") TensorRT支持使用8位整數(shù)表示量化的浮點(diǎn)值
TensorRT支持使用8位整數(shù)表示量化的浮點(diǎn)值
7.1. Introduction to Quantization
TensorRT 支持使用 8 位整數(shù)來(lái)表示量化的浮點(diǎn)值。量化方案是對(duì)稱均勻量化 – 量化值以有符號(hào) INT8 表示,從量化到非量化值的轉(zhuǎn)換只是一個(gè)乘法。在相反的方向上,量化使用倒數(shù)尺度,然后是舍入和鉗位。
要啟用任何量化操作,必須在構(gòu)建器配置中設(shè)置 INT8 標(biāo)志。
7.1.1. Quantization Workflows
創(chuàng)建量化網(wǎng)絡(luò)有兩種工作流程:
訓(xùn)練后量化(PTQ: Post-training quantization) 在網(wǎng)絡(luò)經(jīng)過(guò)訓(xùn)練后得出比例因子。 TensorRT 為 PTQ 提供了一個(gè)工作流程,稱為校準(zhǔn)(calibration),當(dāng)網(wǎng)絡(luò)在代表性輸入數(shù)據(jù)上執(zhí)行時(shí),它測(cè)量每個(gè)激活張量?jī)?nèi)的激活分布,然后使用該分布來(lái)估計(jì)張量的尺度值。
量化感知訓(xùn)練(QAT: Quantization-aware training) 在訓(xùn)練期間計(jì)算比例因子。這允許訓(xùn)練過(guò)程補(bǔ)償量化和去量化操作的影響。
TensorRT 的量化工具包是一個(gè) PyTorch 庫(kù),可幫助生成可由 TensorRT 優(yōu)化的 QAT 模型。您還可以利用工具包的 PTQ 方式在 PyTorch 中執(zhí)行 PTQ 并導(dǎo)出到 ONNX。
7.1.2. Explicit vs Implicit Quantization
量化網(wǎng)絡(luò)可以用兩種方式表示:
在隱式量化網(wǎng)絡(luò)中,每個(gè)量化張量都有一個(gè)相關(guān)的尺度。在讀寫張量時(shí),尺度用于隱式量化和反量化值。
在處理隱式量化網(wǎng)絡(luò)時(shí),TensorRT 在應(yīng)用圖形優(yōu)化時(shí)將模型視為浮點(diǎn)模型,并適時(shí)的使用 INT8 來(lái)優(yōu)化層執(zhí)行時(shí)間。如果一個(gè)層在 INT8 中運(yùn)行得更快,那么它在 INT8 中執(zhí)行。否則,使用 FP32 或 FP16。在這種模式下,TensorRT 僅針對(duì)性能進(jìn)行優(yōu)化,您幾乎無(wú)法控制 INT8 的使用位置——即使您在 API 級(jí)別明確設(shè)置層的精度,TensorRT 也可能在圖優(yōu)化期間將該層與另一個(gè)層融合,并丟失它必須在 INT8 中執(zhí)行的信息。 TensorRT 的 PTQ 功能可生成隱式量化網(wǎng)絡(luò)。
在顯式量化的網(wǎng)絡(luò)中,在量化和未量化值之間轉(zhuǎn)換的縮放操作由圖中的IQuantizeLayer ( C++ , Python)和IDequantizeLayer ( C++ , Python ) 節(jié)點(diǎn)顯式表示 – 這些節(jié)點(diǎn)此后將被稱為 Q/DQ 節(jié)點(diǎn)。與隱式量化相比,顯式形式精確地指定了與 INT8 之間的轉(zhuǎn)換在何處執(zhí)行,并且優(yōu)化器將僅執(zhí)行由模型語(yǔ)義規(guī)定的精度轉(zhuǎn)換,即使:
- 添加額外的轉(zhuǎn)換可以提高層精度(例如,選擇 FP16 內(nèi)核實(shí)現(xiàn)而不是 INT8 實(shí)現(xiàn))
- 添加額外的轉(zhuǎn)換會(huì)導(dǎo)致引擎執(zhí)行得更快(例如,選擇 INT8 內(nèi)核實(shí)現(xiàn)來(lái)執(zhí)行指定為具有浮點(diǎn)精度的層,反之亦然)
ONNX 使用顯式量化表示 – 當(dāng) PyTorch 或 TensorFlow 中的模型導(dǎo)出到 ONNX 時(shí),框架圖中的每個(gè)偽量化操作都導(dǎo)出為 Q,然后是 DQ。由于 TensorRT 保留了這些層的語(yǔ)義,因此您可以期望任務(wù)準(zhǔn)確度非常接近框架中看到的準(zhǔn)確度。雖然優(yōu)化保留了量化和去量化的位置,但它們可能會(huì)改變模型中浮點(diǎn)運(yùn)算的順序,因此結(jié)果不會(huì)按位相同。 請(qǐng)注意,與 TensorRT 的 PTQ 相比,在框架中執(zhí)行 QAT 或 PTQ 然后導(dǎo)出到 ONNX 將產(chǎn)生一個(gè)明確量化的模型。Table 2. Implicit vs Explicit Quantization
有關(guān)量化的更多背景信息,請(qǐng)參閱深度學(xué)習(xí)推理的整數(shù)量化:原理和實(shí)證評(píng)估論文。
7.1.3. Per-Tensor and Per-Channel Quantization
有兩種常見(jiàn)的量化尺度粒度:
每張量量化:其中使用單個(gè)比例值(標(biāo)量)來(lái)縮放整個(gè)張量。
每通道量化:沿給定軸廣播尺度張量 – 對(duì)于卷積神經(jīng)網(wǎng)絡(luò),這通常是通道軸。
通過(guò)顯式量化,權(quán)重可以使用每張量量化進(jìn)行量化,也可以使用每通道量化進(jìn)行量化。在任何一種情況下,比例精度都是 FP32。激活只能使用每張量量化來(lái)量化。
當(dāng)使用每通道量化時(shí),量化軸必須是輸出通道軸。例如,當(dāng)使用KCRS表示法描述 2D 卷積的權(quán)重時(shí), K是輸出通道軸,權(quán)重量化可以描述為:
For each k in K: For each c in C: For each r in R: For each s in S: output[k,c,r,s] := clamp(round(input[k,c,r,s] / scale[k]))
比例尺是一個(gè)系數(shù)向量,必須與量化軸具有相同的大小。量化尺度必須由所有正浮點(diǎn)系數(shù)組成。四舍五入方法是四舍五入到最近的關(guān)系到偶數(shù),并且鉗位在[-128, 127]范圍內(nèi)。
除了定義為的逐點(diǎn)操作外,反量化的執(zhí)行方式類似:
output[k,c,r,s] := input[k,c,r,s] * scale[k]
TensorRT 僅支持激活張量的每張量量化,但支持卷積、反卷積、全連接層和 MatMul 的每通道權(quán)重量化,其中第二個(gè)輸入是常數(shù)且兩個(gè)輸入矩陣都是二維的。7.2. Setting Dynamic Range
TensorRT 提供 API 來(lái)直接設(shè)置動(dòng)態(tài)范圍(必須由量化張量表示的范圍),以支持在 TensorRT 之外計(jì)算這些值的隱式量化。 API 允許使用最小值和最大值設(shè)置張量的動(dòng)態(tài)范圍。由于 TensorRT 目前僅支持對(duì)稱范圍,因此使用max(abs(min_float), abs(max_float))計(jì)算比例。請(qǐng)注意,當(dāng)abs(min_float) != abs(max_float)時(shí),TensorRT 使用比配置更大的動(dòng)態(tài)范圍,這可能會(huì)增加舍入誤差。
將在 INT8 中執(zhí)行的操作的所有浮點(diǎn)輸入和輸出都需要?jiǎng)討B(tài)范圍。
您可以按如下方式設(shè)置張量的動(dòng)態(tài)范圍: C++
tensor-》setDynamicRange(min_float, max_float);
Python
tensor.dynamic_range = (min_float, max_float)
sampleINT8API說(shuō)明了這些 API 在 C++ 中的使用。
7.3. Post-Training Quantization using Calibration
在訓(xùn)練后量化中,TensorRT 計(jì)算網(wǎng)絡(luò)中每個(gè)張量的比例值。這個(gè)過(guò)程稱為校準(zhǔn),需要您提供有代表性的輸入數(shù)據(jù),TensorRT 在其上運(yùn)行網(wǎng)絡(luò)以收集每個(gè)激活張量的統(tǒng)計(jì)信息。
所需的輸入數(shù)據(jù)量取決于應(yīng)用程序,但實(shí)驗(yàn)表明大約 500 張圖像足以校準(zhǔn) ImageNet 分類網(wǎng)絡(luò)。
給定激活張量的統(tǒng)計(jì)數(shù)據(jù),決定最佳尺度值并不是一門精確的科學(xué)——它需要平衡量化表示中的兩個(gè)誤差源:離散化誤差(隨著每個(gè)量化值表示的范圍變大而增加)和截?cái)嗾`差(其中值被限制在可表示范圍的極限)。因此,TensorRT 提供了多個(gè)不同的校準(zhǔn)器,它們以不同的方式計(jì)算比例。較舊的校準(zhǔn)器還為 GPU 執(zhí)行層融合,以在執(zhí)行校準(zhǔn)之前優(yōu)化掉不需要的張量。這在使用 DLA 時(shí)可能會(huì)出現(xiàn)問(wèn)題,其中融合模式可能不同,并且可以使用kCALIBRATE_BEFORE_FUSION量化標(biāo)志覆蓋。
IInt8EntropyCalibrator2
熵校準(zhǔn)選擇張量的比例因子來(lái)優(yōu)化量化張量的信息論內(nèi)容,通常會(huì)抑制分布中的異常值。這是當(dāng)前推薦的熵校準(zhǔn)器,是 DLA 所必需的。默認(rèn)情況下,校準(zhǔn)發(fā)生在圖層融合之前。推薦用于基于 CNN 的網(wǎng)絡(luò)。
IInt8MinMaxCalibrator
該校準(zhǔn)器使用激活分布的整個(gè)范圍來(lái)確定比例因子。它似乎更適合 NLP 任務(wù)。默認(rèn)情況下,校準(zhǔn)發(fā)生在圖層融合之前。推薦用于 NVIDIA BERT(谷歌官方實(shí)現(xiàn)的優(yōu)化版本)等網(wǎng)絡(luò)。
IInt8EntropyCalibrator
這是原始的熵校準(zhǔn)器。它的使用沒(méi)有 LegacyCalibrator 復(fù)雜,通常會(huì)產(chǎn)生更好的結(jié)果。默認(rèn)情況下,校準(zhǔn)發(fā)生在圖層融合之后。
IInt8LegacyCalibrator
該校準(zhǔn)器與 TensorRT 2.0 EA 兼容。此校準(zhǔn)器需要用戶參數(shù)化,并且在其他校準(zhǔn)器產(chǎn)生不良結(jié)果時(shí)作為備用選項(xiàng)提供。默認(rèn)情況下,校準(zhǔn)發(fā)生在圖層融合之后。您可以自定義此校準(zhǔn)器以實(shí)現(xiàn)最大百分比,例如,觀察到 99.99% 的最大百分比對(duì)于 NVIDIA BERT 具有最佳精度。
構(gòu)建 INT8 引擎時(shí),構(gòu)建器執(zhí)行以下步驟:
構(gòu)建一個(gè) 32 位引擎,在校準(zhǔn)集上運(yùn)行它,并為激活值分布的每個(gè)張量記錄一個(gè)直方圖。
從直方圖構(gòu)建一個(gè)校準(zhǔn)表,為每個(gè)張量提供一個(gè)比例值。
根據(jù)校準(zhǔn)表和網(wǎng)絡(luò)定義構(gòu)建 INT8 引擎。
校準(zhǔn)可能很慢;因此步驟 2 的輸出(校準(zhǔn)表)可以被緩存和重用。這在多次構(gòu)建相同的網(wǎng)絡(luò)時(shí)非常有用,例如,在多個(gè)平臺(tái)上 – 特別是,它可以簡(jiǎn)化工作流程,在具有離散 GPU 的機(jī)器上構(gòu)建校準(zhǔn)表,然后在嵌入式平臺(tái)上重用它。可在此處找到樣本校準(zhǔn)表。 在運(yùn)行校準(zhǔn)之前,TensorRT 會(huì)查詢校準(zhǔn)器實(shí)現(xiàn)以查看它是否有權(quán)訪問(wèn)緩存表。如果是這樣,它直接進(jìn)行到上面的步驟 3。緩存數(shù)據(jù)作為指針和長(zhǎng)度傳遞。
只要校準(zhǔn)發(fā)生在層融合之前,校準(zhǔn)緩存數(shù)據(jù)就可以在平臺(tái)之間以及為不同設(shè)備構(gòu)建引擎時(shí)移植。這意味著在默認(rèn)情況下使用IInt8EntropyCalibrator2或IInt8MinMaxCalibrator校準(zhǔn)器或設(shè)置QuantizationFlag::kCALIBRATE_BEFORE_FUSION時(shí),校準(zhǔn)緩存是可移植的。不能保證跨平臺(tái)或設(shè)備的融合是相同的,因此在層融合之后進(jìn)行校準(zhǔn)可能不會(huì)產(chǎn)生便攜式校準(zhǔn)緩存。 除了量化激活,TensorRT 還必須量化權(quán)重。它使用對(duì)稱量化和使用權(quán)重張量中找到的最大絕對(duì)值計(jì)算的量化比例。對(duì)于卷積、反卷積和全連接權(quán)重,尺度是每個(gè)通道的。
注意:當(dāng)構(gòu)建器配置為使用 INT8 I/O 時(shí),TensorRT 仍希望校準(zhǔn)數(shù)據(jù)位于 FP32 中。您可以通過(guò)將 INT8 I/O 校準(zhǔn)數(shù)據(jù)轉(zhuǎn)換為 FP32 精度來(lái)創(chuàng)建 FP32 校準(zhǔn)數(shù)據(jù)。您還必須確保 FP32 投射校準(zhǔn)數(shù)據(jù)在[-128.0F, 127.0F]范圍內(nèi),因此可以轉(zhuǎn)換為 INT8 數(shù)據(jù)而不會(huì)造成任何精度損失。
INT8 校準(zhǔn)可與動(dòng)態(tài)范圍 API 一起使用。手動(dòng)設(shè)置動(dòng)態(tài)范圍會(huì)覆蓋 INT8 校準(zhǔn)生成的動(dòng)態(tài)范圍。
注意:校準(zhǔn)是確定性的——也就是說(shuō),如果您在同一設(shè)備上以相同的順序?yàn)?TensorRT 提供相同的校準(zhǔn)輸入,則生成的比例在不同的運(yùn)行中將是相同的。當(dāng)提供相同的校準(zhǔn)輸入時(shí),當(dāng)使用具有相同批量大小的相同設(shè)備生成時(shí),校準(zhǔn)緩存中的數(shù)據(jù)將按位相同。當(dāng)使用不同的設(shè)備、不同的批量大小或使用不同的校準(zhǔn)輸入生成校準(zhǔn)緩存時(shí),不能保證校準(zhǔn)緩存中的確切數(shù)據(jù)按位相同。
7.3.1. INT8 Calibration Using C++
要向 TensorRT 提供校準(zhǔn)數(shù)據(jù),請(qǐng)實(shí)現(xiàn)IInt8Calibrator接口。
關(guān)于這個(gè)任務(wù)
構(gòu)建器調(diào)用校準(zhǔn)器如下:
首先,它查詢接口的批次大小并調(diào)用getBatchSize()來(lái)確定預(yù)期的輸入批次的大小。
然后,它反復(fù)調(diào)用getBatch()來(lái)獲取批量輸入。批次必須與getBatchSize()的批次大小完全相同。當(dāng)沒(méi)有更多批次時(shí), getBatch()必須返回false 。
實(shí)現(xiàn)校準(zhǔn)器后,您可以配置構(gòu)建器以使用它:
config->setInt8Calibrator(calibrator.get());
要緩存校準(zhǔn)表,請(qǐng)實(shí)現(xiàn)writeCalibrationCache()和readCalibrationCache()方法。
有關(guān)配置 INT8 校準(zhǔn)器對(duì)象的更多信息,請(qǐng)參閱sampleINT8
7.3.2. Calibration Using Python
以下步驟說(shuō)明了如何使用 Python API 創(chuàng)建 INT8 校準(zhǔn)器對(duì)象。 程序
導(dǎo)入 TensorRT:
import tensorrt as trt
NUM_IMAGES_PER_BATCH = 5 batchstream = ImageBatchStream(NUM_IMAGES_PER_BATCH, calibration_files)
Int8_calibrator = EntropyCalibrator(["input_node_name"], batchstream)
config.set_flag(trt.BuilderFlag.INT8) config.int8_calibrator = Int8_calibrator
7.4. Explicit Quantization
當(dāng) TensorRT 檢測(cè)到網(wǎng)絡(luò)中存在 Q/DQ 層時(shí),它會(huì)使用顯式精度處理邏輯構(gòu)建一個(gè)引擎。
AQ/DQ 網(wǎng)絡(luò)必須在啟用 INT8 精度構(gòu)建器標(biāo)志的情況下構(gòu)建:
config->setFlag(BuilderFlag::kINT8);
在顯式量化中,表示與 INT8 之間的網(wǎng)絡(luò)變化是顯式的,因此,INT8 不能用作類型約束。7.4.1. Quantized Weights
Q/DQ 模型的權(quán)重必須使用 FP32 數(shù)據(jù)類型指定。 TensorRT 使用對(duì)權(quán)重進(jìn)行操作的IQuantizeLayer的比例對(duì)權(quán)重進(jìn)行量化。量化的權(quán)重存儲(chǔ)在引擎文件中。也可以使用預(yù)量化權(quán)重,但必須使用 FP32 數(shù)據(jù)類型指定。 Q 節(jié)點(diǎn)的 scale 必須設(shè)置為1.0F ,但 DQ 節(jié)點(diǎn)必須是真實(shí)的 scale 值。
7.4.2. ONNX Support
當(dāng)使用 Quantization Aware Training (QAT) 在 PyTorch 或 TensorFlow 中訓(xùn)練的模型導(dǎo)出到 ONNX 時(shí),框架圖中的每個(gè)偽量化操作都會(huì)導(dǎo)出為一對(duì)QuantizeLinear和DequantizeLinear ONNX 運(yùn)算符。
當(dāng) TensorRT 導(dǎo)入 ONNX 模型時(shí),ONNX QuantizeLinear算子作為IQuantizeLayer實(shí)例導(dǎo)入,ONNX DequantizeLinear算子作為IDequantizeLayer實(shí)例導(dǎo)入。
使用 opset 10 的 ONNX 引入了對(duì) QuantizeLinear/DequantizeLinear 的支持,并且在 opset 13 中添加了量化軸屬性(每通道量化所必需的)。 PyTorch 1.8 引入了對(duì)使用 opset 13 將 PyTorch 模型導(dǎo)出到 ONNX 的支持。
警告: ONNX GEMM 算子是一個(gè)可以按通道量化的示例。 PyTorch torch.nn.Linear層導(dǎo)出為 ONNX GEMM 算子,具有(K, C)權(quán)重布局并啟用了transB GEMM 屬性(這會(huì)在執(zhí)行 GEMM 操作之前轉(zhuǎn)置權(quán)重)。另一方面,TensorFlow在 ONNX 導(dǎo)出之前預(yù)轉(zhuǎn)置權(quán)重(C, K) :
PyTorch: $y = xW^T$
TensorFlow: $y = xW$
因此,PyTorch 權(quán)重由 TensorRT 轉(zhuǎn)置。權(quán)重在轉(zhuǎn)置之前由 TensorRT 進(jìn)行量化,因此源自從 PyTorch 導(dǎo)出的 ONNX QAT 模型的 GEMM 層使用維度0進(jìn)行每通道量化(軸K = 0 );而源自 TensorFlow 的模型使用維度1 (軸K = 1 )。
TensorRT 不支持使用 INT8 張量或量化運(yùn)算符的預(yù)量化 ONNX 模型。具體來(lái)說(shuō),以下 ONNX 量化運(yùn)算符不受支持,如果在 TensorRT 導(dǎo)入 ONNX 模型時(shí)遇到它們,則會(huì)生成導(dǎo)入錯(cuò)誤:
QLinearConv/QLinearMatmul
ConvInteger/MatmulInteger
7.4.3. TensorRT Processing Of Q/DQ Networks
當(dāng) TensorRT 在 Q/DQ 模式下優(yōu)化網(wǎng)絡(luò)時(shí),優(yōu)化過(guò)程僅限于不改變網(wǎng)絡(luò)算術(shù)正確性的優(yōu)化。由于浮點(diǎn)運(yùn)算的順序會(huì)產(chǎn)生不同的結(jié)果(例如,重寫 $a * s + b * s$ 為 $(a + b) * s$是一個(gè)有效的優(yōu)化)。允許這些差異通常是后端優(yōu)化的基礎(chǔ),這也適用于將具有 Q/DQ 層的圖轉(zhuǎn)換為使用 INT8 計(jì)算。
Q/DQ 層控制網(wǎng)絡(luò)的計(jì)算和數(shù)據(jù)精度。 IQuantizeLayer實(shí)例通過(guò)量化將 FP32 張量轉(zhuǎn)換為 INT8 張量, IDequantizeLayer實(shí)例通過(guò)反量化將INT8張量轉(zhuǎn)換為 FP32 張量。 TensorRT 期望量化層的每個(gè)輸入上都有一個(gè) Q/DQ 層對(duì)。量化層是深度學(xué)習(xí)層,可以通過(guò)與IQuantizeLayer和IDequantizeLayer實(shí)例融合來(lái)轉(zhuǎn)換為量化層。當(dāng) TensorRT 執(zhí)行這些融合時(shí),它會(huì)將可量化層替換為實(shí)際使用 INT8 計(jì)算操作對(duì) INT8 數(shù)據(jù)進(jìn)行操作的量化層。
對(duì)于本章中使用的圖表,綠色表示 INT8 精度,藍(lán)色表示浮點(diǎn)精度。箭頭代表網(wǎng)絡(luò)激活張量,正方形代表網(wǎng)絡(luò)層。
下圖。 可量化的AveragePool層(藍(lán)色)與 DQ 層和 Q 層融合。所有三層都被量化的AveragePool層(綠色)替換。
在網(wǎng)絡(luò)優(yōu)化期間,TensorRT 在稱為 Q/DQ 傳播的過(guò)程中移動(dòng) Q/DQ 層。傳播的目標(biāo)是最大化以低精度處理的圖的比例。因此,TensorRT 向后傳播 Q 節(jié)點(diǎn)(以便盡可能早地進(jìn)行量化)和向前傳播 DQ 節(jié)點(diǎn)(以便盡可能晚地進(jìn)行去量化)。 Q-layers 可以與 commute-with-Quantization 層交換位置,DQ-layers 可以與 commute-with-Dequantization 層交換位置。
A layer Op commutes with quantization if $Q (Op (x) ) ==Op (Q (x) )$
Similarly, a layer Op commutes with dequantization if $Op (DQ (x) ) ==DQ (Op (x) )$
下圖說(shuō)明了 DQ 前向傳播和 Q 后向傳播。這些是對(duì)模型的合法重寫,因?yàn)?Max Pooling 具有 INT8 實(shí)現(xiàn),并且因?yàn)?Max Pooling 與 DQ 和 Q 通訊。
下圖描述 DQ 前向傳播和 Q 后向傳播的插圖。
注意:
為了理解最大池化交換,讓我們看一下應(yīng)用于某個(gè)任意輸入的最大池化操作的輸出。 Max Pooling應(yīng)用于輸入系數(shù)組并輸出具有最大值的系數(shù)。對(duì)于由系數(shù)組成的組i : ${x_0 。 . x_m}$
$utput_i := max({x_0, x_1, … x_m}) = max({max({max({x_0, x_1}), x_2)}, … x_m})$
因此,在不失一般性(WLOG)的情況下查看兩個(gè)任意系數(shù)就足夠了:
$x_j = max({x_j, x_k})\ \ \ for\ \ \ x_j 》= x_k$
對(duì)于量化函數(shù)$Q(a, scale, x_max, x_min) := truncate(round(a/scale), x_max,x_min)$ 來(lái)說(shuō)$scale》0$, 注意(不提供證明,并使用簡(jiǎn)化符號(hào)):
$Q(x_j, scale) 》= Q(x_k, scale)\ \ \ for\ \ \ x_j 》= x_k$
因此:
$max({Q(x_j, scale), Q(x_k, scale)}) = Q(x_j, scale)\ \ \ for\ \ \ x_j 》= x_k$
然而,根據(jù)定義:
$Q(max({x_j, x_k}), scale) = Q(x_j, scale)\ \ \ for\ \ \ x_j 》= x_k$
函數(shù) $max$ commutes-with-quantization 和 Max Pooling 也是如此。
類似地,對(duì)于去量化,函數(shù)$DQ (a, scale) :=a * scale with scale》0$ 我們可以證明:
$max({DQ(x_j, scale), DQ(x_k, scale)}) = DQ(x_j, scale) = DQ(max({x_j, x_k}), scale)\ \ \ for\ \ \ x_j 》= x_k$
量化層和交換層的處理方式是有區(qū)別的。兩種類型的層都可以在 INT8 中計(jì)算,但可量化層也與 DQ 輸入層和 Q 輸出層融合。例如, AveragePooling層(可量化)不與 Q 或 DQ 交換,因此使用 Q/DQ 融合對(duì)其進(jìn)行量化,如第一張圖所示。這與如何量化 Max Pooling(交換)形成對(duì)比。
7.4.4. Q/DQ Layer-Placement Recommendations
Q/DQ 層在網(wǎng)絡(luò)中的放置會(huì)影響性能和準(zhǔn)確性。由于量化引入的誤差,激進(jìn)量化會(huì)導(dǎo)致模型精度下降。但量化也可以減少延遲。此處列出了在網(wǎng)絡(luò)中放置 Q/DQ 層的一些建議。
量化加權(quán)運(yùn)算(卷積、轉(zhuǎn)置卷積和 GEMM)的所有輸入。權(quán)重和激活的量化降低了帶寬需求,還使 INT8 計(jì)算能夠加速帶寬受限和計(jì)算受限的層。
下圖 TensorRT 如何融合卷積層的兩個(gè)示例。在左邊,只有輸入被量化。在右邊,輸入和輸出都被量化了。
默認(rèn)情況下,不量化加權(quán)運(yùn)算的輸出。保留更高精度的去量化輸出有時(shí)很有用。例如,如果線性運(yùn)算后面跟著一個(gè)激活函數(shù)(SiLU,下圖中),它需要更高的精度輸入才能產(chǎn)生可接受的精度。
不要在訓(xùn)練框架中模擬批量歸一化和 ReLU 融合,因?yàn)?TensorRT 優(yōu)化保證保留這些操作的算術(shù)語(yǔ)義。
TensorRT 可以在加權(quán)層之后融合element-wise addition,這對(duì)于像 ResNet 和 EfficientNet 這樣具有跳躍連接的模型很有用。element-wise addition層的第一個(gè)輸入的精度決定了融合輸出的精度。
比如下圖中,$x_f^1$的精度是浮點(diǎn)數(shù),所以融合卷積的輸出僅限于浮點(diǎn)數(shù),后面的Q層不能和卷積融合。
相比之下,當(dāng)$x_f^1$量化為 INT8 時(shí),如下圖所示,融合卷積的輸出也是 INT8,尾部的 Q 層與卷積融合。
為了獲得額外的性能,請(qǐng)嘗試使用 Q/DQ 量化不交換的層。目前,具有 INT8 輸入的非加權(quán)層也需要 INT8 輸出,因此對(duì)輸入和輸出都進(jìn)行量化。
如果 TensorRT 無(wú)法將操作與周圍的 Q/DQ 層融合,則性能可能會(huì)降低,因此在添加 Q/DQ 節(jié)點(diǎn)時(shí)要保守,并牢記準(zhǔn)確性和 TensorRT 性能進(jìn)行試驗(yàn)。
下圖是額外 Q/DQ 操作可能導(dǎo)致的次優(yōu)融合示例(突出顯示的淺綠色背景矩形)。
對(duì)激活使用逐張量量化;和每個(gè)通道的權(quán)重量化。這種配置已經(jīng)被經(jīng)驗(yàn)證明可以帶來(lái)最佳的量化精度。
您可以通過(guò)啟用 FP16 進(jìn)一步優(yōu)化引擎延遲。 TensorRT 盡可能嘗試使用 FP16 而不是 FP32(目前并非所有層類型都支持)
7.4.5. Q/DQ Limitations
TensorRT 執(zhí)行的一些 Q/DQ 圖重寫優(yōu)化比較兩個(gè)或多個(gè) Q/DQ 層之間的量化尺度值,并且僅在比較的量化尺度相等時(shí)才執(zhí)行圖重寫。改裝可改裝的 TensorRT 引擎時(shí),可以為 Q/DQ 節(jié)點(diǎn)的尺度分配新值。在 Q/DQ 引擎的改裝操作期間,TensorRT 檢查是否為參與尺度相關(guān)優(yōu)化的 Q/DQ 層分配了破壞重寫優(yōu)化的新值,如果為真則拋出異常。
下比較 Q1 和 Q2 的尺度是否相等的示例,如果相等,則允許它們向后傳播。如果使用 Q1 和 Q2 的新值對(duì)引擎進(jìn)行改裝,使得Q1 != Q2 ,則異常中止改裝過(guò)程。
7.4.6. QAT Networks Using TensorFlow
目前,沒(méi)有用于 TensorRT 的 TensorFlow 量化工具包,但是,有幾種推薦的方法:
TensorFlow 2 引入了一個(gè)新的 API 來(lái)在 QAT(量化感知訓(xùn)練)中執(zhí)行偽量化: tf.quantization.quantize_and_dequantize_v2 該算子使用與 TensorRT 的量化方案一致的對(duì)稱量化。我們推薦這個(gè) API 而不是 TensorFlow 1 tf.quantization.quantize_and_dequantize API。 導(dǎo)出到 ONNX 時(shí),可以使用tf2onnx轉(zhuǎn)換器將quantize_and_dequantize_v2算子轉(zhuǎn)換為一對(duì) QuantizeLinear 和 DequantizeLinear 算子(Q/DQ 算子) 。請(qǐng)參閱quantization_ops_rewriter以了解如何執(zhí)行此轉(zhuǎn)換。
默認(rèn)情況下,TensorFlow 將tf.quantization.quantize_and_dequantize_v2算子(導(dǎo)出到 ONNX 后的 Q/DQ 節(jié)點(diǎn))放在算子輸出上,而 TensorRT 建議將 Q/DQ 放在層輸入上。有關(guān)詳細(xì)信息,請(qǐng)參閱QDQ 位置。
TensorFlow 1 不支持每通道量化 (PCQ)。建議將 PCQ 用于權(quán)重,以保持模型的準(zhǔn)確性。
7.4.7. QAT Networks Using PyTorch
PyTorch 1.8.0 和前版支持 ONNX QuantizeLinear / DequantizeLinear ,支持每通道縮放。您可以使用pytorch-quantization進(jìn)行 INT8 校準(zhǔn),運(yùn)行量化感知微調(diào),生成 ONNX,最后使用 TensorRT 在此 ONNX 模型上運(yùn)行推理。更多詳細(xì)信息可以在PyTorch-Quantization Toolkit 用戶指南中找到。
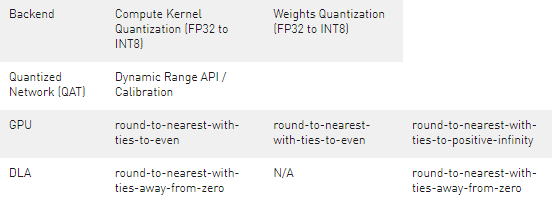
7.5. INT8 Rounding Modes
關(guān)于作者
Ken He 是 NVIDIA 企業(yè)級(jí)開(kāi)發(fā)者社區(qū)經(jīng)理 & 高級(jí)講師,擁有多年的 GPU 和人工智能開(kāi)發(fā)經(jīng)驗(yàn)。自 2017 年加入 NVIDIA 開(kāi)發(fā)者社區(qū)以來(lái),完成過(guò)上百場(chǎng)培訓(xùn),幫助上萬(wàn)個(gè)開(kāi)發(fā)者了解人工智能和 GPU 編程開(kāi)發(fā)。在計(jì)算機(jī)視覺(jué),高性能計(jì)算領(lǐng)域完成過(guò)多個(gè)獨(dú)立項(xiàng)目。并且,在機(jī)器人和無(wú)人機(jī)領(lǐng)域,有過(guò)豐富的研發(fā)經(jīng)驗(yàn)。對(duì)于圖像識(shí)別,目標(biāo)的檢測(cè)與跟蹤完成過(guò)多種解決方案。曾經(jīng)參與 GPU 版氣象模式GRAPES,是其主要研發(fā)者。
審核編輯:郭婷
-
API
+關(guān)注
關(guān)注
2文章
1502瀏覽量
62099 -
引擎
+關(guān)注
關(guān)注
1文章
361瀏覽量
22579
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
解鎖NVIDIA TensorRT-LLM的卓越性能
TensorRT-LLM低精度推理優(yōu)化

基于FPGA的數(shù)字信號(hào)處理——浮點(diǎn)數(shù)

西門子博途新數(shù)據(jù)類型之:SINT(8位整數(shù))

LM4675測(cè)試條件中負(fù)載電阻的2個(gè)15uH的電感參數(shù)表示什么意思?
鴻蒙原生應(yīng)用元服務(wù)開(kāi)發(fā)-倉(cāng)頡基礎(chǔ)數(shù)據(jù)類型整數(shù)類型
鴻蒙原生應(yīng)用元服務(wù)開(kāi)發(fā)-倉(cāng)頡基礎(chǔ)數(shù)據(jù)類型浮點(diǎn)類型
MATLAB(1)--MATLAB數(shù)值數(shù)據(jù)
labview數(shù)據(jù)類型的取值范圍是多少
深度神經(jīng)網(wǎng)絡(luò)模型量化的基本方法
未來(lái)輕量級(jí)深度學(xué)習(xí)技術(shù)探索
選用8位和32位MCU的關(guān)鍵考量
verilog語(yǔ)音實(shí)現(xiàn)浮點(diǎn)運(yùn)算
分享一個(gè)適用于 HPM6300 AndeStar V5 DSP 擴(kuò)展指令的 32位有符號(hào)整數(shù) 全周傅里葉算法加速器
一文帶你秒懂IEEE 754浮點(diǎn)數(shù)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論