

前面我們花了很多力氣在 TAO 上面訓(xùn)練模型,其最終目的就是要部署到推理設(shè)備上發(fā)揮功能。除了將模型訓(xùn)練過程進(jìn)行非常大幅度的簡(jiǎn)化,以及整合遷移學(xué)習(xí)等功能之外,TAO 還有一個(gè)非常重要的任務(wù),就是讓我們更輕松獲得 TensorRT 加速引擎。
將一般框架訓(xùn)練的模型轉(zhuǎn)換成 TensorRT 引擎的過程并不輕松,但是 TensorRT 所帶來的性能紅利又是如此吸引人,如果能避開麻煩又能享受成果,這是多么好的福利!
-
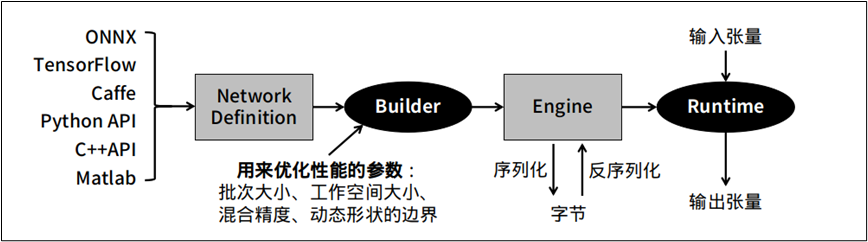
一般深度學(xué)習(xí)模型轉(zhuǎn)成 TensorRT 引擎的流程
下圖是將一般模型轉(zhuǎn)成 TesnorRT 的標(biāo)準(zhǔn)步驟,在中間 “Builder” 右邊的環(huán)節(jié)是相對(duì)單純的,比較復(fù)雜的是 “Builder” 左邊的操作過程。
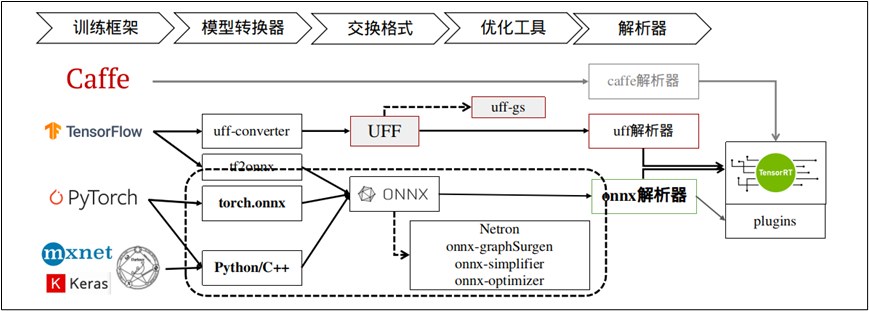
下圖就上圖 “NetworkDefinition” 比較深入的內(nèi)容,TensorRT 提供 Caffe、uff 與 ONNX 三種解析器,其中 Caffe 框架已淡出市場(chǎng)、uff 僅支持 TensorFlow 框架,其他的模型就需要透過 ONNX 交換格式進(jìn)行轉(zhuǎn)換。
這里以 TensorRT 所提供的 YOLOv3 范例來做范例,在安裝 Jetpack 4.6 版本的 Jetson Nano 設(shè)備上進(jìn)行體驗(yàn),請(qǐng)進(jìn)入到 TesnorRT 的 YOLOv3 范例中:
cd /usr/src/tensorrt/samples/python/yolov3_onnx?
根據(jù)項(xiàng)目的 README.md 指示,我們需要先為工作環(huán)境添加依賴庫,不過由于部分庫的版本關(guān)系,請(qǐng)先將 requirements.txt 的第 1、3 行進(jìn)行以下的修改:
numpy==1.19.4protobuf>=3.11.3onnx==1.10.1Pillow; python_version<"3.6"Pillow==8.1.2; python_version>="3.6"pycuda<2021.1
然后執(zhí)行以下指令進(jìn)行安裝:
python3 -m pip install -r requirements.txt
接下來需要先下載 download.yml 里面的三個(gè)文件,
wget https://pjreddie.com/media/files/yolov3.weightswget https://raw.githubusercontent.com/pjreddie/darknet/f86901f6177dfc6116360a13cc06ab680e0c86b0/cfg/yolov3.cfgwgethttps://github.com/pjreddie/darknet/raw/f86901f6177dfc6116360a13cc06ab680e0c86b0/data/dog.jpg
然后就能執(zhí)行以下指令,將 yolov3.weights 轉(zhuǎn)成 yolov3.onnx:
./yolov3_to_onnx.py -d /usr/src/tensorrt
這個(gè)執(zhí)行并不復(fù)雜,是因?yàn)?TensorRT 已經(jīng)提供 yolov3_to_onnx.py 的 Python 代碼,但如果將代碼打開之后,就能感受到這 750+ 行代碼要處理的內(nèi)容是相當(dāng)復(fù)雜,必須對(duì) YOLOv3 的結(jié)構(gòu)與算法有足夠了解,包括解析 yolov3.cfg 的 788 行配置。想象一下,如果這個(gè)代碼需要自行開發(fā)的話,這個(gè)難度有多高!
接下去再用下面指令,將 yolov3.onnx 轉(zhuǎn)成 yolov3.trt 加速引擎:
./onnx_to_tensorrt.py -d /usr/src/tensorrt
以上是從一般神經(jīng)網(wǎng)絡(luò)模型轉(zhuǎn)成 TensorRT 加速引擎的標(biāo)準(zhǔn)步驟,這需要對(duì)所使用的神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)層、數(shù)學(xué)公式、參數(shù)細(xì)節(jié)等等都有相當(dāng)足夠的了解,才有能力將模型先轉(zhuǎn)換成 ONNX 文件,這是技術(shù)門檻比較高的環(huán)節(jié)。
-
TAO 工具訓(xùn)練的模型轉(zhuǎn)成 TensorRT 引擎的工具
用 TAO 工具所訓(xùn)練、修剪并匯出的 .etlt 文件,可以跳過上述過程,直接在推理設(shè)備上轉(zhuǎn)換成 TensorRT 加速引擎,我們完全不需要了解神經(jīng)網(wǎng)絡(luò)的任何結(jié)構(gòu)與算法內(nèi)容,直接將 .etlt 文件復(fù)制到推理設(shè)備上,然后用 TAO 所提供的轉(zhuǎn)換工具進(jìn)行轉(zhuǎn)換就可以。
這里總共需要執(zhí)行三個(gè)步驟:
1、下載 tao-converter 工具,并調(diào)試環(huán)境:
請(qǐng)根據(jù)以下 Jetpack 版本,下載對(duì)應(yīng)的 tao-converter 工具:
Jetpack 4.4:https://developer.nvidia.com/cuda102-trt71-jp44-0Jetpack 4.5:https://developer.nvidia.com/cuda110-cudnn80-trt72-0Jetpack 4.6:https://developer.nvidia.com/jp46-20210820t231431z-001zip
下載壓縮文件后執(zhí)行解壓縮,就會(huì)生成 tao-converter 與 README.txt 兩個(gè)文件,再根據(jù) README.txt 的指示執(zhí)行以下步驟:
(1)安裝 libssl-dev 庫:
sudo apt install libssl-dev
(2) 配置環(huán)境,請(qǐng)?jiān)?strong> ~/.bashrc 最后面添加兩行設(shè)置:
export TRT_LIB_PATH=/usr/lib/aarch64-linux-gnuexportTRT_INCLUDE_PATH=/usr/include/aarch64-linux-gnu
(3) 將 tao-convert 變成可執(zhí)行文件:
source ~/.bashrcchmod +x tao-convertersudocptao-converter/usr/local/bin
2、安裝 TensorRT 的 OSS (Open Source Software)
這是 TensorRT 的開源插件,項(xiàng)目在 https://github.com/NVIDIA/TensorRT,下面提供的安裝說明非常復(fù)雜,我們將繁瑣的步驟整理之后,就是下面的步驟:
export ARCH=請(qǐng)根據(jù)設(shè)備進(jìn)行設(shè)置,例如Nano為53、NX為72、Xavier為62export TRTVER=請(qǐng)根據(jù)系統(tǒng)的TensorRT版本,例如Jetpack 4.6為8.0.1git clone -b $TRTVER https://github.com/nvidia/TensorRT TRTosscd TRToss/git checkout -b $TRTVER && git submodule update --init --recursivemkdir -p build && cd buildcmake ..-DGPU_ARCHS=$ARCH-DTRT_LIB_DIR=/usr/lib/aarch64-linux-gnu/-DCMAKE_C_COMPILER=/usr/bin/gcc-DTRT_BIN_DIR=`pwd`/out-DTRT_PLATFORM_ID=aarch64-DCUDA_VERSION=10.2make nvinfer_plugin -j$(nproc)sudomv/usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.0.1/usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.0.1.baksudocplibnvinfer_plugin.so.8.0.1/usr/lib/aarch64-linux-gnu/libnvinfer_plugin.so.8.0.1
這樣就能開始用 tao-converter 來將 .etlt 文件轉(zhuǎn)換成 TensorRT 加速引擎了。
3、用 tao-converter 進(jìn)行轉(zhuǎn)換
(1)首先將 TAO 最終導(dǎo)出 (export) 的文件復(fù)制到 Jetson Nano 上,例如前面的實(shí)驗(yàn)中最終導(dǎo)出的文件 ssd_resnet18_epoch_080.etlt,
(2)在 Jetson Nano 上執(zhí)行 TAO 的 ssd.ipynb 最后所提供的轉(zhuǎn)換指令,如下:
KEY=tao converter -k $KEY-d 3,300,300-o NMS-e ssd_resnet18_epoch_080.trt # 自己設(shè)定輸出名稱16-t fp16 # 使用export時(shí)相同精度nchwssd_resnet18_epoch_080.etlt
這樣就能生成在 Jetson Nano 上的 ssd_resnet18_epoch_080.trt 加速引擎文件,整個(gè)過程比傳統(tǒng)方式要簡(jiǎn)便許多。
原文標(biāo)題:NVIDIA Jetson Nano 2GB系列文章(64):將模型部署到Jetson設(shè)備
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5199瀏覽量
105558 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5550瀏覽量
122373 -
模型訓(xùn)練
+關(guān)注
關(guān)注
0文章
20瀏覽量
1429
原文標(biāo)題:NVIDIA Jetson Nano 2GB系列文章(64):將模型部署到Jetson設(shè)備
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
在OpenVINO?工具套件的深度學(xué)習(xí)工作臺(tái)中無法導(dǎo)出INT8模型怎么解決?
深度學(xué)習(xí)模型的魯棒性優(yōu)化
GPU深度學(xué)習(xí)應(yīng)用案例
FPGA加速深度學(xué)習(xí)模型的案例
AI大模型與深度學(xué)習(xí)的關(guān)系
深度學(xué)習(xí)編譯器和推理引擎的區(qū)別
深度學(xué)習(xí)模型有哪些應(yīng)用場(chǎng)景
深度學(xué)習(xí)模型量化方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論