") 用于工業(yè)AI的Jetson AGX Xavier模塊
用于工業(yè)AI的Jetson AGX Xavier模塊
工業(yè)物聯(lián)網(wǎng)架構(gòu)師花了數(shù)年時(shí)間才得出結(jié)論,邊緣需要數(shù)據(jù)中心級(jí)的性能,以實(shí)現(xiàn)高效分析、提高安全性和降低網(wǎng)絡(luò)成本。在人工智能和機(jī)器學(xué)習(xí)領(lǐng)域,傳感器設(shè)備內(nèi)部或附近對(duì)高端處理能力的需求從一開始就很明顯。
考慮到即使是簡單的自主機(jī)器(我知道這是矛盾的說法)也需要大量的計(jì)算能力來運(yùn)行神經(jīng)網(wǎng)絡(luò)來執(zhí)行障礙物檢測、識(shí)別和避免等功能。例如,京東和菜鳥等公司生產(chǎn)的自動(dòng)送貨車需要大約每秒 30 兆次運(yùn)算 (TOPS) 的處理性能,而雅馬哈正在開發(fā)的自動(dòng)駕駛檢查無人機(jī)需要大約 20 兆次運(yùn)算 (TOPS) 的處理性能。
當(dāng)然,這對(duì)嵌入式和工業(yè)工程師提出了一個(gè)經(jīng)典的設(shè)計(jì)挑戰(zhàn):平衡每瓦性能。性能太低,應(yīng)用程序失敗。功耗太大,自主機(jī)器必須連接到持續(xù)的電源。
隨著NVIDIA 的 Jetson AGX Xavier 模塊的發(fā)布,這種情況正在改變。
服務(wù)器級(jí)性能,嵌入式功耗
Jetson AGX Xavier 核心的 Xavier SoC 包含大量異構(gòu)處理性能,適用于人工智能驅(qū)動(dòng)的機(jī)器人應(yīng)用程序,包括:
512 核 Volta GPU,帶有 64 個(gè) TensorCore
雙 NVDLA(NVIDIA 深度學(xué)習(xí)加速器)引擎
雙 7 路 VLIW 視覺加速器引擎
這代表 Jetson AGX 模塊的性能高達(dá) 32 TOPS,尺寸為 87 mm x 100 mm。如上圖所示,該芯片還包括一個(gè) 256 位 LPDDR4X 接口,能夠以 137 GBps 的速度將數(shù)據(jù)傳輸?shù)侥K上的 16 GB DRAM,用于與 AI 工作負(fù)載相關(guān)的頻繁讀寫。
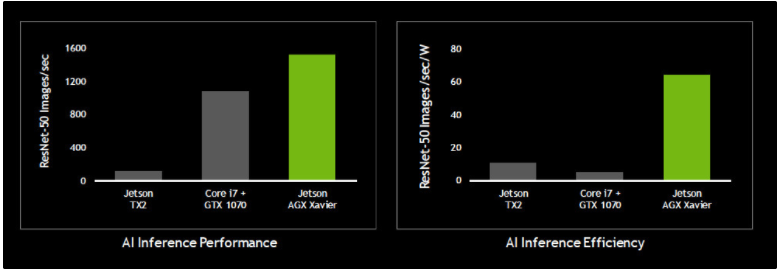
基本上,Jetson AGX Xavier 以嵌入式模塊形式提供服務(wù)器級(jí)性能。然而,同樣重要的是,該模塊的功耗僅為 10W,或與臺(tái)式風(fēng)扇差不多。用戶可將操作模式配置為 10W、15W 或 30W,NVIDIA 報(bào)告稱每瓦性能 (PPW) 的最佳點(diǎn)在 15W 左右。即使在那個(gè)水平(大約相當(dāng)于藍(lán)光播放器的功耗),Jetson AGX Xavier 在推理性能和能源效率方面也大大超過了其前身 Jetson TX2 和 Intel Core i7 + GTX 1070 顯卡。
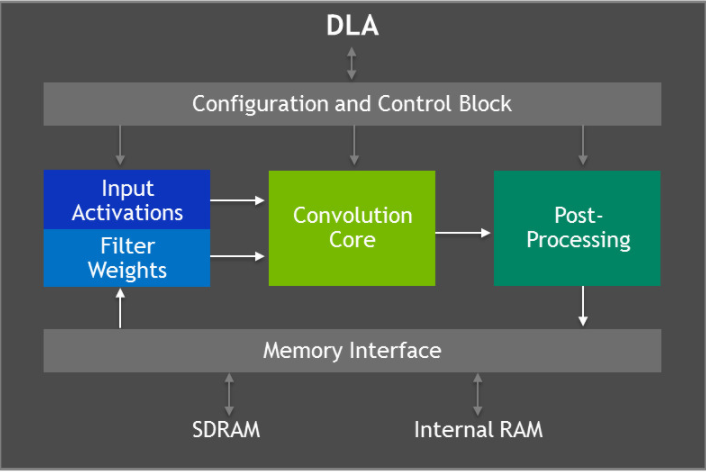
Jetson AGX Xavier:引擎蓋下
Jetson AGX Xavier 的多項(xiàng)功能可實(shí)現(xiàn)這種類型的每瓦性能,從基礎(chǔ)芯片架構(gòu)開始。雖然 SoC 上的每個(gè)內(nèi)核都有自己的內(nèi)存,但內(nèi)存是離散 SoC 模塊之間的零內(nèi)存復(fù)制。雖然 AGX Xavier 模塊確實(shí)通過外部 16 GB LPDDR4X DRAM 提供共享內(nèi)存,但片上數(shù)據(jù)只是通過管道傳遞到必要的處理核心。
架構(gòu)的異構(gòu)性也提高了效率,因?yàn)楣ぷ髫?fù)載可以在最適合任務(wù)的架構(gòu)上執(zhí)行。這方面的一個(gè)例子是片上加速引擎,它可以卸載 Volta GPU,以便它可以專注于更復(fù)雜或用戶定義的任務(wù)。例如,在以 8 位分辨率推斷固定功能卷積神經(jīng)網(wǎng)絡(luò) (CNN) 時(shí),NVDLA 引擎可提供高達(dá) 5 TOPS 的性能,以 16 位分辨率推斷 2.5 TFLOPS 時(shí),功耗在 0.5W 和 1.5W 之間。
同時(shí),Carmel CPU 內(nèi)核可以保留用于通用計(jì)算任務(wù)。
JetPack 簡化了深度學(xué)習(xí)編程的復(fù)雜性
Jetson AGX 系列運(yùn)行 Linux,這在工業(yè)嵌入式系統(tǒng)中變得越來越普遍。許多希望利用 Jetson AGX Xavier 性能的工業(yè)和嵌入式開發(fā)人員可能不太熟悉的是對(duì) GPU 和/或深度學(xué)習(xí)加速器進(jìn)行編程。幸運(yùn)的是,NVIDIA JetPack 4.1.1 軟件開發(fā)套件 (SDK)在CUDA Toolkit中提供了一攬子 API、嵌入式庫以及與常用語言的集成,因此您無需了解如何編程 GPU對(duì) GPU 進(jìn)行編程。
最新JetPack版本中的一些軟件工具包括:
Linux For Tegra R31.0.1 (K4.9)
CUDA 工具包 10.0
cuDNN 7.3
張量RT 5.0 GA
OpenCV 3.3.1
OpenGL 4.6 / GLES 3.2
伏爾甘 1.1
多媒體 API R31.1
阿格斯 0.97 相機(jī) API
TensorRT 5.0 包中提供的 API 也簡化了對(duì) DLA 進(jìn)行編程以執(zhí)行神經(jīng)網(wǎng)絡(luò)工作負(fù)載。例如,_setDeviceType() 和 setDefaultDeviceType() 命令可用于在 GPU 或任一 DLA 上執(zhí)行特定的神經(jīng)網(wǎng)絡(luò)層或?qū)樱?_allowGPUFallback() 這樣的命令可讓工作負(fù)載在 DLA 不支持的情況下恢復(fù)到 GPU 。
此外,DeepStream 3.0 SDK 支持 Jetson AGX Xavier,該 SDK 利用 TensorRT、CUDA、多媒體和成像 API 來加速視頻分析應(yīng)用程序的開發(fā)。
當(dāng)然,低級(jí) CUDA 編程是另一種選擇。
審核編輯:郭婷
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4773瀏覽量
100890 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5013瀏覽量
103246 -
gpu
+關(guān)注
關(guān)注
28文章
4752瀏覽量
129057
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
NVIDIA發(fā)布小巧高性價(jià)比的Jetson Orin Nano Super開發(fā)者套件
初創(chuàng)公司借助NVIDIA Metropolis和Jetson提高生產(chǎn)線效率
使用NVIDIA Jetson打造機(jī)器人導(dǎo)盲犬
用于工業(yè)以太網(wǎng)PHY的AM2x評(píng)估模塊附加板用戶指南

GPU計(jì)算主板學(xué)習(xí)資料第735篇:基于3U VPX的AGX Xavier GPU計(jì)算主板 信號(hào)計(jì)算主板 視頻處理 相機(jī)信號(hào)
fx3系列的硬件主要由什么組成
新品發(fā)布 | 合眾恒躍發(fā)布多款無人機(jī)智能飛控產(chǎn)品搭載英偉達(dá)Jetson模塊,賦能低空經(jīng)濟(jì)新質(zhì)生產(chǎn)力

瑞薩電子推出Reality AI Explorer Tier,用于開發(fā)AI與TinyML解決方案
AC/DC電源模塊:應(yīng)用于工業(yè)自動(dòng)化領(lǐng)域

除英偉達(dá)Jetson系列外,AI邊緣計(jì)算盒子還能搭載哪些算力芯片
研華:AI視覺檢測+AMR精準(zhǔn)控制,激發(fā)智能制造新動(dòng)力
人形機(jī)器人主板:jetson orin nx核心模塊與SOM-7583核心模塊結(jié)合在一塊主板上

AIDI工業(yè)AI視覺檢測軟件介紹
NanoEdge AI的技術(shù)原理、應(yīng)用場景及優(yōu)勢
NVIDIA Jetson為嵌入式計(jì)算領(lǐng)域探索AI可能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論