


作者
武卓博士
曾主持國家級及省部級科研項目十余項,已授權國際國內專利十余項。
前言:該技術能讓PaddleOCR的開發者在筆記本電腦上即可獲得超越40FPS的速度,極大降低了PaddleOCR的部署成本。
簡介
在上篇文章中我們介紹過,光學字符識別(OCR)技術可以將文件、圖片或自然場景中的文字信息進行識別并提取,與一系列的自然語言處理技術聯合使用,能夠完成諸如文檔票據的文字信息自動化處理、實時圖片文字翻譯等任務。通過機器的自動化處理,可以幫助財務人員在處理票據時省卻大量手工輸入的工作量,也能夠方便我們在出國旅游時隨時對異域中的外國文字信息進行實時翻譯、減少語言不通帶來的不便。
既然OCR技術如此實用,有沒有什么方法能讓我們利用自己手邊的設備,隨時使用到這項技術呢?答案當然是肯定的。接下來,我們將以百度開源的PaddleOCR1-2 技術為例,具體介紹如何利用英特爾開源的OpenVINO 工具套件,僅使用我們手邊都有的CPU就能輕松實現對PaddleOCR的實時推理。
本篇是用OpenVINO 工具套件實現基于OCR及NLP輕松實現信息自動化提取的系列博客中的第二篇。我們將簡要介紹PaddleOCR的原理,以及利用OpenVINO 工具套件實現PaddleOCR推理加速的工作流程。同樣只需利用一頁Jupyter notebook,依照簡單的三個步驟,即可利用CPU實現基于PaddleOCR的實時文字信息提取。
PaddleOCR原理簡介
PaddleOCR是基于深度學習框架PaddlePaddle的一項OCR技術,具有超輕、模型小、便于移動端及服務器端部署等特點。整個PaddleOCR技術的工作流程如下圖所示,主要包括文本檢測、方向分類、以及文本識別三部分。
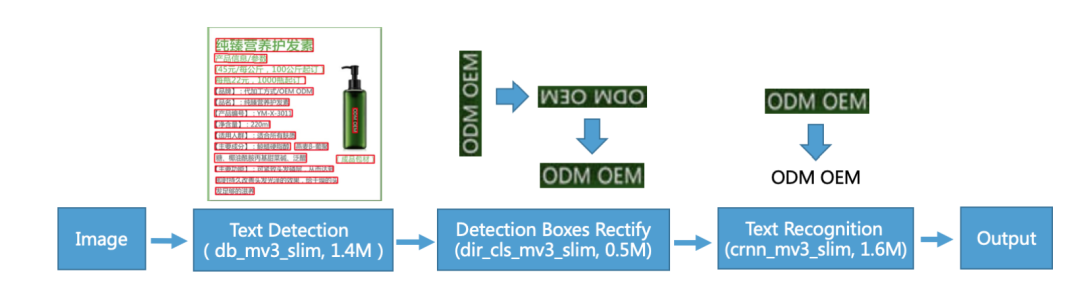
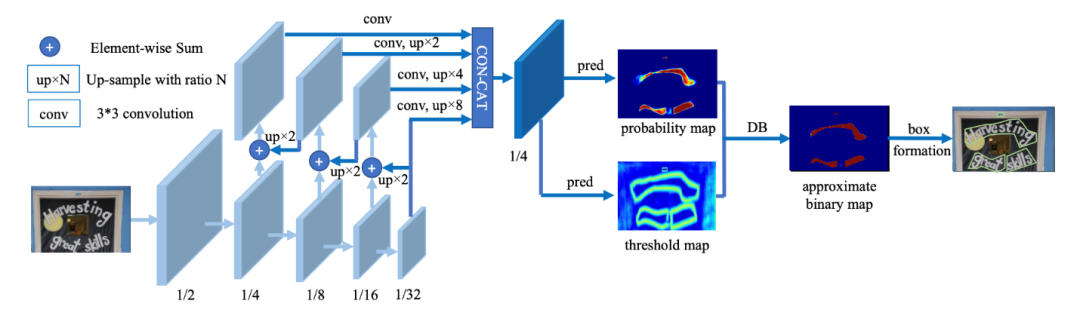
文本檢測任務是找出圖像或視頻中的文字位置。不同于目標檢測任務,目標檢測不僅要解決定位問題,還要解決目標分類問題。但是,文本檢測也面臨一些難點,比如:自然場景中的文本具有多樣性,文字大小、方向、長度、形狀、語言都會有不同。有的時候,文字重疊或者密度較高,這些都會影響最終文本檢測的效果。目前常用的文本檢測方法有基于回歸以及基于分割的方法。而在PaddleOCR中,我們選取的是基于分割的DBNet3方法。
DBNet的工作原理如下圖所示。針對基于分割的方法需要使用閾值進行二值化處理而導致后處理耗時的問題,DBNet提出了一種可學習閾值的方法,并巧妙地設計了一個近似于階躍函數的二值化函數,使得分割網絡在訓練的時候能端對端的學習文本分割的閾值。自動調節閾值不僅帶來精度的提升,同時簡化了后處理,提高了文本檢測的性能。
方向分類指的是針對圖片中某些經文本檢測得到的bounding box中的文字方向為非水平排列的情況,對bounding box的方向進行檢測。如果發現bounding box中的文字方向為非水平排列,則對該bounding box的方向進行糾正,使其旋轉為文字水平排列的方向,方便下一步的文本識別。
文本識別的任務是將文本檢測得到的bounding box中的具體的文字內容識別出來。文本識別的算法有針對規則文本以及不規則文本識別的算法。對于規則文本,主流的算法CTC(Conectionist Temporal Classification)和基于Sequence2Sequence 的方法。
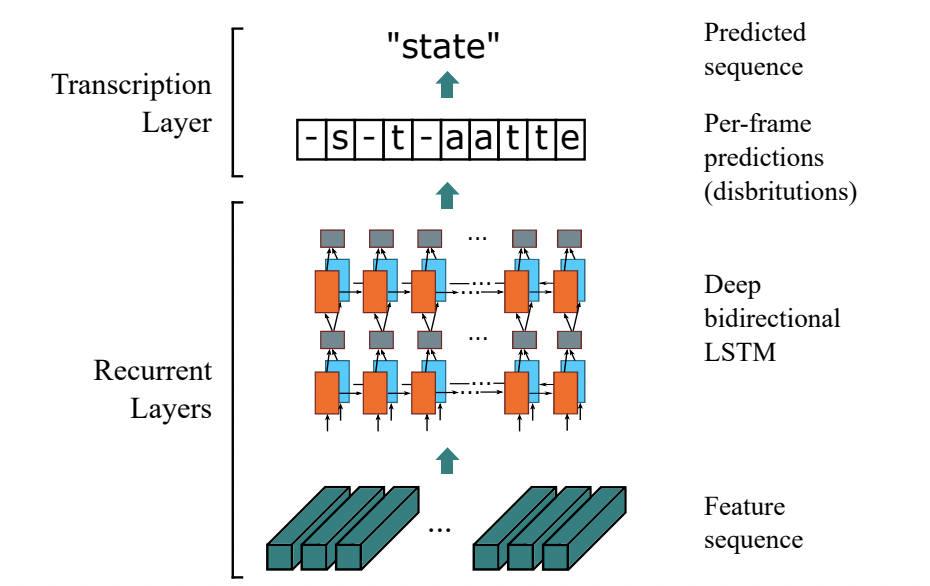
在本文demo中,我們采用的是基于CTC的方法。由于文本識別任務的特殊性,輸入數據中存在大量的上下文信息,卷積神經網絡的卷積核特性使其更關注于局部信息,缺乏長依賴的建模能力,因此僅使用CNN很難挖掘到文本之間的上下文聯系。
為了解決這一問題,首先通過使用CRNN (Convolutional Recurrent Neural Network)4 ,利用卷積網絡提取圖像特征,并同時引入了雙向 LSTM(Long Short-Term Memory) 用來增強上下文建模。最終將輸出的特征序列輸入到CTC模塊, 通過ctc歸納字符間的連接特性,直接解碼序列結果。該結構被驗證有效,并廣泛應用在文本識別任務中, 如下圖所示。
5分鐘 3步驟
快速實現PaddleOCR實時推理
在最新版本的OpenVINO 2022.1中,已經實現了對基于PaddlePaddle深度學習框架的深度學習模型的支持。而PaddleOCR作為一項深受廣大開發者喜愛的開源技術,其中開源的預訓練模型已經可以在OpenVINO 2022.1版本中直接進行模型讀取以及加速推理。
接下來,我們將通過代碼示例,介紹如何按照簡單的三個步驟,實現OpenVINO 工具套件對PaddleOCR的加速推理。整個工作流程如下圖所示:
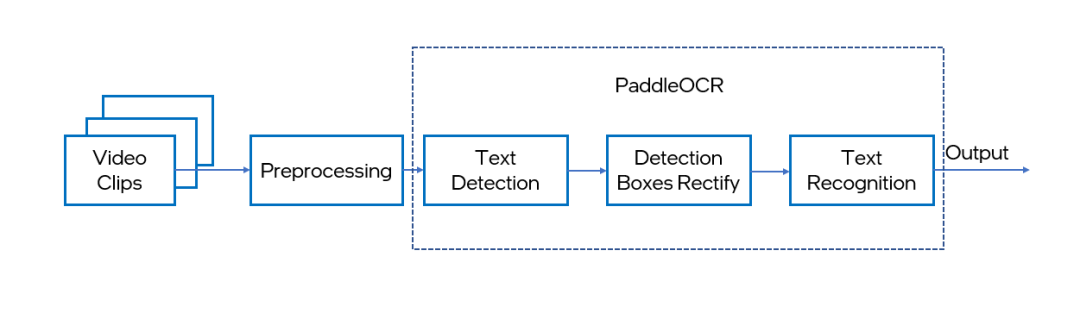
其中OpenVINO 工具套件會對PaddleOCR中的文本檢測以及文本識別模型進行讀取以及推理加速。本次demo中我們展示的是利用自己的網絡攝像頭,將實時獲取的視頻流中的文字信息利用PaddleOCR進行提取。當然,開發者也可以上傳圖片,利用OpenVINO 工具套件對PaddleOCR的推理實現對圖片中的文字信息進行提取。
步驟一:下載需要使用的PaddleOCR預訓練模型,并完成模型的讀取與加載
在導入需要使用到的相應Python包后,首先需要對將要使用的PaddleOCR開源預訓練模型進行下載。本次demo中使用到的是輕量化的"Chinese and English ultra-lightweight PP-OCR model (9.4M)"模型。由于PaddleOCR中包含了文本檢測及文本識別兩個深度學習模型,因此,我們首先定義一個模型下載函數,如下圖所示。

接下來,完成文本檢測模型的下載,
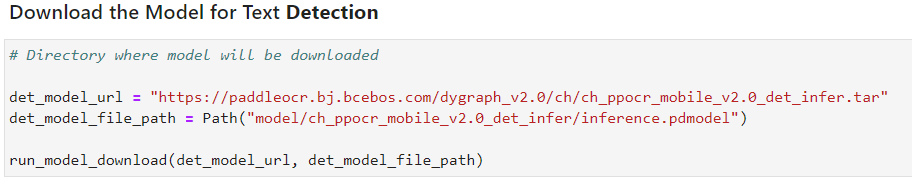
以及推理引擎的初始化、文本檢測模型的讀取以及在 CPU上面的加載。
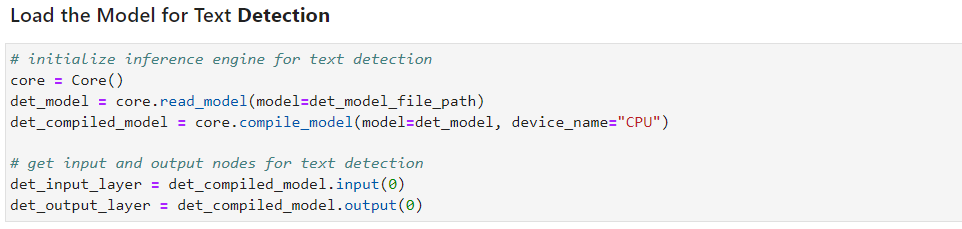
再然后,完成文本識別模型的下載,

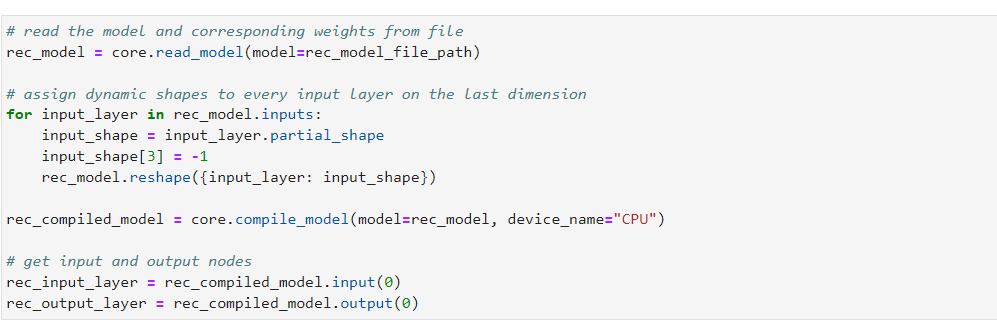
以及文本識別模型的讀取以及在CPU上面的加載。其中,有一步需要特別說明的是,動態輸入的處理。
由于文本識別模型的輸入是文本檢測得到的一系列bounding box圖像,而圖像中的字體由于大小和文字長短程度不一,就造成了文本識別模型的輸入是動態輸入的。與以往版本需要對圖像尺寸進行重調整(resize)而將模型輸入尺寸固定、從而可能引起性能損失的處理方法不同的是,OpenVINO 2022. 1版本已經可以很好的支持模型的動態輸入。
在CPU上進行文本識別模型加載之前,只需要對于輸入的若干維度中具有動態輸入的維度賦值-1或申明動態輸入尺寸的上限值,比如Dimension(1,512),即可完成對模型動態輸入的處理。接下來,即可按常規步驟完成在CPU上加載文本識別模型。
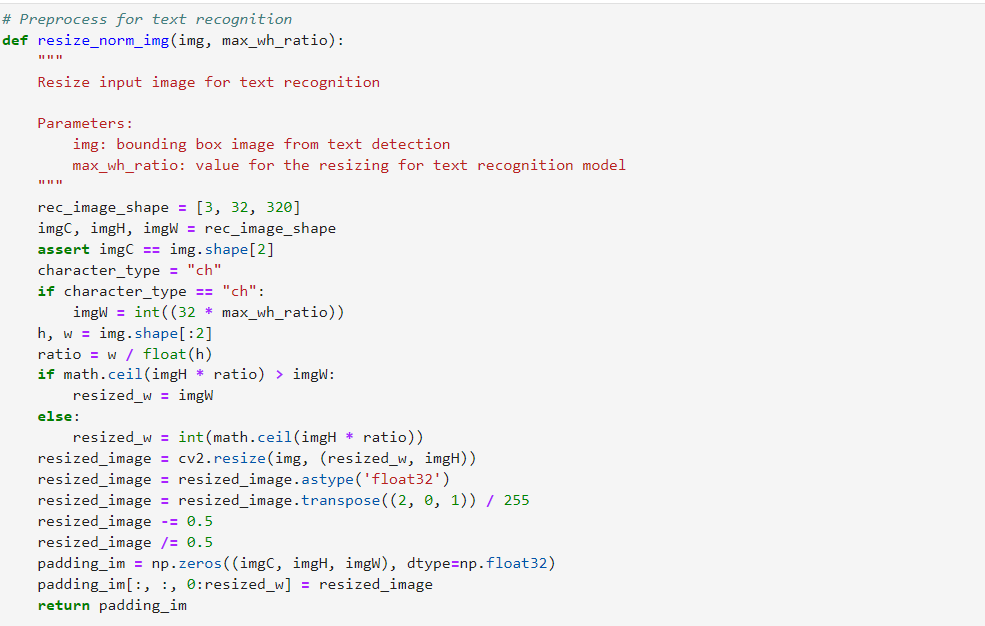
步驟二:為文本檢測及文本識別定義必要的前處理及后處理函數。
為文本檢測模型定義必要的前處理函數,如下圖所示

為文本識別模型定義必要的前處理函數,如下圖所示

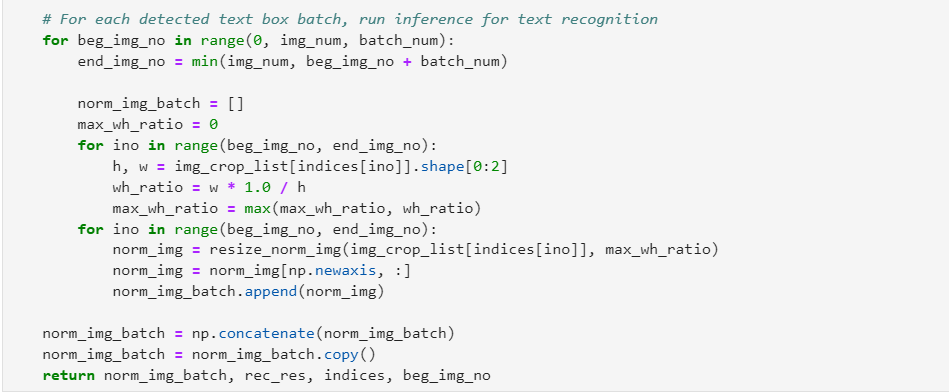
為文本檢測模型定義后處理函數,將文本檢測模型的推理結果轉為bounding box形式,作為文本識別模型的輸入,如下圖所示。
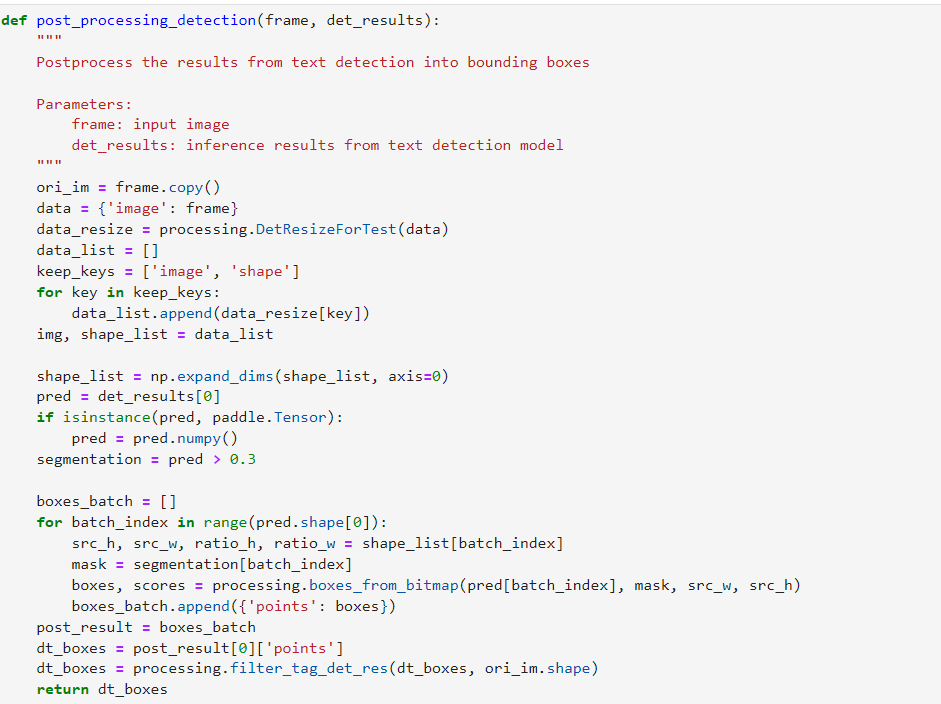
步驟三:利用OpenVINO 工具套件推理引擎(Runtime)針對攝像頭采集視頻進行實時推理

定義運行PaddleOCR模型推理的主函數,主要包括以下四個部分:
01運行網絡攝像頭,將捕捉到的視頻流作為paddleOCR的輸入

02準備進行文本檢測和文本識別的視頻幀

03針對文本檢測進行推理
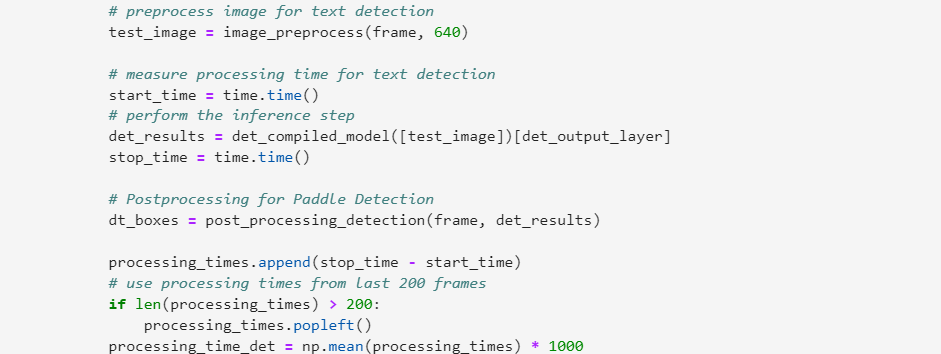
根據文本檢測得到的bounding box,進行文本識別推理

04將文本提取的結果可視化
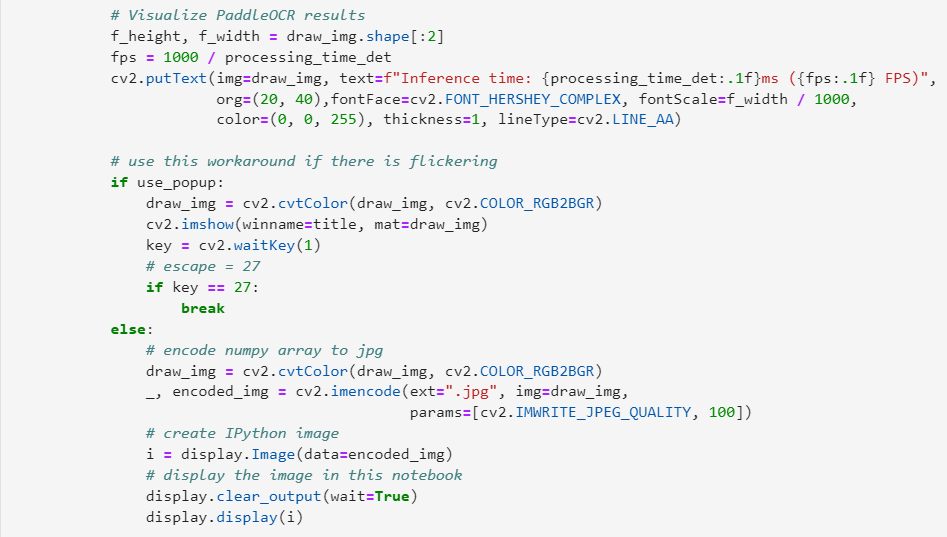
結果討論
下面我們來看看運行結果吧:
我們可以看到,對于網絡攝像頭采集的視頻流中的文字提取效果還是很不錯的。僅僅利用CPU進行推理,也可以得到30FPS以上的性能,可以說能夠達到實時的推理效果!當然,除了視頻流作為輸入,開發者還可以上傳圖片,進行文本信息提取。以下是針對上傳圖片中印刷體文字和手寫體文字信息提取的一些測試效果。
你還在等什么,快來根據我們提供的源代碼,在自己的個人電腦上嘗試一下吧!
小結
OCR具有將圖片、掃描文檔或自然場景中的文字信息識別轉化為數字化、機器編碼方式存儲的優勢。將OCR進行文字識別的結果與自然語言處理中的NLP技術相結合,能夠實現自動化的信息提取,為我們免去手動輸入信息填寫的麻煩,并有助于信息的結構化存儲與查找。在本次系列博客的第二篇中,我們簡要介紹了PaddleOCR的工作原理,并提供了一個基于OpenVINO 工具套件實現PaddleOCR的Jupyter notebook demo。可以方便讀者在閱讀的同時,下載源碼并在自己的電腦端利用CPU來輕松實現PaddleOCR的加速推理。
原文標題:用OpenVINO? 輕松實現PaddleOCR實時推理 | 開發者實戰
文章出處:【微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
-
英特爾
+關注
關注
61文章
10204瀏覽量
174916 -
OCR
+關注
關注
0文章
161瀏覽量
16816 -
深度學習
+關注
關注
73文章
5564瀏覽量
122889
原文標題:用OpenVINO? 輕松實現PaddleOCR實時推理 | 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
信而泰×DeepSeek:AI推理引擎驅動網絡智能診斷邁向 “自愈”時代

大模型推理顯存和計算量估計方法研究
Modbus轉以太網終極方案:三步實現老舊設備智能升級
Claude 3.7:編碼助手首選,claude api key如何申請獲取與深度解析*

150℃無壓燒結銀最簡單三個步驟
“輕松上手!5分鐘學會用京東云打造你自己的專屬DeepSeek”
工程師指南:38步驟 反激式開關電源設計提供全面指導

實現實時三維測量的技術挑戰
如何實現數字孿生?分為以下四步驟
放電消納負載如何實現的
FPGA和ASIC在大模型推理加速中的應用


PCBA加工打樣要經過哪些流程?每一步驟都很關鍵






 工商網監
工商網監

評論