


寫在前面
大家好,我是劉聰NLP。
最近在做Prompt的相關(guān)內(nèi)容,本人意識中一直覺得Prompt機制在序列標注任務(wù)上不是很好轉(zhuǎn)換,因此,很早前,組長問我時,我夸下海口,說:“誰用prompt做NER呀”。然后,調(diào)研發(fā)現(xiàn)大佬們真是各顯神通,是我目光短淺了。于是,決定進行一番總結(jié),分享給大家。「有點長,大家慢慢看,記得點贊收藏轉(zhuǎn)發(fā)」
部分論文已經(jīng)在自己的數(shù)據(jù)上進行了實驗,最后一趴會進行簡要概述,并且會分析每種方法的優(yōu)劣。
TemplateNER
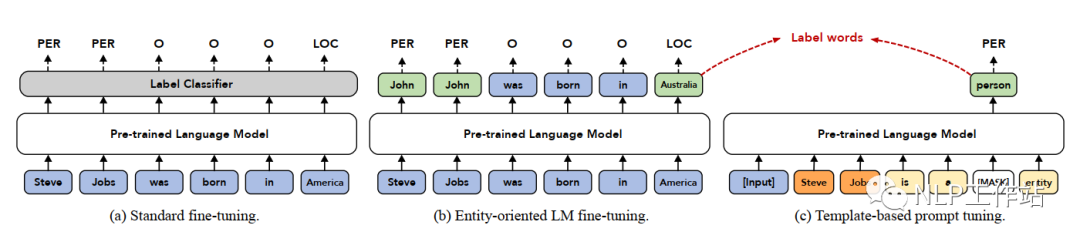
TemplateNER,原文《Template-Based Named Entity Recognition Using BART》,是第一篇將Prompt方法應(yīng)用于序列標注任務(wù)的論文,核心思想是通過N-Gram方法構(gòu)建候選實體,然后將其與所有手工模板進行拼接,使用BART模型對其打分,從而預(yù)測出最終實體類別。是一篇「手工模板且無答案空間映射」的Prompt論文。
paper:https://arxiv.org/abs/2106.01760
github:https://github.com/Nealcly/templateNER
模型,訓(xùn)練階段如下圖(c)所示,預(yù)測階段如下圖(b)所示,下面詳細介紹。
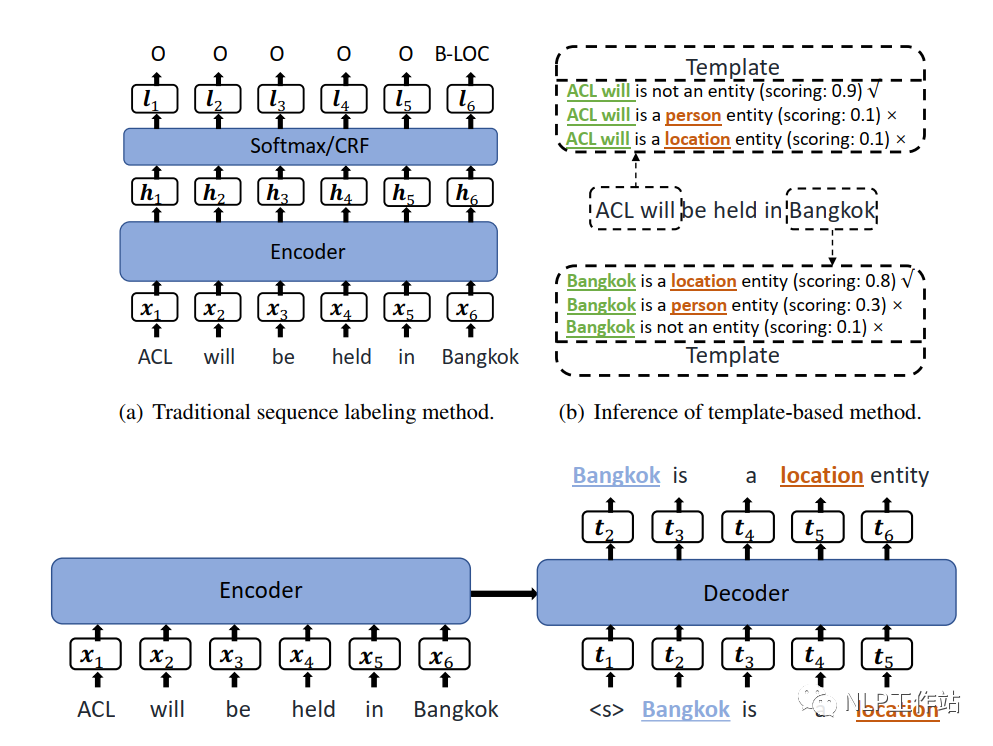
任務(wù)構(gòu)造
將序列標注任務(wù)轉(zhuǎn)換成一個生成任務(wù),在Encoder端輸入為原始文本,Decoder端輸入的是一個已填空的模板文本,輸出為已填空的模板文本。待填空的內(nèi)容為候選實體片段以及實體類別。候選實體片段由原始文本進行N-Gram滑窗構(gòu)建,為了防止候選實體片段過多,論文中最大進行8-gram。
模板構(gòu)建
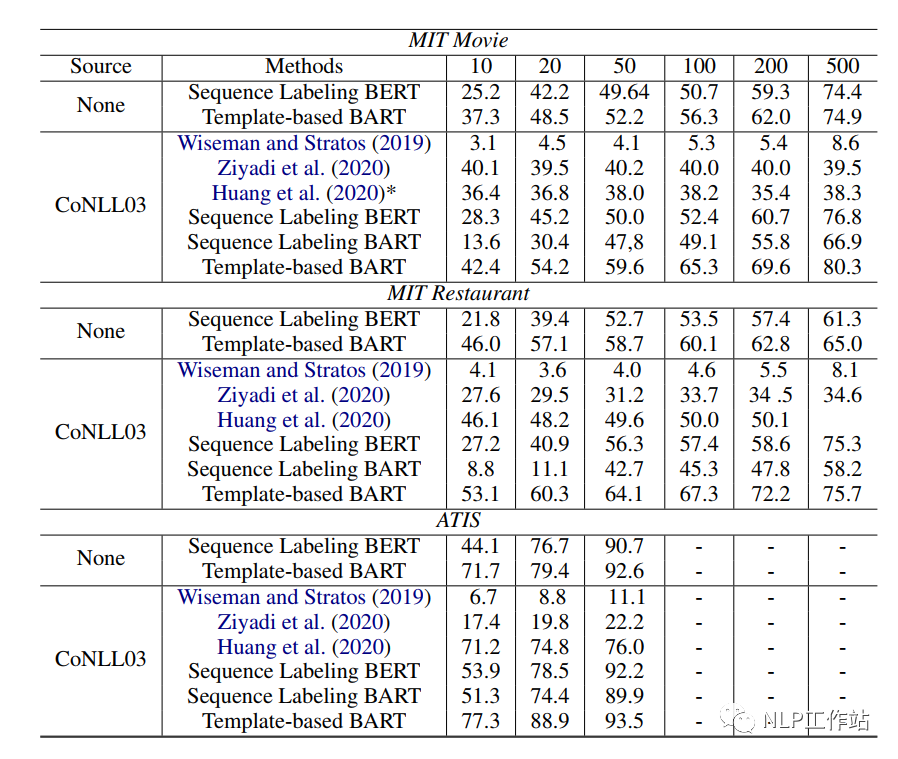
模板為手工模板,主要包括正向模板和負向模板,其中,正向模板表示一個文本片段是某種實體類型,負向文本表示一個文本片段不是實體。具體模板如下表所示,我們也可以看出,最終模型效果是與手工模板息息相關(guān)的。

訓(xùn)練階段
在訓(xùn)練階段,正樣本由實體+實體類型+正向模板構(gòu)成,負樣本由非實體片段+負向模板構(gòu)成;由于負樣本過多,因此對負樣本進行隨機負采樣,使其與正樣本的比例保持1.5:1。其學(xué)習(xí)目標為:
預(yù)測階段
在預(yù)測階段,將進行8-gram滑窗的所有候選實體片段與模板組合,然后使用訓(xùn)練好的模型進行預(yù)測,獲取每個候選實體片段與模板組合的分數(shù)(可以理解為語義通順度PPL,但是計算公式不同),分數(shù)計算如下:
其中,表示實體片段,表示第k個實體類別,T_{y_{k},x_{i:j}}表示實體片段與模板的文本。
針對,每個實體片段,選擇分數(shù)最高的模板,判斷是否為一個實體,哪種類型的實體。
DemonstrationNER
DemonstrationNER,原文《Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER》,核心思想為在原始文本的基礎(chǔ)上,拼接示例模板信息,提高原始序列標注模型的效果。是一篇「示例模板且無答案空間映射」的Prompt論文。
paper:https://arxiv.org/abs/2110.08454
github:https://github.com/INK-USC/fewNER
模型如下圖(b)所示,下面詳細介紹。
任務(wù)構(gòu)造
依然是序列標注模型,僅將原始文本后面拼接示例模板,而示例模板的作用主要是提供額外信息(什么樣的實體屬于什么類別,與原文相似文本中哪些實體屬于哪些類別等),幫助模型可以更好地識別出原始文本中的實體。
示例模板的構(gòu)建
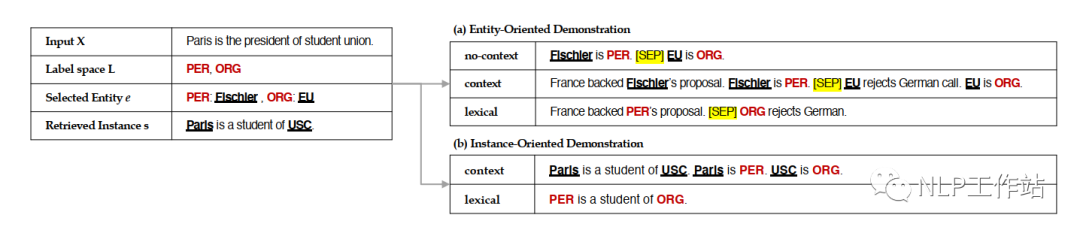
示例分為面向?qū)嶓w的示例和面向句子的示例,如下圖所示,
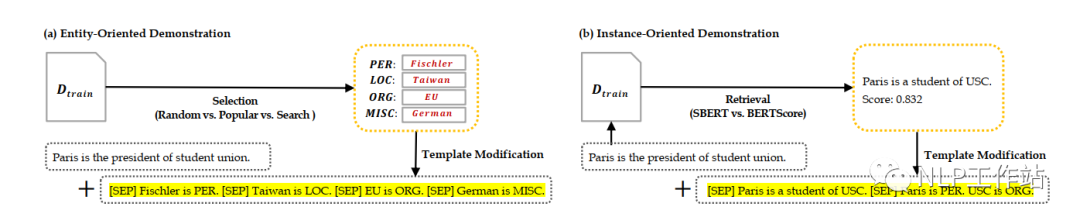
面向?qū)嶓w的示例構(gòu)造方法包括:
- 隨機法,即,隨機從訓(xùn)練集的實體列表中,抽取若干個實體,作為示例。
- 統(tǒng)計法,即,選擇在訓(xùn)練集中出現(xiàn)次數(shù)較多的實體,作為示例。
- 網(wǎng)格搜索法,即,對所有實體進行網(wǎng)格搜索,判斷采用哪些實體作為示例時,在驗證集上的效果最優(yōu)。
面向句子的示例構(gòu)造方法包括:
- SBERT法,即,使用[CLS]向量之間的余弦值作為句子相似度分數(shù),選擇與原始句子最相似的句子作為示例。
- BERTScore法,即,使用句子中每個token相似度之和作為句子相似度分數(shù),選擇與原始句子最相似的句子作為示例。
模板形式主要有三種,無上下文模板、有上下文模板和詞典模板,如下圖所示,
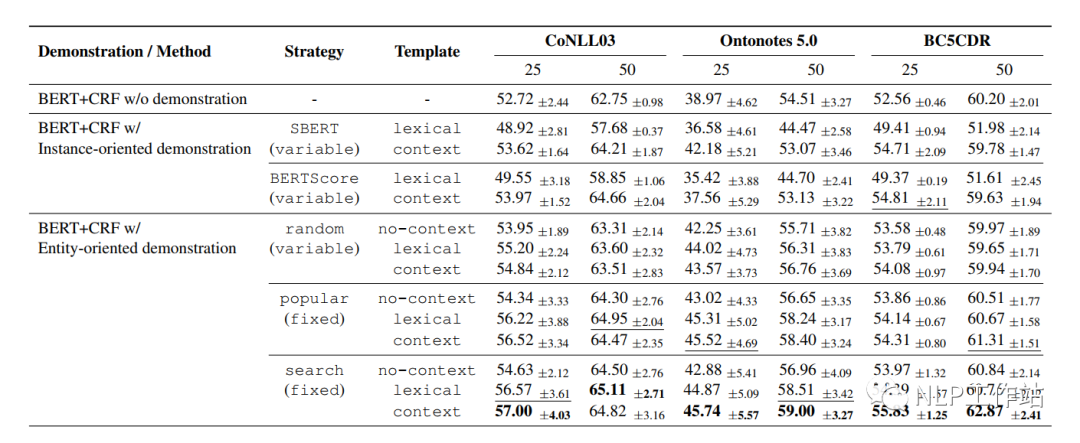
最終實驗結(jié)果為實體-網(wǎng)格搜索法-有上下文模板效果最佳。分析句子級別不好可能是由于數(shù)據(jù)空間中句子間的相似度太低導(dǎo)致。
訓(xùn)練&預(yù)測
將示例模板拼接到原始模板后面,一起進入模型,僅針對原始文本進行標簽預(yù)測與損失計算,如下:
其中,表示原始文本,表示示例模板,表示原始文本經(jīng)過模型后的序列向量,表示示例模板經(jīng)過模型后的序列向量。損失如下:
僅考慮原始文本部分。將需要領(lǐng)域遷移時,將原有模型的參數(shù)賦予新模型,進訓(xùn)練標簽映射部分參數(shù)(linear或crf)即可。
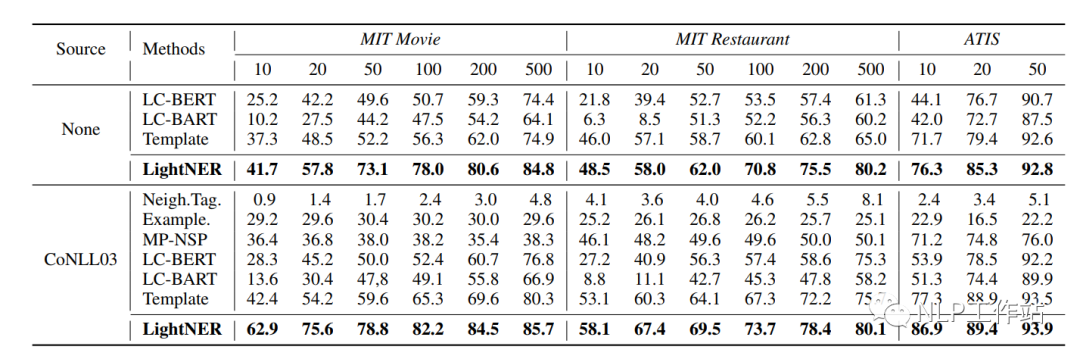
LightNER
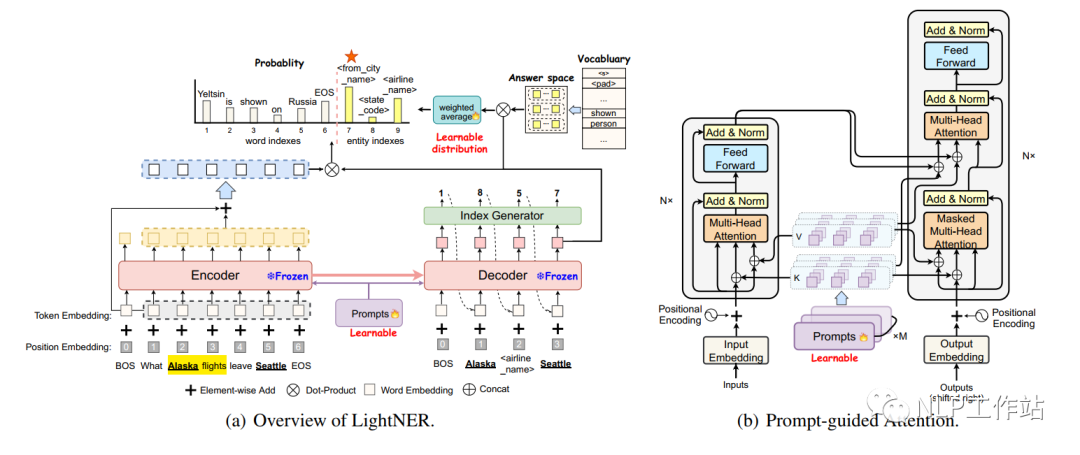
LightNER,原文《LightNER: A Lightweight Generative Framework with Prompt-guided Attention for Low-resource NER》,核心思想為將原始序列標注任務(wù)轉(zhuǎn)化為Seq2Seq的生成任務(wù),通過在transformer的attetion機制中融入提示信息,在少量參數(shù)訓(xùn)練下,使模型達到較好的效果。是一篇「軟模版且有答案空間映射」的Prompt論文。
paper:https://arxiv.org/abs/2109.00720
github:https://github.com/zjunlp/DeepKE/blob/main/example/ner/few-shot/README_CN.md
模型如下圖所示,下面詳細介紹。
任務(wù)構(gòu)造
將序列標注任務(wù)轉(zhuǎn)換成一個生成任務(wù),在Encoder端輸入為原始文本,Decoder端逐字生成實體以及實體類型。模板信息融到Encoder和Decoder模型attention機制中,模板為soft-prompt,即一種可學(xué)習(xí)的自動模板。
基于提示引導(dǎo)的Attention
如上圖(b)所示,分別在Encoder和Decoder中加入可訓(xùn)練參數(shù),其中,為transformer的層數(shù),,為模板長度,為隱藏節(jié)點維度,表示由key和value兩項組成。
給定輸入序列,對于每一層transformer,的原始表示如下:
變化后的attention如下:
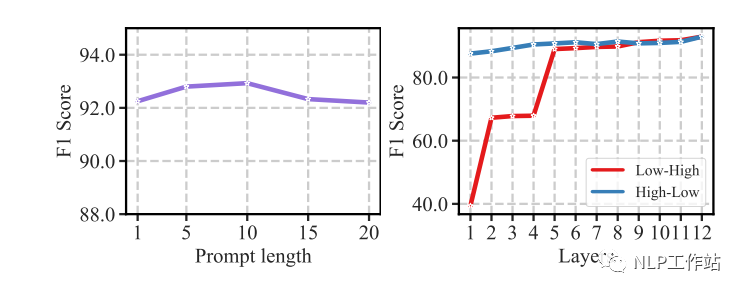
基于提示引導(dǎo)的Attention可以根據(jù)提示內(nèi)容重新調(diào)節(jié)注意機制,使其少參數(shù)調(diào)節(jié)。并且實驗發(fā)現(xiàn),模板長度和提示信息融入的層數(shù)影響最終效果,當長度為10時,效果最佳。當層數(shù)為12層時,效果最佳。
訓(xùn)練&預(yù)測
對于Encoder端,輸入文本,獲取表示;
對于Decoder端,輸出不僅為實體內(nèi)容還可能為實體類別,即,其每個輸出內(nèi)容為。
標簽預(yù)測時,
其中,通過答案空間映射得來,具體為“將標簽中幾個詞語的向量加權(quán)求和,作為標簽的答案空間向量”。
消融實驗發(fā)現(xiàn),基于提示引導(dǎo)的Attention和答案空間映射對于結(jié)果的影響均較大。
EntLM
EntLM,原文《Template-free Prompt Tuning for Few-shot NER》,核心思想為將序列標注任務(wù)變成原始預(yù)訓(xùn)練的LM任務(wù),僅通過答案空間映射,實現(xiàn)任務(wù)轉(zhuǎn)化,消除下游任務(wù)與原始LM任務(wù)的Gap,提高模型效果。是一篇「無模板且有答案空間映射」的Prompt論文。
paper:https://arxiv.org/abs/2109.13532
github:https://github.com/rtmaww/EntLM/
模型如下圖所示,下面詳細介紹。
任務(wù)構(gòu)造
將序列標注任務(wù)轉(zhuǎn)換成一個與預(yù)訓(xùn)練階段一致的LM任務(wù),消除下游任務(wù)與預(yù)訓(xùn)練任務(wù)的Gap。對其輸入文本進行LM預(yù)測,當token不是實體時,預(yù)測成與輸入一致的token;當token是實體時,預(yù)測成實體類別下的token。而針對每個實體類別下的token的整合,即答案空間映射如何構(gòu)造。
答案空間映射的構(gòu)造
在特定領(lǐng)域下,往往未標注文本以及每個實體類別的實體列表是很好獲取的,通過詞表回溯構(gòu)建偽標簽數(shù)據(jù),其中,表示實體類別,表示文本數(shù)據(jù)。由于偽標簽數(shù)據(jù)會存在很多噪音數(shù)據(jù),因此在構(gòu)建答案空間映射時,使用4種方法,對每個實體類別中的候選詞語進行篩選。
- 數(shù)據(jù)分布法,即,篩選出在語料庫中,每個實體類別出現(xiàn)頻率最高的幾個詞。
- 語言模型輸出法,即,將數(shù)據(jù)輸入到語言模型中,統(tǒng)計每個類別中詞匯在語言模型輸出概率的總和,選擇概率最高的幾個詞。
- 數(shù)據(jù)分布&語言模型輸出法,即將數(shù)據(jù)分布法和語言模型輸出法相結(jié)合,將每個實體類別中的某一詞的詞頻*該詞模型輸出概率作為該詞得分,選擇分數(shù)最高的幾個詞。
- 虛擬標簽法,即,使用向量代替實體類別中的詞語,相當于類別「原型」,向量獲取辦法為將上述某一種方法獲取的高頻詞,輸入到語言模型中,獲取每個詞語的向量,然后進行加和取平均,獲取類別向量。
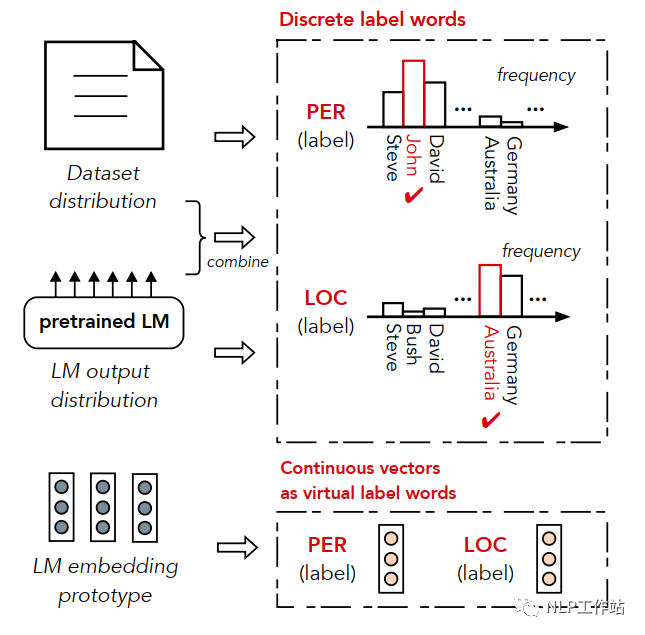
- 由于一些高頻詞可能出現(xiàn)在多個實體類別中,造成標簽混亂,因此采用閾值過濾方法去除沖突詞語,即(某個類別中的詞語出現(xiàn)的次數(shù)/詞語在所有類別中出現(xiàn)的次數(shù))必須大于規(guī)定的閾值,才將該詞語作為該實體類別的標簽詞語。
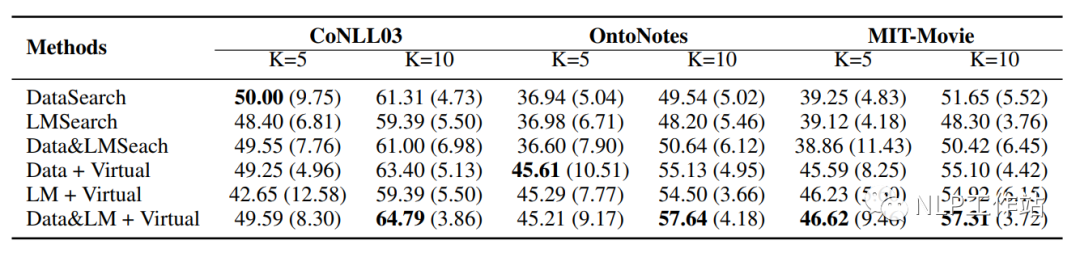
- 實驗發(fā)現(xiàn),絕大多少情況下,數(shù)據(jù)分布&語言模型輸出法獲取高頻詞,再使用虛擬標簽法獲取類別「原型」的方法最好。
訓(xùn)練&預(yù)測
模型訓(xùn)練階段采用LM任務(wù)的損失函數(shù),如下:
其中,,為預(yù)訓(xùn)練過程中LM層參數(shù)。
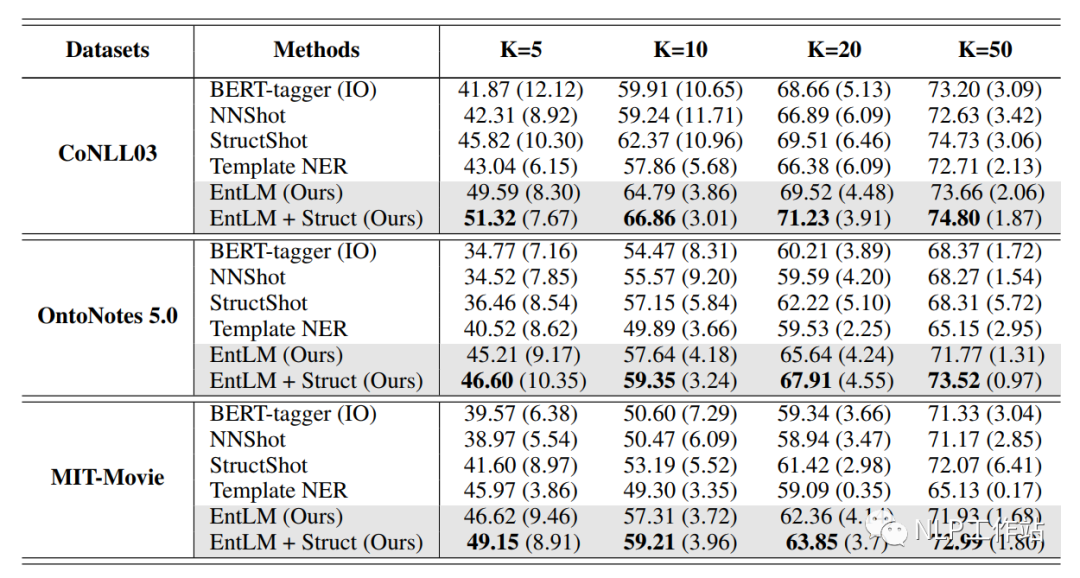
UIE
UIE,原文《Unified Structure Generation for Universal Information Extraction》,核心思想為將序列標注任務(wù)轉(zhuǎn)化為Seq2Seq的生成任務(wù),將手工提示模板與原始文本進行結(jié)合,通知模型待抽取的內(nèi)容,再通過特定的抽取格式,進行逐字解碼生成,提高模型效果。是一篇「手工模板且無答案空間映射」的Prompt論文。不過UIE適用于所有信息抽取任務(wù),不限于NER任務(wù),但后面主要以NER任務(wù)為例,進行闡述。
paper:https://arxiv.org/abs/2203.12277
github:https://github.com/universal-ie/UIE
模型如下圖所示,下面詳細介紹。
值得注意的是,UIE這篇論文與百度Paddle提到到UIE框架并不一個東西(看過源碼的人都知道,不要混淆)。百度Paddle提到到UIE框架本質(zhì)是一個基于提示的MRC模型,將提示模板作為query,文本作為document,使用Span抽取提示對應(yīng)的內(nèi)容片段。
任務(wù)構(gòu)造
將序列標注任務(wù)轉(zhuǎn)換成一個生成任務(wù),在Encoder端輸入為提示模板+原始文本,Decoder端逐字生成結(jié)構(gòu)化內(nèi)容。以T5為基礎(chǔ),采用預(yù)訓(xùn)練技術(shù),學(xué)習(xí)從文本到結(jié)構(gòu)化生成。
手工模板
在編碼端,通過待抽取schema(實體類別、關(guān)系等)構(gòu)造Prompt模板,稱為SSI,同于控制生成內(nèi)容。模板樣式如下圖所示,
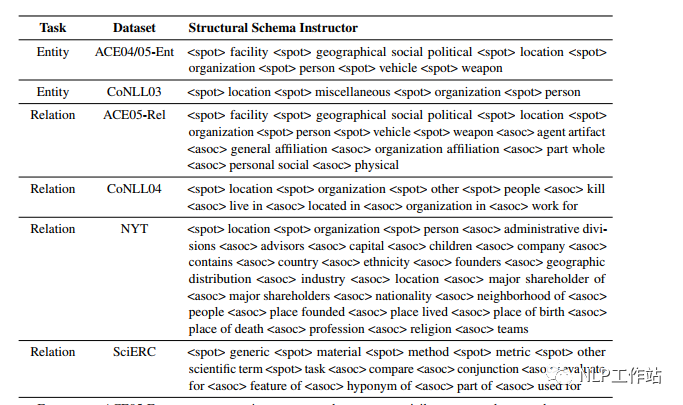
在解碼端,設(shè)計了特定的抽取結(jié)構(gòu),稱為SEL,而這種特殊的結(jié)構(gòu),也可以算作模板的一種吧,可以使解碼時,按照統(tǒng)一要求進行表示。抽取結(jié)構(gòu)樣式如下圖所示,
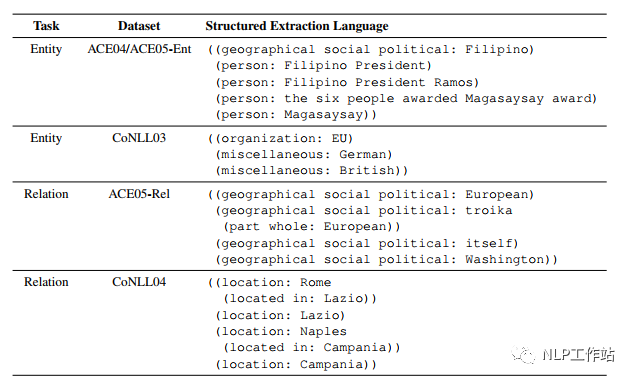
只需關(guān)注Entity部分即可。
訓(xùn)練&測試
對于Encoder端,輸入文本以及SSI內(nèi)容,獲取表示為:
對于Decoder端,逐字生成,如下:
由于訓(xùn)練數(shù)據(jù)中,待生成部分的數(shù)據(jù)格式均按照SEL格式構(gòu)造,因此生成內(nèi)容也會遵循其結(jié)構(gòu)。
而模型重點是如何構(gòu)造預(yù)訓(xùn)練數(shù)據(jù),在預(yù)訓(xùn)練過程中,數(shù)據(jù)來自Wikidata、Wikipedia和ConceptNet。并且構(gòu)造的數(shù)據(jù)格式包含三種,分別為、和。
- ,是通過Wikidata和Wikipedia構(gòu)建的text-to-struct平行語料。
- ,是僅包含結(jié)構(gòu)化形式的數(shù)據(jù)。
- ,是無結(jié)構(gòu)化的純文本數(shù)據(jù)。
在預(yù)訓(xùn)練過程中,三種語料對應(yīng)不同的訓(xùn)練損失,訓(xùn)練的網(wǎng)絡(luò)結(jié)構(gòu)也不一樣。訓(xùn)練整個Encoder-Decoder網(wǎng)絡(luò)結(jié)構(gòu),僅訓(xùn)練Decoder網(wǎng)絡(luò)結(jié)構(gòu),進訓(xùn)練Encoder網(wǎng)絡(luò)結(jié)構(gòu),最終的損失是三者的加和。
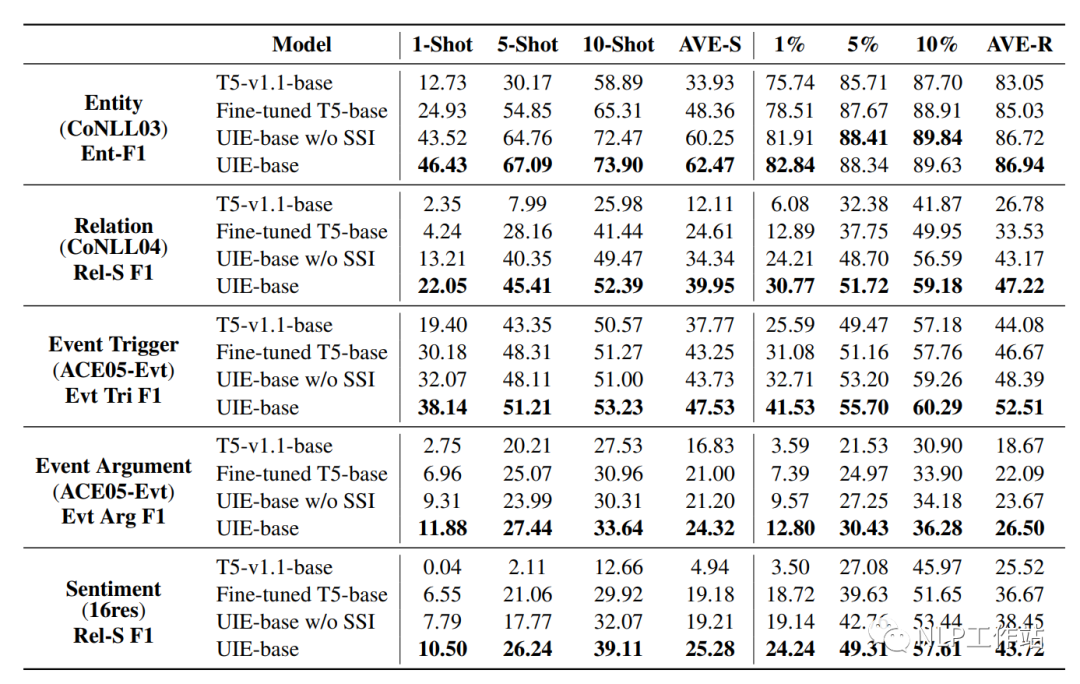
總結(jié)
本人在自己的中文數(shù)據(jù)集上,測試了TemplateNER、LightNER和EntLM的效果,驚奇的發(fā)現(xiàn)當數(shù)據(jù)量增加到50-shot時,「BERT-CRF」的效果是最好的(別整哪些沒用的,加點數(shù)據(jù)啥都解決了,這也是令我比較沮喪的點。也許、可能、大概、興許、或許是數(shù)據(jù)集或者代碼復(fù)現(xiàn)(code下載錯誤?)的問題,無能狂怒!!!)。
當5-shot和10-shot時,EntLM方法的效果較好,但是跟答案空間映射真的是強相關(guān),必須要找到很好的標簽詞才能獲取較好的效果。而TemplateNER方法測試時間太久了,在工業(yè)上根本無法落地。
就像之前我對prompt的評價一樣,我從來不否認Promot的價值,只是它并沒有達到我的預(yù)期。是世人皆醉我獨醒,還是世人皆醒我獨醉,路還要走,任務(wù)還要做,加油!!!
-
模板
+關(guān)注
關(guān)注
0文章
109瀏覽量
20877 -
模型
+關(guān)注
關(guān)注
1文章
3525瀏覽量
50494 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1224瀏覽量
25480
原文標題:總結(jié) | Prompt在NER場景的應(yīng)用
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
CYW20829在ESL場景下,event和Subevent時間長短的設(shè)置是什么?
敏捷合成器的技術(shù)原理和應(yīng)用場景
華為支付-(可選)特定場景配置操作
多用示波器的原理和應(yīng)用場景
開源大模型在多個業(yè)務(wù)場景的應(yīng)用案例
倍頻器的技術(shù)原理和應(yīng)用場景
關(guān)于歐盟法規(guī)中測試場景的研究
關(guān)于中斷知識學(xué)習(xí)總結(jié)筆記
汽車雷達回波發(fā)生器的技術(shù)原理和應(yīng)用場景
AI對話魔法 Prompt Engineering 探索指南






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論