 處理器架構探索的混合創新
處理器架構探索的混合創新
架構探索一直是產品設計的圣杯。它有可能徹底改變產品工程。研究和用例評估表明,在架構探索期間可以實現 80% 的系統優化和幾乎 100% 的性能/功耗權衡。
不幸的是,除了公司投入大量資源和時間的利基領域外,架構探索未能起飛。架構探索被高度誤解,并且已經推出了聲稱架構探索但圍繞現有產品(例如指令集模擬器、軟件時序分析器和硬件驗證)的產品。用一組類庫突出顯示語言不足以建立方法、輕松創建模型、針對基準進行驗證和性能系統優化。
架構探索的主要障礙是缺乏高端內核、互連、緩存和內存的架構模型。有限的模型范圍往往適用于架構探索不會增加顯著價值的低端處理器,每秒運行最多 1,000 條指令的周期精確模型,需要很長時間來安裝、學習和組裝,并在 IP 發貨后很好地發布。這些模型需要數周時間才能運行一個基準測試,并且對于比較驗證很有用。此外,它們不能跨內核、SoC、系統和軟件進行擴展。
架構模型往往是 IP 提供商和 EDA 供應商的低優先級,因為他們必須提供 RTL 和軟件工具,例如編譯器、調試器和驗證 IP。此外,為大規模分發創建架構模型需要特殊的技能,因為每個核心類型的流程都重新開始。組裝需要很長時間,需要多種資源,并且運行速度極慢。每個新的處理器內核都有很多變化——緩存的讀/寫寬度、多線程、ISA 版本、可變流水線階段、用于將指令分派到執行單元的調度邏輯以及指令緩沖區。
具有隨機性的傳統架構模型被組裝大型系統和數據中心的公司使用。這些模型將模擬不同類型的請求和任務的延遲和功耗。
另一個主要問題是驗證過程。對于新處理器,用于驗證模型準確性的基準數據有限。這個問題對于功耗、高速緩存命中未命中率和內存吞吐量而言更為嚴重。當然,FPGA 板可以通過使用舊版本的內核以及更新的緩存、互連和內存設置來減輕一些負載。測試新內核正確性的最佳方法是仔細檢查每個可能的場景,包括并發執行,運行緩存層次結構和 DMA 的舊跟蹤,并生成確保絕對覆蓋的場景。
圖 1:基于 RISC-V 和 ARM 的 VisualSim 處理器架構探索
Mirabilis Design 最近采用的一種方法是在具有圖形開發環境的離散事件模擬器上提供混合處理器架構庫。這類架構模型消除了早期方法的所有問題。這是一個通用的生成器,它使用電子表格來定義核心配置。內部定序器通過消除不影響流正確性、性能和功率的邏輯來優化仿真性能,并提供靈活的選項列表來定義不同的管道變體。這種方法的美妙之處在于可以快速構建新的甚至不存在的內核。
這種方法有多種好處,包括:
單個庫模塊可以將微控制器建模為高性能處理器。
處理器庫具有研究單個集群、多核集群組、片上系統和完整系統(如 ECU、雷達或超級計算機)的仿真性能。
這種方法提供了一個龐大的供應商內核庫。
混合核心與隨機核心不同,具有運行軟件跟蹤的能力。
擴展庫具有使生成的內核與緩存、動態系統緩存、TileLink、AMBA AXI、NoC、DDR、LPDDR、GDDR、DMA 和橋完全集成的所有連接性和方法。
這些使用混合處理器的模型可用于選擇時鐘速度、緩沖區大小、寬度和容量,同時提供拓撲、路由、flit 大小和設備連接性。在電源方面,系統模型可以確定最佳電源狀態集和最佳電源管理算法。在這個早期階段分析功率可以深入了解配電、電池容量、充電系統和熱要求。混合模型的準確性使軟件性能調整和調度器和仲裁器的選擇成為可能。
需要為性能生成的所需指標是延遲、吞吐量、緩沖區占用率、命中率、流水線停頓、MIPS 和周期/指令。對平均和瞬時功率、能耗、每個任務和設備的功率以及能源管理算法的影響進行真正的功率分析指標。高級分析將涵蓋功能正確性、發生故障時的行為和服務質量。
要在混合處理器中定義的屬性包括對執行單元和延遲周期的 ISA 分配、浮點和整數單元的數量、每個集群的核心數、有序和無序的分布以及大/小數量核心。緩存配置可以涵蓋包含/排除、容量、關聯性、銀行計數、暫存器的使用以及各種替換和寫入策略。對于互連,吞吐量要求、緩沖區占用率、最有效的仲裁算法以及傳輸突發/閃存大小。在內存中,該模型可以測量跟蹤、順序和隨機地址的帶寬、延遲和打開/關閉頁面。
在 SoC 級別,使用了 DMA 與 TCP 傳輸、張量操作探索和拆分鎖安排。必須對系統進行跨集群的任務分區、內存控制器調度、路由器數量和設備連接性測試。隨著系統越來越接近客戶部署,可以擴展相同的模型以集成多處理器集成,最大限度地減少芯片到芯片的開銷,將應用程序分配到處理器以及存儲策略。
架構師可以從供應商列表中選擇或在幾天內創建一個新的。一旦處理器內核被實例化,用戶就可以連接其他半導體 IP 以形成完整的 SoC。在短時間內,用戶可以擁有一個多核多集群、基于 NoC 的 SoC,帶有 GPU、TPU/AI 加速器、內存、顯示控制器、以太網和其他接口。為了模擬這個模型,IO 由泊松分布和數據范圍生成的數據流觸發,處理器執行軟件跟蹤以執行模擬。多個 SoC 可以通過連貫的 PCIe 或 CXL 組合,或與高速以太網或可靠的 OpenVPX 背板連接。
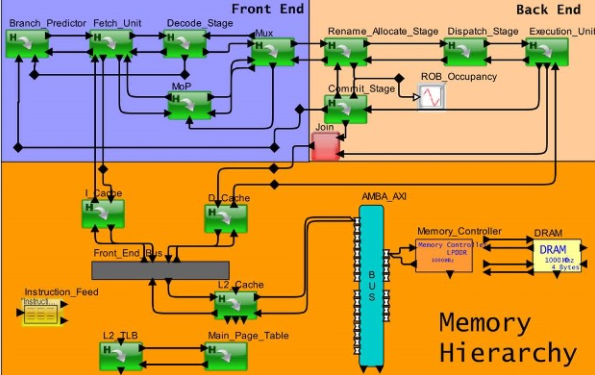
圖 2:具有高速緩存存儲器層次結構的亂序處理器管道的系統級模型
新的混合處理器對加載/存儲行為具有指令感知,按順序/無序執行,支持多指令獲取和分派,支持每個流水線階段的不同屬性,支持之間的流控制階段、任務發布隊列、跳轉流水線階段、流水線和緩存之間的緩沖、可變讀寫寬度和搶占支持。混合方法可以擴展到 20 個整數、浮點、向量、分支、加載和存儲類型的執行單元。同時,每個執行單元的流水線級數可以是可變的,最多可以定義為 20 個。
混合處理器的所有這些新功能都支持帶有緩存地址的執行軟件跟蹤。為了準備在此處理器模型上執行的軟件,全自動系統會生成指令序列、指令高速緩存地址和數據高速緩存地址以用于加載存儲。架構模型與流量和軟件執行的結合提供了一個有效的平臺來測試內核、緩存、互連和內存的準確性。該測試涵蓋了端到端設計的延遲和功耗,還測量了緩存命中率和內存吞吐量。這種新的基準測試方法可以增強用戶的信心,并確保進行高質量的權衡分析。
新的混合處理器可供使用 ARM 或 RISC-V 內核開發定制 SoC 的系統公司、集成多個非異構主設備、加速器、GPU 和其他處理單元的半導體公司,以及實施新應用程序和高級 AI/ML 工作負載的 AI 公司使用。 系統和半導體的競爭在所有市場上都很重要,新產品的時間安排正在縮短。由于半導體短缺,公司必須更長時間地使用現有 SoC,識別新應用并支持現有設備上增加的功能。進行廣泛的架構覆蓋將提供對實際性能和容量的詳細視圖,從而為將產品集成到其環境中的客戶提供有價值的見解。
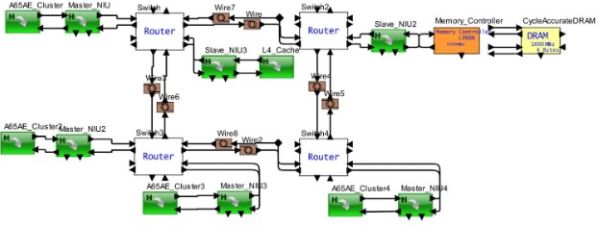
圖 3:具有 Aaa65AE 的多集群多核處理器,用于汽車安全關鍵型應用
混合處理器的一個重要附帶好處是能夠運行軟件并準確查看目標配置上的軟件性能。當今的 SoC 配置非常復雜,以至于在 FPGA 上運行它會導致您錯過一致性、數據分配、跨集群的工作負載分配以及數據路徑和緩存之間復雜的通信。當一組軟件任務在多核架構上同時運行時,軟件團隊可以及早了解時序和功耗。
類似地,每個內核都提供了緩存層次結構的變化以及與諸如回寫、寬度、塊大小、預取條件、存儲體、關聯性、私有與系統等項目的連接。然后是來自DDR、LPDDR、GDDR、HBM的內存,以及商業內存控制器中不同類型的調度器。最后,不同的互連選項:供應商特定的片上網絡、極小的 NoC、AMBA 變體和 Tilelink。為此添加 DMA、網橋、中斷、動態共享緩存單元、IO、以太網、CAN/CAN-FD 和 PCIe 以獲得完整的要求。
混合處理器是電子設計行業的一項重大創新。它為架構師提供了更多的權力,并使團隊能夠在開發之前可視化系統行為。由于分析速度很快,真正的架構覆蓋是可能的,并且可以涵蓋性能、功率、服務質量、效率、可靠性和功能正確性。通過添加軟件性能分析和調整,所有系統團隊都可以在同一環境中參與。隨著設計人員參與新應用、小型工藝技術和不斷增加的功率要求,混合處理器是未來。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19275瀏覽量
229744 -
以太網
+關注
關注
40文章
5421瀏覽量
171658 -
soc
+關注
關注
38文章
4165瀏覽量
218215
發布評論請先 登錄
相關推薦
對稱多處理器和非對稱多處理器的區別
簡述微處理器的指令集架構
盛顯科技:在拼接處理器上配置混合矩陣的步驟是什么?
ARM處理器和CISC處理器的區別
盛顯科技:拼接處理器為什么要配置混合矩陣?







 工商網監
工商網監
評論