






 工商網監
工商網監
評論