 Linux內存管理的基礎知識科普
Linux內存管理的基礎知識科普
Linux的內存管理可謂是學好Linux的必經之路,也是Linux的關鍵知識點,有人說打通了內存管理的知識,也就打通了Linux的任督二脈,這一點不夸張。有人問網上有很多Linux內存管理的內容,為什么還要看你這一篇,這正是我寫此文的原因,網上碎片化的相關知識點大都是東拼西湊,先不說正確性與否,就連基本的邏輯都沒有搞清楚,我可以負責任的說Linux內存管理只需要看此文一篇就可以讓你入Linux內核的大門,省去你東找西找的時間,讓你形成內存管理知識的閉環。
文章比較長,做好準備,深呼吸,讓我們一起打開Linux內核的大門!
Linux內存管理之CPU訪問內存的過程
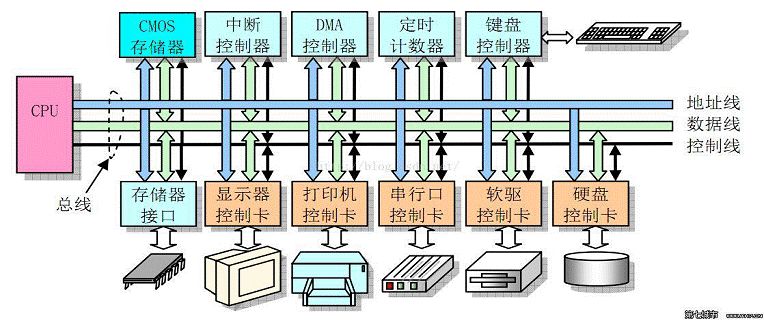
我喜歡用圖的方式來說明問題,簡單直接:
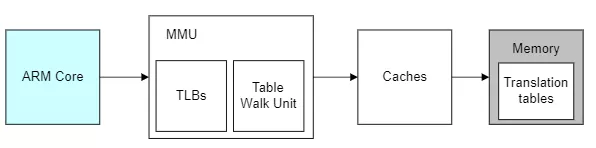
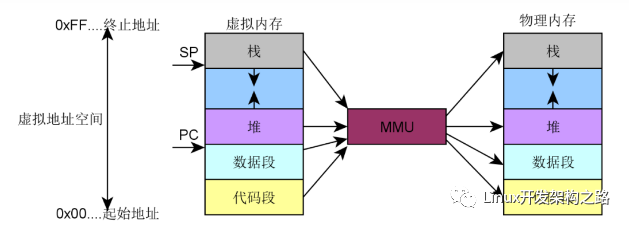
藍色部分是cpu,灰色部分是內存,白色部分就是cpu訪問內存的過程,也是地址轉換的過程。在解釋地址轉換的本質前我們先理解下幾個概念:
- TLB:MMU工作的過程就是查詢頁表的過程。如果把頁表放在內存中查詢的時候開銷太大,因此為了提高查找效率,專門用一小片訪問更快的區域存放地址轉換條目。(當頁表內容有變化的時候,需要清除TLB,以防止地址映射出錯。)
- Caches:cpu和內存之間的緩存機制,用于提高訪問速率,armv8架構的話上圖的caches其實是L2 Cache,這里就不做進一步解釋了。
虛擬地址轉換為物理地址的本質
我們知道內核中的尋址空間大小是由CONFIG_ARM64_VA_BITS控制的,這里以48位為例,ARMv8中,Kernel Space的頁表基地址存放在TTBR1_EL1寄存器中,User Space頁表基地址存放在TTBR0_EL0寄存器中,其中內核地址空間的高位為全1,(0xFFFF0000_00000000 ~ 0xFFFFFFFF_FFFFFFFF),用戶地址空間的高位為全0,(0x00000000_00000000 ~ 0x0000FFFF_FFFFFFFF)
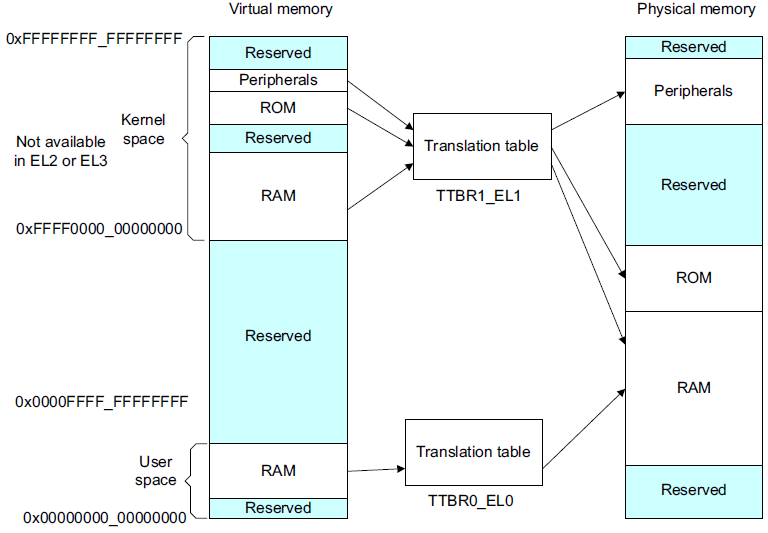
有了宏觀概念,下面我們以內核態尋址過程為例看下是如何把虛擬地址轉換為物理地址的。
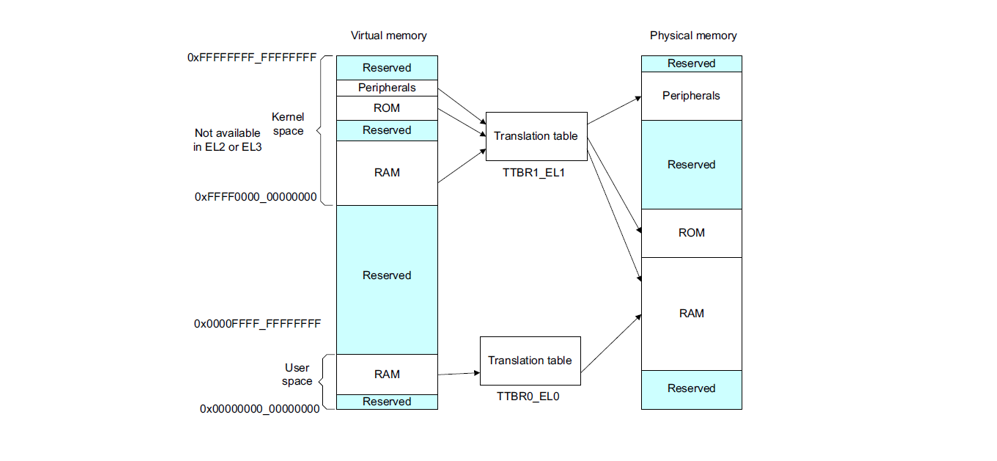
我們知道linux采用了分頁機制,通常采用四級頁表,頁全局目錄(PGD),頁上級目錄(PUD),頁中間目錄(PMD),頁表(PTE)。如下:
- MMU根據虛擬地址的最高位判斷用哪個頁表基地址做為訪問的起點。最高位是0時,使用TTBR0_EL0作為起點,表示訪問用戶空間地址;最高位時1時,使用TTBR1_EL1作為起點,表示訪問內核空間地址。MMU從相應的頁表基地址寄存器TTBR0_EL0或者TTBR1_EL1,獲取PGD頁全局目錄基地址。
-
找到PGD后,從虛擬地址中找到PGD index,通過PGD index找到頁上級目錄PUD基地址。
-
找到PUD后,從虛擬地址中找到PUD index,通過PUD index找到頁中間目錄PMD基地址。
-
找到PMD后,從虛擬地址中找到PDM index,通過PMD index找到頁表項PTE基地址。
-
找到PTE后,從虛擬地址中找到PTE index,通過PTE index找到頁表項PTE。
-
從頁表項PTE中取出物理頁幀號PFN,然后加上頁內偏移VA[11,0],就組成了最終的物理地址PA。
整個過程是比較機械的,每次轉換先獲取物理頁基地址,再從線性地址中獲取索引,合成物理地址后再訪問內存。不管是頁表還是要訪問的數據都是以頁為單位存放在主存中的,因此每次訪問內存時都要先獲得基址,再通過索引(或偏移)在頁內訪問數據,因此可以將線性地址看作是若干個索引的集合。
Linux內存初始化
有了armv8架構訪問內存的理解,我們來看下linux在內存這塊的初始化就更容易理解了。
創建啟動頁表:
在匯編代碼階段的head.S文件中,負責創建映射關系的函數是create_page_tables。create_page_tables函數負責identity mapping和kernel image mapping。
- identity map:是指把idmap_text區域的物理地址映射到相等的虛擬地址上,這種映射完成后,其虛擬地址等于物理地址。idmap_text區域都是一些打開MMU相關的代碼。
- kernel image map:將kernel運行需要的地址(kernel txt、rodata、data、bss等等)進行映射。
arch/arm64/kernel/head.S:
ENTRY(stext)
blpreserve_boot_args
blel2_setup//DroptoEL1,w0=cpu_boot_mode
adrpx23,__PHYS_OFFSET
andx23,x23,MIN_KIMG_ALIGN-1//KASLRoffset,defaultsto0
blset_cpu_boot_mode_flag
bl__create_page_tables
/*
*ThefollowingcallsCPUsetupcode,seearch/arm64/mm/proc.Sfor
*details.
*Onreturn,theCPUwillbereadyfortheMMUtobeturnedonand
*theTCRwillhavebeenset.
*/
bl__cpu_setup//initialiseprocessor
b__primary_switch
ENDPROC(stext)
__create_page_tables主要執行的就是identity map和kernel image map:
__create_page_tables:
......
create_pgd_entryx0,x3,x5,x6
movx5,x3//__pa(__idmap_text_start)
adr_lx6,__idmap_text_end//__pa(__idmap_text_end)
create_block_mapx0,x7,x3,x5,x6
/*
*Mapthekernelimage(startingwithPHYS_OFFSET).
*/
adrpx0,swapper_pg_dir
mov_qx5,KIMAGE_VADDR+TEXT_OFFSET//compiletime__va(_text)
addx5,x5,x23//addKASLRdisplacement
create_pgd_entryx0,x5,x3,x6
adrpx6,_end//runtime__pa(_end)
adrpx3,_text//runtime__pa(_text)
subx6,x6,x3//_end-_text
addx6,x6,x5//runtime__va(_end)
create_block_mapx0,x7,x3,x5,x6
......
其中調用create_pgd_entry進行PGD及所有中間level(PUD, PMD)頁表的創建,調用create_block_map進行PTE頁表的映射。關于四級頁表的關系如下圖所示,這里就不進一步解釋了。
匯編結束后的內存映射關系如下圖所示:
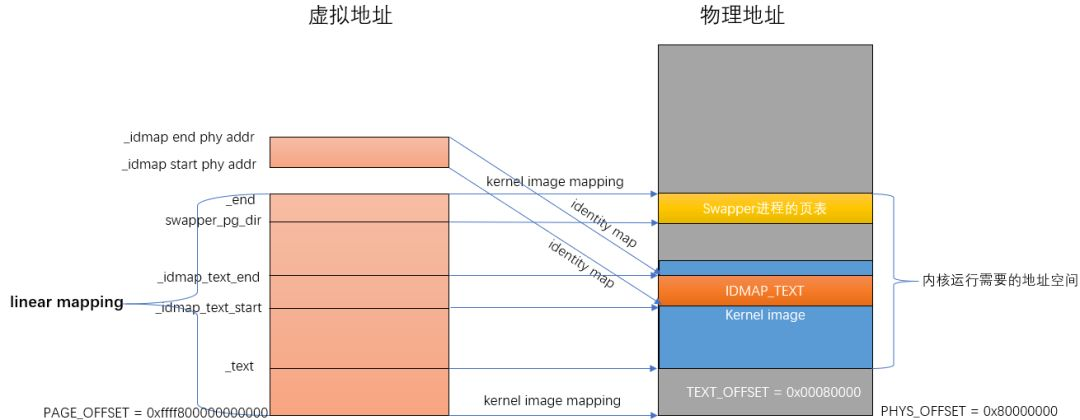
等內存初始化后就可以進入真正的內存管理了,初始化我總結了一下,大體分為四步:
- 物理內存進系統前
- 用memblock模塊來對內存進行管理
- 頁表映射
- zone初始化
Linux是如何組織物理內存的?
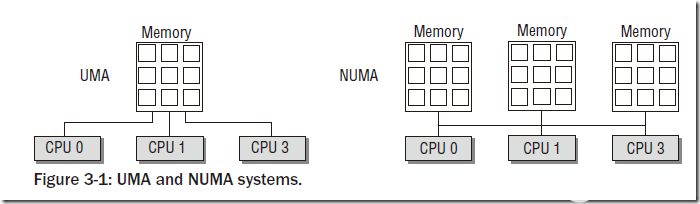
- node目前計算機系統有兩種體系結構:
- 非一致性內存訪問 NUMA(Non-Uniform Memory Access)意思是內存被劃分為各個node,訪問一個node花費的時間取決于CPU離這個node的距離。每一個cpu內部有一個本地的node,訪問本地node時間比訪問其他node的速度快
- 一致性內存訪問 UMA(Uniform Memory Access)也可以稱為SMP(Symmetric Multi-Process)對稱多處理器。意思是所有的處理器訪問內存花費的時間是一樣的。也可以理解整個內存只有一個node。
- zone
ZONE的意思是把整個物理內存劃分為幾個區域,每個區域有特殊的含義
- page
代表一個物理頁,在內核中一個物理頁用一個struct page表示。
- page frame
為了描述一個物理page,內核使用struct page結構來表示一個物理頁。假設一個page的大小是4K的,內核會將整個物理內存分割成一個一個4K大小的物理頁,而4K大小物理頁的區域我們稱為page frame
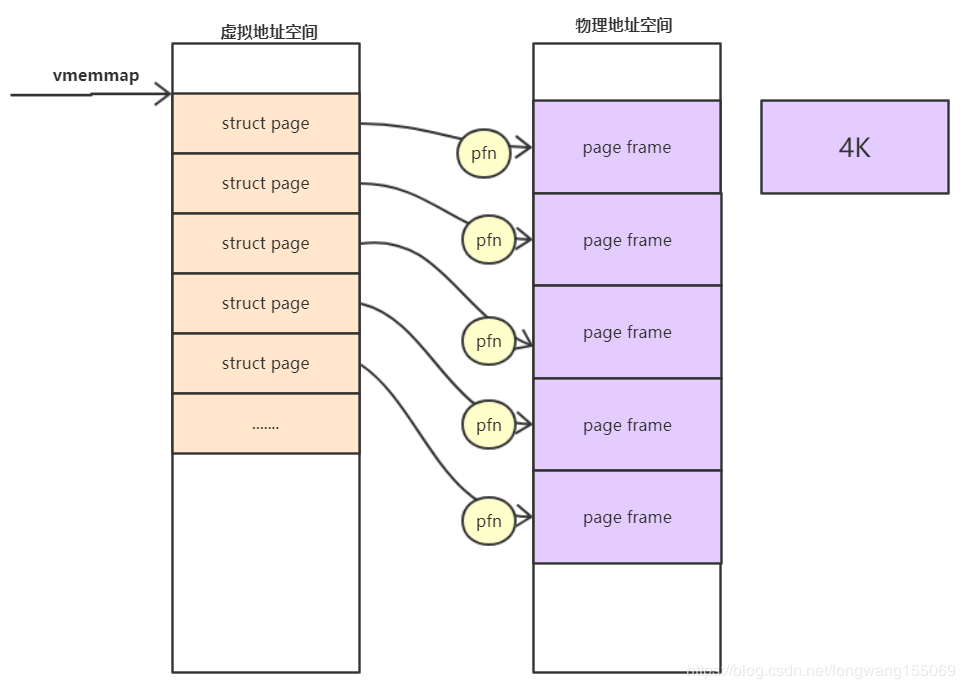
- page frame num(pfn)
pfn是對每個page frame的編號。故物理地址和pfn的關系是:
物理地址>>PAGE_SHIFT = pfn
- pfn和page的關系
內核中支持了好幾個內存模型:CONFIG_FLATMEM(平坦內存模型)CONFIG_DISCONTIGMEM(不連續內存模型)CONFIG_SPARSEMEM_VMEMMAP(稀疏的內存模型)目前ARM64使用的稀疏的類型模式。
系統啟動的時候,內核會將整個struct page映射到內核虛擬地址空間vmemmap的區域,所以我們可以簡單的認為struct page的基地址是vmemmap,則:
vmemmap+pfn的地址就是此struct page對應的地址。
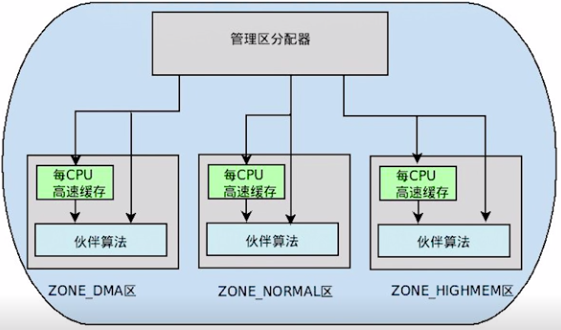
Linux分區頁框分配器
頁框分配在內核里的機制我們叫做分區頁框分配器(zoned page frame allocator),在linux系統中,分區頁框分配器管理著所有物理內存,無論你是內核還是進程,都需要請求分區頁框分配器,這時才會分配給你應該獲得的物理內存頁框。當你所擁有的頁框不再使用時,你必須釋放這些頁框,讓這些頁框回到管理區頁框分配器當中。
有時候目標管理區不一定有足夠的頁框去滿足分配,這時候系統會從另外兩個管理區中獲取要求的頁框,但這是按照一定規則去執行的,如下:
- 如果要求從DMA區中獲取,就只能從ZONE_DMA區中獲取。
- 如果沒有規定從哪個區獲取,就按照順序從 ZONE_NORMAL -> ZONE_DMA 獲取。
- 如果規定從HIGHMEM區獲取,就按照順序從 ZONE_HIGHMEM -> ZONE_NORMAL -> ZONE_DMA 獲取。
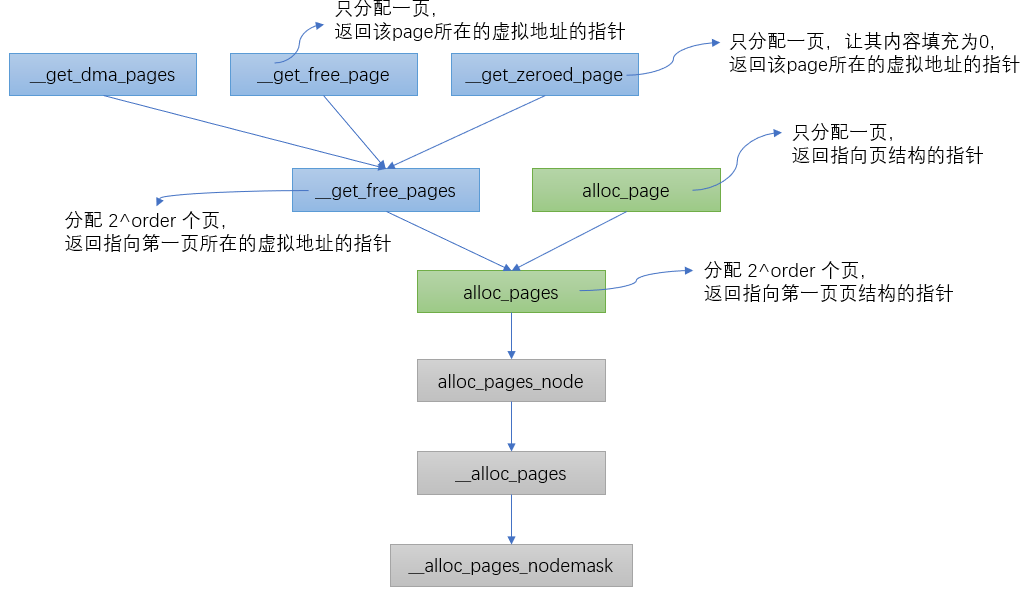
內核中根據不同的分配需求有6個函數接口來請求頁框,最終都會調用到__alloc_pages_nodemask。
structpage*
__alloc_pages_nodemask(gfp_tgfp_mask,unsignedintorder,intpreferred_nid,
nodemask_t*nodemask)
{
page=get_page_from_freelist(alloc_mask,order,alloc_flags,&ac);//fastpath分配頁面:從pcp(per_cpu_pages)和伙伴系統中正常的分配內存空間
......
page=__alloc_pages_slowpath(alloc_mask,order,&ac);//slowpath分配頁面:如果上面沒有分配到空間,調用下面函數慢速分配,允許等待和回收
......
}
在頁面分配時,有兩種路徑可以選擇,如果在快速路徑中分配成功了,則直接返回分配的頁面;快速路徑分配失敗則選擇慢速路徑來進行分配。總結如下:
- 正常分配(或叫快速分配):
- 如果分配的是單個頁面,考慮從per CPU緩存中分配空間,如果緩存中沒有頁面,從伙伴系統中提取頁面做補充。
- 分配多個頁面時,從指定類型中分配,如果指定類型中沒有足夠的頁面,從備用類型鏈表中分配。最后會試探保留類型鏈表。
- 慢速(允許等待和頁面回收)分配:
- 當上面兩種分配方案都不能滿足要求時,考慮頁面回收、殺死進程等操作后在試。
Linux頁框分配器之伙伴算法
staticstructpage*
get_page_from_freelist(gfp_tgfp_mask,unsignedintorder,intalloc_flags,
conststructalloc_context*ac)
{
for_next_zone_zonelist_nodemask(zone,z,ac->zonelist,ac->high_zoneidx,ac->nodemask)
{
if(!zone_watermark_fast(zone,order,mark,ac_classzone_idx(ac),alloc_flags))
{
ret=node_reclaim(zone->zone_pgdat,gfp_mask,order);
switch(ret){
caseNODE_RECLAIM_NOSCAN:
continue;
caseNODE_RECLAIM_FULL:
continue;
default:
if(zone_watermark_ok(zone,order,mark,ac_classzone_idx(ac),alloc_flags))
gototry_this_zone;
continue;
}
}
try_this_zone://本zone正常水位
page=rmqueue(ac->preferred_zoneref->zone,zone,order,gfp_mask,alloc_flags,ac->migratetype);
}
returnNULL;
}
首先遍歷當前zone,按照HIGHMEM->NORMAL的方向進行遍歷,判斷當前zone是否能夠進行內存分配的條件是首先判斷free memory是否滿足low water mark水位值,如果不滿足則進行一次快速的內存回收操作,然后再次檢測是否滿足low water mark,如果還是不能滿足,相同步驟遍歷下一個zone,滿足的話進入正常的分配情況,即rmqueue函數,這也是伙伴系統的核心。
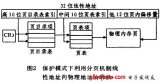
Buddy 分配算法
在看函數前,我們先看下算法,因為我一直認為有了“道”的理解才好進一步理解“術”。

假設這是一段連續的頁框,陰影部分表示已經被使用的頁框,現在需要申請一個連續的5個頁框。這個時候,在這段內存上不能找到連續的5個空閑的頁框,就會去另一段內存上去尋找5個連續的頁框,這樣子,久而久之就形成了頁框的浪費。為了避免出現這種情況,Linux內核中引入了伙伴系統算法(Buddy system)。把所有的空閑頁框分組為11個塊鏈表,每個塊鏈表分別包含大小為1,2,4,8,16,32,64,128,256,512和1024個連續頁框的頁框塊。最大可以申請1024個連續頁框,對應4MB大小的連續內存。每個頁框塊的第一個頁框的物理地址是該塊大小的整數倍,如圖:
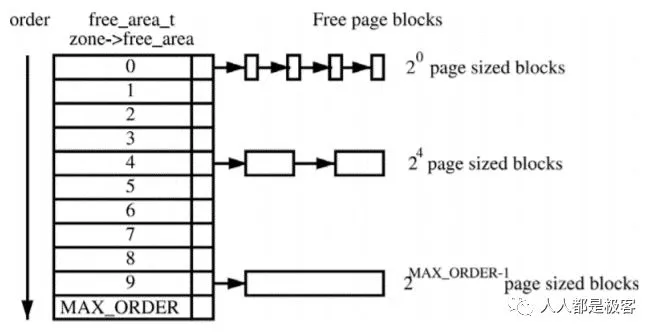
假設要申請一個256個頁框的塊,先從256個頁框的鏈表中查找空閑塊,如果沒有,就去512個頁框的鏈表中找,找到了則將頁框塊分為2個256個頁框的塊,一個分配給應用,另外一個移到256個頁框的鏈表中。如果512個頁框的鏈表中仍沒有空閑塊,繼續向1024個頁框的鏈表查找,如果仍然沒有,則返回錯誤。頁框塊在釋放時,會主動將兩個連續的頁框塊合并為一個較大的頁框塊。
從上面可以知道Buddy算法一直在對頁框做拆開合并拆開合并的動作。Buddy算法牛逼就牛逼在運用了世界上任何正整數都可以由2^n的和組成。這也是Buddy算法管理空閑頁表的本質。空閑內存的信息我們可以通過以下命令獲取:

也可以通過echo m > /proc/sysrq-trigger來觀察buddy狀態,與/proc/buddyinfo的信息是一致的:
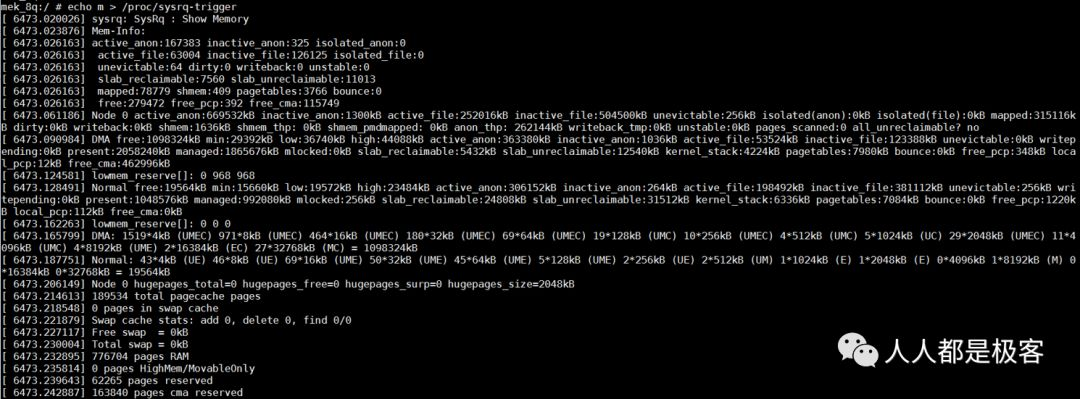
Buddy 分配函數
staticinline
structpage*rmqueue(structzone*preferred_zone,
structzone*zone,unsignedintorder,
gfp_tgfp_flags,unsignedintalloc_flags,
intmigratetype)
{
if(likely(order==0)){//如果order=0則從pcp中分配
page=rmqueue_pcplist(preferred_zone,zone,order,gfp_flags,migratetype);
}
do{
page=NULL;
if(alloc_flags&ALLOC_HARDER){//如果分配標志中設置了ALLOC_HARDER,則從free_list[MIGRATE_HIGHATOMIC]的鏈表中進行頁面分配
page=__rmqueue_smallest(zone,order,MIGRATE_HIGHATOMIC);
}
if(!page)//前兩個條件都不滿足,則在正常的free_list[MIGRATE_*]中進行分配
page=__rmqueue(zone,order,migratetype);
}while(page&&check_new_pages(page,order));
......
}
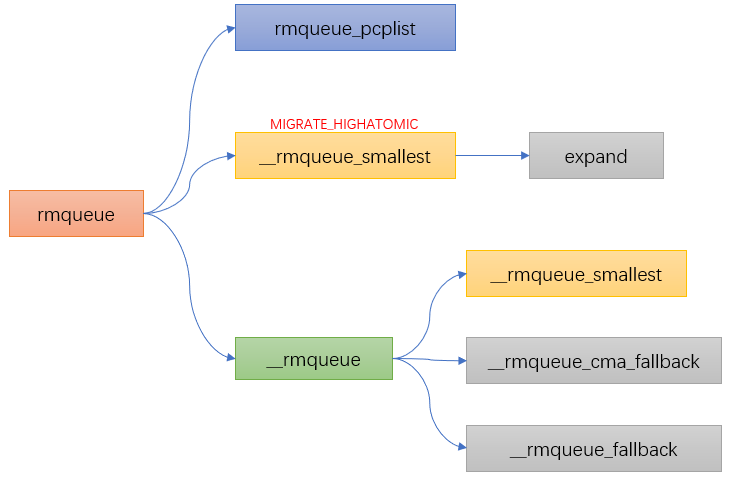
Linux分區頁框分配器之水位
我們講頁框分配器的時候講到了快速分配和慢速分配,其中伙伴算法是在快速分配里做的,忘記的小伙伴我們再看下:
staticstructpage*
get_page_from_freelist(gfp_tgfp_mask,unsignedintorder,intalloc_flags,
conststructalloc_context*ac)
{
for_next_zone_zonelist_nodemask(zone,z,ac->zonelist,ac->high_zoneidx,ac->nodemask)
{
if(!zone_watermark_fast(zone,order,mark,ac_classzone_idx(ac),alloc_flags))
{
ret=node_reclaim(zone->zone_pgdat,gfp_mask,order);
switch(ret){
caseNODE_RECLAIM_NOSCAN:
continue;
caseNODE_RECLAIM_FULL:
continue;
default:
if(zone_watermark_ok(zone,order,mark,ac_classzone_idx(ac),alloc_flags))
gototry_this_zone;
continue;
}
}
try_this_zone://本zone正常水位
page=rmqueue(ac->preferred_zoneref->zone,zone,order,gfp_mask,alloc_flags,ac->migratetype);
}
returnNULL;
}
可以看到在進行伙伴算法分配前有個關于水位的判斷,今天我們就看下水位的概念。
簡單的說在使用分區頁面分配器中會將可以用的free pages與zone里的水位(watermark)進行比較。
水位初始化
-
nr_free_buffer_pages 是獲取ZONE_DMA和ZONE_NORMAL區中高于high水位的總頁數nr_free_buffer_pages = managed_pages - high_pages
-
min_free_kbytes 是總的min大小,min_free_kbytes = 4 * sqrt(lowmem_kbytes)
-
setup_per_zone_wmarks 根據總的min值,再加上各個zone在總內存中的占比,然后通過do_div就計算出他們各自的min值,進而計算出各個zone的水位大小。min,low,high的關系如下:low = min *125%;
-
high = min * 150%
-
minhigh = 46
-
setup_per_zone_lowmem_reserve 當從Normal失敗后,會嘗試從DMA申請分配,通過lowmem_reserve[DMA],限制來自Normal的分配請求。其值可以通過/proc/sys/vm/lowmem_reserve_ratio來修改。
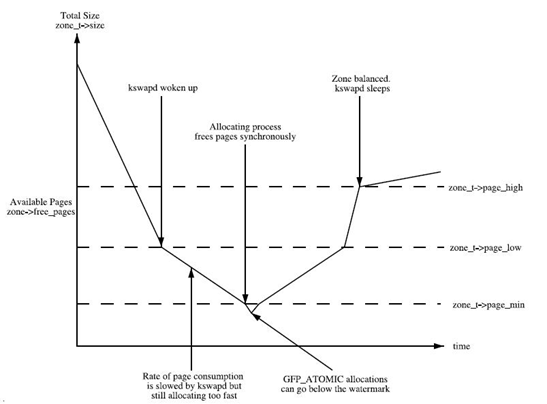
從這張圖可以看出:
- 如果空閑頁數目min值,則該zone非常缺頁,頁面回收壓力很大,應用程序寫內存操作就會被阻塞,直接在應用程序的進程上下文中進行回收,即direct reclaim。
- 如果空閑頁數目小于low值,kswapd線程將被喚醒,并開始釋放回收頁面。
- 如果空閑頁面的值大于high值,則該zone的狀態很完美, kswapd線程將重新休眠。
Linux頁框分配器之內存碎片化整理
什么是內存碎片化
Linux物理內存碎片化包括兩種:內部碎片化和外部碎片化。
- 內部碎片化:
指分配給用戶的內存空間中未被使用的部分。例如進程需要使用3K bytes物理內存,于是向系統申請了大小等于3Kbytes的內存,但是由于Linux內核伙伴系統算法最小顆粒是4K bytes,所以分配的是4Kbytes內存,那么其中1K bytes未被使用的內存就是內存內碎片。
- 外部碎片化:
指系統中無法利用的小內存塊。例如系統剩余內存為16K bytes,但是這16K bytes內存是由4個4K bytes的頁面組成,即16K內存物理頁幀號#1不連續。在系統剩余16K bytes內存的情況下,系統卻無法成功分配大于4K的連續物理內存,該情況就是內存外碎片導致。
碎片化整理算法
Linux內存對碎片化的整理算法主要應用了內核的頁面遷移機制,是一種將可移動頁面進行遷移后騰出連續物理內存的方法。
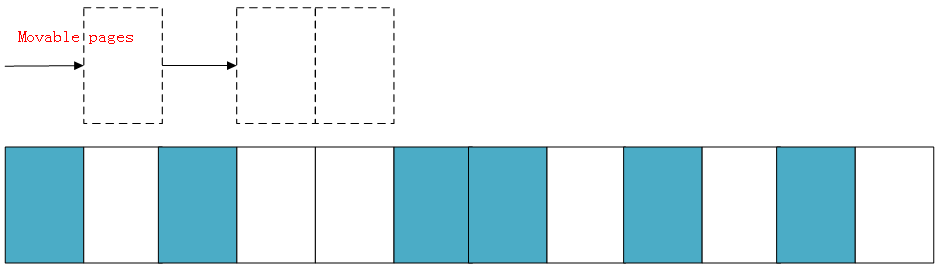
假設存在一個非常小的內存域如下:

藍色表示空閑的頁面,白色表示已經被分配的頁面,可以看到如上內存域的空閑頁面(藍色)非常零散,無法分配大于兩頁的連續物理內存。
下面演示一下內存規整的簡化工作原理,內核會運行兩個獨立的掃描動作:第一個掃描從內存域的底部開始,一邊掃描一邊將已分配的可移動(MOVABLE)頁面記錄到一個列表中:
另外第二掃描是從內存域的頂部開始,掃描可以作為頁面遷移目標的空閑頁面位置,然后也記錄到一個列表里面:
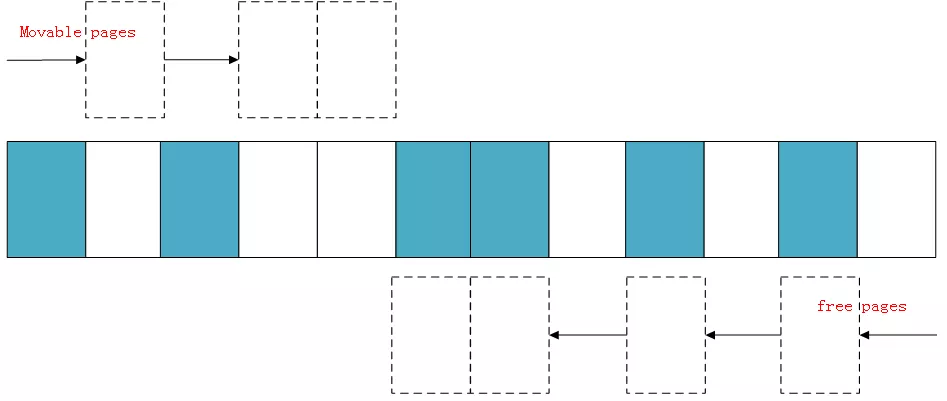
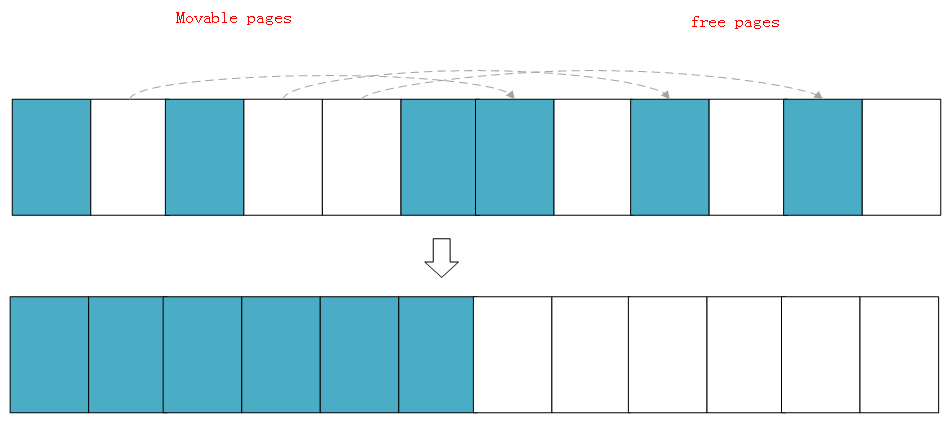
等兩個掃描在域中間相遇,意味著掃描結束,然后將左邊掃描得到的已分配的頁面遷移到右邊空閑的頁面中,左邊就形成了一段連續的物理內存,完成頁面規整。
碎片化整理的三種方式
staticstructpage*
__alloc_pages_direct_compact(gfp_tgfp_mask,unsignedintorder,
unsignedintalloc_flags,conststructalloc_context*ac,
enumcompact_priorityprio,enumcompact_result*compact_result)
{
structpage*page;
unsignedintnoreclaim_flag;
if(!order)
returnNULL;
noreclaim_flag=memalloc_noreclaim_save();
*compact_result=try_to_compact_pages(gfp_mask,order,alloc_flags,ac,
prio);
memalloc_noreclaim_restore(noreclaim_flag);
if(*compact_result<=?COMPACT_INACTIVE)
??returnNULL;
count_vm_event(COMPACTSTALL);
page=get_page_from_freelist(gfp_mask,order,alloc_flags,ac);
if(page){
structzone*zone=page_zone(page);
zone->compact_blockskip_flush=false;
compaction_defer_reset(zone,order,true);
count_vm_event(COMPACTSUCCESS);
returnpage;
}
count_vm_event(COMPACTFAIL);
cond_resched();
returnNULL;
}
在linux內核里一共有3種方式可以碎片化整理,我們總結如下:
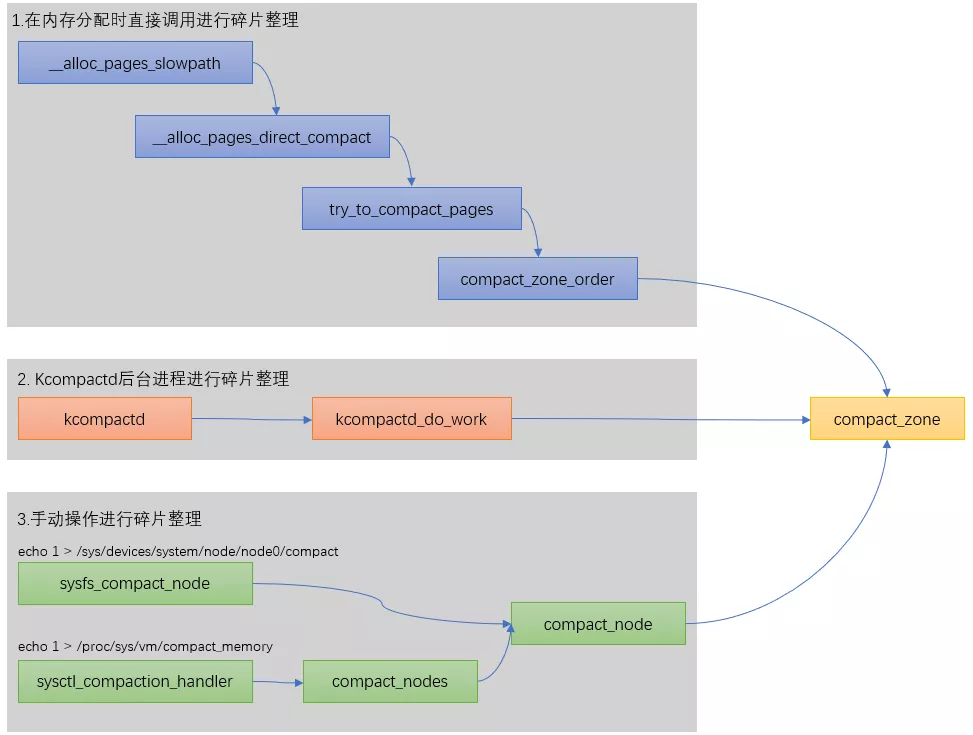
Linux slab分配器
在Linux中,伙伴系統是以頁為單位分配內存。但是現實中很多時候卻以字節為單位,不然申請10Bytes內存還要給1頁的話就太浪費了。slab分配器就是為小內存分配而生的。slab分配器分配內存以Byte為單位。但是slab分配器并沒有脫離伙伴系統,而是基于伙伴系統分配的大內存進一步細分成小內存分配。
他們之間的關系可以用一張圖來描述:
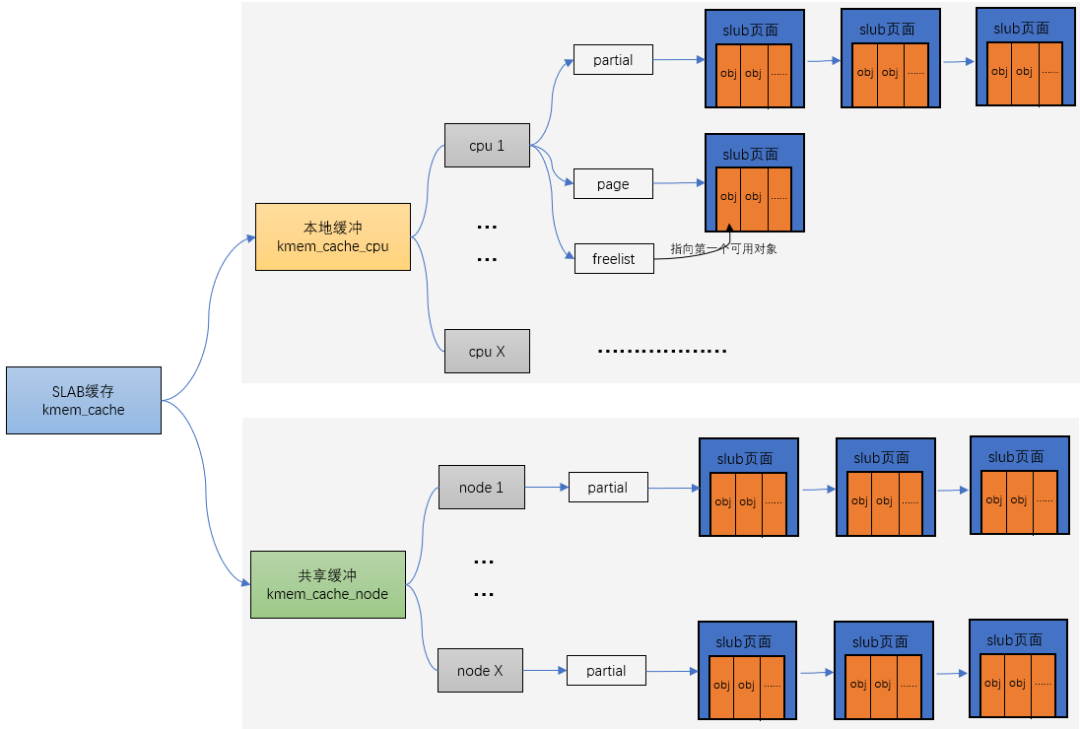
流程分析
kmem_cache_alloc 主要四步:
- 先從 kmem_cache_cpu->freelist中分配,如果freelist為null
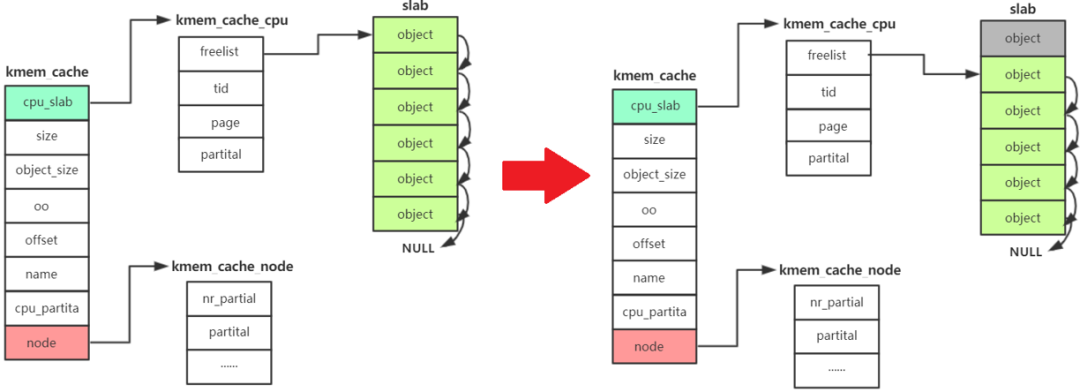
- 接著去 kmem_cache_cpu->partital鏈表中分配,如果此鏈表為null
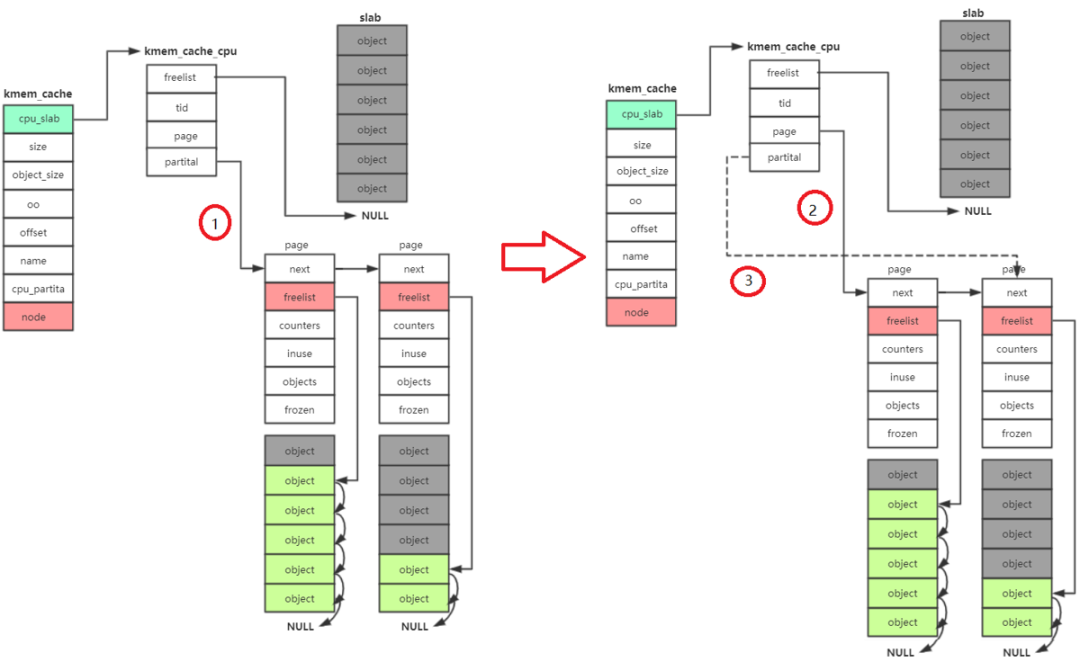
- 接著去 kmem_cache_node->partital鏈表分配,如果此鏈表為null
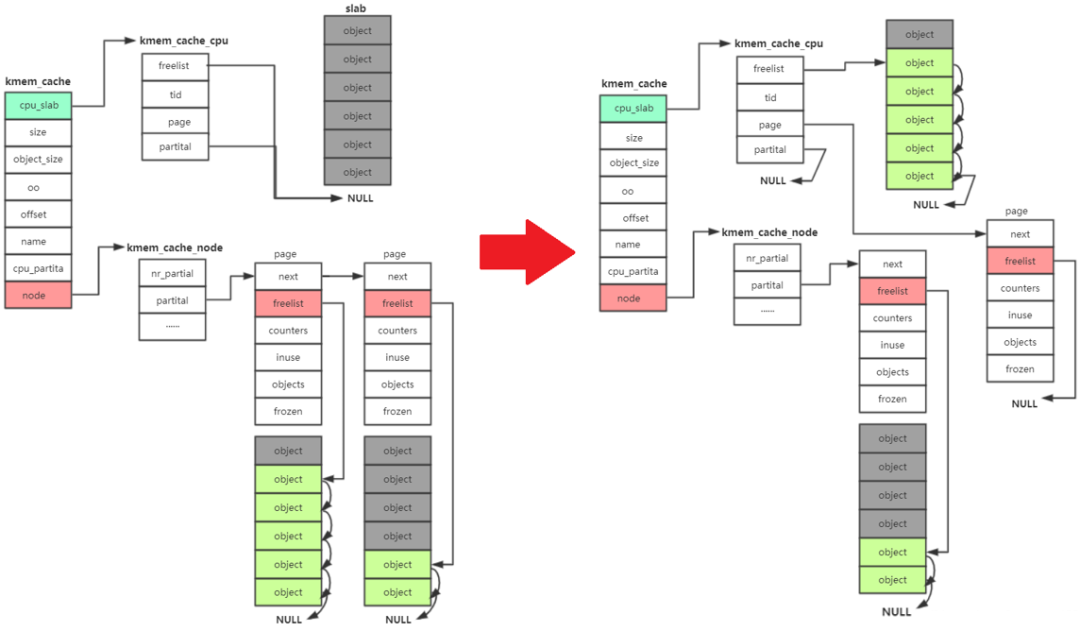
- 重新分配一個slab。
Linux 內存管理之vmalloc
根據前面的系列文章,我們知道了buddy system是基于頁框分配器,kmalloc是基于slab分配器,而且這些分配的地址都是物理內存連續的。但是隨著碎片化的積累,連續物理內存的分配就會變得困難,對于那些非DMA訪問,不一定非要連續物理內存的話完全可以像malloc那樣,將不連續的物理內存頁框映射到連續的虛擬地址空間中,這就是vmap的來源)(提供把離散的page映射到連續的虛擬地址空間),vmalloc的分配就是基于這個機制來實現的。
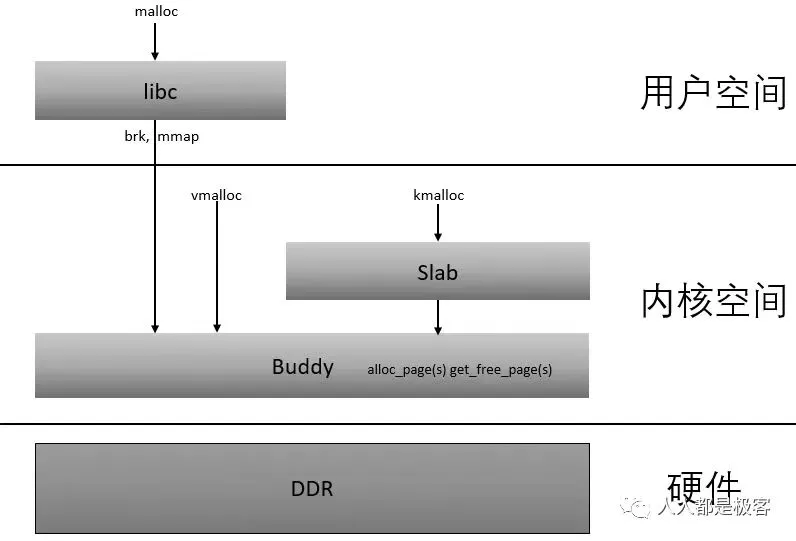
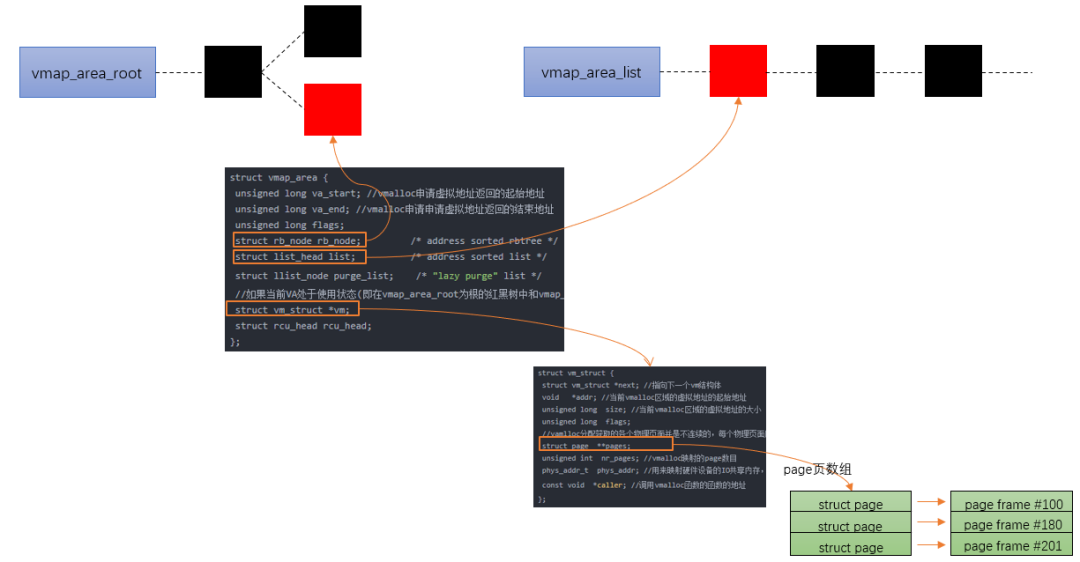
vmalloc最小分配一個page,并且分配到的頁面不保證是連續的,因為vmalloc內部調用alloc_page多次分配單個頁面。
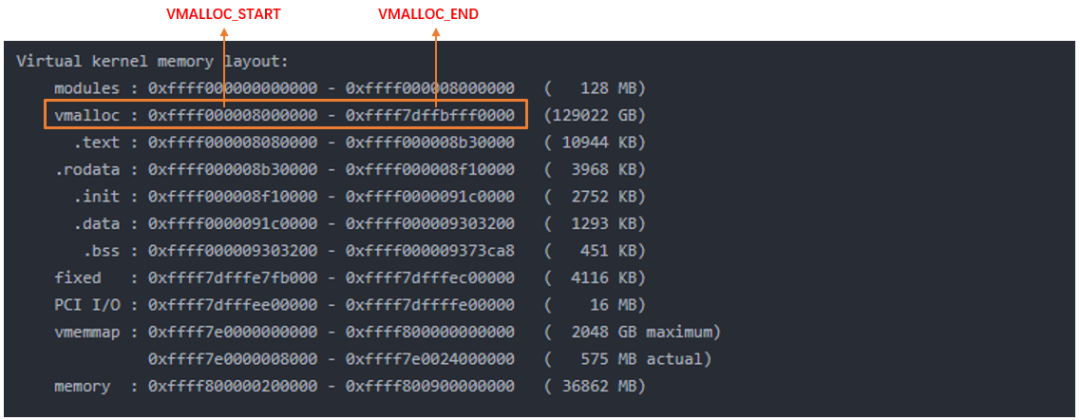
vmalloc的區域就是在上圖中VMALLOC_START - VMALLOC_END之間,可通過/proc/vmallocinfo查看。
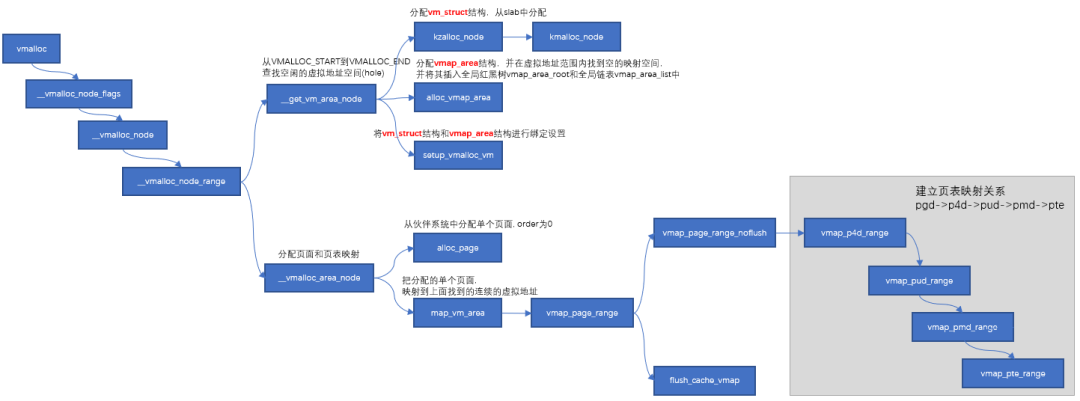
vmalloc流程
主要分以下三步:
- 從VMALLOC_START到VMALLOC_END查找空閑的虛擬地址空間(hole)
- 根據分配的size,調用alloc_page依次分配單個頁面.
- 把分配的單個頁面,映射到第一步中找到的連續的虛擬地址。把分配的單個頁面,映射到第一步中找到的連續的虛擬地址。
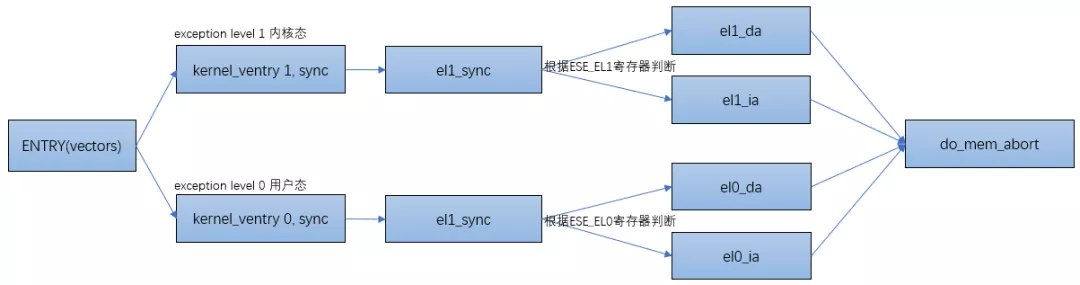
Linux進程的內存管理之缺頁異常
當進程訪問這些還沒建立映射關系的虛擬地址時,處理器會自動觸發缺頁異常。
ARM64把異常分為同步異常和異步異常,通常異步異常指的是中斷(可看《上帝視角看中斷》),同步異常指的是異常。關于ARM異常處理的文章可參考《ARMv8異常處理簡介》。
當處理器有異常發生時,處理器會先跳轉到ARM64的異常向量表中:
ENTRY(vectors)
kernel_ventry1,sync_invalid//SynchronousEL1t
kernel_ventry1,irq_invalid//IRQEL1t
kernel_ventry1,fiq_invalid//FIQEL1t
kernel_ventry1,error_invalid//ErrorEL1t
kernel_ventry1,sync//SynchronousEL1h
kernel_ventry1,irq//IRQEL1h
kernel_ventry1,fiq_invalid//FIQEL1h
kernel_ventry1,error_invalid//ErrorEL1h
kernel_ventry0,sync//Synchronous64-bitEL0
kernel_ventry0,irq//IRQ64-bitEL0
kernel_ventry0,fiq_invalid//FIQ64-bitEL0
kernel_ventry0,error_invalid//Error64-bitEL0
#ifdefCONFIG_COMPAT
kernel_ventry0,sync_compat,32//Synchronous32-bitEL0
kernel_ventry0,irq_compat,32//IRQ32-bitEL0
kernel_ventry0,fiq_invalid_compat,32//FIQ32-bitEL0
kernel_ventry0,error_invalid_compat,32//Error32-bitEL0
#else
kernel_ventry0,sync_invalid,32//Synchronous32-bitEL0
kernel_ventry0,irq_invalid,32//IRQ32-bitEL0
kernel_ventry0,fiq_invalid,32//FIQ32-bitEL0
kernel_ventry0,error_invalid,32//Error32-bitEL0
#endif
END(vectors)
以el1下的異常為例,當跳轉到el1_sync函數時,讀取ESR的值以判斷異常類型。根據類型跳轉到不同的處理函數里,如果是data abort的話跳轉到el1_da函數里,instruction abort的話跳轉到el1_ia函數里:
el1_sync:
kernel_entry1
mrsx1,esr_el1//readthesyndromeregister
lsrx24,x1,#ESR_ELx_EC_SHIFT//exceptionclass
cmpx24,#ESR_ELx_EC_DABT_CUR//dataabortinEL1
b.eqel1_da
cmpx24,#ESR_ELx_EC_IABT_CUR//instructionabortinEL1
b.eqel1_ia
cmpx24,#ESR_ELx_EC_SYS64//configurabletrap
b.eqel1_undef
cmpx24,#ESR_ELx_EC_SP_ALIGN//stackalignmentexception
b.eqel1_sp_pc
cmpx24,#ESR_ELx_EC_PC_ALIGN//pcalignmentexception
b.eqel1_sp_pc
cmpx24,#ESR_ELx_EC_UNKNOWN//unknownexceptioninEL1
b.eqel1_undef
cmpx24,#ESR_ELx_EC_BREAKPT_CUR//debugexceptioninEL1
b.geel1_dbg
bel1_inv
流程圖如下:
do_page_fault
staticint__do_page_fault(structmm_struct*mm,unsignedlongaddr,
unsignedintmm_flags,unsignedlongvm_flags,
structtask_struct*tsk)
{
structvm_area_struct*vma;
intfault;
vma=find_vma(mm,addr);
fault=VM_FAULT_BADMAP;//沒有找到vma區域,說明addr還沒有在進程的地址空間中
if(unlikely(!vma))
gotoout;
if(unlikely(vma->vm_start>addr))
gotocheck_stack;
/*
*Ok,wehaveagoodvm_areaforthismemoryaccess,sowecanhandle
*it.
*/
good_area://一個好的vma
/*
*CheckthatthepermissionsontheVMAallowforthefaultwhich
*occurred.
*/
if(!(vma->vm_flags&vm_flags)){//權限檢查
fault=VM_FAULT_BADACCESS;
gotoout;
}
//重新建立物理頁面到VMA的映射關系
returnhandle_mm_fault(vma,addr&PAGE_MASK,mm_flags);
check_stack:
if(vma->vm_flags&VM_GROWSDOWN&&!expand_stack(vma,addr))
gotogood_area;
out:
returnfault;
}
從__do_page_fault函數能看出來,當觸發異常的虛擬地址屬于某個vma,并且擁有觸發頁錯誤異常的權限時,會調用到handle_mm_fault函數來建立vma和物理地址的映射,而handle_mm_fault函數的主要邏輯是通過__handle_mm_fault來實現的。
__handle_mm_fault
staticint__handle_mm_fault(structvm_area_struct*vma,unsignedlongaddress,
unsignedintflags)
{
......
//查找頁全局目錄,獲取地址對應的表項
pgd=pgd_offset(mm,address);
//查找頁四級目錄表項,沒有則創建
p4d=p4d_alloc(mm,pgd,address);
if(!p4d)
returnVM_FAULT_OOM;
//查找頁上級目錄表項,沒有則創建
vmf.pud=pud_alloc(mm,p4d,address);
......
//查找頁中級目錄表項,沒有則創建
vmf.pmd=pmd_alloc(mm,vmf.pud,address);
......
//處理pte頁表
returnhandle_pte_fault(&vmf);
}
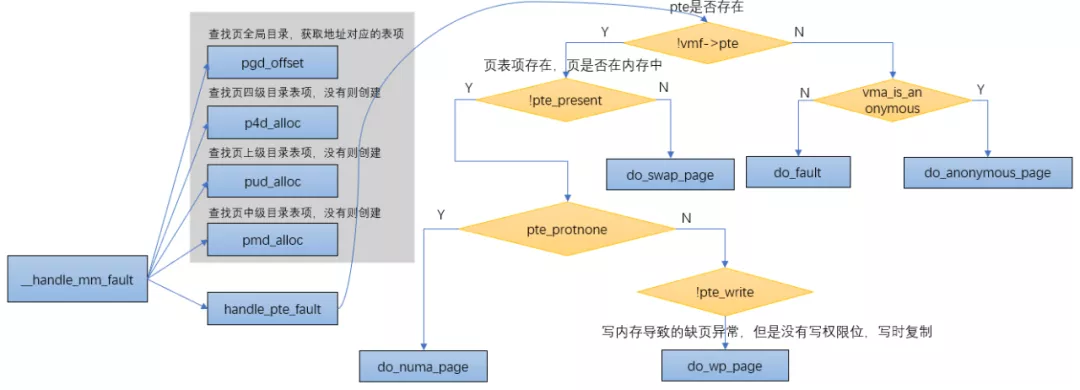
do_anonymous_page
匿名頁缺頁異常,對于匿名映射,映射完成之后,只是獲得了一塊虛擬內存,并沒有分配物理內存,當第一次訪問的時候:
- 如果是讀訪問,會將虛擬頁映射到0頁,以減少不必要的內存分配
- 如果是寫訪問,用alloc_zeroed_user_highpage_movable分配新的物理頁,并用0填充,然后映射到虛擬頁上去
- 如果是先讀后寫訪問,則會發生兩次缺頁異常:第一次是匿名頁缺頁異常的讀的處理(虛擬頁到0頁的映射),第二次是寫時復制缺頁異常處理。
從上面的總結我們知道,第一次訪問匿名頁時有三種情況,其中第一種和第三種情況都會涉及到0頁。
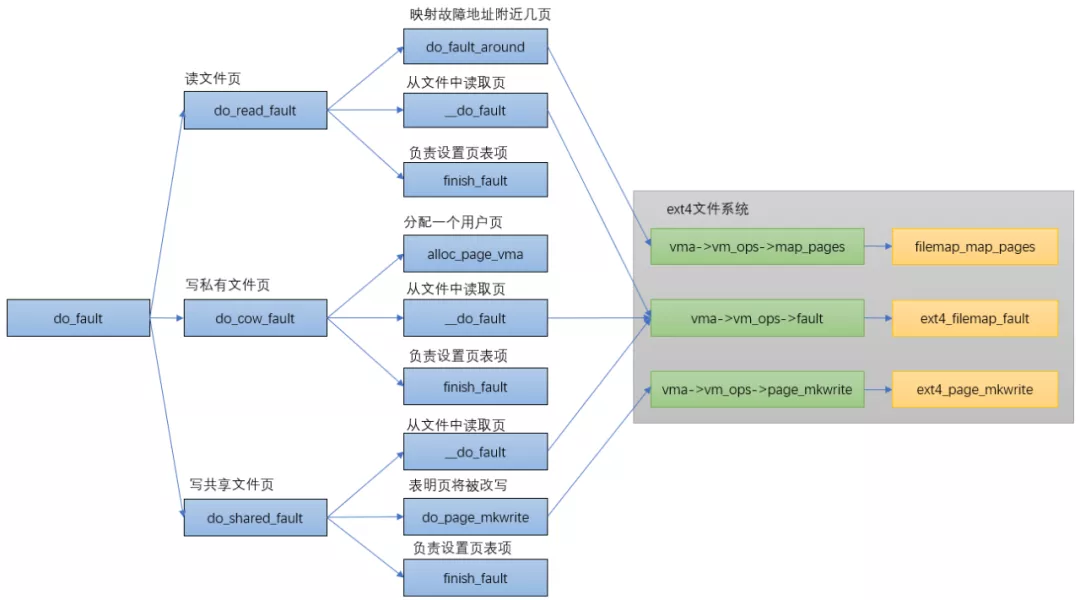
do_fault
do_swap_page
上面已經講過,pte對應的內容不為0(頁表項存在),但是pte所對應的page不在內存中時,表示此時pte的內容所對應的頁面在swap空間中,缺頁異常時會通過do_swap_page()函數來分配頁面。
do_swap_page發生在swap in的時候,即查找磁盤上的slot,并將數據讀回。
換入的過程如下:
- 查找swap cache中是否存在所查找的頁面,如果存在,則根據swap cache引用的內存頁,重新映射并更新頁表;如果不存在,則分配新的內存頁,并添加到swap cache的引用中,更新內存頁內容完成后,更新頁表。
- 換入操作結束后,對應swap area的頁引用減1,當減少到0時,代表沒有任何進程引用了該頁,可以進行回收。
intdo_swap_page(structvm_fault*vmf)
{
......
//根據pte找到swapentry,swapentry和pte有一個對應關系
entry=pte_to_swp_entry(vmf->orig_pte);
......
if(!page)
//根據entry從swap緩存中查找頁,在swapcache里面尋找entry對應的page
//Lookupaswapentryintheswapcache
page=lookup_swap_cache(entry,vma_readahead?vma:NULL,
vmf->address);
//沒有找到頁
if(!page){
if(vma_readahead)
page=do_swap_page_readahead(entry,
GFP_HIGHUSER_MOVABLE,vmf,&swap_ra);
else
//如果swapcache里面找不到就在swaparea里面找,分配新的內存頁并從swaparea中讀入
page=swapin_readahead(entry,
GFP_HIGHUSER_MOVABLE,vma,vmf->address);
......
//獲取一個pte的entry,重新建立映射
vmf->pte=pte_offset_map_lock(vma->vm_mm,vmf->pmd,vmf->address,
&vmf->ptl);
......
//anonpage數加1,匿名頁從swap空間交換出來,所以加1
//swappage個數減1,由page和VMA屬性創建一個新的pte
inc_mm_counter_fast(vma->vm_mm,MM_ANONPAGES);
dec_mm_counter_fast(vma->vm_mm,MM_SWAPENTS);
pte=mk_pte(page,vma->vm_page_prot);
......
flush_icache_page(vma,page);
if(pte_swp_soft_dirty(vmf->orig_pte))
pte=pte_mksoft_dirty(pte);
//將新生成的PTEentry添加到硬件頁表中
set_pte_at(vma->vm_mm,vmf->address,vmf->pte,pte);
vmf->orig_pte=pte;
//根據page是否為swapcache
if(page==swapcache){
//如果是,將swap緩存頁用作anon頁,添加反向映射rmap中
do_page_add_anon_rmap(page,vma,vmf->address,exclusive);
mem_cgroup_commit_charge(page,memcg,true,false);
//并添加到active鏈表中
activate_page(page);
//如果不是
}else{/*ksmcreatedacompletelynewcopy*/
//使用新頁面并復制swap緩存頁,添加反向映射rmap中
page_add_new_anon_rmap(page,vma,vmf->address,false);
mem_cgroup_commit_charge(page,memcg,false,false);
//并添加到lru鏈表中
lru_cache_add_active_or_unevictable(page,vma);
}
//釋放swapentry
swap_free(entry);
......
if(vmf->flags&FAULT_FLAG_WRITE){
//有寫請求則寫時復制
ret|=do_wp_page(vmf);
if(ret&VM_FAULT_ERROR)
ret&=VM_FAULT_ERROR;
gotoout;
}
......
returnret;
}
do_wp_page
走到這里說明頁面在內存中,只是PTE只有讀權限,而又要寫內存的時候就會觸發do_wp_page。
do_wp_page函數用于處理寫時復制(copy on write),其流程比較簡單,主要是分配新的物理頁,拷貝原來頁的內容到新頁,然后修改頁表項內容指向新頁并修改為可寫(vma具備可寫屬性)。
staticintdo_wp_page(structvm_fault*vmf)
__releases(vmf->ptl)
{
structvm_area_struct*vma=vmf->vma;
//從頁表項中得到頁幀號,再得到頁描述符,發生異常時地址所在的page結構
vmf->page=vm_normal_page(vma,vmf->address,vmf->orig_pte);
if(!vmf->page){
//沒有page結構是使用頁幀號的特殊映射
/*
*VM_MIXEDMAP!pfn_valid()case,orVM_SOFTDIRTYclearona
*VM_PFNMAPVMA.
*
*Weshouldnotcowpagesinasharedwriteablemapping.
*Justmarkthepageswritableand/orcallops->pfn_mkwrite.
*/
if((vma->vm_flags&(VM_WRITE|VM_SHARED))==
(VM_WRITE|VM_SHARED))
//處理共享可寫映射
returnwp_pfn_shared(vmf);
pte_unmap_unlock(vmf->pte,vmf->ptl);
//處理私有可寫映射
returnwp_page_copy(vmf);
}
/*
*Takeoutanonymouspagesfirst,anonymoussharedvmasare
*notdirtyaccountable.
*/
if(PageAnon(vmf->page)&&!PageKsm(vmf->page)){
inttotal_map_swapcount;
if(!trylock_page(vmf->page)){
//添加原來頁的引用計數,方式被釋放
get_page(vmf->page);
//釋放頁表鎖
pte_unmap_unlock(vmf->pte,vmf->ptl);
lock_page(vmf->page);
vmf->pte=pte_offset_map_lock(vma->vm_mm,vmf->pmd,
vmf->address,&vmf->ptl);
if(!pte_same(*vmf->pte,vmf->orig_pte)){
unlock_page(vmf->page);
pte_unmap_unlock(vmf->pte,vmf->ptl);
put_page(vmf->page);
return0;
}
put_page(vmf->page);
}
//單身匿名頁面的處理
if(reuse_swap_page(vmf->page,&total_map_swapcount)){
if(total_map_swapcount==1){
/*
*Thepageisallours.Moveitto
*ouranon_vmasothermapcodewill
*notsearchourparentorsiblings.
*Protectedagainstthermapcodeby
*thepagelock.
*/
page_move_anon_rmap(vmf->page,vma);
}
unlock_page(vmf->page);
wp_page_reuse(vmf);
returnVM_FAULT_WRITE;
}
unlock_page(vmf->page);
}elseif(unlikely((vma->vm_flags&(VM_WRITE|VM_SHARED))==
(VM_WRITE|VM_SHARED))){
//共享可寫,不需要復制物理頁,設置頁表權限即可
returnwp_page_shared(vmf);
}
/*
*Ok,weneedtocopy.Oh,well..
*/
get_page(vmf->page);
pte_unmap_unlock(vmf->pte,vmf->ptl);
//私有可寫,復制物理頁,將虛擬頁映射到物理頁
returnwp_page_copy(vmf);
}
Linux 內存管理之CMA
CMA是reserved的一塊內存,用于分配連續的大塊內存。當設備驅動不用時,內存管理系統將該區域用于分配和管理可移動類型頁面;當設備驅動使用時,此時已經分配的頁面需要進行遷移,又用于連續內存分配;其用法與DMA子系統結合在一起充當DMA的后端,具體可參考《沒有IOMMU的DMA操作》。
CMA區域 cma_areas 的創建
CMA區域的創建有兩種方法,一種是通過dts的reserved memory,另外一種是通過command line參數和內核配置參數。
- dts方式:
reserved-memory{
/*globalautoconfiguredregionforcontiguousallocations*/
linux,cma{
compatible="shared-dma-pool";
reusable;
size=<0?0x28000000>;
alloc-ranges=<0?0xa0000000?0?0x40000000>;
linux,cma-default;
};
};
device tree中可以包含reserved-memory node,系統啟動的時候會打開rmem_cma_setup
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
- command line方式:cma=nn[MG]@[start[MG][-end[MG]]]
staticint__initearly_cma(char*p)
{
pr_debug("%s(%s)
",__func__,p);
size_cmdline=memparse(p,&p);
if(*p!='@'){
/*
ifbaseandlimitarenotassigned,
setlimittohighmemorybondarytouselowmemory.
*/
limit_cmdline=__pa(high_memory);
return0;
}
base_cmdline=memparse(p+1,&p);
if(*p!='-'){
limit_cmdline=base_cmdline+size_cmdline;
return0;
}
limit_cmdline=memparse(p+1,&p);
return0;
}
early_param("cma",early_cma);
系統在啟動的過程中會把cmdline里的nn, start, end傳給函數dma_contiguous_reserve,流程如下:
setup_arch--->arm64_memblock_init--->dma_contiguous_reserve->dma_contiguous_reserve_area->cma_declare_contiguous
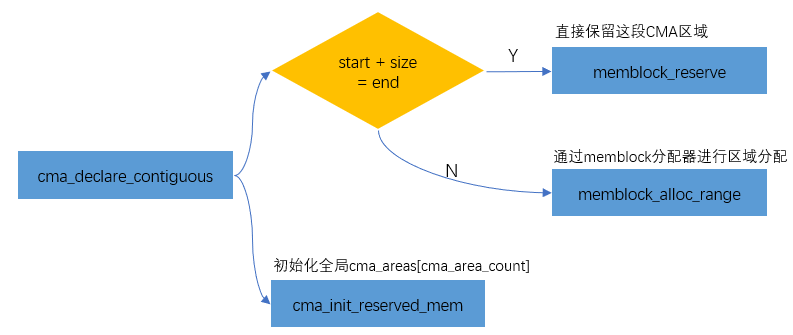
將CMA區域添加到Buddy System
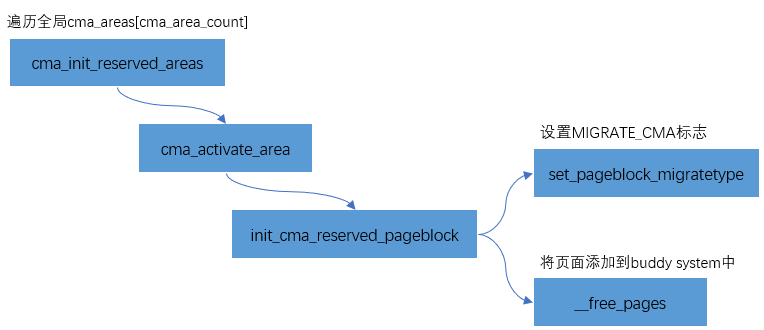
為了避免這塊reserved的內存在不用時候的浪費,內存管理模塊會將CMA區域添加到Buddy System中,用于可移動頁面的分配和管理。CMA區域是通過cma_init_reserved_areas接口來添加到Buddy System中的。
staticint__initcma_init_reserved_areas(void)
{
inti;
for(i=0;iif(ret)
returnret;
}
return0;
}
core_initcall(cma_init_reserved_areas);
其實現比較簡單,主要分為兩步:
- 把該頁面設置為MIGRATE_CMA標志
- 通過__free_pages將頁面添加到buddy system中
CMA分配
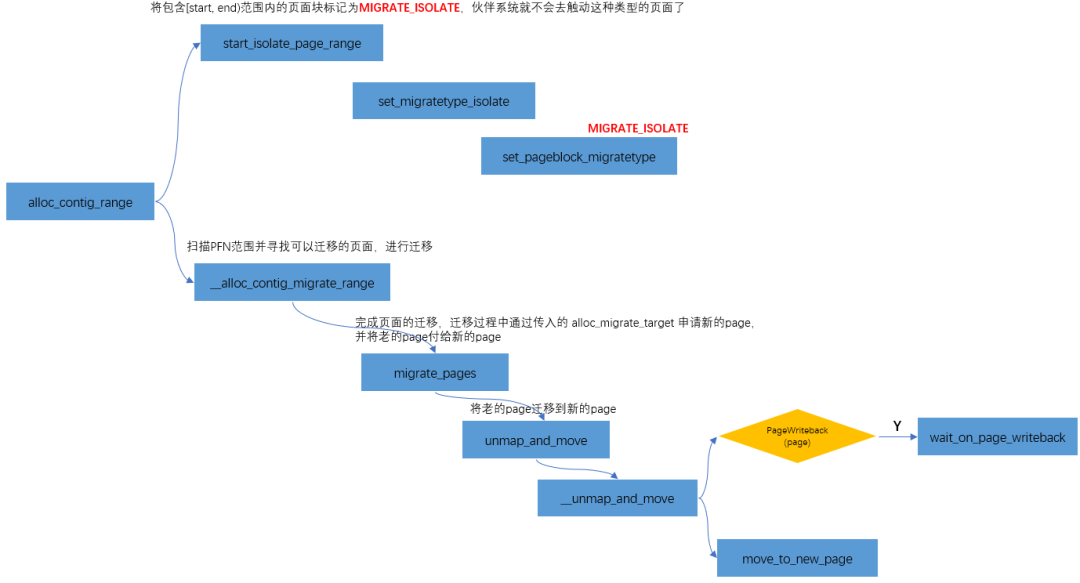
《沒有IOMMU的DMA操作》里講過,CMA是通過cma_alloc分配的。cma_alloc->alloc_contig_range(..., MIGRATE_CMA,...),向剛才釋放給buddy system的MIGRATE_CMA類型頁面,重新“收集”過來。
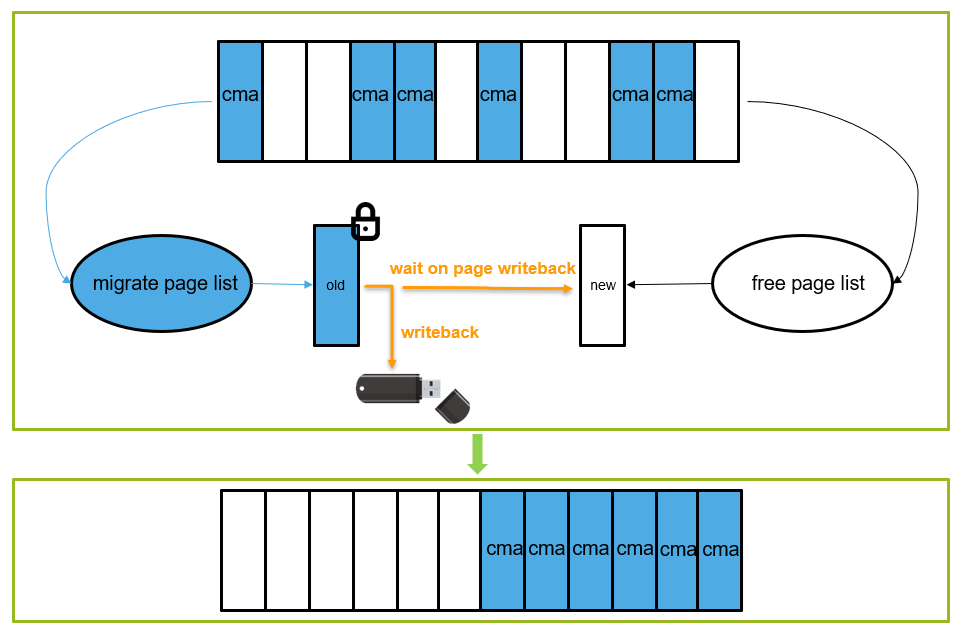
用CMA的時候有一點需要注意:
也就是上圖中黃色部分的判斷。CMA內存在分配過程是一個比較“重”的操作,可能涉及頁面遷移、頁面回收等操作,因此不適合用于atomic context。比如之前遇到過一個問題,當內存不足的情況下,向U盤寫數據的同時操作界面會出現卡頓的現象,這是因為CMA在遷移的過程中需要等待當前頁面中的數據回寫到U盤之后,才會進一步的規整為連續內存供gpu/display使用,從而出現卡頓的現象。
總結
至此,從CPU開始訪問內存,到物理頁的劃分,再到內核頁框分配器的實現,以及slab分配器的實現,最后到CMA等連續內存的使用,把Linux內存管理的知識串了起來,算是形成了整個閉環。相信如果掌握了本篇內容,肯定打開了Linux內核的大門,有了這個基石,接下來的內核學習會越來越輕松。
原文標題:萬字整理,肝翻Linux內存管理所有知識點
文章出處:【微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
-
Linux
+關注
關注
87文章
11292瀏覽量
209328 -
內存管理
+關注
關注
0文章
168瀏覽量
14134
原文標題:萬字整理,肝翻Linux內存管理所有知識點
文章出處:【微信號:yikoulinux,微信公眾號:一口Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論