") 國內AI芯片面臨怎樣的機遇和挑戰(zhàn)?
國內AI芯片面臨怎樣的機遇和挑戰(zhàn)?
電子發(fā)燒友網(wǎng)報道(文/李彎彎)智能化美好新時代,計算產(chǎn)業(yè)的發(fā)展是必然趨勢,而算力是計算產(chǎn)業(yè)的基石,談到算力就必然離不開AI芯片。
長期以來市場和生態(tài)制約著國產(chǎn)芯片產(chǎn)業(yè)的發(fā)展,國外芯片巨頭定義了傳統(tǒng)芯片生態(tài)的規(guī)則,壟斷了國內市場,在智能化新時代,國內的AI芯片又面臨怎樣的機遇和挑戰(zhàn)?AI芯片產(chǎn)業(yè)落地需要關注哪些問題?
如今AI算法的應用越來越廣泛,對AI算力提出了很高的要求,而傳統(tǒng)處理器架構性能提升受限,那么AI芯片架構又該有怎樣的改進?
日前在百度技術論壇上,昆侖芯科技研發(fā)總監(jiān)羅航、昆侖芯科技NPU架構負責人王京、昆侖芯科技基礎工具鏈開發(fā)負責人張釗從各個角度對上述問題進行了闡述。
國內AI芯片的機遇和挑戰(zhàn)
國內AI芯片面臨怎樣的機遇和挑戰(zhàn)?羅航從需求側和供給側談到了這個話題,他認為,從需求側來看,機遇方面,近幾年的中美博弈為國產(chǎn)芯片打開了市場空間,新基建、雙循環(huán)、自主可控等政策扶持也給AI芯片帶了新的機遇,另外AI芯片是一個全新的市場,全球生態(tài)格局沒有固化,這是與傳統(tǒng)芯片不同的地方;挑戰(zhàn)方面,AI產(chǎn)業(yè)仍處于早期階段,商業(yè)化不成熟,需求尚未爆發(fā),對產(chǎn)業(yè)拉動效應未顯現(xiàn)。
從供給測來看,機遇方面,摩爾定律逼近極限,領先者和追趕者代差會逐步縮小,大陸已有28nm工藝儲備,中國具有資本、技術、人才的后發(fā)優(yōu)勢;挑戰(zhàn)方面,與第一梯隊還存在非常巨大的代際差距,產(chǎn)品和生態(tài)還很不完善,芯片設計等底層EDA還依賴國外技術。

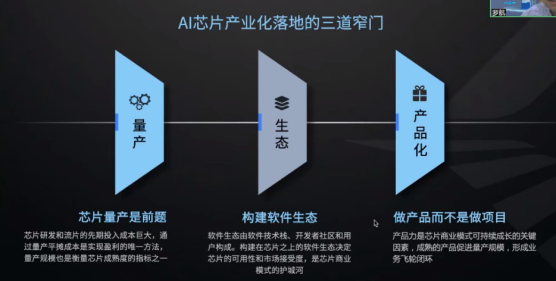
那么AI芯片產(chǎn)業(yè)產(chǎn)業(yè)化落地重點需要關注和解決的問題是什么?羅航談到幾點:1、芯片量產(chǎn)是前提,芯片研發(fā)和流片的先期投入成本巨大,通過量產(chǎn)平攤成本是實現(xiàn)盈利的唯一方法,量產(chǎn)規(guī)模也是衡量芯片成熟度的指標之一;2、構建軟件生態(tài):軟件生態(tài)由軟件技術棧、開發(fā)者社區(qū)和用戶構成。構建在芯片之上的軟件生態(tài)決定芯片的可用性和市場接受度,是芯片商業(yè)模式的護城河;3、做產(chǎn)品而不是做項目:產(chǎn)品力是芯片商業(yè)模式可持續(xù)成長的關鍵因素,成熟的產(chǎn)品促進量產(chǎn)規(guī)模,形成業(yè)務飛輪閉環(huán)。
在羅航看來,AIoT相當于是萬物數(shù)據(jù)+超強算力,數(shù)據(jù)是生產(chǎn)資料,算力是生產(chǎn)力。物聯(lián)網(wǎng)負責海量數(shù)據(jù)生產(chǎn)和消費,AI芯片負責這些數(shù)據(jù)的處理和再造,二者相輔相成,缺一不可,計算速度、計算方法、通信能力、數(shù)據(jù)總量代表未來國與國之間的競爭力。
通用AI芯片架構昆侖芯XPU的優(yōu)勢
昆侖芯科技是一家AI芯片公司,2021年4月完成了獨立融資,前身是百度智能芯片及架構部,昆侖芯在AI芯片上經(jīng)歷了超過10年的發(fā)展歷程,2017年發(fā)布自研架構昆侖芯XPU;2020年昆侖芯1代大規(guī)模部署;2021年昆侖芯2代量產(chǎn)。
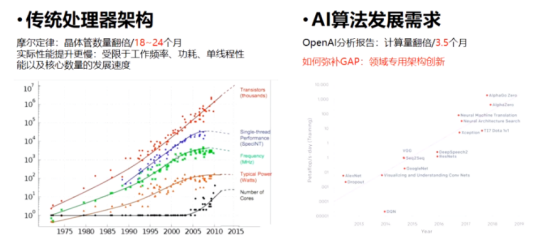
為什么要自研AI芯片架構,王京談到,如今各行各業(yè)都需要用到語音、圖像、自然語言處理等技術,AI算法的廣泛應用對AI算力提出更高要求,根據(jù)OpenAI分析報告,每3.5個月計算量就要翻倍,而傳統(tǒng)處理器架構,根據(jù)摩爾定律,晶體管數(shù)量翻倍要18-24個月,而且工作頻率、功耗、單線程性能以及核心數(shù)量的發(fā)展速度已經(jīng)非常緩慢,受限于此,傳統(tǒng)處理器架構實際性能提升更慢了。因此,有必要開發(fā)一款通用的AI芯片架構。
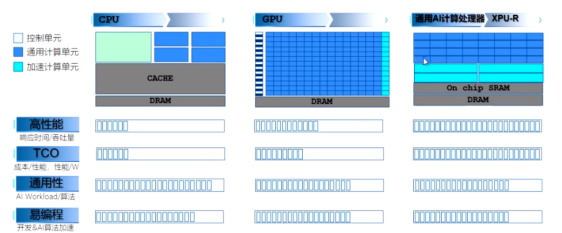
相比于傳統(tǒng)的CPU、GPU,昆侖芯科技開發(fā)的通用AI計算處理器XPU-R改變了通用計算單元和加速計算單元的數(shù)量和分布,從高性能、TCO、通用性、易編程幾個指標來看,通用AI計算處理器XPU-R相比于CPU、GPU都表現(xiàn)出比較明顯的優(yōu)勢。
昆侖芯2代,具有高性能分布式AI系統(tǒng),芯片間互聯(lián)支持訓練和推理中模型并行&數(shù)據(jù)并行策略的通訊要求;支持硬件虛擬化,計算單元和存儲單元的物理隔離,優(yōu)化了加速芯片的利用率在保證延時和吞吐量的情況下支持推理和訓練等混合工作負載;增強的通用計算能力,XPU-R架構為CLUSTER的算力提升2-3倍,進一步擴展通用AI計算能力。
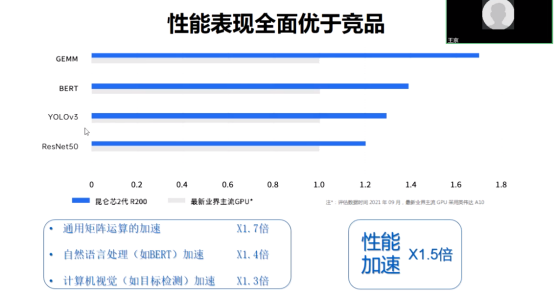
以昆侖芯AI加速卡R200為例,與業(yè)界主流150W GPU相比,它的通用矩陣乘法性能加速為后者的1.7倍;視覺的目標檢測算法YOLO性能加速為1.3倍;自然語言處理約典型算法Bert性能加速為1.4倍;視覺的圖像分類模型ResNet50性能加速為1.2倍。
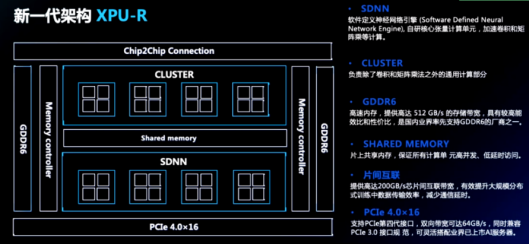
張釗詳細來介紹了新一代架構XPU-R,如下圖。SDNN,軟件定位神經(jīng)網(wǎng)絡引擎,自研核心張量計算單元,加速卷積和矩陣乘等計算;CLUSTER,負責除了卷積和矩陣乘法之外的通用計算部分;GDDR6,高速內存,提供高達512GB/s的存儲帶寬,具有較高能效比和性價比,是國內業(yè)界率先支持GDDR6的廠商之一;SHARED MEMORY,片上共享內存,保證所有計算單元高并發(fā),低延時訪問;片間互聯(lián),提供高達200GB/s芯片間互聯(lián)帶寬,有效提升大規(guī)模分布式訓練中數(shù)據(jù)傳輸效率,減少通信延時;PCIe 4.0*16,支持PCIe第四代接口,雙向帶寬可達64GB/s,同時兼容PCIe 3.0接口規(guī)范,可靈活搭配業(yè)界已上市AI服務器。
昆侖芯原生支持開源深度學習框架飛槳(PaddlePaddle)、百度機器學習平臺BML及各種類的AI能力引擎;已經(jīng)適配90%以上主流模型,推理高效支持飛槳、TensorFlow/Pytorch等框架,訓練與飛槳社區(qū)進行協(xié)同生態(tài)建設,已經(jīng)開源;昆侖芯+飛槳是百度人工智能生態(tài)端到端軟硬件一體解決方案的獨特產(chǎn)品組合,已與多款國產(chǎn)操作系統(tǒng)、國產(chǎn)通用處理器完成端到端的系統(tǒng)適配,實現(xiàn)國產(chǎn)AI計算生態(tài)解決方案。
如今昆侖芯已經(jīng)在互聯(lián)網(wǎng)、智慧城市、智慧工業(yè)、生物計算、智慧金融、智慧政務、智算中心以及智慧交通等各行業(yè)AI應用場景中落地。
-
處理器
+關注
關注
68文章
19259瀏覽量
229655 -
AI芯片
+關注
關注
17文章
1879瀏覽量
34993 -
AI算法
+關注
關注
0文章
249瀏覽量
12259
發(fā)布評論請先 登錄
相關推薦
產(chǎn)業(yè)"內卷化"下磁性元件面臨的機遇與挑戰(zhàn)

仇肖莘探討2024 AI芯片新趨勢與邊緣智能機遇
億鑄科技熊大鵬探討AI大算力芯片的挑戰(zhàn)與解決策略
大算力芯片面臨的技術挑戰(zhàn)和解決策略
AI for Science:人工智能驅動科學創(chuàng)新》第4章-AI與生命科學讀后感
億鑄科技談大算力芯片面臨的技術挑戰(zhàn)和解決策略
數(shù)據(jù)中心的AI時代轉型:挑戰(zhàn)與機遇

蘋果AI服務在華面臨挑戰(zhàn),尋求本土合作新機遇
中國AI芯片行業(yè),自主突破與未來展望
在機遇與挑戰(zhàn)并存的AI時代,三星如何在DRAM領域開拓創(chuàng)新?

2024年國內USB Type-C廠商的機遇與挑戰(zhàn)分析
國產(chǎn)光耦2024:發(fā)展機遇與挑戰(zhàn)全面解析

中國芯片企業(yè)芯片完全解析

機遇與挑戰(zhàn)并存,2024年AI、汽車將給元器件行業(yè)帶來大量機會






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論