") 關于ZooKeeper知識你知道多少
關于ZooKeeper知識你知道多少
1 ZooKeeper簡介
ZooKeeper 是一個開源的分布式協(xié)調框架,它的定位是為分布式應用提供一致性服務,是整個大數(shù)據(jù)體系的管理員。ZooKeeper 會封裝好復雜易出錯的關鍵服務,將高效、穩(wěn)定、易用的服務提供給用戶使用。
如果上面的官方言語你不太理解,你可以認為 ZooKeeper = 文件系統(tǒng) + 監(jiān)聽通知機制。
1.1 文件系統(tǒng)
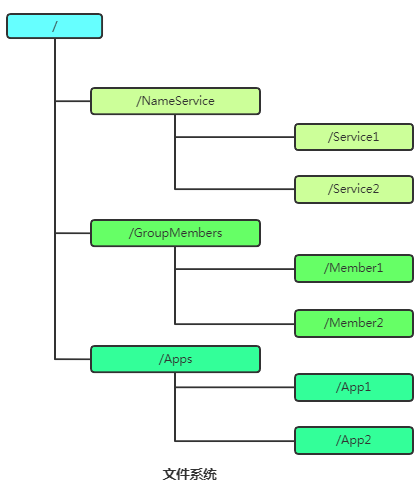
Zookeeper維護一個類似文件系統(tǒng)的樹狀數(shù)據(jù)結構,這種特性使得 Zookeeper 不能用于存放大量的數(shù)據(jù),每個節(jié)點的存放數(shù)據(jù)上限為1M。每個子目錄項如 NameService 都被稱作為 znode(目錄節(jié)點)。和文件系統(tǒng)一樣,我們能夠自由的增加、刪除znode,在一個znode下增加、刪除子znode,唯一的不同在于znode是可以存儲數(shù)據(jù)的。默認有四種類型的znode:
- 持久化目錄節(jié)點 PERSISTENT:客戶端與zookeeper斷開連接后,該節(jié)點依舊存在。
- 持久化順序編號目錄節(jié)點 PERSISTENT_SEQUENTIAL:客戶端與zookeeper斷開連接后,該節(jié)點依舊存在,只是Zookeeper給該節(jié)點名稱進行順序編號。
- 臨時目錄節(jié)點 EPHEMERAL:客戶端與zookeeper斷開連接后,該節(jié)點被刪除。
- 臨時順序編號目錄節(jié)點 EPHEMERAL_SEQUENTIAL:客戶端與zookeeper斷開連接后,該節(jié)點被刪除,只是Zookeeper給該節(jié)點名稱進行順序編號。
1.2 監(jiān)聽通知機制
Watcher 監(jiān)聽機制是 Zookeeper 中非常重要的特性,我們基于 Zookeeper 上創(chuàng)建的節(jié)點,可以對這些節(jié)點綁定監(jiān)聽事件,比如可以監(jiān)聽節(jié)點數(shù)據(jù)變更、節(jié)點刪除、子節(jié)點狀態(tài)變更等事件,通過這個事件機制,可以基于 Zookeeper 實現(xiàn)分布式鎖、集群管理等功能。
Watcher 特性:
當數(shù)據(jù)發(fā)生變化的時候, Zookeeper 會產生一個 Watcher 事件,并且會發(fā)送到客戶端。但是客戶端只會收到一次通知。如果后續(xù)這個節(jié)點再次發(fā)生變化,那么之前設置 Watcher 的客戶端不會再次收到消息。(Watcher 是一次性的操作)。可以通過循環(huán)監(jiān)聽去達到永久監(jiān)聽效果。
ZooKeeper 的 Watcher 機制,總的來說可以分為三個過程:
- 客戶端注冊 Watcher,注冊 watcher 有 3 種方式,getData、exists、getChildren。
- 服務器處理 Watcher 。
- 客戶端回調 Watcher 客戶端。
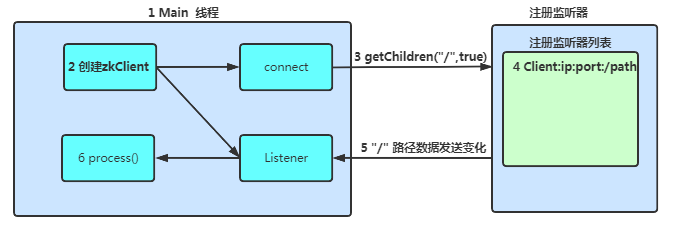
監(jiān)聽流程:
1.3 Zookeeper 特點
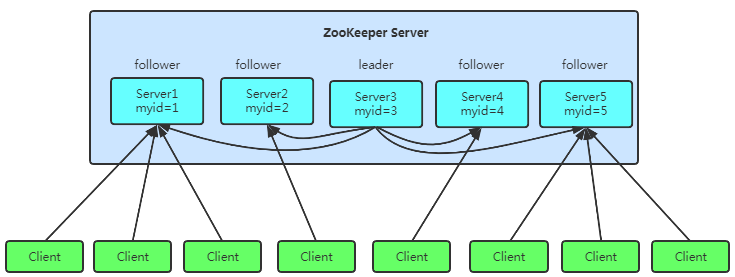
- 集群:Zookeeper是一個領導者(Leader),多個跟隨者(Follower)組成的集群。
- 高可用性:集群中只要有半數(shù)以上節(jié)點存活,Zookeeper集群就能正常服務。
- 全局數(shù)據(jù)一致:每個Server保存一份相同的數(shù)據(jù)副本,Client無論連接到哪個Server,數(shù)據(jù)都是一致的。
- 更新請求順序進行:來自同一個Client的更新請求按其發(fā)送順序依次執(zhí)行。
- 數(shù)據(jù)更新原子性:一次數(shù)據(jù)更新要么成功,要么失敗。
- 實時性:在一定時間范圍內,Client能讀到最新數(shù)據(jù)。
-
從
設計模式角度來看,zk是一個基于觀察者設計模式的框架,它負責管理跟存儲大家都關心的數(shù)據(jù),然后接受觀察者的注冊,數(shù)據(jù)反生變化zk會通知在zk上注冊的觀察者做出反應。 - Zookeeper是一個分布式協(xié)調系統(tǒng),滿足CP性,跟SpringCloud中的Eureka滿足AP不一樣。
- 分布式協(xié)調系統(tǒng):Leader會同步數(shù)據(jù)到follower,用戶請求可通過follower得到數(shù)據(jù),這樣不會出現(xiàn)單點故障,并且只要同步時間無限短,那這就是個好的 分布式協(xié)調系統(tǒng)。
- CAP原則又稱CAP定理,指的是在一個分布式系統(tǒng)中,一致性(Consistency)、可用性(Availability)、分區(qū)容錯性(Partition tolerance)。CAP 原則指的是,這三個要素最多只能同時實現(xiàn)兩點,不可能三者兼顧。
2 Zookeeper 提供的功能
通過對 Zookeeper 中豐富的數(shù)據(jù)節(jié)點進行交叉使用,配合 Watcher 事件通知機制,可以非常方便的構建一系列分布式應用中涉及的核心功能,比如 數(shù)據(jù)發(fā)布/訂閱、負載均衡、命名服務、分布式協(xié)調/通知、集群管理、Master 選舉、分布式鎖和分布式隊列 等功能。
1. 數(shù)據(jù)發(fā)布/訂閱
當某些數(shù)據(jù)由幾個機器共享,且這些信息經常變化數(shù)據(jù)量還小的時候,這些數(shù)據(jù)就適合存儲到ZK中。
- 數(shù)據(jù)存儲:將數(shù)據(jù)存儲到 Zookeeper 上的一個數(shù)據(jù)節(jié)點。
- 數(shù)據(jù)獲取:應用在啟動初始化節(jié)點從 Zookeeper 數(shù)據(jù)節(jié)點讀取數(shù)據(jù),并在該節(jié)點上注冊一個數(shù)據(jù)變更 Watcher
- 數(shù)據(jù)變更:當變更數(shù)據(jù)時會更新 Zookeeper 對應節(jié)點數(shù)據(jù),Zookeeper會將數(shù)據(jù)變更通知發(fā)到各客戶端,客戶端接到通知后重新讀取變更后的數(shù)據(jù)即可。
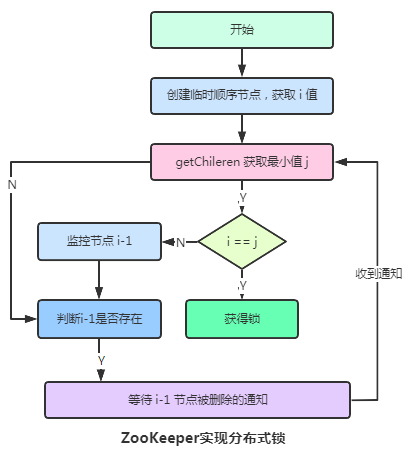
2. 分布式鎖
關于分布式鎖其實在 Redis 中已經講過了,并且Redis提供的分布式鎖是比ZK性能強的。基于ZooKeeper的分布式鎖一般有如下兩種。
- 保持獨占
核心思想:在zk中有一個唯一的臨時節(jié)點,只有拿到節(jié)點的才可以操作數(shù)據(jù),沒拿到的線程就需要等待。缺點:可能引發(fā)
羊群效應,第一個用完后瞬間有999個同時并發(fā)的線程向zk請求獲得鎖。
- 控制時序
主要是避免了羊群效應,臨時節(jié)點已經預先存在,所有想要獲得鎖的線程在它下面創(chuàng)建臨時順序編號目錄節(jié)點,編號最小的獲得鎖,用完刪除,后面的依次排隊獲取。
3. 負載均衡
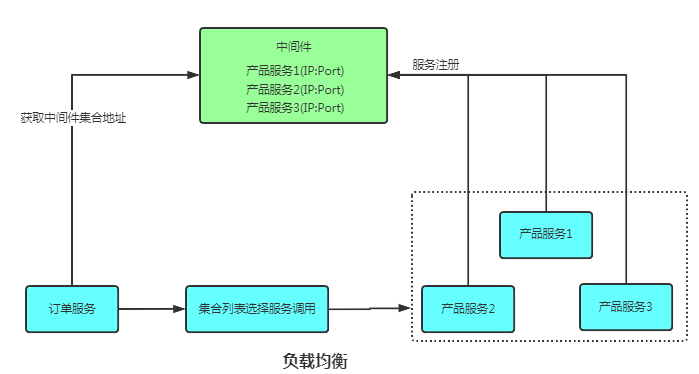
多個相同的jar包在不同的服務器上開啟相同的服務,可以通過nginx在服務端進行負載均衡的配置。也可以通過ZooKeeper在客戶端進行負載均衡配置。
- 多個服務注冊
- 客戶端獲取中間件地址集合
- 從集合中隨機選一個服務執(zhí)行任務
ZooKeeper負載均衡和Nginx負載均衡區(qū)別:
- ZooKeeper不存在單點問題,zab機制保證單點故障可重新選舉一個leader只負責服務的注冊與發(fā)現(xiàn),不負責轉發(fā),減少一次數(shù)據(jù)交換(消費方與服務方直接通信),需要自己實現(xiàn)相應的負載均衡算法。
- Nginx存在單點問題,單點負載高數(shù)據(jù)量大,需要通過 KeepAlived + LVS 備機實現(xiàn)高可用。每次負載,都充當一次中間人轉發(fā)角色,增加網絡負載量(消費方與服務方間接通信),自帶負載均衡算法。
4. 命名服務
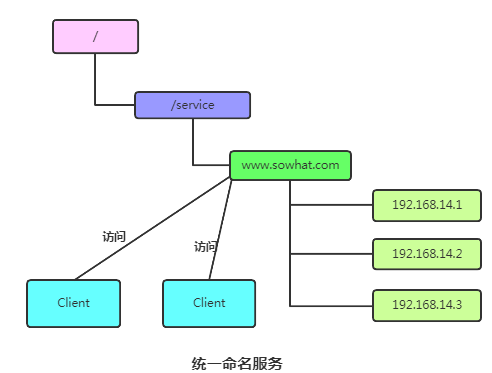
命名服務是指通過指定的名字來獲取資源或者服務的地址,利用 zk 創(chuàng)建一個全局唯一的路徑,這個路徑就可以作為一個名字,指向集群中的集群,提供的服務的地址,或者一個遠程的對象等等。
5. 分布式協(xié)調/通知
- 對于系統(tǒng)調度來說,用戶更改zk某個節(jié)點的value, ZooKeeper會將這些變化發(fā)送給注冊了這個節(jié)點的 watcher 的所有客戶端,進行通知。
- 對于執(zhí)行情況匯報來說,每個工作進程都在目錄下創(chuàng)建一個攜帶工作進度的臨時節(jié)點,那么匯總的進程可以監(jiān)控目錄子節(jié)點的變化獲得工作進度的實時的全局情況。
6. 集群管理
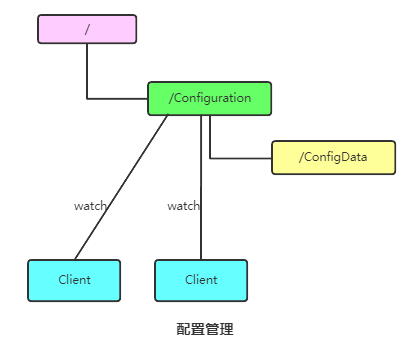
大數(shù)據(jù)體系下的大部分集群服務好像都通過ZooKeeper管理的,其實管理的時候主要關注的就是機器的動態(tài)上下線跟Leader選舉。
- 動態(tài)上下線:
比如在zookeeper服務器端有一個znode叫 /Configuration,那么集群中每一個機器啟動的時候都去這個節(jié)點下創(chuàng)建一個EPHEMERAL類型的節(jié)點,比如server1 創(chuàng)建 /Configuration/Server1,server2創(chuàng)建**/Configuration /Server1**,然后Server1和Server2都watch /Configuration 這個父節(jié)點,那么也就是這個父節(jié)點下數(shù)據(jù)或者子節(jié)點變化都會通知到該節(jié)點進行watch的客戶端。
- Leader選舉:
- 利用ZooKeeper的強一致性,能夠保證在分布式高并發(fā)情況下節(jié)點創(chuàng)建的全局唯一性,即:同時有多個客戶端請求創(chuàng)建 /Master 節(jié)點,最終一定只有一個客戶端請求能夠創(chuàng)建成功。利用這個特性,就能很輕易的在分布式環(huán)境中進行集群選舉了。
- 就是動態(tài)Master選舉。這就要用到 EPHEMERAL_SEQUENTIAL類型節(jié)點的特性了,這樣每個節(jié)點會
自動被編號。允許所有請求都能夠創(chuàng)建成功,但是得有個創(chuàng)建順序,每次選取序列號最小的那個機器作為Master 。
3 Leader選舉
ZooKeeper集群節(jié)點個數(shù)一定是奇數(shù)個,一般3個或者5個就OK。為避免集群群龍無首,一定要選個大哥出來當Leader。這是個高頻考點。
3.1 預備知識
3.1.1. 節(jié)點四種狀態(tài)。
- LOOKING:尋 找 Leader 狀態(tài)。當服務器處于該狀態(tài)時會認為當前集群中沒有 Leader,因此需要進入 Leader 選舉狀態(tài)。
- FOLLOWING:跟隨者狀態(tài)。處理客戶端的非事務請求,轉發(fā)事務請求給 Leader 服務器,參與事務請求 Proposal(提議) 的投票,參與 Leader 選舉投票。
- LEADING:領導者狀態(tài)。事務請求的唯一調度和處理者,保證集群事務處理的順序性,集群內部個服務器的調度者(管理follower,數(shù)據(jù)同步)。
- OBSERVING:觀察者狀態(tài)。3.0 版本以后引入的一個服務器角色,在不影響集群事務處理能力的基礎上提升集群的非事務處理能力,處理客戶端的非事務請求,轉發(fā)事務請求給 Leader 服務器,不參與任何形式的投票。
3.1.2 服務器ID
既Server id,一般在搭建ZK集群時會在myid文件中給每個節(jié)點搞個唯一編號,編號越大在Leader選擇算法中的權重越大,比如初始化啟動時就是根據(jù)服務器ID進行比較。
3.1.3 ZXID

ZooKeeper 采用全局遞增的事務 Id 來標識,所有 proposal(提議)在被提出的時候加上了ZooKeeper Transaction Id ,zxid是64位的Long類型,這是保證事務的順序一致性的關鍵。zxid中高32位表示紀元epoch,低32位表示事務標識xid。你可以認為zxid越大說明存儲數(shù)據(jù)越新。
- 每個leader都會具有不同的epoch值,表示一個紀元/朝代,用來標識 leader 周期。每個新的選舉開啟時都會生成一個新的epoch,新的leader產生的話epoch會自增,會將該值更新到所有的zkServer的zxid和epoch,
- xid是一個依次遞增的事務編號。數(shù)值越大說明數(shù)據(jù)越新,所有 proposal(提議)在被提出的時候加上了zxid,然后會依據(jù)數(shù)據(jù)庫的兩階段過程,首先會向其他的 server 發(fā)出事務執(zhí)行請求,如果超過半數(shù)的機器都能執(zhí)行并且能夠成功,那么就會開始執(zhí)行。
3.2 Leader選舉
Leader的選舉一般分為啟動時選舉跟Leader掛掉后的運行時選舉。
3.2.1 啟動時Leader選舉
我們以上面的5臺機器為例,只有超過半數(shù)以上,即最少啟動3臺服務器,集群才能正常工作。
- 服務器1啟動,發(fā)起一次選舉。
服務器1投自己一票。此時服務器1票數(shù)一票,不夠半數(shù)以上(3票),選舉無法完成,服務器1狀態(tài)保持為LOOKING。
- 服務器2啟動,再發(fā)起一次選舉。
服務器1和2分別投自己一票,此時服務器1發(fā)現(xiàn)服務器2的id比自己大,更改選票投給服務器2。此時服務器1票數(shù)0票,服務器2票數(shù)2票,不夠半數(shù)以上(3票),選舉無法完成。服務器1,2狀態(tài)保持LOOKING。
- 服務器3啟動,發(fā)起一次選舉。
與上面過程一樣,服務器1和2先投自己一票,然后因為服務器3id最大,兩者更改選票投給為服務器3。此次投票結果:服務器1為0票,服務器2為0票,服務器3為3票。此時服務器3的票數(shù)已經超過半數(shù)(3票),服務器3當選Leader。服務器1,2更改狀態(tài)為FOLLOWING,服務器3更改狀態(tài)為LEADING;
- 服務器4啟動,發(fā)起一次選舉。
此時服務器1、2、3已經不是LOOKING狀態(tài),不會更改選票信息,交換選票信息結果。服務器3為3票,服務器4為1票。此時服務器4服從多數(shù),更改選票信息為服務器3,服務器4并更改狀態(tài)為FOLLOWING。
- 服務器5啟動,發(fā)起一次選舉
同4一樣投票給3,此時服務器3一共5票,服務器5為0票。服務器5并更改狀態(tài)為FOLLOWING;
- 最終
Leader是服務器3,狀態(tài)為LEADING。其余服務器是Follower,狀態(tài)為FOLLOWING。
3.2.2 運行時Leader選舉
運行時候如果Master節(jié)點崩潰了會走恢復模式,新Leader選出前會暫停對外服務,大致可以分為四個階段 選舉、發(fā)現(xiàn)、同步、廣播。
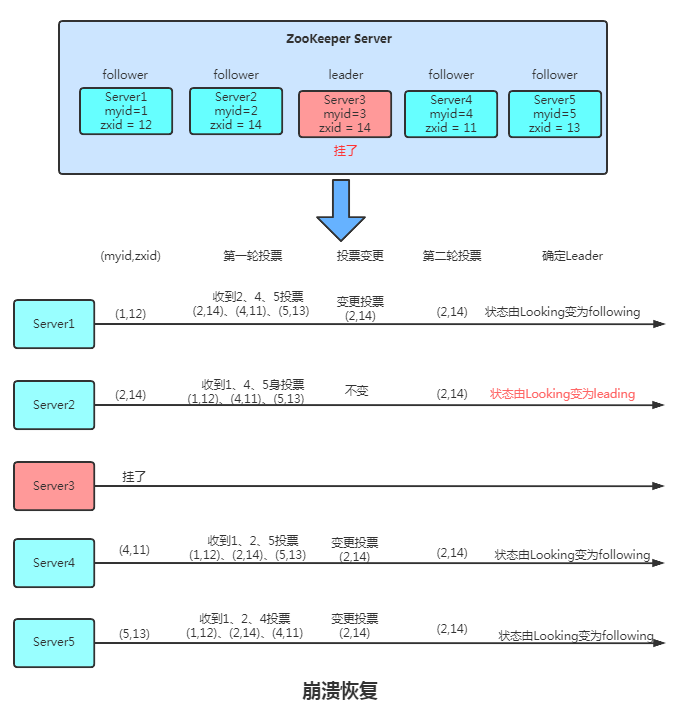
- 每個Server會發(fā)出一個投票,第一次都是投自己,其中投票信息 = (myid,ZXID)
- 收集來自各個服務器的投票
- 處理投票并重新投票,處理邏輯:優(yōu)先比較ZXID,然后比較myid。
- 統(tǒng)計投票,只要超過半數(shù)的機器接收到同樣的投票信息,就可以確定leader,注意epoch的增加跟同步。
- 改變服務器狀態(tài)Looking變?yōu)镕ollowing或Leading。
- 當 Follower 鏈接上 Leader 之后,Leader 服務器會根據(jù)自己服務器上最后被提交的 ZXID 和 Follower 上的 ZXID 進行比對,比對結果要么回滾,要么和 Leader 同步,保證集群中各個節(jié)點的事務一致。
- 集群恢復到廣播模式,開始接受客戶端的寫請求。
3.3 腦裂
腦裂問題是集群部署必須考慮的一點,比如在Hadoop跟Spark集群中。而ZAB為解決腦裂問題,要求集群內的節(jié)點數(shù)量為2N+1。當網絡分裂后,始終有一個集群的節(jié)點數(shù)量過半數(shù),而另一個節(jié)點數(shù)量小于N+1, 因為選舉Leader需要過半數(shù)的節(jié)點同意,所以我們可以得出如下結論:
有了過半機制,對于一個Zookeeper集群,要么沒有Leader,要沒只有1個Leader,這樣就避免了腦裂問題
4 一致性協(xié)議之 ZAB
建議先看下 淺談大數(shù)據(jù)中的2PC、3PC、Paxos、Raft、ZAB ,不然可能看的吃力。
4.1 ZAB 協(xié)議介紹
ZAB (Zookeeper Atomic Broadcast 原子廣播協(xié)議) 協(xié)議是為分布式協(xié)調服務ZooKeeper專門設計的一種支持崩潰恢復的一致性協(xié)議。基于該協(xié)議,ZooKeeper 實現(xiàn)了一種主從模式的系統(tǒng)架構來保持集群中各個副本之間的數(shù)據(jù)一致性。
分布式系統(tǒng)中l(wèi)eader負責外部客戶端的寫請求。follower服務器負責讀跟同步。這時需要解決倆問題。
- Leader 服務器是如何把數(shù)據(jù)更新到所有的Follower的。
- Leader 服務器突然間失效了,集群咋辦?
因此ZAB協(xié)議為了解決上面兩個問題而設計了兩種工作模式,整個 Zookeeper 就是在這兩個模式之間切換:
- 原子廣播模式:把數(shù)據(jù)更新到所有的follower。
- 崩潰恢復模式:Leader發(fā)生崩潰時,如何恢復。
4.2 原子廣播模式
你可以認為消息廣播機制是簡化版的 2PC協(xié)議,就是通過如下的機制保證事務的順序一致性的。
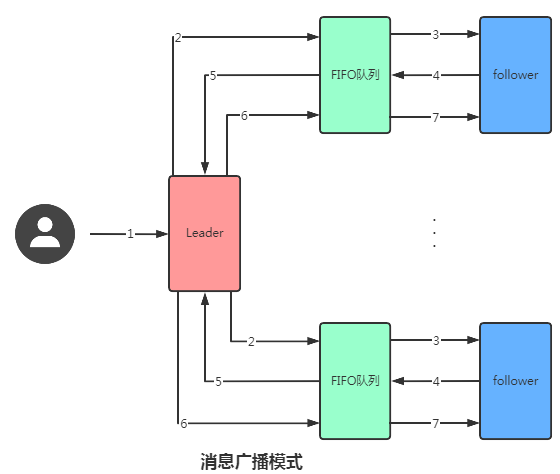
-
leader從客戶端收到一個寫請求后生成一個新的事務并為這個事務生成一個唯一的
ZXID, - leader將將帶有 zxid 的消息作為一個提案(proposal)分發(fā)給所有 FIFO隊列。
- FIFO隊列取出隊頭proposal給follower節(jié)點。
- 當 follower 接收到 proposal,先將 proposal 寫到硬盤,寫硬盤成功后再向 leader 回一個 ACK。
- FIFO隊列把ACK返回給Leader。
- 當leader收到超過一半以上的follower的ack消息,leader會進行commit請求,然后再給FIFO發(fā)送commit請求。
- 當follower收到commit請求時,會判斷該事務的ZXID是不是比歷史隊列中的任何事務的ZXID都小,如果是則提交,如果不是則等待比它更小的事務的commit(保證順序性)
4.3 崩潰恢復
消息廣播過程中,Leader 崩潰了還能保證數(shù)據(jù)一致嗎?當 Leader 崩潰會進入崩潰恢復模式。其實主要是對如下兩種情況的處理。
- Leader 在復制數(shù)據(jù)給所有 Follwer 之后崩潰,咋搞?
- Leader 在收到 Ack 并提交了自己,同時發(fā)送了部分 commit 出去之后崩潰咋辦?
針對此問題,ZAB 定義了 2 個原則:
-
ZAB 協(xié)議確保
執(zhí)行那些已經在 Leader 提交的事務最終會被所有服務器提交。 -
ZAB 協(xié)議確保
丟棄那些只在 Leader 提出/復制,但沒有提交的事務。
至于如何實現(xiàn)確保提交已經被 Leader 提交的事務,同時丟棄已經被跳過的事務呢?關鍵點就是依賴上面說到過的 ZXID了。
4.4 ZAB 特性
- 一致性保證
可靠提交(Reliable delivery) :如果一個事務 A 被一個server提交(committed)了,那么它最終一定會被所有的server提交
- 全局有序(Total order)
假設有A、B兩個事務,有一臺server先執(zhí)行A再執(zhí)行B,那么可以保證所有server上A始終都被在B之前執(zhí)行
- 因果有序(Causal order)
如果發(fā)送者在事務A提交之后再發(fā)送B,那么B必將在A之后執(zhí)行
- 高可用性
只要大多數(shù)(法定數(shù)量)節(jié)點啟動,系統(tǒng)就行正常運行
- 可恢復性
當節(jié)點下線后重啟,它必須保證能恢復到當前正在執(zhí)行的事務
4.5 ZAB 和 Paxos 對比
相同點:
- 兩者都存在一個類似于 Leader 進程的角色,由其負責協(xié)調多個 Follower 進程的運行.
- Leader 進程都會等待超過半數(shù)的 Follower 做出正確的反饋后,才會將一個提案進行提交.
- ZAB 協(xié)議中,每個 Proposal 中都包含一個 epoch 值來代表當前的 Leader周期,Paxos 中名字為 Ballot
不同點:
ZAB 用來構建高可用的分布式數(shù)據(jù)主備系統(tǒng)(Zookeeper),Paxos 是用來構建分布式一致性狀態(tài)機系統(tǒng)。
5 ZooKeeper 零散知識
5.1 常見指令
Zookeeper 有三種部署模式:
- 單機部署:一臺機器上運行。
- 集群部署:多臺機器運行。
- 偽集群部署:一臺機器啟動多個 Zookeeper 實例運行。
部署完畢后常見指令如下:
| 命令基本語法 | 功能描述 |
|---|---|
| help | 顯示所有操作命令 |
| ls path [watch] | 顯示所有操作命令 |
| ls path [watch] | 查看當前節(jié)點數(shù)據(jù)并能看到更新次數(shù)等數(shù)據(jù) |
| create |
普通創(chuàng)建, -s 含有序列, -e 臨時(重啟或者超時消失) |
| get path [watch] | 獲得節(jié)點的值 |
| set | 設置節(jié)點的具體值 |
| stat | 查看節(jié)點狀態(tài) |
| delete | 刪除節(jié)點 |
| rmr | 遞歸刪除節(jié)點 |
5.2 Zookeeper客戶端
5.2.1. Zookeeper原生客戶端
Zookeeper客戶端是異步的哦!需要引入CountDownLatch 來確保連接好了再做下面操作。Zookeeper原生api是不支持迭代式的創(chuàng)建跟刪除路徑的,具有如下弊端。
- 會話的連接是異步的;必須用到回調函數(shù) 。
- Watch需要重復注冊:看一次watch注冊一次 。
- Session重連機制:有時session斷開還需要重連接。
- 開發(fā)復雜性較高:開發(fā)相對來說比較瑣碎。
5.2.2. ZkClient
開源的zk客戶端,在原生API基礎上封裝,是一個更易于使用的zookeeper客戶端,做了如下優(yōu)化。
優(yōu)化一 、在session loss和session expire時自動創(chuàng)建新的ZooKeeper實例進行重連。優(yōu)化二、 將一次性watcher包裝為持久watcher。
5.2.3. Curator
開源的zk客戶端,在原生API基礎上封裝,apache頂級項目。是Netflix公司開源的一套Zookeeper客戶端框架。了解過Zookeeper原生API都會清楚其復雜度。Curator幫助我們在其基礎上進行封裝、實現(xiàn)一些開發(fā)細節(jié),包括接連重連、反復注冊Watcher和NodeExistsException等。目前已經作為Apache的頂級項目出現(xiàn),是最流行的Zookeeper客戶端之一。
5.2.4. Zookeeper圖形化客戶端工具
工具名叫ZooInspector,百度安裝教程即可。
5.3 ACL 權限控制機制
ACL全稱為Access Control List 即訪問控制列表,用于控制資源的訪問權限。zookeeper利用ACL策略控制節(jié)點的訪問權限,如節(jié)點數(shù)據(jù)讀寫、節(jié)點創(chuàng)建、節(jié)點刪除、讀取子節(jié)點列表、設置節(jié)點權限等。
5.4 Zookeeper使用注意事項
- 集群中機器的數(shù)量并不是越多越好,一個寫操作需要半數(shù)以上的節(jié)點ack,所以集群節(jié)點數(shù)越多,整個集群可以抗掛點的節(jié)點數(shù)越多(越可靠),但是吞吐量越差。集群的數(shù)量必須為奇數(shù)。
- zk是基于內存進行讀寫操作的,有時候會進行消息廣播,因此不建議在節(jié)點存取容量比較大的數(shù)據(jù)。
- dataDir目錄、dataLogDir兩個目錄會隨著時間推移變得龐大,容易造成硬盤滿了。建議自己編寫或使用自帶的腳本保留最新的n個文件。
- 默認最大連接數(shù) 默認為60,配置maxClientCnxns參數(shù),配置單個客戶端機器創(chuàng)建的最大連接數(shù)。
審核編輯 :李倩
-
文件系統(tǒng)
+關注
關注
0文章
285瀏覽量
19916 -
分布式
+關注
關注
1文章
903瀏覽量
74541 -
zookeeper
+關注
關注
0文章
33瀏覽量
3689
原文標題:5 ZooKeeper 零散知識
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
關于陶瓷電路板你不知道的事



求助關于論壇的選擇
「漲知識」關于LoRa擴頻技術,你知道多少?

關于定位系統(tǒng)技術你知道多少?
關于主干布線,你應該知道什么
電容6大特性參數(shù),你知道幾個?
詳解zookeeper的session管理機制





 工商網監(jiān)
工商網監(jiān)
評論