

雖然估計故障前的時間很有用,但更有價值的是描述預期發生的故障類型(根本原因)的信息。可以根據歷史故障數據對預測故障類型的模型進行訓練,但是,工程師通常會遇到各種故障場景缺乏故障數據的情況。在我的第三篇也是最后一篇博客中,我們將探討預測性維護中最關鍵且經常被忽略的組件之一:工作流故障以及知道如何預測它們。
以下是兩個可行的解決方案,團隊可以利用它們來阻止這種缺乏故障數據成為預測性維護實施過程中的致命缺陷:
生成樣本故障數據:故障模式影響分析 (FMEA) 等歷史上使用的工具為確定要模擬的故障提供了有用的起點。從這里開始,工程師可以在各種場景中將行為整合到模型中,通過調整溫度、流速或振動或添加突發故障來模擬故障。模擬時,場景會產生故障數據,這些數據可以被標記和存儲以供進一步分析。
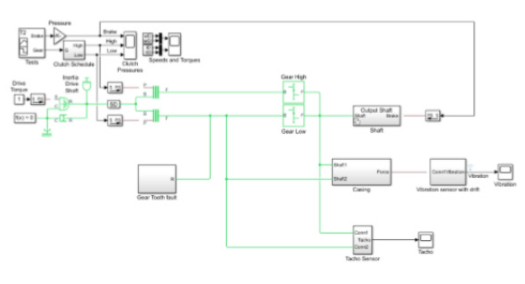
圖 1. 使用 Simulink 生成故障數據
了解可用數據:根據可用的傳感器,某些類型的故障可能需要同時查看多個傳感器以識別不良行為。但是查看來自數十或數百個傳感器的原始數據可能會令人生畏。在這種情況下,諸如主成分分析 (PCA) 等無監督學習技術(機器學習的一個分支)將原始傳感器數據轉換為低維表示。這些數據比高維原始數據更容易可視化和分析,使您能夠在未標記數據中找到有價值的模式和趨勢。即使不存在故障數據,操作數據也可能表明機器如何隨時間退化的趨勢,并估計組件的剩余使用壽命 (RUL)。
減少學習曲線的簡單步驟
工程師面臨的另一個常見障礙是對看似陌生和令人生畏的算法進行建模和測試。
希望減少這種學習曲線的工程師可以遵循以下三個簡單步驟:
定義目標:預先定義您的目標是什么(例如,更早地識別故障、更長的周期、減少停機時間),以及預測性維護算法將如何影響它們。作為早期步驟,構建一個可以測試算法并根據您的目標估計其性能的框架,以實現更快的設計迭代。這將確保在公平的競爭環境中比較所有不同的方法。
從小處著手:練習使用具有深入理解系統的項目,越簡單越好。例如,從組件級別而不是系統或子系統級別開始。這將減少需要調查的故障數量并縮短開發初始原型的時間。
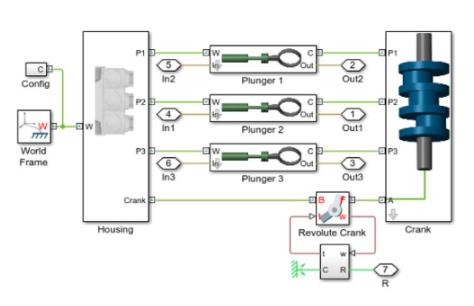
圖 2. 對三種類型的故障進行建模:氣缸泄漏、進氣口阻塞和軸承摩擦增加。
獲得信心:當您開始看到有希望的結果時,請使用團隊內的領域知識根據成本和嚴重程度預測不同的結果。在現有維護程序的背景下運行預測性維護模型,以了解模型在實踐中的工作原理。
總之,定義明確的目標,從小處著手,根據數據進行驗證,然后迭代直到對結果充滿信心。
審核編輯:郭婷
-
傳感器
+關注
關注
2564文章
52596瀏覽量
763781 -
工程師
+關注
關注
59文章
1589瀏覽量
69228
發布評論請先 登錄
非技術人員如何用n8n + DeepSeek打造AI自動化工作流?
預測性維護實戰:如何通過數據模型實現故障預警?

NX CAD軟件:數字化工作流程解決方案(CAD工作流程)

AI工作流自動化是做什么的
MVTRF:多視圖特征預測SSD故障

變頻器過流(OC)故障維修及案例分析

飛利浦與亞馬遜云科技擴展戰略合作,增強HealthSuite云服務能力并賦能生成式AI工作流
用CPLD控制ADS7229,工作流程是怎么樣的?
數據科學工作流原理
淺談無刷電機的工作流程





 工商網監
工商網監

評論