") 詳解GPGPU與人工智能
詳解GPGPU與人工智能
GPGPU即通用計(jì)算GPU,實(shí)際不是通用計(jì)算,而是深度學(xué)習(xí)計(jì)算或者說(shuō)AI人工智能計(jì)算,這種計(jì)算深入到最底層就是矩陣之間的乘積累加。GPGPU基本上被英偉達(dá)壟斷,英偉達(dá)之所以能壟斷這個(gè)市場(chǎng),并在無(wú)人駕駛領(lǐng)域大放異彩,主要是靠2005年開(kāi)發(fā)的CUDA。
對(duì)于GPGPU即通用計(jì)算型GPU,軟件棧是其生態(tài)系統(tǒng)得以擴(kuò)展的核心。GPGPU在軟件棧上主要有兩個(gè)特點(diǎn):一是掩蓋硬件細(xì)節(jié),高度透明,讓硬件抽象為一個(gè)軟件系統(tǒng),讓程序員感覺(jué)不到硬件;二是編程模型更友好,人人都能上手。這會(huì)產(chǎn)生一個(gè)問(wèn)題,抽象掩藏掉的硬件細(xì)節(jié)越多,編程模型對(duì)用戶越友好,那么它會(huì)越難充分發(fā)揮硬件的全部潛力。因此GPGPU的抽象是分層次的:越靠近用戶的層次越易用,同時(shí)該層次的性能或者靈活性會(huì)越差。這樣特定應(yīng)用領(lǐng)域的用戶,如果重心在開(kāi)發(fā)效率,可以選擇高層次的編程模型;而需要充分發(fā)揮GPGPU性能潛力的用戶可以選擇低層次的編程模型。這也正是我們把GPGPU的編程模型稱(chēng)為‘軟件棧’的原因。
英偉達(dá)的GPGPU帝國(guó)其核心不是其GPU架構(gòu),而是5層軟件棧打造的無(wú)可匹敵的生態(tài)系統(tǒng),想要打破英偉達(dá)的壟斷必須也打造類(lèi)似的生態(tài)系統(tǒng),這難比登天,做硬件容易,GPGPU的IP唾手可得,舍得砸錢(qián)有辦法在臺(tái)積電那里拿到最先進(jìn)的產(chǎn)能,堆核心面積可以輕松做出來(lái)比肩英偉達(dá)的高性能GPU,但是生態(tài)體系沒(méi)有15年時(shí)間是做不起來(lái)的。
英偉達(dá)的AI軟件棧自底向上至少可以分成5層:
SASS是硬件實(shí)際執(zhí)行的指令集,類(lèi)似CPU的匯編,處在最底層;
PTX是虛擬指令集,為不同代的NVIDIA GPGPU提供了一個(gè)統(tǒng)一的編程接口,處在倒數(shù)第二層;
CUDA是用戶在編寫(xiě)高性能GPGPU程序時(shí)主要的編程模型,處在倒數(shù)第三層,當(dāng)然這三層也可以理解為廣義的CUDA;
cuBLAS,cuDNN, cuFFT, CUTLASS等運(yùn)算庫(kù)勉強(qiáng)算第四層,讓用戶可以通過(guò)調(diào)用NVIDIA針對(duì)自家GPGPU高度定制的算子庫(kù),不需要花費(fèi)太多精力進(jìn)行性能調(diào)優(yōu)就可以發(fā)揮英偉達(dá)GPGPU的最強(qiáng)性能,所有主流深度學(xué)習(xí)框架(Framework)都集成了這些算子庫(kù)中的最少一個(gè)算子(cuDNN基本都有);
TensorRT、Triton和Megastron則是英偉達(dá)針對(duì)特定AI應(yīng)用場(chǎng)景深度定制,讓AI類(lèi)用戶開(kāi)箱即用的軟件平臺(tái)。
人工智能的運(yùn)算流程通常是用戶用CUDA編譯代碼,編譯出架構(gòu)的PTX指令,再由PTX指令轉(zhuǎn)化為底層的SASS指令,英偉達(dá)開(kāi)放了PTX指令接口,程序員可以使用ASM寫(xiě)PTX的內(nèi)嵌匯編,SASS沒(méi)有開(kāi)放,也不會(huì)開(kāi)放,那是英偉達(dá)的核心,SASS應(yīng)該是能和底層二進(jìn)制或十六進(jìn)制的計(jì)算機(jī)指令一一對(duì)應(yīng)的指令。
CUDA
CUDA是我們接觸最多的,CUDA已形成了事實(shí)上的壟斷,AI或者說(shuō)人工智能深度學(xué)習(xí)等高密度計(jì)算都離不開(kāi)CUDA,反過(guò)來(lái)CUDA也讓英偉達(dá)的GPGPU熱賣(mài),形成滾雪球的良性循環(huán),讓英偉達(dá)的GPGPU也形成了壟斷。要想做GPGPU硬件,就必須兼容CUDA,但這就意味著性能沒(méi)有優(yōu)化,這樣做出來(lái)的模型,在英偉達(dá)的設(shè)備上自然會(huì)運(yùn)行的比較好。
沒(méi)有CUDA之前,GPU只能按照?qǐng)D形渲染管線和API來(lái)執(zhí)行操作。CUDA(Compute Unified Device Architecture),它包含了CUDA指令集架構(gòu)(ISA)以及GPU內(nèi)部的并行計(jì)算引擎。CUDA架起了一座普通程序員與GPU硬件間的橋梁,一方面讓GPU可以從事通用計(jì)算而不僅僅是圖形渲染,且能最大限度發(fā)揮GPU多核心的物理優(yōu)勢(shì),另一方面GPU對(duì)程序員來(lái)說(shuō)完全透明,程序員可以像用CPU那樣為其開(kāi)發(fā)程序。開(kāi)發(fā)人員可以使用最常見(jiàn)的計(jì)算機(jī)語(yǔ)言即C語(yǔ)言來(lái)為CUDA架構(gòu)編寫(xiě)程序,所編寫(xiě)出的程序可以在支持CUDA的處理器得以最大化發(fā)揮其性能。CUDA3.0 開(kāi)始支持C++和FORTRAN。而這些語(yǔ)言一開(kāi)始都是為CPU而設(shè)計(jì)的。
經(jīng)常有人拿OpenCL與CUDA對(duì)比,其實(shí)CUDA和OpenCL的關(guān)系并不是沖突關(guān)系,而是包容關(guān)系。CUDA是一個(gè)并行計(jì)算的架構(gòu),包含有一個(gè)指令集架構(gòu)和相應(yīng)的硬件引擎。OpenCL是一個(gè)并行計(jì)算的應(yīng)用程序編程接口(API),CUDA高于OpenCL,它是支持OpenCL的,在NVIDIA CUDA架構(gòu)上OpenCL是除了C for CUDA外新增的一個(gè)CUDA程序開(kāi)發(fā)途徑。CUDA C語(yǔ)言與OpenCL的定位不同,或者說(shuō)是使用人群不同。CUDA C是一種高級(jí)語(yǔ)言,那些對(duì)硬件了解不多的非專(zhuān)業(yè)人士也能輕松上手;而OpenCL則是針對(duì)硬件的應(yīng)用程序開(kāi)發(fā)接口,它能給程序員更多對(duì)硬件的控制權(quán),相應(yīng)的上手及開(kāi)發(fā)會(huì)比較難一些。那些在X86 CPU平臺(tái)使用C語(yǔ)言的人員,會(huì)很容易接受基于CUDA GPU平臺(tái)的C語(yǔ)言;而習(xí)慣于使用ARM平臺(tái)的程序員,看到OpenCL會(huì)更加親切一些,在其基礎(chǔ)上開(kāi)發(fā)與圖形、視頻有關(guān)的計(jì)算程序會(huì)非常容易。基于C語(yǔ)言的CUDA被包裝成一種容易編寫(xiě)的代碼,因此即使是不熟悉芯片構(gòu)造的科研人員,也可能利用CUDA工具編寫(xiě)出實(shí)用的程序。而OpenCL雖然句法上與CUDA接近,但是它更加強(qiáng)調(diào)底層操作,因此難度較高,但正因?yàn)槿绱耍琌penCL才能跨平臺(tái)運(yùn)行。CUDA最初就是為科研人員開(kāi)發(fā)的。
OpenCL開(kāi)發(fā)的過(guò)程中,技術(shù)平臺(tái)均為NVIDIA的GPU,實(shí)際上OpenCL是基于NVIDIA GPU的平臺(tái)進(jìn)行開(kāi)發(fā)的,當(dāng)然它是可以跨平臺(tái)的。另外OpenCL的第一次演示也是運(yùn)行在NVIDIA的GPU上。從本質(zhì)上來(lái)說(shuō),OpenCL就是一個(gè)相當(dāng)于Windows平臺(tái)中DirectX那樣的技術(shù)。或者說(shuō),它是一個(gè)連接硬件和軟件的API接口。在這一點(diǎn)上,它與OpenGL類(lèi)似,不過(guò)OpenCL的涉及范圍要比OpenGL大得多,它不僅是用來(lái)作用于3D圖形。如果用一句話描述,OpenCL的作用就是通過(guò)調(diào)用處理器和GPU的計(jì)算資源,釋放硬件潛力,讓程序運(yùn)行得更快更好。順便說(shuō)一下,OpenCL是蘋(píng)果在2008年?duì)款^發(fā)起的。
CUDA雖然是英偉達(dá)獨(dú)家開(kāi)發(fā),但其源頭卻是微軟,2005年底,微軟推出DirectX 10,DirectX 10最大的革新就是統(tǒng)一渲染架構(gòu)(Unified Shader Architecture)。各類(lèi)圖形硬件和API均采用分離渲染架構(gòu),即頂點(diǎn)渲染和像素渲染各自獨(dú)立進(jìn)行,前者的任務(wù)是構(gòu)建出含三維坐標(biāo)信息的多邊形頂點(diǎn),后者則是將這些頂點(diǎn)從三維轉(zhuǎn)換為二維。這為實(shí)現(xiàn)GPU通用計(jì)算奠定了基礎(chǔ)。第一代CUDA在2006年底發(fā)布的首款DX10規(guī)范的G80架構(gòu)上實(shí)現(xiàn),到了GT 200時(shí)代,GTX 200系列顯卡實(shí)現(xiàn)了硬件級(jí)雙精度算術(shù)(GT200核心中擁有30個(gè)64位浮點(diǎn)單元)。
英偉達(dá)的顯卡架構(gòu)都有對(duì)應(yīng)的CUDA版本,比如3.x稱(chēng)為Kepler,包括3.0、3.5、3.7等,5.x稱(chēng)為Maxwell,包括5.0、5.2、5.3等,6.x是Pascal,包括6.0、6.1、6.2等。7.0是Volta,7.5是Turing。目前最常見(jiàn)的Ampere架構(gòu)卡A100是8.0,目前Ampere架構(gòu)最高到11.6版,最新的Hopper架構(gòu)應(yīng)該是12.x版。隨著英偉達(dá)在CPU領(lǐng)域的持續(xù)發(fā)力,未來(lái)CUDA可能會(huì)有比較大的變化。
CUDA架構(gòu)

圖片來(lái)源:互聯(lián)網(wǎng)
CUDA主要提供了4個(gè)重要的東西:CUDA C和對(duì)應(yīng)的COMPILER,CUDA庫(kù)、CUDA RUNTIME和CUDA DRIVER。CUDA C其實(shí)就是C的變種,它加入4大特性:
1)可以定義程序的哪部分運(yùn)行在GPU或CPU上;
2)可以定義變量位于GPU的存儲(chǔ)類(lèi)型;
3)利用KERNEL、BLOCK、GRID來(lái)定義最原始的并行計(jì)算;
4)State變量。
CUDA庫(kù)包含了很多有用的數(shù)學(xué)應(yīng)用,如cuFFT,CUDA RUNTIME其實(shí)就是個(gè)JIT編譯器,動(dòng)態(tài)地將PTX中間代碼編譯成符合實(shí)際平臺(tái)的硬件代碼,并做特定優(yōu)化。Driver便是相應(yīng)API直接與GPU打交道的接口了。
在CUDA中程序執(zhí)行區(qū)域分為兩部分,CPU和GPU——HOST和DEVICE,任務(wù)組織和發(fā)送是在CPU里完成的,但并行計(jì)算是在GPU里完成,每當(dāng)CPU遇到需要并行計(jì)算的任務(wù),則將要做的運(yùn)算組織成kernel,即數(shù)據(jù)并行處理函數(shù)(核函數(shù)),然后發(fā)給GPU去執(zhí)行,在GPU上執(zhí)行的程序,一個(gè)Kernel對(duì)應(yīng)一個(gè)Grid網(wǎng)格,網(wǎng)格是一維或多維線程塊(block),CUDA在把任務(wù)正式提交給GPU前,會(huì)對(duì)kernel做些處理,讓kernel符合GPU體系架構(gòu),把GPU想成擁有上百個(gè)核的CPU,kernel當(dāng)成一個(gè)要?jiǎng)?chuàng)建為線程的函數(shù),所以CUDA現(xiàn)在要用kernel創(chuàng)建出上百個(gè)thread,然后將這些thread送到GPU中的各個(gè)核上去運(yùn)行,為了更好利用GPU資源,提高并行度,CUDA還要將這些thread加以?xún)?yōu)化組織,將能利用共有資源的線程組織到一個(gè)thread block中,同一thread block中的thread可以共享數(shù)據(jù),每個(gè)thread block最高可擁有512個(gè)線程。擁有同樣維度同樣kernel的thread block被組織成一個(gè)grid,而CUDA處理任務(wù)的最大單元便是grid了。
人工智能、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)基礎(chǔ)
所謂人工智能實(shí)際可以等同于機(jī)器學(xué)習(xí),人是能夠提出問(wèn)題發(fā)現(xiàn)問(wèn)題的,而機(jī)器永遠(yuǎn)做不到這一點(diǎn),從這個(gè)角度講,人工智能永遠(yuǎn)都無(wú)法實(shí)現(xiàn),因?yàn)槿祟?lèi)一切科學(xué)的源頭,智能的源頭就是人類(lèi)有好奇心,能夠發(fā)現(xiàn)問(wèn)題,而機(jī)器只能解決問(wèn)題。
機(jī)器學(xué)習(xí)中最常見(jiàn)的是深度學(xué)習(xí),深度學(xué)習(xí)可以按照訓(xùn)練方式分為六大類(lèi),分別是:
監(jiān)督學(xué)習(xí)(supervised learning):已知數(shù)據(jù)和其一一對(duì)應(yīng)的標(biāo)注(標(biāo)簽),也就是說(shuō)訓(xùn)練數(shù)據(jù)集需要全部標(biāo)注。訓(xùn)練一個(gè)智能算法,將輸入數(shù)據(jù)映射到標(biāo)注的過(guò)程。監(jiān)督學(xué)習(xí)是最常見(jiàn)的深度學(xué)習(xí),也是ADAS自動(dòng)駕駛感知領(lǐng)域幾乎唯一的深度學(xué)習(xí)方式,就是人們口中常說(shuō)的分類(lèi)(Classification)問(wèn)題。
無(wú)監(jiān)督學(xué)習(xí)(unsupervised learning):已知數(shù)據(jù)沒(méi)有任何標(biāo)注,按照一定的偏好,訓(xùn)練一個(gè)智能算法,將所有的數(shù)據(jù)映射到多個(gè)不同標(biāo)簽的過(guò)程。
強(qiáng)化學(xué)習(xí)(reinforcement learning):智能算法在沒(méi)有人為指導(dǎo)的情況下,通過(guò)不斷的試錯(cuò)來(lái)提升任務(wù)性能的過(guò)程。“試錯(cuò)”的意思是還是有一個(gè)衡量標(biāo)準(zhǔn),用棋類(lèi)游戲舉例,我們并不知道棋手下一步棋是對(duì)是錯(cuò),不知道哪步棋是制勝的關(guān)鍵,但是我們知道結(jié)果是輸還是贏,如果算法這樣走最后的結(jié)果是勝利,那么算法就學(xué)習(xí)記憶,如果按照那樣走最后輸了,那么算法就學(xué)習(xí)以后不這樣走。
弱監(jiān)督學(xué)習(xí)(weakly supervised learning):已知數(shù)據(jù)和其一一對(duì)應(yīng)的弱標(biāo)簽,訓(xùn)練一個(gè)智能算法,將輸入數(shù)據(jù)映射到一組更強(qiáng)的標(biāo)簽的過(guò)程。標(biāo)簽的強(qiáng)弱指的是標(biāo)簽蘊(yùn)含的信息量的多少,比如相對(duì)于分割的標(biāo)簽來(lái)說(shuō),分類(lèi)的標(biāo)簽就是弱標(biāo)簽。
半監(jiān)督學(xué)習(xí)(semi supervised learning) :已知數(shù)據(jù)和部分?jǐn)?shù)據(jù)一一對(duì)應(yīng)的標(biāo)簽,有一部分?jǐn)?shù)據(jù)的標(biāo)簽未知,訓(xùn)練一個(gè)智能算法,學(xué)習(xí)已知標(biāo)簽和未知標(biāo)簽的數(shù)據(jù),將輸入數(shù)據(jù)映射到標(biāo)簽的過(guò)程。半監(jiān)督通常是一個(gè)數(shù)據(jù)的標(biāo)注非常困難,比如說(shuō)醫(yī)院的檢查結(jié)果,醫(yī)生也需要一段時(shí)間來(lái)判斷健康與否,可能只有幾組數(shù)據(jù)知道是健康還是非健康。
多示例學(xué)習(xí)(multiple instance learning) :已知包含多個(gè)數(shù)據(jù)的數(shù)據(jù)包和數(shù)據(jù)包的標(biāo)簽,訓(xùn)練智能算法,將數(shù)據(jù)包映射到標(biāo)簽的過(guò)程,在有的問(wèn)題中也同時(shí)給出包內(nèi)每個(gè)數(shù)據(jù)的標(biāo)簽。多事例學(xué)習(xí)引入了數(shù)據(jù)包的概念。
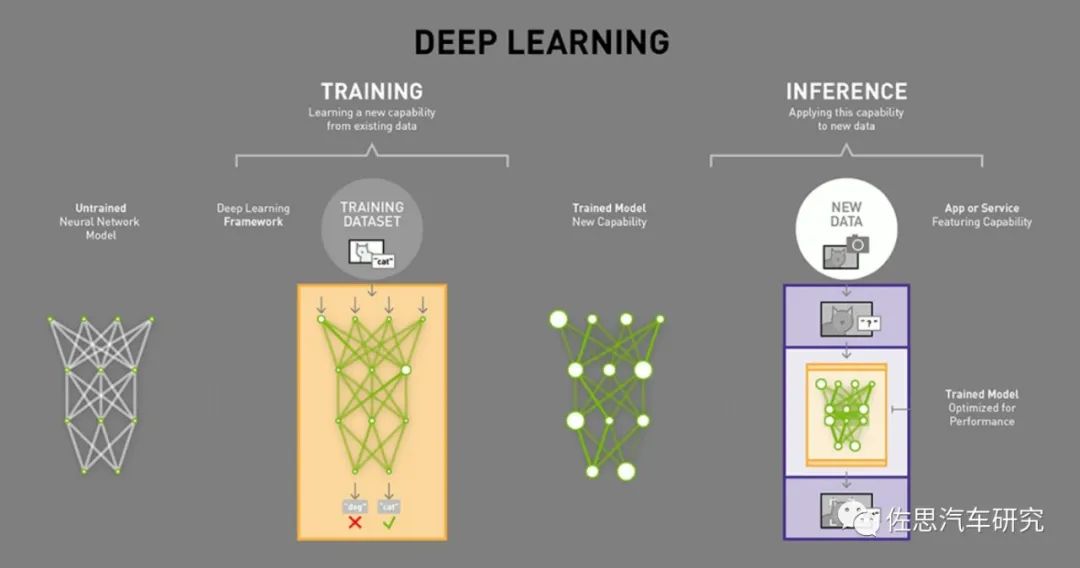
圖片來(lái)源:互聯(lián)網(wǎng)
深度學(xué)習(xí)分為訓(xùn)練和推理兩部分,訓(xùn)練就好比我們?cè)趯W(xué)校的學(xué)習(xí),但神經(jīng)網(wǎng)絡(luò)的訓(xùn)練和我們?nèi)祟?lèi)接受教育的過(guò)程之間存在相當(dāng)大的不同。神經(jīng)網(wǎng)絡(luò)對(duì)我們?nèi)四X的生物學(xué)——神經(jīng)元之間的所有互連——只有一點(diǎn)點(diǎn)拙劣的模仿。我們的大腦中的神經(jīng)元可以連接到特定物理距離內(nèi)任何其它神經(jīng)元,而深度學(xué)習(xí)卻不是這樣——它分為很多不同的層(layer)、連接(connection)和數(shù)據(jù)傳播(data propagation)的方向,因?yàn)槎鄬樱钟斜姸噙B接,所以稱(chēng)其為神經(jīng)網(wǎng)絡(luò)。
訓(xùn)練神經(jīng)網(wǎng)絡(luò)的時(shí)候,訓(xùn)練數(shù)據(jù)被輸入到網(wǎng)絡(luò)的第一層。然后所有的神經(jīng)元,都會(huì)根據(jù)任務(wù)執(zhí)行的情況,根據(jù)其正確或者錯(cuò)誤的程度如何,分配一個(gè)權(quán)重參數(shù)(權(quán)重值)。在一個(gè)用于圖像識(shí)別的網(wǎng)絡(luò)中,第一層可能是用來(lái)尋找圖像的邊。第二層可能是尋找這些邊所構(gòu)成的形狀——矩形或圓形。第三層可能是尋找特定的特征——比如閃亮的眼睛或按鈕式的鼻子。每一層都會(huì)將圖像傳遞給下一層,直到最后一層;最后的輸出由該網(wǎng)絡(luò)所產(chǎn)生的所有這些權(quán)重總體決定。
經(jīng)過(guò)初步(是初步,這個(gè)是隱藏的)訓(xùn)練后得到全部權(quán)重模型后,我們就開(kāi)始考試它,比如注入神經(jīng)網(wǎng)絡(luò)幾萬(wàn)張含有貓的圖片(每張圖片都需要在貓的地方標(biāo)注貓,這個(gè)過(guò)程一般是手工標(biāo)注,也有自動(dòng)標(biāo)注,但準(zhǔn)確度肯定不如手工),然后拿一張圖片讓神經(jīng)網(wǎng)絡(luò)識(shí)別圖片里的是不是貓。如果答對(duì)了,這個(gè)正確會(huì)反向傳播到該權(quán)重層,給予獎(jiǎng)勵(lì)就是保留,如果答錯(cuò)了,這個(gè)錯(cuò)誤會(huì)回傳到網(wǎng)絡(luò)各層,讓網(wǎng)絡(luò)再猜一下,給出一個(gè)不同的論斷,這個(gè)錯(cuò)誤會(huì)反向地傳播通過(guò)該網(wǎng)絡(luò)的層,該網(wǎng)絡(luò)也必須做出其它猜測(cè),網(wǎng)絡(luò)并不知道自己錯(cuò)在哪里,也無(wú)需知道。在每一次嘗試中,它都必須考慮其它屬性——在我們的例子中是「貓」的屬性——并為每一層所檢查的屬性賦予更高或更低的權(quán)重。然后它再次做出猜測(cè),一次又一次,無(wú)數(shù)次嘗試……直到其得到正確的權(quán)重配置,從而在幾乎所有的考試中都能得到正確的答案。
得到正確的權(quán)重配置,這是一個(gè)巨大的數(shù)據(jù)庫(kù),顯然無(wú)法實(shí)際應(yīng)用,特別是嵌入式應(yīng)用,于是我們要對(duì)其修剪,讓其瘦身。首先去掉神經(jīng)網(wǎng)絡(luò)中訓(xùn)練之后就不再激活的部分。這些部分已不再被需要,可以被「修剪」掉。其次是壓縮,這和我們常用的圖像和視頻壓縮類(lèi)似,保留最重要的部分,如今模擬視頻幾乎不存在,都是壓縮視頻的天下,但我們并未感覺(jué)到壓縮視頻與原始視頻有區(qū)別。壓縮的理論基礎(chǔ)是信息論(它與算法信息論密切相關(guān))以及率失真理論,這個(gè)領(lǐng)域的研究工作主要是由上世紀(jì)40年代的 Claude Shannon 奠定的,實(shí)際機(jī)器學(xué)習(xí)所有的理論基礎(chǔ)在上世紀(jì)50年代就已經(jīng)全部具備,絕大部分理論基礎(chǔ)也來(lái)自Claude Shannon 的信息論,唯一差的就是算力,是英偉達(dá)的GPU造就了深度學(xué)習(xí)時(shí)代的到來(lái),目前的深度學(xué)習(xí)沒(méi)有理論上的突破,只是應(yīng)用上的擴(kuò)展。經(jīng)過(guò)壓縮后,多個(gè)神經(jīng)網(wǎng)絡(luò)層被合為一個(gè)單一的計(jì)算。最后得到的這個(gè)就是推理Inference用模型或者說(shuō)算法模型,實(shí)際我覺(jué)得叫Prediction猜測(cè)更準(zhǔn)確。
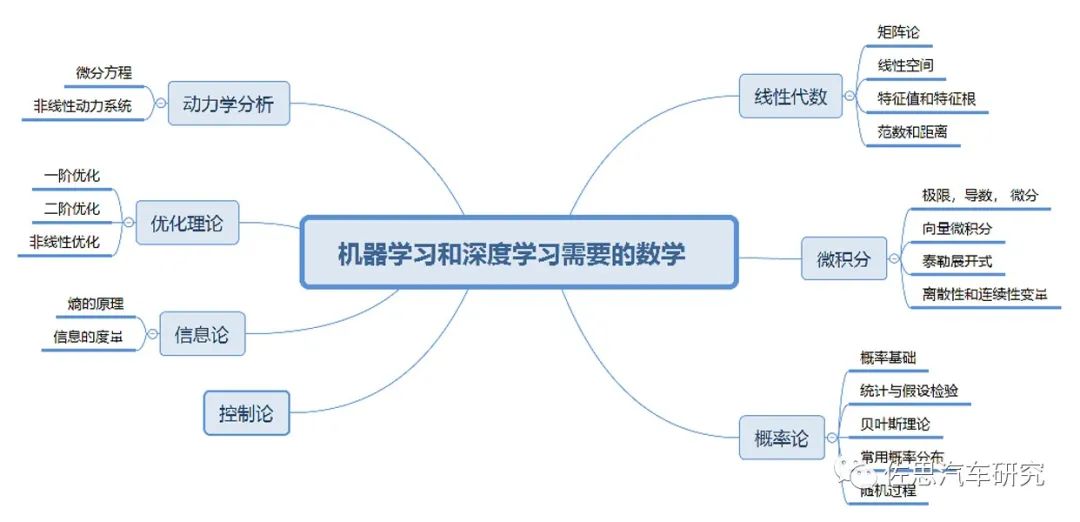
圖片來(lái)源:互聯(lián)網(wǎng)
深度學(xué)習(xí)的關(guān)鍵理論是線性代數(shù)和概率論,因?yàn)樯疃葘W(xué)習(xí)的根本思想就是把任何事物轉(zhuǎn)化成高維空間的向量,強(qiáng)大無(wú)比的神經(jīng)網(wǎng)絡(luò),說(shuō)來(lái)歸齊就是無(wú)數(shù)的矩陣運(yùn)算和簡(jiǎn)單的非線性變換的結(jié)合。在19世紀(jì)中期,矩陣?yán)碚摼鸵呀?jīng)成熟。概率論在18世紀(jì)中期就有托馬斯貝葉斯,在1900年俄羅斯的馬爾科夫發(fā)表概率演算,概率論完全成熟。優(yōu)化理論主要來(lái)自微積分,包括拉格朗日乘子法及其延伸的KKT,而拉格朗日是18世紀(jì)中葉的法國(guó)數(shù)學(xué)家。RNN則和非線性動(dòng)力學(xué)關(guān)聯(lián)甚密,其基礎(chǔ)在20世紀(jì)初已經(jīng)完備。至于GAN網(wǎng)絡(luò),則離不開(kāi)19世紀(jì)末偉大的奧地利物理學(xué)家波爾茲曼。強(qiáng)化學(xué)習(xí)的理論基礎(chǔ)是1906年俄羅斯數(shù)學(xué)家馬爾科夫發(fā)表的弱大數(shù)定律(weak law of large numbers)和中心極限定理(central limit theorem),也就是馬爾科夫鏈。
深度學(xué)習(xí)的理論基礎(chǔ)已經(jīng)不可能出現(xiàn)大的突破,因?yàn)槟壳叭祟?lèi)的數(shù)學(xué)特別是非確定性數(shù)學(xué)已經(jīng)走火入魔了。
實(shí)際深度學(xué)習(xí)就是靠蠻力計(jì)算(當(dāng)然也有1X1卷積、池化等操作降低參數(shù)量和維度)代替了精妙的科學(xué)。深度學(xué)習(xí)沒(méi)有數(shù)學(xué)算法那般有智慧,它知其然,不知其所以然,它只是概率預(yù)測(cè)(深度學(xué)習(xí)里最重要的置信度)。所以在目前的深度學(xué)習(xí)方法中,參數(shù)的調(diào)節(jié)方法依然是一門(mén)“藝術(shù)”,而非“科學(xué)”。深度學(xué)習(xí)方法深刻地轉(zhuǎn)變了人類(lèi)幾乎所有學(xué)科的研究方法。以前學(xué)者們所采用的觀察現(xiàn)象,提煉規(guī)律,數(shù)學(xué)建模,模擬解析,實(shí)驗(yàn)檢驗(yàn),修正模型的研究套路被徹底顛覆,被數(shù)據(jù)科學(xué)的方法所取代:收集數(shù)據(jù),訓(xùn)練網(wǎng)絡(luò),實(shí)驗(yàn)檢驗(yàn),加強(qiáng)訓(xùn)練。這也使得算力需求越來(lái)越高。機(jī)械定理證明驗(yàn)證了命題的真?zhèn)危菬o(wú)法明確地提出新的概念和方法,實(shí)質(zhì)上背離了數(shù)學(xué)的真正目的。這是一種“相關(guān)性”而非“因果性”的科學(xué)。歷史上,人類(lèi)積累科學(xué)知識(shí),在初期總是得到“經(jīng)驗(yàn)公式”,但是最終還是尋求更為深刻本質(zhì)的理解。例如從煉丹術(shù)到化學(xué)、量子力學(xué)的發(fā)展歷程。人類(lèi)智能獨(dú)特之處也在于數(shù)學(xué)推理,特別是機(jī)械定理證明,對(duì)于這一點(diǎn),機(jī)器學(xué)習(xí)永遠(yuǎn)無(wú)能為力的。
對(duì)于深度學(xué)習(xí)推理階段來(lái)說(shuō),分解到最底層,其運(yùn)算核心就是數(shù)據(jù)矩陣與權(quán)重模型之間的乘積累加,乘積累加運(yùn)算(英語(yǔ):Multiply Accumulate, MAC)。這種運(yùn)算的操作,是將乘法的乘積結(jié)果和累加器A的值相加,再存入累加器:
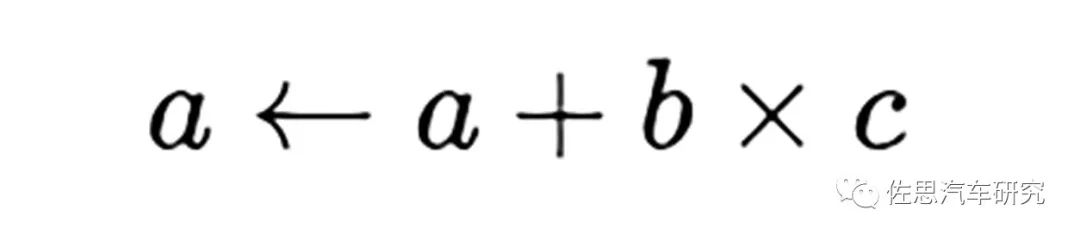
若沒(méi)有使用MAC指令,上述的程序需要二個(gè)指令,但MAC指令可以使用一個(gè)指令完成。而許多運(yùn)算(例如卷積運(yùn)算、點(diǎn)積運(yùn)算、矩陣運(yùn)算、數(shù)字濾波器運(yùn)算、乃至多項(xiàng)式的求值運(yùn)算,基本上全部的深度學(xué)習(xí)類(lèi)型都可以對(duì)應(yīng))都可以分解為數(shù)個(gè)MAC指令,因此可以提高上述運(yùn)算的效率。推理階段要求精度不高,一般是整數(shù)8位,即INT8。
對(duì)于訓(xùn)練階段,要求比較高,常見(jiàn)的是FP64和FP32兩種精度,近來(lái)又出現(xiàn)Bfloat16,Bfloat16就是截?cái)喔↑c(diǎn)數(shù)(truncated 16-bit floating point),它是由一個(gè)float32截?cái)嗲?6位而成。它和IEEE定義的float16不同,主要用于取代float32來(lái)加速訓(xùn)練網(wǎng)絡(luò),同時(shí)降低梯度消失(vanishing gradient)的風(fēng)險(xiǎn),也可以防止出現(xiàn)NaN這樣的異常值。深層神經(jīng)網(wǎng)絡(luò)每次梯度相乘的系數(shù)如果小于1,那就是浮點(diǎn)數(shù),如果層數(shù)越來(lái)越多,那這個(gè)系數(shù)會(huì)越來(lái)越大,傳播到最底層可以學(xué)習(xí)到的參數(shù)就很小了,所以需要截?cái)鄟?lái)防止(或降低)梯度消失。在float32和bfloat16之間進(jìn)行轉(zhuǎn)換時(shí)非常容易,事實(shí)上 Tensorflow也只提供了bfloat16和float32之間的轉(zhuǎn)換,不過(guò)畢竟還是需要轉(zhuǎn)換的。
英特爾的內(nèi)嵌匯編格式GNU Gas添加了BFloat16支持,英特爾在2019年4月發(fā)布補(bǔ)丁,支持GNU編譯器集合(GCC)中的BFloat16支持。和IEEE float16相比,動(dòng)態(tài)范圍更大(和float32一樣大),但是尾數(shù)位更少(精度更低)。更大的動(dòng)態(tài)范圍意味著不容易下溢(上溢在實(shí)踐中幾乎不會(huì)發(fā)生,這里不考慮)。另一個(gè)優(yōu)勢(shì)是Bfloat16既可以用于訓(xùn)練又可以用于推斷。Amazon也證明Deep Speech模型使用BFloat16的訓(xùn)練和推斷的效果都足夠好。Uint8在大部分情況下不能用于訓(xùn)練,只能用于推斷,大多數(shù)的Uint8模型都從FP32轉(zhuǎn)換而來(lái)。所以,Bfloat16可能是未來(lái)包括移動(dòng)端的主流格式,尤其是需要語(yǔ)言相關(guān)的模型時(shí)候。當(dāng)然英偉達(dá)認(rèn)為Bfloat16犧牲了部分精度,對(duì)于某些場(chǎng)合如HPC,精度比運(yùn)算效率和成本更重要。
一個(gè)MAC單元通常包括三部分:乘法器、加法器和累加器。
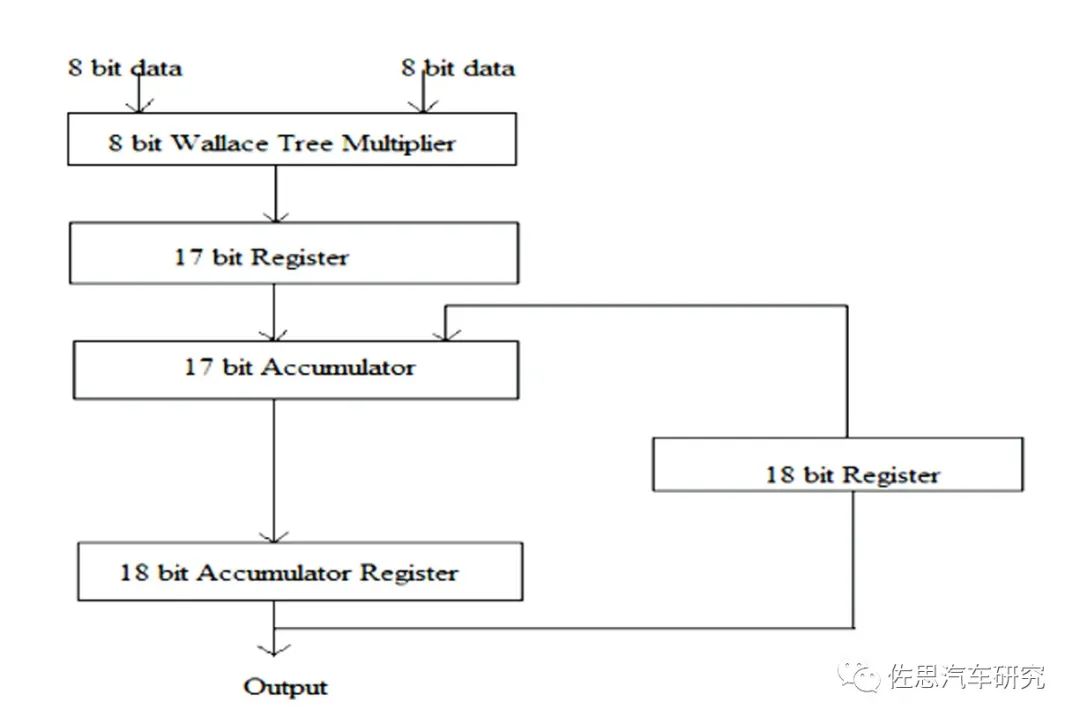
圖片來(lái)源:互聯(lián)網(wǎng)
上圖為一個(gè)典型的MAC單元。計(jì)算機(jī)體系中的乘法和加法都?xì)v經(jīng)了長(zhǎng)時(shí)間的研究改進(jìn),純粹的乘法器和加法器肯定是不會(huì)有人用。乘法器最常用的Wallace樹(shù),這是1963年C.S.Wallace提出的一種高效快速的加法樹(shù)結(jié)構(gòu),被后人稱(chēng)為Wallace樹(shù)。人工智能95%的理論工作都是在1970年前完成的,只是沒(méi)有高性能計(jì)算系統(tǒng),才沒(méi)有在那個(gè)時(shí)代鋪展開(kāi)。加法器多是CSA,即進(jìn)位保存加法器(Carry Save Adder,CSA)。使用進(jìn)位保存加法器在執(zhí)行多個(gè)數(shù)加法時(shí)具有極小的進(jìn)位傳播延遲,它的基本思想是將3個(gè)加數(shù)的和減少為2個(gè)加數(shù)的和,將進(jìn)位c和s分別計(jì)算保存,并且每比特可以獨(dú)立計(jì)算c和s,所以速度極快。這些都已經(jīng)非常成熟,剛出校門(mén)的學(xué)生都可以做到。
除了降低精度以外,還可以結(jié)合一些數(shù)據(jù)結(jié)構(gòu)轉(zhuǎn)換來(lái)減少運(yùn)算量,比如通過(guò)快速傅里葉變換(FFT)來(lái)減少矩陣運(yùn)算中的乘法;還可以通過(guò)查表的方法來(lái)簡(jiǎn)化MAC的實(shí)現(xiàn)等。
審核編輯 :李倩
-
gpu
+關(guān)注
關(guān)注
28文章
4739瀏覽量
128941 -
人工智能
+關(guān)注
關(guān)注
1791文章
47274瀏覽量
238469 -
汽車(chē)系統(tǒng)
+關(guān)注
關(guān)注
1文章
134瀏覽量
19748
原文標(biāo)題:深入了解汽車(chē)系統(tǒng)級(jí)芯片SoC連載之九:詳解GPGPU與人工智能
文章出處:【微信號(hào):zuosiqiche,微信公眾號(hào):佐思汽車(chē)研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論