") 稠密檢索模型在zero-shot場(chǎng)景下的泛化能力
稠密檢索模型在zero-shot場(chǎng)景下的泛化能力
引言
隨著預(yù)訓(xùn)練語(yǔ)言模型在自然語(yǔ)言處理領(lǐng)域的蓬勃發(fā)展,基于預(yù)訓(xùn)練語(yǔ)言模型的稠密檢索(dense retrieval)近年來也變成了主流的一階段檢索(召回)技術(shù),在學(xué)術(shù)界和工業(yè)界均已經(jīng)得到了廣泛的研究。與傳統(tǒng)的基于字面匹配的稀疏檢索(sparse retrieval)模型相比,稠密檢索模型通過學(xué)習(xí)低維的查詢和文檔向量來實(shí)現(xiàn)語(yǔ)義級(jí)別的檢索,能夠更好地理解用戶的查詢意圖,返回能夠更好地滿足用戶信息需求的結(jié)果。
通常情況下,訓(xùn)練一個(gè)優(yōu)秀的稠密檢索模型離不開大規(guī)模的人工標(biāo)注數(shù)據(jù),然而,在很多應(yīng)用場(chǎng)景和業(yè)務(wù)問題上,這種與領(lǐng)域相關(guān)的大規(guī)模標(biāo)注數(shù)據(jù)非常難以獲得,因此稠密檢索模型的零樣本域外泛化能力(zero-shot OOD generalizability)就變得非常重要。在實(shí)際應(yīng)用中,不同領(lǐng)域之間通常存在較大差異,這種zero-shot能力直接影響著稠密檢索模型在現(xiàn)實(shí)場(chǎng)景中的大規(guī)模應(yīng)用。相比之下,傳統(tǒng)的BM25可以簡(jiǎn)單有效地部署在不同場(chǎng)景下,如果稠密檢索模型無(wú)法在現(xiàn)實(shí)場(chǎng)景中取得比BM25顯著優(yōu)異的性能,則稠密檢索模型的應(yīng)用價(jià)值將會(huì)大打折扣。
目前,已經(jīng)有一些工作開始研究如何評(píng)估稠密檢索模型的zero-shot泛化能力以及提高該能力的方法。現(xiàn)有的一些研究指出,稠密檢索模型的zero-shot能力非常有限,在某些場(chǎng)景下甚至無(wú)法超越傳統(tǒng)的BM25算法。然而,現(xiàn)有研究的實(shí)驗(yàn)設(shè)置相對(duì)比較單一,大多關(guān)注于模型在不同目標(biāo)領(lǐng)域上的測(cè)試結(jié)果,而沒有關(guān)注不同的源域設(shè)置會(huì)如何影響模型的zero-shot泛化性能,從而導(dǎo)致我們并不清楚是什么因素影響了稠密檢索模型的零樣本泛化能力。
因此,本文針對(duì)zero-shot場(chǎng)景下的稠密檢索模型泛化能力進(jìn)行了較為深入的研究,旨在理解何種因素影響了稠密檢索模型的zero-shot泛化能力,以及如何改善這些因素從而提升模型的zero-shot泛化能力。為此,我們?cè)O(shè)計(jì)了充分的實(shí)驗(yàn),從源域query分布、源域document分布、數(shù)據(jù)規(guī)模、目標(biāo)域分布偏移程度等幾個(gè)方面進(jìn)行了全面的分析,并發(fā)現(xiàn)了不同因素對(duì)模型zero-shot泛化能力的影響。另外,我們還系統(tǒng)梳理了近期出現(xiàn)的幾種提升zero-shot泛化性能的優(yōu)化策略,并指出每種策略是如何影響上述幾個(gè)因素從而實(shí)現(xiàn)改進(jìn)的。
背景和設(shè)置
Zero-shot場(chǎng)景下的稠密檢索
稠密檢索任務(wù)旨在通過給定的query,在一個(gè)龐大的document語(yǔ)料庫(kù)中召回與query高度相關(guān)的document(本文中document泛指語(yǔ)料庫(kù)中的文本內(nèi)容,可以是句子,段落,文章等),其中query和document的語(yǔ)義相關(guān)性通常建模為query和document表示向量的點(diǎn)積或余弦相似度。本文主要關(guān)注zero-shot場(chǎng)景下的稠密檢索,即使用源域上的標(biāo)注數(shù)據(jù)訓(xùn)練模型,在目標(biāo)領(lǐng)域的測(cè)試集上評(píng)估模型,且不能使用該目標(biāo)域上的標(biāo)注數(shù)據(jù)進(jìn)一步訓(xùn)練模型。
數(shù)據(jù)集
為了能夠更全面地評(píng)估稠密檢索模型的zero-shot泛化能力,我們收集了12個(gè)當(dāng)前常用的檢索數(shù)據(jù)集,它們分屬于多個(gè)不同領(lǐng)域,其數(shù)據(jù)特性也各不相同。我們把這些數(shù)據(jù)集劃分為源域數(shù)據(jù)集和目標(biāo)域數(shù)據(jù)集,其中每個(gè)數(shù)據(jù)集都有對(duì)應(yīng)的query集合和document集合。數(shù)據(jù)的統(tǒng)計(jì)信息如下表所示:
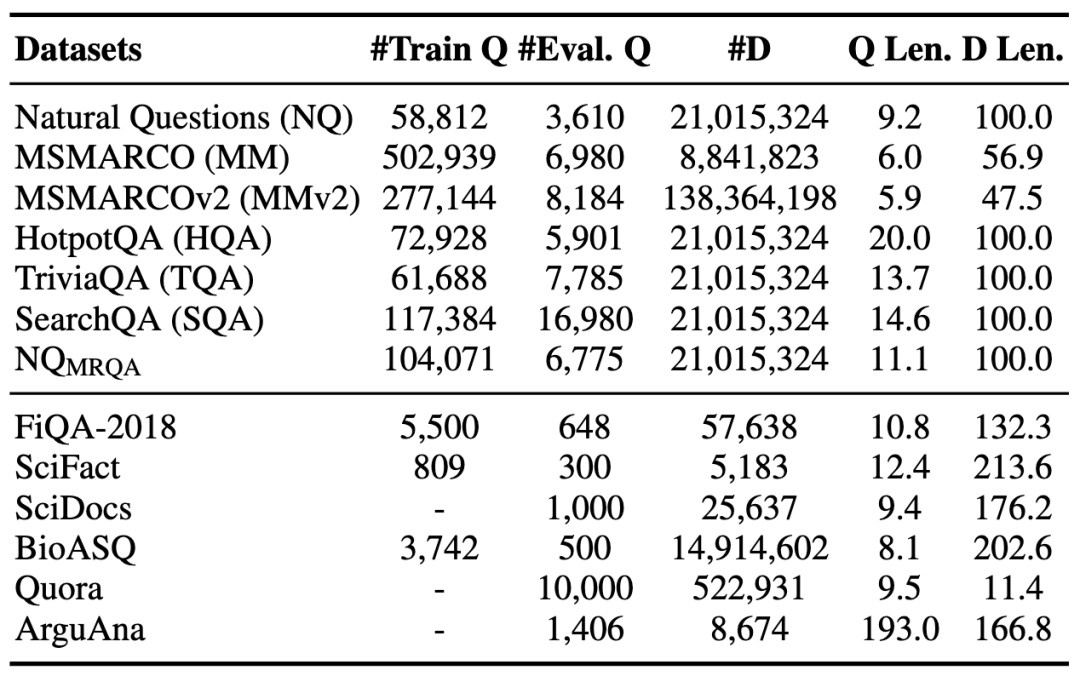
表1 數(shù)據(jù)集概覽。上半部分為源領(lǐng)域數(shù)據(jù)集,下半部分為目標(biāo)領(lǐng)域數(shù)據(jù)集
后續(xù)分析實(shí)驗(yàn)中,我們采用控制變量法,分別調(diào)整源領(lǐng)域上訓(xùn)練樣本的構(gòu)造方式,從而探索樣本層面不同因素對(duì)于模型zero-shot能力的影響。我們使用
MSMARCO和NQ上的初步分析
為了初步理解稠密檢索模型的zero-shot泛化能力,我們首先在兩個(gè)最常用的公開檢索數(shù)據(jù)集MSMARCO和NQ上進(jìn)行實(shí)驗(yàn)。本文中我們使用RocketQAv2[1]作為基礎(chǔ)模型,在這兩個(gè)數(shù)據(jù)集上分別訓(xùn)練模型(RocketQA(MSMARCO/NQ)),同時(shí)進(jìn)行了域內(nèi)和域外的模型性能評(píng)測(cè),結(jié)果如下表所示:
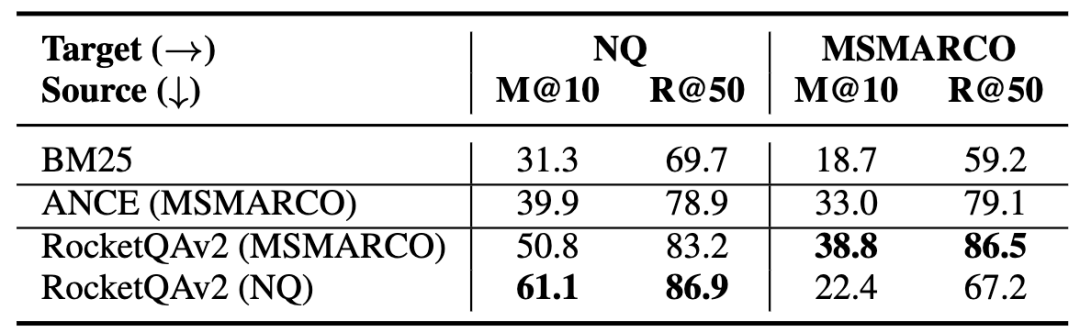
表2 MSMARCO和NQ上的評(píng)估結(jié)果
可以發(fā)現(xiàn),在這兩個(gè)數(shù)據(jù)集上,稠密檢索模型的zero-shot評(píng)估結(jié)果均優(yōu)于BM25。同時(shí),RocketQAv2(MSMARCO)的zero-shot泛化性能損失(MRR@10 61.1 -> 50.8)要低于RocketQAv2(NQ)的zero-shot泛化性能損失(MRR@10 38.8 -> 22.4),說明在MSMARCO上訓(xùn)練的稠密檢索模型的zero-shot泛化性能更好。
進(jìn)一步,我們還在六個(gè)目標(biāo)域數(shù)據(jù)集上分別測(cè)試了RocketQAv2(MSMARCO)和RocketQAv2(NQ)的zero-shot性能(表3 A部分)。我們發(fā)現(xiàn)RocketQAv2(MSMARCO)幾乎在所有目標(biāo)域數(shù)據(jù)集上的性能都領(lǐng)先于RocketQAv2(NQ)。另外值得注意的是,BM25也是一個(gè)較強(qiáng)的baseline,在某些數(shù)據(jù)集上大幅領(lǐng)先稠密檢索模型。
通過初步實(shí)驗(yàn),可以發(fā)現(xiàn)在不同的源域數(shù)據(jù)集上訓(xùn)練的模型的zero-shot泛化能力存在差異,但是由于MSMARCO和NQ的差異點(diǎn)很多,從目前的實(shí)驗(yàn)結(jié)果不能得到更多的結(jié)論。接下來,我們會(huì)從多個(gè)方面深入地分析有哪些因素影響著模型的zero-shot泛化能力。
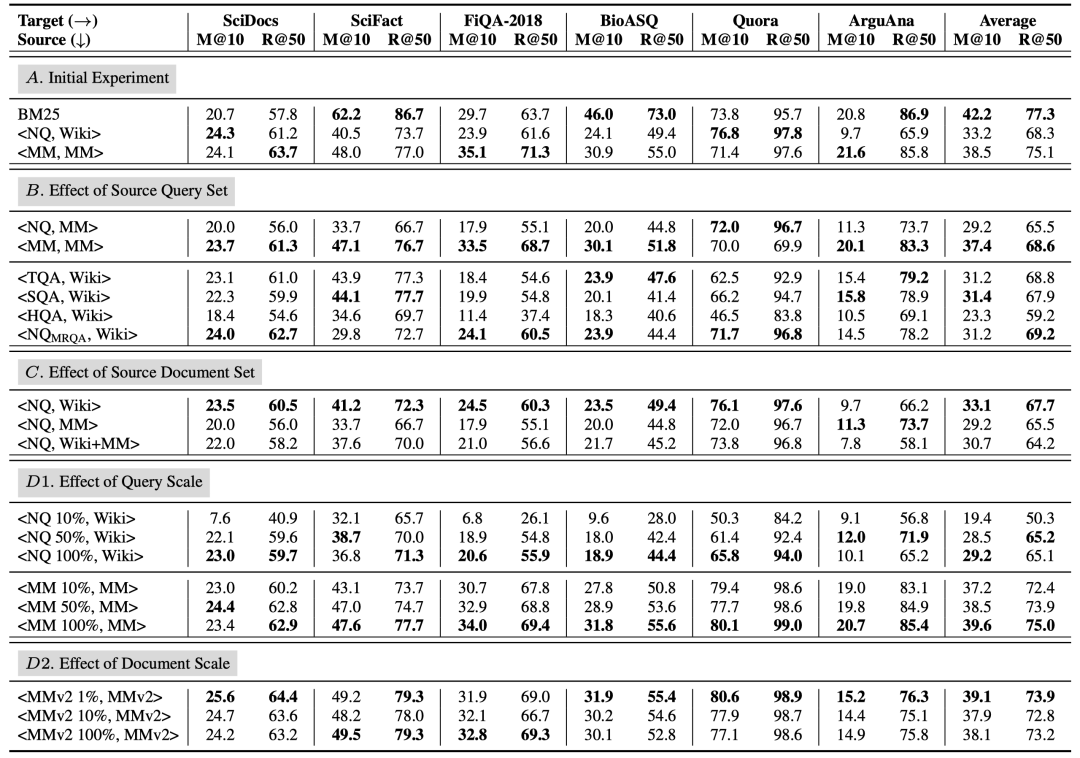
表3 六個(gè)目標(biāo)集上的評(píng)估結(jié)果。M@10和R@50分別為檢索模型的MRR@10和Recall@50的結(jié)果
分析與發(fā)現(xiàn)
1. 源領(lǐng)域query集合的影響
實(shí)驗(yàn)結(jié)果
為了研究源域query集合分布的影響,我們?cè)谙旅娴膶?shí)驗(yàn)中固定住document集合不變,只改變query集合進(jìn)行分析。
首先,我們固定MSMARCO作為document集合,分別使用NQ和MSMARCO的query集合構(gòu)造訓(xùn)練數(shù)據(jù)。另外,我們還收集了MRQA中的四個(gè)數(shù)據(jù)集,包括TriviaQA,SearchQA,HotpotQA和NQ,它們統(tǒng)一使用Wikipedia作為document集合。
表3(B部分)展示了模型在六個(gè)目標(biāo)數(shù)據(jù)集上的zero-shot結(jié)果。使用NQ訓(xùn)練的模型整體的zero-shot泛化性能弱于使用MSMARCO訓(xùn)練的模型,和上面初步實(shí)驗(yàn)中的結(jié)果一致,這也證明了源域query集合對(duì)稠密檢索模型的zero-shot能力有比較大的影響。同時(shí)我們發(fā)現(xiàn)HotpotQA訓(xùn)練的模型在目標(biāo)域數(shù)據(jù)集上的效果最差,因?yàn)樗膓uery主要由多跳問題組成,說明特殊格式的源域query集合可能會(huì)影響模型的zero-shot泛化性能。
基于這些實(shí)驗(yàn)分析,我們對(duì)更細(xì)節(jié)的因素進(jìn)行了研究。
query的詞匯重疊
詞匯重疊率是衡量?jī)蓚€(gè)領(lǐng)域相似性的重要指標(biāo),對(duì)于每個(gè)源域query集合和目標(biāo)域query集合的組合,我們計(jì)算了它們的weighted Jaccard相似度,該指標(biāo)越高說明兩個(gè)集合的詞匯重疊程度越高。
圖1(紅線)展示了在六個(gè)目標(biāo)域上,不同的源域和目標(biāo)域query詞匯重疊程度與模型zero-shot性能的關(guān)系(對(duì)應(yīng)表3結(jié)果),我們發(fā)現(xiàn)它們之間存在一定的正相關(guān)關(guān)系,因?yàn)楦蟮脑~項(xiàng)重疊程度意味著更大的領(lǐng)域相似度。document的詞匯重疊情況也有類似的結(jié)果(藍(lán)線),不再額外贅述。
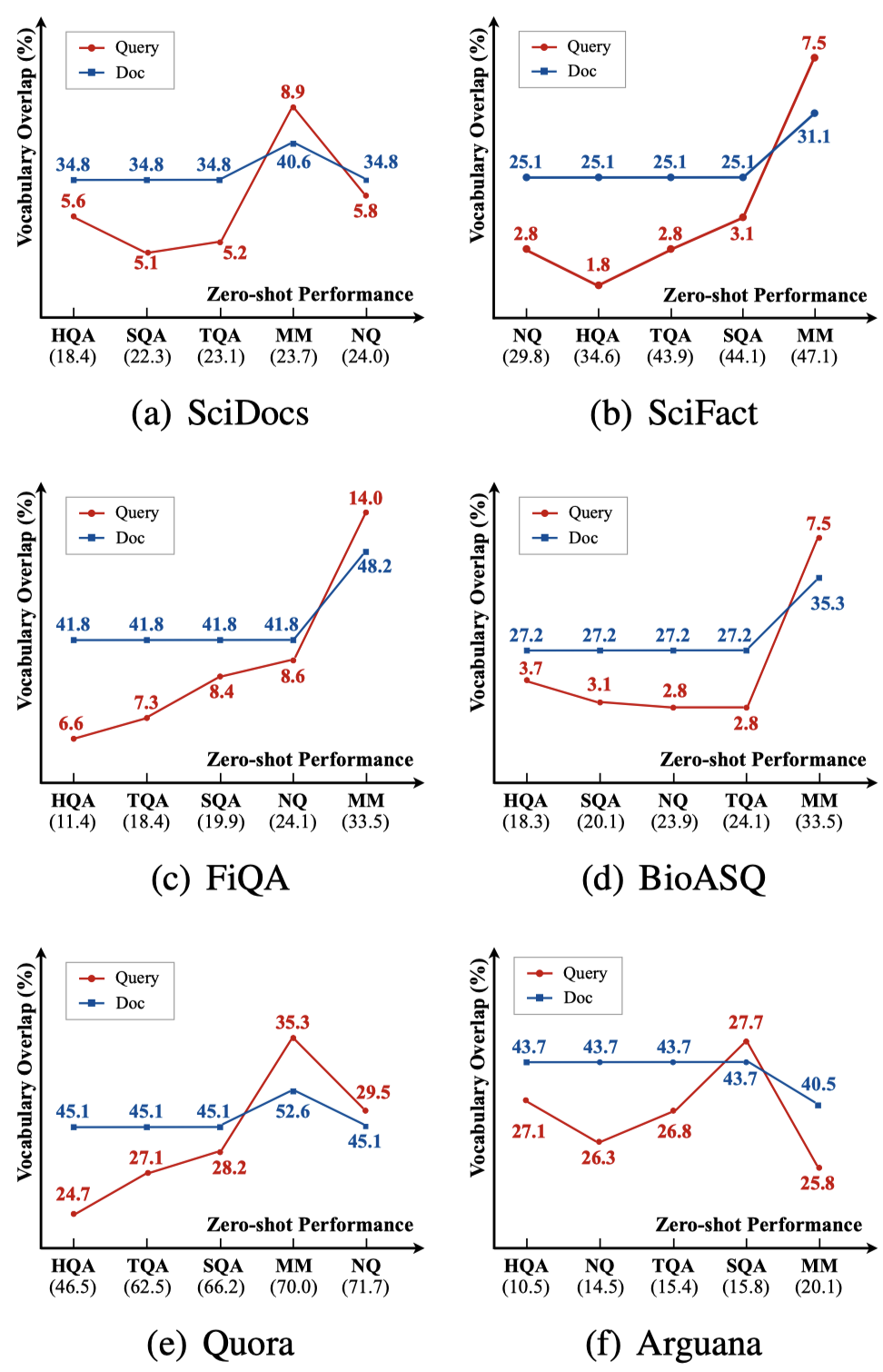
圖1 詞項(xiàng)重疊程度與zero-shot性能的關(guān)系。橫坐標(biāo)對(duì)應(yīng)在不同源領(lǐng)域訓(xùn)練模型從低到高的zero-shot性能,縱坐標(biāo)表示源領(lǐng)域和目標(biāo)領(lǐng)域間query/document的詞項(xiàng)重疊程度。
query的類型分布
另一個(gè)重要的因素是query的類型分布,我們分析了不同源域和目標(biāo)域數(shù)據(jù)集各自的query類型分布,主要關(guān)注“WH”、”Y/N“和陳述類的query占整個(gè)query集合的比例,我們同時(shí)計(jì)算了每個(gè)query類型分布的信息熵來體現(xiàn)平衡性,如圖2所示。
首先,我們發(fā)現(xiàn)模型在query類型分布更均衡的源域數(shù)據(jù)集上訓(xùn)練模型可能有助于更穩(wěn)定的整體zero-shot泛化性能。如圖2所示,MSMARCO數(shù)據(jù)集包含最全面和多樣化的query類型,這使得在該數(shù)據(jù)集訓(xùn)練的模型具有最好的zero-shot能力。雖然NQ數(shù)據(jù)集多樣性也較高,但是該數(shù)據(jù)集上占比最高query類型的是”Who“類型,我們猜測(cè)由于這種問題類型在其他大多數(shù)數(shù)據(jù)集中出現(xiàn)頻率較低,過度學(xué)習(xí)該類型的問題可能不利于模型的zero-shot泛化能力。
另外,當(dāng)源域和目標(biāo)域query集合的query類型分布一致性較高時(shí),模型在該目標(biāo)域上的zero-shot泛化性能也較好。比如在SearchQA上訓(xùn)練的模型在ArguAna和SciFact數(shù)據(jù)集上都有不錯(cuò)的表現(xiàn),而這幾個(gè)數(shù)據(jù)集中的query絕大多數(shù)都為陳述類問題。
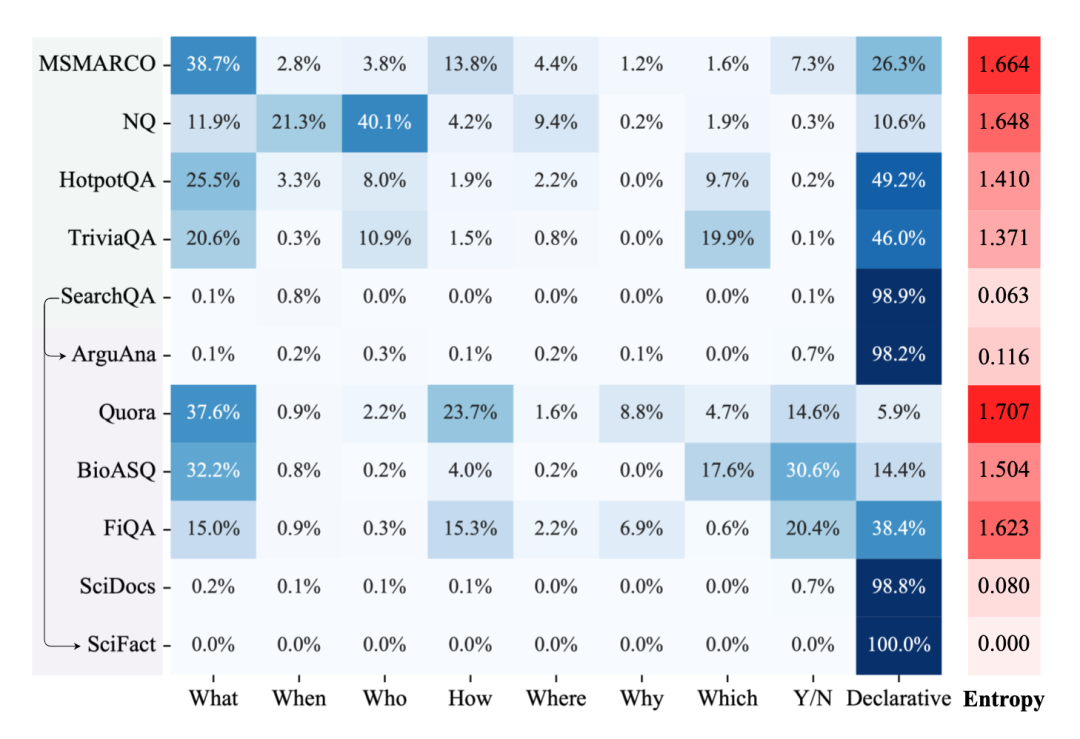
圖2 各數(shù)據(jù)集的query類型分布及信息熵
2. 源領(lǐng)域document集合的影響
與針對(duì)query集合的分析類似,我們?cè)诓煌瑢?shí)驗(yàn)設(shè)置下固定NQ的query集合作為源域query集合,并分別使用Wikipedia和MSMARCO作為源域document集合,另外我們還合并了這兩個(gè)集合組成一個(gè)新的document集合,用于研究在原document集合中引入額外document的影響。
測(cè)試結(jié)果如表3(C部分)所示,我們發(fā)現(xiàn)引入了額外document后,訓(xùn)練出來的模型在目標(biāo)域上的zero-shot性能有所下降。一個(gè)可能的原因是query集合的短答案標(biāo)注是基于原始的document集合,而這種數(shù)據(jù)標(biāo)注方式并不能很好地適應(yīng)其他document集合,從而導(dǎo)致性能下降。但從整體上來看,document集合的影響不如query集合的影響顯著。
3. 數(shù)據(jù)規(guī)模的影響
由于稠密檢索比較依賴于大規(guī)模訓(xùn)練數(shù)據(jù),因此數(shù)據(jù)規(guī)模的影響也值得關(guān)注。
Query規(guī)模
Query的規(guī)模指源域數(shù)據(jù)集上訓(xùn)練集query的數(shù)量。我們使用不同數(shù)據(jù)規(guī)模的NQ和MSMARCO數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),每個(gè)數(shù)據(jù)集的訓(xùn)練集中隨機(jī)采樣10%、50%和100%的query子集,構(gòu)造三組訓(xùn)練集,分別訓(xùn)練模型并進(jìn)行域內(nèi)和域外的測(cè)試。
表4展示了模型在NQ和MSMARCO上的域內(nèi)測(cè)試效果,表3(D1部分)展示了模型在六個(gè)目標(biāo)域上的zero-shot性能。首先可以發(fā)現(xiàn),隨著query規(guī)模的提高,模型在域內(nèi)和域外的性能都有提高,在數(shù)據(jù)規(guī)模較小時(shí),模型性能對(duì)于query規(guī)模的變動(dòng)可能更敏感。另外,“NQ 100%”和“MSMARCO 10%”數(shù)據(jù)量基本一致,但是MSMARCO訓(xùn)練的模型仍然具有較好的zero-shot性能,說明了MSMARCO數(shù)據(jù)集上更好的zero-shot泛化能力并不完全來自于更大的query規(guī)模。
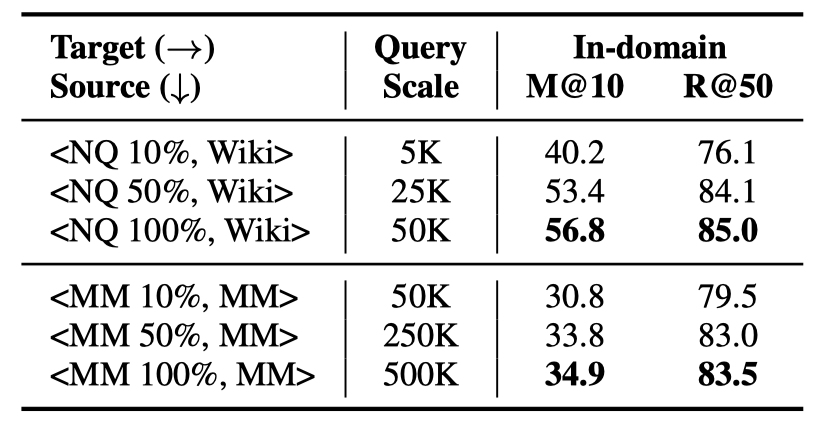
表4 不同規(guī)模query集合訓(xùn)練的模型在NQ和MSMARCO上的領(lǐng)域內(nèi)測(cè)試結(jié)果
Document規(guī)模
我們使用MSMARCOv2 passage版本的數(shù)據(jù)集進(jìn)行document規(guī)模的分析,它擁有140M左右段落,據(jù)我們所知,這是目前最大的公開document集合。
我們隨機(jī)從MSMARCOv2的document集合中采樣了1%、10%和100%三個(gè)子集,各包含1.4M、14M和140M的document,結(jié)合MSMARCOv2的query集合,構(gòu)造了三組訓(xùn)練數(shù)據(jù)來訓(xùn)練模型。
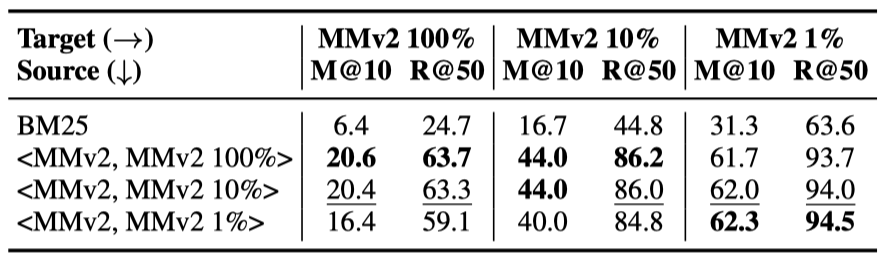
表5 MSMARCOv2上的不同document規(guī)模實(shí)驗(yàn)
首先我們使用采樣的三組不同規(guī)模的document集合,在MSMARCOv2 dev集合上對(duì)三個(gè)模型進(jìn)行了測(cè)試。如表5所示,在更大規(guī)模的域內(nèi)document集合上訓(xùn)練的模型在域內(nèi)看起來有更好的性能。
之后,我們依然在目標(biāo)領(lǐng)域上對(duì)上述三個(gè)模型進(jìn)行了zero-shot性能測(cè)試。我們意外地發(fā)現(xiàn)使用1% document規(guī)模訓(xùn)練的模型獲得了最好的zero-shot效果。我們猜測(cè)在更大規(guī)模的document集合上采樣的負(fù)樣本可能帶來更豐富的本領(lǐng)域特征,導(dǎo)致對(duì)本領(lǐng)域的過度擬合,這可能會(huì)損害模型在其他領(lǐng)域上的泛化能力。
進(jìn)一步地,我們查看了MSMARCOv2上三個(gè)document集合、以及MSMARCO上document集合的主題重合情況,使用與前文類似的方法計(jì)算不同document集合間的詞項(xiàng)重疊率。我們發(fā)現(xiàn)雖然MSMARCOv2有大規(guī)模的document集合,但相比于MSMARCO和MSMARCOv2的兩個(gè)子集,并沒有帶來與數(shù)據(jù)量成正比的更豐富的主題,可能這也是模型在這種大規(guī)模document庫(kù)上效果不佳的原因之一,即對(duì)源域上的document集合產(chǎn)生了過擬合。
4. 目標(biāo)集合的有偏情況
BEIR[2]指出了稀疏檢索模型通常被用于數(shù)據(jù)集構(gòu)造,這可能導(dǎo)致BM25在這種數(shù)據(jù)集上的評(píng)測(cè)結(jié)果偏高。因此,我們定量地研究了這種有偏情況是如何影響稀疏檢索和稠密檢索模型的zero-shot泛化性能的。
我們計(jì)算了不同目標(biāo)域測(cè)試集上query和正例document間的詞項(xiàng)重疊率,并研究這種詞項(xiàng)匹配程度如何影響不同檢索模型的zero-shot泛化性能。這里的詞項(xiàng)重疊率計(jì)算方式為每對(duì)query-document中出現(xiàn)詞項(xiàng)重疊的個(gè)數(shù)除以query長(zhǎng)度(去掉停用詞后),并在整個(gè)測(cè)試集上求平均。
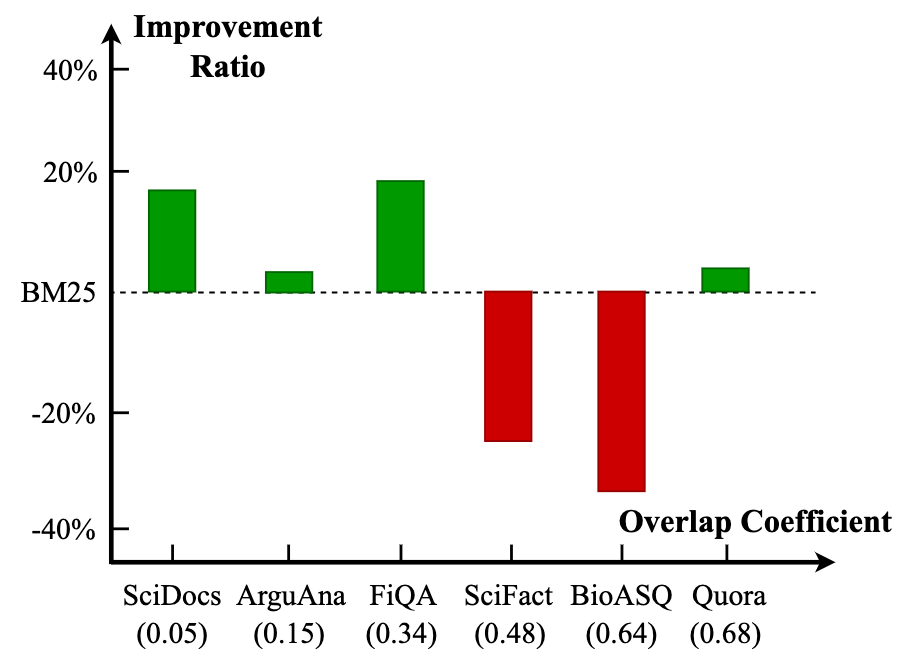
圖3 稠密檢索模型相比于BM25的效果提升比例和query與標(biāo)注document的overlap coefficient間的關(guān)系
我們計(jì)算了六個(gè)目標(biāo)域測(cè)試集上query和正例document的詞項(xiàng)重疊率,并據(jù)其對(duì)數(shù)據(jù)集做排序。圖3展示了其與稀疏、稠密檢索模型的性能差異的關(guān)系。
我們發(fā)現(xiàn)整體上,BM25在有更大詞項(xiàng)重疊率的目標(biāo)域測(cè)試集上表現(xiàn)更好,這也與預(yù)期相符,而稠密檢索模型在詞項(xiàng)重疊率更小的時(shí)候有更好的表現(xiàn),這說明現(xiàn)有的數(shù)據(jù)集中確實(shí)存在一定程度的模型偏好,從而導(dǎo)致BM25相比于稠密檢索模型有著更好的zero-shot泛化性能,這種有偏情況體現(xiàn)在query和標(biāo)注的document之間的詞項(xiàng)重疊率中。
模型分析
現(xiàn)有方案歸納
表6總結(jié)了現(xiàn)有的zero-shot稠密檢索相關(guān)的方法。隨后,我們分類討論了目前的主要技術(shù)以及代表性方法。
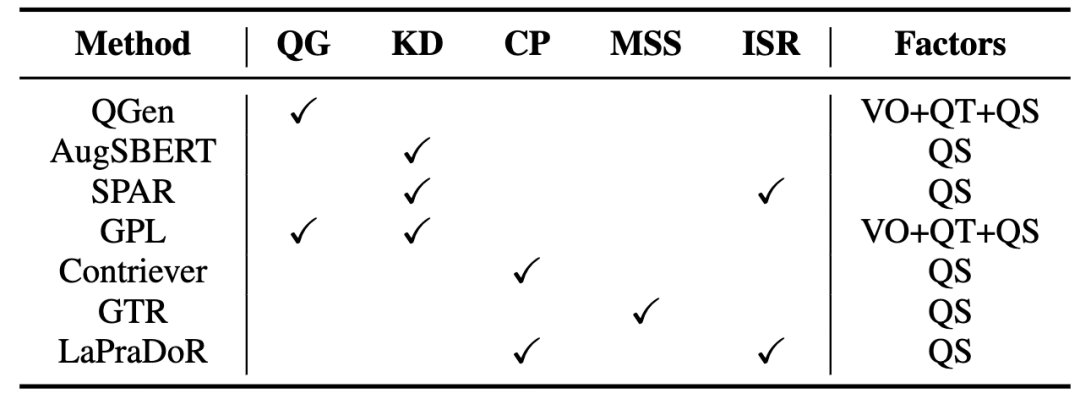
表6 Zero-shot稠密檢索方法及其采用的技術(shù)和涉及到的影響因素。其中VO、QT和QS分別代表vocabulary overlap,query type和query scale
Query生成(QG)
Query生成方法通常使用現(xiàn)成的query生成模型為目標(biāo)域的document生成偽query,從而實(shí)現(xiàn)目標(biāo)域的數(shù)據(jù)增廣。這種方法可以提高源域和目標(biāo)域的詞匯重疊率,同時(shí)也提高了訓(xùn)練數(shù)據(jù)規(guī)模(query規(guī)模)。比如QGen[3]在源域訓(xùn)練了一個(gè)生成模型,為目標(biāo)域的document生成偽query;GPL[4]使用一個(gè)經(jīng)過預(yù)訓(xùn)練的T5模型生成偽query然后使用MarginMSE loss來實(shí)現(xiàn)更穩(wěn)定的模型訓(xùn)練。
知識(shí)蒸餾(KD)
知識(shí)蒸餾是稠密檢索中一個(gè)常用的方法,其利用一個(gè)性能更強(qiáng)大的教師模型來提升稠密檢索模型的性能。當(dāng)前研究表明,這種方式也有助于提高模型的域外檢索性能。基于知識(shí)蒸餾的方法緩解了數(shù)據(jù)匱乏的問題,其相當(dāng)于增加訓(xùn)練數(shù)據(jù)規(guī)模(query規(guī)模)。比如AugSBERT[5]和GPL使用一個(gè)交互式模型來標(biāo)注無(wú)標(biāo)簽的query-document對(duì)訓(xùn)練稠密檢索模型;SPAR[6]提出通過使用BM25召回的段落讓稠密檢索模型蒸餾BM25的知識(shí)。
對(duì)比學(xué)習(xí)預(yù)訓(xùn)練(CP)
隨著無(wú)監(jiān)督對(duì)比學(xué)習(xí)在NLP領(lǐng)域的興起,研究者開始應(yīng)用該方法到zero-shot稠密檢索中。其基本思路為利用無(wú)標(biāo)簽語(yǔ)料庫(kù)構(gòu)造大規(guī)模偽標(biāo)簽訓(xùn)練數(shù)據(jù),讓模型可以在預(yù)訓(xùn)練階段就學(xué)會(huì)捕獲兩個(gè)文本間的匹配關(guān)系,其本質(zhì)上仍然是增大訓(xùn)練數(shù)據(jù)規(guī)模。Contriever[7]和LaPraDoR[8]是兩個(gè)典型的無(wú)監(jiān)督預(yù)訓(xùn)練方法,它們通過dropout等方法構(gòu)造了大規(guī)模的偽標(biāo)簽預(yù)訓(xùn)練數(shù)據(jù)進(jìn)行對(duì)比學(xué)習(xí)預(yù)訓(xùn)練。
擴(kuò)大模型規(guī)模(MSS)
增大預(yù)訓(xùn)練語(yǔ)言模型的規(guī)模帶來性能提升已經(jīng)成為了一個(gè)廣泛的共識(shí)。近期,這種方法也已經(jīng)在zero-shot稠密檢索領(lǐng)域得到了證明。GTR[9]是一個(gè)基于50億參數(shù)的T5模型的稠密檢索模型,其使用了20億query-document對(duì)進(jìn)行預(yù)訓(xùn)練,證明了增大模型和數(shù)據(jù)的規(guī)模可以持續(xù)帶來性能提升。
結(jié)合稀疏檢索(ISR)
很多工作已經(jīng)指出稀疏檢索在zero-shot場(chǎng)景下的強(qiáng)大能力,稀疏檢索和稠密檢索模型在處理不同數(shù)據(jù)時(shí)各有優(yōu)劣。因此,對(duì)這兩種模型做一個(gè)有效的結(jié)合是很重要的性能提升手段,我們認(rèn)為該方法更多地是實(shí)現(xiàn)了稠密檢索和稀疏檢索模型的集成。比如SPAR通過知識(shí)蒸餾的方式把稀疏檢索模型的能力融入稠密檢索模型中;LaPraDoR把稀疏檢索模型和稠密檢索模型的相似度打分進(jìn)行了乘性結(jié)合,提升了模型的zero-shot泛化能力。
方法比較
我們本著盡量進(jìn)行公平對(duì)比的原則,對(duì)現(xiàn)有的zero-shot稠密檢索方法性能進(jìn)行了整理,提取或復(fù)現(xiàn)了部分方法在三個(gè)目標(biāo)數(shù)據(jù)集上的效果,展示在表7中。
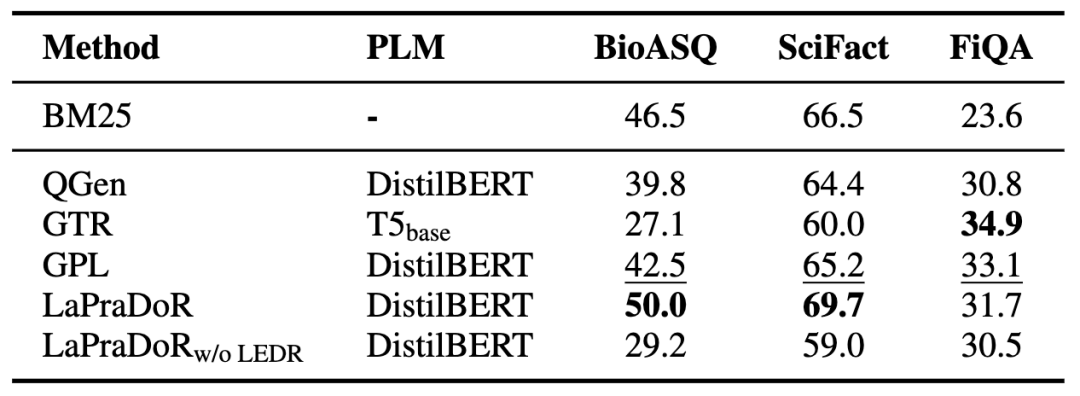
表7 不同方法在三個(gè)目標(biāo)領(lǐng)域數(shù)據(jù)集上的NDCG@10結(jié)果
首先我們發(fā)現(xiàn)LaPraDoR整體表現(xiàn)最好,而去掉ISR策略后,模型性能在BioASQ和SciFact上有較大下滑,說明引入稀疏檢索模型在有偏情況較嚴(yán)重的數(shù)據(jù)集上更有效。GPL也獲得了較好的效果,它涉及到前文分析中的提升詞匯重疊程度、提高query規(guī)模和擬合query類型分布三個(gè)因素。我們也發(fā)現(xiàn),除了結(jié)合稀疏檢索類方法,現(xiàn)有方法的zero-shot性能在BioASQ和SciFact數(shù)據(jù)集上仍然整體落后于BM25。我們猜測(cè)其原因很大程度上是前文分析提到的這兩個(gè)數(shù)據(jù)集比較依賴于詞項(xiàng)匹配,導(dǎo)致稠密檢索方法相比于稀疏檢索方法具有天然的劣勢(shì)。
總結(jié)和展望
本文深入地研究了稠密檢索模型在zero-shot場(chǎng)景下的泛化能力,廣泛地分析了不同因素對(duì)模型zero-shot泛化能力的影響。具體來講,我們發(fā)現(xiàn)詞匯重疊、query類型分布以及數(shù)據(jù)規(guī)模是影響該能力的重要因素。另外,數(shù)據(jù)集的構(gòu)造方式可能會(huì)影響對(duì)稀疏檢索模型和稠密檢索模型的zero-shot泛化能力的對(duì)比。我們認(rèn)為,稠密檢索模型的zero-shot泛化能力仍有提升空間,并且值得進(jìn)一步地深入研究。
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3255瀏覽量
48903 -
檢索
+關(guān)注
關(guān)注
0文章
27瀏覽量
13170 -
自然語(yǔ)言處理
+關(guān)注
關(guān)注
1文章
619瀏覽量
13579
原文標(biāo)題:總結(jié)和展望
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
智譜推出深度推理模型GLM-Zero預(yù)覽版
智譜GLM-Zero深度推理模型預(yù)覽版正式上線
靈初智能發(fā)布端到端具身模型Psi R0,實(shí)現(xiàn)復(fù)雜操作與泛化能力
開源大模型在多個(gè)業(yè)務(wù)場(chǎng)景的應(yīng)用案例
AI模型部署邊緣設(shè)備的奇妙之旅:目標(biāo)檢測(cè)模型
PCM1680這個(gè)zero1/2 out是個(gè)什么應(yīng)用場(chǎng)景?不接有什么問題嗎?
【書籍評(píng)測(cè)活動(dòng)NO.52】基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化
簡(jiǎn)述中軟國(guó)際模型工場(chǎng)服務(wù)場(chǎng)景
大模型時(shí)代,程序員當(dāng)下如何應(yīng)對(duì) AI 的挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論